
热门标签
热门文章
- 1Tensorflow构建自己的图片数据集TFrecords_tensorflow 自己的图片 数组
- 2群晖 Docker版qbittorrent 下载显示错误 解决方法_qbittorrent下载错误
- 3IOS下的横竖屏切换研究_ios 下的横竖屏切换研究
- 4面试经典150题——矩阵置零
- 5 在 Linux 中安装 Cassandra
- 6RuntimeError: Expected all tensors to be on the same device, but found at least two devices
- 7mybatis typehandler的使用_type-handlers-package
- 8ModuleNotFoundError: No module named ‘sklearn‘_modulenotfounderror: no module named 'sklearn
- 9学习会员上线啦,快来看看会有哪些权益吧~_scdn 学员收益:
- 10【个人笔记】OpenCV4 C++ 快速入门 26课_【个人笔记 - 目录】opencv c++ 快速入门 30讲
当前位置: article > 正文
模型如何压缩?使用轻量化的模型压缩技术剪枝(pruning)
作者:IT小白 | 2024-03-05 11:44:41
赞
踩
模型如何压缩?使用轻量化的模型压缩技术剪枝(pruning)
深度学习模型参数太多,本地服务器部署没有问题,但是如果部署到移动端、边缘端,像手机、树莓派等,它们的性能不能满足,所以我们要压缩模型大小,让他们可以部署到边缘端
模型压缩:使用轻量化的模型压缩技术,如剪枝(pruning)和量化(quantization),来减小深度学习模型大小
- 通过剪枝可以去除冗余的权重参数和不必要的神经元,从而减小模型的尺寸。
- 量化可以将浮点数权重参数转换为更小的整数,从而减少存储和计算开销。
