
- 1Paul Graham:梦寐以求的编程语言_prefix owned by other rid
- 2两数之和(不使用+、- 运算符)LeetCode_不用数学操作符实现两个数字相加
- 32020/12/11 基于Istio实现微服务治理
- 4书生·浦语全链条开源开放体系
- 5总结避免死锁的几种方法_避免死锁的三种方法
- 6iis网站用Web.config文件设置301和404跳转,_web.config 301
- 7清华ChatGLM2-6B一键式部署,无需自行安装依赖环境!!_chatglm2-6b下载
- 8微软曾想将 Bing 搜索卖给苹果;英伟达首次公开将华为列为对手丨 RTE 开发者日报 Vol.151
- 9go语言基础知识-GOROOT、GOPATH、go install、go build、go mod_go mod install
- 10Java中抽象类与接口详解_java接口与抽象类
Elasticsearch7.17 二:mapping映射和高级语法查询DSL_es 7.17 分页查询
赞
踩
mapping映射和高级语法查询DSL
文档映射Mapping
映射类型
Mapping类似数据库中的schema的定义,作用如下:
- 定义索引中的字段的名称
- 定义字段的数据类型,例如字符串,数字,布尔等
- 字段,倒排索引的相关配置(Analyzer)
ES中Mapping映射可以分为动态映射和静态映射。
动态映射:
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类 型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
静态映射: 静态映射是在Elasticsearch中也可以事先定义好映射,包含文档的各字段类型、分词器 等,这种方式称之为静态映射
更改Mapping的字段类型
新增加字段
dynamic设为true时,一旦有新增字段的文档写入,Mapping 也同时被更新
dynamic设为false,Mapping 不会被更新,新增字段的数据无法被索引,但是信息会出现在_source中
dynamic设置成strict(严格控制策略),文档写入失败,抛出异常
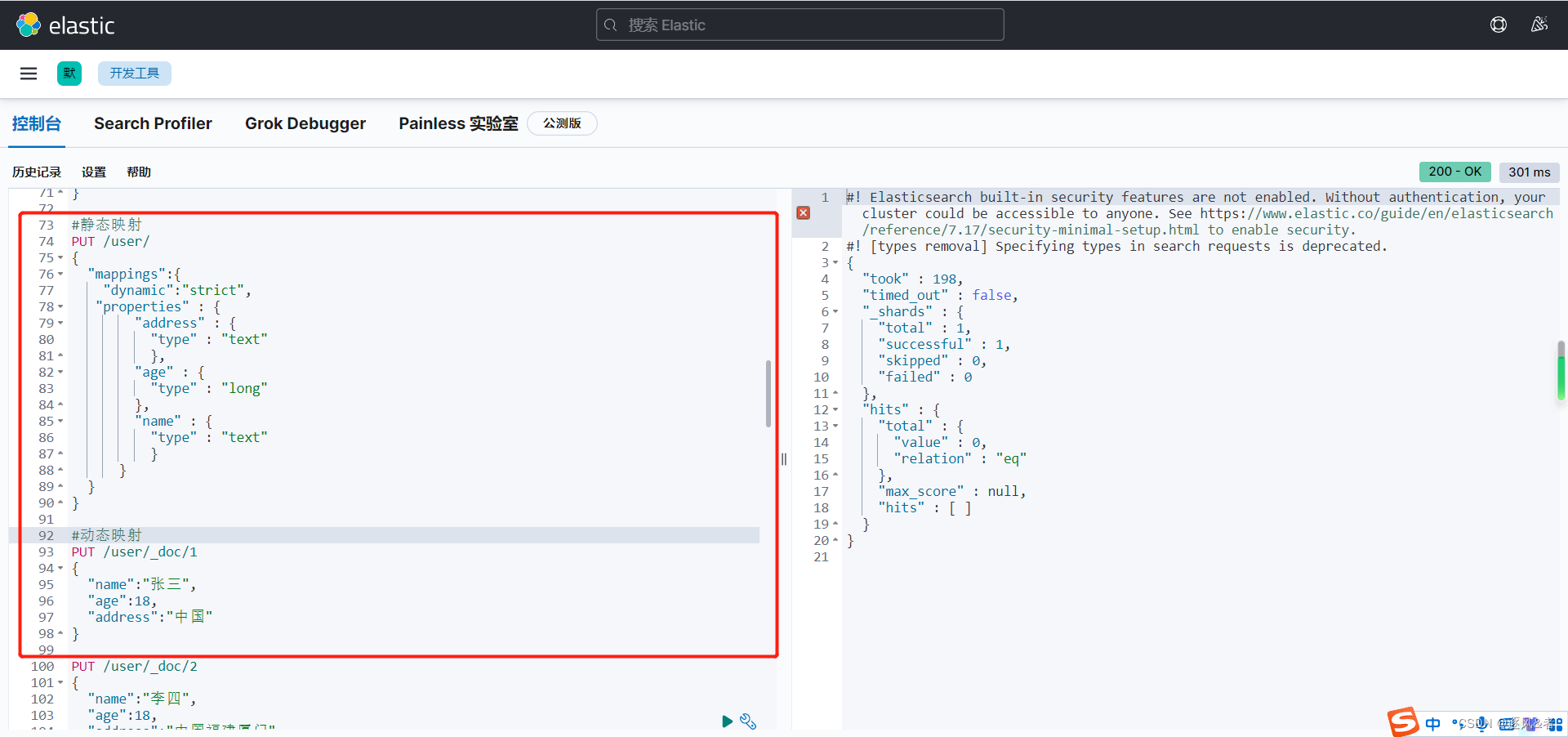
PUT /user/ { "mappings":{ "dynamic":"strict", "properties" : { "address" : { "type" : "text" }, "age" : { "type" : "long" }, "name" : { "type" : "text" } } } } PUT /user/_doc/1 { "name":"张三", "age":18, "address":"中国" } # 如果"dynamic"为true,province会更新到mapping中,可以被搜索 # 如果"dynamic"为false,province不会更新到mapping中,无法被搜索,但会在_source中展示 # 如果"dynamic"为strict,执行 PUT /user/_doc/2 会报错 PUT /user/_doc/2 { "name":"李四", "age":18, "address":"中国福建厦门", "province":"厦门" }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
对已有字段:
一旦已经有数据写入,就不再支持修改字段定义。Lucene 实现的倒排索引,一旦生成后,就不允许修改如果希望改变字段类型,可以利用 reindex API,重建索引。因为:如果修改了字段的数据类型,会导致已被索引的数据无法被搜索
但是如果是增加新的字段,就不会有这样的影响
那如何修改已有的字段,具体步骤
1)如果要推倒现有的映射, 你得重新建立一个静态索引
2)然后把之前索引里的数据导入到新的索引里
3)删除原创建的索引
4)为新索引起个别名, 为原索引名
#新建索引 PUT /user2/ { "mappings":{ "properties" : { "address" : { "type" : "keyword" }, "age" : { "type" : "long" }, "name" : { "type" : "text", "analyzer": "ik_max_word" } } } } #将旧索引的数据复制到新索引中 POST _reindex { "source": { "index": "user" }, "dest": { "index": "user2" } } #删除旧索引 DELETE /user # 给新索引设置别名 PUT /user2/_alias/user
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
通过这几个步骤就实现了索引的平滑过渡,并且是零停机
常用Mapping参数配置
ndex: 控制当前字段是否被索引,默认为true。如果设置为false,该字段不可被搜索
index options配置:有四种不同index options配置,控制倒排索引记录的内容:
- docs : 记录doc id
