
- 1图解基于AQS队列实现的CountDownLatch和CyclicBarrier_countdownlatch和cyclicbarrier是基于aqs组件
- 2麻雀搜索算法(SSA)优化BP神经网络做预测,matlab程序,预测精度比普通的BP大幅提升
- 3 书籍:掌握Python的网络和安全 PySpark SQL Recipes_ With HiveQL, Dataframe and ...
- 4算法导论_15.3 动态规划基础_最优解的值和最优解的区别
- 5沉睡者IT - 为你解密那些卖虚拟资源和知识付费课程的平台到底有多简单和多赚钱。_虚拟资源平台
- 6C语言 AF_UNIX tcp/udp socket实例_udp af unix
- 7智胜未来,新时代IT技术人风口攻略-第七版(弃稿)
- 8行人重识别系统概述
- 9cross_entropy_error(y, t)和accuracy_function(y, t)对于正确解(数组版)的应用_accuracy function
- 10Shader基础的简单实现(基于URP渲染)_urp 基础shader
easyExcel 与 POI 基础知识_easyexcel对应poi版本
赞
踩
POI 与 easyExcel
一、 了解
开发中经常会涉及到Excel的处理,如导出Excel,导入Excel到数据库中
引用场景:
将用户信息导出为Excel表格
将Excel表中的信息录入到网站数据库(习题上传…),大大减轻网站录入量。(大概意思就是将内容写在表格中,然后通过表格一次性的录入数据库,不用一个一个的在网页的表格中输入)
目前最流行的就是 **Apache POI **和阿里巴巴的 easyExcel
1.1 Apache POI
比较麻烦
官网: https://poi.apache.org/
开放源码函式库,提供API给Java程序对Microsoft Office格式档案读和写的功能。
结构:
HSSF 提供读写MicrosoftExcel各式档案的功能。(03 版Excel,最多65535行)
XSSF 提供读写MicrosoftExcel OOXML各式档案的功能。(07 版Excel,没有限制多少行)
HWPF 提供读写MicrosofttWord各式档案的功能。(Word)
HSLF 提供读写MicrosofPowerPoint林式档案的功能(幻灯片)
HDGF 提供读写Microsoft Visio式档案的功能。
1.2 easyExcel
easyExcel 官网地址 : https://github.com/alibaba/easyexcel
Apache POI 比较消耗内存,对于easyExcel,不管数据量多发都不会出现内存溢出。
内存问题:
对于POI, POI=100w 即100w条数据先加载到内存,此时内存就会溢出
对于EasyExcel,会一行一行的写,本质就是时间和空间的转换
在帮助文档中“关于EasyExcel”中,文件解压文件读取通过文件形式
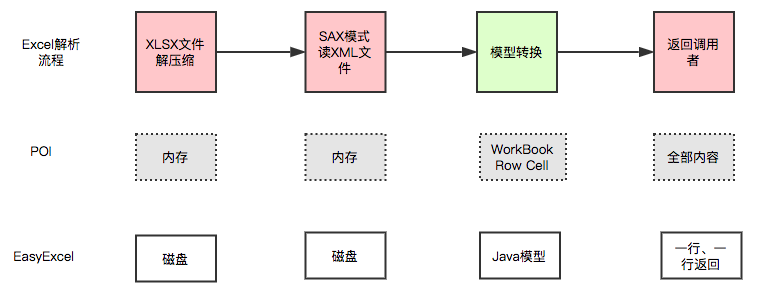
二、 准备工作
2.1 Maven坐标
<!--xls(03版)--> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.9</version> </dependency> <!--xls(07版)--> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.9</version> </dependency> <!--日期格式化工具--> <dependency> <groupId>joda-time</groupId> <artifactId>joda-time</artifactId> <version>2.10.1</version> </dependency>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.2 Excel讲解
03版本与07版本的区别:
① 首先是文件结尾不同,03版本Excel文件结尾是".xls",07版本Excel文件结尾是".xlsx"
②03版本最多65536行数据,而07版本的数据量没有限制,理论是无线的
③03版本与07版本对应的工具类不同,在我们上面的左面就看出来了
03版本与07版本的相同处:
工作簿、工作表、行、列。一会也是按照这个操作进行读和写。
三、 Excel基本写操作(导出Excel)
**创建工作簿对象:**其中org.apache.poi.ss.usermodel.Workbook是一个接口,有三个实现类,分别是HSSFWorkbook(Excel 03 版本)、SXSSFWorkbook(可以加快速度的处理07版本Excel)、XSSFWorkbook(Excel 07 版本,处理速度会慢一点)
3.1 03 版本Excel导出操作
@SpringBootTest class EasyExcelApplicationTests { // 路径 String PATH = "D:/"; @Test void contextLoads() { // TODO 创建一个工作薄 Workbook workbook = new HSSFWorkbook(); // 03版本Excel // TODO 创建一个工作表 工作表就是打开Excel表下面的sheet1、sheet2、sheet3 Sheet sheet = workbook.createSheet("张靖奇测试表1"); // TODO 创建第一行 Row row1 = sheet.createRow(0); //第一行 // TODO 创建一个单元格(在二维坐标里面我们叫做[0,0]或者叫做[1,1],也就是第一行的第一个单元格,即第一行第一列交叉处) // [1,1] Cell cell11 = row1.createCell(0); cell11.setCellValue("今日新增观众"); // [1,2] Cell cell12 = row1.createCell(1); cell12.setCellValue("666"); // TODO 创建第二行 Row row2 = sheet.createRow(1); // [2,1] Cell cell21 = row2.createCell(0); cell21.setCellValue("统计时间"); Cell cell22 = row2.createCell(1); String time = new DateTime().toString("yyyy-MM-dd HH:mm:ss"); cell22.setCellValue(time); // TODO IO 流生成一张表 FileOutputStream fileOutputStream =null; try { fileOutputStream = new FileOutputStream(PATH + "张靖奇测试"+".xls");//注意是03版本结尾 // TODO 写出 workbook.write(fileOutputStream); } catch (IOException e) { e.printStackTrace(); } finally { // TODO 关闭流 if (fileOutputStream!