
- 1苹果(APPLE)开发者账号说明及注册流程(99美元公司版/个人版及299美元企业版)_apple developer 申请299企业证书
- 2MySQL健康检查(一)_mysql 健康检查
- 3如何实现sam(Segment Anything Model)|fastsam模型_sam模型能自己训练吗
- 4YOLO系列:YOLO V3模型讲解_置信度损失值
- 5uniapp vue3版本 引用color-ui的cu-custom组件问题
- 6Android 布局中@NULL的使用和代码实现方式详解_android @null
- 7Linux系统编程之Linux 信号集编程:信号集的基本概念、用法和实现方式_linux信号集
- 8Parallels Desktop 19破解版下载,如果Parallels Desktop密钥15天激活期限能延长_parallels desktop19到期怎么办
- 9面试题005-Java-JVM(上)
- 10如何把视频转成文字稿?分享7个视频转文字方法!
Hadoop Yarn详解_yarn 主要监控指标
赞
踩
https://www.cnblogs.com/lzc-1105m/p/9984122.html
https://blog.csdn.net/weixin_34348174/article/details/91841245
架构:yarn+hive
问题:yarn中使用capacity scheduler做任务调度,创建了三个队列分别为不同的场景提供服务。后来发现一个问题,在集群资源充裕的情况下,yarn中的并发applicaiton都特别少,在hive管理界面上,查看应用状态,提示:“ACCEPTED:waiting for AM contrainer to be allocated,launched and register with RM.”查资料后,我的理解应该是application在等待任务contrainer,由于拿不到资源,导致pending,同时检查memory used和vcores used两个指标均只用了一半资源,集群利用效率上不去
解决:在检查yarn的队列配置中主要有两个参数用来控制application的资源分配
yarn.scheduler.capacity.<queue-path>.user-limit-factor:每个用户能使用队列资源的上线,默认是10,即:10%,因为我们的场景都是单用户使用该队列,我们调到了100;
yarn.scheduler.capacity.<queue-path>.maximum-am-resource-percent:队列资源拿多少资源出来分配给application(注意:yarn中container有两种用途,一种是分配给application,另外一种是分配给map或者reducer任务)
重启服务器后,观察队列的使用情况,集群效率低的问题得到了很大的改善。
摘要: 一、Yarn简介 Yarn是Hadoop集群的资源管理系统。Hadoop2.0对MapReduce框架做了彻底的设计重构,我们称Hadoop2.0中的MapReduce为MRv2或者Yarn。
一、Yarn简介
Yarn是Hadoop集群的资源管理系统。Hadoop2.0对MapReduce框架做了彻底的设计重构,我们称Hadoop2.0中的MapReduce为MRv2或者Yarn。在介绍Yarn之前,我们先回头看一下Hadoop1.x对MapReduce job的调度管理方式(可参考:Hadoop核心之MapReduce架构设计),它主要包括两部分功能:
- 1. ResourceManagement 资源管理
- 2. JobScheduling/JobMonitoring 任务调度监控
到了Hadoop2.x也就是Yarn,它的目标是将这两部分功能分开,也就是分别用两个进程来管理这两个任务:
- 1. ResourceManger
- 2. ApplicationMaster
需要注意的是,在Yarn中我们把job的概念换成了application,因为在新的Hadoop2.x中,运行的应用不只是MapReduce了,还有可能是其它应用如一个DAG(有向无环图Directed Acyclic Graph,例如storm应用)。Yarn的另一个目标就是拓展Hadoop,使得它不仅仅可以支持MapReduce计算,还能很方便的管理诸如Hive、Hbase、Pig、Spark/Shark等应用。这种新的架构设计能够使得各种类型的应用运行在Hadoop上面,并通过Yarn从系统层面进行统一的管理,也就是说,有了Yarn,各种应用就可以互不干扰的运行在同一个Hadoop系统中,共享整个集群资源,如下图所示: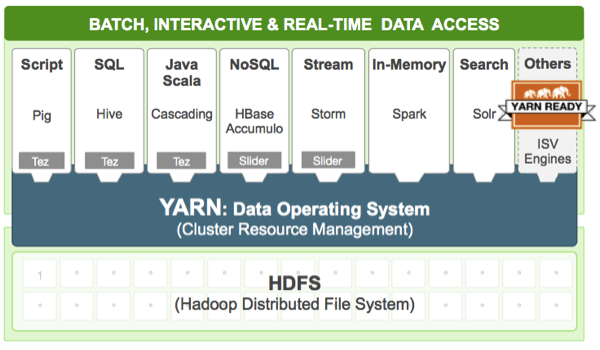
