
ResNet 残差网络、残差块_resnet中残差模块的组成及功能
赞
踩
在深度学习中,为了增强模型的学习能力,网络的层数会不断的加深,于此同时,也伴随着一些比较棘手的问题,主要包括:
①模型复杂度上升,网络训练困难
②出现梯度消失/梯度爆炸问题
③网络退化,即增加层数并不能提升精度
为了解决网络退化的问题,深度残差网络被提出....
ResNet残差网络是由残差块构建的。
残差块
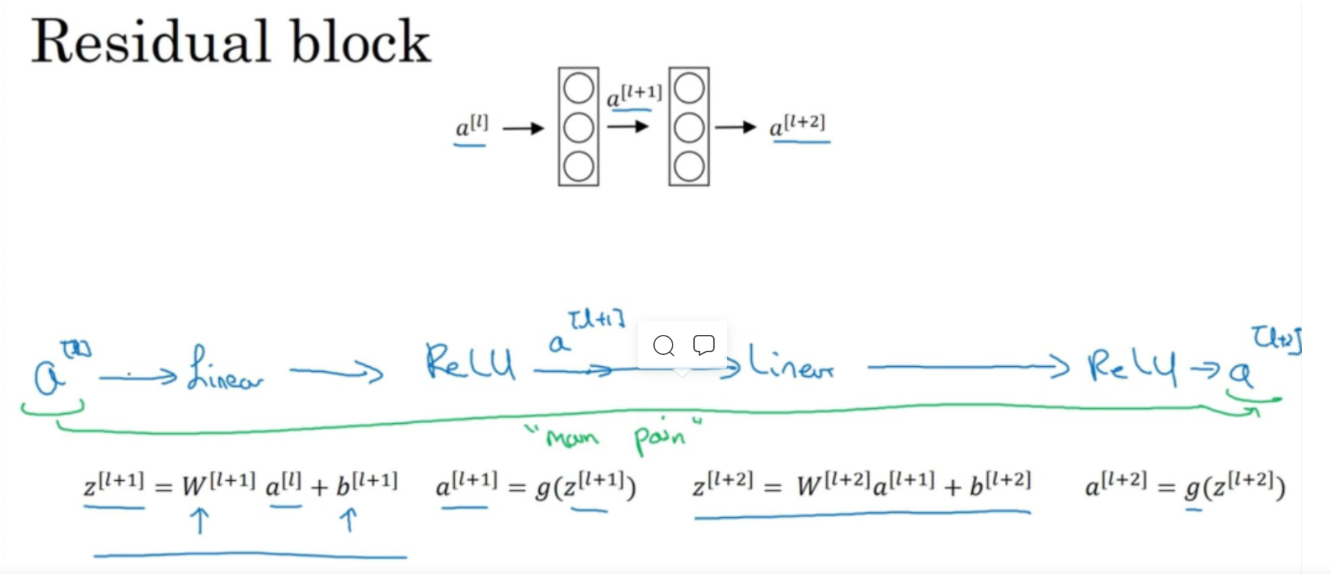
在普通的两层网络中,回顾之前的网络传递过程:
即

那什么是残差块?如下:
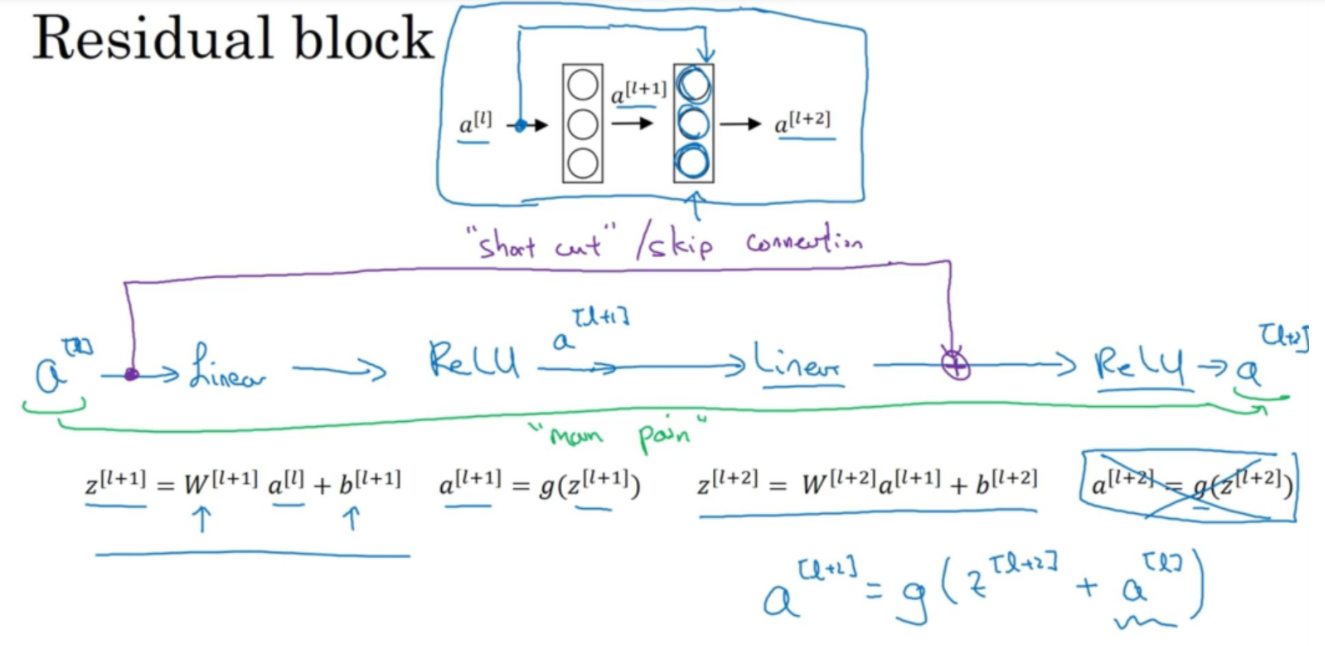
如上图紫色路线所示,在a[l]沿着原来的路线进行传递的基础上,同时将a[l]的值直接往后传递,与z[l+2] 在ReLU激活函数之前叠加,此时a[l+2]的计算公式为:
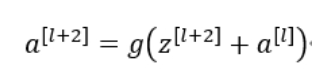
通过以上操作的神经网络就成了“残差块”,有时也称这个过程为 shortcut 或者 skip connection,意思就是a[l]跳过一层或者好几层,直接向后传递的过程。
残差网络
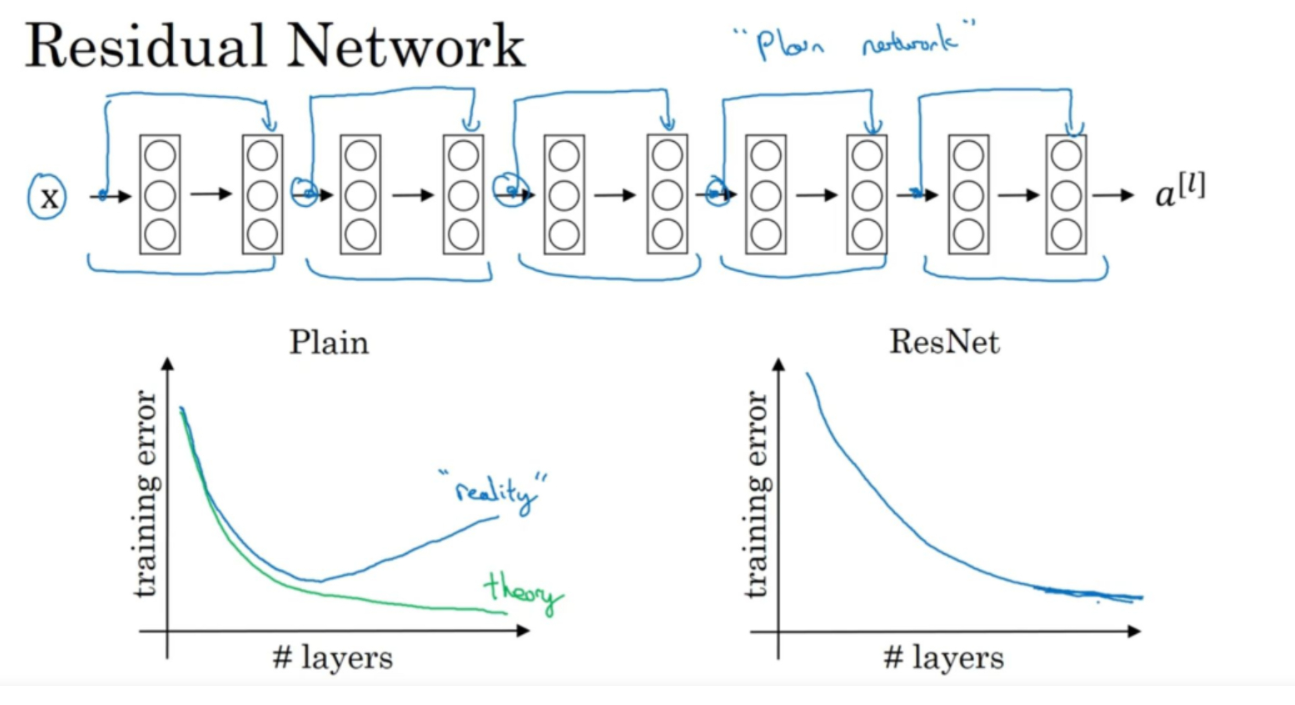
