- 1SpringCloud Hystrix保护机制_hystrix断路器保护机制
- 2Kafka中的max-poll-records和listener.concurrency配置
- 3Centos7搭建minio_centos7安装minio
- 4Linux源码安装pgadmin4,linux安装pgadmin3
- 5区间划分DP模板题!!!!_将数组分割成 k 段 异或 dp
- 6cmd查看局域网内所有设备ip
- 7大数据Hadoop集群之超级详细的Hive安装配置_hadoop配置hive
- 8Linux快速部署大语言模型LLaMa3,Web可视化j交互(Ollama+Open Web UI)_llama3 webui
- 9数字逻辑基础实验——组合逻辑电路的设计一_数字逻辑电路实验
- 10Matlab绘制对数轴
Java面试中的常见问题_java面试项目中遇到的问题与解决
赞
踩
Java面试中的常见问题
ps
- 本篇文章一方面是为了记录自己在面试时遇到的一些问题,一方面也是为了巩固自己的知识以及方便自己查看。
- 其中内容可能有些会有错,欢迎大家指出,想看更详细的可以参考官方文档或者大佬文章,用这篇文章来开启自己写博客的第一次尝试吧。
正文
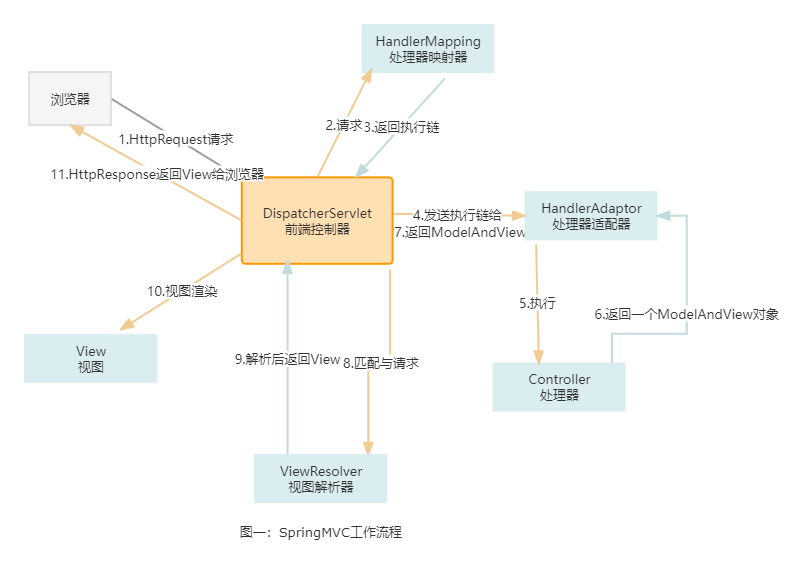
1.讲讲SpringMvc的执行流程
浏览器提交http请求 >> 请求发送到服务器,被DispatcherServlet(前端控制器)拦截 >> 根据配置文件找到请求对应的HandlerMapping(处理器映射器)>> 找到对应的Controller,执行Service业务代码 >> 返回结果封装到ModelAndView >> 再次根据DispatcherServlet找到对应的ViewResolver(视图解析器)>> 将Model传入进行视图渲染 >> 最后返回请求到浏览器
2.讲讲Spring的IOC和AOP
1、IOC简称控制反转,又被叫做依赖注入(DI),作用就是将原来需要手动创建对象的权力交给了Spring工厂管理,避免了程序员创建和管理对象的繁琐。当我们需要一个对象时,只需要配置好文件或者使用注解就可以实现自动注入。控制对象生命周期的不再是引用它的对象,而是Spring。对于某个具体的对象而言,以前时它控制其他对象,现在是所有对象都被Spring所控制,这就叫做控制反转。
2、AOP面向切面编程,主要应用于在一些与应用核心业务无关但又需要对业务做增强的时候。例如:事务的控制、权限、安全、日志。
3.数据库方面有了解吗?讲讲关系型数据库和非关系型数据库的区别
- 关系型数据库(如MySql)
特点:存储的格式可以直观地反映实体间的关系。关系型数据库和常见的表格比较相似,关系型数据库中表与表之间是有很多复杂的关联关系的。
优势:体积小、速度快、成本低、能始终保持数据的一致性
不足:随着云计算的发展和大数据时代的到来,关系型数据库越来越无法满足需要,这主要是由于越来越多的半关系型和非关系型数据需要用数据库进行存储管理,以此同时,分布式技术等新技术的出现也对数据库的技术提出了新的要求,于是越来越多的非关系型数据库就开始出现。
- 非关系型数据库(如Rides)
特点:非关系型数据不适合表格存储方式,通常以数据集的方式,大量的数据集中存储在一起,类似于键值对、图结构或者文档。更强调数据库数据的高并发读写和存储大数据。
优势:数据库结构相对简单,在大数据量下的读写性能好;高扩展、高性能;能满足随时存储自定义数据格式需求,非常适用于大数据处理工作。
不足:数据量过大时很难保证数据的准确性
4.讲讲数据库的事务
关系型数据库强调ACID规则(原子性、一致性、隔离性、持久性):
