
- 1【学习笔记】无人机系统(UAS)的连接、识别和跟踪(三)-架构模型和概念
- 2docker-compose部署kafka_docker bitnami kafka配置文件docker-compose-cluster
- 3Excel 神器 —— OpenPyXl_excel神器
- 4chatgpt赋能python:Python波动方程介绍:掌握物理模型与实际应用_python在建立物理模型中的应用
- 5Flutter学习路线总结_flutter前端开发学习路径
- 6SpringBoot整合Kafka(自动配置分析、同步异步producer、comsumer、自定义KafkaAdmin和KafkaTemplate)_kafka集成spring boot
- 7matlab结构力学仿真,MATLAB在结构力学分析中应用.doc
- 8微软语音合成助手 TTS-VUE 文字转语音工具_tts云野配音
- 9SHENLAN_Chapter6_基于安全走廊和Bezier曲线的硬约束轨迹生成方法_安全走廊约束
- 10Springboot 开发 -- 集成 JWT 构建安全的API接口服务_jwt api
SD3发布,送你3个ComfyUI工作流_sd3 webui
赞
踩
大家好,我是每天分享AI应用的萤火君!
这几天AI绘画界最轰动的消息莫过于Stable Diffusion 3(简称SD3)的发布。SD3是一个多模态的 Diffusion Transformer 模型,其在图像质量、排版、复杂提示理解和资源效率方面具有显著提升。
废话不多说,先给大家看看我使用SD3生成的几张图片:

SD3介绍
SD3是一个多模态的 Diffusion Transformer 模型,这个模型有什么特点呢?这里给大家简单拆解下:
多模态:这个词大家可能比较陌生,不过也很简单,就是一个模型中有多个子模型,它们分别处理不同方面的任务,让模型的整体能力更强。在SD3内部,模型先将文本和图像分为两个子模型,然后在后续的处理中又把它们连接起来。通过这种方法,允许图像和文本令牌之间的信息流动,以改善生成输出的整体理解和排版。
Diffusion:这个大家可能都很熟悉了,SD这个名字中就包含它。扩散模型的训练过程是先向图片中增加噪音,噪音可以看作图片中的小雪花,一张完全噪音图可以看作为没有信号时的电视画面,然后扩散模型再学习根据文本提示词逐步去除噪音、还原图片。添加噪音的过程就是扩散(Diffusion,逐步将图片转换为完全噪音图),根据提示词将噪音图还原为图片的过程称为反向扩散(从完全噪音图生成出目标图像)。我们生成图片的过程是其中的反向扩散。
Transformer:自从OpenAI给大家展示了Sora的惊艳效果后,各种AI模型都开始向 Transformer 这一架构靠近。Transformer 这一架构最初用在自然语言翻译上,后来在大语言模型(GPT、LLama等)上取得了巨大的成功,通过它进行的机器学习效果都不错。所以SD也从之前使用的UNet架构迁移到了Transformer架构。
这几个名词有一些简称,为了方便大家识别,这里也简单说明下:
- Diffusion Transformer 简称为 DiT。
- Multimodal Diffusion Transformer 简称为 MMDiT,其中 Multimodal 是多模态的意思。
使用SD3 Medium
本次发布,Stability AI只公开了SD3的一个中等版本(sd3_medium),参数量是2B,也就是20亿参数,所谓中等就是模型的参数量不上不下,Stability AI 还有个更大的8B模型没有公开发布。
目前(2024年6月20日)开源的UI工具中只有ComfyUI正式支持了SD3,Stable Diffusion WebUI还没有正式放出(有一个开发版本,建议再等等)。所以我这里将以ComfyUI为例,讲解SD3的使用方法。
安装 ComfyUI
之前我专门写过一篇文章介绍ComfyUI的安装方法,不过自己安装 ComfyUI 有几个拦路虎:
- 特殊网络设置,很多AI程序和模型都在外网,访问不便。
- 12G显存以上的Nvidia显卡,N卡轻者数千,重者数万。
- 一定的电脑动手能力,需要执行命令,解决一些程序冲突。
使用云环境镜像
通过云环境,我们可以先低成本的试用测试,然后再做决定。
这里给大家推荐两个我经常使用的云平台:
- AutoDL:AutoDL有丰富的GPU显卡类型,出道的比较早,价格也很公道,相比阿里云、腾讯云,简直实惠的不得了,更有大量的社区镜像可以使用。
- 京东云:目前京东云的GPU服务器全网价格最低(东哥豪气),更有免费代金券可以领取,机不可失。领取代金券,请发消息 “京东云” 到公众号 “萤火遛AI”。
我在这两个云平台都发布了ComfyUI的镜像,内置了常用的工作流,大家可以一键启动,直接使用,不用费劲吧啦的各种安装调测。最新版本的镜像已经内置SD3工作流,平台正在审核中,大家可以及时关注。
两个云服务器的使用方法请看这里的介绍:
使用中如果遇到问题,可以直接向我反馈!