可以类比人脑
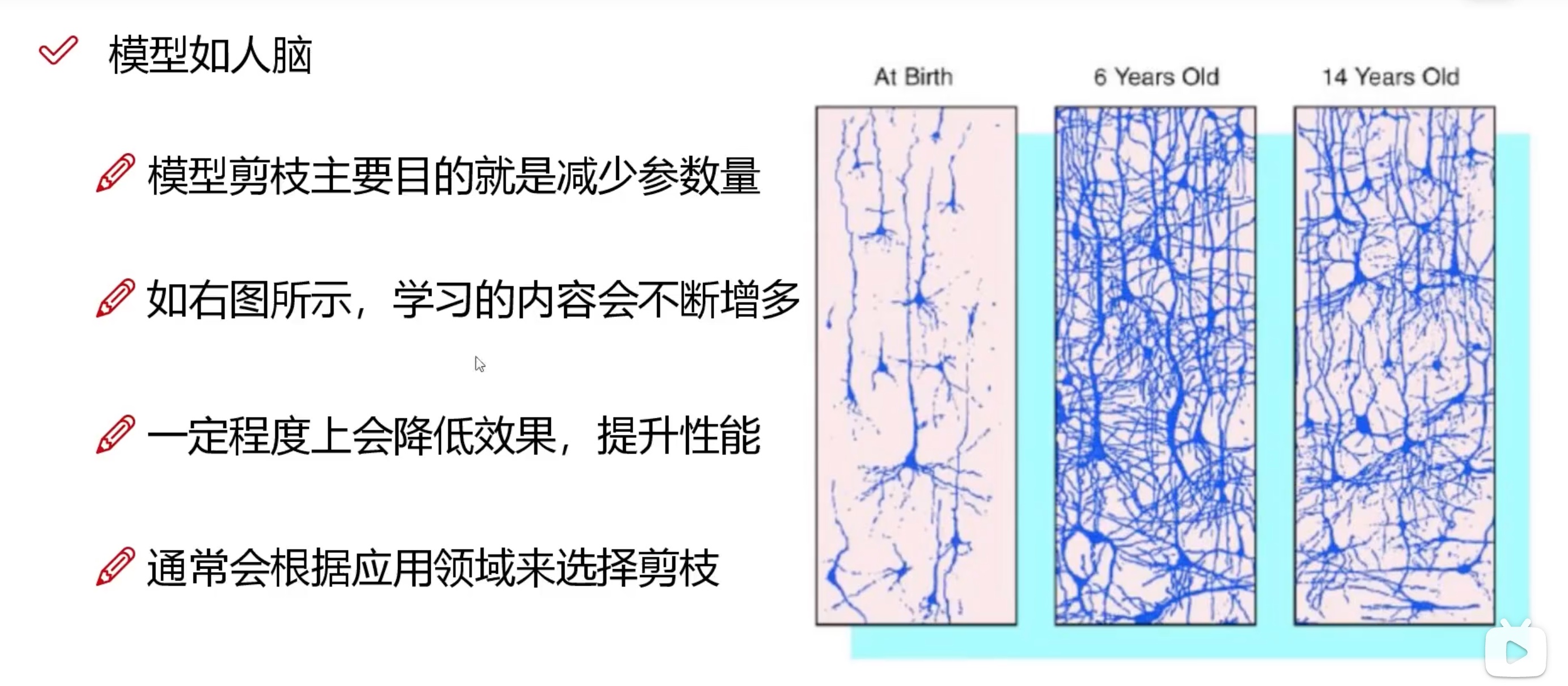
深度学习模型有点玄学,最好还是在一开始设计好模型,比后期做剪枝操作要强
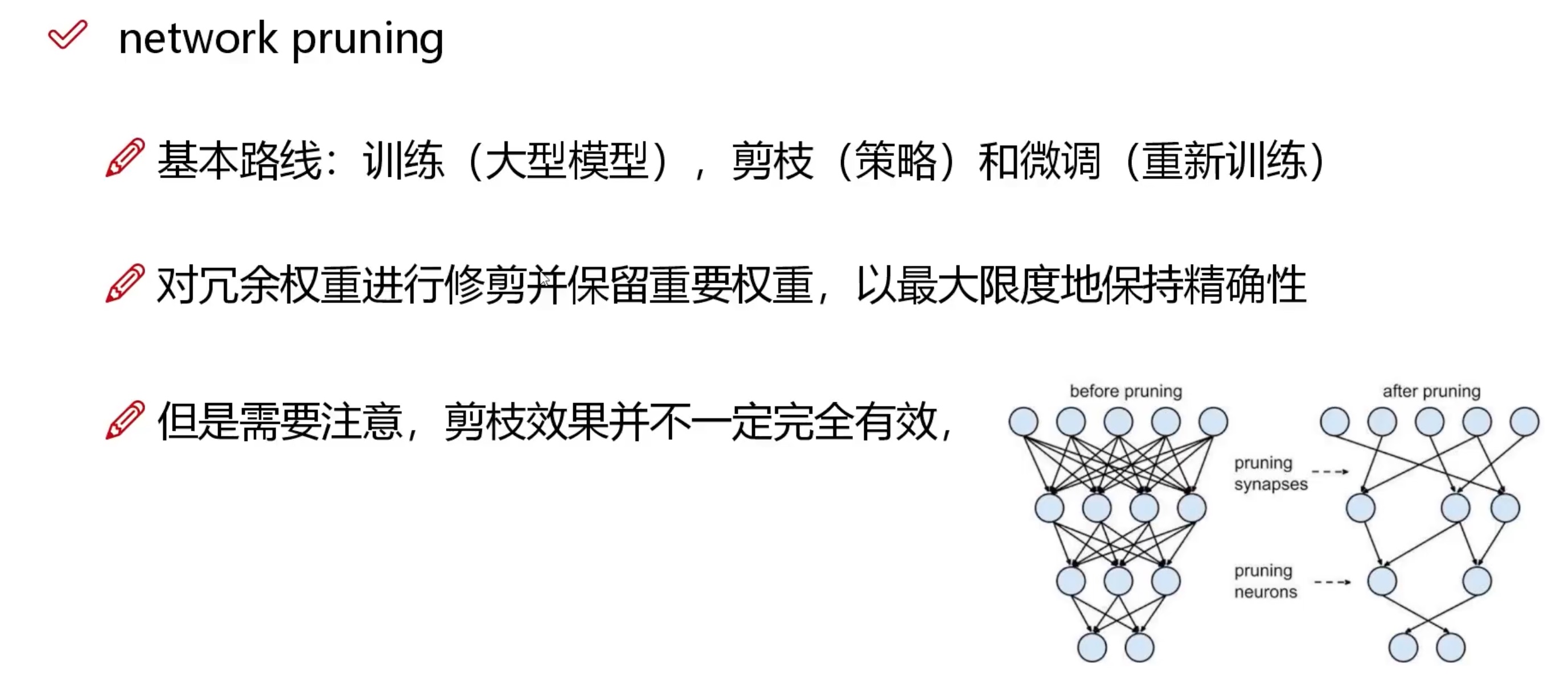
剪枝的一些操作:
-
聚类,效果不好
-
大网络训练作为小网络的先验知识(不常用)
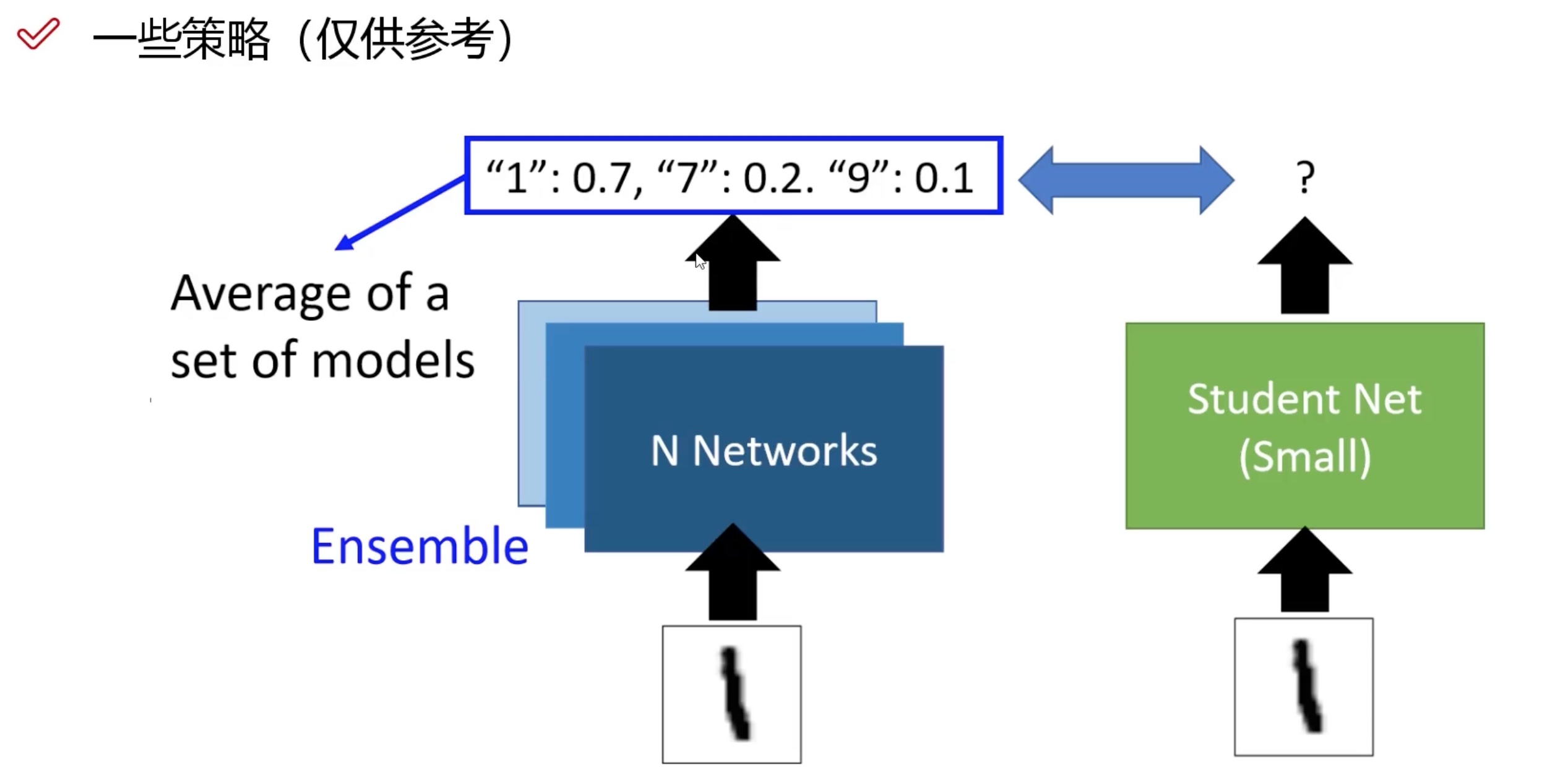
-
SVD,中间加上一个层(两个全连接层之间,减少参数)
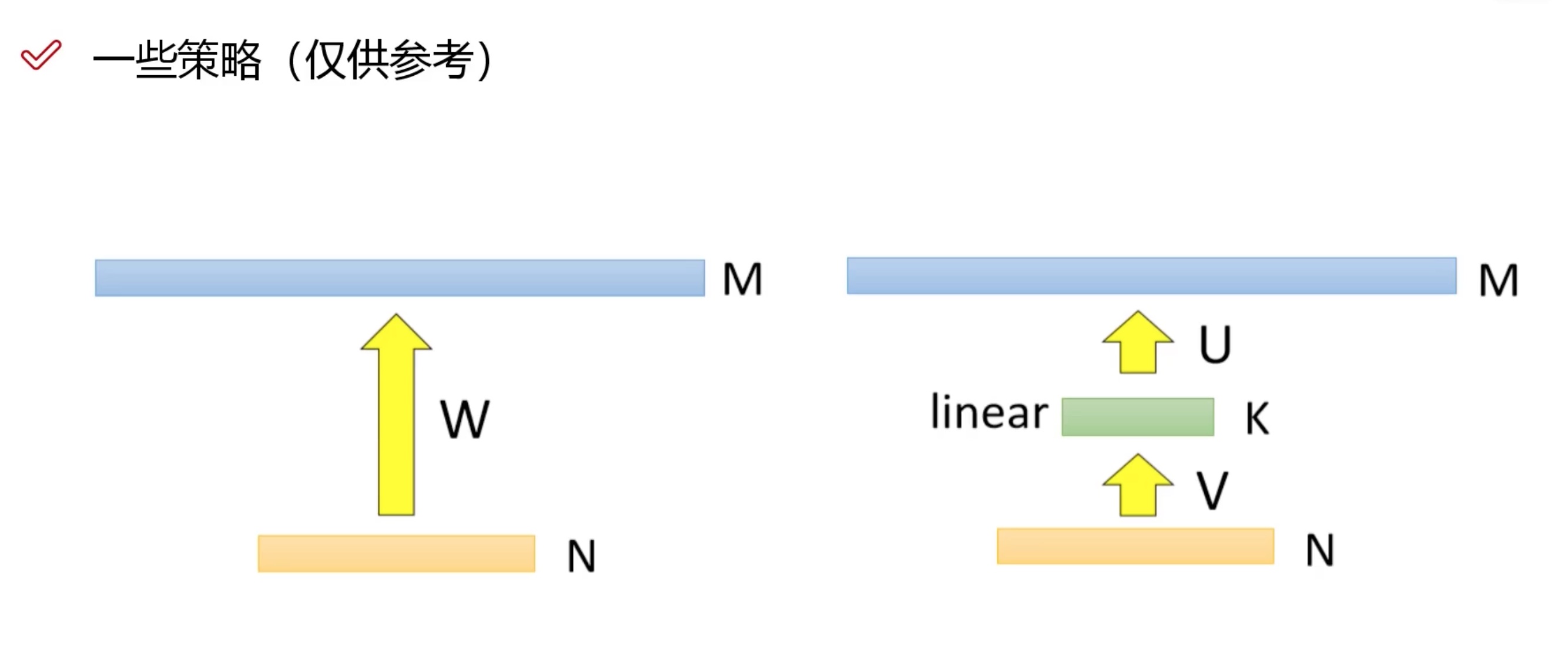
剪枝是什么?

