
- 1Mac苹果电脑清理软件哪个好及CleanMyMac X优势对比_cleanmymacx中文版 区别
- 2如何让pycharm的shell环境代码编写同python文件中一样丝滑_pycharm 编写 shell
- 3macOS Sonoma 14.4(23E214)发布[附黑苹果/Mac系统镜像]_macos sonoma 14.4下载
- 4python数据结构实验设计(单链表):通讯录管理_python数据结构课程设计
- 5Micropython板学习笔记_mircopython from pyb
- 6(后续更新)【微信小程序】毕业设计 租房小程序开发实战,零基础开发房屋租赁系统小程序_微信小程序 房源展示
- 7银河麒麟服务器操作系统V10搭建内网YUM源服务器_麒麟系统安装yum
- 8subprocess.run方法
- 9解决selenium错误,升级chromedriver到121.0.6167.140_chrome121.0.6167.140驱动
- 10OpenHarmony APP开发基础_openharmony native app
NLP-自然语言处理-文本分类-总结-Tensorflow2.0版_文本分类模型 tensorflow2
赞
踩
一、文本分类综述
1、基本概念
(1)定义
在给定的分类体系中(eg:文档P(可能含有标题t)),将文本分到指定的某个或某几个类别当中
(2)分类对象
短文本(句子/标题/商品评论)、长文本(文章)
(3)实质
使用包含文本文档和标签的数据集来训练一个分类器。
(4)应用场景及其对应标签
| 应用场景 | 对应标签 |
|---|---|
| 情感分析(Sentiment Analyse) | (积极、消极、中性) |
| 主题分类(Topic Labeling) | (金融、体育、军事、社会) |
| 问答任务(Question Answering) | (是、否) |
| 意图识别(Dialog Act Classification) | (天气查询、歌曲搜索、随机闲聊) |
| 自然语言推理(Natural Language Inference) | (导出、矛盾、中立) |
| 垃圾邮件判断 | (是、否) |
| 新闻分类news classification (NC) |
(5)分类模式
binary:2分类问题,(属于或不属于)
multi-class:多分类问题
multi-label:多标签问题,(一个文本可以属于多类)
(6)NLP发展史
- 神经语言模型
- 多任务学习
- 词嵌入
- NLP神经网络
- sequence2sequence模型
- 注意力机制
- 善于记忆的网络
- 预训练语言模型
2、文本分类总流程
(1)文本清洗与预处理
分词==(jieba、tokenizer)==
去停用词stopwords==(re)==
词性标注==(jieba)==
处理大小写Capitalization
Tokenization(将文本流分为单词、短语)
Gensim(将原始文本转为所能理解的稀疏向量)
(2)降维
- 主成分分析法(PCA)
- 线性判别分析(LDA)
- 非负矩阵分解(NMF)
(3)文本特征提取(构建词向量空间):
TfidfVectorizer = CountVectorizer + TfidfTransformer。
①CountVectorizer(Sklearn)
CountVectorizer得到的是词频(term frequency)特征
- 统计词汇出现的次数,并用词汇出现的次数的稀疏矩阵来表示文本的特征。它会统计所有出现的词汇,每个词汇出现了多少次,最后得到的稀疏矩阵的列就是词汇的数量(每个词汇就是一个特征/维度)
from sklearn.feature_extraction.text import CountVectorizer
ctv = CountVectorizer()#使用默认
"""参数主要
(1)ngram_range=(x,y)。其中,x,y 为数字,即n元语法。
(2)stop_words = stop_words。其中,stop_words是从停用词文件中读取的list,每行一个停用词。
(3)max_features = n。其中,n为词汇表的数量。表示根据词频大小降序排列后的TOP n词汇数。"""
需要fit_transform
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
②TF-IDF(与CountVectorizer很像)
TfidfVectorizer就像一个给词频term frequency加权了一个作用
- TfidfVectorizer提取的特征是:在一个文本中各个有效词汇对应的TFIDF值是多少,同时,每个文本特征向量会自动进行normalization(归一化)操作。
from sklearn.feature_extraction.text import TfidfVectorizertfv = TfidfVectorizer()
"""
ngram_range=(x,y)。其中,x,y 为数字,即n元语法。
stop_words = stop_words。其中,stop_words为自己从停用词文件中获取到的。
max_features = n。其中,n为词汇表的数量。表示根据词频大小降序排列后的TOP n词汇数。"""
- 1
- 2
- 3
- 4
- 5
③BoW(从语料库中统计词频)
④词嵌入Word_Embedding:word2vec, FastText、Glove
⑤语法词表示:N-gram
⑥Word2Vec==(用gensim)==:CBoW和Skip-gram
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x2P1MMaQ-1641710073816)(/Users/duanyuqing/Library/Application Support/typora-user-images/image-20220107002442037.png)]
# 生成Word2Vec模型
model = gensim.models.Word2Vec(sentences, size = 50, sg=1, min_count= 3, window = 8, iter = 20 )
"""min_count用于修剪内部字典(Prune the Internal Dictionary)
size:是gensim Word2Vec将词汇映射到的N维空间的维度数量(N)。
sg:是模型训练所采用的的算法类型:1 代表 skip-gram,该模型从上下文语境(context)对目标词汇(target word)的预测中学习到其词向量的表达;0代表 CBOW,该模型从目标词汇(target word)对上下文语境(context)的预测中学习到其词向量的表达
