
- 1Spring全面详解(学习总结)_spring详解
- 2js 灰度图转成白色透明图_98fxk9u466
- 3《商业银行信息科技风险管理指引》
- 4Go指针探秘:深入理解内存与安全性
- 5利用Python绘制太阳花_python太阳花代码
- 6想学好Python的话,这6本书带你从入门到精通_python从入门到精通电子书
- 7Dubbo详解,用心看这一篇文章就够了【重点】_dubbo-qos pom
- 8基于Java校园驿站管理系统设计实现(源码+lw+部署文档+讲解等)_基于java的快递驿站管理系统
- 9【华为OD机试真题 JS语言】402、寻找最富裕的小家庭 | 机试真题+思路参考+代码解析(C卷)(本题100%)_js最小富裕家庭
- 10最全最详细的大数据组件介绍_大数据技术组件有哪些
【腾讯云 TDSQL-C Serverless 产品体验】TDSQL-C MySQL Serverless最佳实践_serverless部署mysql
赞
踩
一、引言:
随着云计算技术的不断发展,越来越多的企业开始选择将自己的数据库部署在云上,以更好了的支持企业数字化转型以及业务创新,在这个过程中,很多客户会遇到这样一个问题,业务会存在高峰期和低谷期,同样数据库的访问量也是会存在相应的高峰期和低谷期。
| 序号 | 业务负载 | 业务痛点 |
|---|---|---|
| 1 | 在业务的高峰期 | ①. 客户选择的小规格的数据库服务无法承载业务的高额负载。 ②. 为避免出现数据库服务不可用的情况,需要做临时的规格升配。 ③. 或者在一开始就选择够买大规格的云数据库实例。 |
| 2 | 在业务的低谷期 | ①. 客户又会发现大规格的数据库服务在每天产生高额的账单。 ②. 导致了很多不必要的费用。 |
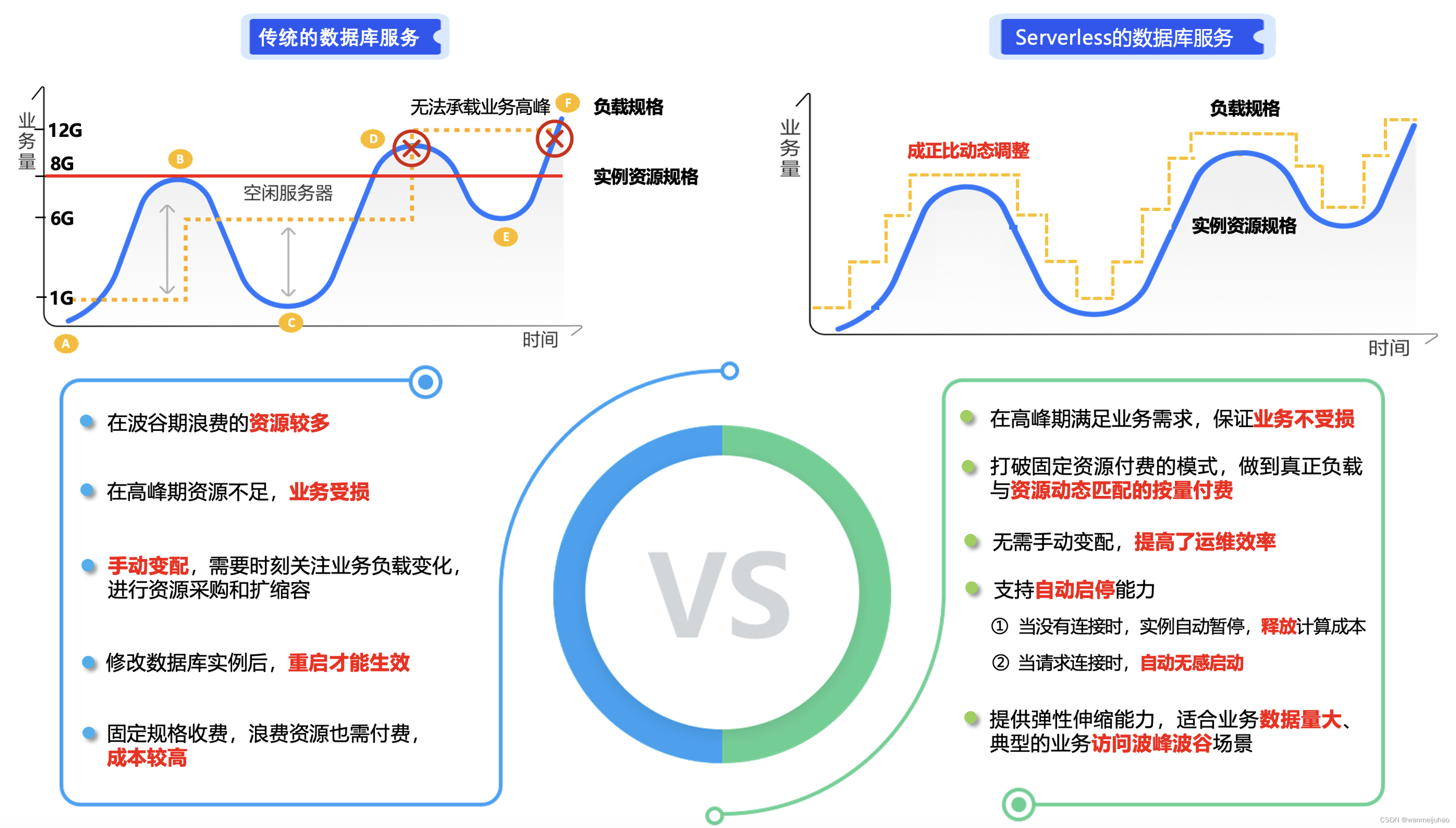
传统的数据库服务并不能很好的解决这个问题,只能依赖反复的人工升降配,即不安全稳定,又会造成额外的IT运维成本以及人力资源成本,因此在客户的强烈的降本增效呼声之中,腾讯云TDSQL-C MySQL Serverless数据库应运而生。

借助《腾讯云TDSQL-C联合CSDN产品测评活动》,让我们来深入了解并实践一下TDSQL-C MySQL Serverless数据库,利用产品的资源用量低、简单易用、弹性灵活和价格低廉等优点和特性,赋能业务合理优化使用成本,创造价值,进一步助力企业降本增效,为国产云数据库点赞,遥遥领先。
二、TDSQL-C MySQL Serverless数据库:
TDSQL-C MySQL Serverless数据库是腾讯云针对中小型企业或个人开发者推出的一款数据库,提供了CPU、内存的实时弹性能力,构建云架构下的数据库产品新形态。
1. 什么是Serverless?
Serverless无服务器架构是基于互联网的系统,其中应用开发不使用常规的服务进程。相反,它们仅依赖于第三方服务(例如腾讯云Serverless Framework服务),客户端逻辑和服务托管远程过程调用的组合。
云计算的发展从IaaS、PaaS、SaaS,到最新的BaaS、FasS,在这个趋势中Serverless(去服务器化)越来越明显,随着容器技术,IoT,5G,区块链等技术的快速发展,技术上对去中心化,轻量虚拟化,细粒度计算等技术需求愈发强烈,未来Serverless将在云计算的舞台上大放异彩。
云计算经历了从 IaaS -> PaaS -> Serverless/FaaS 的发展历程,下面对这些概念做一些基本介绍。
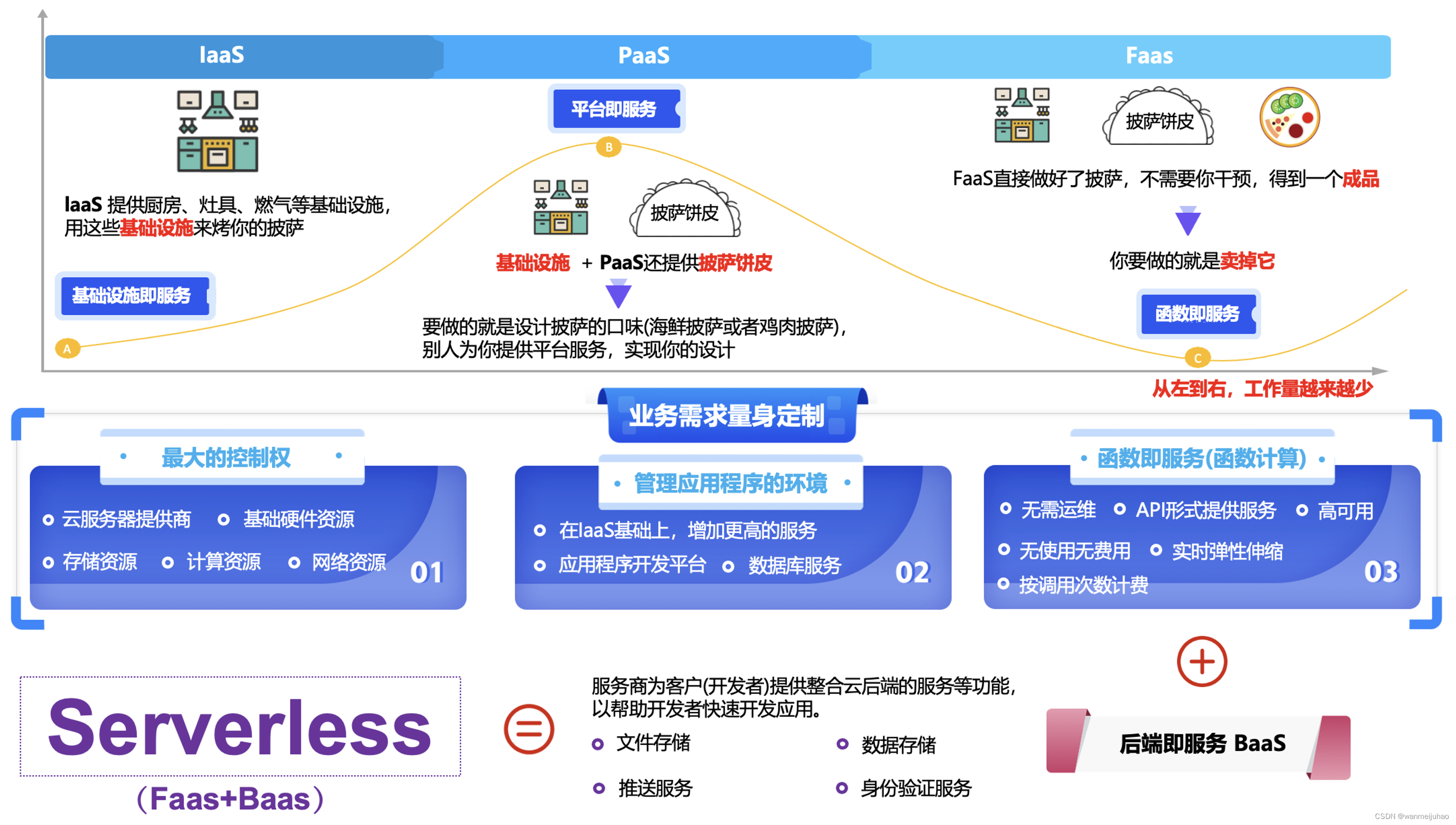
| 序号 | 简称 | 云服务架构中文名称 | 作用 |
|---|---|---|---|
| 1 | IaaS | 服务商提供底层/物理层基础设施资源 | 通过IaaS提供的服务平台购买虚拟资源,选择操作系统,安装软件,部署程序。 |
| 2 | PaaS | 服务商提供基础设施底层服务 | 提供操作系统、数据库服务器、Web服务器、负载均衡器和其他中间件,相对于IaaS客户仅仅需要自己控制上层的应用程序部署与应用托管的环境。 |
| 3 | BaaS | 服务商为客户(开发者)提供整合云后端的服务 | 如提供文件存储、数据存储、推送服务、身份验证服务等功能,以帮助开发者快速开发应用。 |
| 4 | FaaS | 服务商提供一个允许客户开发、运行和管理应用程序功能的平台,而无需构建和维护基础架构 | 按照此模型构建应用程序是实现“无服务器”体系结构的一种方式。 |
总结的说,从IDC → IaaS,用户不用关注真实的物理资源。从IaaS → PaaS,用户不再关注操作系统,数据库,中间件等基础软件。从PaaS → BaaS/FaaS, 用户可以很少甚至不用关注后台。Serverless是云计算发展到一定阶段的必然产物:
- “绿色”计算(最大程度利用资源,减少空闲资源浪费)
- “低门槛”技术(成本低,包括学习成本及使用成本)
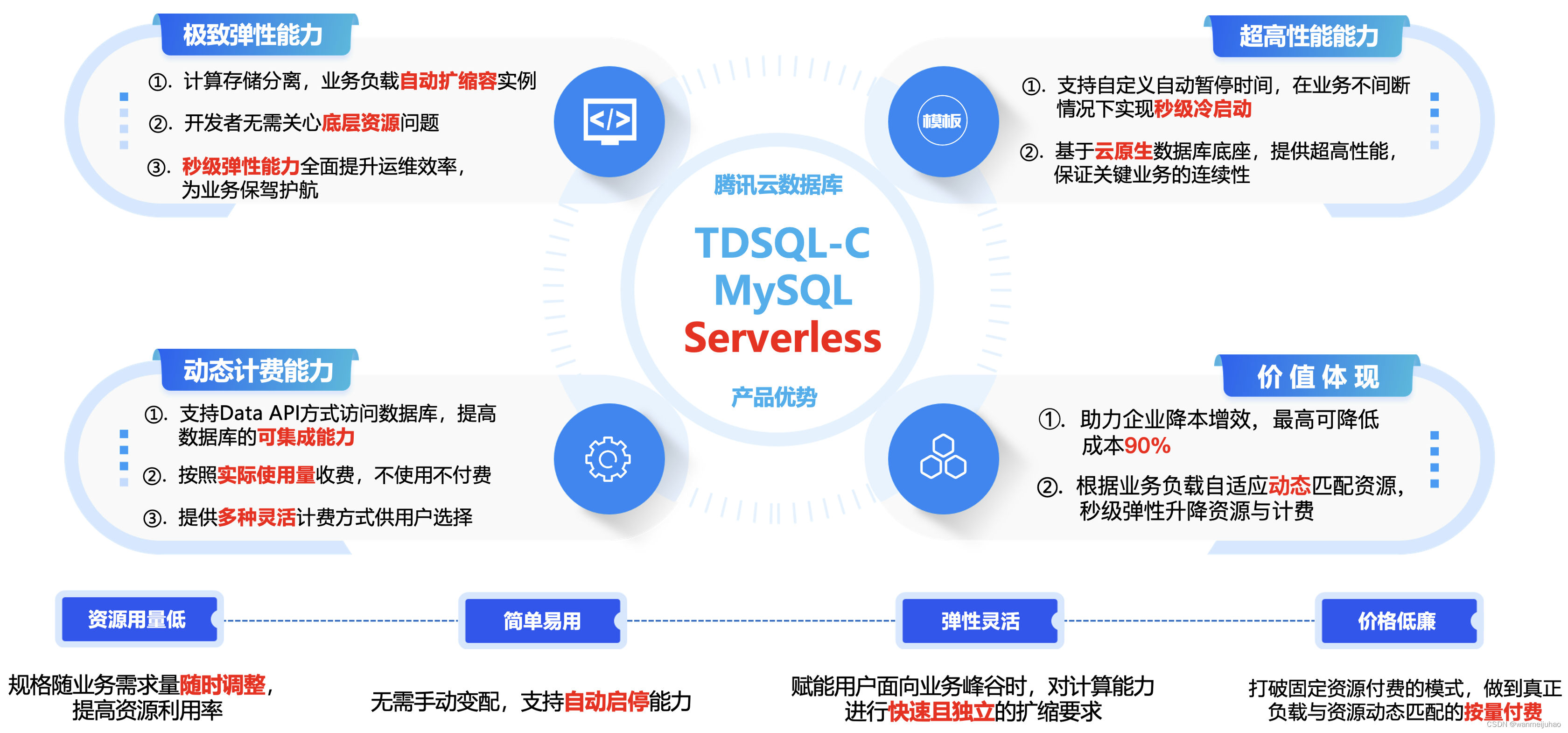
2. TDSQL-C MySQL Serverless数据库实例的优势:
与普通MySQL数据库实例相比,TDSQL-C MySQL Serverless数据库实例有如下6点明显的优势:
| 优势: |
|---|
| ①. 由于其规格随业务需求量随时调整,总体浪费的资源很少,提升了资源利用率,降低了资源使用量。 |
| ②. 在高峰期也能完全满足业务需求,保证业务不受损,提高了系统的稳定性。 |
| ③. 打破固定资源付费的模式,做到真正负载与资源动态匹配的按量付费,可节省大量成本。 |
| ④. 无需手动变配,提高了运维效率,降低了运维管理人员和开发人员的运维成本。 |
| ⑤. 支持自动启停能力,当没有连接时,实例自动暂停,释放计算成本;当请求连接时,自动无感启动。 |
| ⑥. 对高吞吐写入场景和高并发业务进行了设计优化,同时提供了弹性伸缩能力,适合业务数据量大、并具有典型的业务访问波峰波谷场景。 |
TDSQL-C MySQL Serverless数据库可以根据业务负载自动扩缩容实例,开发者无需关心底层资源问题,支持自定义自动暂停时间,在业务不间断情况下实现秒级冷启动,提供多种灵活计费方式供用户选择。
Serverless计费方式无需按固定资源付费,按照实际使用量进行收费,不使用不付费,根据业务负载自适应动态匹配资源,秒级弹性升降资源与计费,助力企业降本增效,最高可降低成本90%。
3. 生活场景阐述区别:
以在学校时,看过的一篇小说场景来进行阐述传统数据库与TDSQL-C MySQL Serverless数据库直观的对比,从生活中的实际场景来描述,从而更容易理解,从而选择合适的产品。
每一年的国庆节假已经来临,2位主角安排了自己的旅游出行,由于双方家庭经济基础不一样,所以,对于出行的安排也是会有区别的。
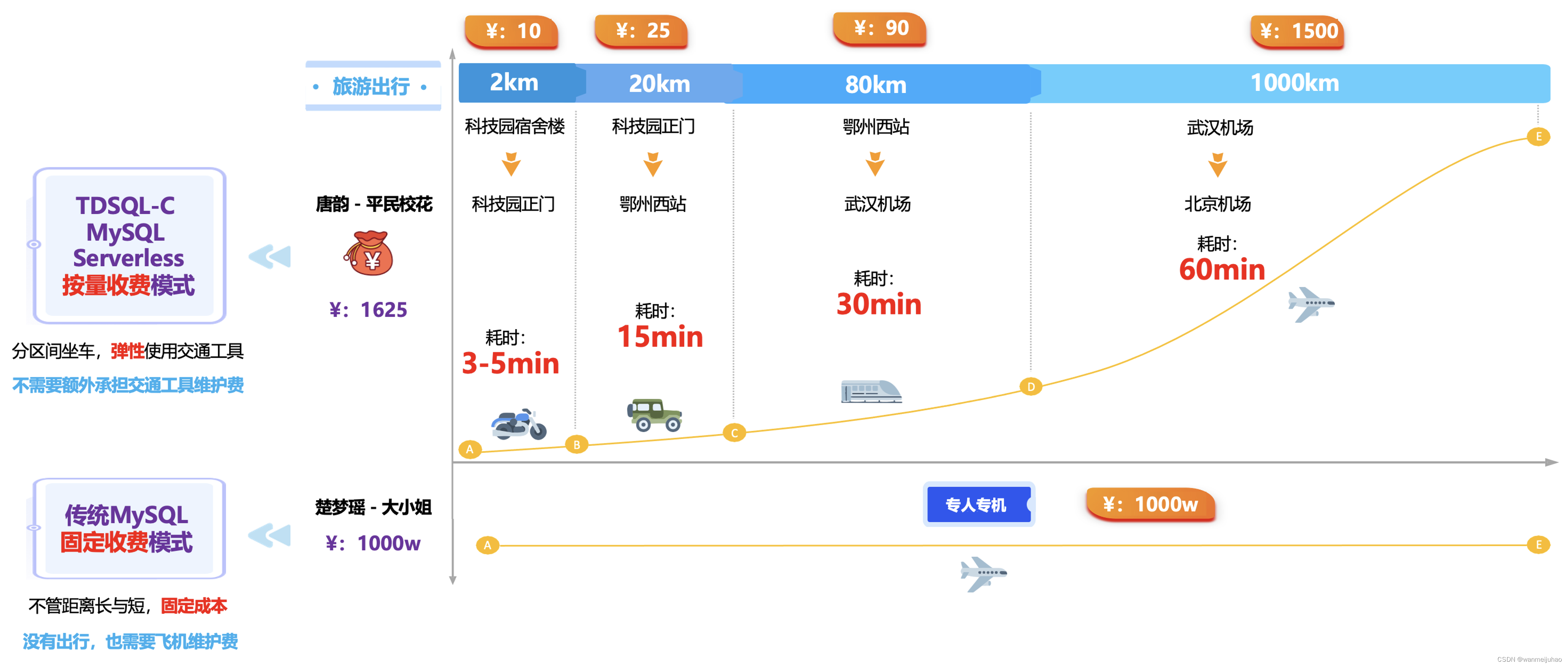
| 主角一:唐韵是工薪家庭 |
|---|
| ①. 为了节省成本,就根据距离的长短,弹性的乘坐性价(考量费用成本、时间成本)比合适的交通工具,距离可以当成数据库平时的配置(比如2km相当于2核2G),随着距离的大小,对应产生的计算费用也不同。 |
| ②. 所以,10个人用户的系统,使用2km的配置完全是够的,但是20个人,需要使用20km的配置,依次类推,最后,在完全满足出行的条件下,总共花费了1625元。 |
| ③. 在旅行期间,也不需要承担交通的建设、设备的购买、设备的保养、司机的工资,也不需要在非出行时间段承担相关的费用(实例不使用就不收费),只需要明确目的地就可以即方便又便宜的出行。 |
| 主角二:楚梦瑶家里有上市公司 |
|---|
| ①. 为了保障安全,家里购买了专人专用的私人飞机,可以应付所有的常规交通出行,而且也不用怕随时会有堵车(并发量过高),唯一的代价就是费用比较昂贵(高配置实例固定收费)。 |
| ②. 哪怕飞机没有起飞,也是会产生大量的费用,比如平时的保养,飞行员的人力成本(实例购买了不用的期间也会产生费用)。 |
4. 总结:
TDSQL-C MySQL Serverless数据库实例提供计算资源按需计费的能力,具有资源用量低、简单易用、弹性灵活和价格低廉等优点,赋能用户面向业务峰谷时对计算能力进行快速且独立的扩缩要求,做到快速响应业务变化的同时,合理优化使用成本,进一步助务企业降本增效。
三 、TDSQL-C MySQL Serverless数据库服务特性:
TDSQL-C MySQL 版提供 Serverless 服务以满足企业对特定业务场景的数据库服务要求,助力企业降本增效。

1. TDSQL-C MySQL Serverless的总体架构:
Serverless 服务是腾讯云自研的新一代云原生关系型数据库 TDSQL-C MySQL 版的无服务器架构版,是全 Serverless 架构的云原生数据库。Serverless 服务支持按实际计算和存储资源使用量收取费用,不用不付费,将腾讯云云原生技术普惠用户。
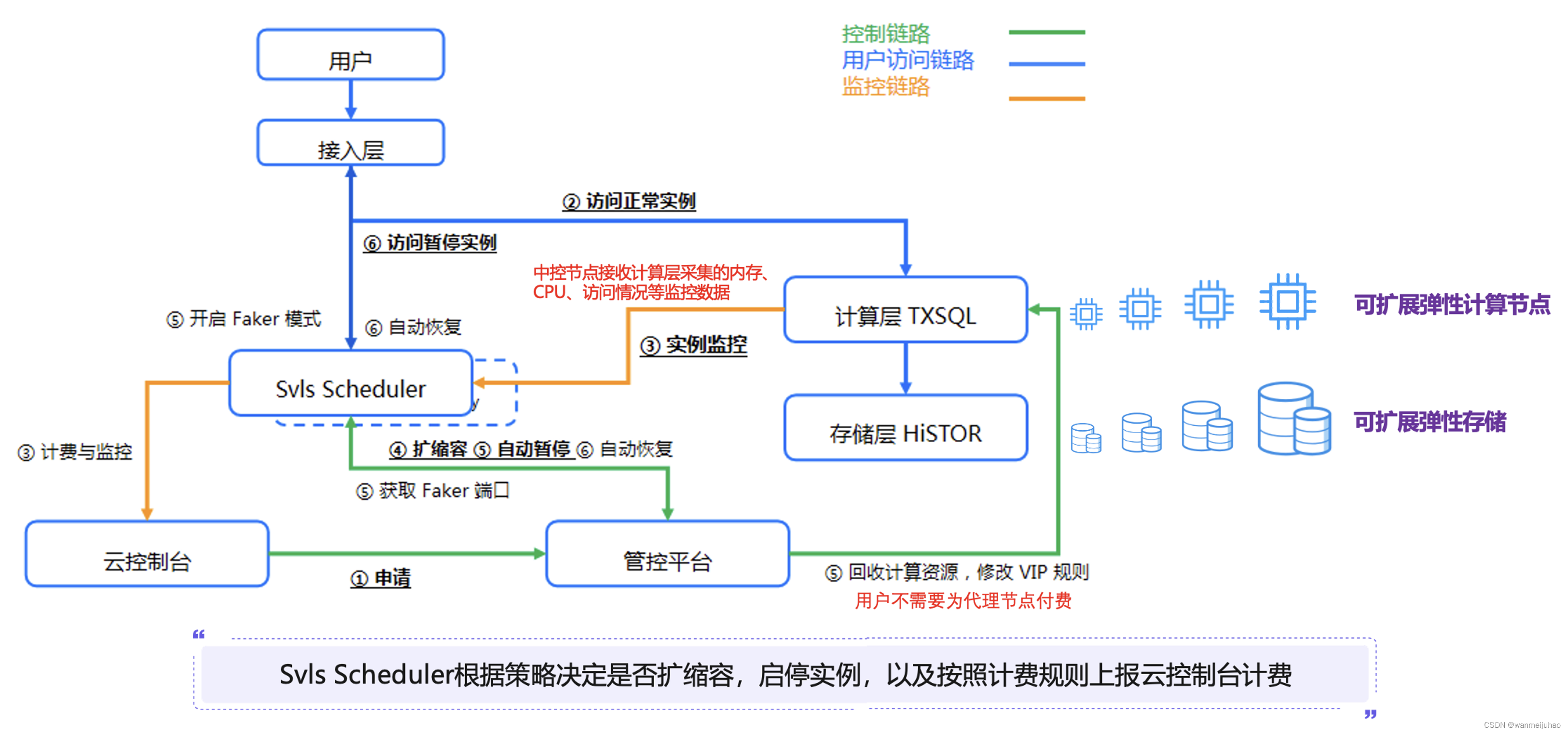
上图为TDSQL-C MySQL Serverless的总体架构,核心模块为中控节点(svls scheduler)。中控节点接收计算层采集的内存/CPU/访问情况等监控数据,根据策略决定是否扩缩容,启停实例,以及按照计费规则上报云控制台计费。
TDSQL-C MySQL Serverless有faker模块,暂停计算节点时会把四层的vip:vport绑定到faker端口,用户请求过来后,识别为有效的MySQL协议,则通知中控模块将实例重新拉起,其优点在于用户不需要为代理节点付费。
2. 资源扩缩范围(CCU):
