
- 1C# JSON之序列化与反序列化_json序列化对象 c#
- 212.Java String 类教程(一看就会)
- 3SpringCache集成Redis
- 4Proximal Policy Optimization (PPO): A Robust and Efficient RL Algorith
- 5面试程序员时HR都在想些什么?
- 6【学习笔记】Day 2
- 7git add使用大全_git add --force
- 8合泰单片机市场占有率_holtek单片机图文全面详解
- 9flink数据实时传入mysql_flink mysql同步到mysql
- 10最终还是放弃了拼多多 NLP 算法岗(大模型方向)Offer。。。_拼多多nlp
YOLOv10(6):YOLOv10基于TensorRT的部署(基于INetworkDefinition)_yolov10 tensor 版本
赞
踩
1. 写在前面
我们在前面已经讲过很多关于YOLOv10的一些知识点,也简单理了一下如何训练自己的数据。
现在本篇文章主要是讲解一下如何在TensorRT中部署YOLOv10,相信经过这一步,各位小伙伴已经能够无限的接近于将YOLOv10产品化了。
另一个需要说明的是,本文中所述的TensorRT部署并不是基于ONNX中转方法的部署,而是通过基于INetworkDefinition的手动构建网络进行部署,这种方式能过使得我们对网络有一个较为清晰的了解和认识。