=null){ try { fileOutputStream.close(); } catch (IOException e) { e.printStackTrace(); } } } System.out.println("Excel表导出完毕!"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
3.2 07版本Excel导出操作
下面的实现,Workbook接口的实现类是XSSFWorkbook,IO流输出的文件的名称结尾是".xlsx",除此之外其他的基本相同。
@Test void contextLoads07() { // TODO 创建一个工作薄 Workbook workbook = new XSSFWorkbook(); // 07版本Excel // TODO 创建一个工作表 工作表就是打开Excel表下面的sheet1、sheet2、sheet3 Sheet sheet = workbook.createSheet("张靖奇测试表1"); // TODO 创建第一行 Row row1 = sheet.createRow(0); //第一行 // TODO 创建一个单元格(在二维坐标里面我们叫做[0,0]或者叫做[1,1],也就是第一行的第一个单元格,即第一行第一列交叉处) // [1,1] Cell cell11 = row1.createCell(0); cell11.setCellValue("今日新增观众"); // [1,2] Cell cell12 = row1.createCell(1); cell12.setCellValue("666"); // TODO 创建第二行 Row row2 = sheet.createRow(1); // [2,1] Cell cell21 = row2.createCell(0); cell21.setCellValue("统计时间"); Cell cell22 = row2.createCell(1); String time = new DateTime().toString("yyyy-MM-dd HH:mm:ss"); cell22.setCellValue(time); // TODO IO 流生成一张表 FileOutputStream fileOutputStream =null; try { fileOutputStream = new FileOutputStream(PATH + "张靖奇测试"+".xlsx");//注意是07版本结尾 // TODO 写出 workbook.write(fileOutputStream); } catch (IOException e) { e.printStackTrace(); } finally { // TODO 关闭流 if (fileOutputStream!=null){ try { fileOutputStream.close(); } catch (IOException e) { e.printStackTrace(); } } } System.out.println("Excel表导出完毕!"); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
3.3 大数据量的导出(数据批量导入到磁盘)
大文件写HSSF:
缺点: 最多只能处理65536行,超出则抛异常
优点: 过程中写入缓存,不操作磁盘,最后一次性写入磁盘
大文件写XSSF:
缺点: 写数据速度非常慢,非常消耗内存,也会发生内存溢出,如100万条
优点:可以写较大的数据量,如20万条
大文件写SXSSF:
优点: 可以写入非常大的数据量,如100万条甚至更多条,写数据速度快,占用更少的内存
注意:
过程中会产生临时文件,需要清理临时文件
默认100条记录被保存在内存中,如果超过这个数量,则最前面的数据被写入临时文件
如果想自定义内存中数据的数量,可以使用 new SXSSFWorkbook(数量)
**SXSSFWorkbook-来至官方的解释:**实现"BigGridDemo"策略的流式XSSFWorkbook版本。这允许写入非常大的文件而不会耗尽内存,因为任何时候只有可配置的行部分被保存在内存中。
请注意,仍然可能会消耗大量内存,这些内存基于您正在使用的功能,例如合并区域,注释…仍然只存储在内存中,因此如果广泛使用,可能需要大量内存。
@Test void testWrite07BigDataSupper() throws IOException { // TODO 创建一个簿 Workbook workbook = new SXSSFWorkbook(); // TODO 创建表 Sheet sheet = workbook.createSheet(); // TODO 写入数据 for (int rowNum =0; rowNum<100000; rowNum++){ // TODO 行 Row row = sheet.createRow(rowNum); for (int cellNum=0;cellNum<10;cellNum++){ Cell cell = row.createCell(cellNum); cell.setCellValue(cellNum); } } // TODO 导出Excel FileOutputStream outputStream = new FileOutputStream(PATH+"超大数据测试"+".xlsx"); workbook.write(outputStream); // TODO 清理临时文件,因为SXSSFWorkbook写出时会生成临时文件,但是占用内存不是很大 ((SXSSFWorkbook) workbook).dispose(); outputStream.close(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
四、Excel基本读取及注意
4.1 03版本Excel文件读取