可调整 CCU 弹性扩缩容的范围,Serverless 集群会在该范围内根据实际业务压力自动增加或减少 CCU。
2.1 CCU是啥?
CCU(TDSQL-C Compute Unit)为 Serverless 的计算计费单位,一个 CCU 近似等于1个CPU和2GB内存的计算资源,每个计费周期的 CCU 使用数量为:数据库所使用的 CPU 核数 与 内存大小的1/2 二者中取最大值。
Serverless 服务需要设定弹性范围,详细弹性范围区间可参考 算力配置。
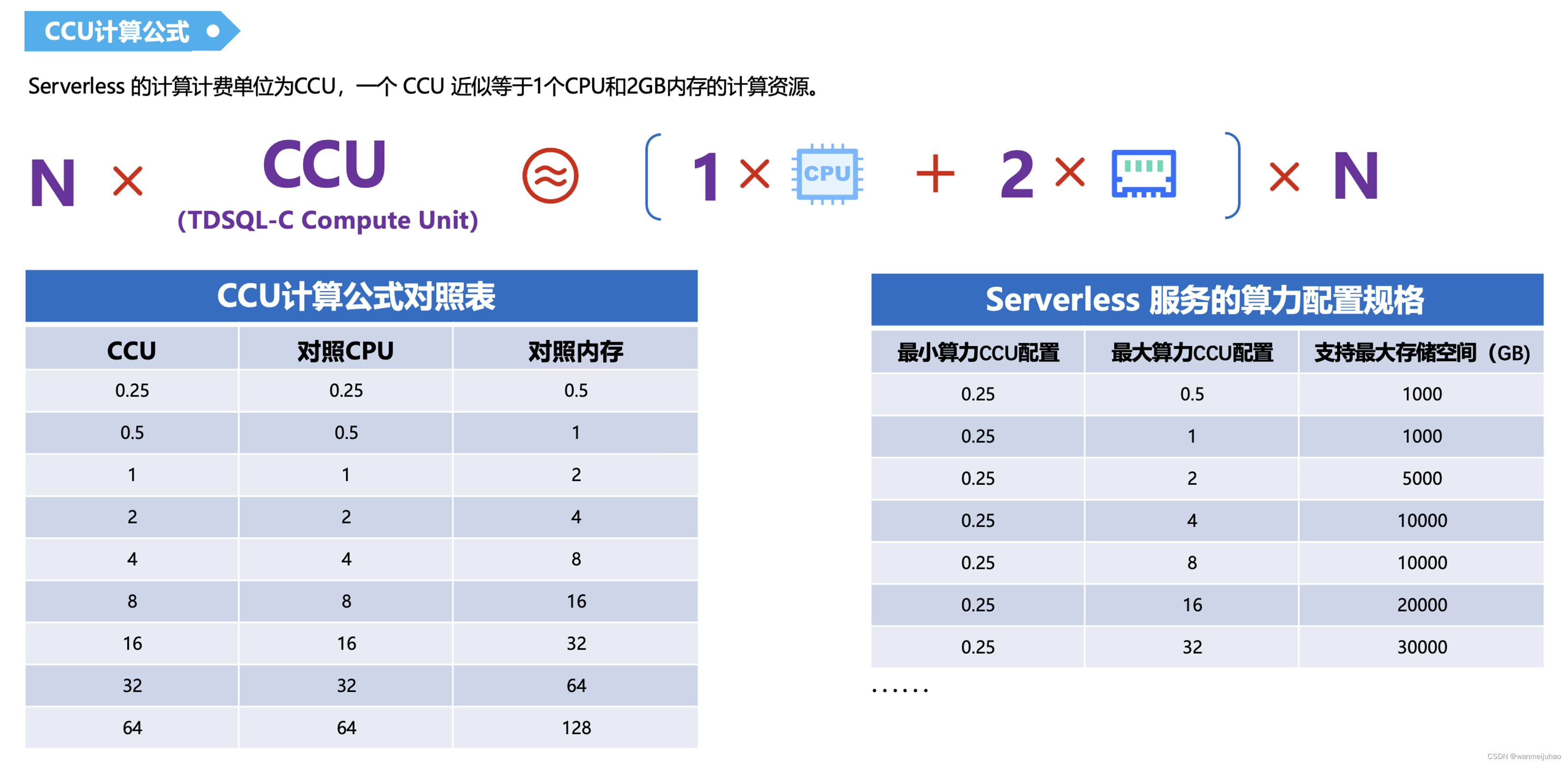
2.2 MySQL实例资源选择:
通过TDSQL-C MySQL Serverless实例资源的算力配置,最低可选择0.25CCU,代表0.25的CPU以及0.5GB内存,最高可选择64CCU,代表64的CPU以及128G的内存,足以应付很多场景的覆盖。
建议在第一次设置弹性范围时,最小容量配置为0.25 CCU,最大容量选择较高的值。较小的容量设置可以让集群在完全空闲时最大限度地进行缩减,避免产生额外的费用,较大的容量可以在集群负载过大时最大限度地进行扩展,稳定度过业务峰值。


通过指定实例资源波动的上下限,以CCU作为单位,让数据库服务变的更加灵活,切实的帮助企业达成降本增效的目标 。
3. 弹性策略:
Serverless 集群会持续监控用户的 CPU、内存等 workload 负载情况,根据一定的规则触发自动扩缩容策略。
3.1 传统Serverless架构中的自动扩缩容方案:
下图左侧传统Serverless架构中会有一个共享的虚拟机池,里面存放的是不同大小的规格,假设需要从1核2G扩大到2核4G,则从池子里面找到2核4G的虚拟机,将对应的数据盘挂载到虚拟机,并将访问切到该虚拟机,即可完成自动扩容。
传统Serverless架构中自动扩容存在的问题点:
| 问题点: |
|---|
| ①. 假设用户就只需要4核8G,传统Serverless架构仍需要从1核2G、2核4G、4核8G逐渐递增上去,扩容耗时偏长。 |
| ②. 由于选择新的虚拟机扩容,会导致BP失效,访问将经历一次冷启动过程,用户体验不是太友好。 |
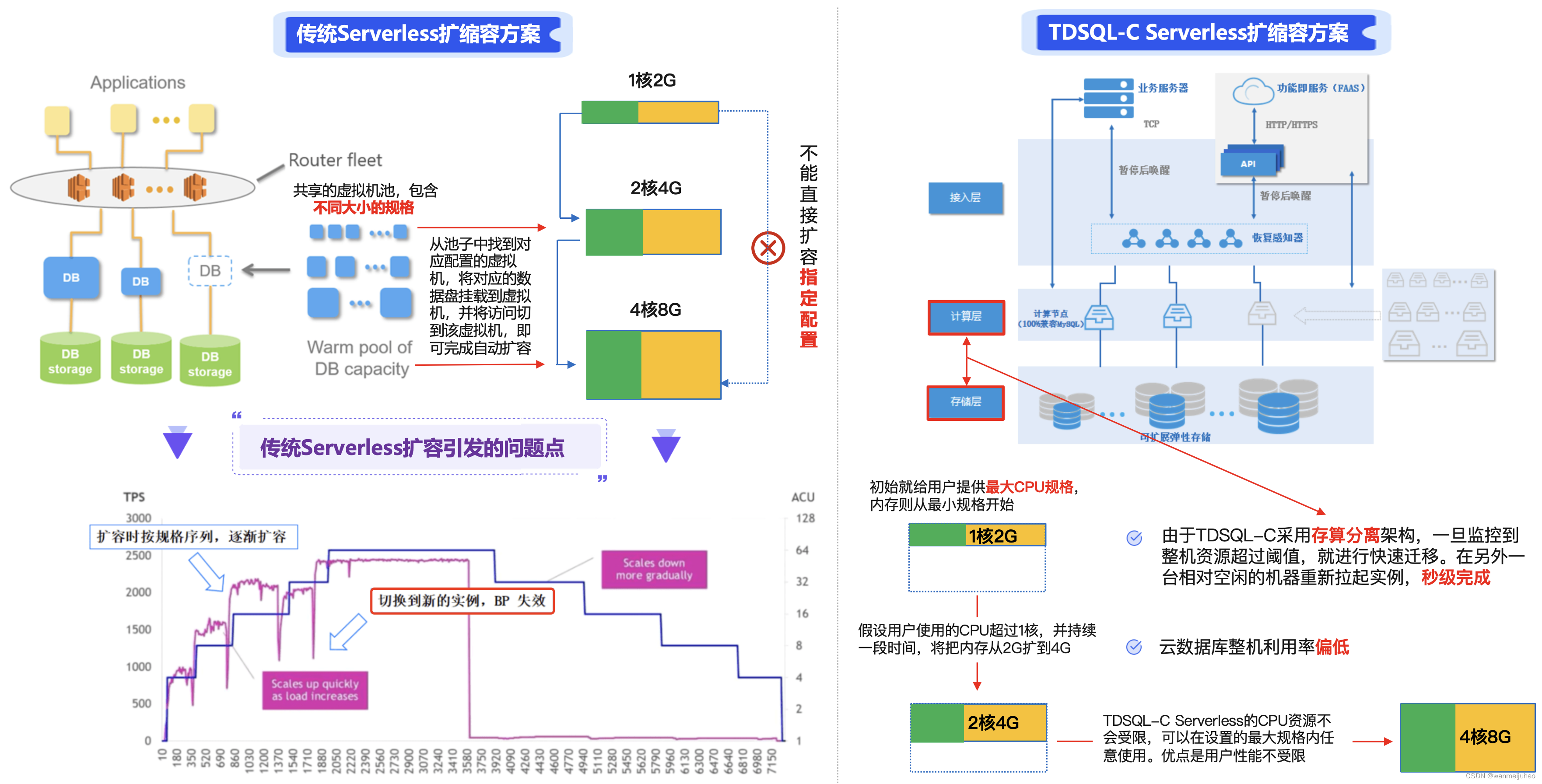
3.2 传统TDSQL-C Serverless架构中的自动扩缩容方案:
而上图右侧TDSQL-C Serverless架构中,用户在购买时选择最小规格为1核2G,最大规格为4核8G。TDSQL-C Serverless会在初始就给用户提供最大CPU规格,内存则从最小规格开始。可以看出,TDSQL-C Serverless的CPU资源不会受限,可以在设置的最大规格内任意使用。优点是用户性能不受限,引入的缺点是可能整机出现满负载。
基于以下两点,TDSQL-C Serverless可以很好应对自动扩缩容:
| TDSQL-C Serverless自动扩缩容方案: |
|---|
| ①. 由于TDSQL-C采用存算分离架构,一旦监控到整机资源超过阈值,就进行快速迁移,迅速在另外一台相对空闲的机器重新拉起实例,秒级完成,在资源负载上可以精准控制。 |
| ②. 云数据库整机利用率偏低。 |
3.3 小结:
Serverless 服务的弹性策略是利用监控计算层实现的。通过监控业务负载情况,系统对计算资源进行自动扩缩容。
| 自动扩缩容原理: |
|---|
| ①. Serverless 服务的弹性策略一开始会根据用户购买时选择的容量范围,将 CPU、内存资源限制到最大规格,极大程度降低因 CPU 和内存扩容带来的时间影响和使用限制。 |
| ②. 当集群触发到自动弹性的负载阈值后,Buffer pool 会根据监控提前进行分钟级调整。 |
| ③. 在这个方案下用户使用数据库可以无感知进行 CPU 扩容,并且不会因为连接突增导致实例 OOM。 |
4. 自动启停:
Serverless 服务支持自定义实例自动暂停时间,无连接时实例会自动暂停。当有任务连接接入时,实例会秒级无间断自动唤醒。

当没有数据库请求时,监控服务会触发计算资源的回收,并通知接入层。当用户再次访问时,接入层则会唤醒集群,再次提供访问。
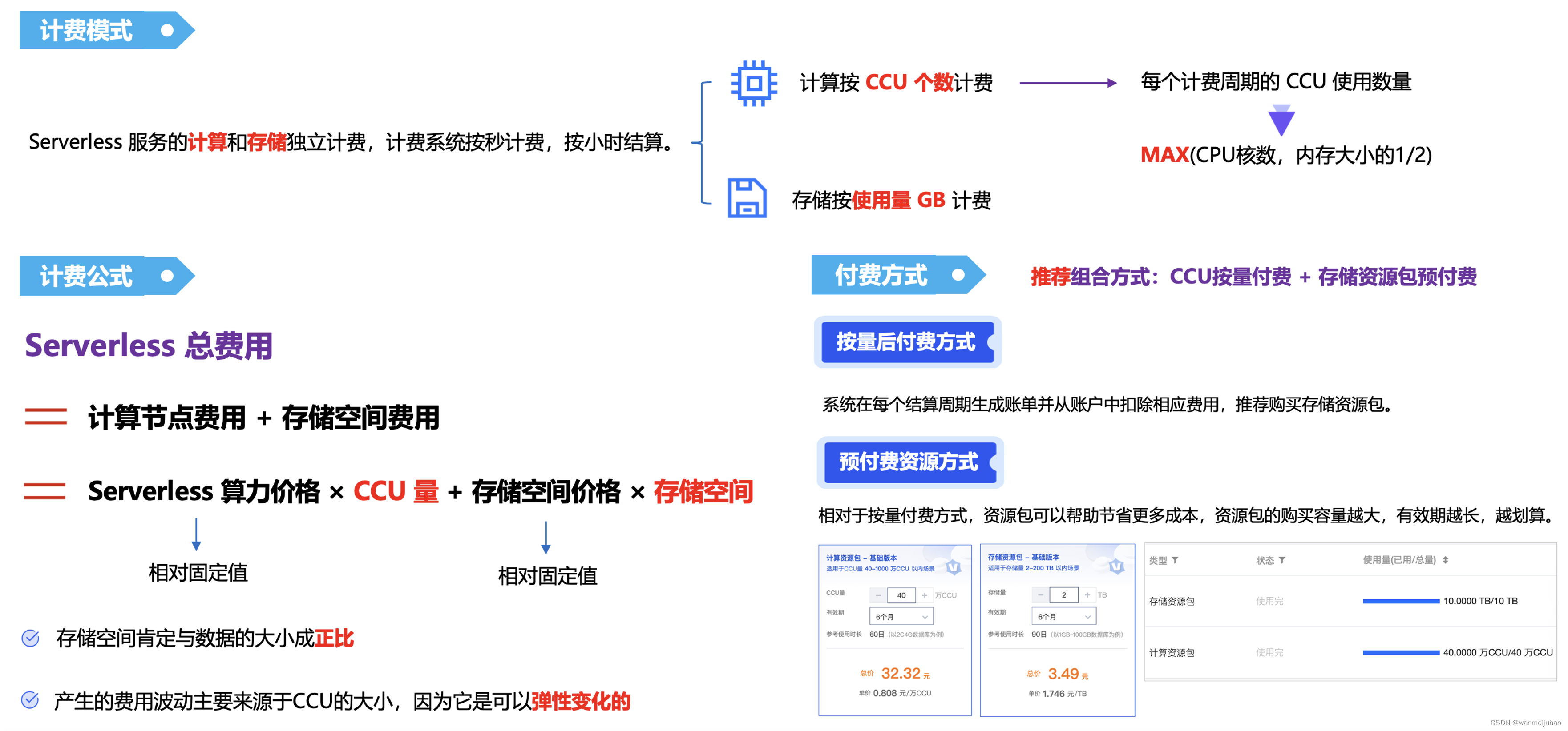
5. 计费模式:
Serverless 服务通过监控业务负载情况,系统对计算资源进行自动扩缩容,并对该时刻所消耗的资源进行计费。
6. 存储资源包的误区:
| 模式 | 描述 |
|---|---|
| 想像的收费模式 | ①. 买了多少存储资源包,就能用多少量的数据存储。 ②. 比如购买了10TB存储资源包,就可以长期使用,直到数据库的数据达到10TB。 |
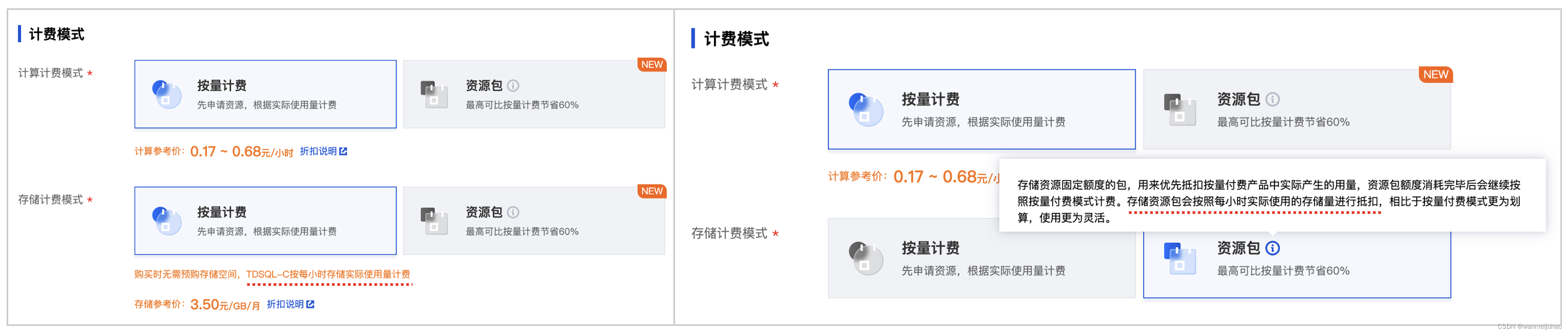
| 实际的收费模式 | ①. 存储资源包会按照每小时实际使用的存储量进行抵扣收费,在实际项目要特别注意一下数据量的预估。 ②. 比如购买了10TB存储资源包,现有的数据量是200GB,计算的公式是10TB/(0.2* 24) = 2.08天 |
在使用过程中,发现一个存储资源包的相关问题,有段时间没有使用,在收取存储资源的费用,记得当时明明已经购买过存储的资源包了,这么快就用完了吗?记忆中好像用的数据量也不多。

查看TDSQL-C MySQL Serverless实际的使用存储量为224.57GB,但是我购买的是40TB的存储资源包,为什么这么快就用完了呢?

