
热门标签
热门文章
- 1VNC Viewer远程Mac共享桌面_vnc viewer链接mac会显示两个桌面
- 2深度学习、机器学习毕业设计 - 选题建议_机器学习毕设
- 3同城上门按摩服务平台,同城上门小程序搭建有具备哪些功能?
- 4Graphpad Prism10.2.1(395) 安装教程 (含Win/Mac版)_graphpad prism 10 for mac v10.2.1 直装版
- 5Mysql -- zerofill自动填充_zerofill在数据库中的用法
- 6移动云荣获OpenInfra社区“算力基础设施技术突破奖”_天元操作系统(bc-linux)
- 7一站式在线协作开源办公软件ONLYOFFICE,协作更安全更便捷_结构化文档 在线编辑 开源
- 8jmeter使用非GUI,命令行模式进行压力测试_don't use gui mode for load testing !, only for te
- 9C++:统计素数_输入一个正整数n。判断2到n中有那些素数。输出的每一个素数占一行。 注意:请严格
- 10什么是内网穿透?内网穿透有什么用?内网穿透如何实现_内网穿透服务
当前位置: article > 正文
总结:知识图谱KG+大模型LLM_知识图谱 大模型
作者:IT小白 | 2024-04-01 11:35:51
赞
踩
知识图谱 大模型
- LLM-based KG
- KnowLM
- OpenSPG
- KG-based RAG
- 基本原理
- 从query出发的语义解析
- pre-LLM方法
- 思想:直接将问题解析为对应的逻辑表达式,然后到知识图谱中查询。
- 方法:通常包含逻辑表达式、语义解析算法、语义解析模型训练三部分。一般步骤是将问句解析成中间表示,再将中间表示向知识库映射,获得最终的逻辑表示。
- 逻辑表达式:lambda-calculus(支持实体,数词,函数等常量,支持多种逻辑连接词,支持\exists,\forall等存在量词,argmax,argmin等额外量词),lambda-DCS(组合语法更简单,支持最基本的实体、关系、Join/intersection操作,支持Bridging操作,可以把两个独立的语义片段组合起来,将离散语义组合为更完整的语义), 组合范畴语法CCG(由解析规则、解析算法、解析模型训练组成,解析规则由词汇、句法类型、语义类型构成,CCG支持应用、组合、类型转化、并列等操作)。
- 语义解析的基本步骤:短语检测(识别短语的实体和关系,包括分词、词性标注POS、命名实体识别NER,依赖关系分析构造短语依存图等步骤),资源映射(grouding,包括实体链接、概念匹配、关系分类/关系抽取,目标是将问句与知识图谱上的本体匹配,可以从短语依存图出发实现),语义组合(包括句法分析,组合模型训练,语义组合等步骤),逻辑表达生成。
- 语义解析器的训练:目标是通过大规模知识库上的问题/答案对集合训练Parser,用在语义组合阶段。以词法、语法、对齐、桥接、实体链接、关系识别为特征,以候选逻辑表达式为目标

- 难点:1. 语义解析的Bridging操作,通常谓词不是明确表示的,导致问句中的谓词无法与知识图谱中的关系直接映射,将实体周边的谓词与问句中真正的谓词对应,即Bridging。2. 知识图谱是高度不完备的,因此需要进行问句的短语重写来匹配知识(Prapharasing),因此需要搜集高质量的语料来训练短语重写模型。
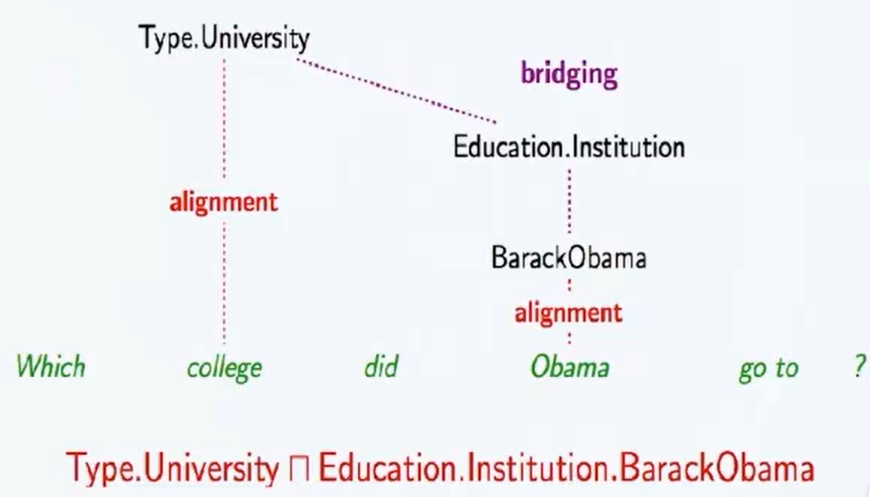
- 缺点:最大缺点是对知识图谱中资源的利用程度不够,知识图谱中的海量知识是可以极大的增强问句的理解过程的,更好的方法应该充分深挖问句和知识图谱两方面资源所包含的信息。
- LLM-based方法