1、原子性(Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么全部不执行。
2、一致性(Consistency):几个并行执行的事务,其执行结果必须与按某一顺序 串行执行的结果相一致。
3、隔离性(Isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
4、持久性(Durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。
数据库事务的隔离级别有4种,由低到高分别为Read uncommitted 、Read committed 、Repeatable read 、Serializable 。而且,在事务的并发操作中可能会出现脏读,不可重复读,幻读。
5.讲讲多线程
定义:线程是进程中的一部分,也是进程的的实际运作单位,它也是操作系统中的最小运算调度单位。进程中的一个单一顺序的控制流就是一条线程,多个线程可以在一个进程中并发。可以使用多线程技术来提高运行效率。
实现多线程的几种方式:
1、继承Thread类
新建一个类继承Thread类,并重写Thread类中的run()方法,将要执行的任务放到run()方法里面
创建该类的对象,调用该对象的start()方法,即可启动一个新的线程,并在新的线程中执行run()方法中的任务
2、通过Runnable接口
新建一个类实现Runnable接口,并重写Runnable接口中的run()方法,将要执行的任务放到run()方法里面
3、借助线程池
新建一个类实现Runnable接口,重写run()方法,放入任务;或者实现Callable接口,重写call方法,放入任务
调用Executors类的newFixedThreadPool()方法,获取一个指定线程池容量的ExecutorService类型对象。
调用该对象的execute()方法,传入Runnable类型的对象或者调用submit()方法,传入Callable类型的对象,即可在一个新的线程中执行任务
线程的生命周期
线程生命周期的五个状态:创建(New)、就绪(Runnable)、运行(Running)、阻塞(blocked)、死亡(dead)
当线程进入运行状态时,不会一直进入运行状态霸占CPU,一般的操作系统是采用自有调度式的方式让线程获取CPU权限开始执行,线程会在就绪、执行、阻塞之间来回切换
6.string、stringbuffer和stringbuilder的区别是什么?
区别:String类是不可变类,当一个String对象被创建,则包含在对象中的字符序列是不可改变的,直至对象被销毁;StringBuffer对象代表可变字符串对象,且线程安全;StringBuilder类代表可变字符串对象,且非线程安全。
7.Redis的数据类型有几种?了解他们的数据结构吗?
Redis数据类型有5种:
分别是String(字符串),Hash(哈希),List(列表),Set(集合)及Zset(sorted set:有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
Redis常见数据类型的数据结构:
String
简单动态字符串 (Simple Dynamic String,SDS)
List
压缩列表 双向链表
Hash
哈希表
Sorted Set
压缩列表
跳表: 主要服务范围操作,提供O(logN)的复杂度
哈希表: 额外存储结构:用来存储元素对应的score mapping, 用于返回单个集合member的分数,它的操作复杂度是O(1)
Set
整形数组
哈希表
8.谈谈session和cookie的区别?