二、Yarn的组件及架构
Yarn主要由以下几个组件组成:
- 1. ResourceManager:Global(全局)的进程
- 2. NodeManager:运行在每个节点上的进程
- 3. ApplicationMaster:Application-specific(应用级别)的进程
- - *Scheduler:是ResourceManager的一个组件*
- - *Container:节点上一组CPU和内存资源*
Container是Yarn对计算机计算资源的抽象,它其实就是一组CPU和内存资源,所有的应用都会运行在Container中。ApplicationMaster是对运行在Yarn中某个应用的抽象,它其实就是某个类型应用的实例,ApplicationMaster是应用级别的,它的主要功能就是向ResourceManager(全局的)申请计算资源(Containers)并且和NodeManager交互来执行和监控具体的task。Scheduler是ResourceManager专门进行资源管理的一个组件,负责分配NodeManager上的Container资源,NodeManager也会不断发送自己Container使用情况给ResourceManager。
ResourceManager和NodeManager两个进程主要负责系统管理方面的任务。ResourceManager有一个Scheduler,负责各个集群中应用的资源分配。对于每种类型的每个应用,都会对应一个ApplicationMaster实例,ApplicationMaster通过和ResourceManager沟通获得Container资源来运行具体的job,并跟踪这个job的运行状态、监控运行进度。
下面我们看一下整个Yarn的架构图: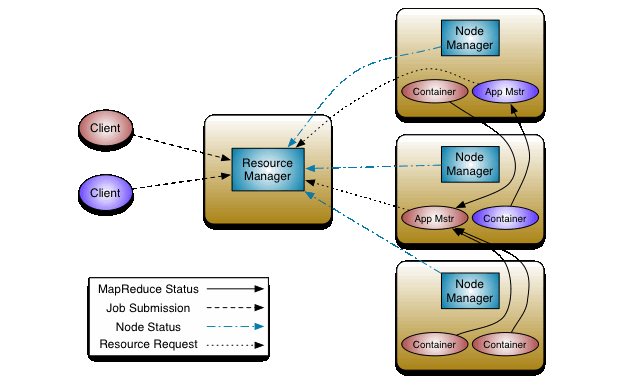
三、Yarn的组件详解
3.1 Container
Container是Yarn框架的计算单元,是具体执行应用task(如map task、reduce task)的基本单位。Container和集群节点的关系是:一个节点会运行多个Container,但一个Container不会跨节点。
一个Container就是一组分配的系统资源,现阶段只包含两种系统资源(之后可能会增加磁盘、网络等资源):
- 1. CPU core
- 2. Memory in MB
既然一个Container指的是具体节点上的计算资源,这就意味着Container中必定含有计算资源的位置信息:计算资源位于哪个机架的哪台机器上。所以我们在请求某个Container时,其实是向某台机器发起的请求,请求的是这台机器上的CPU和内存资源。
任何一个job或application必须运行在一个或多个Container中,在Yarn框架中,ResourceManager只负责告诉ApplicationMaster哪些Containers可以用,ApplicationMaster还需要去找NodeManager请求分配具体的Container。
3.2 Node Manager
NodeManager进程运行在集群中的节点上,每个节点都会有自己的NodeManager。NodeManager是一个slave服务:它负责接收ResourceManager的资源分配请求,分配具体的Container给应用。同时,它还负责监控并报告Container使用信息给ResourceManager。通过和ResourceManager配合,NodeManager负责整个Hadoop集群中的资源分配工作。ResourceManager是一个全局的进程,而NodeManager只是每个节点上的进程,管理这个节点上的资源分配和监控运行节点的健康状态。下面是NodeManager的具体任务列表:
- - 接收ResourceManager的请求,分配Container给应用的某个任务
- - 和ResourceManager交换信息以确保整个集群平稳运行。ResourceManager就是通过收集每个NodeManager的报告信息来追踪整个集群健康状态的,而NodeManager负责监控自身的健康状态。
- - 管理每个Container的生命周期
- - 管理每个节点上的日志
- - 执行Yarn上面应用的一些额外的服务,比如MapReduce的shuffle过程
当一个节点启动时,它会向ResourceManager进行注册并告知ResourceManager自己有多少资源可用。在运行期,通过NodeManager和ResourceManager协同工作,这些信息会不断被更新并保障整个集群发挥出最佳状态。