- 增加一路与向量库平行的KG上下文增强策略,基于模型的NL2X能力或单独的NL2X模块,将query解析为图查询语言,直接执行图查询,然后后查询的结果转换为文本片段。
- pre-LLM方法
- 从图谱出发的检索排序
- pre-LLM方法
- 主要思路:根据query抽取实体,然后把实体作为种子节点对图进行采样(必要时,可把KG中节点和query中实体先向量化,通过向量相似度设置种子节点),然后把获取的子图转换成文本片段,针对query进行排序。
- 关键模块:排序模型
- 基于特征的检索排序模型:针对每个答案构造特征,常用的问题特征包括:疑问词特征、问题实体特征、问题类型特征、问题动词特征、问题上下文特征。常用的答案特征包括:谓词特征、类型特征、上下文特征。
- 基于子图匹配的检索排序模型:从输入问题中定位问题实体,随后答案候选检索模块以该问题实体为起点按照特定规则从知识图谱中选择答案候选,接下来,答案子图生成模块为每个答案候选实体从知识图谱中抽取出一个子图,作为该答案实体的一种表示。最后答案检索排序模块计算输入问题和每个答案子图之间的相似度用来对子图对应的答案候选进行打分,从而排序得到最终答案,Wen-tau Yih, Ming-Wei Chang, Xiaodong He, Jianfeng Gao. Semantic Parsing via StagedQuery Graph Generation: Question Answering with Knowledge Base, ACL, 2015。
- 基于向量表示的检索排序:为输入问题Q 和答案候选 A 分别学习两个稠密的向量表示f(Q)和g(A):并在向量空间中计算问题向量和答案向量之间的相似度,用于对不同的答案候选进行打分。
- 基于记忆网络的检索排序:除问答模块之外,引入记忆网络模块,记忆网络模块负责将有限的记忆单元表示为向量,问答模块从记忆网络模块中寻找与问题有关的答案,如Key-value Memory Network将外部数据输入表示为记忆单元,通过问句与记忆单元之间的计算来寻找答案。
- 主要难点:实体链接
- 难点1:实体链接,在文本中对知识图谱中的命名实体进行识别和消歧的任务。标准方法使用实体对齐工具(如TagMe)来检测输入文本中提到的知识图谱实体并将它们链接到正确的知识图谱条目。但也可以将实体链接问题的两部分——识别和消歧——作为一个联合任务,使用端到端的神经网络进行优化
- 难点2:多语言实体链接,在实际应用中,我们经常需要把多语言的文本中的实体链接到一个或多个不同语种的知识图谱上这类型的设定被称为是跨语言实体链接当语种数目足够多时,会出现低资源语种或实体对应的训练数据极少的情况,因此,需要格外关注零样本和少样本的情形。《Entity Linking in 100 Languages》
- LLM-based方法
- 基本方法:基于LLM进行中心实体抽取,然后从中心实体出发,获取知识图谱中有关的实体的子图,转换为自然语言作为候选答案,然后对候选答案进行向量化,根据与query的语义相似度进行排序,选出得分最高的候选答案作为上下文,输入LLM进行编排得到最终回答。
- 实体链接实现(KG-RAG):实体识别使用LLM实现,预先将KG中的节点使用特定的embedding模型进行向量化,查询时计算抽取实体与KG节点的相似度,选择topk相似节点作为候选实体。问题:1,理论层面,没有消歧,不能解决实体异名、同名异意的问题;2. 实现层面,需要预先向量化,指定向量集合和KG数据库。
- pre-LLM方法
- 从query出发的语义解析
- KAPING:直接以KG中抽取的三元组作为提示
