
- 1基于Hadoop2.2.0版本分布式云盘的设计与实现_基于hadoop的web版云盘
- 2k8s1.18-kubeadm安装手册_s.82ydaxg.top
- 3技术人的成长路径_开发人员的成长路径
- 4Spark_Day01:Spark 框架概述和Spark 快速入门_图解spark第一季
- 5基于SSM+vue社区物业管理系统源码和论文_ssm物业管理系统论文
- 6使用Docker安装Drone和Gogs实现自动化部署_docker drone
- 7python之DDOS攻击_用python做ddos
- 8python入门14:os库,遍历文件夹下的所有文件,一些常用函数(获取文件目录、判断文件是否存在、合并路径、删除文件等),以及应用举例_os库遍历删除文件
- 9从零编写 vue 后台管理系统(01)_vue.js如何做后台管理系统
- 10【已解决】安装Issac gym卡在solving environment_isaac gym无响应
多模态CLIP和BLIP_clip blip
赞
踩
一、CLIP
全称为Contrastive Language-Image Pre-Training用于做图-文匹配,部署在预训练阶段,最终理解为图像分类器。
1.背景
以前进行分类模型时,存在类别固定和训练时要进行标注。因此面对这两个问题提出CLIP,通过这个预训练模型实现zero-shot,并且判断类别不是固定的,即增加类别也不用重新训练模型。CLIP在完全不使用ImageNet中的数据训练前提下,直接zero-shot得到的结果与resnet在Imagenet数据训练后效果一样,同时CLIP的数据是从网络上爬取的4亿文本对。
2.网络模型
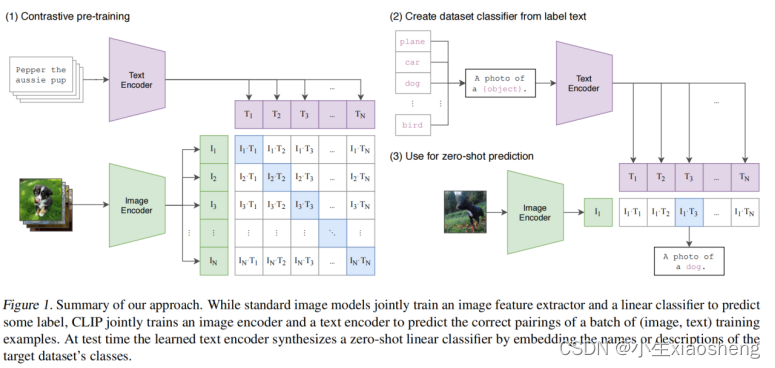
通过上图左边我们得知在预训练时有两个模型,一个是Bert模型做文字方面的Text Encoder,一个是ViT模型做图像方面Image Encoder。
本文对(图片信息和文字描述对应的)是从网络上爬取的有4亿对数据,但是因为都是从网络上爬取的,所以可能会有错(也就是说带有噪声,存在的问题)。从4亿对数据中,我们批次拿取batchsize为3万对的数据来进行encoder变成768维的向量。经过大量的正向传播和反向传播之后那么中间的值会越来越对齐。