登录https://github.com/tecsai/YOLOv10_TensorRT获取网络构建代码。
话不多数,开始吧。
2. YOLOv10的网络组成
本次以YOLOv10m为例,通过阅读“yolov10m.yaml”文件可以看到,整个网络的组成和YOLOv8极为相似,仅在一些局部位置有改动。
从网络结构配置文件yolov10m.yaml可以看出,YOLOv10有一些基本的模块组成,包括Conv、C2f、SCDown、C2fCIB、PSA、Upsample以及v10Detection组成。
其中,
Conv就是基本的卷积模块;
C2f照搬了YOLOv8中的C2f;
SCDown由两个基本的Conv模块组成,通过控制Kernel和Stride,实现特征图的两倍下采样;
C2fCIB就是特殊形式的C2f,其将C2f中的Bottleneck模块换成了CIB模块。
Upsample就是特征图上采样;
PSA是MHSA与FFN配合实现的Transformer结构(QKV自注意力);
3. 基本的Conv模块
Conv模块就是普通的卷积模块,如下所示为训练工程中的PyTorch版本的卷积。
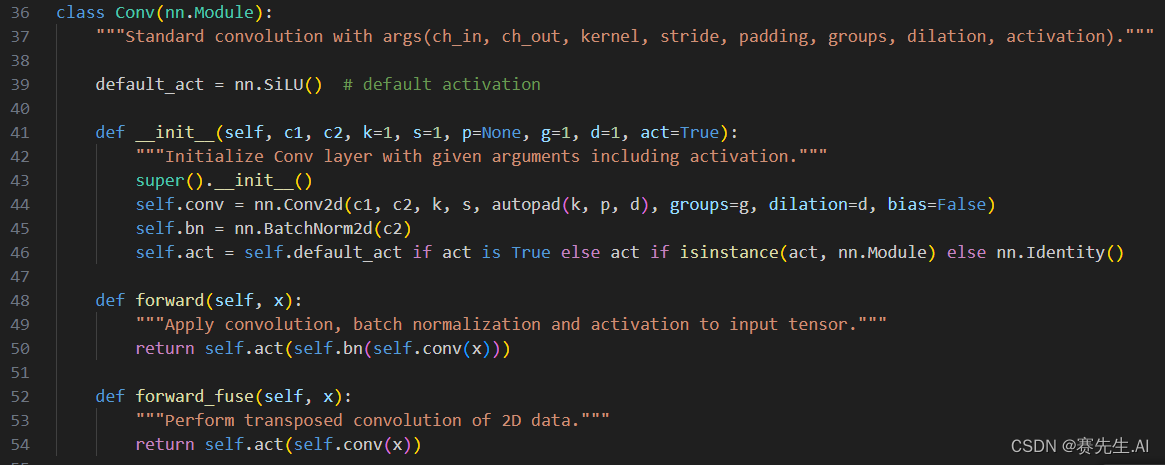
可以看到,参数已经设置的非常全面了,包括输入输出通道(c1, c2),卷积核尺寸(k),stride(s),padding(p),group(g),dilation(d)以及是否使用激活函数(act)。