@Test void testRead03() throws IOException { // TODO 获取文件流,读取工作簿 FileInputStream fileInputStream = new FileInputStream("D:/明细表.xls"); // TODO 创建一个工作薄.Excel能操作的,此工作簿对象都能操作 Workbook workbook = new HSSFWorkbook(fileInputStream); // 03版本Excel // TODO 得到表 Sheet sheet = workbook.getSheetAt(0);//可以通过名字获取表,也可以通过下标,下面这个形式就是通过下标 // TODO 取出行 Row row = sheet.getRow(1); // // TODO 取出列 读取值的时候一定要注意类型 // 字符串类型数据 // Cell cell = row.getCell(0); // System.out.println(cell.getStringCellValue()); // 数字类型数据 Cell cell = row.getCell(0); System.out.println(cell.getNumericCellValue()); // TODO 关闭流 fileInputStream.close(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
4.2 07版本Excel文件读取
文件名后缀不同,Workbook实现类不同
@Test void testRead07() throws IOException { // TODO 获取文件流,读取工作簿 FileInputStream fileInputStream = new FileInputStream("D:/明细表.xlsx"); // TODO 创建一个工作薄.Excel能操作的,此工作簿对象都能操作 Workbook workbook = new XSSFWorkbook(fileInputStream); // 07版本Excel // TODO 得到表 Sheet sheet = workbook.getSheetAt(0);//可以通过名字获取表,也可以通过下标,下面这个形式就是通过下标 // TODO 取出行 Row row = sheet.getRow(1); // // TODO 取出列 读取值的时候一定要注意类型 // 字符串类型数据 // Cell cell = row.getCell(0); // System.out.println(cell.getStringCellValue()); // 数字类型数据 Cell cell = row.getCell(0); System.out.println(cell.getNumericCellValue()); // TODO 关闭流 fileInputStream.close(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
4.3 难点 — 读取不同类型的数据
@Test void testRead() throws IOException { // TODO 获取文件流,读取工作簿 FileInputStream fileInputStream = new FileInputStream("D:/明细表.xls"); // TODO 创建一个工作薄.Excel能操作的,此工作簿对象都能操作 Workbook workbook = new HSSFWorkbook(fileInputStream); // 03版本Excel // TODO 获取哪个页面 Sheet sheet = workbook.getSheetAt(0); // TODO 获取标题内容 Row rowTitle = sheet.getRow(0); if (rowTitle != null) { int cellCount = rowTitle.getPhysicalNumberOfCells(); //表示这一行有多少个数据 // TODO 每个遍历每个单元格 for (int cellNum = 0; cellNum < cellCount; cellNum++) { Cell cell = rowTitle.getCell(cellNum); if (cell != null) { int cellType = cell.getCellType(); // 获取类型,方便下面判断 String cellValue = cell.getStringCellValue(); System.out.print(cellValue + "|"); //卡号|持卡人|手机号|消费日期|小票号|商品编号|商品条码|商品名称|商品单位|原价|销售价|销售数量|销售金额|优惠金额|是否上架| } } System.out.println(); } // TODO 获取表中的内容 int rowCount = sheet.getPhysicalNumberOfRows(); // 获取行的数量 for (int rowNum = 1; rowNum < rowCount; rowNum++) { //第一行是标题,我们已经提取过了 // TODO 读取行 Row rowData = sheet.getRow(rowNum); if (rowData != null) { // TODO 读取列 int cellCount = rowTitle.getPhysicalNumberOfCells(); //表示这一行有多少个数据 // TODO 遍历每列单元格 for (int cellNum = 0; cellNum < cellCount; cellNum++) { System.out.print("[" + (rowNum + 1) + "-" + (cellNum + 1) + "]"); Cell cell = rowData.getCell(cellNum); // TODO 匹配数据类型(就是这个地方麻烦) if (cell == null){ continue; } int cellType = cell.getCellType(); String cellValue = null; switch (cellType) { // 1 字符串 case HSSFCell.CELL_TYPE_STRING: System.out.print("[String]"); cellValue = cell.getStringCellValue(); break; // 4 布尔 case HSSFCell.CELL_TYPE_BOOLEAN: System.out.print("[BOOLEAN]"); cellValue = String.valueOf(cell.getBooleanCellValue()); break; // 3 空 case HSSFCell.CELL_TYPE_BLANK: System.out.print("[BLANK]"); break; // 0 数字(日期、普通数字) case HSSFCell.CELL_TYPE_NUMERIC: System.out.print("[NUMERIC]"); if (HSSFDateUtil.isCellDateFormatted(cell)) { System.out.print("[日期]"); Date date = cell.getDateCellValue(); cellValue = new DateTime(date).toString(); } else { // 为什么转换成字符串? // 不是日期格式,防止数字过长! System.out.print("[数字 -转换为字符串输出 ]"); // 这个地方比较特别,需要设置一下类型 转换成字符串 cell.setCellType(HSSFCell.CELL_TYPE_STRING); cellValue = cell.toString(); } break; // 5 错误 case HSSFCell.CELL_TYPE_ERROR: System.out.print("[ERROR - 数据类型错误]"); break; } System.out.println(cellValue); } System.out.println(); } } // TODO 关闭流 fileInputStream.close(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
五、 计算公式 - 了解
前提是知道哪个单元格是需要计算公式的
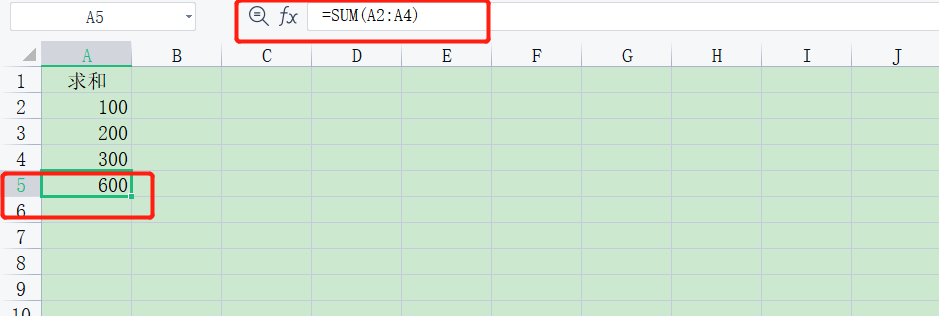
@Test void sum() throws IOException { // TODO 获取文件流,读取工作簿 FileInputStream fileInputStream = new FileInputStream("D:/公式.xls"); // TODO 创建一个工作薄.Excel能操作的,此工作簿对象都能操作 Workbook workbook = new HSSFWorkbook(fileInputStream); // 03版本Excel // TODO 获取表 Sheet sheet = workbook.getSheetAt(0); // TODO 获取行 Row row = sheet.getRow(4); // TODO 获取列 - 单元格 Cell cell = row.getCell(0); // TODO 拿到计算公式 eval HSSFFormulaEvaluator hssfFormulaEvaluator = new HSSFFormulaEvaluator((HSSFWorkbook) workbook); // TODO 输出单元格的内容 // 判断类型 int cellType = cell.getCellType(); // 如果cell单元格和计算公式无关,就不会执行下面的代码,也不会报错 switch (cellType){ // 2 公式 case Cell.CELL_TYPE_FORMULA: String cellFormula = cell.getCellFormula(); System.out.println(cellFormula); //SUM(A2:A4) // TODO 计算 CellValue evaluate = hssfFormulaEvaluator.evaluate(cell); System.out.println(evaluate); //org.apache.poi.ss.usermodel.CellValue [600.0] String format = evaluate.formatAsString(); System.out.println(format); // 600.0 break; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
六、 EasyExcel 使用
easyExcel 官网地址 : https://github.com/alibaba/easyexcel
详细帮助文档: https://easyexcel.opensource.alibaba.com/docs/current/
6.1 Maven
这个左边下面还连带这POI的坐标,我们需要把之前导入POI相关坐标删除,防止依赖冲突。
<!--easyExcel-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>2.2.0-beta2</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
但是我用上面这个坐标有问题。我用的下面这个
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.2.1</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
6.2 创建标题类
@Data public class DemoData { @ExcelProperty("字符串标题") private String string; @ExcelProperty("日期标题") private Date date; @ExcelProperty("数字标题") private Double doubleData; // 忽略这个字段 @ExcelIgnore private String ignore; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
6.3 导出 - 写出