window:控制窗口,它指当前词和预测词之间的最大距离
"""
#打印模型(反映模型中的参数)和词汇列表(仅展示按词汇的首字母进行排序的前50个词汇):
print(model)
print(list(model.wv.vocab)[:50])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
⑦Glove
(4)分类算法构建(机器/深度学习)
机器学习:
朴素贝叶斯NB,随机森林模型(RF),SVM分类模型,KNN分类模型,Voting、Stacking、神经网络分类模型、逻辑回归LR、决策树(DT)、GBDT/XGBOOST、集成算法Boosting/Bagging
深度学习 全连接神经网络(DNN)、卷积神经网络(CNN)、循环神经网络(RNN)、 GRU、LSTM、BiLSTM
Fasttext、TextCNN、textRNN、Attention、Bert
"""采用Sequential方法搭建——按照顺序搭建——————单输入单输出——————简单""" model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ]) """采用Functional API方式搭建————工业常用""" #输入,构建模型 inputs = keras.Input(shape=(28, 28, 1), name="img") x = layers.Conv2D(16, 3, activation="relu")(encoder_input) x = layers.Conv2D(32, 3, activation="relu")(x) x = layers.MaxPooling2D(3)(x) x = layers.Conv2D(32, 3, activation="relu")(x) x = layers.Conv2D(16, 3, activation="relu")(x) outputs = layers.GlobalMaxPooling2D()(x) model = keras.Model(inputs=inputs, outputs=outputs, name="model") """模型编译(选择优化器、损失函数、评价指标)""" model.compile(optimizer='adam',loss='sparse_categorical_crossentropy', metrics=['accuracy']) """查看模型""" model.summary()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
(5)训练并评价分类结果
机器学习———①训练fit(x,y)
#训练fit
clf = clf.fit(X, y)
#转换transform
- 1
- 2
- 3
- 4
机器学习———②预测predict(x_test)
机器学习———③标准cross_val_score(clf, X, y, cv=5)和cross_validate
scores = cross_val_score(clf, X, y, cv=5)
scores = cross_validate(clf, X, y, scoring=scoring)#返回一个字典
- 1
- 2
机器学习———④词汇相似性查询任务
获取词汇相关的前n个词语,当positive和negative同时使用的话,就是词汇类比 (Word Analogy )。
model.wv.most_similar(positive=['文本挖掘', '汽车'], negative=['内容'], topn=20)
- 1
找出与其他词差异最大的词汇
model.wv.doesnt_match("舆情 互联网 媒体 商业 场景 咨询 ".split())
- 1
接近词汇A更甚于词汇B接近词汇A的【所有】词汇,按相似度由高到低降序排列
model.wv.closer_than('微博','社会化媒体')
#'微博'是词汇A,'社会化媒体'是词汇B
- 1
- 2
找到前N个最相似的单词:similar_by_word
基于cosine余弦计算词汇之间的相似度,数值越大代表相似度越高
model.wv.similarity('微博', '数据')
model.wv.similarity('social_listening', '社会化媒体')
- 1
- 2
深度学习———①模型训练model.fit()
"""使用history就是为了能够callback每个epoch训练"""
history = model.fit(x_train, y_train, batch_size=64, epochs=2, validation_split=0.2,)
#或者选择val的数据集:validation_data=(x_val, y_val)
- 1
- 2
- 3
深度学习———②模型评估和预测(推断)[Model.evaluate()]和 [Model.predict()]
"""模型评估————输入:test_data 和 label,输出:loss和accuracy"""
results = model.evaluate(x_test, y_test, batch_size=128)
"""模型预测————输入:test_data,输出:预测的label"""
predictions = model.predict(x_test[:3])
- 1
- 2
- 3
- 4
深度学习———③模型评价指标
- Accuracy
- Loss
二、基础结构
文本分类包含两大基础结构:
1、特征表示
(1)目的
让将文本转变成一种能够让计算机更容易处理的形式,同时减少信息的损失。
(2)表示方法
①BoW词袋模型(Bow of Words)
用词典大小的向量来表征文本,每个值代表该词在文中出现的次数
该方法忽略了文本当中的词序
②TF-IDF词频-逆文档频率
使用词频和逆文档频率来建模文本
③N-gram
将相邻的文字和词组信息纳入到表征的词典当中
def create_ngram_set(input_list, ngram_value=2):
"""从整数列表中提取一组n-gram
eg: create_ngram_set([1, 4, 9, 4, 1, 4], ngram_value=2)
{(4, 9), (4, 1), (1, 4), (9, 4)}
eg: create_ngram_set([1, 4, 9, 4, 1, 4], ngram_value=3)
[(1, 4, 9), (4, 9, 4), (9, 4, 1), (4, 1, 4)]
"""