- freqs:记录doc id 和term frequencies(词频)
- positions: 记录doc id / term frequencies / term position
- offsets: doc id / term frequencies / term posistion / character offsets
text类型默认记录postions,其他默认为 docs。记录内容越多,占用存储空间越大
null_value: 需要对Null值进行搜索,只有keyword类型支持设计Null_Value
copy_to设置:将字段的数值拷贝到目标字段,满足一些特定的搜索需求。copy_to的目标字段不出现在_source中。
PUT /user2/ { "mappings":{ "properties" : { "address" : { "type" : "keyword", "index": false, "null_value": "NULL" }, "age" : { "type" : "long" }, "name" : { "type" : "text", "analyzer": "ik_max_word", "index_options": "docs" }, "province" : { "type" : "keyword", "copy_to": "full_address" }, "city" : { "type" : "text", "copy_to": "full_address" } } }, "settings" : { "index" : { "analysis.analyzer.default.type": "ik_max_word" } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
批量操作
批量操作可以减少网络连接所产生的开销,提升性能
- 支持在一次API调用中,对不同的索引进行操作
- 可以再URI中指定Index,也可以在请求的Payload中进行
- 操作中单条操作失败,并不会影响其他操作
- 返回结果包括了每一条操作执行的结果
通过_bulk操作文档,一般至少有两行参数(或偶数行参数),第一行参数为指定操作的类型及操作的对象(index,type和id)
第二行参数才是操作的数据。
参数类似于:
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}
- 1
- 2
actionName:表示操作类型,主要有create,index,delete和update
批量创建文档create
批量对文档进行写操作是通过_bulk的API来实现的
POST _bulk
{"create":{"_index":"user","_id":1}}
{"id":1,"name":"张三","content":"张三的名称","tags":["java","面向对象"],"create_time":1554015482530}
{"create":{"_index":"user","_id":2}}
{"id":2,"title":"李四","content":"李四的名称","tags":["java","面向对象"],"create_time":1554015482530}
- 1
- 2
- 3
- 4
- 5
普通创建或全量替换index
POST _bulk
{"index":{"_index":"user","_id":1}}
{"id":1,"name":"张三","content":"张三的名称","tags":["java","面向对象"],"create_time":1554015482530}
{"index":{"_index":"user","_id":2}}
{"id":2,"title":"李四","content":"李四的名称","tags":["java","面向对象"],"create_time":1554015482530}
- 1
- 2
- 3
- 4
- 5
如果原文档不存在,则是创建
如果原文档存在,则是替换(全量修改原文档)
批量删除delete
POST _bulk
{"delete":{"_index":"user","_id":1}}
{"delete":{"_index":"user","_id":2}}
- 1
- 2
- 3
批量修改update
POST _bulk
{"update":{"_index":"user", "_id":1}}
{"doc":{"name":"张三111"}}
{"update":{"_index":"user", "_id":2}}
{"doc":{"name":"李四111"}}
- 1
- 2
- 3
- 4
- 5
ES高级查询Query DSL
ES中提供了一种强大的检索数据方式,这种检索方式称之为Query DSL(Domain Specified Language) , Query DSL是利用Rest API传递JSON格式的请求体(RequestBody)数据与ES进行交互,这种方式的丰富查询语法让ES检索变得更强大,更简洁。语法:GET /es_db/_search {json请求体数据}
测试数据
PUT _bulk