NodeManager只负责管理自身的Container,它并不知道运行在它上面应用的信息。负责管理应用信息的组件是ApplicationMaster,在后面会讲到。
3.3 Resource Manager
ResourceManager主要有两个组件:Scheduler和ApplicationManager。
Scheduler是一个资源调度器,它主要负责协调集群中各个应用的资源分配,保障整个集群的运行效率。Scheduler的角色是一个纯调度器,它只负责调度Containers,不会关心应用程序监控及其运行状态等信息。同样,它也不能重启因应用失败或者硬件错误而运行失败的任务
Scheduler是一个可插拔的插件,它可以调度集群中的各种队列、应用等。在Hadoop的MapReduce框架中主要有两种Scheduler:Capacity Scheduler和Fair Scheduler,关于这两个调度器后面会详细介绍。
另一个组件ApplicationManager主要负责接收job的提交请求,为应用分配第一个Container来运行ApplicationMaster,还有就是负责监控ApplicationMaster,在遇到失败时重启ApplicationMaster运行的Container。
3.4 Application Master
ApplicationMaster的主要作用是向ResourceManager申请资源并和NodeManager协同工作来运行应用的各个任务然后跟踪它们状态及监控各个任务的执行,遇到失败的任务还负责重启它。
在MR1中,JobTracker即负责job的监控,又负责系统资源的分配。而在MR2中,资源的调度分配由ResourceManager专门进行管理,而每个job或应用的管理、监控交由相应的分布在集群中的ApplicationMaster,如果某个ApplicationMaster失败,ResourceManager还可以重启它,这大大提高了集群的拓展性。
在MR1中,Hadoop架构只支持MapReduce类型的job,所以它不是一个通用的框架,因为Hadoop的JobTracker和TaskTracker组件都是专门针对MapReduce开发的,它们之间是深度耦合的。Yarn的出现解决了这个问题,关于Job或应用的管理都是由ApplicationMaster进程负责的,Yarn允许我们自己开发ApplicationMaster,我们可以为自己的应用开发自己的ApplicationMaster。这样每一个类型的应用都会对应一个ApplicationMaster,一个ApplicationMaster其实就是一个类库。这里要区分ApplicationMaster*类库和ApplicationMaster实例*,一个ApplicationMaster类库何以对应多个实例,就行java语言中的类和类的实例关系一样。总结来说就是,每种类型的应用都会对应着一个ApplicationMaster,每个类型的应用都可以启动多个ApplicationMaster实例。所以,在yarn中,是每个job都会对应一个ApplicationMaster而不是每类。
Yarn 框架相对于老的 MapReduce 框架什么优势呢?
- - 这个设计大大减小了 ResourceManager 的资源消耗,并且让监测每一个 Job 子任务 (tasks) 状态的程序分布式化了,更安全、更优美。
- - 在新的 Yarn 中,ApplicationMaster 是一个可变更的部分,用户可以对不同的编程模型写自己的 AppMst,让更多类型的编程模型能够跑在 Hadoop 集群中,可以参考 hadoop Yarn 官方配置模板中的 ``mapred-site.xml`` 配置。
- - 对于资源的表示以内存为单位 ( 在目前版本的 Yarn 中,没有考虑 cpu 的占用 ),比之前以剩余 slot 数目更合理。
- - 老的框架中,JobTracker 一个很大的负担就是监控 job 下的 tasks 的运行状况,现在,这个部分就扔给 ApplicationMaster 做了,而 ResourceManager 中有一个模块叫做 ApplicationsManager,它是监测 ApplicationMaster 的运行状况,如果出问题,会将其在其他机器上重启。
- - Container 是 Yarn 为了将来作资源隔离而提出的一个框架。这一点应该借鉴了 Mesos 的工作,目前是一个框架,仅仅提供 java 虚拟机内存的隔离 ,hadoop 团队的设计思路应该后续能支持更多的资源调度和控制 , 既然资源表示成内存量,那就没有了之前的 map slot/reduce slot 分开造成集群资源闲置的尴尬情况。