return set(zip(*[input_list[i:] for i in range(ngram_value)]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
④One-hot独热编码
二分类变量作为二进制向量的表示,构建向量,除了本身单词位置是1,其余都是0
one-hot 编码仅仅只是将词符号化,不包含任何语义信息
one-hot 的缺点如下:
- 无法表达词语之间的关系
- 这种过于稀疏的向量,导致计算和存储的效率都不高
⑤Word2Vec(无监督的)
Word2vec使用局部上下文信息来获取词向量。
⑥Glove词向量
Glove采用了局部上下文信息和全局统计特征。
2、分类模型
(1)机器学习模型
特征工程+(分类器)算法(Naive Bayes/SVM/LR/KNN……)
- 依赖于人工获取的文本特征,虽然模型参数相对较少,但是在复杂任务中往往能够表现出较好的效果,具有很好的领域适应性。
- 总结:学习预定义的特征表示,其中人工特征是问题难点
NB朴素贝叶斯、SVM支持向量机、KNN K近邻、DT决策树、RF随机森林
集成模型:集成学习是指通过将多个弱分类器的分类结果进行整合,获得比单个弱分类器更好效果的机器学习方法。
bagging中的各个弱分类器取值是相互独立的、无关的,常使用有放回抽样实现。
boosting中的弱分类器是在基分类器/前一个分类器的基础上通过迭代不断优化/调整出来
(2)深度学习模型
词向量+模型(FastText/TextCNN/TextRNN/TextRCNN)
- 深度学习模型结构相对复杂,不依赖与人工获取的文本特征,可以直接对文本内容进行学习、建模,但是深度学习模型对于数据的依赖性较高,且存在领域适应性不强的问题。
ReNN(Relu-embedded Neural network)规则嵌入神经网络
MLP(Multi-Layer Preceptron)多层感知机
RNN(Recurrent Neural Network)循环神经网络
CNN(Convolutional Neural Network)卷积神经网络
Attention注意力机制
Transformer
BERT
三、传统文本分类流程(机器学习)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PjsTVkhm-1641710073818)(/Users/duanyuqing/Library/Application Support/typora-user-images/image-20220106052513566.png)]
1. 准备和加载数据集:
第一步:准备数据集,包括加载数据集和执行基本预处理,然后把数据集分为训练集和验证集。导入Sklearn的包使用
将下载的数据加载到包含两个列(文本和标签)的pandas的数据结构(dataframe)中。
数据清洗和预处理
(1)英文
-
非英文部分
html、json等格式,提取出文本数据
- 文本泛化:数字、表情符号、网址……
-
拼写检查更正
-
词干提取(steming)、词形还原(lemmatization)
has/had/having->have am/is/are->is isn’t->is not
-
大写转小写
-
去停用词
a, to, the, according, any…
(2)中文——文本分词、去停用词、编码
-
非中文部分
html、json等格式,提取出文本数据
- 文本泛化:数字、英文、网址……
-
中文编码问题(one-hot、LabelEncoder)
-
中文分词
jieba分词、nltk、SnowNLP……
举例jieba分词代码
-
import jieba jieba.enable_parallel() #并行分词开启 data['文本分词'] = data['正文'].apply(lambda i:jieba.cut(i) ) data['文本分词'] =[' '.join(i) for i in data['文本分词']]- 1
- 2
- 3
- 4
- 5
- 6
-
去停用词stopwords
-
- 啊、哎、哎哟、但是、不如……
-
词语替换
-
- 俺->我,俺们->我们,装13->装逼
- 禾斗匕匕->科比,孬->不好,灰机->飞机
- CEO->首席执行官,Tencent->腾讯
2、特征工程:
第二步是特征工程,将原始数据集被转换为用于训练机器学习模型的平坦特征(flat features),并从现有数据特征创建新的特征。
文本表示
特征提取
(1)文本表示
目的:是把文本预处理后的转换成计算机可理解的方式
方法:词袋模型(BOW, Bag Of Words)或向量空间模型(Vector Space Model)
缺点:忽略文本上下文关系,每个词之间彼此独立,并且无法表征语义信息。
词袋模型:高纬度、高稀疏性
示例: ( 0, 0, 0, 0, … , 1, … 0, 0, 0, 0)
解决 向量空间模型通过特征项选择降低维度,通过特征权重计算增加稠密性。
(2)特征提取
向量空间模型的文本表示方法的特征提取对应特征项的选择和特征权重计算两部分
基本思路:根据某个评价指标独立的对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。
评价指标:文档频率、互信息、信息增益、χ²统计量等
(3)基于语义的文本表示
方法:LDA主题模型、LSI/PLSI概率潜在语义索引
3、模型训练
最后一步是建模,利用标注数据集训练机器学习模型。
分类器——统计分类方法
朴素贝叶斯分类算法(Naïve Bayes)、KNN、SVM、最大熵和神经网络
主要介绍集成学习的方法(采用Sklearn)
(1)集成学习sklearn.ensemble
- VotingClassifier分类问题:
用多个模型对样本进行分类,以“投票”的形式,投票最多者为最终的分类。
Hard Voting:使用预测的Label进行多数决定投票
Soft Voting:根据预测概率和的argmax来预测Label
代码展示:
#选择3个分类器,分别为逻辑回归、随机森林、朴素贝叶斯
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(n_estimators=50, random_state=1)
clf3 = GaussianNB()
eclf = VotingClassifier(
estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
voting='hard')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- VotingRegressor回归问题
对不同模型得出的结果取平均或加权平均