{"create":{"_index":"es_db","_id":1}}
{"name": "张三","sex": 1,"age": 25,"address": "广州天河公园","remark": "java developer"}
{"create":{"_index":"es_db","_id":2}}
{"name": "李四","sex": 1,"age": 28,"address": "广州荔湾大厦","remark": "java assistant"}
{"create":{"_index":"es_db","_id":3}}
{"name": "王五","sex": 0,"age": 26,"address": "广州白云山公园","remark": "php developer"}
{"create":{"_index":"es_db","_id":4}}
{"name": "赵六","sex": 0,"age": 22,"address": "长沙橘子洲","remark": "python assistant"}
{"create":{"_index":"es_db","_id":5}}
{"name": "张龙","sex": 0,"age": 19,"address": "长沙麓谷企业广场","remark":"java architect assistant"}
{"create":{"_index":"es_db","_id":6}}
{"name": "赵虎","sex": 1,"age": 32,"address": "长沙麓谷兴工国际产业园","remark":"java architect"}
{"create":{"_index":"es_db","_id":7}}
{"name": "小小","sex": 1,"age": 32,"address": "广州世界公园","remark":"java architect"}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
查询所有match_all
使用match_all,默认只会返回10条数据。_search查询默认采用的是分页查询,每页记录数size的默认值为10。如果想显示更多数据,指定size
GET /es_db/_search 等同于 GET /es_db/_search { "query":{ "match_all":{} } #================== } GET es_db/_search { "size":10001 #size默认最大1万条,超过会报错 可以通过参数配置 } #设置查询结果的窗口的限制 PUT es_db/_settings { "index.max_result_window" :"20000" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
注意:参数index.max_result_window主要用来限制单次查询满足查询条件的结果窗口的大小,窗口大小由from + size共同决定。不能简单理解成查询返回给调用方的数据量。这样做主要是为了限制内存的消耗。
分页查询
from 关键字: 用来指定起始返回位置,和size关键字连用可实现分页效果
GET es_db/_search
{
"size": 2,
"from": 0
}
- 1
- 2
- 3
- 4
- 5
深分页查询Scroll
改动index.max_result_window参数值的大小,只能解决一时的问题,当索引的数据量持续增长时,在查询全量数据时还是会出现问题。而且会增加ES服务器内存大结果集消耗完的风险。最佳实践还是根据异常提示中的采用scroll api更高效的请求大量数据集。
#查询命令中新增scroll=1m,说明采用游标查询,保持游标查询窗口一分钟。
GET /es_db/_search?scroll=1m
{
"size": 3
}
#scroll_id 的值就是上一个请求中返回的 _scroll_id 的值
#这里不需要指定size,第一次查询多少条,通过scroll返回的也是多少条
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFldmbm0tUkU3U0JPUUhUY0RST1Y1SmcAAAAAAABgnhZUTGlHdVB3MlEyeUU0d1VRTjNXd1F3"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
多次根据scroll_id游标查询,直到没有数据返回则结束查询。采用游标查询索引全量数据,更安全高效,限制了单次对内存的消耗。
指定字段排序和指定字段返回
GET es_db/_search
{
"from": 0,"size": 10,
"sort": [{"age": "desc"}], #指定排序会让得分失效
"_source": ["name","sex","address"]
}
- 1
- 2
- 3
- 4
- 5
- 6
match
match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找。match支持以下参数:
query : 指定匹配的值
operator : 匹配条件类型