- 从知识图谱中抽取相关的事实三元组,并将其作为提示信息输入到大模型。因此在这一方法中,如何抽取最相关的三元组是需要解决的主要问题。所提方法分为三个模块:知识获取-知识表达-知识注入。知识获取的目标从给定问题中抽取相关的实体。本模块采用的方法为传统的实体链接方法。然而,该实体相关三元组可能规模较大,且并非所有都与问题相关。基于这一考虑,本文首先采用已有的句子表示模型,分别将三元组和问题映射到统一表示空间,选择前K个与问题语义最相似的三元组。知识表达的目标是将三元组转化为文本形式的表示。知识注入的目标是根据三元组和给定问题构建大模型提示词。构建方法为首先列出N个相关三元组,然后增加说明信息“Below are facts in the form of the triple meaningful to answer the question”。
- Think on Graph:从KG中搜索下一步推理路径
- 从给定问题出发,每一步推理都要经过扩展-推理的过程,每步推理都是基于问题通过大模型在知识图谱数据中搜索下一步推理的相关路径。主要步骤为首先识别输入问题中的主题实体,然后利用大模型对外部知识图谱进行探索和推理,检索相关的路径。如此循环直到达到最大步数或得到推理答案。
- 开源项目
- https://github.com/stanford-oval/WikiChat
- 1. 基于LLM生成从wiki百科检索的查询,发送到信息检索系统,从语料库中获取相关段落,并根据时间信息对结果进行重新排序,以获取近义词段落。再看有趣的大模型RAG问答优化策略:Wikichat七步走及KG-RAG实现范式 (qq.com)
- 文本索引:使用WikiExtractor工具(https://github.com/attardi/wikiextractor) 从2023年4月28日获得的英文维基百科转储中提取纯文本,与ColBERT一样,将每篇文章(忽略表格和信息框)划分为不同的文本块作为段落,并在段落前加上文章标题,将段落和标题的总长度限制在120字以内。
- 检索召回:在维基百科上使用ColBERTv2(https://github.com/stanford-futuredata/ColBERT/) 和PLAID(https://arxiv.org/abs/2205.09707) 作为检索工具。ColBERT是一种快速准确的检索模型,可在数十毫秒内对大型文本集合进行基于BERT的可扩展搜索,ColBERT的后期交互,可有效地对查询和段落之间的细粒度相似性进行评分。ColBERT是表示-交互检索模型的代表,由一个线上encoder一个线下encoder组成,encoder具体采用的是bert,而且是共享权重的。此外,encoder的输出会进入一个没有激活函数的线性层,用于缩小每个token的维度,起到加速的作用。 而且还会将document的encoder输出结果中的标点符号去掉,也是起到加速作用。
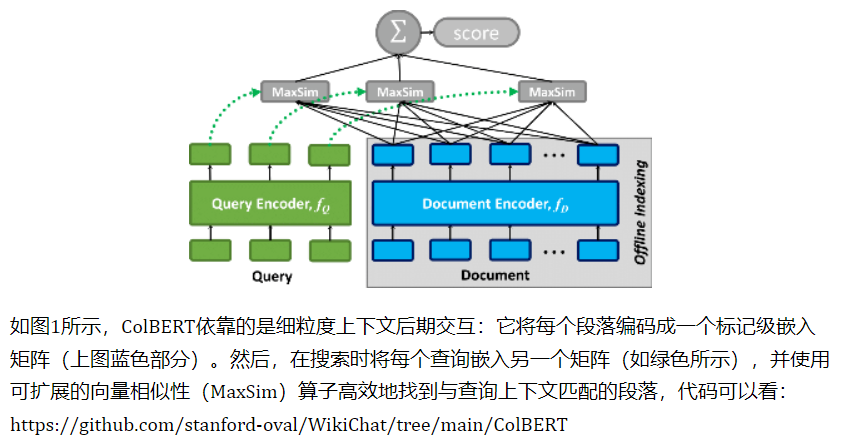
- 2. 汇总和过滤检索到的段落,基于LLM从检索到的段落中提取相关部分,并将其归纳为要点
- 3. 生成初始回复,提示LLM生成对对话历史的回复,这种回复通常包含有趣和有用的知识,但本质上并不可靠
- 4. 从回复中提取声明,LLM回复被分解为多个声明(claim)。这一阶段解决共同参照问题,以减少歧义,并解决了"当前"和"去年"等相对时间信息
- 5. 使用检索到的证据对回复中的声明进行事实检查,使用思维链提示,只有得到证据支持的声明才会被保留
- 6. 起草最终回复,根据给定的要点清单和对话历史记录生成回复草稿
- 7. 完善最终回复,根据相关性、自然性、非重复性和时间正确性生成反馈并完善回复
- 1. 基于LLM生成从wiki百科检索的查询,发送到信息检索系统,从语料库中获取相关段落,并根据时间信息对结果进行重新排序,以获取近义词段落。再看有趣的大模型RAG问答优化策略:Wikichat七步走及KG-RAG实现范式 (qq.com)