过程==》假设有5张图片和5段文本,一张图片和一段文本是对应的。然后经过对应的Text Encoder和Image Encoder,分别生成五个图片编码和文字编码,然后图片编码和文字两两相互之间计算相似度,选相似度最高作为一对正样本,否则就是负样本,所以正样本个数为N,负样本为N(N-1)。这里是对比学习的思想,也就是Text Encoder和Image Encoder是在不断迭代的。
上图右边进行测试,给出图片然后给出类别种类,得出图片的编码,文字类别时加入提示词组成一个完整的话语然后再经过编码器得到文字编码,然后让图片编码和文字编码计算相似度,相似度最高的那么这个图片描述的信息就是文字信息,类别也就是文字类别。
CLIP的核心思想就是通过海量的弱监督文本对通过对比学习,将图片和文本通过各自的预训练模型获得的编码向量在向量空间上对齐。
3.结果
只能和resnet50网络进行比较,但是resnet50网络不是最强的,同时收集数据的时候很多文本对存在噪声。不过经过对比学习,Image Encoder模型和Text Encoder模型是越来越强,用于下游任务中,能帮助其他模型快速得到准确率高的结果
二、BLIP
BLIP能完成图-文匹配,同时也能完成生成任务,即文字生成图片和图片生成文字。
1.背景
视觉语言预训练旨在利用图像文本数据来教会模型共同理解视觉和文本信息的能力,但是大多数现有的预训练模型不够灵活,无法适应广泛的视觉语言任务;并且大多数模型都会对从网络自动收集的图像和替代文本对进行预训练,然而网络自动收集数据存在大量噪声。而BLIP模型与三个视觉语言目标联合预训练:图像文本对比学习、图像文本匹配和图像条件语言建模,且提出字幕和过滤,一种新的数据集增强方法,用于从噪声图像-文本对中学习。
2.网络模型
1)网络模型
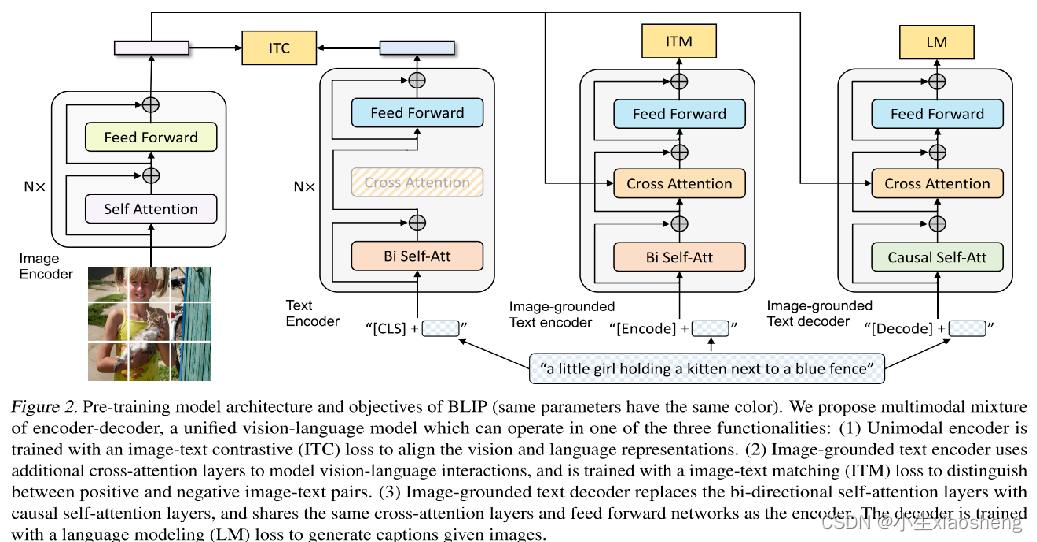
其中cross attention和causal self-att分别为
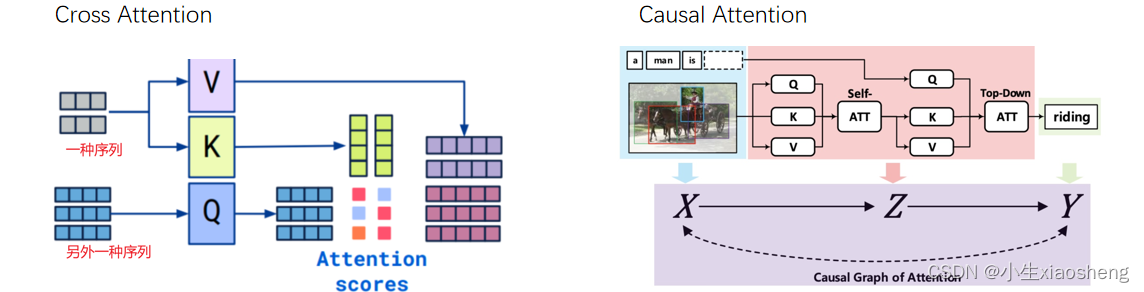
流程步骤:
①首先是对图片进行ViT分片的一样操作,然后传入给transformer的编码器,输出一个向量,这个向量代表了图片是所有特征(768维度)。右边的“三个模型”相同颜色的块共用同样的参数。