1、保存的位置不同
cookie保存在浏览器端,session保存在服务端。
2、使用方式不同
cookie如果在浏览器端对cookie进行设置对应的时间,则cookie保存在本地硬盘中,此时如果没有过期,则就可以使用,如果过期则就删除。如果没有对cookie设置时间,则默认关闭浏览器,则cookie就会删除。
session:我们在请求中,如果发送的请求中存在sessionId,则就会找到对应的session对象,如果不存在sessionId,则在服务器端就会创建一个session对象,并且将sessionId返回给浏览器,可以将其放到cookie中,进行传输,如果浏览器不支持cookie,则应该将其通过encodeURL(sessionID)进行调用,然后放到url中。
3、存储内容不同:cookie只能存储字符串,而session存储结构类似于hashtable的结构,可以存放任何类型。
4、存储大小:``cookie最多可以存放4k大小的内容,session则没有限制。
5、session的安全性要高于cooKie
6、cookie的session的应用场景:cookie可以用来保存用户的登陆信息,如果删除cookie则下一次用户仍需要重新登录
session就类似于我们拿到钥匙去开锁,拿到的就是我们个人的信息,一般我们可以在session中存放个人的信息或者购物车的信息。
7、session和cookie的弊端:cookie的大小受限制,cookie不安全,如果用户禁用cookie则无法使用cookie。如果过多的依赖session,当很多用户同时登陆的时候,此时服务器压力过大。sessionId存放在cookie中,此时如果对于一些浏览器不支持cookie,此时还需要改写代码,将sessionID放到url中,也是不安全。
9.说说类加载机制
a.加载
我们编写的 Java 文件都是以.java 为后缀的文件,编译器会将我们编写的.java 的文件编译成.class 文件,简单来说类加载机制就是jvm从文件系统将一系列的 class 文件转化为二进制流加载 JVM 内存中并生成一个该类的Class对象,为后续程序运行提供资源的动作。
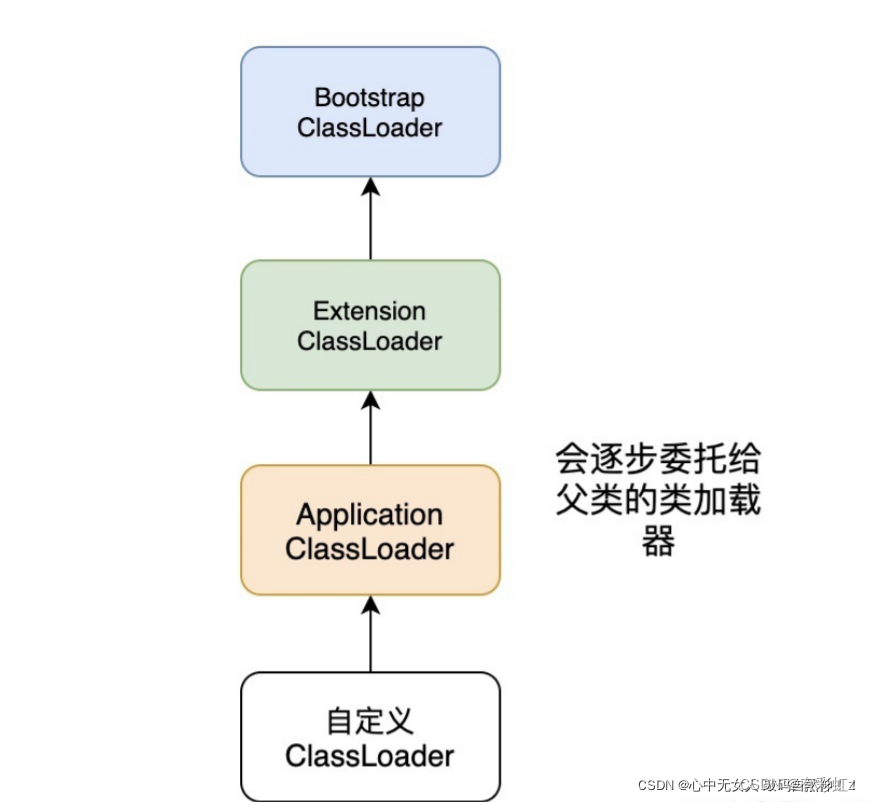
b.类加载器
类加载器:讲到类加载不得不讲到类加载的顺序和类加载器。Java 中大概有四种类加载器,分别是:启动类加载器(Bootstrap ClassLoader),扩展类加载器(Extension ClassLoader),系统类加载器(System ClassLoader),自定义类加载器(Custom ClassLoader),依次属于继承关系(注意这里的继承不是 Java 类里面的 extends)
启动类加载器(Bootstrap ClassLoader):主要负责加载存放在Java_Home/jre/lib下,或被-Xbootclasspath参数指定的路径下的,并且能被虚拟机识别的类库(如rt.jar,所有的java.*开头的类均被Bootstrap ClassLoader加载),启动类加载器是无法被Java程序直接引用的。
扩展类加载器(Extension ClassLoader):主要负责加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载Java_Home/jre/lib/ext目录中,或者由java.ext.dirs系统变量指定的路径中的所有类库(如javax.*开头的类),开发者可以直接使用扩展类加载器。
系统类加载器(System ClassLoader):主要负责加载器由sun.misc.Launcher$AppClassLoader来实现,它负责加载用户类路径(ClassPath)所指定的类,开发者可以直接使用该类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
自定义类加载器(Custom ClassLoader:自己开发的类加载器
c:双亲委派
如果一个类加载器需要加载类,那么首先它会把这个类加载请求委派给父类加载器去完成,如果父类还有父类则接着委托,每一层都是如此。
一直递归到顶层,当父加载器无法完成这个请求时,子类才会尝试去加载。
10.什么是缓存雪崩、击穿、穿透?