- https://github.com/stanford-oval/WikiChat
- 基本原理
- KG-enhanced LLM
- 知识注入训练的LLM
- ERNIE
- KnowBert
- LUKE
- KBERT
- 基于知识图谱微调的LLM
- KoPA(介绍)
- KoPA是一个两阶段的基于LLM的KGC框架。首先对给定的KG中的实体和关系进行结构嵌入预训练(上面的支路),然后然后通过结构前缀适配器将这些信息注入输入序列,用于采用指令调优来微调LLM。结构嵌入预训练:KoPA从KG中提取实体和关系的结构信息,并将其适应到LLM的文本表示空间中。使用负采样的自监督预训练目标定义得分函数 ( F(h,r,t) ) 来衡量三元组的合理性。通过最小化这种预训练损失,实体和关系的结构嵌入被优化以适应所有相关的三元组。知识前缀适配器:在完成结构嵌入预训练后,通过知识前缀适配器将结构嵌入转换为虚拟知识Token。这些Token作为输入序列的前缀,由于解码器仅在LLM中的单向注意力,所有后续的文本Token都可以看到这些前缀。这样,文本Token可以对输入三元组的结构嵌入进行单向注意,从而在微调和推理期间实现结构感知提示。
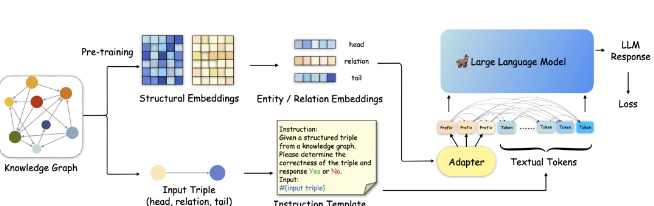
- KoPA是一个两阶段的基于LLM的KGC框架。首先对给定的KG中的实体和关系进行结构嵌入预训练(上面的支路),然后然后通过结构前缀适配器将这些信息注入输入序列,用于采用指令调优来微调LLM。结构嵌入预训练:KoPA从KG中提取实体和关系的结构信息,并将其适应到LLM的文本表示空间中。使用负采样的自监督预训练目标定义得分函数 ( F(h,r,t) ) 来衡量三元组的合理性。通过最小化这种预训练损失,实体和关系的结构嵌入被优化以适应所有相关的三元组。知识前缀适配器:在完成结构嵌入预训练后,通过知识前缀适配器将结构嵌入转换为虚拟知识Token。这些Token作为输入序列的前缀,由于解码器仅在LLM中的单向注意力,所有后续的文本Token都可以看到这些前缀。这样,文本Token可以对输入三元组的结构嵌入进行单向注意,从而在微调和推理期间实现结构感知提示。
- KoPA(介绍)
- 知识注入训练的LLM
- KG-enhanced LMM
- Structure-CLIP:通过场景图知识增强多模态结构化表示增强CLIP
- 出发点:CLIP模型产生的通用表征能力无法区分那些包含相同单词但在结构化知识方面存在差异的文本段落。换言之,CLIP模型表现出类似于词袋模型的特点,未能有效理解和捕捉句子中的细粒度语义。思路:通过场景图知识增强多模态结构化表示。与NegCLIP的随机交换方法不同,Structure-CLIP采用了基于场景图的引导策略来进行单词交换,以更精确地捕捉底层语义意图。此外,还提出了一种知识增强编码器,它利用场景图来提取关键的结构信息,并通过在输入层面上融合结构化知识,从而增强结构化表示的能力。
- Structure-CLIP:通过场景图知识增强多模态结构化表示增强CLIP
- KG-enhanced Prompt Engineering
- CoK:诱导LLM生成结构三元组来提高CoT推理中的依据可信度
- 出发点:旨在解决CoT中中间生成理由错误的问题,方法是诱导LLM生成结构三元组的显式知识证据,基于此还引入F2-Verification方法,从事实性和忠实性两个方面来评估推理链的可靠性。对于不可靠的回答,可以指出错误的证据,促使LLM重新思考。主要创新点:提示格式,因为纯文本推理链不足以让LLM生成可靠而具体的推理过程。受知识库中三重结构的启发,需要用结构化特征来增强提示。事后验证。LLM通常无法检查他们所回答的答案,这就要求利用外部知识进行验证。方法:CoK由两个主要部分组成,即证据三元组(CoK-ET)和解释提示(CoK-EH)。