以下是购买资源包的列表,发现存储资源包已经满了。

因为不知道是什么原因导致的,只能无奈去提一个工单来询问一下是什么问题。
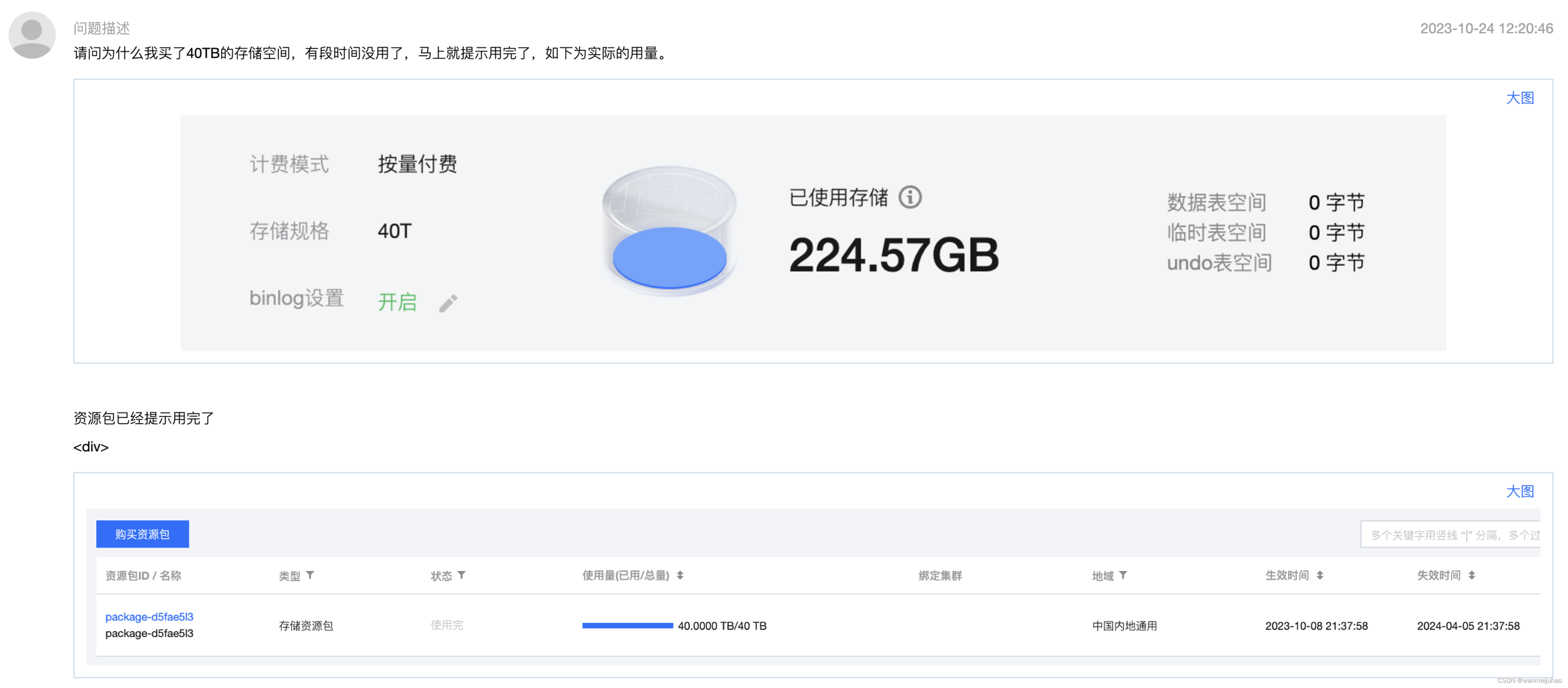
以下为腾讯云工程师给的回复,40T的存储资源包,而现在已使用的存储为0.2T,每天是24小时,按照他给的公式,表示8天左右就会使用完。
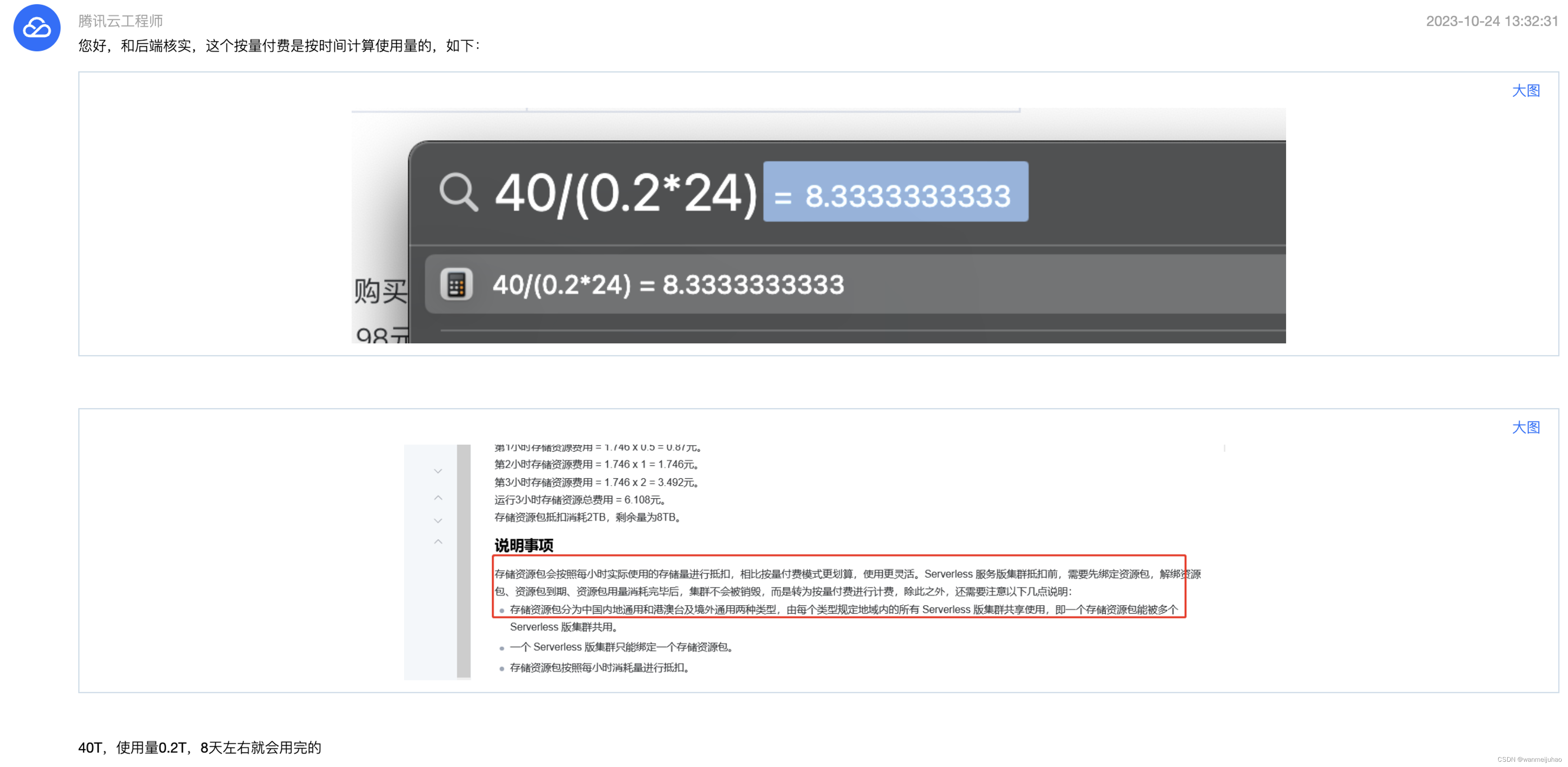
看来是自己理解错误了,结论是存储资源包会按照每小时实际使用的存储量进行抵扣收费 ,在购买的时候,选择计费模式的时候,上面也有备注。
四、TDSQL-C MySQL Serverless自动启停实验:
1. MySQL数据库连接原理:
MySQL 服务端实例启动后,就可以通过客户端建立与服务端的连接,然后发送查询/更新请求了。

| 3种MySQL客户端连接渠道: |
|---|
| ①. 通过图形化客户端软件(如MySQL Workbench、Navicat For MySQL、DataGrip、TablePlus、Sequel Pro等)建立与 MySQL 服务端的连接。 |
| ②. 通过 MySQL 安装目录 bin 目录下的 mysql 二进制文件在终端窗口通过命令行建立与 MySQL 服务端的连接。 |
| ③. 在PHP、Go、Python、Java等后端编程语言中使用的数据库SDK建立与 MySQL 服务端的连接,只不过SDK是对数据库连接做了封装而已。 |
2. 可视化图形工具客户端连接数据库:
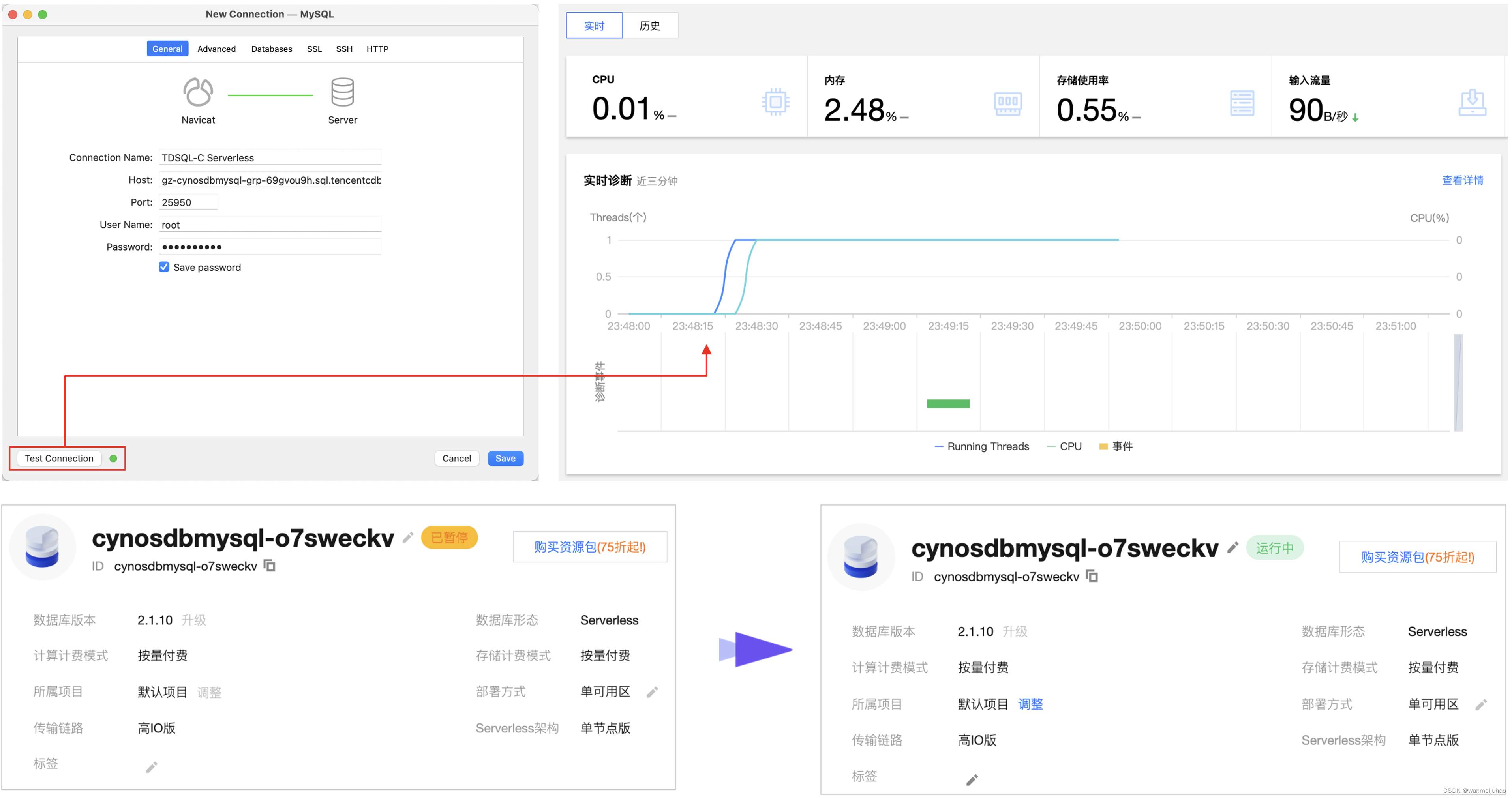
先将TDSQL-C Serverless服务器关掉,再在Navicat For MySQL填写完Host、Port、User Name、Password后,点击“Test Connection”后,可以看到服务器的实时监控,发现有连接进来后,马上把服务器进行恢复。因为没有有效的记录时间的方案,只能看折现图,可以发现Threads进程是在23时48分15秒左右马上启动起来了。
3. MySQL二进制文件的两种连接方式:
Linux平台环境下主要有两种连接方式,一种是TCP/IP连接方式,另一种就是socket连接:
- 通过TCP/IP连接MySQL实例时,MySQL会先检查一张权限表,用来判断发起请求的客户端IP是否允许连接到MySQL实例,该表就是MySQL库下面的user表。
- UNIX Socket连接方式其实不是一个网络协议,所以只能在MySQL客户端和数据库实例在同一台服务器上的情况下使用。
| Unix套接字连接MySQL的优势: |
|---|
| ①. 更快的连接速度: Unix套接字连接不经过TCP/IP协议栈,因此速度更快。 |
| ②. 更高的安全性: Unix套接字连接只能在本地主机上使用,因此对于需要保护数据安全的数据库应用程序来说,这是一个重要的因素。 |
| ③. 更少的网络负载: 由于Unix套接字连接只在本地主机上连接,因此不会浪费带宽和网络负载。 |
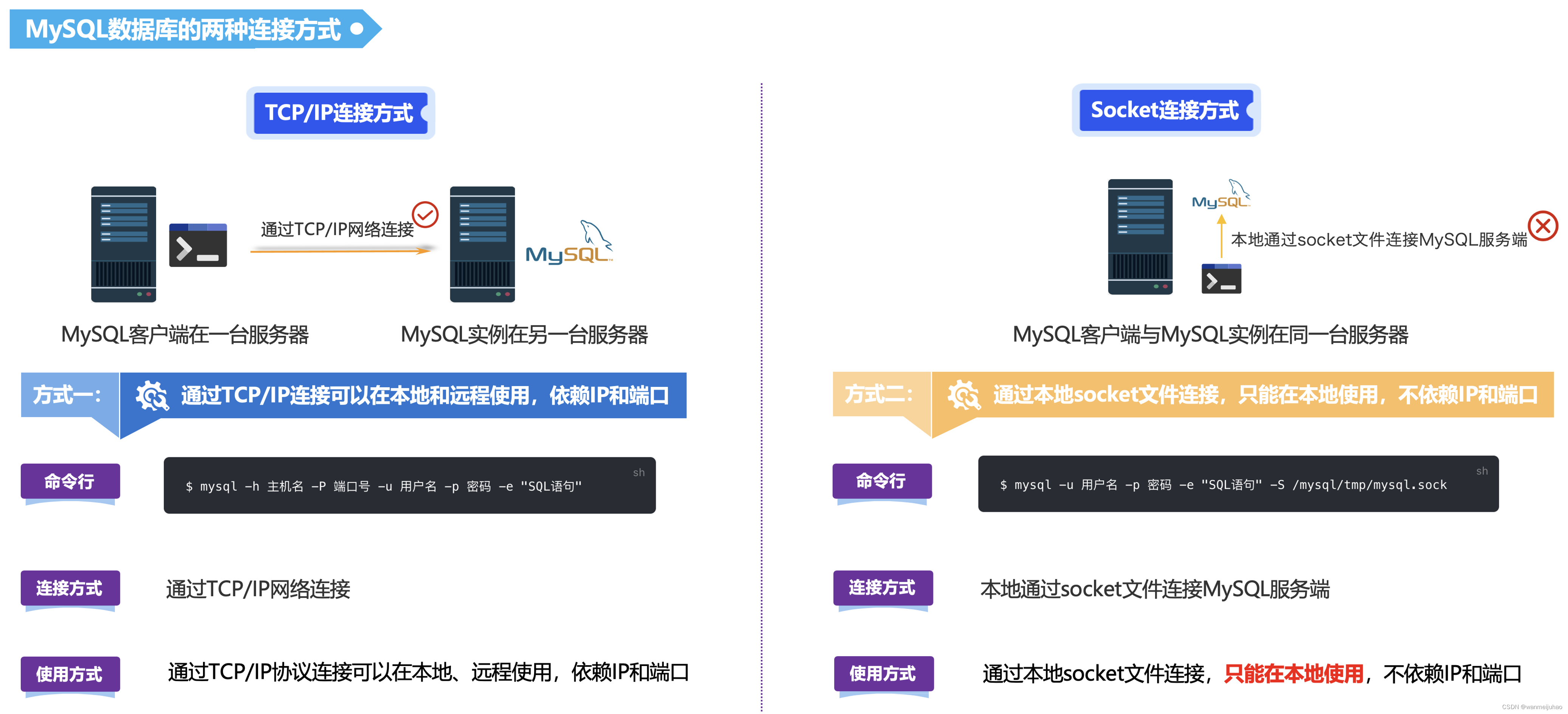
因此,本次测试会采用MySQL TCP/IP的方式进行测试。
可以使用shell脚本来操作TDSQL-C MySQL Serverless数据库自动启停,使用-e参数可以执行各种sql的(创建、删除、增、删、改、查)等各种操作。
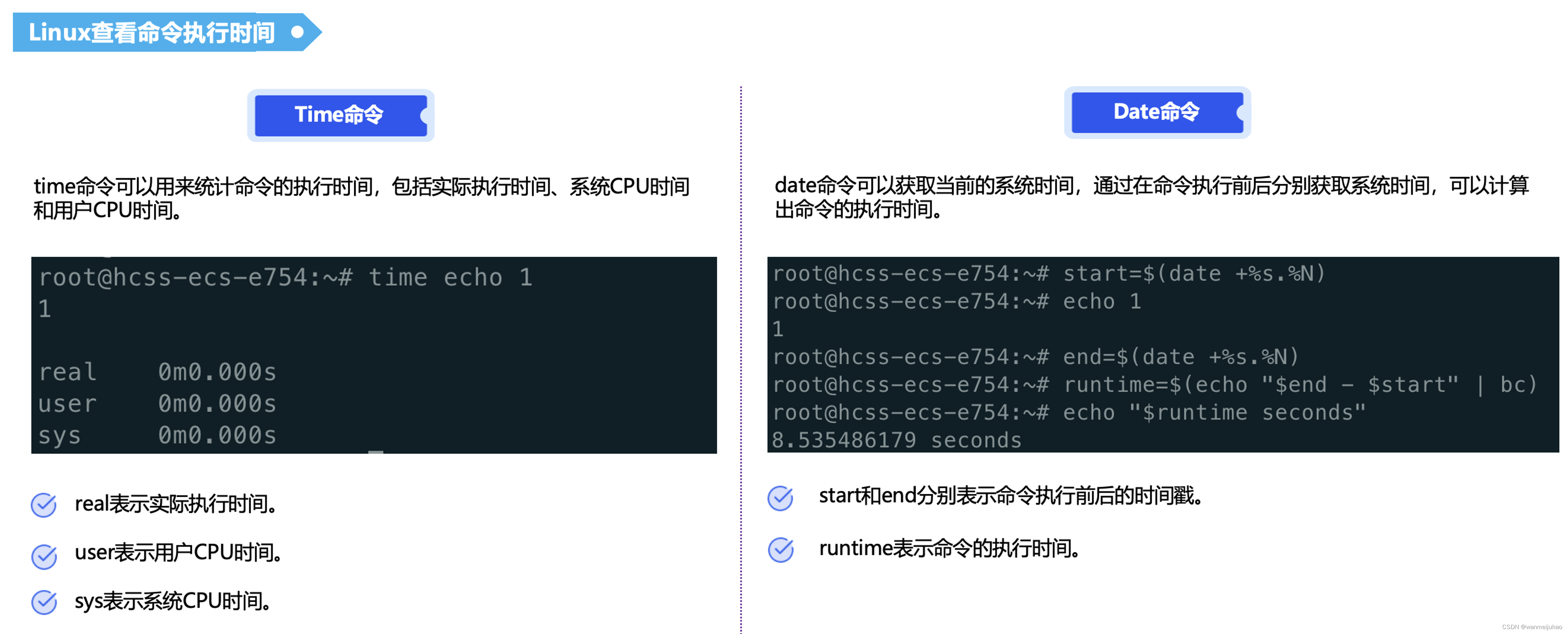
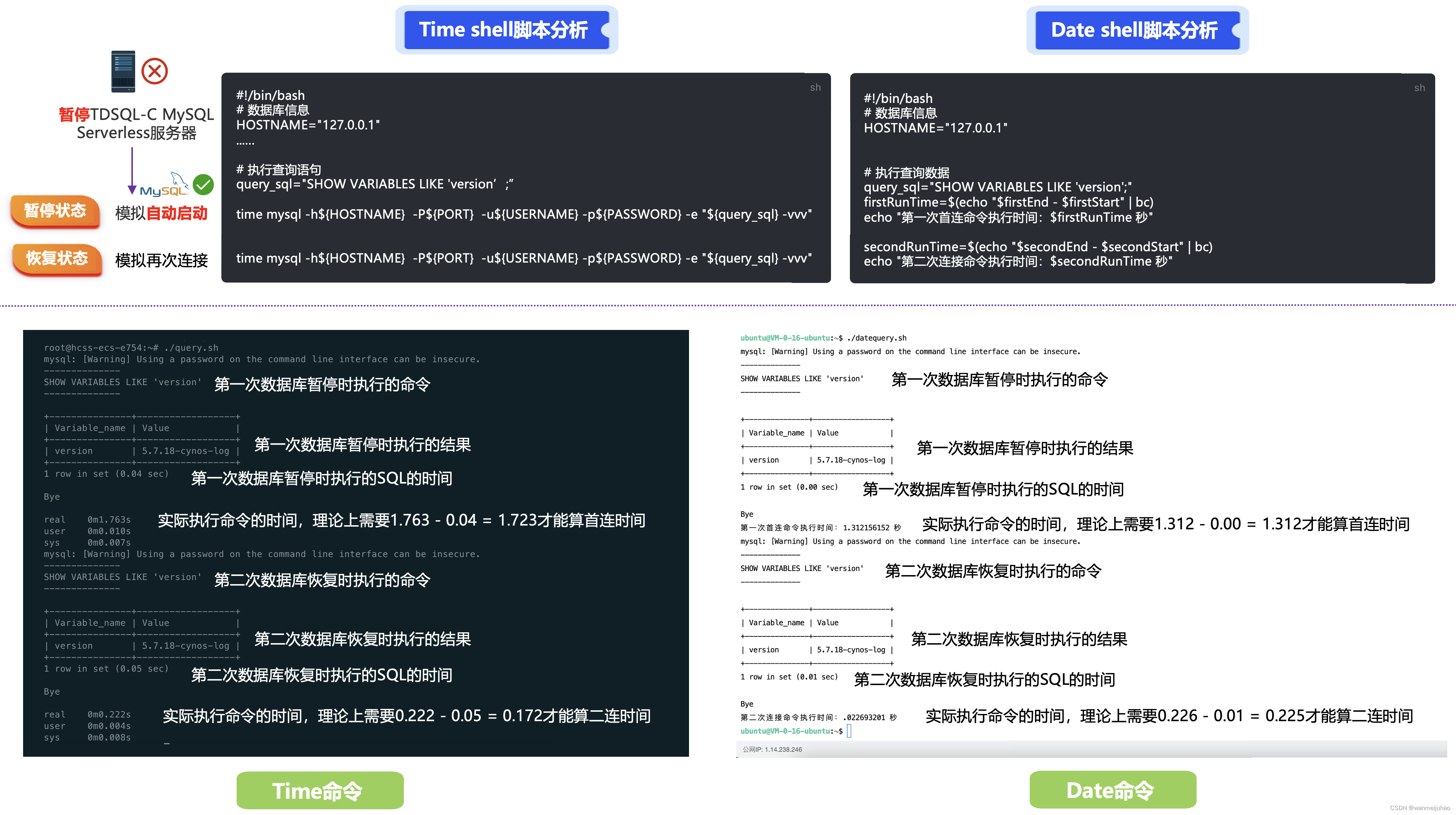
3.1 时间命令time的shell脚本:
脚本的作用是当数据库暂停后,第一个mysql连接是模拟登录到Serverless数据库,出现自动启动数据库,看看时间是多久,然后,马上再次用mysql连接模拟一下在数据库启动的状态下,需要多久进行连接。
#!/bin/bash
# 数据库信息
HOSTNAME="gz-cynosdbmysql-grp-69gvou9h.sql.tencentcdb.com"
PORT="25950"
USERNAME="root"
PASSWORD="Mydb123."
# 执行查询数据
query_sql="SHOW VARIABLES LIKE 'version';"
time mysql -h${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} -e "${query_sql} -vvv"
time mysql -h${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} -e "${query_sql} -vvv"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
