
热门标签
当前位置: article > 正文
特征选取-随机森林演示_随机森林 贡献率
作者:IT小白 | 2024-03-15 05:57:30
赞
踩
随机森林 贡献率
特征选取-随机森林演示
机器学习中,面对数据集里面较多的特征,模型需要根据实际需求和算法选取必要的特征,选取数据中重要特征的同时,由于减少了部分特征,也可进一步减少模型运行的速度,常用特征方法包括过滤法、包裹法、嵌入法,过滤法更多是探索变量自身及变量之间相关关系,包裹法通过模型选取合适的类别变量,嵌入法师将集成学习和混合学习方法结合
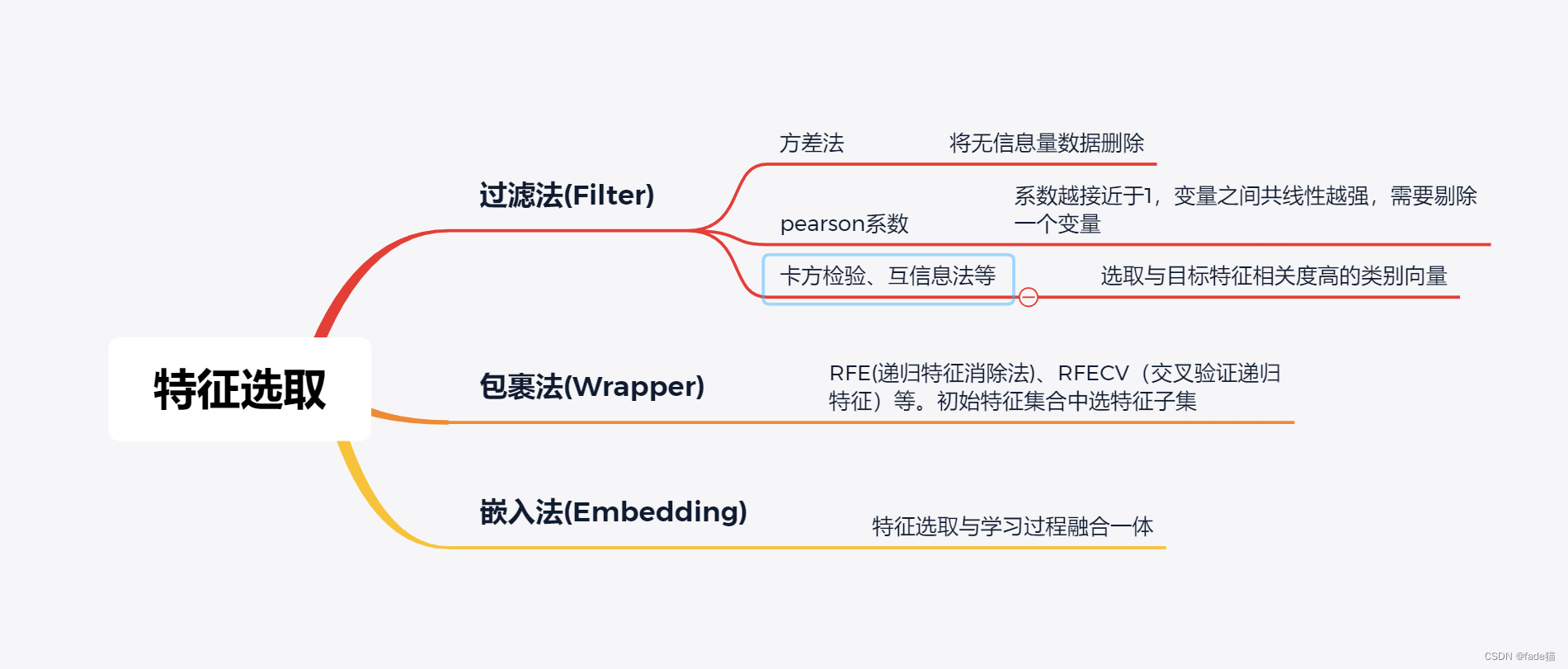
本次选择集成学习算法中随机森林(Random Forest)模型为演示对象,为集成学习的Bagging算法,随机森林内部生成N个独立的决策树模型,通过内部投票少数服从多数选择最佳决策,相当于三个人分别下在某一个的领域都是佼佼者,三人在做同一件事,顶得上一个诸葛亮;换一个思路看,三个人可以看成单个弱分类器,诸葛亮相当于强分类器,如果将三个人分类串联融合,形成强分类器,这就是集成学习算法的Boosting思想,典型代表AdaBoost、GBDT、XGBoost、LightGBM
以下以IBM HR Analytics Employee Attrition & Performance公开数据集进行演示,为员工流失数据数据集,穿插演示常用的特征选取方法(数据集质量本身不错,需要预处理的地方不多)
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
pd.set_option('display.max_columns', None)
from sklearn.inspection import permutation_importance
from sklearn.feature_selection import RFE
from sklearn.feature_selection import RFECV
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这边发现EmployeeCount、Over18、StandardHours列中唯一值数量都是1,从过滤法方差的角度,方差等于0,基本没有信息,予以删除,同时员工编号,对员工是否流失没有起到实际意义,因此也可删除
df = pd.read_csv("HR-Employee-Attrition.csv")
for column in df.columns:
print(f"{column}: 唯一值数量 {df[column].nunique()}")
df.head(1)
df.drop(['EmployeeCount', 'EmployeeNumber', 'Over18', 'StandardHours'], axis="columns", inplace=True)
- 1
- 2
- 3
- 4
- 5