# Training classifiers
#选择3个,回归器,梯度提升树、随机森林回归、线性回归
reg1 = GradientBoostingRegressor(random_state=1)
reg2 = RandomForestRegressor(random_state=1)
reg3 = LinearRegression()
ereg = VotingRegressor(
estimators=[('gb', reg1), ('rf', reg2), ('lr', reg3)])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- Stacking(分类:StackingClassifier 回归:StackingRegressor)
本质上是分层的结构。
第一层是k折交叉的训练集,针对于每一折,由除自己以外的其他的训练数据训练出模型,并以此模型对这一折进行预测。
按照此流程进行k次之后,我们得到了用不同模型预测训练集标签的结果,按顺序罗列之后作为第二层的训练集。再用k次训练的模型预测测试集标签,将得到的结果除以k取平均,作为第二层的测试集。
随后,再用另一个模型去训练第二层的训练集并预测第二层的测试集,获取对原始的测试集的预测结果进行评估。
estimators = [('ridge', RidgeCV()),
('lasso', LassoCV(random_state=42)),
('knr', KNeighborsRegressor(n_neighbors=20,
metric='euclidean'))]
final_estimator = GradientBoostingRegressor(
n_estimators=25, subsample=0.5, min_samples_leaf=25, max_features=1,
random_state=42)
reg = StackingRegressor(estimators=estimators,
final_estimator=final_estimator)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4、进一步提高分类器性能
四、深度学习文本分类模型
1、 文本的分布式表示:词向量(Word Embedding)
(1)基本思想:每个词表达成 n 维稠密、连续的实数向量,与之相对的one-hot encoding向量空间只有一个维度是1,其余都是0。
(2)优点:具备很强的特征表达能力,n维向量每维k个值,可以表征kn个概念
(3)来源:神经网络语言模型==(下图)==(NNLM,Neural Probabilistic Language Model)每个词表示为稠密的实数向量
————词的分布式表示即词向量(word embedding)是训练语言模型的一个附加产物,即图中的Matrix C。
##2、深度学习文本分类模型
文本分类模型则是利用CNN/RNN等深度学习网络及其变体解决自动特征提取(即特征表达)的问题。
(1)FastText——文本长,且速度要求快时用
①原理
把句子中所有的词向量进行平均(某种意义上可以理解为只有一个avg pooling特殊CNN),然后直接接 softmax 层。
其实文章也加入了一些 n-gram 特征的 trick 来捕获局部序列信息。
输入的词向量可以是预先训练好的,也可以随机初始化,跟着分类任务一起训练
②适用场景
文本长且对速度要求高的场景Fasttext是baseline首选。
用它在无监督语料上训练词向量,进行文本表示
③模型图
第一层:添加Input层(embedding层)
第二层:Hidden层(投影层)
投影层对一个文档中所有单词的向量进行叠加平均。这层的input_shape是Embedding层的output_shape,这层的output_shape=(batch_size, embedding_dim);
第三层:output层(softmax层)
真实的fastText这层是Hierarchical Softmax,这层指定了class_num,对于一篇文档,输出层会产生class_num个概率值,分别表示此文档属于当前类的可能性。这层的output_shape=(batch_size, class_num)
技巧:字符级n-gram特征的引入(用skip-gram)
分层Softmax分类
④Keras实现过程
#第一步:从整数数组中抽取n-grams去重set
def create_ngram_set(input_list, ngram_value=2):
return set(zip(*[input_list[i:] for i in range(ngram_value)]))
- 1
- 2
- 3
#第二步:通过n-gram,来扩充输入参数sequnences序列;
def add_ngram(sequences, token_indice, ngram_range=2):
new_sequences = []
for input_list in sequences:
new_list = input_list[:]
for ngram_value in range(2, ngram_range + 1):
for i in range(len(new_list) - ngram_value + 1):
ngram = tuple(new_list[i:i + ngram_value])
if ngram in token_indice:
new_list.append(token_indice[ngram])
new_sequences.append(new_list)
return new_sequences
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