下载 SD3 Medium模型
目前SD3的模型发布在Huggingface网站:
https://huggingface.co/stabilityai/stable-diffusion-3-medium
访问不了外网的同学可以发消息“SD3”到公/众\号“萤火遛AI”,即可获取。
这里简单介绍下其中的几个模型文件:

- sd3_medium.safetensors 包括 MMDiT 和 VAE 模型,但不包括任何文本编码器。
- sd3_medium_incl_clips_t5xxlfp16.safetensors 包含所有必要的权重,包括 T5XXL 文本编码器的 fp16 版本,文件在15G左右,性能表现最佳,一般使用这个就好了。
- sd3_medium_incl_clips_t5xxlfp8.safetensors 包含所有必要的权重,包括 T5XXL 文本编码器的 fp8 版本,在质量和资源要求之间提供平衡,文件大概10G左右,电脑跑不起来fp16版本,可以用这个。
- sd3_medium_incl_clips.safetensors 包括除 T5XXL 文本编码器之外的所有必要权重。它需要的资源很少,但因为没有 T5XXL 文本编码器,模型的性能会有所降低。
- text_encoders 文件夹包含三个文本编码器,以方便用户单独使用。
这里有几个名词,我再解释一下:
VAE:因为扩散模型内部使用了一个压缩空间进行图片的生成,这样使用计算资源会少很多很多,但是生成出来的图片数据不是我们可见的图片数据格式,需要进行解码,VAE就是用来干这件事的。
