
- 1k8s 攻击面
- 2【Linux】在Ubuntu下安装Zotero_ubuntu安装zotero
- 3开源驰骋BPM低代码-积极拥抱AI时代
- 4【数学建模】【优化算法】:【MATLAB】从【一维搜索】到】非线性方程】求解的综合解析_非线性方程的一维搜索
- 5Flink - Java篇_java flink
- 6Leecode刷题笔记——378. 有序矩阵中第K小的元素_leeetcode378 python
- 7SQL:DATE_FORMAT()函数_dateformat sql函数
- 8FastDFS配置之常见错误_fastdfs部署,配置能用127.0.0.1么
- 9Mac环境安装jmeter - 终端启动(输入jmeter即可启动)_jmeter怎么显示终端
- 10解决RequestContextHolder获取请求的javax与Jakarta不匹配的问题_jakarta 获取request
神经网络算法 - 一文搞懂Tokenization(分词)_tokennizer
赞
踩
前言
本文将从分词的本质、中英文分词、分词的方法三个方面,带您一文搞懂Tokenization(分词)。

一、分词的本质
核心逻辑:将句子、段落、文章这种长文本,分解为以字词为单位的数据结构。
-
文本切分:分词是将连续的文本切分为独立的、有意义的词汇单元的过程。这些词汇单元可以是单词、词组或特定的符号,切分的目的是使文本更易于处理和解析。
-
语义理解的基础:分词是语义理解的基础步骤。计算机通过分词能够识别出文本中的基本语义单元,进而进行词性标注、句法分析、语义推理等更高级的处理。
-
数据结构化:分词将非结构化的文本数据转化为结构化的词汇序列,使得文本数据能够被计算机程序有效地处理和分析。
为什么要分词:分词是将自然语言简化为数学问题,提供合适语义粒度的关键步骤。
- 问题转化:分词可以将非结构化的文本数据转化为结构化数据,这样复杂的自然语言处理就被转化为了更易于处理的数学问题。

- 合适的语义粒度:词是语言中表达完整含义的基本单位。与字相比,词能够提供更丰富的语义信息。单个字往往无法独立表达完整的意义,而词则可以。同时,与句子相比,词的粒度更小,更易于处理和复用。
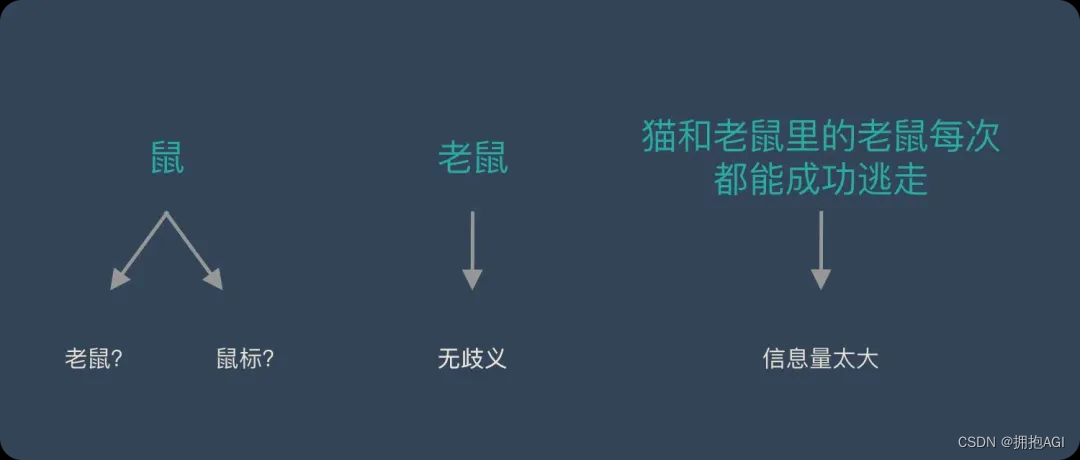
二、中英文分词
中英文分词对比:

-
分词方式:英文文本天然地通过空格分隔单词,为自动分词提供了便利。中文则缺乏明确的分隔符,分词需要依据语义和上下文进行,更加复杂且容易产生歧义。
-
词形变化:英文单词具有丰富的词形变化,如时态、语态、单复数等,需要进行词形还原(Lemmatization)和词干提取(Stemming)以统一处理。词性还原:does,done,doing,did 需要通过词性还原恢复成 do。词干提取:cities,children,teeth 这些词,需要转换为 city,child,tooth”这些基本形态。中文则不需要。
-
粒度问题:中文分词时需要考虑粒度大小,即词汇的划分粗细。不同粒度可能对应不同的语义,需要根据具体场景选择。英文中由于单词本身即为基础单位,不存在这一问题。
中文分词难点:
-
缺乏统一标准
问题描述:中文分词没有公认、统一的标准或规范。
挑战:导致不同机构、公司或组织采用各异的分词方法和规则,增加了中文分词研究和应用的复杂性。
-
歧义词汇切分
问题描述:中文中存在大量歧义词汇,其分词方式随上下文变化。
挑战:要求分词系统能够准确根据上下文判断词汇边界和具体含义,增加了分词的难度和复杂性。
-
新词快速识别
问题描述:信息爆炸时代,新词和流行语不断涌现。
挑战:要求中文分词系统具备灵活性和自适应性,能够快速、准确地识别和处理这些新词,如“多巴胺穿搭、显眼包”等网络流行语。
三、分词的方法
基于统计:
-
特点:对新词和未登录词识别良好。
-
基本思路:通过统计学习建立模型,利用上下文信息进行分词。
-
常用算法:隐马尔可夫模型(HMM)、支持向量机(SVM)等。
基于深度学习:
-
特点:能自动学习文本中的复杂特征。
-
基本思路:使用深度学习模型进行序列标注实现分词。
-
常用模型:双向长短期记忆网络(BiLSTM)、条件随机场(CRF)等。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