# 第三步:处理训练数据 if ngram_range > 1: print('Adding {}-gram features'.format(ngram_range)) # 从训练数据集中,创建n-gram去重set ngram_set = set() for input_list in x_train: for i in range(2, ngram_range + 1): set_of_ngram = create_ngram_set(input_list, ngram_value=i) ngram_set.update(set_of_ngram) # 对n-gram词产出不同序号的词典 # 这些序号的值要大于max_features # Integer values are greater than max_features in order # 去避免跟已有的特征重合 start_index = max_features + 1 # 词 -> 序号 token_indice = {v: k + start_index for k, v in enumerate(ngram_set)} # 序号 -> 词 indice_token = {token_indice[k]: k for k in token_indice} # 需要更新max_features max_features = np.max(list(indice_token.keys())) + 1 # 对x_train和x_test用n-grams特征进行扩充 x_train = add_ngram(x_train, token_indice, ngram_range) x_test = add_ngram(x_test, token_indice, ngram_range) # 截断补齐 x_train = sequence.pad_sequences(x_train, maxlen=maxlen) x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
⑤优缺点
- 模型本身复杂度低,但效果不错,能快速产生任务的baseline
- fastText在保持高精度的情况下加快了训练速度和测试速度
- fastText不需要预训练好的词向量,fastText会自己训练词向量
- 采用了char-level的n-gram作为附加特征,比如paper的trigram是 [pap, ape, per],在将输入paper转为向量的同时也会把trigram转为向量一起参与计算。这样一方面解决了长尾词的OOV (out-of-vocabulary)问题,一方面利用n-gram特征提升了表现
- 当类别过多时,支持采用hierarchical softmax进行分类,提升效率
缺点
完全没有考虑词序信息,而它用的 n-gram 特征 trick 恰恰说明了局部序列信息的重要意义。
⑥代码实现——直接导入fasttext模型
fastText文本分类要求的数据存储格式
__ label __ 我 爱 中国
-
__ label __ : 类别前缀, __ label __ 后面接类别
-
1: 类别 id,用来区分不同类,可自定义
-
“我 爱 中国”: 分词后文本
-
代码:
"__label__"+str(label)+"\t"+" ".join(segs) import fasttext """有监督学习"""fasttext.train_supervised classifier=fasttext.train_supervised('./data/train_data.txt',label='label', wordNgrams=2,epoch=20,lr=0.1,dim=100) """无监督学习:无监督训练模式: 'skipgram' 或者 'cbow', 默认为'skipgram', 在实践中,skipgram模式在利用子词方面比cbow更好."""fasttext.train_unsupervised model = fasttext.train_unsupervised('path‘, "cbow", dim=300, epoch=1, lr=0.1, thread=8) # 模型批量预测 classifier.test test_result=classifier.test('./data/test_data.txt') #输出返回:元组中的每项分别代表, 验证集样本数量, 精度以及召回率 # 模型单例预测 classifier.predict labels = classifier.predict(texts) # 输出:元组中的第一项代表标签, 第二项代表对应的概率
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
#参数说明 """ train_supervised(path, lr=0.1, dim=100, ws=5, epoch=5, minCount=1, minCountLabel=0, minn=0, maxn=0, neg=5, wordNgrams=1, loss="softmax", bucket=2000000, thread=12, lrUpdateRate=100,t=1e-4, label="__label__", verbose=2, pretrainedVectors="") 训练一个监督模型, 返回一个模型对象 @param path: 训练数据文件路径 @param lr: 学习率————————————默认为0.05, 根据经验, 建议选择[0.01,1]范围内. @param dim: 向量维度——————————默认为100, 但随着语料库的增大, 词嵌入的维度往往也要更大. @param ws: cbow模型时使用 @param epoch: 次数————————————————默认为5, 但当你的数据集足够大, 可能不需要那么多次. @param minCount: 词频阈值, 小于该值在初始化时会过滤掉 @param minCountLabel: 类别阈值,类别小于该值初始化时会过滤掉 @param minn: 构造subword时最小char个数 @param maxn: 构造subword时最大char个数 @param neg: 负采样 @param wordNgrams: n-gram个数 @param loss: 损失函数类型, softmax, ns: 负采样, hs: 分层softmax @param bucket: 词扩充大小, [A, B]: A语料中包含的词向量, B不在语料中的词向量 @param thread: 线程个数, 0号线程负责loss输出————————————默认为12个线程, 一般建议和你的cpu核数相同. @param lrUpdateRate: 学习率更新 @param t: 负采样阈值 @return model object """
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
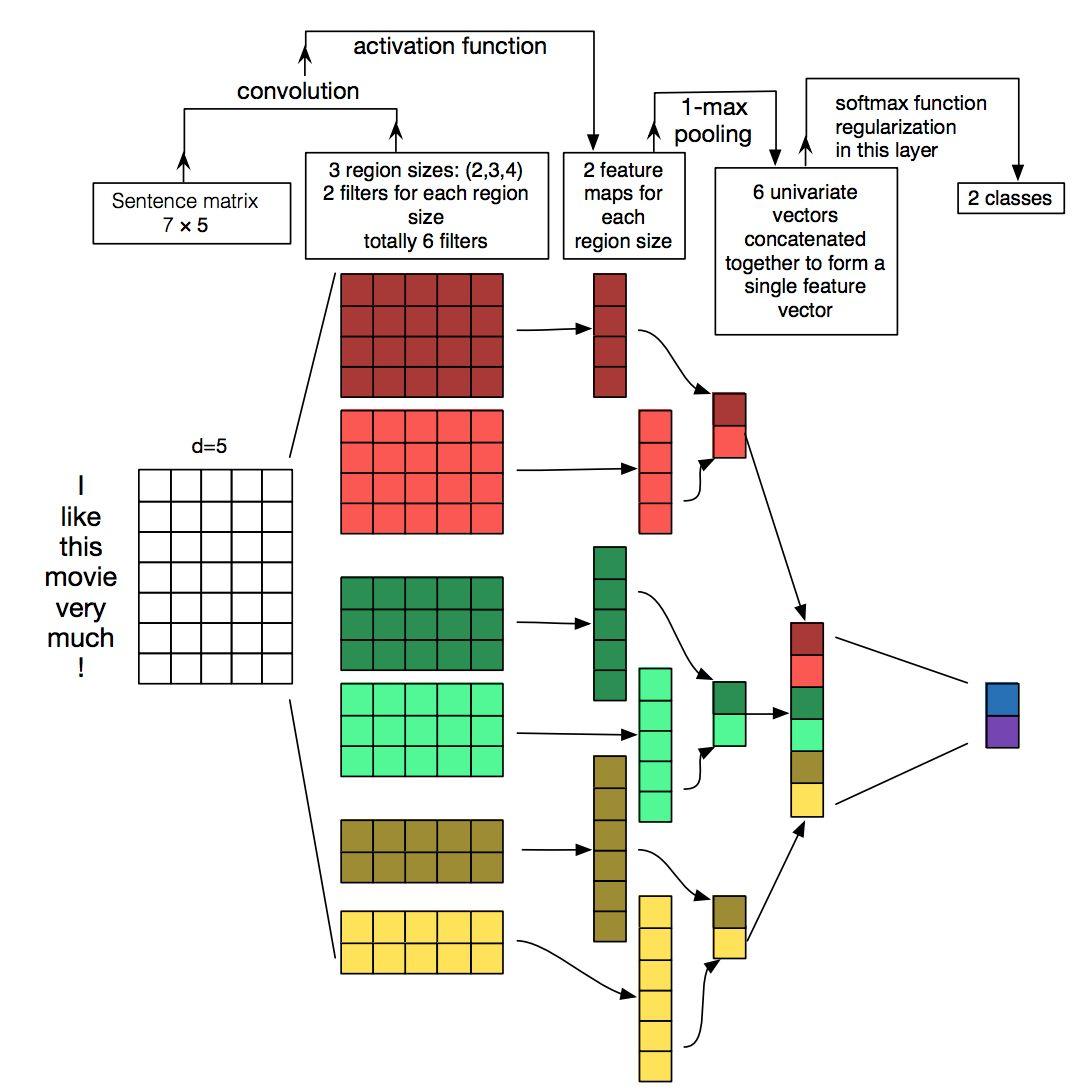
(2)TextCNN——利用CNN来提取句子中类似 n-gram 的关键信息
①TextCNN详细过程
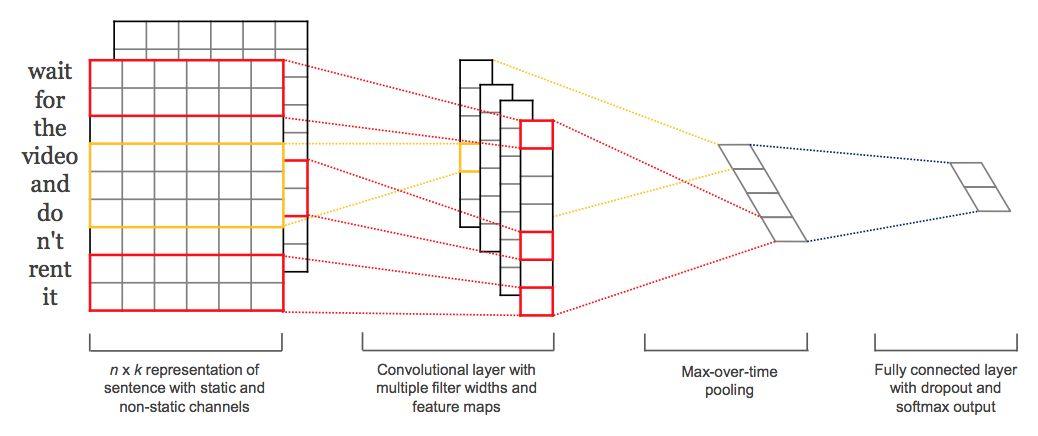
-
第一层:embedding Layer(用于把单词映射到一组向量表示),得到
[seq_length, embedding_dim] ——一般是300维度,主要针对于训练
接下去是一层卷积层,使用了多个filters,这里有3,4,5个单词一次遍历。接着是一层
