
热门标签
热门文章
- 1Linux命令之将标准输入转为命令行参数xargs_linux如何控制台中的输出值变为参数
- 2php落寞了,日渐唱衰的php是否真的已经不堪一击了?
- 3单调栈 c++实现_单调栈 c语言代码
- 4HarmonyOS应用开发基础认证(2024.01)_发送网络数据请求需要导入以下哪个模块
- 5Android 意图(Intent) 理论详解_intent意图对象的__ _ _方法用于指定意图的动作行为
- 6反爬虫技术
- 780端口攻击_内网端口转发工具的使用总结
- 8深入探索Kafka底层原理
- 9pyLDAvis安装和使用 | AttributeError: module ‘pyLDAvis‘ has no attribute ‘gensim‘ | 可视化结果导出为独立网页
- 10香农编码 哈夫曼编码 费诺编码的比较
当前位置: article > 正文
总结一下利用pandas进行条件筛选的几个方法_pandas筛选符合条件的数据
作者:IT小白 | 2024-03-08 11:50:25
赞
踩
pandas筛选符合条件的数据
首先创建一个表:
- df = pd.DataFrame({'A':[100, 100, 200, 300, 400],
- 'B':['a', 'a', 'c', 'd', 'e'],
- 'C':[3, 2, 1, 5, 4]})
生成出来的表如下所示:

1)找出df中A列值为100的所有数据
df[df.A==100]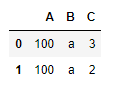
这里也可以是小于(<)、大于(>)、小于等于(<=)、大于等于(>=)、不等于(!=)等情况。
2) 找出df中A列值为100、200、300的所有数据
- num = [100, 200, 300]
- df[df.A.isin(num)]

3) 找出df中A列值为100且B列值为‘a’的所有数据
df[(df.A==200)&(df.B=='c')]
4)找出df中A列值为100或B列值为‘b’的所有数据
df[(df.A==100)|(df.B=='b')] 
这里需要注意的是,多条件筛选的时候,必须加括号'()'。
5) 需要删除B列的重复行,同时保留重复行中C列最大值所在的行
df.sort_values("C", ascending=False).drop_duplicates("B", keep='first').reset_index(drop=True)
可以看到,B列数据只有一个‘a’数据了,这句代码的意思是先对C列进行降序排序,然后删除B列重复的数据,keep参数是只保留第一个,因为是降序排序,第一个B列的C列数据相对于其他重复的C列数据是最大的(有点绕口)
参考:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/209903
推荐阅读
相关标签