文本编码器:首先计算机内部都是各种数字,AI模型内部也是各种数字参数。我们使用文本生成图片时,首先要把文本进行编码,转换为AI模型内部可以识别的信息,文本编码器就是来干这个事的。不同的模型可能搭配不同的文本编码器。
fp16、fp8:参数的数值精度,AI模型内部大部分都是数字参数,为了节省空间,在计算机内部这些数字通常使用浮点数来表示。精度越高,表示越精确,但是占用的空间也越大。一般采用fp16,但是如果文件体积过大,对空间使用比较敏感,fp8也可以接受。
在ComfyUI中使用SD3
SD3的使用很简单,我这里给大家贴出来一个最简单的SD3工作流:
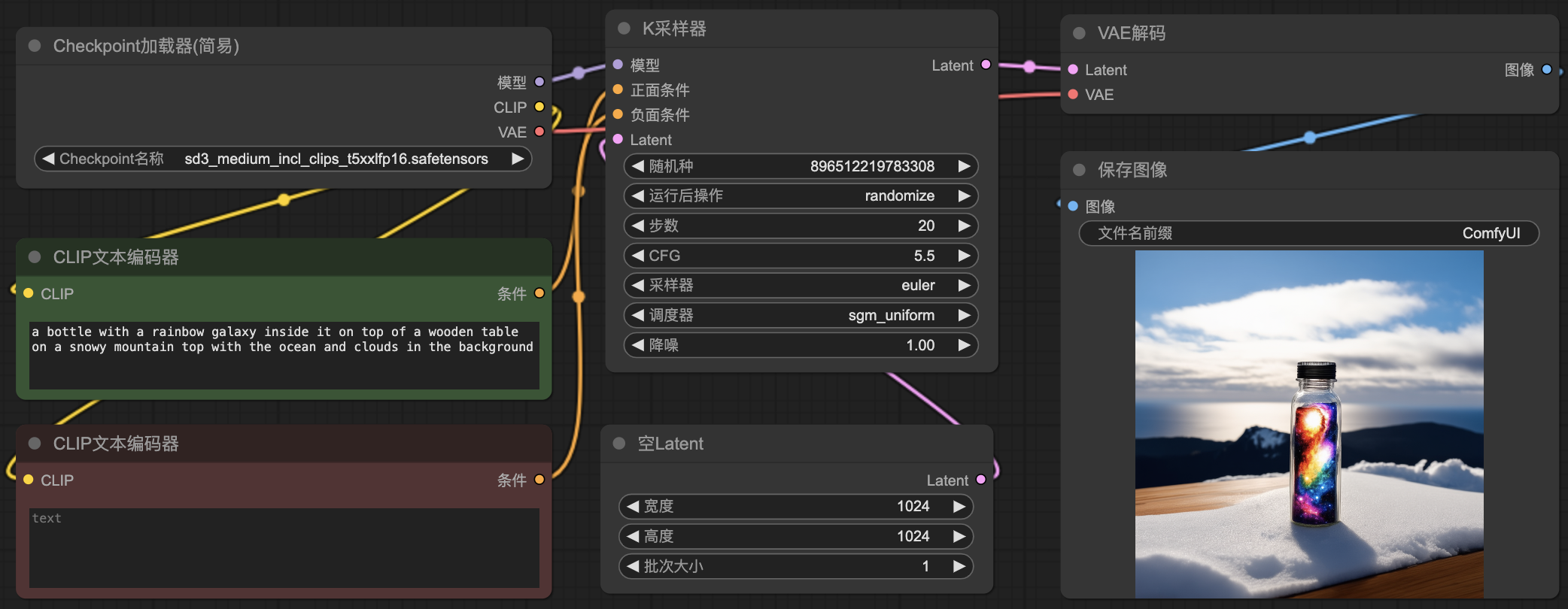
除了选择的模型是 sd3 medium 之外,这个工作流和我们之前使用的SDXL、SD1.5的工作流并没有什么差别。
可能有些同学刚开始接触ComfyUI,我这里对其中的节点做一个简单的介绍。
Checkpoint加载器:加载SD基础模型,SD基础模型中一般会包含三个部分:扩散模型、文本编码器、潜空间数据解码器,对应到这个节点的三个输出:模型、CLIP和VAE。
CLIP文本编码器:这里有两个文本编码器,分别用来编码正向提示词和反向提示词,也就是画面中希望出现的内容和不希望出现的内容。他们都连接到“Checkpoint加载器”的CLIP输出点,因为我现在使用的这个SD3基础模型包含了一个文本编码器。有些SD3的基础模型可能不包含文本编码器,我们就需要使用单独的文本编码器加载节点。
K采样器:扩散模型生成图片的过程就是不断的去噪音采样,在采样的过程中,它需要依赖一个模型、采样条件(也就是要生成什么,来自提示词编码结果)、一个潜空间,然后这里边还有一些采样的参数,比如采样步数、采样器、噪音调度器、降噪幅度、CFG(提示词引导系数)等。关于这些参数的详细说明、Stable Diffusion的各种基础知识,以及SD实战技法可以看我的SD全面实战教程:小报童