从数据的描述信息来看,需要对object类型数据进行编码
df.info()
df["Attrition"] = LabelEncoder().fit_transform(df['Attrition'])
df["BusinessTravel"] = LabelEncoder().fit_transform(df['BusinessTravel'])
df["Department"] = LabelEncoder().fit_transform(df['Department'])
df["EducationField"] = LabelEncoder().fit_transform(df['EducationField'])
df["Gender"] = LabelEncoder().fit_transform(df['Gender'])
df["JobRole"] = LabelEncoder().fit_transform(df['JobRole'])
df["MaritalStatus"] = LabelEncoder().fit_transform(df['MaritalStatus'])
df["OverTime"] = LabelEncoder().fit_transform(df['OverTime'])在这里插入代码片
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这边将相关系数变量大于>0.9成对的变量仅保留1个,删除的原因,这些变量特征表现高度相关,容易产生共线性,影响最后结果,反应在线性回归问题上,容易产生极端系数,MonthlyIncome和JobLevel相关程度0.95,高度相关,可以删除掉JobLevel,保留MonthlyIncome
f,ax = plt.subplots(figsize=(18, 18))
sns.heatmap(df.corr(), annot=True, linewidths=.5, fmt= '.2f',ax=ax)
df.drop(['JobLevel'], axis="columns", inplace=True)在这里插入代码片
- 1
- 2
- 3

模型构建
这里可以尝试从决策树ID3算法中信息熵、信息增益的角度去理解决策树模型,举个极端例子,假设国足踢进世界杯信息熵等于0.999,不确定性非常高,在外星人帮助人踢进世界杯的信息熵为0.001,信息增益等于0.998,换句话说,引入外星人这个变量,国足踢进世界杯的信息熵由原来0.999,减小到0.001,变的更加确定了,
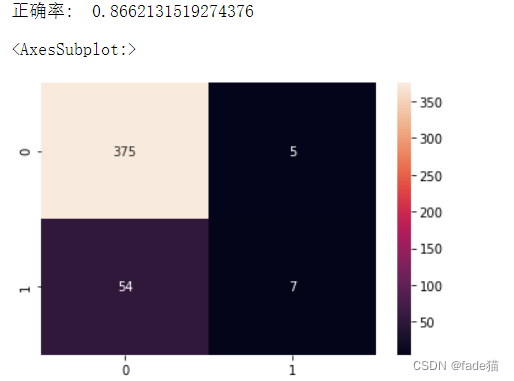
模型正确率86.6
#模型构建,随机森林这边选取建立70个决策树,画出混淆矩阵
X = df.drop('Attrition', axis=1)
y = df.Attrition
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
clf_rf = RandomForestClassifier(n_estimators=70,random_state=43)
clr_rf = clf_rf.fit(x_train,y_train)
ac = accuracy_score(y_test,clf_rf.predict(x_test))
print('正确率: ',ac)
cm = confusion_matrix(y_test,clf_rf.predict(x_test))
sns.heatmap(cm,annot=True,fmt="d")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
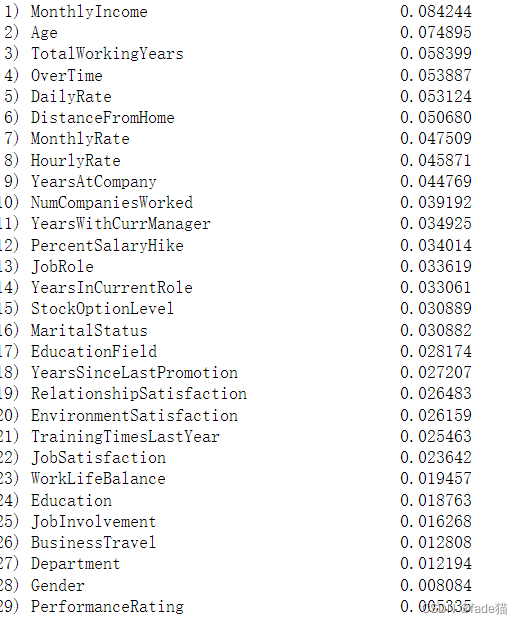
从随机森林重要特征结果来看,对员工是否流失影响靠前的特征为MonthlyIncome(收入)、Age(年龄)、TotalWorkingYears(工作年限)、overTime(加班)、DailyRate (工资类)、DistanceFromHome (工作地远近),对模型的贡献度较高,这里不做解释。这种特征重要性算法其实是有很强的弊端,对连续型特征变量会过高估计其重要性,显然,MonthlyIncome、Age均属于连续型变量,因此,需要用其他模型对其进行验证,是否MonthlyIncome、Age有很高的贡献度
importances = clr_rf.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(x_train.shape[1]):
print("%2d) %-*s %f" % (f + 1, 40, x_train.columns[indices[f]], importances[indices[f]]))
- 1
- 2
- 3
- 4
现在有一种Permutation Feature Importance测量重要特征的方法,它的思想倾向于我们用测试集,来测试在训练集的模型得分结果,我们在测试集每打乱一个特征,然后数据给模型获得新分数,如果刚才的特征很重要,且分数急剧下降,那么这个特征很重要,如果特征基本无变化,那么这个特征基本不重要
现在注意到对员工流失影响主要特征包括OverTime(加班)、MaritalStatus(婚姻状况)、DistanceFromHome(离家距离)、Age(年龄)、JobSatisfaction(工作的主观满意度),可以明显感觉现在选取的特征对模型的贡献度比刚才更符合正常逻辑
perm_importance = permutation_importance(clr_rf, x_test, y_test).importances_mean
indices = np.argsort(perm_importance)[::-1]
for f in range(x_test.shape[1]):
print("%2d) %-*s %f" % (f + 1, 40, x_test.columns[indices[f]], perm_importance[indices[f]]))
- 1
- 2
- 3
- 4
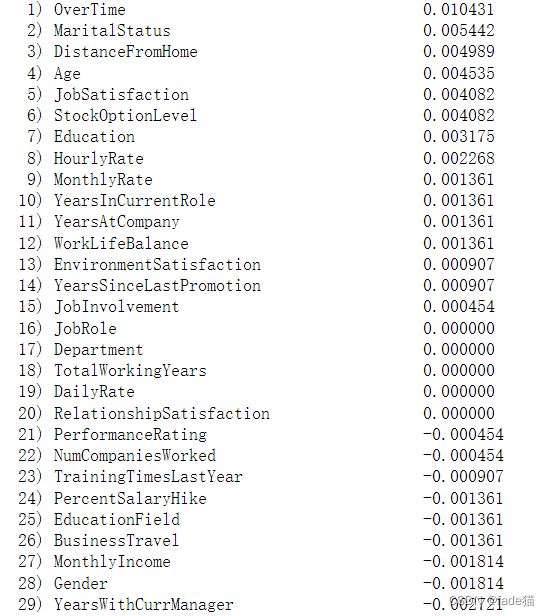
根据过滤法中卡方检验,选取前10的特征分最高的特征,这边10是随机指定的,实际情况需要多次尝试才能选择比较好的结果,可以循环跑下,这里模型正确率85.2
x_train_2 = select_feature.transform(x_train)
x_test_2 = select_feature.transform(x_test)
clf_rf_2 = RandomForestClassifier(n_estimators=70)
clr_rf_2 = clf_rf_2.fit(x_train_2,y_train)
ac_2 = accuracy_score(y_test,clf_rf_2.predict(x_test_2))
print("正确率:",ac_2)
cm_2 = confusion_matrix(y_test,clf_rf_2.predict(x_test_2))
sns.heatmap(cm_2,annot=True,fmt="d")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