对应,我们在基于TensorRT的版本中依葫芦画瓢就可以了,参考如下。
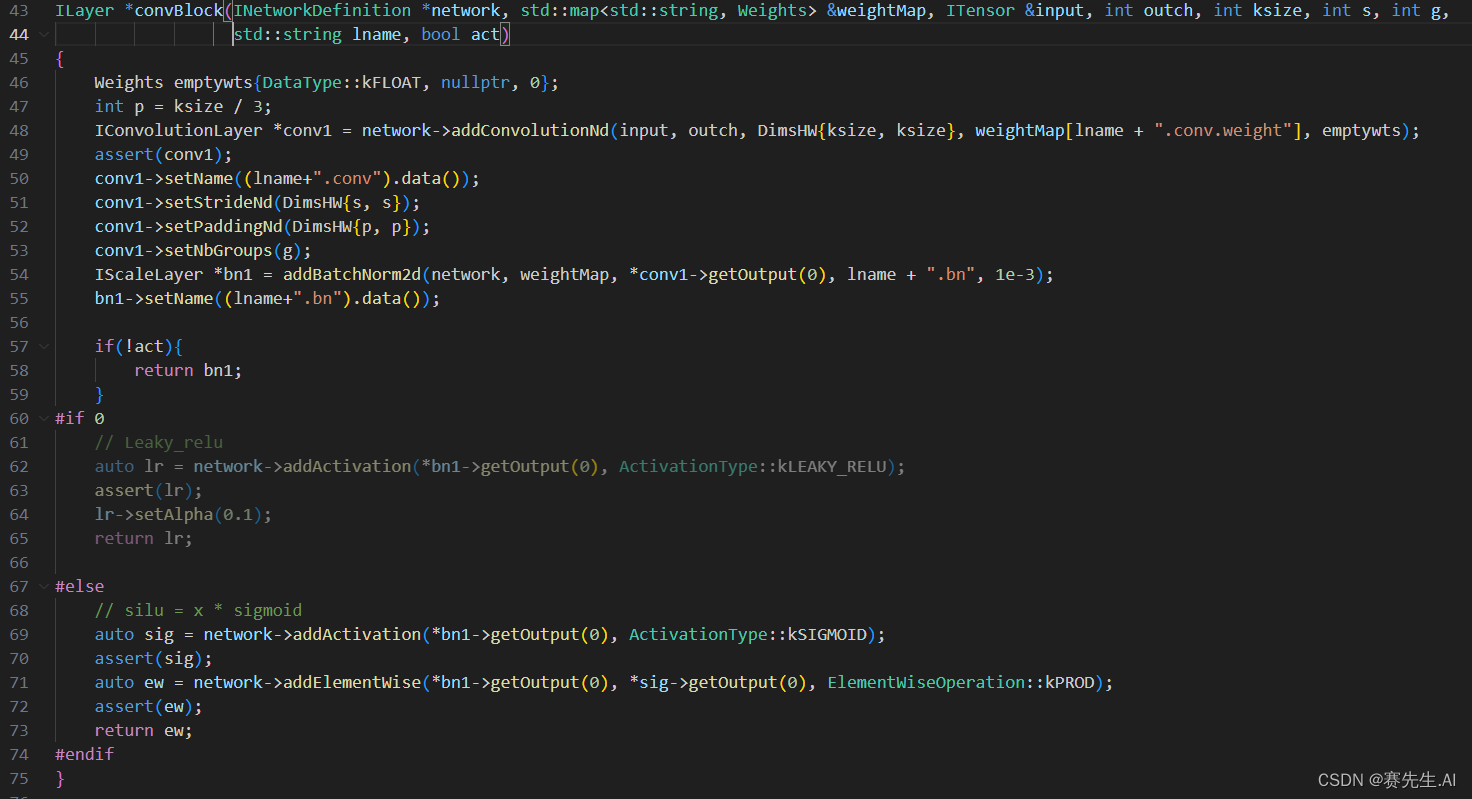
这里有一个建议,后期大家可以将激活函数SILU换成LeakyReLU,这也算是在边缘端提速的一个技巧了。
4. C2f与C2fCIB
C2f可以看做是C3的优化,与C3单元相比,每一个Bottleneck的输入Tensor的Channel都只有上一级的0.5倍,因此计算量明显降低。从另一方面讲,梯度流的增加,也能够明显提升收敛速度和收敛效果。如下分别是C3和C2f的网络结构。
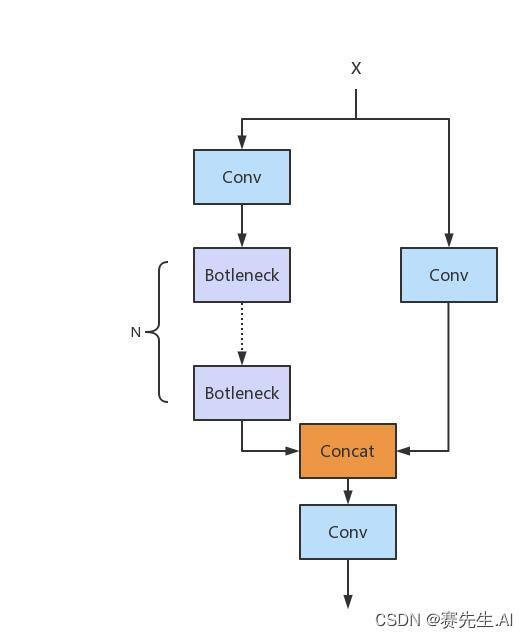
(C3)
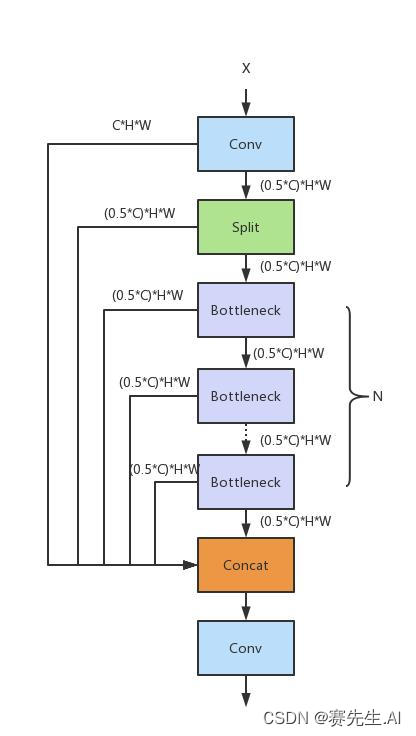
