
- 1python 数据归一化_python 实现对数据集的归一化的方法(0-1之间)
- 2Android中转义字符_android转义字符表
- 3【图文】2024年腾讯云Palworld/幻兽帕鲁服务器超详细搭建教程
- 4阿里云服务器租用费用_2023价格表_阿里云服务器一般多少钱一年
- 5Python--Matplotlib(简单绘图和用法)_import matplotlib.pyplot as plt df.plot(kind = 'sc
- 6Dubbo+Zookeeper架构—持续集成篇10—Jenkins自动化部署:Jenkins的安装配置使用_doubbo + zookeeper + jenkins
- 7Python之并发请求 (干货)_python并发请求
- 8Linux内核定时器_linux mod_timer
- 9AGPL-3.0翻译版本_agpl-3.0 license
- 10python中base64 decode_python中base64模块的加解密函数
让AI“读懂”短视频,爱奇艺内容标签技术解析_爱奇艺开源视频分类算法
赞
踩
前言
随着短视频的兴起,每天有大量的短视频被生产并上传到各大视频平台,面对海量的短视频,如何提升这些短视频的智能分发效率是各大短视频平台面临的重要课题。
视频的标签技术是内容理解的一种重要手段,已经在业界被广泛应用于推荐系统的各个环节:用户画像、召回、排序等。标签一般分为“类型标签”和“内容标签”两大类别,类型标签是对短视频内容进行层次分类,分类体系是预先定义好的;而内容标签是根据不同的短视频内容生成的不同的关键词或短语,用来表征短视频的内容,它是一个开放的集合。本文将详细介绍爱奇艺在短视频场景中内容标签技术。
内容标签技术难点
短视频一般由短视频文本标题、封面图、视频内容等元素组成,要想较准确的抽取出内容标签,需要综合利用这些多模态信息。如何将这些不同模态的信息融合起来应用于模型中并取得较好的结果是需要较多的探索;又因为内容标签是一个开放集合,如何判断哪些词语可以作为内容标签也是比较困难的。在实际人工标注过程中发现,两个人同时标注同一批数据,标注的完全一致率只有22.1%,以下是一些标注例子:

最后,大量的内容标签并没有在文本标题中出现,我们称这种标签为“抽象标签”,如短视频标题:“母亲染病雪上加霜,女儿自强渴望工作”,其内容标签为:“励志”、“正能量”。根据我们的统计,有40%以上的标签为抽象标签。
内容标签算法迭代之路
爱奇艺的内容标签模型的演变经过了文本模型、融合封面图模型、融合BERT向量模型和进一步融合视频帧模型四个阶段之后,形成了最终的解决方案。下面分别对这四个阶段进行介绍:
(一)
文本模型
文本模型仅仅使用短视频标题等文本信息生成标签。最初使用的是候选生成+排序算法框架,候选标签主要由以下部分组成:
· 通过CRF模型提取的候选标签;
· 通过联想得到的候选标签,联想规则由人工定义,主要包括:
· 同义词、别名联想。如:kof->拳皇, 魔都->上海, 颖宝->赵丽颖;
· 实体联想。如:康熙来了->蔡康永/小s, 露娜->王者荣耀, 章泽天->刘强东;
· 上位概念的联想。如:alphago->围棋, 侧翻->车祸/事故, 戚风→甜品。
· 没有在文中出现的高频标签,通常为准类型标签, 如”街头采访/观看反应/励志”等。
排序模型使用基于注意力机制的语义相似度模型[1] [2] [3],通过注意力机制生成短视频标题的向量表示,然后和候选标签向量做语义相似度计算,再通过划定阈值选取合适的标签。模型架构如下:

该模型结构简单,在对文章的建模上有比较好的效果。但在短视频标题上却有如下缺点:一是这一模型在抽象类的标签上的效果不是很好,通过人工定义的联想规则只能生成一小部分抽象标签;二是由于标题一般都比较短,注意力模型结构过于简单,无法进行准确的语义建模。
“候选生成+排序”的结构本质上是一种抽取式的标签生成方式,即生成的标签主要是在标题中出现的词或短语。相比抽取式,通过端到端训练的生成模型具有比较好的语义抽象能力,其生成出来的标签不需要出现在原文。2017年Google提出Transformer模型,其强大的特征提取能力和并行化带来训练速度的提升,使其在多项文本生成任务中达到了SOTA的效果,其模型结构如图所示。

我们最终使用基于Transformer的生成式+抽取式结合的方式来对文本标题进行建模,即先使用生成式来生成标签,如果没有结果则使用抽取式的结果。我们对抽取式模型做了如下改进:使用self-attention取代attention机制,增强文本表征能力;增加候选标签的上下文特征和文本的频道等特征,模型结构如下:

文本模型通过分析视频的标题和描述等文本信息,生成内容标签。但是对于UGC,经常存在文本信息缺失,不充分等情况,比如:
a) 标题为“分享视频”,则文本模型会生成空标签;
b) 标题为“天地山青,道法无常,李白斗酒诗百篇”,会生成“唐诗”、“李白”这样的标签。但是从封面图看,该视频其实为王者荣耀游戏:

为了弥补文本模型的缺点,我们引入了封面图来弥补标题文本的语义信息缺失的问题,所以需要对封面图进行表征,并加入到生成模型中。
(二)
融合封面图模型
1、图像特征提取
对于图像的表征,业界常见的做法是使用预训练的ImageNet在新的任务新的标注数据上进行Fine-Tune,然后抽取某几层或最后一层作为图像的表征。我们通过实验比较ResNet50、Inception V3、Xception等模型的效果,Xception在我们的数据上能达到最优的结果,模型结构如下:
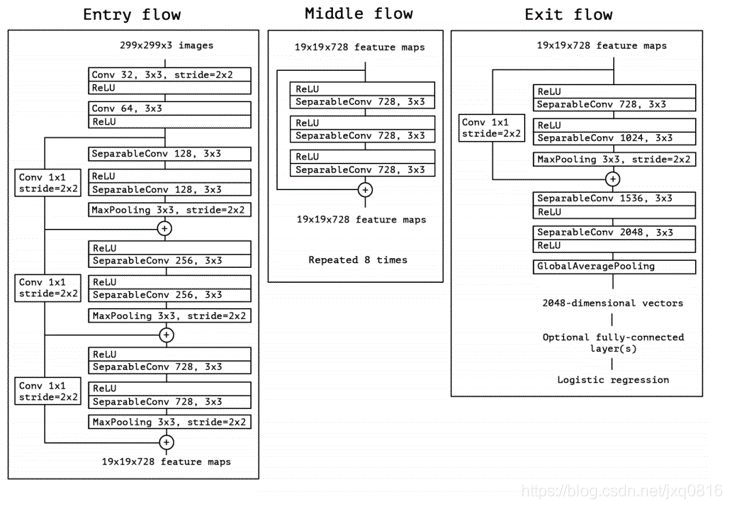
我们使用Xception对封面图进行特征提取,具体流程为:
a) 选取高频抽象标签作为图像分类标签;
b) 分类标签对应的封面图作为该图像的目标标签并构建图像分类模型;
c) 使用ImageNet训练得到的参数作为模型的预训练参数,并使用该分类模型进行Fine-tuning;
d) 提取中间层向量作为封面图向量的表达。
2、图像特征融合
通过实验发现,如下方式[4]将封面图向量融合到Transformer模型后效果更好:
a) 图像特征添加到Encoder的输入;
b) 图像特征添加到Encoder的输出;
c) 图像特征添加到Decoder的初始输入。
三种融合方式经过独立的Feed-Forward Neural Network分别映射到各个空间,模型的结构如下:

(三)
融合BERT向量模型
由于多模态模型的文本部分主要采用站内的短视频标题进行训练,训练集偏向于影视剧/娱乐领域,因此这会导致模型对于通用领域的文本语义理解有所欠缺,比如当模型对标题为“容易被男生吃定的8种类型的女生” 的内容进行分析时, 模型根据站内的数据训练得出结果为“女生”,然而更合适的标签应该为“恋爱技巧”,因此我们希望预训练模型可以解决这种问题。为此我们引入了目前表现最好的预训练模型 BERT。BERT是基于Transformer的深度双向语言表征模型,基本结构如下图所示,其本质上是利用Transformer结构构造了一个多层双向的Encoder网络。

针对不同的任务,BERT模型的输入可以是单句或者句对。对于每一个输入的Token,它的表征由其对应的词表征(Token Embedding)、段表征(Segment Embedding)和位置表征(Position Embedding)相加产生,如下图所示:

BERT 是在海量通用文本语料上训练的语言模型,已被验证具有非常强的语义归纳能力。我们将BERT sentence embedding集成到现有的模型中,以期增强其对通用领域文本的理解能力, 融合方式为:
a) 将文本经过BERT模型抽取语义特征(second-to-last层经过average pooling后的向量);
b) 原始BERT特征经过非线性映射后,分别加入到模型的encoder输入、输出和decoder的初始输入中。
模型结构如下:
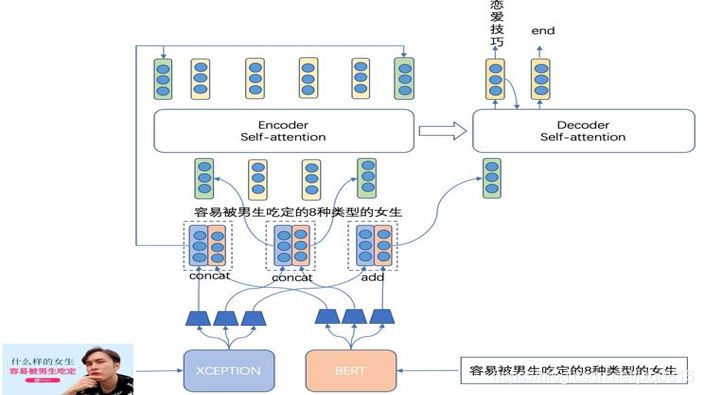
(四)
融合视频帧模型
目前为止,我们已经使用了视频的标题,描述等文本和封面图等信息来生成内容标签。但是对于一些剧情描述类的剧或者综艺等,这些信息还不够充分,比如:
a) 标题为“此‘八卦’非彼‘八卦’,看完视频后觉得,脑子是个好东西!”, 通过分析文本和封面图等信息,会打上“八卦” 标签,而视频内容为“陈翔六点半”;
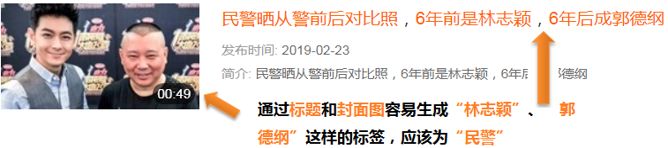
b) 标题为“民警晒从警前后对比照,6年前是林志颖,6年后成郭德纲”,通过分析文本和封面图等信息,会打上“林志颖”、“郭德纲”标签,而合适的标签应该为“民警”。
为了弥补文本和封面图信息的不足,我们在多模态模型中引入了视频帧等信息,引入后模型的总体结构为:

1、特征提取
a) 对每个视频抽取若干个关键帧(信息最丰富的视频帧);
b) 对每个视频帧通过Xception模型提取特征,形成视频帧向量矩阵。
2、特征融合
Encoder端,将文本特征、文本BERT特征、封面图特征、视频帧特征concatenate,然后经过self-attention进行Early Fusion;将文本特征、视频特征,通过交叉query, key, value, 经过cross-attention进行 Deep Fusion[5],其结构如下图所示:
Decoder端,使用EnhancedMulti-Head Self-Attention对 early fusion和deep fusion的编码特征以及视频帧特征进行融合[6],其结构如图所示:

内容标签的应用
短视频内容标签在爱奇艺得到了广泛的使用,典型的应用场景为:短视频的生产、个性化推荐及视频搜索方面,具体如下:
在短视频生产方面,算法生成的高精度内容标签可以替换人工标注,从而节省人力成本,提高内容标签生产效率。目前有60%以上的内容标签的精度达到了90%以上,并且这部分精度高的内容标签已可以代替人工标注;另外,可以通过分析标签的消费情况来指导生产,从而优先生产高质量短视频内容,提升生产流程的利用率。
在个性化推荐方面,内容标签是细粒度用户兴趣标签的最重要来源,通过内容标签也可以做基于内容理解的召回,召回的结果可解释性更强,也具有一定的泛化能力,在排序环节加入用户的兴趣标签和短视频标签的相似性特征可以进一步提升推荐的准确度。
在搜索方面,通过计算内容标签中的抽象标签和query的相似度可以改善语义相关性的效果,通过用户行为构建的query到内容标签的映射可以用来做query的扩展,内容标签也可以用来进行长query的去词、query中心词识别、query中的term紧密度计算等工作。
思考与展望
短视频内容标签技术还有很多优化的空间,未来的优化工作主要从提升标注的质量、融合更多的信息、以及尝试最新的模型和不同的模型结构等方面展开,希望能够进一步提升模型的精度以及在最新短视频上的效果:
1、融合短视频标题文本中的实体、实体关系等先验知识到模型中,提升模型泛化能力;
2、融合更多的视频内容,如增加视频帧、OCR信息、视频人物等以及音频等信息到模型中进一步提升模型的效果。
参考文献
[1]Zhou, P., Shi, W., Tian, J., Qi, Z., Li, B.:Attention-based bidirectional long short-term memory networks for relationclassification. In ACL,2016
[2]Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, AlexSmola, and Eduard Hovy. Hierarchical attention networks for documentclassification. In NAACL-HLT, 2016.
[3]Das, A., Yenala, H., Chinnakotla, M., Shrivastava, M.:Together we stand: Siamese networks for similar question retrieval. In ACL,2016
[4]Iacer Calixto, Qun Liu, and NickCampbell. 2017b. Incorporating Global Visual Features into Attention-BasedNeural Machine Translation. In Proceedings of the 2017 Conference on EmpiricalMethods in Natural Language Processing.
[5] JiasenLu, DhruvBatra, Devi Parikh, StefanLee. ViLBERT: Pretraining Task-Agnostic VisiolinguisticRepresentations for Vision-and-Language Tasks.Neural Information ProcessingSystems (NeurIPS), 2019
[6] Arslan HS, Fishel M, Anbarjafari G(2018) Doubly attentive transformer machine translation. Computing ResearchRepository arXiv:1807.11605