使用包裹法 RFE(递归特征消除法) ,准确率85.9%,RFECV(交叉验证递特征85.2%,代码不贴了,与RFE差不多),结果还与原生clf_rf模型准确率(86.2)差不多,可能是前期删除了一些数据,导致RFE与RFEVC结果方法优势没有凸显出来,也有可能是数据集的问题,数据集比较小,还有可能RFE倾向于选择连续型数据,这里有些连续型变量转换为离散型,效果可能会好一点。国外准确率能达到96%,有空复现一下别人的想法
clf_rf_3 = RandomForestClassifier(n_estimators=70,random_state=42)
rfe = RFE(estimator=clf_rf_3, n_features_to_select=10, step=1)
rfe = rfe.fit(x_train, y_train)
print('由RFE选取最佳10个特征',x_train.columns[rfe.support_])
- 1
- 2
- 3
- 4

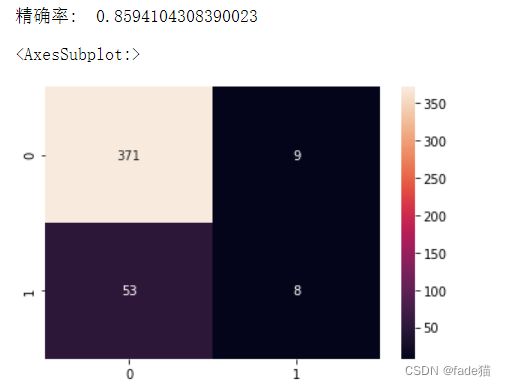
x_train_3 = select_feature.transform(x_train)
x_test_3 = select_feature.transform(x_test)
clf_rf_3 = RandomForestClassifier(n_estimators=50)
clr_rf_3 = clf_rf_3.fit(x_train_3,y_train)
ac_3 = accuracy_score(y_test,clf_rf_3.predict(x_test_3))
print('精确率: ',ac_3)
cm_3 = confusion_matrix(y_test,clf_rf_3.predict(x_test_3))
sns.heatmap(cm_3,annot=True,fmt="d")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/239180
推荐阅读

相关标签

