- 1Python配置清华镜像源_python清华镜像源
- 2linux trim file path,如何在Linux服务器的SSD存储配置周期性TRIM
- 3鸿蒙OS(1) : 安装IDE(3.0)_devecostudio-windows-tool-3.0.0.800.zip
- 4三相 AC-DC 变换电路_三相acdc变换电路
- 5讯飞离线语音合成(离线资源包)_科大讯飞语音文件转语音 离线费用
- 6消息队列——kafka基础_kafka消息队列
- 7OpenHarmony 项目实战-基于ArkUI(TS)声明式开发:列表下拉刷新、上拉加载更多_arkts下拉刷新加载更多
- 8动态监听DOM元素高度变化_vue监听dom元素高度变化
- 9Pingora正式开源:超强的Nginx替代品,每秒可处理4000万请求!
- 10微信的聊天记录导出到网页中的最快方法,语音能听,图片视频能看_bilibili 微信信息导出
记训练时GPU利用率低 -> pytorch profiler分析模型性能
赞
踩
目录
Pytorch profiler with tensorboard.
魔改模型出现的一系列问题:
1.训练报错:参数出现在GPU & CPU中
![]()
解决:在报错位置的张量移入GPU
- # .to(device)
-
- # ...
- # self.shift = nn.Parameter(torch.tensor([0., 128., 128.]))
- # self.matrix = nn.Parameter(torch.from_numpy(matrix))
- self.shift = nn.Parameter(torch.tensor([0., 128., 128.], device=image.device))
- self.matrix = nn.Parameter(torch.from_numpy(matrix).to(image.device))
-
- # ...
- # dct_filter = torch.zeros((batch_size, channel, tile_size_x, tile_size_y))
- dct_filter = torch.zeros((batch_size, channel, tile_size_x, tile_size_y), device=mapper_x.device)
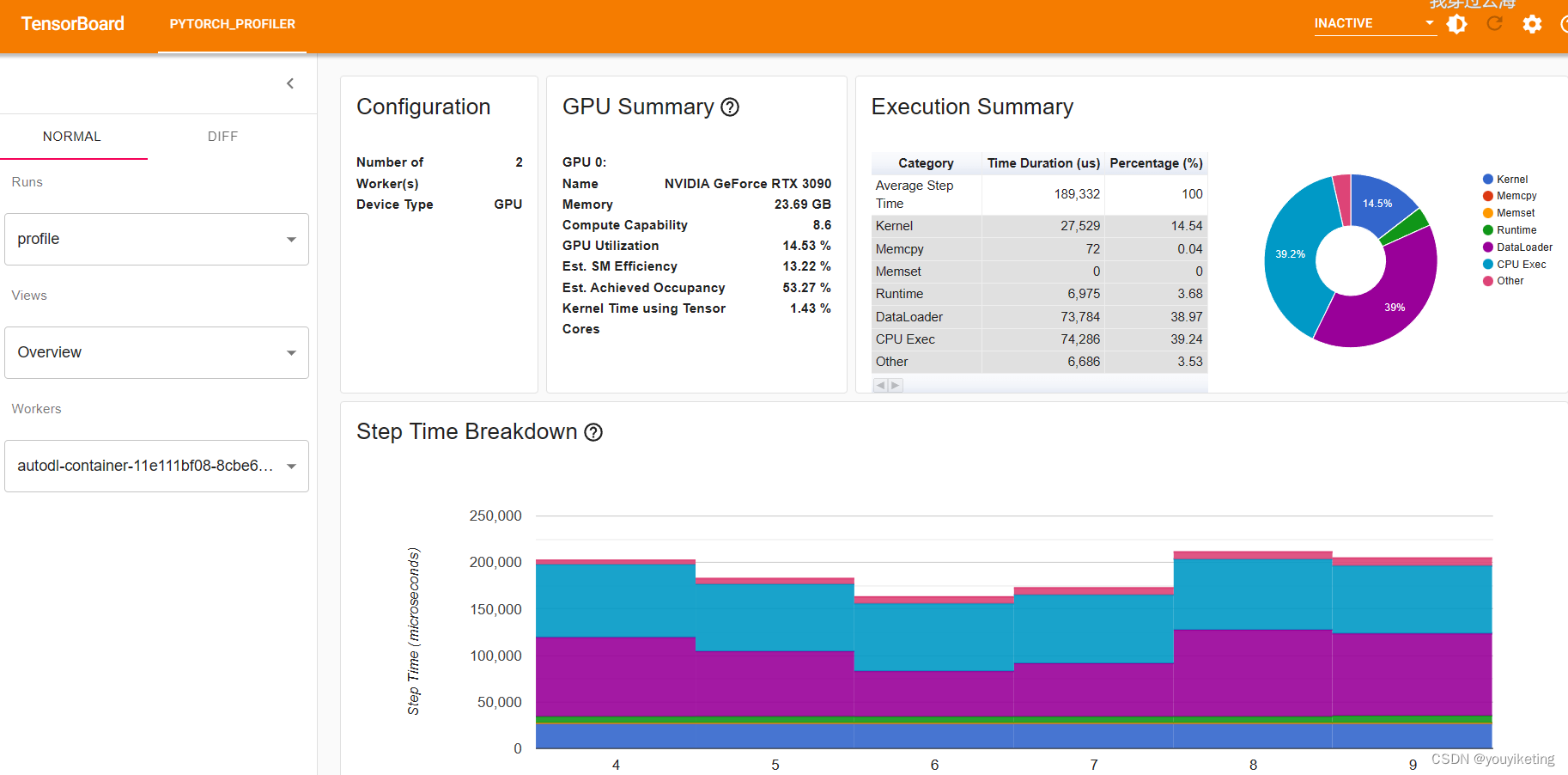
2.训练时,GPU利用率低,训练非常非常缓慢

