
热门标签
热门文章
- 1Unity中的UGUI源码解析之事件系统(7)-输入模块(上)_baseinput
- 2车牌识别系统_车牌识别系统csdn
- 3Axure RP Pro - 相关问题 - 统计选中的复选框的数量_axure 设置复选框数量统计
- 4uniapp使用swiper组件自定义左侧菜单栏和切换菜单_uniapp左侧菜单
- 5yolov5从入门到精通_yolo图书
- 6Ubuntu20.04LTS系统查看NVIDIA显卡驱动版本_ubuntu查看显卡驱动版本
- 7NEO4J学习(一)_for name in invoice_name_list: node_1 = node(label
- 8js 通过id找数组对象中的name_小程序js 通过id获取name
- 9Linux如何指向mysql_linux 下mysql一些基本操作
- 10Excel数据分析项目——电商数据分析实战_电商广告推广数据分析表格怎么做
当前位置: article > 正文
根据yolo训练的csv文件绘制模型对比曲线_yolov5 根据result.txt画出loss图代码
作者:IT小白 | 2024-02-22 10:44:50
赞
踩
yolov5 根据result.txt画出loss图代码
复杂一点的
更简单的直接跳转
csv文件准备:

每个csv文件内容如下
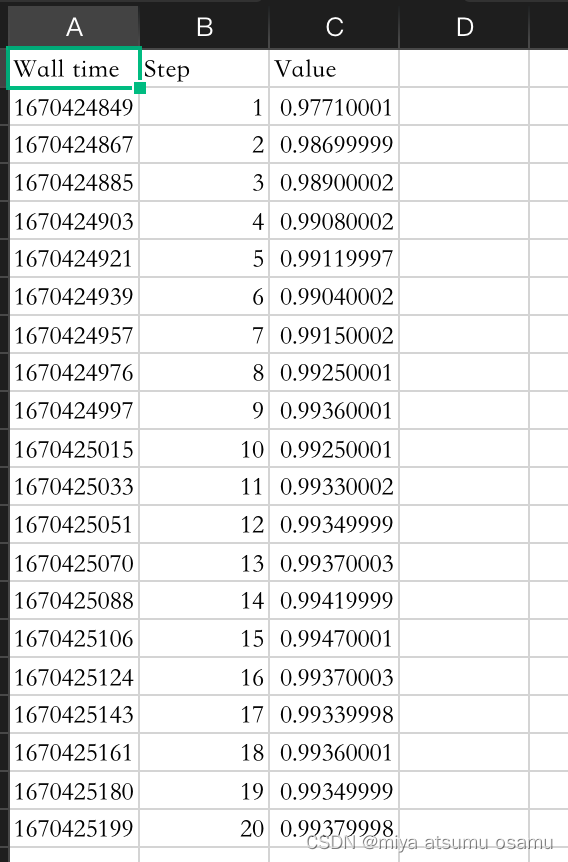 ##### 代码
##### 代码
# 绘制目标检测损失对比曲线 import matplotlib import pandas as pd import warnings import matplotlib.pyplot as plt warnings.filterwarnings("ignore", category=matplotlib.MatplotlibDeprecationWarning) # 进行绘图操作 net2 = pd.read_csv('/Volumes/LaCie/卷积神经网络实现minst数据集分类/minst_demo/edata2/logs2-train_loss/logs2-net2-train_loss.csv', usecols=['Step', 'Value']) plt.plot(net2.Step, net2.Value, lw=1.0, label='net2', color='blue') net4 = pd.read_csv('/Volumes/LaCie/卷积神经网络实现minst数据集分类/minst_demo/edata2/logs2-train_loss/logs2-net4-train_loss.csv', usecols=['Step', 'Value']) plt.plot(net4.Step, net4.Value, lw=1.0, label='net4', color='red', linestyle='dashdot') # 使用曲线插值 net5 = pd.read_csv('/Volumes/LaCie/卷积神经网络实现minst数据集分类/minst_demo/edata2/logs2-train_loss/logs2-net5-train_loss.csv', usecols=['Step', 'Value']) plt.plot(net5.Step, net5.Value, lw=1.0, label='net5', color='black', linestyle='dashdot') # 使用曲线插值 plt.xlabel('Epoch') plt.ylabel('loss') plt.legend(loc=0) plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
效果
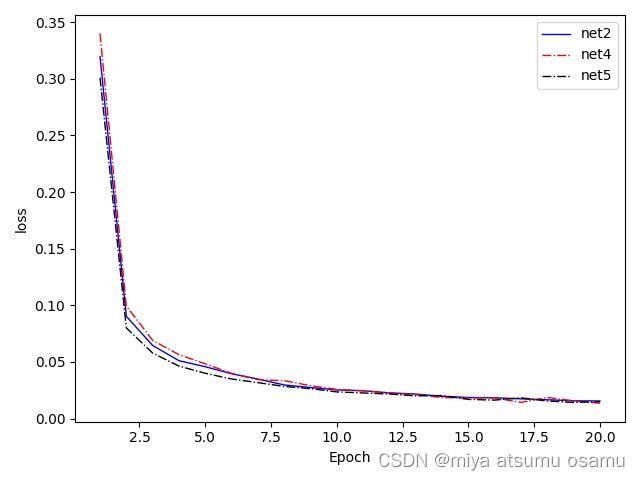
写到这里突然发现有种更简单的方法,后面有时间在补吧!