and : 条件分词后都要匹配
or : 条件分词后有一个匹配即可(默认)
minmum_should_match : 最低匹配度,即条件在倒排索引中最低的匹配度
#分词后or的效果 GET es_db/_search { "query": { "match": { "address": "广州白云山公园" } } } #分词后and的效果 GET es_db/_search { "query": { "match": { "address": {"query": "广州白云山公园","operator": "and"} }} } #分词后or的效果 但至少要满足2个任意的分词条件 GET es_db/_search { "query": {"match": { "address": {"query": "广州白云山公园","operator": "or","minimum_should_match": 2} }} } #查看分词 GET _analyze { "analyzer": "ik_max_word", "text": "广州白云山公园" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
多字段查询multi_match
可以根据字段类型,决定是否使用分词查询,得分最高的在前面
GET es_db/_search
{
"query": {"multi_match": {
"query": "长沙王五",
"fields": ["name","address"]
}}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
注意:字段类型分词,将查询条件分词之后进行查询,如果该字段不分词就会将查询条件作为整体进行查询。
多字段查询query_string
允许我们在单个查询字符串中指定AND | OR | NOT条件,同时也和 multi_match query 一样,支持多字段搜索。和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。
注意: 查询字段分词就将查询条件分词查询,查询字段不分词将查询条件不分词查询
#未指定字段查询 GET /es_db/_search { "query": { "query_string": { "default_field": "address", "query": "白云山 OR 橘子洲" } } } #未指定字段查询 GET es_db/_search { "query": { "query_string": { "query": "张三 OR 橘子洲" } } } #指定多字段查询 GET /es_db/_search { "query": { "query_string": { "fields": ["name","address"], "query": "张三 OR 橘子洲" } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
关键词查询Term
Term用来使用关键词查询(精确匹配),还可以用来查询没有被进行分词的数据类型。Term是表达语意的最小单位,搜索和利用统计语言模型进行自然语言处理都需要处理Term。match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找,而term会直接对关键词进行查找。一般模糊查找的时候,多用match,而精确查找时可以使用term
在ES的Mapping Type 中 keyword , date ,integer, long , double , boolean or ip 这些类型不分词,只有text类型分词。
# 查不到数据 因为倒排索引中没有广白云山公园 GET es_db/_search { "query": { "term": { "address": { "value": "广州白云山公园" } } } } # 可以查到数据 通过keyword 映射到address字段不进行分词 # 相当于mapping中的address的类型是keyword GET /es_db/_search { "query":{ "term": { "address.keyword": { "value": "广州白云山公园" } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在ES中,Term查询,对输入不做分词。会将输入作为一个整体,在倒排索引中查找准确的词项,并且使用相关度算分公式为每个包含该词项的文档进行相关度算分。
PUT /product/_bulk {"index":{"_id":1}} {"productId":"xxx123","productName":"iPhone"} {"index":{"_id":2}} {"productId":"xxx111","productName":"iPad"} # 思考: 查询iPhone可以查到数据吗? GET /product/_search { "query":{ "term": { "productName": { "value": "iPhone" } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