在普通的网络上,通过蓝色线所示的跳跃连接,形成了五个残差块,五个残差块连接在一起组成了残差网络。如果没有使用残差块,在训练网络的时候,在实际上,训练错误会随着网络深度的增加而先减少后增多。但理论上,网络深度越高,训练错误应该越低。其实这是由于随着网络的加深,模型的训练难度越来越大导致的。但假如ResNet之后,会有效的改善深层网络训练难度大的情况。
为什么残差网络有效?
我们了解到,一个网络的深度越深,它在训练集上训练的效率就会有所减弱,这也是有时候我们不希望加深网络的原因。但事实并非如此,至少在训练ResNets网络时,并非完全如此,举例如下:
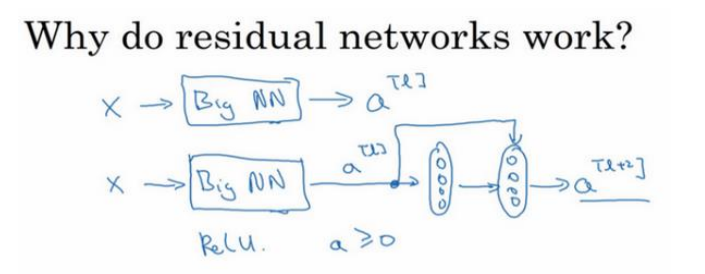
假设有一个大型神经网络Big NN,其输入为X,输出激活值a[l]。假如你想增加这个神经网络的深度,再给这个网络额外依次添加两层,最后输出为a[l+2],可以把这两层看作一个残差块,具有捷径链接的残差快。为了方便说明,我们在整个网络中使用ReLU激活函数,所以激活值都大于等于0,包括输入X的非零值。因为ReLU激活函数输出的数字要么是0,要么是正数。