直接利用csv绘制
还有一种简单一点的方法: 直接根据模型训练得到的csv文件来绘制曲线,一般csv文件的列名是下面这样的
放个清楚一点的就是这样的
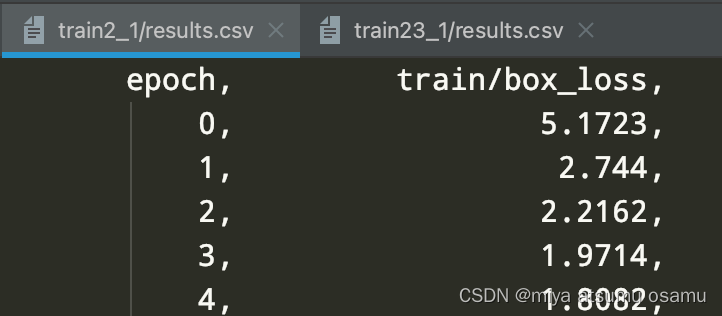
注意,有的模型训练的时候使用了早停机制,所以两个需要对比的csv文件的epoch是不一样的,如果你需要实现以最小的那个epoch为准使用下面这段代码
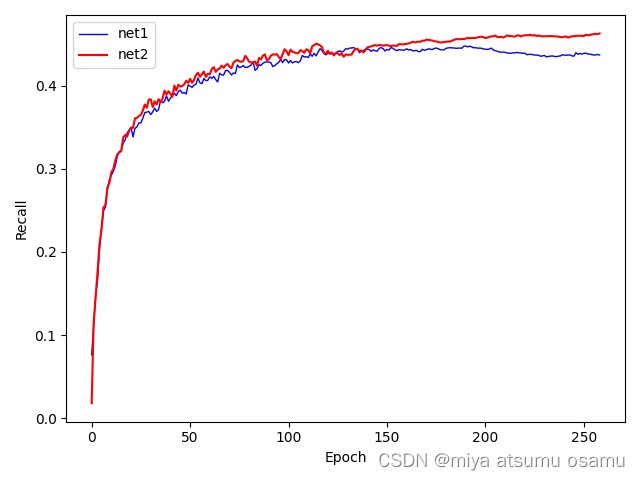
import pandas as pd import matplotlib.pyplot as plt # 读取两个CSV文件 data1 = pd.read_csv('train_data/train23_1/results.csv') data2 = pd.read_csv('train_data/train2_1/results.csv') # 去除列名前后的空格 data1.columns = data1.columns.str.strip() data2.columns = data2.columns.str.strip() # 提取'epoch'和'metrics/recall(B)'列的数据 epoch1 = data1['epoch'] recall1 = data1['metrics/recall(B)'] epoch2 = data2['epoch'] recall2 = data2['metrics/recall(B)'] # 找到两个数据集中的最大epoch值 min_epoch1 = max(epoch1) print(min_epoch1) min_epoch2 = max(epoch2) print(min_epoch2) # 取两个数据集中最大epoch值的最小值,以确定共同的epoch范围 min_common_epoch = min(min_epoch1, min_epoch2) # 仅保留小于最小共同epoch值的数据点 epoch1 = epoch1[epoch1 < min_common_epoch] recall1 = recall1[:len(epoch1)] epoch2 = epoch2[epoch2 < min_common_epoch] recall2 = recall2[:len(epoch2)] # 绘制曲线 plt.plot(epoch1, recall1, lw=1.0, label='net1', color='blue') plt.plot(epoch2, recall2, lw=1.5, label='net2', color='red') plt.xlabel('Epoch') plt.ylabel('Recall') plt.legend(loc=0) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
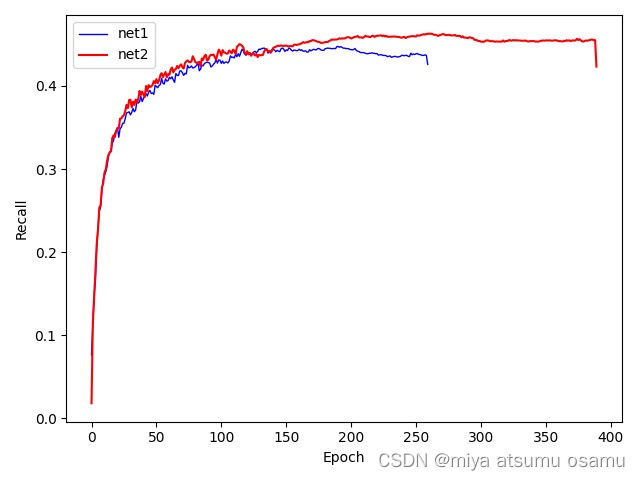
效果如下:
当然,如果你想体现所有的epoch,那就更简单了。下面这段代码请食用:
import pandas as pd import matplotlib.pyplot as plt # 读取CSV文件,不仅仅包括'epoch'和'metrics/recall(B)'列 data1 = pd.read_csv('train_data/train23_1/results.csv') # 去除列名前后的空格,并提取'epoch'和'metrics/recall(B)'列的数据 data1.columns = data1.columns.str.strip() epoch1 = data1['epoch'] recall1 = data1['metrics/recall(B)'] plt.plot(epoch1, recall1, lw=1.0, label='YOLOv8', color='blue') # 类似地处理第二个数据集 data2 = pd.read_csv('train_data/train2_1/results.csv') data2.columns = data2.columns.str.strip() epoch2 = data2['epoch'] recall2 = data2['metrics/recall(B)'] plt.plot(epoch2, recall2, lw=1.5, label='Diamond-YOLO', color='red') # 使用曲线插值 plt.xlabel('Epoch') plt.ylabel('Recall') plt.legend(loc=0) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
效果如下:
持续更新中…
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/129781
推荐阅读
相关标签

