
- 1【2022-09-14】米哈游秋招笔试三道编程题_米哈游笔试题目
- 2小程序bindtap 和 catchtap 的区别以及如何使用_catchtap小程序
- 3从云计算到边缘计算:技术演进的下一个风口
- 4linux系统安全设置加固
- 5装个绿色Xshell,无需注册机,或者需要断网等各种骚操作_xshell 绿色
- 6Git的学习与使用_tortoisegit 2.15.0.0 使用
- 7frok创建子进程的流程(底层实现)||fork源码剖析||(详解)||写实拷贝_流程图fork子流程怎么画
- 8小程序学习笔记(二)_小程序 ontap事件 事件穿透
- 9智能电表MCU需求,及电表芯片厂商排名_智能电表muc方案芯片有哪些
- 10ConstraintLayout(约束布局)使用详解
一文读懂内存池原理与实现(图例解析)_内存池的实现原理
赞
踩
一. 内存池设计
1. 目的
在给定的内存buffer上建立内存管理机制,根据用户需求从该buffer上分配内存或者将已经分配的内存释放回buffer中。
2. 要求
尽量减少内存碎片,平均效率高于C语言的malloc和free。
3. 设计思路
将buffer分为四部分,第1部分是mem_pool结构体;第2部分是内存映射表;第3部分是内存chunk结构体缓冲区;第4部分是实际可分配的内存区。整个buffer结构图如图1所示:

图1 内存buffer结构图
第1部分的作用是可以通过该mem_pool结构体控制整个内存池。
第2部分的作用是记录第4部分,即实际可分配的内存区的使用情况。表中的每一个单元表示一个固定大小的内存块(block),多个连续的block组成一个chunk,每个block的详细结构如图2所示:

图2 memory block结构图
其中count表示该block后面的与该block同属于一个chunk的blokc的个数,start表示该block所在的chunk的起始block索引。其实start这个域只有在每个chunk的最后一个block中才会用到(用于从当前chunk寻找前一个chunk的起始位置),而pmem_chunk则是一个指针,指向一个mem_chunk结构体。任意一块大小的内存都会被取向上整到block大小的整数倍。
第3部分是一个mem_chunk pool,其作用是存储整个程序可用的mem_chunk结构体。mem_chunk pool中的mem_chunk被组织成双向链表结构(快速插入和删除)。每个mem_chunk结构图如图3所示:

图3 memory chunk结构图
其中pmem_block指向该chunk在内存映射表中的位置,others表示其他一些域,不同的实现对应该域的内容略有不同。
第4部分就是实际可以被分配给用户的内存。
整个内存池管理程序除了这四部分外,还有一个重要的内容就是memory chunk set。虽然其中的每个元素都来自mem_chunk pool,但是它与mem_chunk pool的不同之处在于其中的每个memory chunk中记录了当前可用的一块内存的相关信息。而mem_chunk pool中的memory chunk的内容是无定以的。可以这样理解mem_chunk pool与memory chunk set:mem_chunk pool是为memory chunk set分配内存的“内存池”,只是该“内存池”每次分配的内存大小是固定的,为mem_chunk结构体的大小。内存池程序主要是通过搜索这个memory chunk set来获取可被分配的内存。在memory chunk set上建立不同的数据结构就构成了不同的内存池实现方法,同时也导致了不同的搜索效率,直接影响内存池的性能,本文稍后会介绍两种内存池的实现。
4. 内存池管理程序运行过程
初始化:内存映射表中只有一块可用的内存信息,大小为内存池中所有可用的内存。从memory chunk pool中分配一个mem_chunk,使其指向内存映射表中的第一个block,并根据具体的内存池实现方式填充mem_chunk中的其他域,然后将该mem_chunk添加到memory chunk set中。
申请内存:当用户申请一块内存时,首先在memory chunk set中查找合适的内存块。如果找到符合要求的内存块,就在内存映射表中找到相应的chunk,并修改chunk中相应block结构体的内容,然后根据修改后的chunk修改memory chunk set中chunk的内容,最后返回分配内存的起始地址;否则返回NULL。
释放内存:当用户释放一块内存时,首先根据这块内存的起始地址找到其在内存映射表中对应的chunk,然后尝试将该chunk和与其相邻的chunk合并,修改chunk中相应block的内容并修改memory chunk set中相应chunk的内容或者向memory chunk set加入新的mem_chunk(这种情况在不能合并内存是发生)。
5. 减少内存碎片
本文设计的方法只能在一定程度上减少内存碎片,并不能彻底消除内存碎片。具体方法如下:
在用户释放内存时,尝试将该内存与其相邻的内存合并。如果其相邻内存为未分配内存则合并成功,合并后作为一整块内存使用;如火其相邻内存为已分配内存则不能合并,该释放的内存块作为一个独立的内存块被使用。
二. 内存池实现-链表结构
1. 性能分析
链表结构的内存池实现是指将memory chunk set实现为双链表结构。这种方法的优缺点如下:
优点:释放内存很快,O(1)复杂度。
缺点:分配内存较慢,O(n)复杂度。
2. 内存池运行状态转移图
绿色表示未使用的内存,红色表示已经使用的内存。其中每个block表示64B,这个值可以根据具体需要设定。
初始化
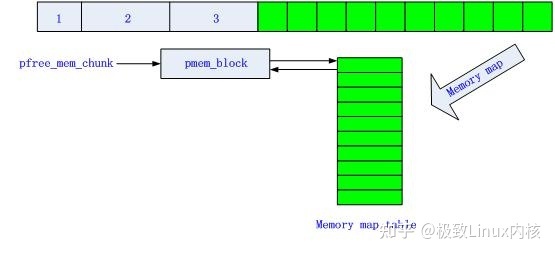
图4 内存池初始化状态
申请内存
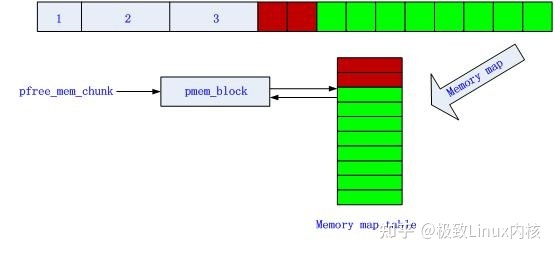
图5 第1次申请128B内存后
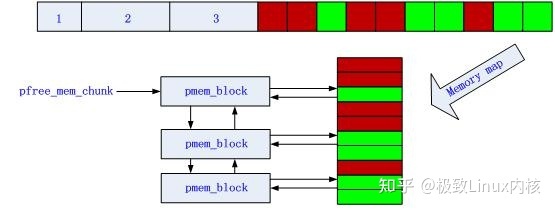
图6 第n次申请、释放内存后
释放内存
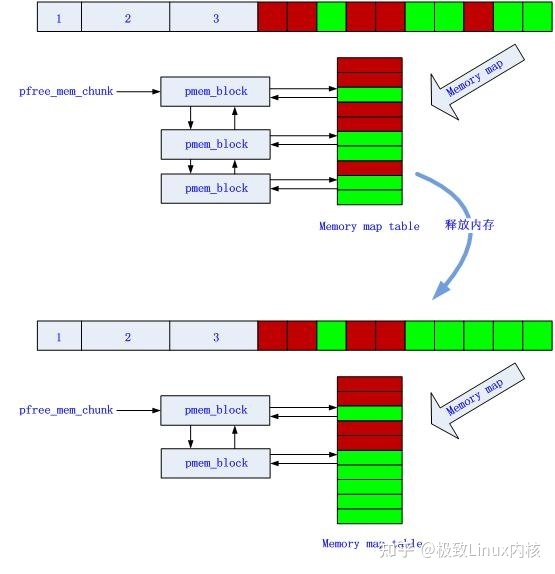
图7 释放64B内存前后
三.内存池实现-大顶堆结构
1. 性能分析
大顶堆结构的内存池实现是指将memory chunk set实现为大顶堆结构。这种方法的优缺点如下:
优点:降低了分配内存的时间复杂度,O(log(n))。
缺点:增加了释放内存的时间复杂度,O(log(n))。
2. 内存池运行状态转移图
绿色表示未使用的内存,红色表示已经使用的内存。其中每个block表示64B,这个值可以根据具体需要设定。
初始化
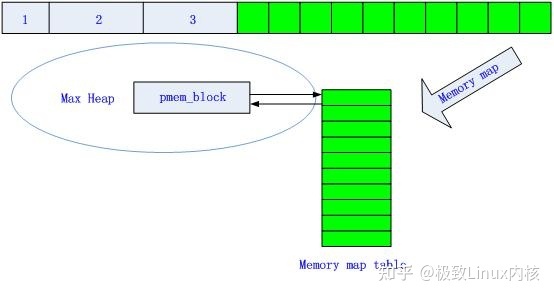
图8 内存池初始化状态
申请内存
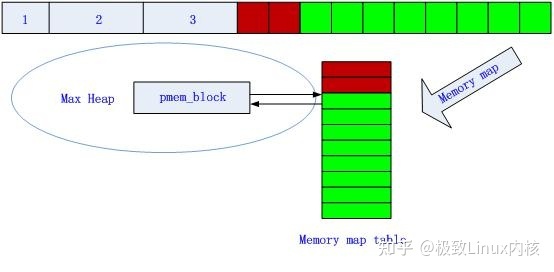
图9 第1次申请128B内存后
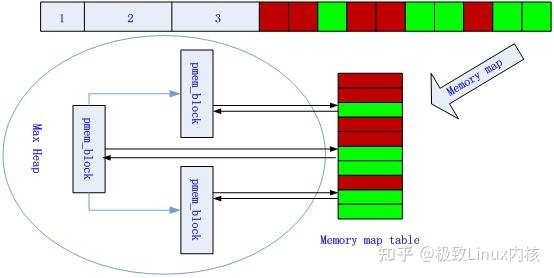
图10 第n次申请、释放内存后
释放内存
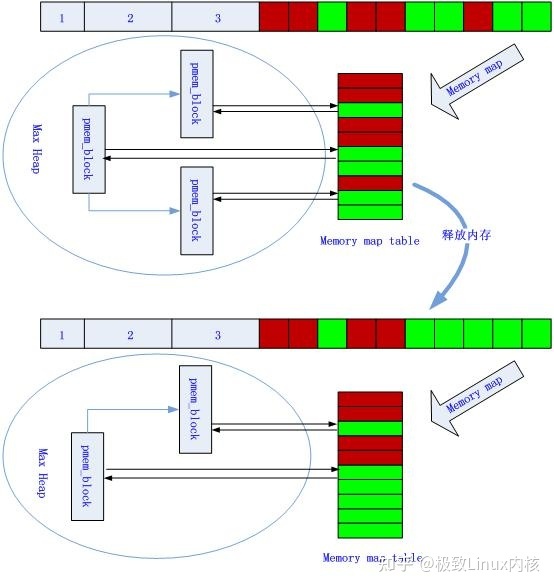
图11 释放64B内存前后
四.性能测试
测试对象:C语言的malloc、free和本文的两种内存池(大小为500M,实际可分配内存为310M)。
测试指标:执行n=2000次随机分配、释放随机大小内存(范围为64B~1024B)的时间比。
测试方法1:
(1) 生成n个随机数,大小在64~1024之间,用于表示n个要分配的内存大小;
(2) 生成n个随机数,取值 为0或者1,表示每次分配内存后紧接着是否释放内存;
(3) 测量C语言的malloc、free和本文两种内存池执行n次随机分配、释放随机大小内存的时间比ratio;
(4) 重复(3)m=200次,记录每次活动的ratio,并绘制相应的曲线。
测试方法2:
(1) 生成n个随机数,大小在a~b之间(初始值a=64,b=1024),用于表示n个要分配的内存大小;
(2) 测量C语言的malloc、free和本文两种内存池执行n次分配、释放随机大小内存的时间比ratio;
(3) 重复(2)m=512次,每次分配的内存容量的范围比前一次大1024B,记录每次获得的ratio,并绘制相应曲线。
1. 性能测试结果-链表结果内存池
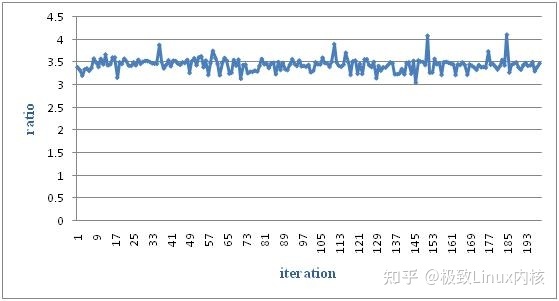
图12 链表结构内存池性能测试结果1