mysql -v参数的作用,为了防止SQL本身执行时间影响到连接的效果,可以把SQL执行的时间也打印出来。
● 若要同时显示语句本身:-v
● 若要增加查询结果行数:-vv
● 若要增加执行时间:-vvv
3.2 时间命令date的shell脚本:
#!/bin/bash # 数据库信息 HOSTNAME="gz-cynosdbmysql-grp-69gvou9h.sql.tencentcdb.com" PORT="25950" USERNAME="root" PASSWORD="Mydb123." # 执行查询数据 query_sql="SHOW VARIABLES LIKE 'version';" firstStart=$(date +%s.%N) mysql -h${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} -e "${query_sql}" -vvv firstEnd=$(date +%s.%N) firstRunTime=$(echo "$firstEnd - $firstStart" | bc) echo "第一次首连命令执行时间:$firstRunTime 秒" secondStart=$(date +%s.%N) mysql -h${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} -e "${query_sql}" -vvv secondEnd=$(date +%s.%N) secondRunTime=$(echo "$secondEnd - $secondStart" | bc) echo "第二次连接命令执行时间:$secondRunTime 秒"

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
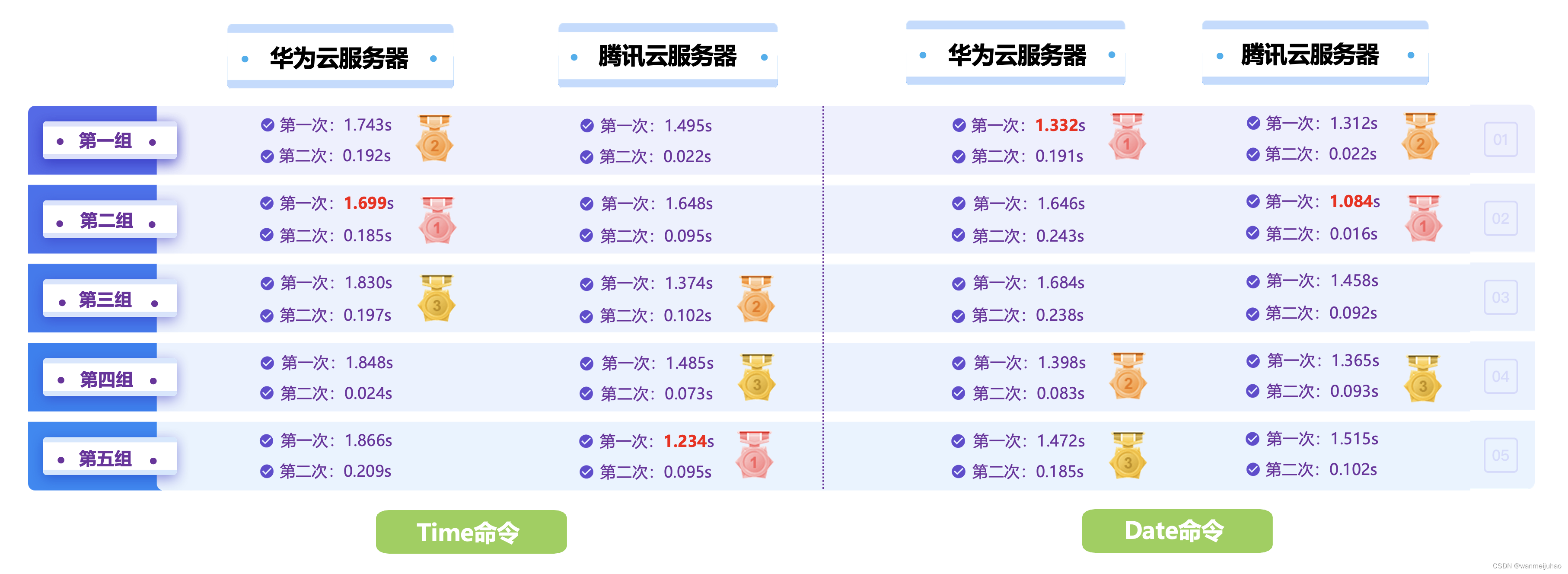
4. 准备两台不同配置的机器:
评测的目标机器为TDSQL-C Serverless,使用的模式为按量收费,机房的位置在广州四区。

准备两台测试机器,一台是腾讯云的CVM云服务器,2核4G 10Mps,广州七区与Serverless实例在同一个区,一台是华为云耀云服务器2核2G 3Mps,华北北京四区,测一下不同服务器、不同区域的结果做比较。
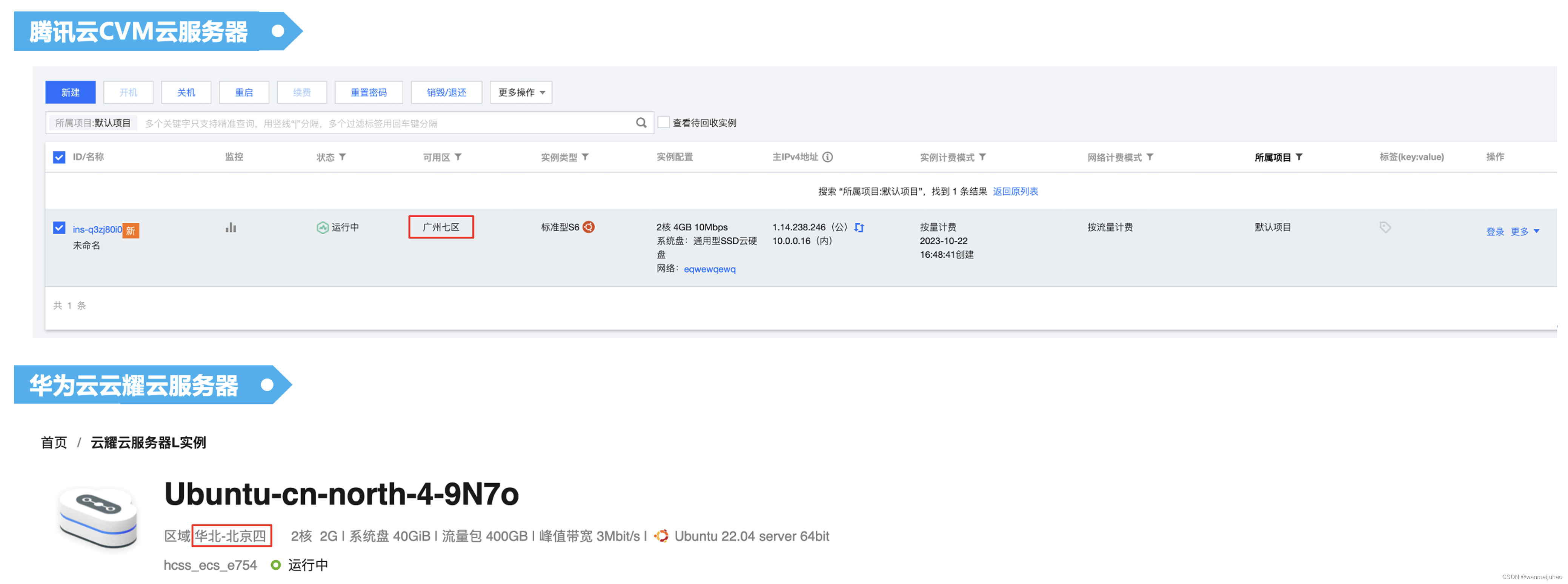
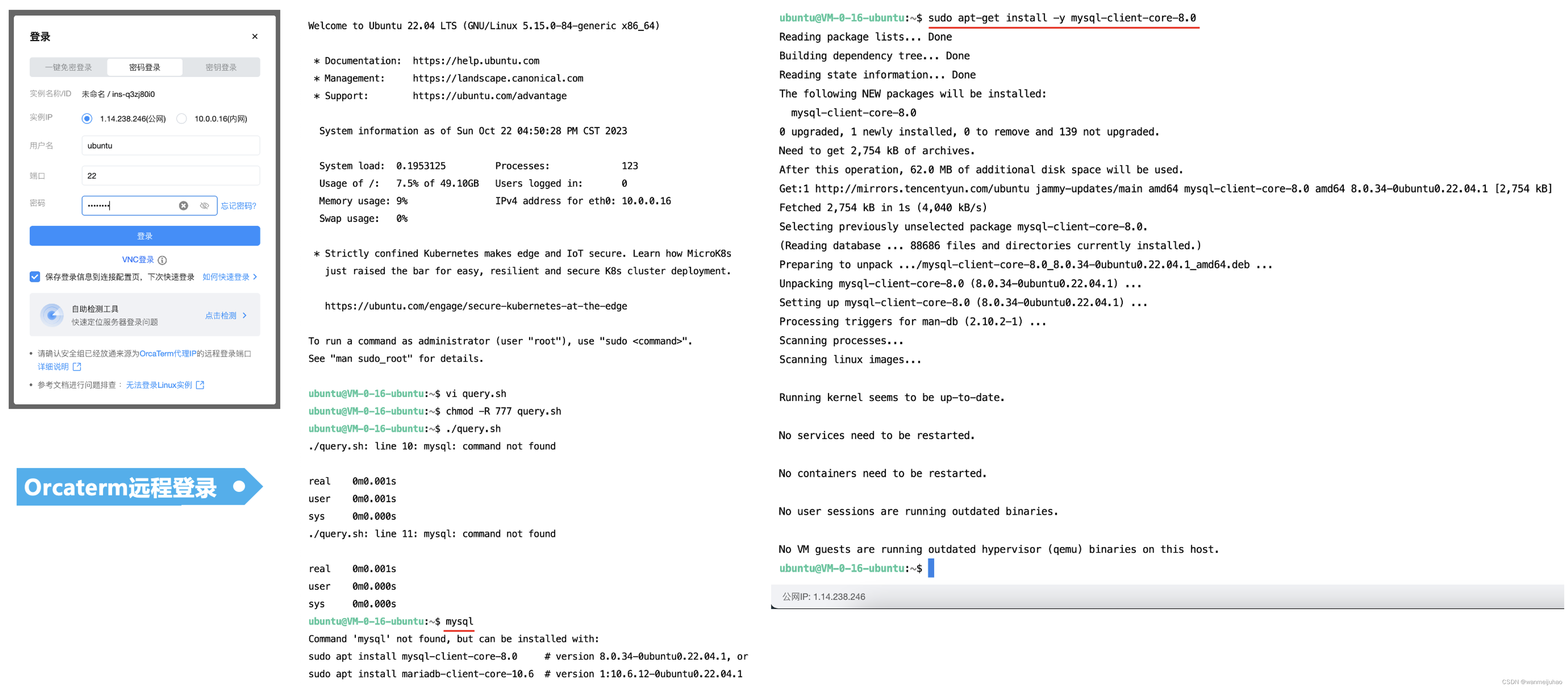
腾讯云的CVM云服务器,可以通过orcaterm进行远程登录,可以进行如下的测试脚本执行流程:
# 复制脚本
vi query.sh
# 增加执行权限
chmod -R 777 query.sh
# 执行shell脚本
./query.sh
# 检查是否有mysql
mysql
# ubuntu安装mysql客户端
apt-get install -y mysql-client-core-8.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
5. 测试脚本分析实验数据:
通过2种查看linux执行时间的命令的shell脚本,每次执行前,先将服务器进行暂停,脚本中第1个mysql命令表示服务器暂停时默认启用,看一下执行的时间多久,这里需要注意的是因为SQL本身也会存在执行时间,比如执行一个慢查询,这里为了得到比较合理的值,增加了-vvv参数来输出SQL命令本身执行的时间,得到的公式:
命令的总执行时间 – SQL本身执行的时间 = Serverless服务器自动启动时间
- 1
每个脚本分别在2台云服务器腾讯云CVM、华为云云耀云服务器各执行5次,得出以下结果:
- 可能由于腾讯云服务器与Serverless在相同的区域广州机房,时间略比华为云服务器要短。
- 基本上在2s左右就能完成Serverless服务器自动启动。
云服务器(Cloud Virtual Machine,CVM)是腾讯云提供的可扩展的计算服务。使用云服务器避免了使用传统服务器时需要预估资源用量及前期投入,帮助在短时间内快速启动任意数量的云服务器并即时部署应用程序,推荐应用在部署时,参考以下方案:

6. Java代码连接MYSQL数据库方式:
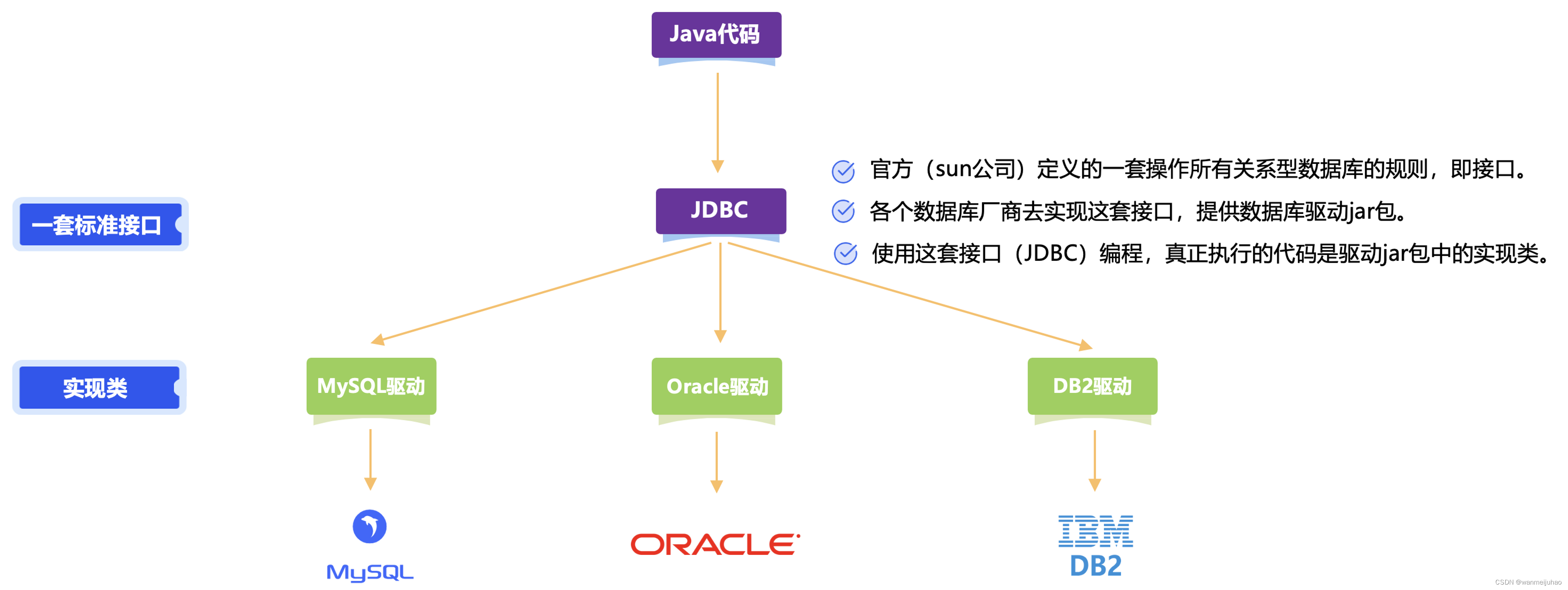
JDBC是Java数据库连接(Java Database Connectivity),是一套用于执行SQL语句的Java API。应用程序可以通过这套API连接到关系型数据库,并使用SQL语句完成对数据中数据的查询、增加、更新和删除等操作。