CoK-ET代表一个由多个三元组组成的列表,每个三元组都代表从大模型那里获得的知识证据,以支持逐步思考的过程。在事实性验证上,事实性可视为每个生成的三元组证据与知识库中的基本真实知识之间的匹配度。具体来说,定义一个函数fv来表示每个证据的真实性。设计两种不同的fv策略:精确验证和隐式验证。在忠实性验证上,给定一个测试查询、一个证据三元组列表和最终答案,直接将它们连接成一个新的序列,利用预置的句子编码器SimCSE来计算新序列与先前序列之间的相似度,最后,对于每个查询,可以得到一个分数Ci(0<Ci<1),表示该理由对答案是否可靠。当LLM生成的推理链未能通过验证且可靠性得分低于阈值θ时,会在反思阶段为它们提供额外的再次生成机会。
- BSChecker:将大模型输出分解为三元组分步进行幻觉检测
- BSChecker其思想在于,与传统的段落或句子级别的分析方法不同,将大模型的输出文本分解成知识三元组,该工作将幻觉检测的最小单元称为一个声明(claim)。在计算方式上,不同于传统幻觉检测方法将整个输出文本分类为是否存在幻觉这两种类别标签,BSChecker对输出文本中的每一个声明都进行幻觉检测并分类。输出文本和其相应的参考文本之间的关系可以分成蕴涵(Entailment,图中绿勾✅)和矛盾(Contradiction,图中红叉❌)以及中立(图中的问号)。BSChecker具有模块化的工作流程,分为声明抽取器E,幻觉检测器C,以及聚合规则τ,将输入文本分解成一组知识三元组。每个三元组都要经过验证,验证。随后,根据预定义的规则,汇总各个结果,以确定给定文本的整体幻觉标签。本质上是以文本抽取的多个三元组为评估基准,来评估整个输出的幻觉可能。
- Extractor使用GPT-4和Claude 2,Checker使用大量现有的ZERO-SHOT校验器,而无需额外的训练,主要考虑两种类型:基于LLM的检查器和基于NLI的检查器,在汇总阶段,得到整个输入文本的整体幻觉标签。
- graph-guided reasoning: 通过图表示/验证步骤引导CoT
- 包括如下几个步骤:1. 图表示,利用LLMs构建一个“问题/理由图”,该图是一个有向无环图,其中每个节点是一个问题或一个理由,每条边是一个关系。图表示的目的是将问题和理由的语义结构显式地表示出来,以便于后续的推理。2. 图验证,利用LLMs对当前的理由节点进行诊断,通过将其与现有的问题/理由图进行比较,来过滤掉无关的理由,并生成后续的问题,以获取更多的相关信息。图验证的目的是检查和纠正当前的推理路径,以避免错误或不完整的推理。3. 图补充,利用LLMs生成不包含图中提取信息的CoT路径,以表示图抽取中遗漏的上下文信息。图补充的目的是补充和完善当前的推理路径,以提高推理的全面性和鲁棒性。
- 具体实现:问题图构建是指利用大型语言模型从问题中提取知识三元组,并将其表示为一个图结构。中间问题生成是指根据问题图中的三元组,生成一个与初始问题相关的子问题,以获取回答问题所需的信息。中间答案生成是指利用大型语言模型回答中间问题,并生成一个作为推理步骤的中间答案。在开放领域的设置中,还可以利用检索增强的方法,根据中间问题作为查询,从外部知识库中检索相关的段落,以辅助中间答案的生成。理由验证是指将生成的中间答案转换为三元组的形式,并与问题图进行匹配,以验证其是否有效和有用。如果中间答案被拒绝,就返回到中间问题生成的步骤。这个过程重复进行,直到生成的理由图与问题图匹配,或者达到重复的限制。然后,大型语言模型根据所有的中间答案,生成最终的答案。
- CoK:诱导LLM生成结构三元组来提高CoT推理中的依据可信度
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/348773
推荐阅读
相关标签