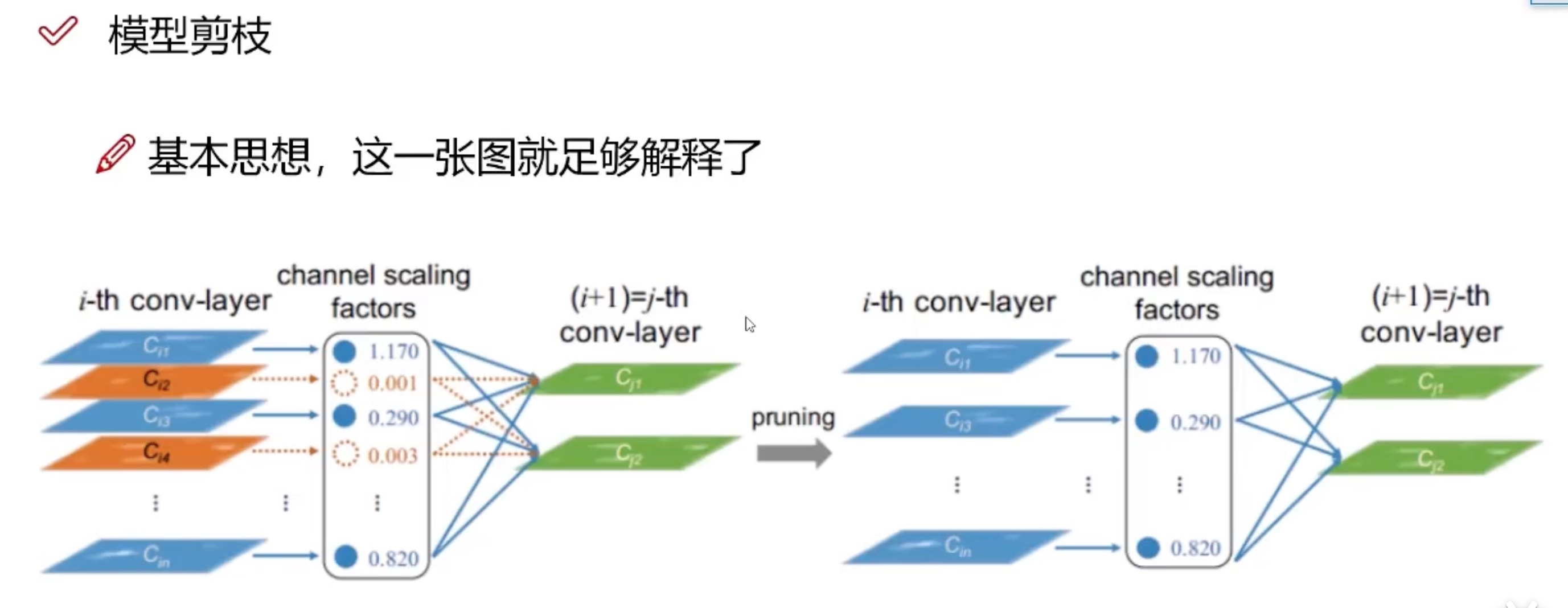
如何减少模型中无用的特征图


常规套路:Conv + BN + Relu激活函数
- BN的作用是为了防止卷积之后的梯度消失或者梯度爆炸