JDBC在应用程序与数据库之间起到了一个桥梁作用,当应用程序使用JDBC访问特定的数据库时,需要通过不同数据库驱动与不同数据库进行连接,连接后即可对该数据库进行相应的操作。
采用的逻辑是先将Java代码启动并且连接上数据库,这时候,程序设定延迟1分钟,此时,手动在服务器控制台进行暂停服务器后,再让程序进行SQL的操作,看看实际生产的一个真实情况能不能满足?
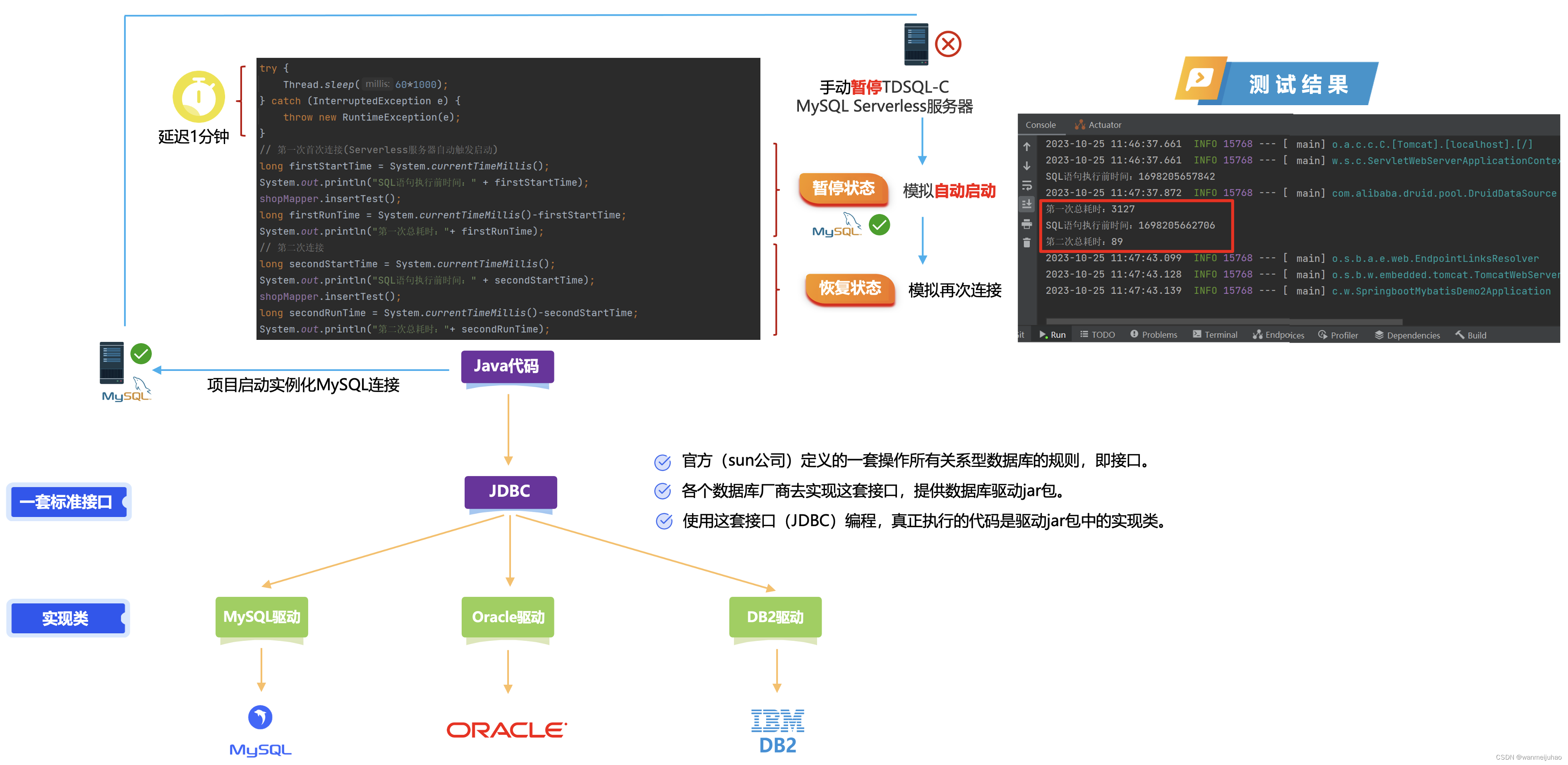
Java核心的代码:
@Component public class Service implements ApplicationContextAware { @Autowired private ShopMapper shopMapper; @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { try { Thread.sleep(60*1000); } catch (InterruptedException e) { throw new RuntimeException(e); } // 第一次首次连接(Serverless服务器自动触发启动) long firstStartTime = System.currentTimeMillis(); System.out.println("SQL语句执行前时间:" + firstStartTime); shopMapper.insertTest(); long firstRunTime = System.currentTimeMillis()-firstStartTime; System.out.println("第一次总耗时:"+ firstRunTime); // 第二次连接 long secondStartTime = System.currentTimeMillis(); System.out.println("SQL语句执行前时间:" + secondStartTime); shopMapper.insertTest(); long secondRunTime = System.currentTimeMillis()-secondStartTime; System.out.println("第二次总耗时:"+ secondRunTime); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
执行结果:

- 项目启动时,要对数据库进行了实例化连接
- 程序启动后,会有一个60s的延迟设置,此时,手动暂停Serverless实例,模拟在程序启动后,在一定时间内不使用,Serverless服务器实例自动暂停
- 第一次连接,触发Serverless恢复感知器自动启动服务器,可以看到在3.127s就完成了
- 第二次连接,Serverless已经恢复了,可以看到在0.089s内完成操作
6. 小结:
通过3种MySQL客户端连接方式的进行测试,TDSQL-C MySQL Serverless自动启停实验,可以完全满足生产环境的需求。
五、TDSQL-C MySQL Serverless弹性伸缩实验:
下面将按照以下5个大的步骤进行对TDSQL-C MySQL Serverless的一个压力的测试过程。

为了可以有效的进行测试观察结果,TDSQL-C MySQL Serverless选择了一个较大的算力弹性区间范围[1,32],即最小可以是1核2G的云数据库服务器(可能会更小,0.1都可能存在),最大可能是32核64G云数据库服务器。
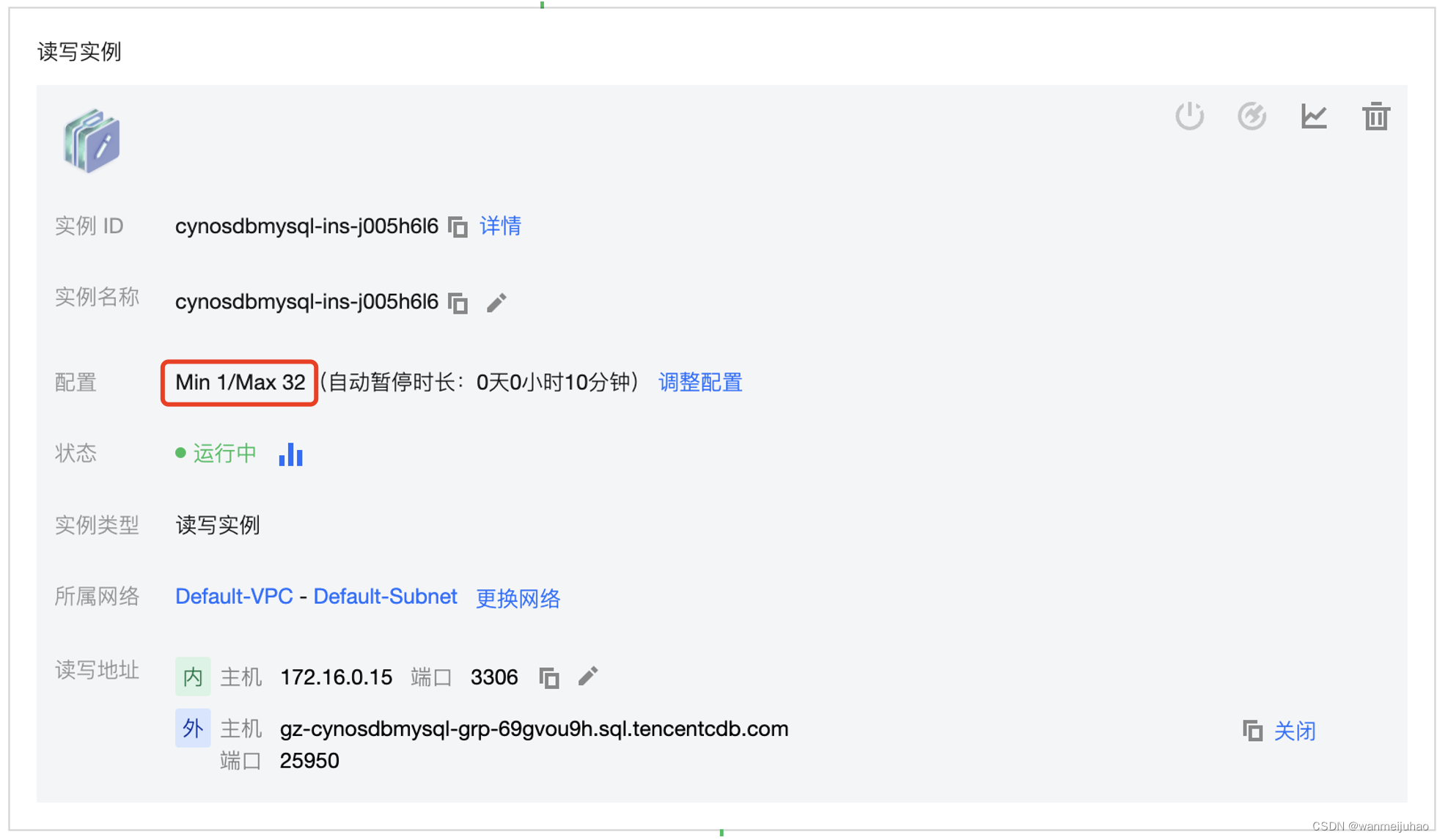
通过对压测的结果进行分析,TDSQL-C MySQL Serverless在不使用的时候,就会释放计算节点,只收取存储的费用。当服务器启动后,就会再加上计算节点的CCU费用,可以看到TDSQL-C MySQL Serverless在最开始的算力为1,可以随着压测的流量变大,同步增加到最大32个算力,当压测停止后,又自动在后面缩容到算力到0为止。
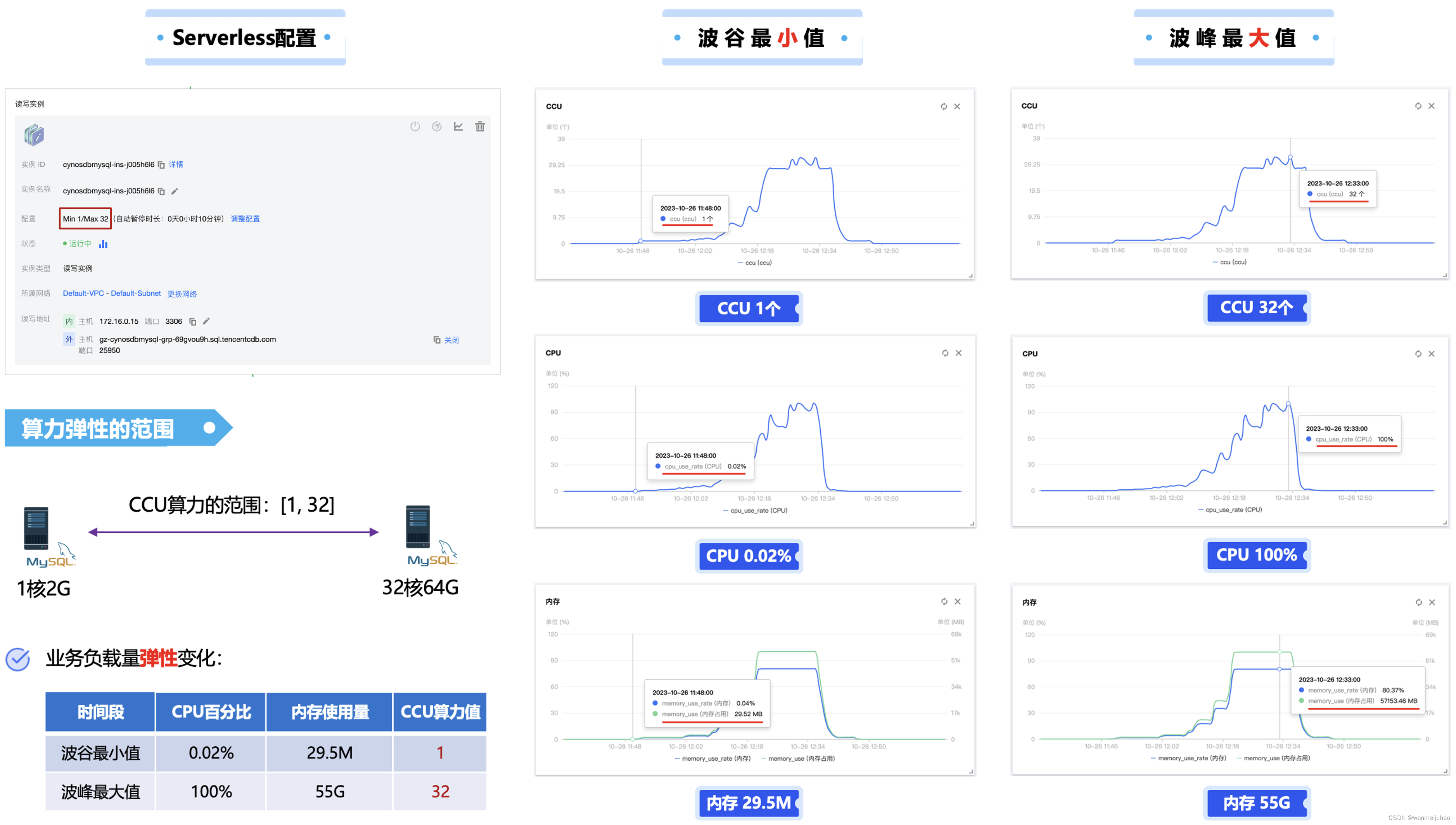
以下为分3个阶段进行TDSQL-C MySQL Serverless的测试,第一步本地进行多进程可以看到没有太多的变化,第二步使用本地JMeter,由于机器配置的原因,也是没有到达一个极限,最后第三步,在购买一台高配的云服务器使用Jmeter压测,可以达到实例的一个满核的负载。
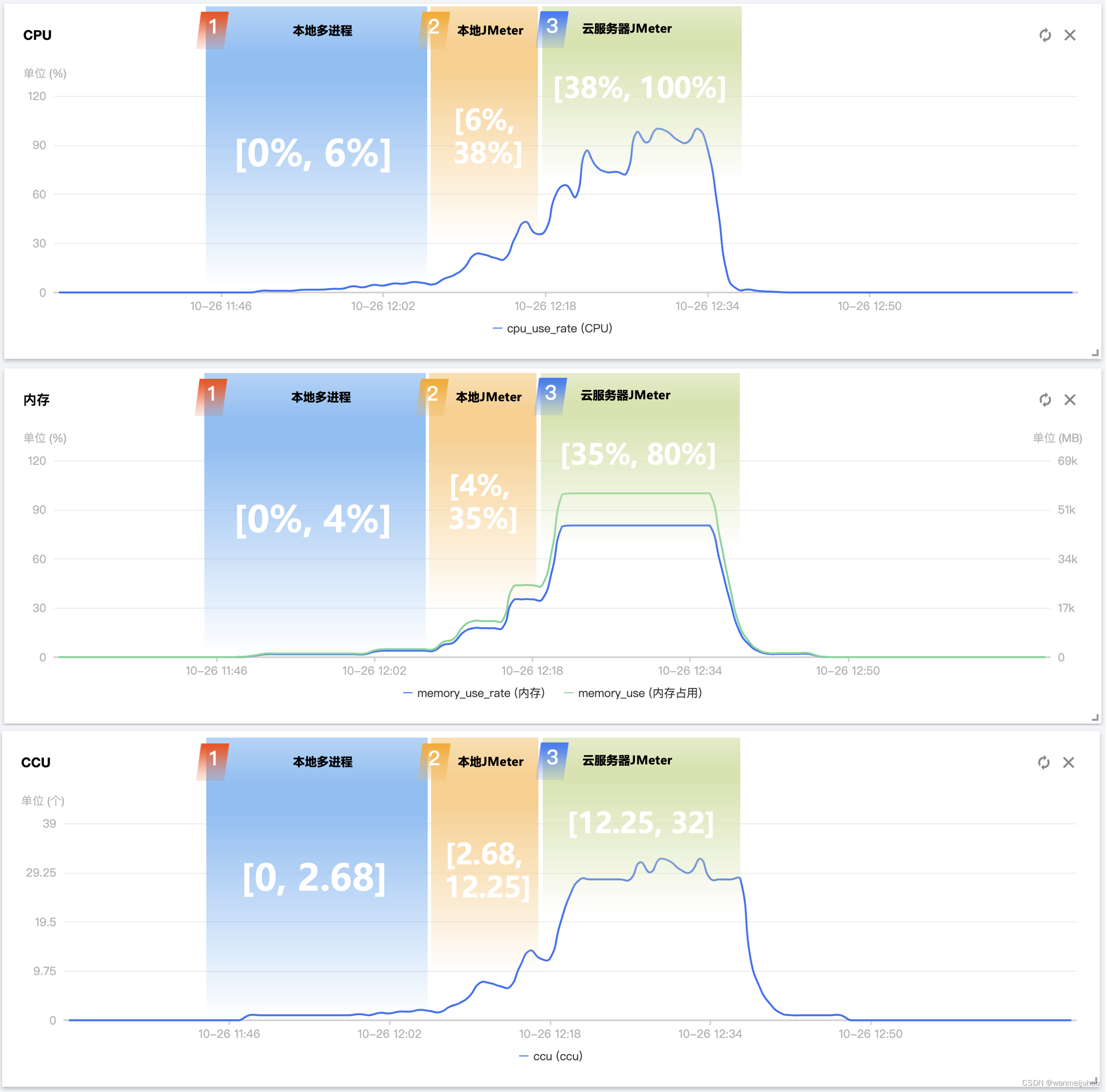
以下为从监控平台得到压力测试这段时间内,得到各个指标参数的值,这里没有把每一分钟的变化值罗列出来,只是把一些波动变化比较大的值,在以下进行列举:
| 时间段 | CPU百分比 | 内存百分比 | 内存使用量 | CCU算力值 |