max-pooling layer得到了一列长特征向量,然后在dropout 之后使用softmax得出每一类的概率。 -
第二层:Convolution Layer(用N个卷积核filter),得到N个
seq_length-filter_size+1长度的一维feature map 使用了多个filters,这里有3,4,5个单词一次遍历。
filter大小为7最优,filter个数100-600(接近600号)
激活函数:ReLU(默认),tanh比sigmoid好
-
第三层:Max_pooling Layer:对feature map进行max-pooling(因为是时间维度的,也称max-over-time pooling),得到N个
1x1的数值,拼接成一个N维向量,作为文本的句子表示. Polling:推荐 1-max-pooling
正则化(防止模型的过拟合):dropout rate最好不好超过0.5;L2正则化效果一般
-
第四层:Softmax Layer:将N维向量压缩到类目个数的维度,过Softmax
特征:词向量
有静态(static)和非静态(non-static)方式。
static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。
non-static则是在训练过程中更新词向量。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛,当然如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
通道(Channels):
图像中可以利用 (R, G, B) 作为不同channel,
文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove)
实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):
图像是二维数据,经过词向量表达的文本为一维数据,
因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
Pooling层:
pooling阶段保留 k 个最大的信息,保留了全局的序列信息。比如在情感分析场景,举个例子:
“ 我觉得这个地方景色还不错,但是人也实在太多了 ”
- 1
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
②代码实现
class TextCNN(object): """ CNN用于文本分类(4层) Embedding Layer:词语转变成为一组向量表示 Convolutional Layer Max-pooling Layer Softmax Layer """ def __init__(self, max_setence_length, num_classes, vocab_size, embedding_dims, filter_sizes, num_filters, l2_reg_lambda=0.0): """ :param max_setence_length: (最大句子长度:int)——文本样本中字词的最大长度,不足补零,多余的截断 :param num_classes: (标签类别数目:int) :param vocab_size: (词典大小:int) :param embedding_size: (词向量长度,每个字词的维度,嵌入维度:int)——一般为128 :param filter_sizes: (卷积核大小:int/list) 1D 卷积窗口的长度 :param num_filters: (卷积核个数:int) :param l2_reg_lambda: (可选的L2正则化) *:param dropout_keep_prob *:param base_lr (学习率)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
注意:filter_sizes和num_filters
filters_sizes是指filter每次处理几个单词
num_filters是指每个尺寸的处理包含几个filter
def creat_CNN_model(self): # 输入层 input = layers.Input((self.maxlen,)) # 嵌入层 embedding = layers.Embedding(self.max_features, self.embedding_dims, input_length=self.maxlen)(input) # 运用不同大小的卷积核嵌套(卷积和池化) convs = [] for kernel_size in [3, 4, 5]: c = layers.Conv1D(128, kernel_size, activation='relu',padding='same')(embedding) c = layers.GlobalMaxPooling1D()(c) convs.append(c) # 将几层串起来 x = layers.Concatenate()(convs) # 输出是全连接层-即多少类别 output = layers.Dense(self.class_num, activation='softmax')(x) model = Model(inputs=input, outputs=output) return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

③适用场景
TextCNN是很适合中短文本场景的强baseline,但不太适合长文本,因为卷积核尺寸通常不会设很大,无法捕获长距离特征。
同时max-pooling也存在局限,会丢掉一些有用特征。
TextCNN和传统的n-gram词袋模型本质是一样的,它的好效果很大部分来自于词向量的引入,解决了词袋模型的稀疏性问题。
③缺点
CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。
###(3)TextRNN——RNN+LSTM
①RNN模型概念
- 它们利用顺序信息。
- 他们有一个记忆,可以捕捉到到目前为止已经计算过的内容,即我=最后讲的内容将影响我=接下来要讲的内容。
- RNN是文本和语音分析的理想选择。
- 最常用的RNN是LSTM。
②模型图
RNN: 
②RNN文本分类原理
- 输入每个单词,单词以某种方式彼此关联。
- 当看到文章中的所有单词时,就会在文章结尾进行预测。
- RNN通过传递来自最后一个输出的输入,能够保留信息,并能够在最后利用所有信息进行预测。
缺点:短句子非常有效,当处理长篇文章时,将存在长期依赖问题
③LSTM :
LSTM内部主要有三个阶段:
- Forget Gate。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
具体来说是通过计算得到的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TWNDc9O7-1641710073819)(https://www.zhihu.com/equation?tex=z%5Ef)] (f表示forget)来作为忘记门控,来控制上一个状态的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gHjxqS1U-1641710073820)(https://www.zhihu.com/equation?tex=c%5E%7Bt-1%7D)] 哪些需要留哪些需要忘。
- Input Gate。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eTuOqWIk-1641710073821)(https://www.zhihu.com/equation?tex=x%5Et)] 进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wDUvRcY3-1641710073821)(https://www.zhihu.com/equation?tex=z+)] 表示。而选择的门控信号则是由 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zZaANdt9-1641710073822)(https://www.zhihu.com/equation?tex=z%5Ei)] (i代表information)来进行控制。
将上面两步得到的结果相加,即可得到传输给下一个状态的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1OyCs8Fc-1641710073823)(https://www.zhihu.com/equation?tex=c%5Et)] 。也就是上图中的第一个公式。
- Output Gate。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YggdT6LF-1641710073823)(https://www.zhihu.com/equation?tex=z%5Eo)] 来进行控制的。并且还对上一阶段得到的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iW2grHCK-1641710073824)(https://www.zhihu.com/equation?tex=c%5Eo)] 进行了放缩(通过一个tanh激活函数进行变化)。
与普通RNN类似,输出 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mnaZ0Aet-1641710073824)(https://www.zhihu.com/equation?tex=y%5Et)] 往往最终也是通过 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7VLEGZ12-1641710073825)(https://www.zhihu.com/equation?tex=h%5Et)] 变化得到。
注意:LSTM模型只是将 FastText 的 GlobalAveragePooling1D 换成了 LSTM 神经网络层,输入先通过嵌入层转换为词向量序列表示,然后经过LSTM转换为128维的向量,然后直接接上sigmoid分类器。
④LSTM代码
keras.layers.LSTM(units, activation='tanh', recurrent_activation='hard_sigmoid',dropout=0.0, recurrent_dropout=0.0,return_sequences=False, return_state=False, )
"""
:param units: 正整数,输出空间的维度。
:param activation: 要使用的激活函数(如果None就是没有激活)
:param recurrent_activation: 用于循环时间步的激活函数
:param return_sequences: 布尔值。是返回输出序列中的最后一个输出,还是全部序列
:param dropout: 在 0 和 1 之间的浮点数。 单元的丢弃比例,用于输入的线性转换
:param recurrent_dropout: 在 0 和 1 之间的浮点数。 单元的丢弃比例,用于循环层状态的线性转换。
:param return_state: 布尔值。除了输出之外是否返回最后一个状态。
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
def LSTM_model():
model = Sequential()
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim))) # 返回维度为 32 的向量序列
model.add(LSTM(32, return_sequences=True)) # 返回维度为 32 的向量序列
model.add(LSTM(32)) # 返回维度为 32 的单个向量
model.add(Dense(10, activation='softmax'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

(4)Bi-LSTM——从某种意义上捕获变长且双向的的 “n-gram” 信息

tf.keras.layers.Bidirectional(
layer, merge_mode="concat", weights=None, backward_layer=None, **kwargs
)
"""
:param layer: keras.layers.RNN实例:如keras.layers.LSTM或keras.layers.GRU。
:param merge_mode:{'sum', 'mul', 'concat', 'ave', None}之一。
如果为None,输出将不会被合并,它们将作为一个列表返回。默认值为“concat”。
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
def create_bilstm_model():
# LSTM
lstm_output_size = 70
model = Sequential()