四、Yarn request分析
4.1 应用提交过程分析
了解了上面介绍的这些概念,我们有必要看一下Application在Yarn中的执行过程,整个执行过程可以总结为三步:
- 1. 应用程序提交
- 2. 启动应用的ApplicationMaster实例
- 3. ApplicationMaster实例管理应用程序的执行
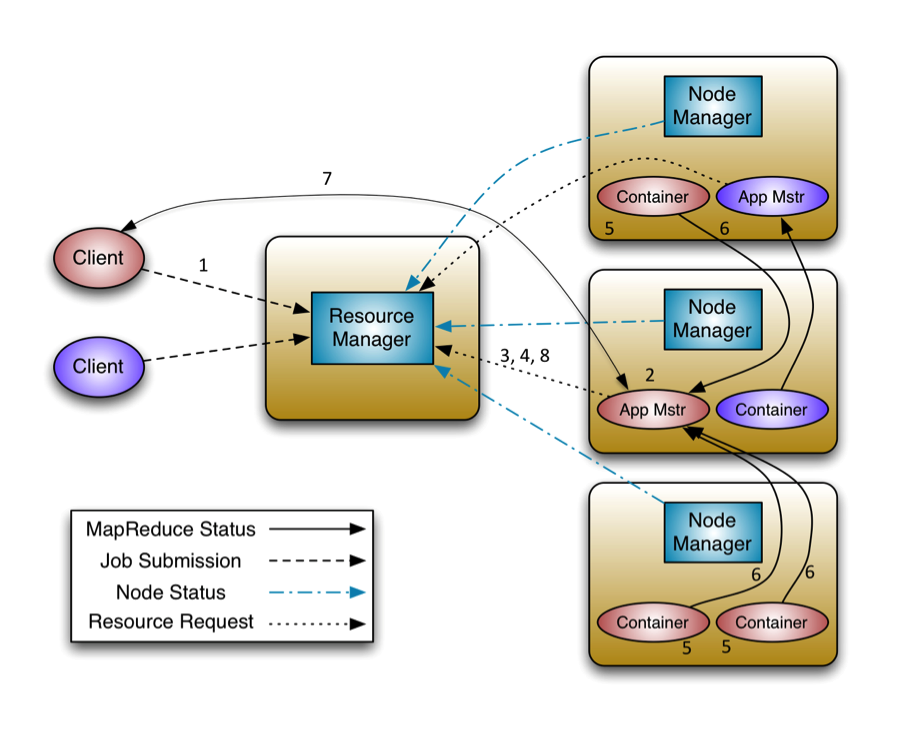
下面这幅图展示了应用程序的整个执行过程:
-
客户端程序向ResourceManager提交应用并请求一个ApplicationMaster实例
-
ResourceManager找到可以运行一个Container的NodeManager,并在这个Container中启动ApplicationMaster实例
-
ApplicationMaster向ResourceManager进行注册,注册之后客户端就可以查询ResourceManager获得自己ApplicationMaster的详细信息,以后就可以和自己的ApplicationMaster直接交互了
-
在平常的操作过程中,ApplicationMaster根据
resource-request协议向ResourceManager发送resource-request请求 -
当Container被成功分配之后,ApplicationMaster通过向NodeManager发送
container-launch-specification信息来启动Container, container-launch-specification信息包含了能够让Container和ApplicationMaster交流所需要的资料 -
应用程序的代码在启动的Container中运行,并把运行的进度、状态等信息通过
application-specific协议发送给ApplicationMaster -
在应用程序运行期间,提交应用的客户端主动和ApplicationMaster交流获得应用的运行状态、进度更新等信息,交流的协议也是
application-specific协议 -
一但应用程序执行完成并且所有相关工作也已经完成,ApplicationMaster向ResourceManager取消注册然后关闭,用到所有的Container也归还给系统
4.2 Resource Request和Container
Yarn的设计目标就是允许我们的各种应用以共享、安全、多租户的形式使用整个集群。并且,为了保证集群资源调度和数据访问的高效性,Yarn还必须能够感知整个集群拓扑结构。为了实现这些目标,ResourceManager的调度器Scheduler为应用程序的资源请求定义了一些灵活的协议,通过它就可以对运行在集群中的各个应用做更好的调度,因此,这就诞生了Resource Request和Container。
具体来讲,一个应用先向ApplicationMaster发送一个满足自己需求的资源请求,然后ApplicationMaster把这个资源请求以resource-request的形式发送给ResourceManager的Scheduler,Scheduler再在这个原始的resource-request中返回分配到的资源描述Container。每个ResourceRequest可看做一个可序列化Java对象,包含的字段信息如下:
<resource-name, priority, resource-requirement, number-of-containers>
- resource-name:资源名称,现阶段指的是资源所在的host和rack,后期可能还会支持虚拟机或者更复杂的网络结构
- priority:资源的优先级
- resource-requirement:资源的具体需求,现阶段指内存和cpu需求的数量
- number-of-containers:满足需求的Container的集合
number-of-containers中的Containers就是ResourceManager给ApplicationMaster分配资源的结果。Container就是授权给应用程序可以使用某个节点机器上CPU和内存的数量。
ApplicationMaster在得到这些Containers后,还需要与分配Container所在机器上的NodeManager交互来启动Container并运行相关任务。当然Container的分配是需要认证的,以防止ApplicationMaster自己去请求集群资源。