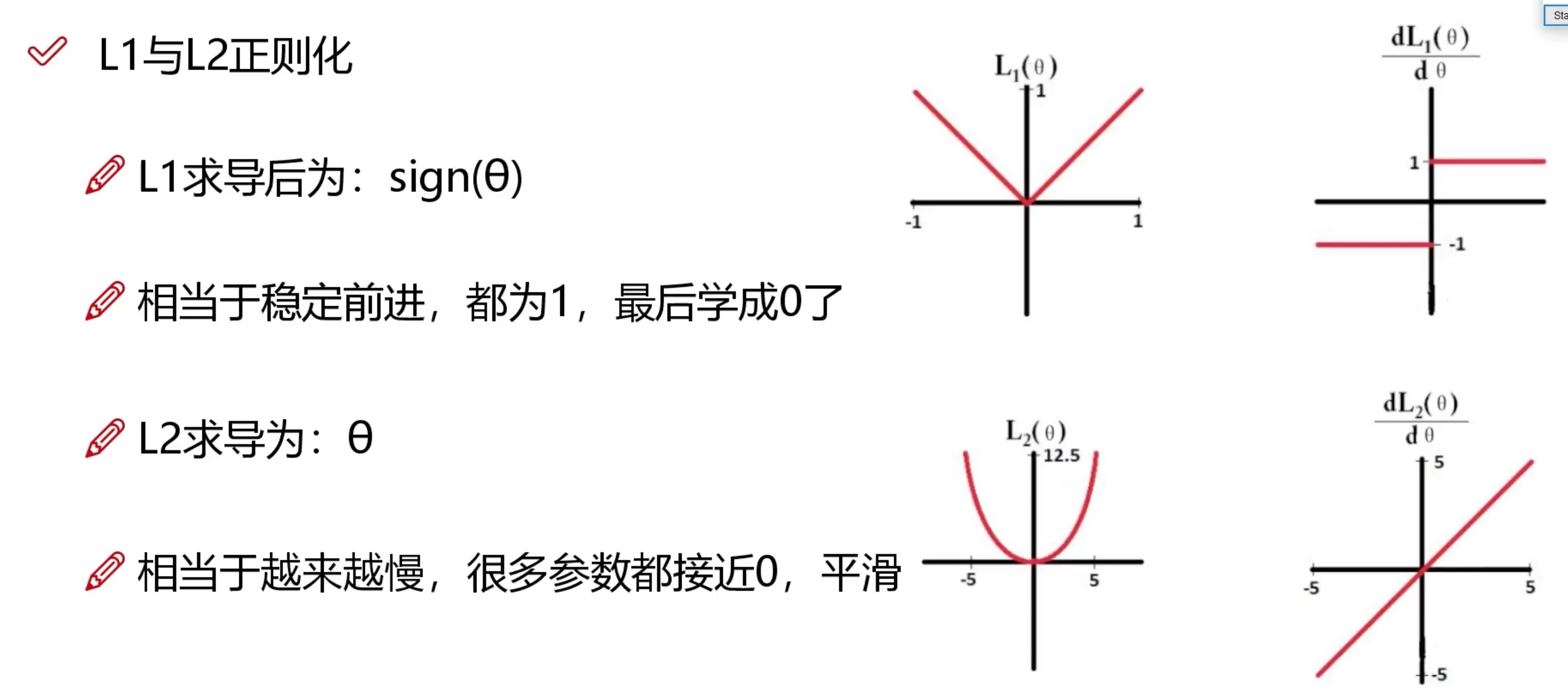
剪枝常用的正则化函数


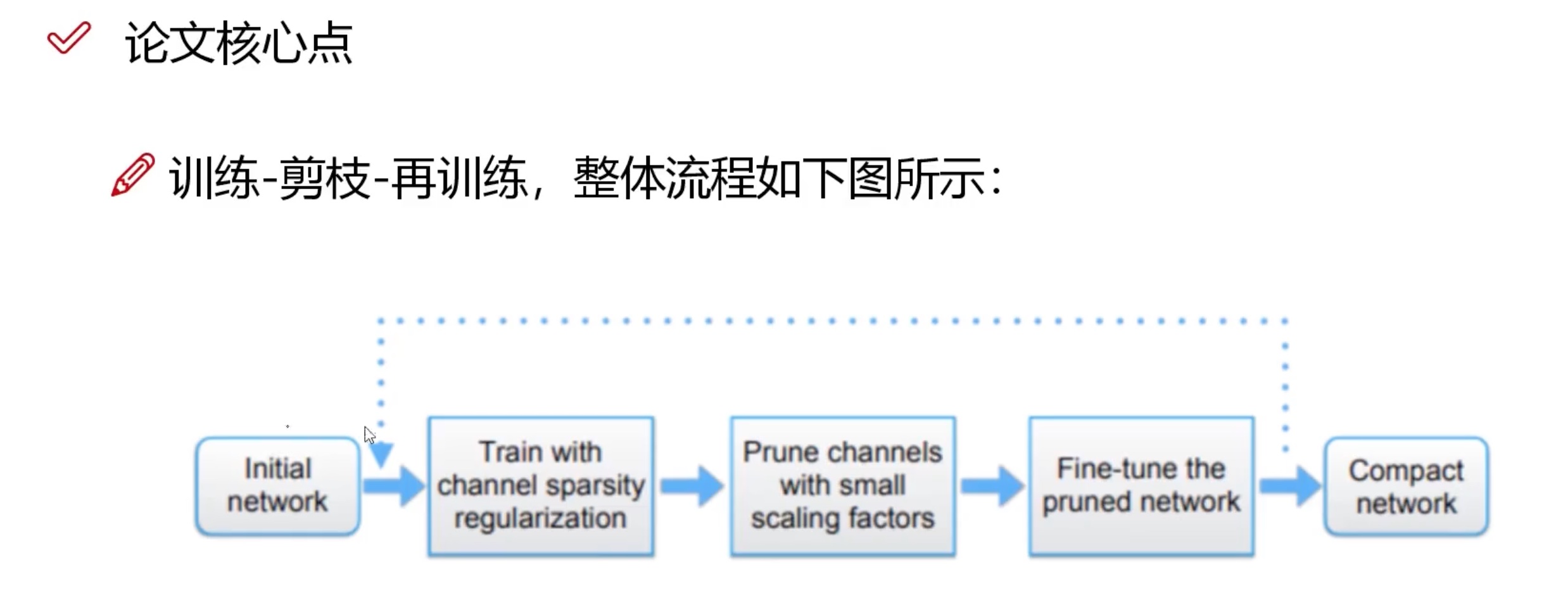
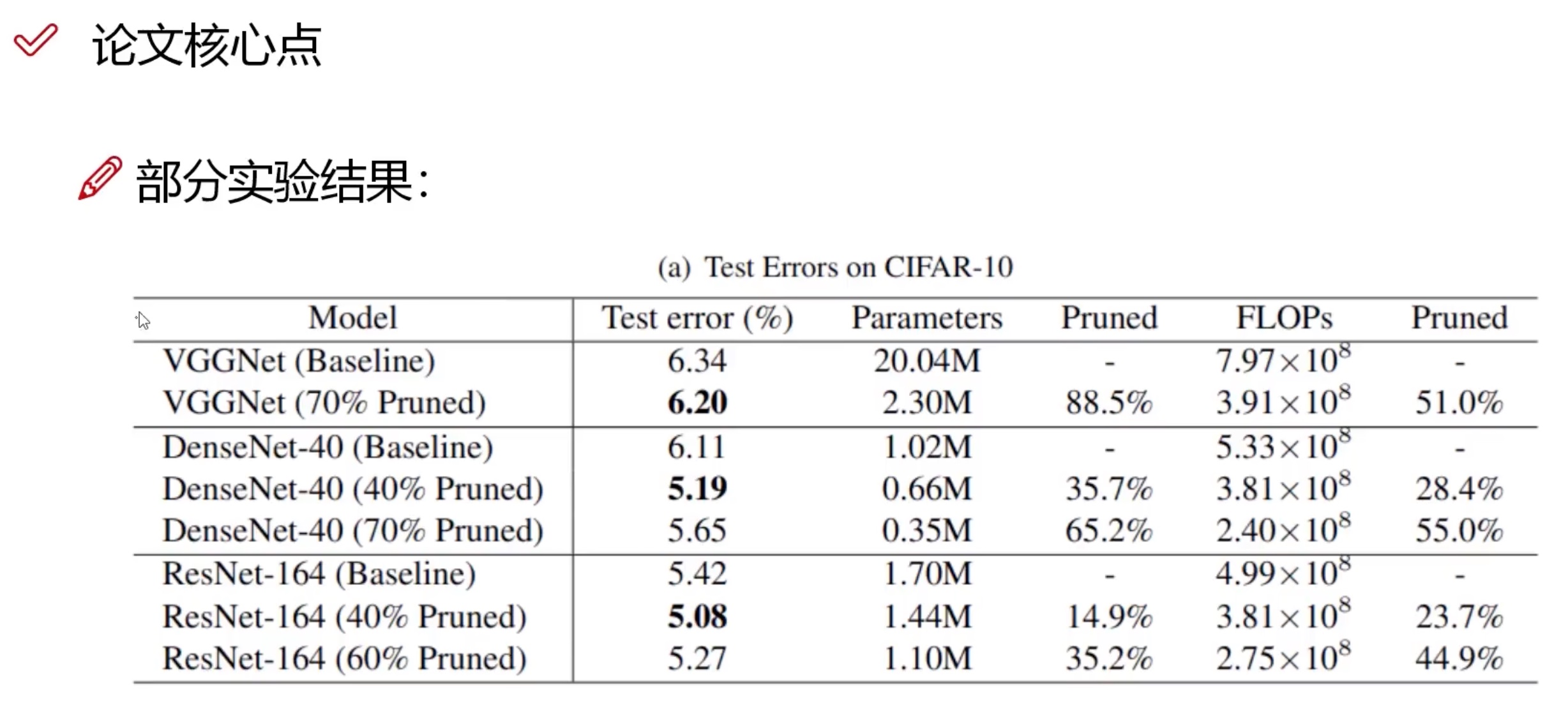
Learning Efficient Convolutional Networks through Network Slimming
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/190780
推荐阅读
相关标签