(C2f)
基于上述图,我们构建的基于INetworkDefinition的C2f的代码如下。
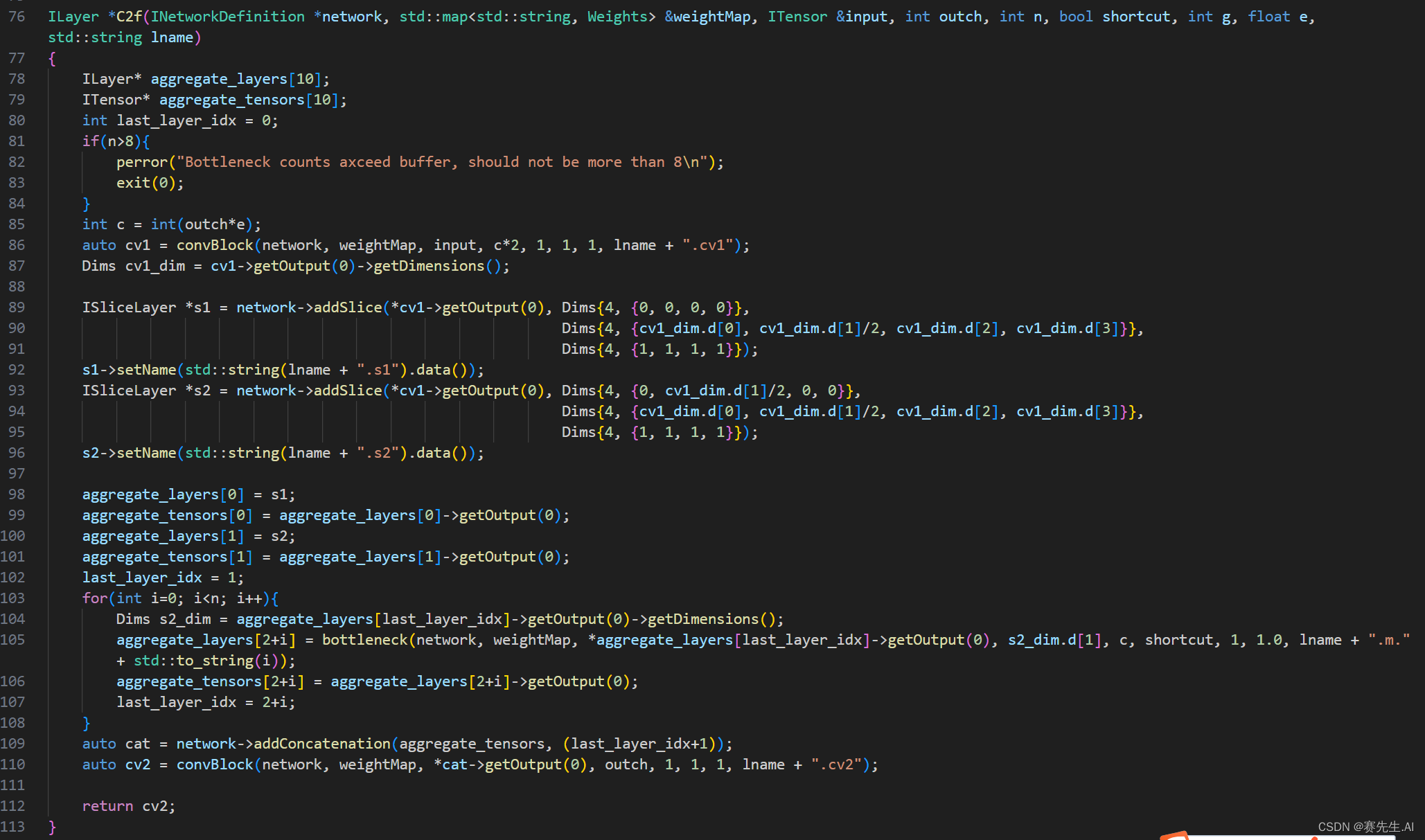
其中,第89行和93行即是对Tensor进行了拆分操作,依次来完成一种类“CSP”的结构。
之后在103行和108行进行一个类“ELAN”的操作,减少计算量,但丰富了梯度流。
在前面我们说过,C2f和C2fCIB实际上是一样的,仅将Bottleneck结构换成了CIB结构,CIB又是Bottleneck的一种演化版本。
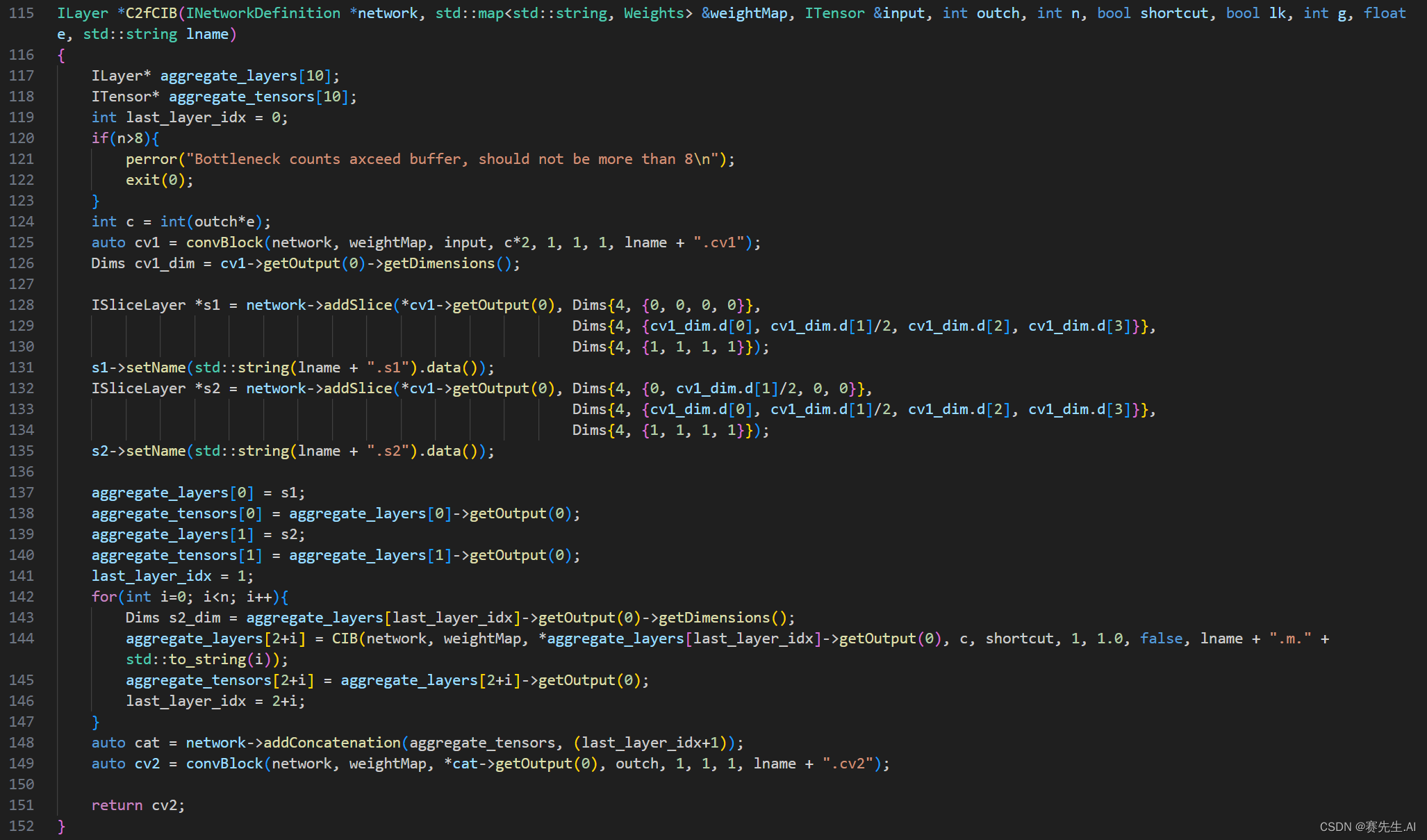
5. PSA