model.add(Embedding(voc_size, embedding_dim, input_length=max_len))
model.add(LSTM(lstm_output_size))
model.add(Bidirectional(LSTM(lstm_output_size)))
model.add(Dropout(0.1))
model.add(Dense(class_num,))
model.add(Activation('softmax'))
return model
bi_lstm_model = create_bilstm_model()
plot_model(bi_lstm_model, to_file='bi_lstm_model.png', show_shapes=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(5)BERT(无监督学习)
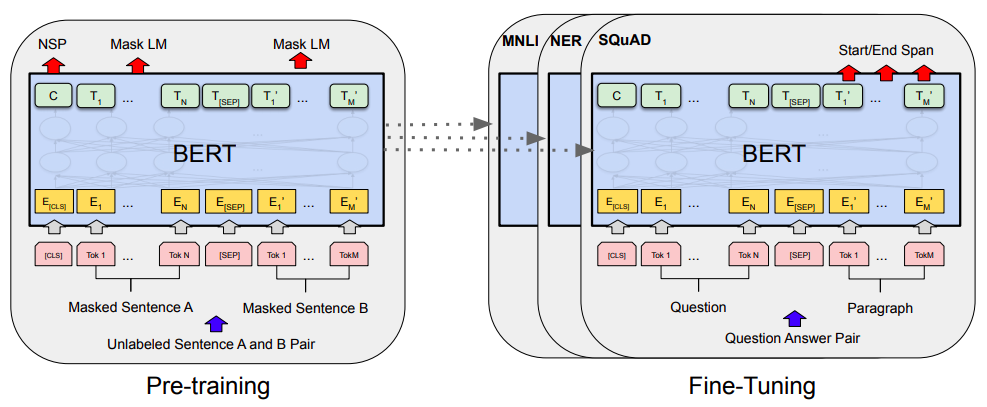
BERT模型:多个Transformer Encoder一层一层地堆叠起来,
且只使用了 Transformer 的 Encoder 模块
①BERT的预训练过程
BERT的预训练阶段包括两个任务:Masked Language Model/Next Sentence Prediction。
Masked Language Model
MLM可以理解为完形填空,作者会随机mask每一个句子中15%的词,用其上下文来做预测,**例如:my dog is hairy → my dog is [MASK] **
此处将hairy进行了mask处理,然后采用非监督学习的方法预测mask位置的词是什么,但是该方法有一个问题,因为是mask15%的词,其数量已经很高了,这样就会导致某些词在fine-tuning阶段从未见过,为了解决这个问题,作者做了如下的处理:
80%的时间是采用[mask],my dog is hairy → my dog is [MASK]
10%的时间是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
10%的时间保持不变,my dog is hairy -> my dog is hairy
那么为啥要以一定的概率使用随机词呢?这是因为transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"。至于使用随机词带来的负面影响,文章中解释说,所有其他的token(即非"hairy"的token)共享15%x10% = 1.5%的概率,其影响是可以忽略不计的。Transformer全局的可视,又增加了信息的获取,但是不让模型获取全量信息。
注意:
# dupe_factor:决定数据duplicate的次数。
# create_instance_from_document函数,构造了一个sentence-pair的样本。
对每一句,
先生成[CLS]+A+[SEP]+B+[SEP],有长(0.9)有短(0.1),
再加上mask,然后做成样本类object。
# create_masked_lm_predictions函数返回的tokens是已经被遮挡词替换之后的tokens
# masked_lm_labels则是遮挡词对应位置真实的label。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Next Sentence Prediction
选择一些句子对A与B,其中50%的数据B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,学习其中的相关性,添加这样的预训练的目的是目前很多NLP的任务比如QA和NLI都需要理解两个句子之间的关系,从而能让预训练的模型更好的适应这样的任务。 Bert先是用Mask来提高视野范围的信息获取量,增加duplicate再随机Mask,这样跟RNN类方法依次训练预测没什么区别了除了mask不同位置外;
全局视野极大地降低了学习的难度,然后再用A+B/C来作为样本,这样每条样本都有50%的概率看到一半左右的噪声;
但直接学习Mask A+B/C是没法学习的,因为不知道哪些是噪声,所以又加上next_sentence预测任务,与MLM同时进行训练,这样用next来辅助模型对噪声/非噪声的辨识,用MLM来完成语义的大部分的学习
②输入
BERT 的输入可以是单一的一个句子或者是句子对。通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入
BERT 模型的主要输入是文本中各个字/词(或者称为 token)的原始词向量,该向量既可以随机初始化,也可以利用 Word2Vector 等算法进行预训练以作为初始值
实际的输入值是segment embedding与position embedding相加,
BERT的输入词向量是三个向量之和:
Token Embedding:WordPiece tokenization subword词向量。
Segment Embedding:表明这个词属于哪个句子(NSP需要两个句子),该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合
Position Embedding:由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT 模型对不同位置的字/词分别附加一个不同的向量以作区分Transformer中是预先设定好的值。
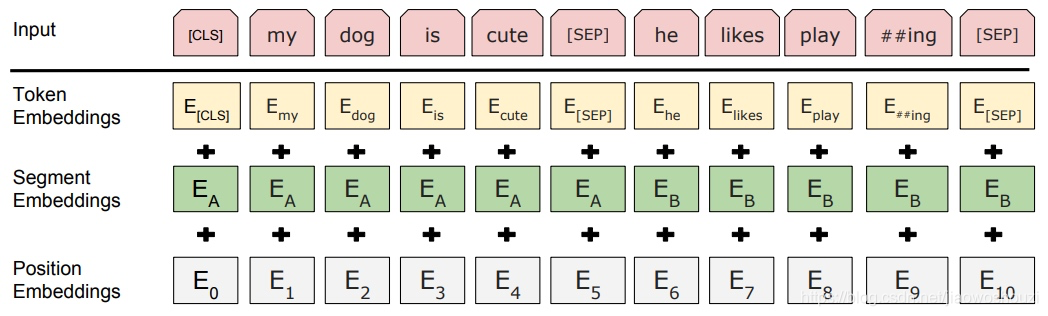
③输出
输出是文本中各个字/词融合了全文语义信息后的向量表示
④优缺点
BERT优点
Transformer Encoder因为有Self-attention机制,因此BERT自带双向功能
因为双向功能以及多层Self-attention机制的影响,使得BERT必须使用Cloze版的语言模型Masked-LM来完成token级别的预训练
为了获取比词更高级别的句子级别的语义表征,BERT加入了Next Sentence Prediction来和Masked-LM一起做联合训练
为了适配多任务下的迁移学习,BERT设计了更通用的输入层和输出层
微调成本小
BERT缺点
task1的随机遮挡策略略显粗犷
[MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现;
每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
BERT对硬件资源的消耗巨大
④代码实现
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