(可能是CPU GPU通信导致的)
3.测试训练好的模型,load模型时出现unexpected key(s)问题

报错原因:
保存模型参数时使用的模型状态字典(state_dict)与加载模型时使用的模型结构不匹配导致的。state_dict是一个Python字典对象,将每个模型参数的名称映射到其对应的张量值。当我们加载模型参数时,PyTorch会根据state_dict中的key与模型中的参数进行匹配,然后将参数值加载到对应的模型中。 然而,加载模型时,模型结构中没有找到与该参数名称对应的模型参数,因此出现了Unexpected key(s)的错误提示。
解决:加载模型时,手动删除不需要的key
- # 使用torch.load加载保存的模型状态
- state_dicts = torch.load(model_name)
- # 从保存的状态字典(state_dicts)中提取神经网络的状态字典(net)
- # network_state_dict = {k: v for k, v in state_dicts['net'].items() if 'tmp_var' not in k}
- network_state_dict = {}
- for k, v in state_dicts['net'].items():
- if 'module.inbs_couple.operations.0.r.attentionBlock.dct_layer.weight' not in k \
- and 'module.dct_gate.dct_trans.shift' not in k \
- and 'module.dct_gate.dct_trans.matrix' not in k:
- network_state_dict[k] = v
- # 使用提取的神经网络状态字典加载神经网络的参数
- net.load_state_dict(network_state_dict)
(这里报错的key正巧与第一步中移入GPU的张量对应,说明第一步改进存在问题啊,这里先测试模型结果,毕竟花了这么久时间钱钱跑出的模型,然后再从头开始找问题吧)
Pytorch profiler with tensorboard.
通过pytorch的profiler工具分析模型各模块运行性能
参考:
Pytorch profiler with tensorboard._pytorch profiler tensorboard-CSDN博客
pytorch profiler 性能分析 demo - 知乎 (zhihu.com)
step1.首先安装Pytorch Profiler TensorBoard plugin.(否则利用tensorboard打开时,会找不到文件,哈哈我就是忽略了这步的倒霉蛋)
pip install torch_tb_profiler
step2.根据pytorch官方文档,使用profiler来记录执行的事件
- from torch.profiler import profile, record_function, ProfilerActivity
-
- with torch.profiler.profile(
- schedule=torch.profiler.schedule(wait=2, warmup=2, active=6, repeat=1),
- on_trace_ready=torch.profiler.tensorboard_trace_handler(dir_name='profile/'),
- activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA],
- record_shapes=True,
- profile_memory=True,
- with_stack=True,
- )as prof:
- for i_batch, data in enumerate(dataloader):
- if i_batch > 2+2+6+1:
- print("break out")
- break
- # data load
- data = data.to(device)
- # test
- out = net(data)
- prof.step()
- print(f'step {i_batch}')
-
- print(prof.key_averages(group_by_stack_n=5).table(sort_by="cuda_time_total", row_limit=10))

PS:可以在任何需要性能监测的代码块外套用 record_function("label") ,如下,监测 backward()执行过程的性能:
- with torch.profiler.record_function("encoder"):
- steg_image, z_output = self.encoder(cover, secret)
step3.运行,生成trace文件于上述代码定义的文件夹下

step4. 通过tensorboard打开,trace文件
- tensorboard --logdir profile
-
- # autodl服务器平台下
- tensorboard --logdir profile --port 6007