1、缓存雪崩解决方案:
1.1 针对大量数据同时过期而引发的缓存雪崩问题,常见的应对方法有下面这几种:
均匀设置过期时间;
互斥锁;
双 key 策略;
后台更新缓存;
1.2 针对 Redis 故障宕机而引发的缓存雪崩问题,常见的应对方法有下面这几种:
服务熔断或请求限流机制;
构建 Redis 缓存高可靠集群;
2、缓存击穿解决方案:
2.1 应对缓存击穿可以采取前面说到两种方案:
互斥锁方案,保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;
3、缓存穿透解决方案:
3.1 缓存穿透的发生一般有这两种情况:
业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据;
黑客恶意攻击,故意大量访问某些读取不存在数据的业务;
3.2 应对缓存穿透的方案,常见的方案有三种。
第一种方案,非法请求的限制;
第二种方案,缓存空值或者默认值;
第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在;

11.什么时反射?
反射机制的概念:
指在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法,对于任意一个对象,都能调用它的任意一个方法.这种动态获取信息,以及动态调用对象方法的功能叫java语言的反射机制.
12.TCP和UDP的区别
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
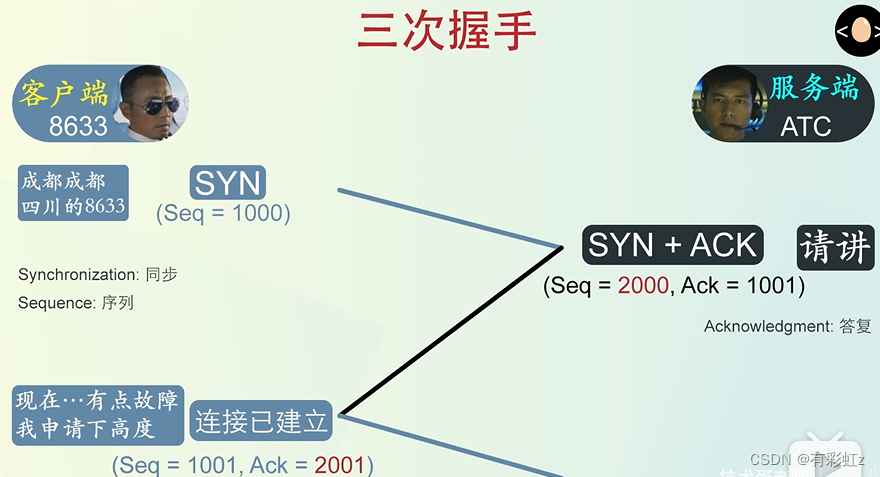
13. 描述一下TCP的三次握手过程
过程描述:
1.首先 Client 端发送连接请求报文
2.Server 端接受连接后回复 ACK 报文,并为这次连接分配资源。
3.Client 端接收到 ACK 报文后也向 Server 段发生 ACK 报文,并分配资源,这样 TCP 连接就建立了。
用川航举例子