对于英文分词会将大写转成小写,可以考虑建立索引时忽略大小写
PUT /product { "settings": { "analysis": { "normalizer": { "aaa": { "filter": [ "lowercase", "asciifolding" ], "type": "custom" } } } }, "mappings": { "properties": { "productId": { "type": "text" }, "productName": { "type": "keyword", "normalizer": "aaa", "index": "true" } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
可以通过 Constant Score 将查询转换成一个 Filtering,避免算分,并利用缓存,提高性能。
- 将Query 转成 Filter,忽略TF-IDF计算,避免相关性算分的开销
- Filter可以有效利用缓存
GET es_db/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"address.keyword": "广州白云山公园"
}
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
ES中的结构化搜索
结构化搜索(Structured search)是指对结构化数据的搜索。
结构化数据:
- 日期,布尔类型和数字都是结构化的
- 文本也可以是结构化的。
如彩色笔可以有离散的颜色集合:红(red) 、绿(green、蓝(blue)
一个博客可能被标记了标签,例如,分布式(distributed)和搜索(search)
电商网站上的商品都有UPC(通用产品码Universal Product Code)或其他的唯一标识,它们都需要遵从严格规定的、结构化的格式。
应用场景:对bool,日期,数字,结构化的文本可以利用term做精确匹配
GET /es_db/_search { "query": { "term": { "age": { "value": 28 } } } } POST /employee/_bulk {"index":{"_id":1}} {"name":"小明","interest":["跑步","篮球"]} {"index":{"_id":2}} {"name":"小红","interest":["跳舞","画画"]} {"index":{"_id":3}} {"name":"小丽","interest":["跳舞","唱歌","跑步"]} #term处理多值字段,term查询是包含,不是等于 POST /employee/_search { "query": { "term": { "interest.keyword": { "value": "跑步" } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
前缀查询prefix和通配符查询
前缀查询
它会对分词后的倒排索引进行前缀搜索。
它不会分析要搜索字符串,传入的前缀就是想要查找的前缀
默认状态下,前缀查询不做相关度分数计算,它只是将所有匹配的文档返回,然后赋予所有相关分数值为1。它的行为更像是一个过滤器而不是查询。两者实际的区别就是过滤器是可以被缓存的,而前缀查询不行。
prefix的原理:需要遍历所有倒排索引,并比较每个term是否已所指定的前缀开头。
GET /es_db/_search
{
"query": {
"prefix": {
"address": {
"value": "广州"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
通配符查询
工作原理和prefix相同,只不过它不是只比较开头,它能支持更为复杂的匹配模式。
GET /es_db/_search
{
"query": {
"wildcard": {
"address": {
"value": "*白*"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
范围查询
range:范围关键字
gte 大于等于
lte 小于等于
gt 大于
lt 小于
now 当前时间
POST /es_db/_search { "query": { "range": { "age": { "gte": 25, "lte": 28 } } } } #=========时间范围查询========== DELETE /product POST /product/_bulk {"index":{"_id":1}} {"price":100,"date":"2021-01-01","productId":"XHDK-1293"} {"index":{"_id":2}} {"price":200,"date":"2022-01-01","productId":"KDKE-5421"} GET /product/_search { "query": { "range": { "date": { "gte": "now-2y" } } } } #多id查询 GET /es_db/_search { "query": { "ids": { "values": [1,2] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