②第一个模型把文字做好向量化再加上cls(表示分类任务,特殊符号,ViT中的概念),然后进入双向自注意力(可以理解为和bert一样),然后进入Feed Forward(其实就是两个全连接层),最后得到一个文本向量(768维度),然后进行ITC(对比学习,是不是一对,一对概率高不是一对概率低,两个向量尽量对齐)。
③中间的模型是把从图片得到的向量和文本向量进行交叉注意力,然后再FFN,最后就是ITM(二分类任务)
④最后一个模型,对于文本是一个一个的输入,然后让其推理预测下一个字,Causal self-att(表示单项注意力机制),LM就是重新把文本预测出来。
2)噪声模型
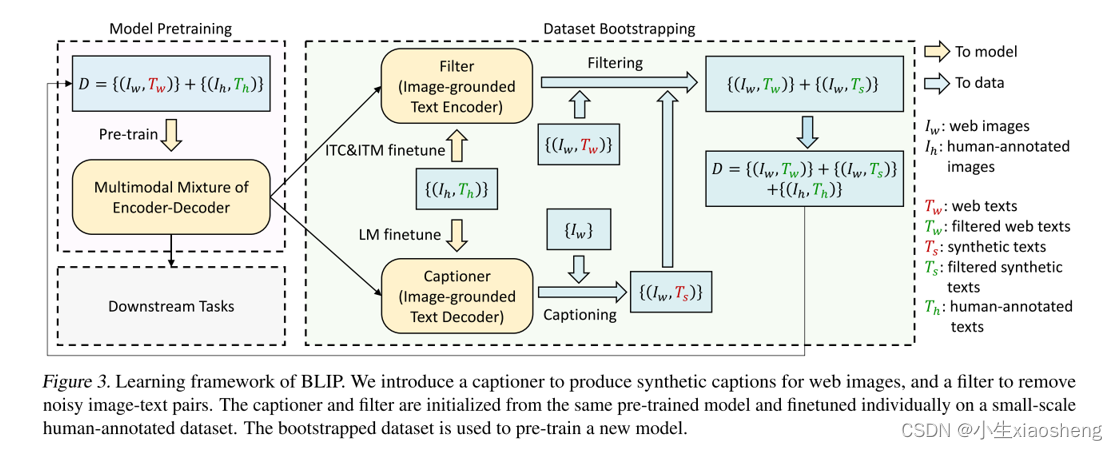
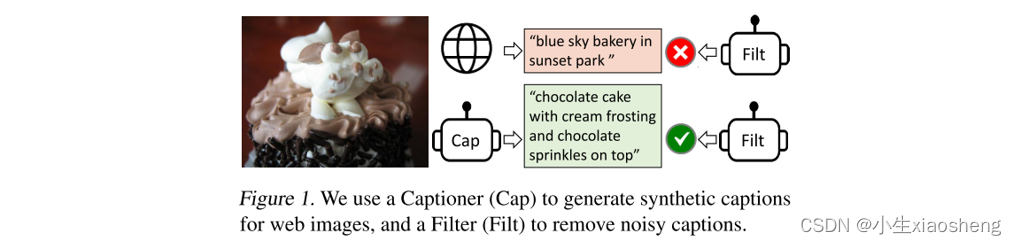
为了解决网络收集到的大规模数据中存在图像文本不配对的这个问题,BLIP通过引入两个模块来引导字幕:字幕生成器Captioner和过滤器Filter。字幕生成器是一个基于图像的文本解码器,给定网络图像,我们使用字幕生成器合成字幕作为额外的训练样本。过滤器是一个基于图像的文本编码器,它会删除与相应图像不匹配的嘈杂文本。
步骤流程:
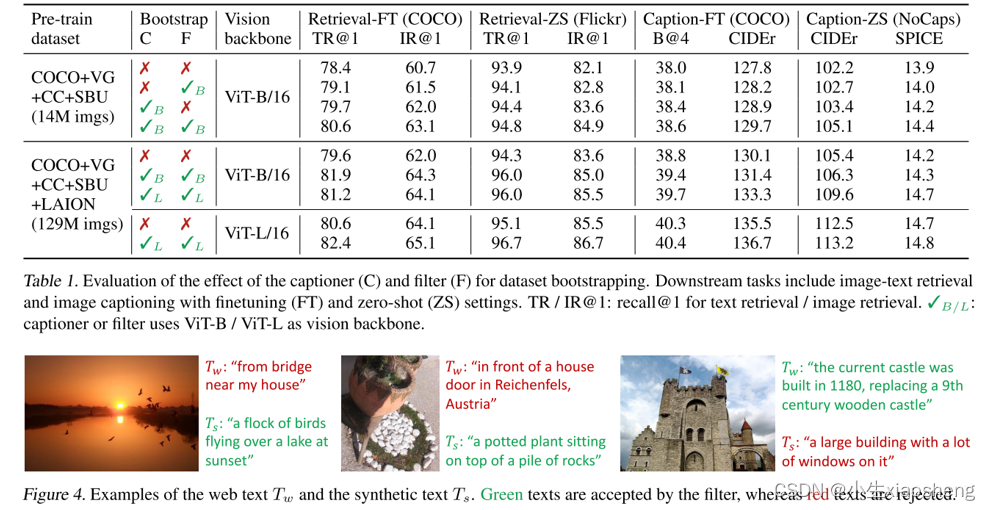
①上图的左边D中的Iw和Tw分别表示图像和文本,红色的表示从网络爬取下来,可能会出现不匹配,Ih和Th绿色的表示人为进行处理的数据对它们匹配的。
②然后我们把这些数据放到刚才的模型中进行训练,我们就能得到几个训练完之后的模型(ITC、ITM和LM)。对于得到的模型我们大概能分为两种类型,其中ITC(图文匹配,对齐)和ITM(图文匹配,二分类)为一类,而LM(看图生成文字)为一类。
③训练好的模型再把人为处理匹配对的图文分别送到(ITC ITM)图文匹配和LM看图生成文字的模型中进行训练。
④对于(ITC ITM)图文匹配的模型我们把从网络上找的图文匹配对进行训练,如果该文本对是匹配的就往后传,如果不匹配就把这个文本对丢弃。
⑤对于LM看图生文字模型,我们把从网络爬取的图片进行训练(只要图片),训练之后得到文字,再把生成的文字再放到前面的(ITC ITM)图文匹配模型上进行训练,如果匹配成功就留下(也就是说模型生成的文字和图片是匹配的),不成功就丢弃。
经过以上的步骤就能找到干净的数据,得到的干净数据再重新送到预训练模型中作为数据再得到ITC、ITM和LM。
3.结果
这个网络框架得到的模型和数据能用于下游任务中,帮助其他模型快速得到准确率高的结果。