图13 链表结构内存池性能测试结果2
2. 性能测试结果-大顶堆结构内存池
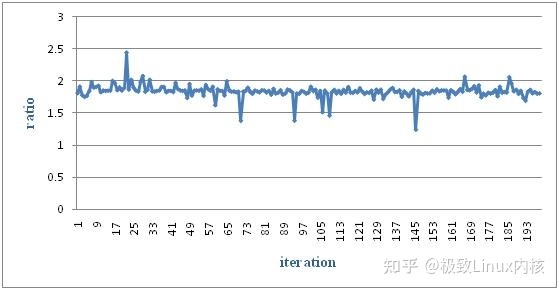
图14 大顶堆内存池性能测试结果1
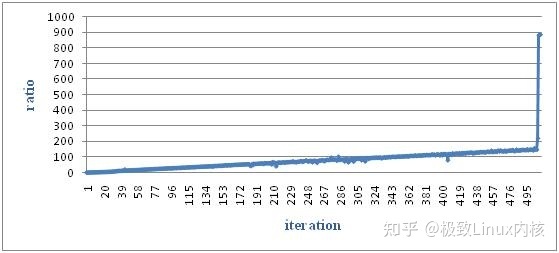
图15 大顶堆内存池性能测试结果2
3. 性能比较
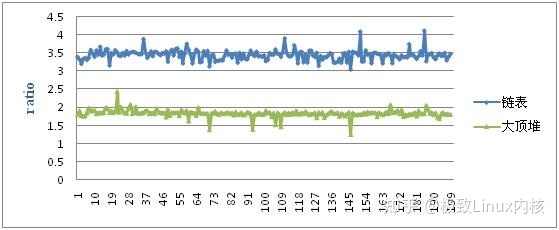
图16 两种内存池性能测试结果比较1

图17 两种内存池性能测试结果比较2
五.结论
从上面的内存池性能测试结果中可以看出,相比C语言的malloc和free,内存池使得用户分配内存和释放内存的效率有了较大的提高,这一优势尤其分配较大快的内存时体现的尤为突出。
同时也可以看出大顶堆结够的内存池的性能并不比链表结构的内存池性能高,反而低于链表结构内存池的性能。这再一次表明O(log(n))优于O(n)是有条件的。当然,本文的测试具有一定的局限性,也许在其他的测试案例中大顶堆结构的内存池性能会超越链表结构的内存池。
【推荐阅读】深入了解Linux内核MMU管理机制