|---|---|---|---|---|
| 11:50 | 1.04% | 0.98% | 700.24M | 1 |
| 11:59 | 3.77% | 1.73% | 1232.21M | 1.21 |
| 12:03 | 5.41% | 3.89% | 2763.62M | 1.73 |
| 12:05 | 6.38% | 3.89% | 2766.62M | 2.04 |
| 12:08 | 8.36% | 3.89% | 2764.70M | 2.68 |
| 12:09 | 10.68% | 7% | 5332.13M | 3.42 |
| 12:10 | 15.12% | 8.87% | 6304.86M | 4.84 |
| 12:11 | 23.08% | 15.09% | 10731.04M | 7.39 |
| 12:15 | 33.33% | 18.08% | 12856.34M | 10.67 |
| 12:16 | 43.13% | 34.1% | 24250.74M | 13.8 |
| 12:18 | 37.91% | 35.29% | 25095.05M | 12.25 |
| 12:19 | 59.37% | 35.29% | 25098.40M | 19 |
| 12:20 | 65.51% | 52.72% | 37488.47M | 24.81 |
| 12:21 | 58.39% | 79.58% | 56593.07M | 27.89 |
| 12:27 | 97.81% | 80.35% | 57140.87M | 31.3 |
| 12:28 | 91.53% | 80.35% | 57140.92M | 29.29 |
| 12:29 | 100% | 80.36% | 57145.35M | 32 |
| 12:32 | 91.61% | 80.37% | 57150.45M | 29.32 |
| 12:33 | 100% | 80.37% | 57153.46M | 32 |
| 12:34 | 87.61% | 80.37% | 57151.07M | 28.04 |
| 12:37 | 1.79% | 58.81% | 41821.7M | 27.89 |
| 12:38 | 1.81% | 35.05% | 24923.48M | 12.3 |
| 12:39 | 0.93% | 15.68% | 11147.32M | 6.2 |
| 12:40 | 0.55% | 7.42% | 5278.11M | 3.14 |
| 12:41 | 0.31% | 3.39% | 2412.45M | 1.43 |
| 12:46 | 0.02% | 1.98% | 1410.64M | 1 |
| 12:48 | 0% | 0% | 0M | 0 |
| 12:50 | 0% | 0% | 0M | 0 |
通过以上的指标数据,我们把他放到echats中去查看,因为内存使用量的值比较大,就不参与计算,通过对11:50到12:50这一个小时压测得到的指标数据,可以形成以下折现图。
option = { title: { text: 'TDSQL-C Serverless CCU趋势图' }, tooltip: { trigger: 'axis' }, legend: { data: ['CPU使用率', '内存的使用率', 'CCU算力值', 'Direct', 'Search Engine'] }, grid: { left: '3%', right: '4%', bottom: '3%', containLabel: true }, toolbox: { feature: { saveAsImage: {} } }, xAxis: { type: 'category', boundaryGap: false, data: ["11:50", "11:59", "12:03", "12:05", "12:08", "12:09", "12:10", "12:11", "12:15", "12:16", "12:18", "12:19", "12:20", "12:21", "12:27", "12:28", "12:29", "12:32", "12:33", "12:34", "12:37", "12:38", "12:39", "12:40", "12:41", "12:46", "12:48", "12:50"] }, yAxis: { type: 'value' }, series: [ { name: 'CPU使用率', type: 'line', stack: 'Total', data: ["1.04", "3.77", "5.41", "6.38", "8.36", "10.68", "15.12", "23.08", "33.33", "43.13", "37.91", "59.37", "65.51", "58.39", "97.81", "91.53", "100", "91.61", "100", "87.61", "1.79", "1.81", "0.93", "0.55", "0.31", "0.02", "0", "0"] }, { name: '内存的使用率', type: 'line', stack: 'Total', data: ["0.98", "1.73", "3.89", "3.89", "3.89", "7", "8.87", "15.09", "18.08", "34.1", "35.29", "35.29", "52.72", "79.58", "80.35", "80.35", "80.36", "80.37", "80.37", "80.37", "58.81", "35.05", "15.68", "7.42", "3.39", "1.98", "0", "0",] }, { name: 'CCU算力值', type: 'line', stack: 'Total', data: ["1", "1.21", "1.73", "2.04", "2.68", "3.42", "4.84", "7.39", "10.67", "13.8", "12.25", "19", "24.81", "27.89", "31.3", "29.29", "32", "29.32", "32", "28.04", "27.89", "12.3", "6.2", "3.14", "1.43", "1", "0", "0",] }, ] };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
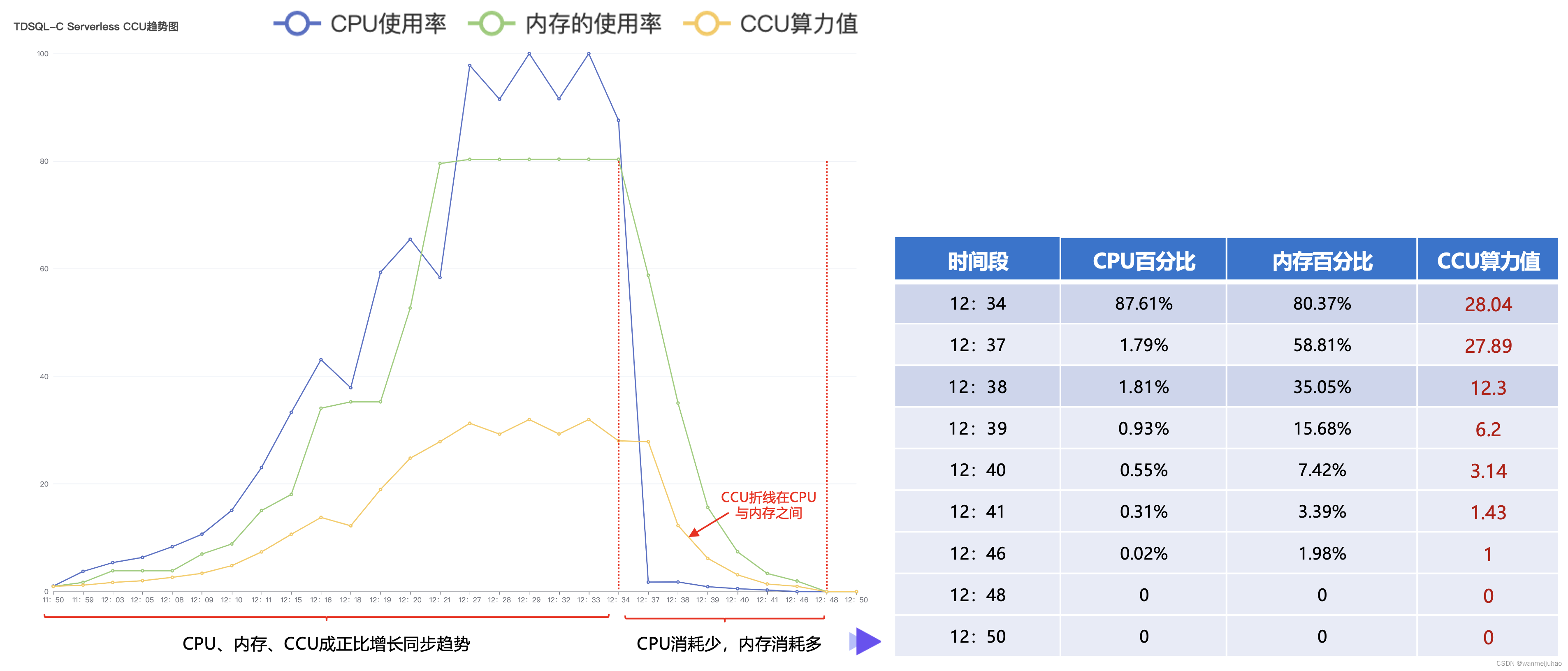
- 前期CPU和内存都在成正比增长的趋势,CCU也是一个成正比的趋势
- 后期CPU急剧下降,而内存的降低幅度没那么快,CCU是与CPU和内存一起有关联的,可以看到CCU的折线在CPU与内存折线之间
在TDSQL-C MySQL Serverless达到波峰的时候,CPU达到100%,顺便测试了一下查询语句,还是能够很快速的访问并得到结果,只要项目中没有大量的慢查询,项目估计还是可以正常的运行的。
六、公司业务导入TDSQL-C MySQL Serverless可行性分析:
公司的业务是做定制化车险的,在创业前期大多采用与第三方机构合作,快速验证商业模式,用以迅速打开市场。
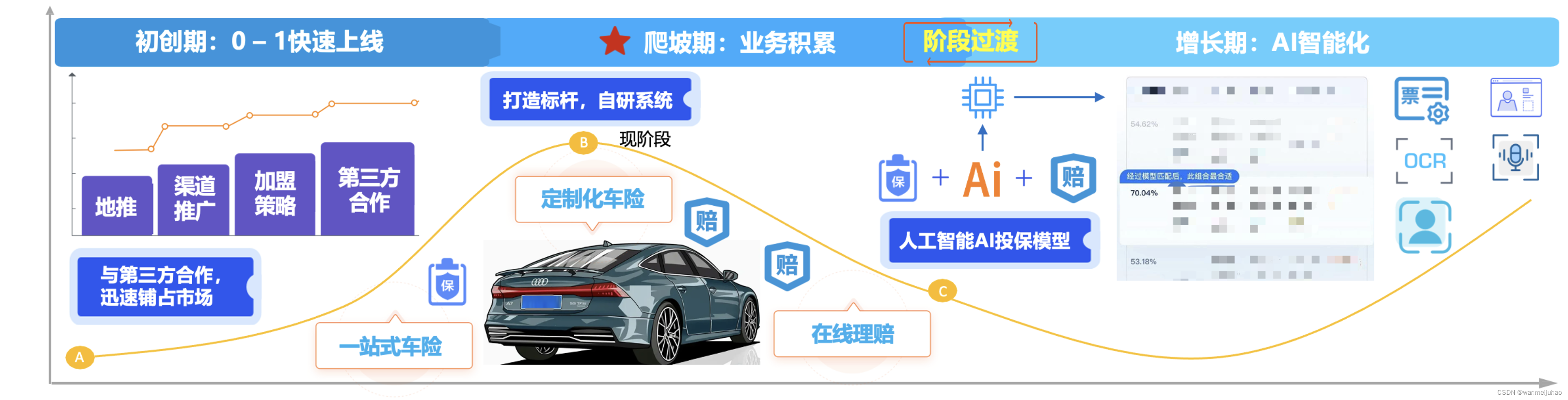
随着业务体系的逐渐完善,公司也慢慢的导入自研的体系,以下是公司可回溯系统的建设体系,对比TDSQL-C MySQL Serverless数据库对比的场景优化思考。

(1). 回溯的场景周期较短,剩余时间不使用也要付费:
开发的某类产品分为投保期和理赔期,投保期一般为2-3个月,等到承保期后,就不再使用了,就是理赔的阶段,这样来看,目前也是按照包年模式来购买的数据库,这样会造成资源的过剩,应该是周期性的资源购买。
(2). 归档后,只有少量的异常案例需要回溯,使用率不高:
可以省出计算节点的费用,只单纯的使用存储量的费用,如果进一步集成COS,可能费用会再一次压缩与缩减。
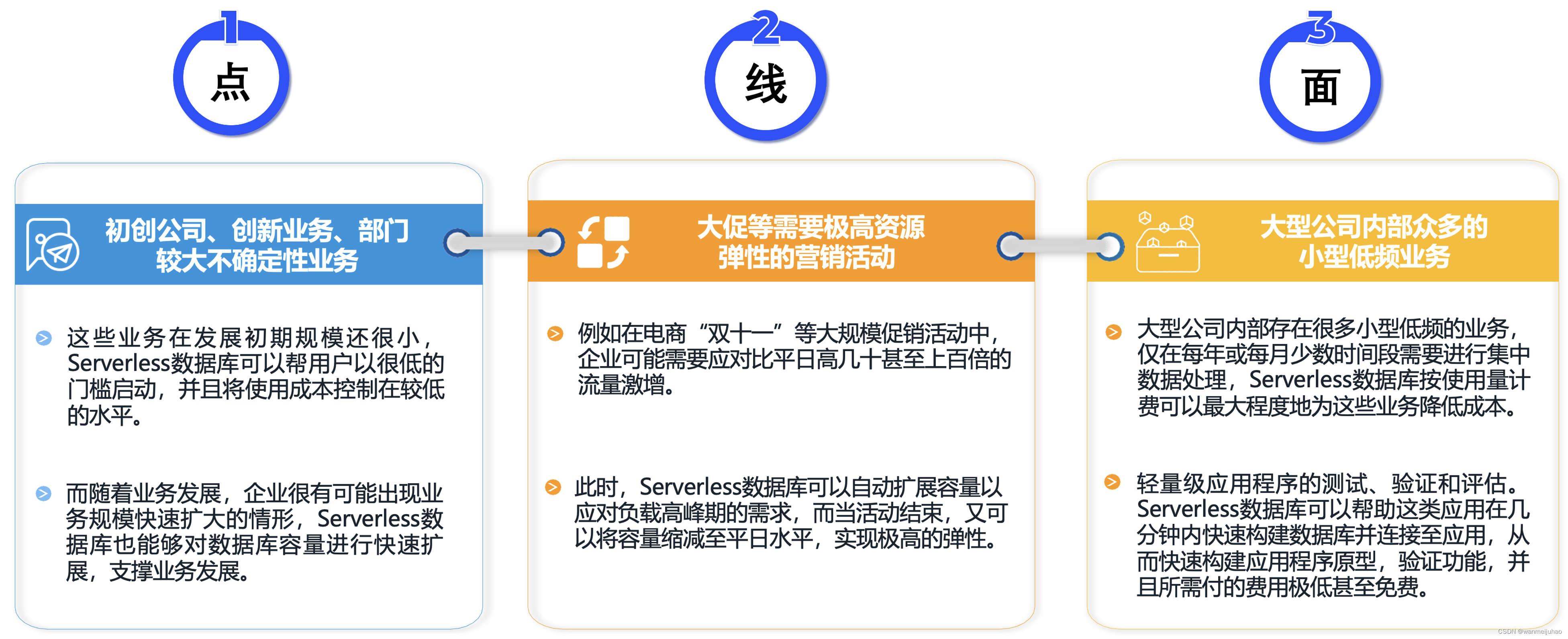
Serverless数据库其它的应用场景:
由于传统企业通常已经预置了大量软硬件资源,以及用户使用习惯不易改变等因素,Serverless数据库在传统企业现有业务中的采用将需要一定的过程,但在以下一些新兴行业企业或新兴业务场景,Serverless数据库正在快速展现其优势,并占据重要位置。
七、总结:
TDSQL-C MySQL Serverless数据库实例不仅提供网络资源、命名空间、存储空间的垂直资源隔离能力,还提供计算资源按需计费的能力,具有资源用量低、简单易用、弹性灵活和价格低廉等优点,赋能用户面向业务峰谷时对计算能力进行快速且独立的扩缩要求,做到快速响应业务变化的同时,合理优化使用成本,进一步助务企业降本增效。
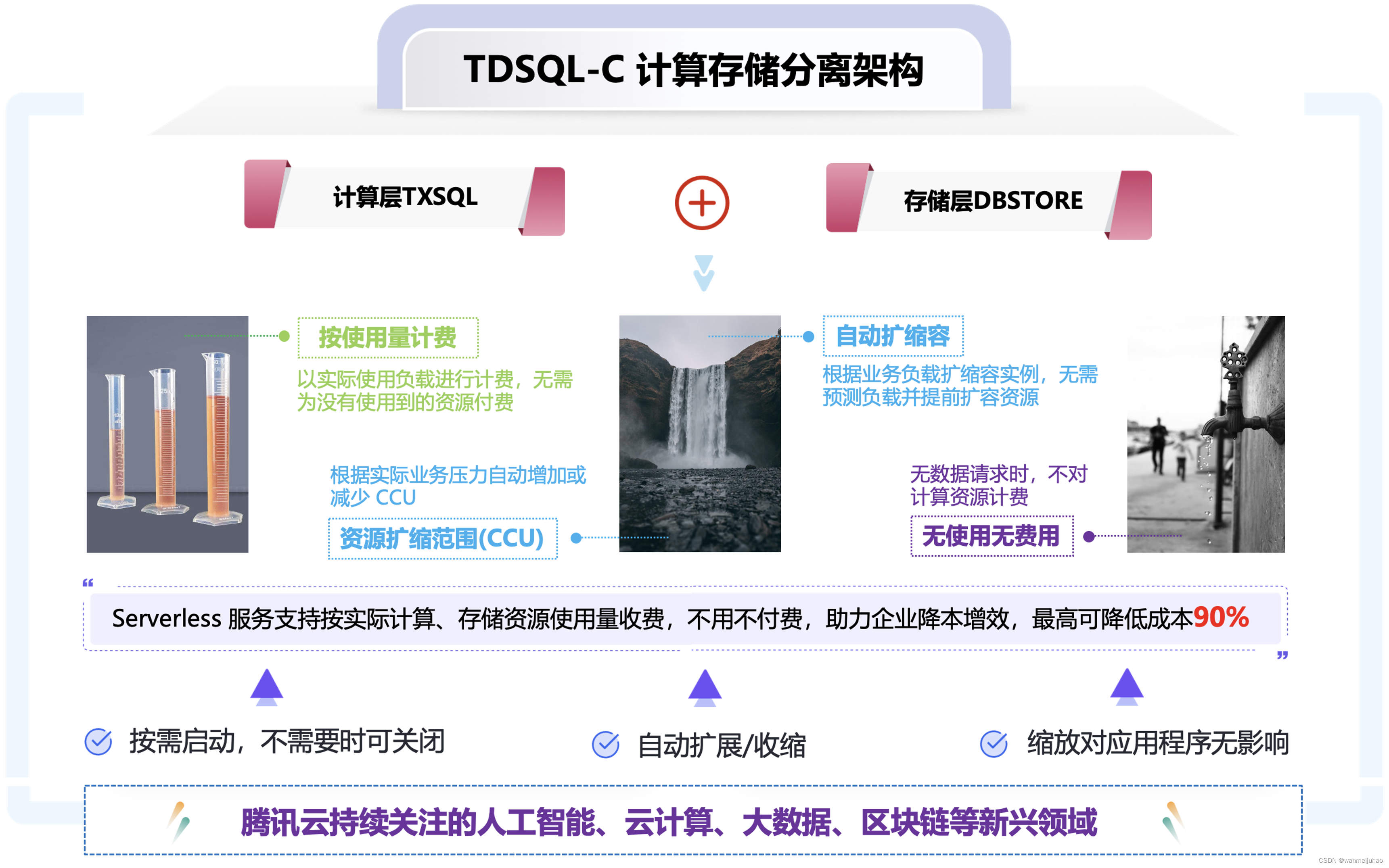
在业务波动较大的场景下,普通数据库实例和TDSQL-C MySQL Serverless数据库实例资源使用和规格变化情况,可以看出普通实例在波谷期浪费的资源较多,在高峰期资源不足会导致客户业务受损,而TDSQL-C MySQL Serverless数据库实例凭借其极致的弹性,完美的支持了客户不同时段的业务负载,并且在最大程度上避免了资源的浪费,节省了大量的成本。