PSA模块本质上是引入了QKV机制的自注意力模块,实现了CNN与Transformer的结合。
PSA全称Partial Self-Attention,即将特征图Tensor的部分进行MHSA+FFN,另一部分则执行了Cross Stage,并与MHSA+FFN的输出进行了融合(Concatenate)。
如下是Attention模块和PSA模块。
Attention
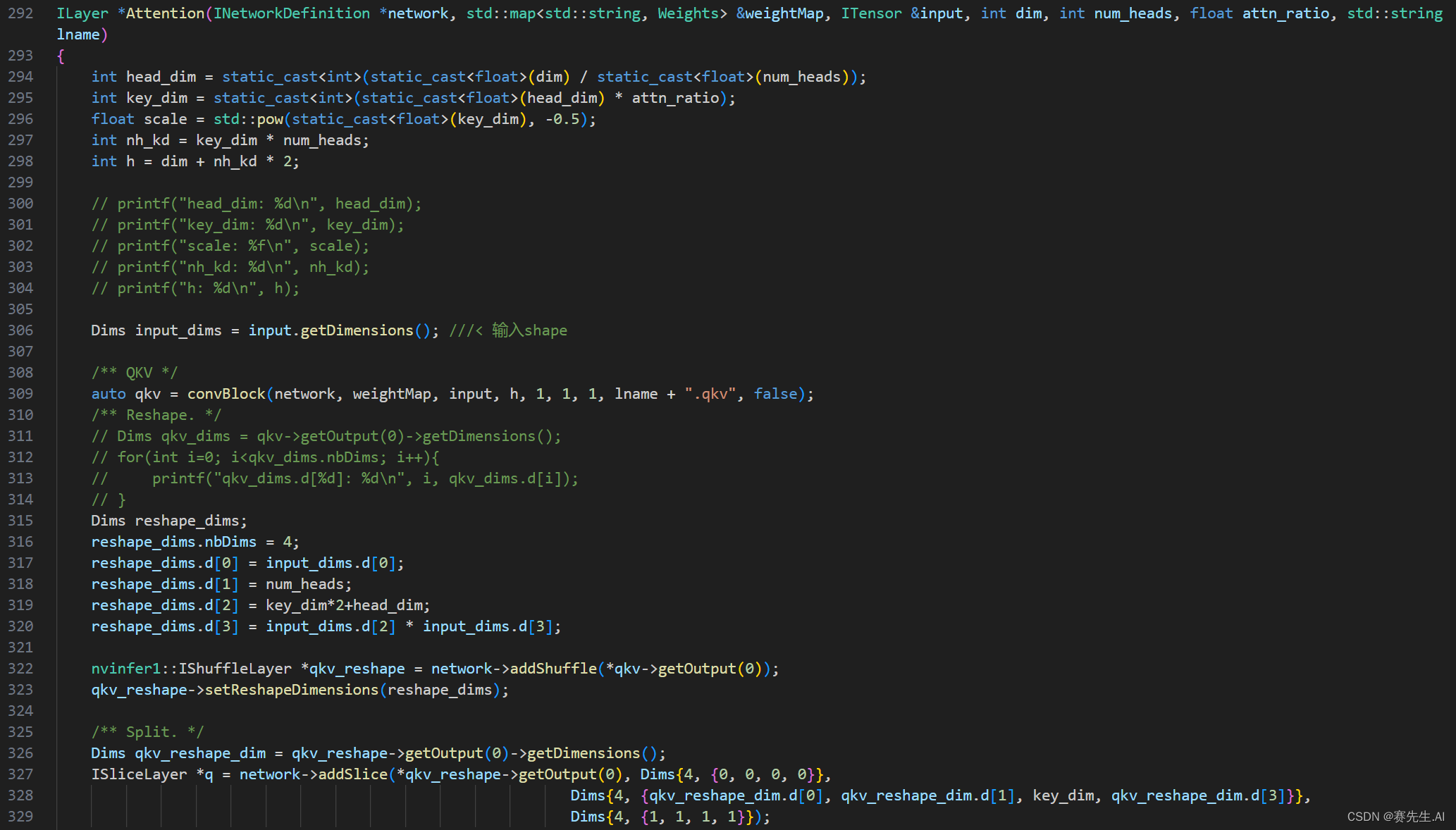
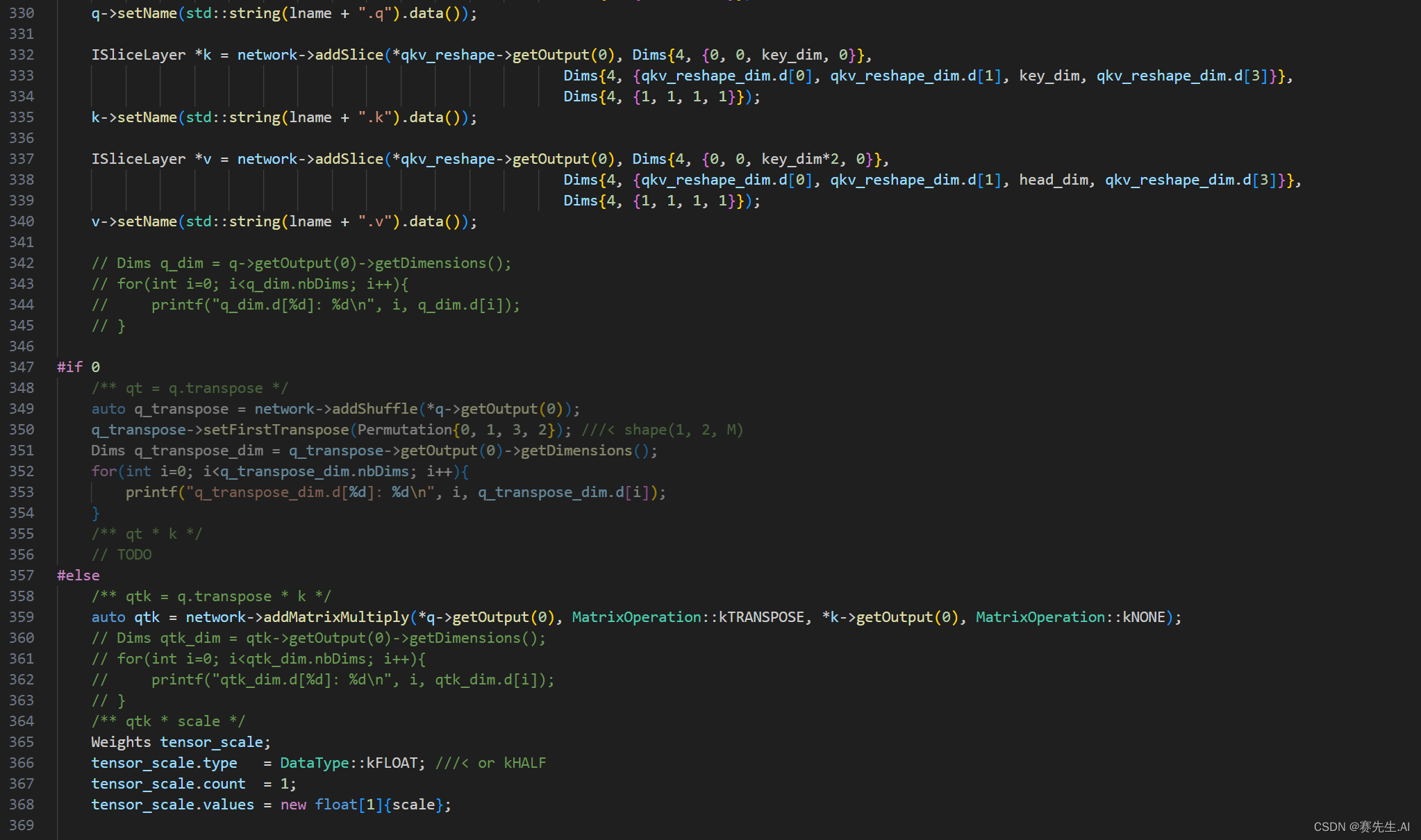

PSA

6. 代码参考
完整的代码可登录https://github.com/tecsai/YOLOv10_TensorRT 获取。