@Test void simpleWrite() { // TODO 写法1 String fileName ="D:/" +"EasyTest.xlsx"; //生成到这个位置 // 这里 需要指定写用哪个class去读,然后写到第一个sheet,名字为模板 然后文件流会自动关闭 // 如果这里想使用03 则 传入excelType参数即可,这里没有使用03 // doWrite 里面添加写入数据 // write(fileName,格式类), sheet(表名),doWrite(数据) EasyExcel.write(fileName, DemoData.class).sheet("模版").doWrite(data()); // EasyExcel.write(fileName, DemoData.class) // .sheet("模板") // .doWrite(() -> { // // 分页查询数据 // return data(); // }); } private List<DemoData> data() { List<DemoData> list = ListUtils.newArrayList(); for (int i = 0; i < 10; i++) { DemoData data = new DemoData(); data.setString("字符串" + i); data.setDate(new Date()); data.setDoubleData(0.56); list.add(data); } return list; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dn4AjoSv-1683983089272)(D:\project\睿策\picture\image-20230506170553405.png)]
6.4 读取
读取逻辑在监听器的invoke逻辑里面
@Test
void simpleRead() {
String fileName = "D:/" +"EasyTest.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
}
- 1
- 2
- 3
- 4
- 5
- 6
// 有个很重要的点 DemoDataListener 不能被spring管理,要每次读取excel都要new,然后里面用到spring可以构造方法传进去 @Slf4j public class DemoDataListener implements ReadListener<DemoData> { /** * 每隔5条存储数据库,实际使用中可以100条,然后清理list ,方便内存回收 */ private static final int BATCH_COUNT = 100; /** * 缓存的数据 */ private List<DemoData> cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT); /** * 假设这个是一个DAO,当然有业务逻辑这个也可以是一个service。当然如果不用存储这个对象没用。 */ private DemoDAO demoDAO; public DemoDataListener() { // 这里是demo,所以随便new一个。实际使用如果到了spring,请使用下面的有参构造函数 demoDAO = new DemoDAO(); } /** * 如果使用了spring,请使用这个构造方法。每次创建Listener的时候需要把spring管理的类传进来 * * @param demoDAO */ public DemoDataListener(DemoDAO demoDAO) { this.demoDAO = demoDAO; } /** * 这个每一条数据解析都会来调用 * * @param data one row value. Is is same as {@link AnalysisContext#readRowHolder()} * @param context */ @Override public void invoke(DemoData data, AnalysisContext context) { log.info("解析到一条数据:{}", JSON.toJSONString(data)); cachedDataList.add(data); // 达到BATCH_COUNT了,需要去存储一次数据库,防止数据几万条数据在内存,容易OOM if (cachedDataList.size() >= BATCH_COUNT) { saveData(); // 存储完成清理 list cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT); } } /** * 所有数据解析完成了 都会来调用 * * @param context */ @Override public void doAfterAllAnalysed(AnalysisContext context) { // 这里也要保存数据,确保最后遗留的数据也存储到数据库 saveData(); log.info("所有数据解析完成!"); } /** * 加上存储数据库 */ private void saveData() { log.info("{}条数据,开始存储数据库!", cachedDataList.size()); demoDAO.save(cachedDataList); log.info("存储数据库成功!"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
public class DemoDAO { public void save(List<DemoData> list) { // 如果是mybatis,尽量别直接调用多次insert,自己写一个mapper里面新增一个方法batchInsert,所有数据一次性插入 } } ); // 存储完成清理 list cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT); } } /** * 所有数据解析完成了 都会来调用 * * @param context */ @Override public void doAfterAllAnalysed(AnalysisContext context) { // 这里也要保存数据,确保最后遗留的数据也存储到数据库 saveData(); log.info("所有数据解析完成!"); } /** * 加上存储数据库 */ private void saveData() { log.info("{}条数据,开始存储数据库!", cachedDataList.size()); demoDAO.save(cachedDataList); log.info("存储数据库成功!"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
public class DemoDAO {
public void save(List<DemoData> list) {
// 如果是mybatis,尽量别直接调用多次insert,自己写一个mapper里面新增一个方法batchInsert,所有数据一次性插入
}
}
- 1
- 2
- 3
- 4
- 5