模糊查询fuzzy
在实际的搜索中,我们有时候会打错字,从而导致搜索不到。在Elasticsearch中,我们可以使用fuzziness属性来进行模糊查询,从而达到搜索有错别字的情形。
fuzzy 查询会用到两个很重要的参数,fuzziness,prefix_length
fuzziness:表示输入的关键字通过几次操作可以转变成为ES库里面的对应field的字段
操作是指:新增一个字符,删除一个字符,修改一个字符,每次操作可以记做编辑距离为1,如中文集团到中威集团编辑距离就是1,只需要修改一个字符;该参数默认值为0,即不开启模糊查询。
如果fuzziness值在这里设置成2,会把编辑距离为2的东东集团也查出来。
prefix_length:表示限制输入关键字和ES对应查询field的内容开头的第n个字符必须完全匹配,不允许错别字匹配
如这里等于1,则表示开头的字必须匹配,不匹配则不返回
默认值也是0
加大prefix_length的值可以提高效率和准确率。
GET /es_db/_search { "query": { "fuzzy": { "address": { "value": "白运山", "fuzziness": 1 } } } } GET /es_db/_search { "query": { "match": { "address": { "query": "广洲", "fuzziness": 1 } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
注意: fuzzy 模糊查询 最大模糊错误 必须在0-2之间
搜索关键词长度为 2,不允许存在模糊
搜索关键词长度为3-5,允许1次模糊
搜索关键词长度大于5,允许最大2次模糊
高亮highlight
highlight 关键字: 可以让符合条件的文档中的关键词高亮。
highlight相关属性:
pre_tags 前缀标签
post_tags 后缀标签
tags_schema 设置为styled可以使用内置高亮样式
require_field_match 多字段高亮需要设置为false
示例数据
#指定ik分词器 PUT /products { "settings" : { "index" : { "analysis.analyzer.default.type": "ik_max_word" } } } PUT /products/_doc/1 { "proId" : "2", "name" : "牛仔男外套", "desc" : "牛仔外套男装春季衣服男春装夹克修身休闲男生潮牌工装潮流头号青年春秋棒球服男 7705浅蓝常规 XL", "timestamp" : 1576313264451, "createTime" : "2019-12-13 12:56:56" } PUT /products/_doc/2 { "proId" : "6", "name" : "HLA海澜之家牛仔裤男", "desc" : "HLA海澜之家牛仔裤男2019时尚有型舒适HKNAD3E109A 牛仔蓝(A9)175/82A(32)", "timestamp" : 1576314265571, "createTime" : "2019-12-18 15:56:56" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
测试
GET /products/_search
{
"query": {
"term": {
"name": {
"value": "牛仔"
}
}
},
"highlight": {
"fields": {
"*":{}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
自定义高亮html标签
可以在highlight中使用pre_tags和post_tags
GET /products/_search { "query": { "term": { "name": { "value": "牛仔" } } }, "highlight": { "post_tags": ["</span>"], "pre_tags": ["<span style='color:red'>"], "fields": { "*":{} } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
多字段高亮
GET /products/_search { "query": { "term": { "name": { "value": "牛仔" } } }, "highlight": { "pre_tags": ["<font color='red'>"], "post_tags": ["<font/>"], "require_field_match": "false", "fields": { "name": {}, "desc": {} } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