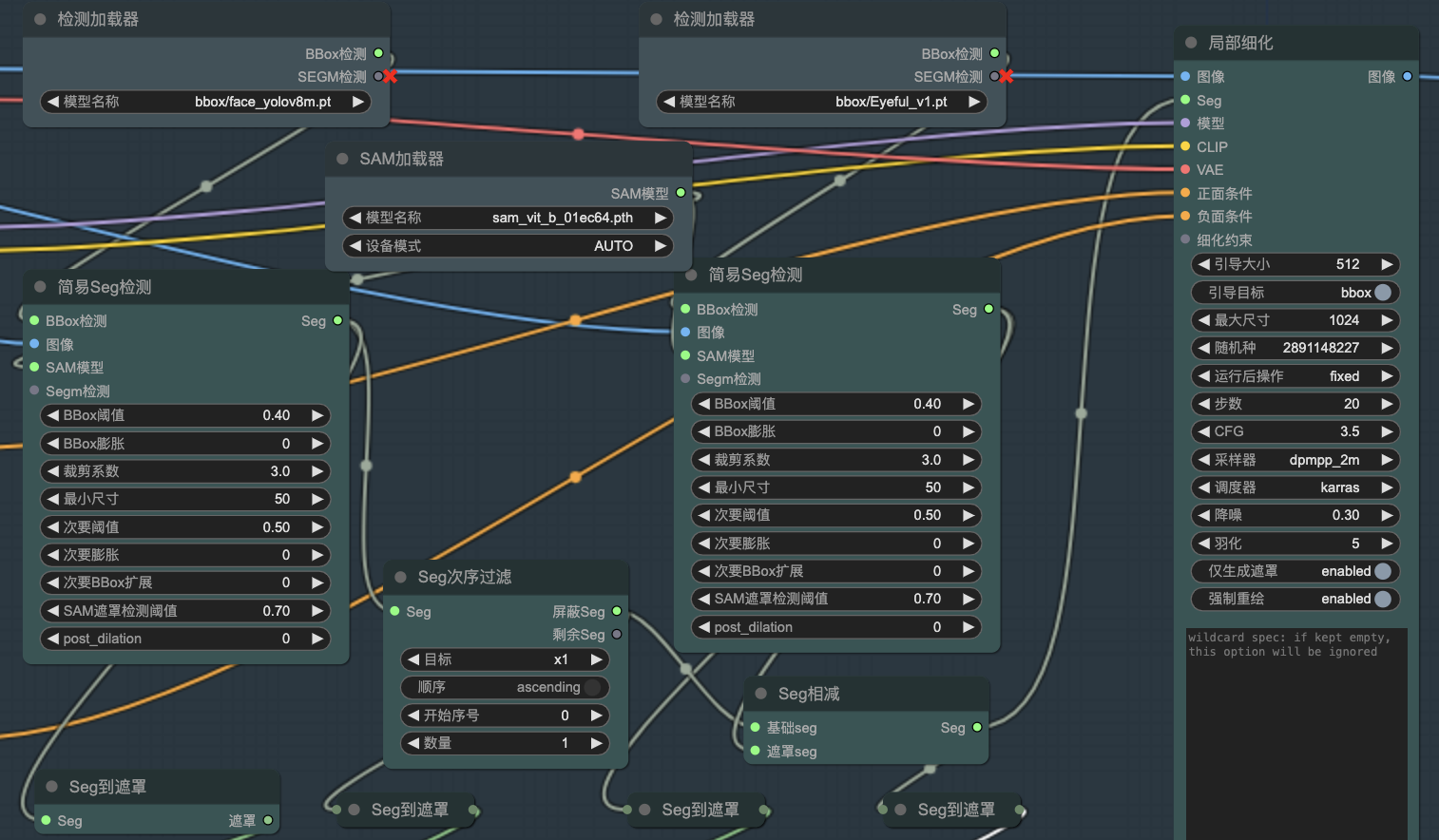
另外我还测试了SD3的其它两个工作流(下载方式见文末):
一是放大图片(不是单纯的放大,让细节更为完美):

二是优化面部皮肤(SD3生成人物的面部过于光滑,不够真实):
资源下载
为了方便大家入门,我整理了一批ComfyUI工作流,包括基本的文生图、图生图、ControlNet的使用、图像的处理、视频的处理等等,当然还有最近发布的SD3,发消息“工作流”到公众号“萤火遛AI”,即可领取。
另外,我创建了一个AI绘画专栏,加入专栏,可以零门槛,全面系统的学习 Stable Diffusion 创作,让灵感轻松落地!如有需要请点击链接或下方扫码进入:SD全面实战![]() https://xiaobot.net/post/03340243-9df6-4ea0-bad6-9911a5034bd6
https://xiaobot.net/post/03340243-9df6-4ea0-bad6-9911a5034bd6
以上就是本文的主要内容。
用好 ComfyUI:
- 首先需要对 Stable Diffusion 的基本概念有清晰的理解,熟悉 ComfyUI 的基本使用方式;
- 然后需要在实践过程中不断尝试、不断加深理解,逐步掌握各类节点的能力和使用方法,提升综合运用各类节点进行创作的能力。
我将在后续文章中持续输出 ComfyUI 的相关知识和热门作品的工作流,帮助大家更快的掌握 ComfyUI,创作出满足自己需求的高质量作品。
请及时关注,以免错过重要信息。