首先对a[l+2]的值进行分析,即a[l+2] = g(W[l+2]a[l+1] + b[l+2] + a[l]), 其中,z[l+2] = W[l+2]a[l+1] + b[l+2]。 如果使用L2正则化或者权重衰减,会使得W[l+2]和b[l+2]的值有可能被压缩。如果W[l+2] = 0,假设b[l+2] = 0 ,就使得W[l+2]a[l+1] + b[l+2] = 0 ,那么a[l+2] = g(a[l]) = a[l],
因为我们假定使用的是ReLU激活函数,并且所有激活值都是非负的,g[a[l]]是应该勇于非负数的ReLu函数,所以a[l+2] = a[l].
这表明,残差快学习这个恒等式函数并不难,跳跃连接是我们容易得出a[l+2] = a[l]。这意味着,即使给神经网络增加了这两层,它的效率也并不逊色于更简单的神经网络,因为学习恒等函数对它来说很简单。尽管它多了两层,也只把a[l]的值赋值给a[l+2]。 所以给大型神经网络增加两层,不论是把残差块添加到神经网络的中间还是末端位置,都不会影响网络的表现。

当然,我们的目标不仅仅是保持网络的效率,还要提升它的效率。想象一下如果残差块学习到一些有用的信息,那么它可能比学习恒等函数表现得更好。而不含残差块和跳跃链接的深度神经网络在层数增加的时候,训练难度增大,训练效果更差。
残差网络起作用的主要原因就是残差块学习恒等函数非常容易,可以使得网络性能不受影响,甚至在残差块学习到好的信息的时候,可以提高效率,因此创建类似残差网络可以提高网络性能。

