
热门标签
热门文章
- 1antd upload 文件上传状态控制 与from 表单数据绑定 问题记录_antd的upload组件上传excel文件放在form表单提交拿不到文件
- 2输入正整数n求出前1-n整数和_编写一个程序,输入一个正整数n,输出前n个自然数之和。
- 3网页常见布局案例解析+代码_简单页面布局代码
- 4【循环神经网络系列】三、GRU_使用gru神经网络的结构
- 5python小波包分解_小波分解和小波包分解
- 6互联网大厂面经分享_值得买科技公司面试
- 7一、列表简介(1)_列表中必须有元素,不能为空,这句话对不对
- 8Mysql ERROR 1040: Too many connections连接数满_connect error (1040) too many connections
- 9oracle 复制工具类,oracle 常用工具类及函数
- 10flask各种版本的项目,终端命令运行方式的实现
当前位置: article > 正文
Stable Diffusion 模型界面介绍_stable diffusion界面
作者:IT小白 | 2024-03-26 00:43:31
赞
踩
stable diffusion界面
Stable Diffusion 模型界面介绍
- 界面1
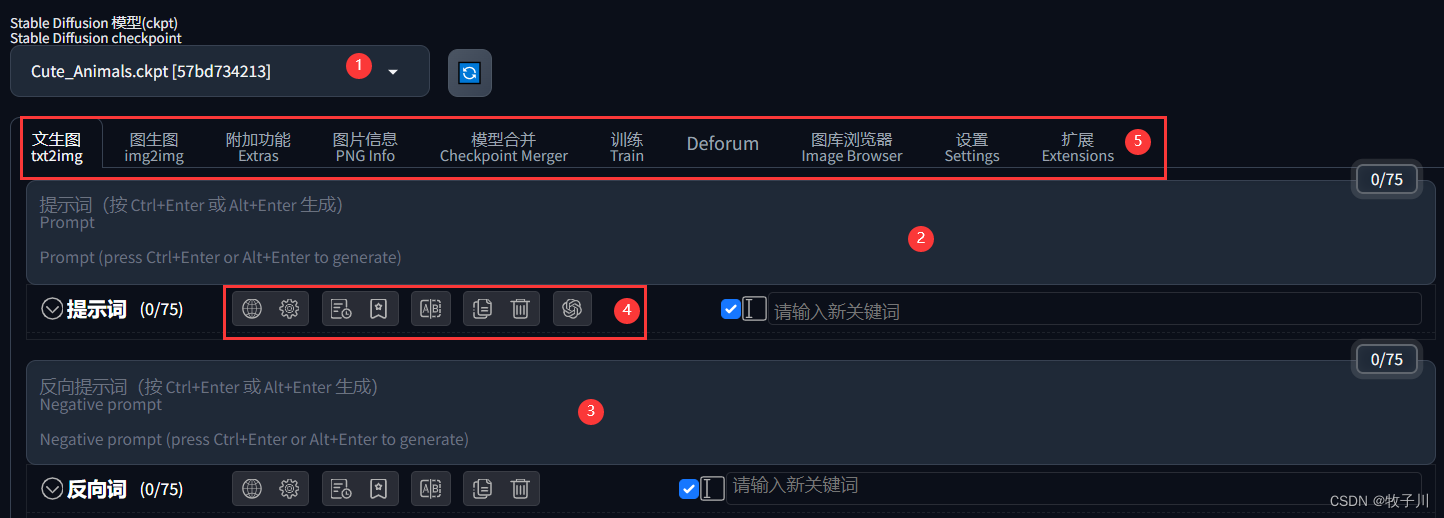
②:prompt --> 正向提示词。表示你的想法,你想要生成一副什么样的图片,包含主体、风格、色彩、质量要求等等
③:negative prompt --> 反向提示词。表示你不想要什么,如不想要图片出现什么,不想图片质量差,不想人物模糊或者多手多脚等
④:提示词相关设置
⑤:选择的样式,一般都是用于文生图(由文字生成图片)和图生图(由一个图片生成另一个图片)
- 界面2
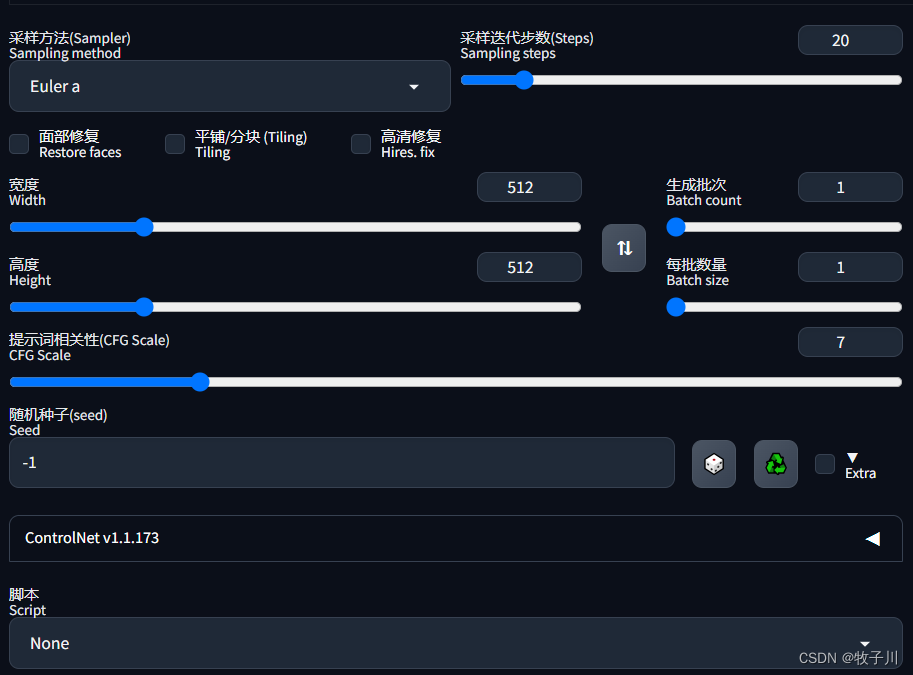
采样方法(Sampler):表示绘制时算法采用偏向哪种风格。目前大众使用的有两种,写实风格使用DPM++ SDE Karras;偏动漫风格一点使用DPM++ 2M Karras。 采样迭代步数(Steps):表示图片生成过程迭代的次数 面部修复(Restore faces):人物风格图片时针对脸部会有一定稳定效果,不会出现奇奇怪怪的五官或者模糊不清 平铺/分块(Tiling):一般不使用 高清修复(Hires.fix):将生成的图片进行高清放大,提升分辨率 宽度(Width):生成的图片宽度 高度(Height):生成的图片高度 生成批次(Batch count):表示绘制时通过几个批次进行绘画 每批数量(Batch size):表示每批生成几张图片 提示词相关性(CFG Scale):数值越大,生成的图片与你的prompt描述越像;数值越小与你的描述关联度越低。一般为5-10之间。 重绘幅度(Denoising):用于在原图上进行重绘的程度 随机种子(Seed):-1表示不基于图片种子进行绘制,完全基于你的prompt生成(未使用种子,出图都是随机状态);如果不为-1,生成的图片会依据图片进行二次绘制。(随机种子的用途就是固定生成图片过程中所产生的随机数,从而在下次生成图片时最大限度的进行还原) 差异随机种子(Variation seed):让生成的图片有更多变化。需点击Extra才能设置。 ControlNet: ControlNet是一个用于深度神经网络的控制技术,它可以通过操作神经网络块的输入条件来控制神经网络的行为 脚本(Script):功能相对较多,一般用得很少。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 界面3
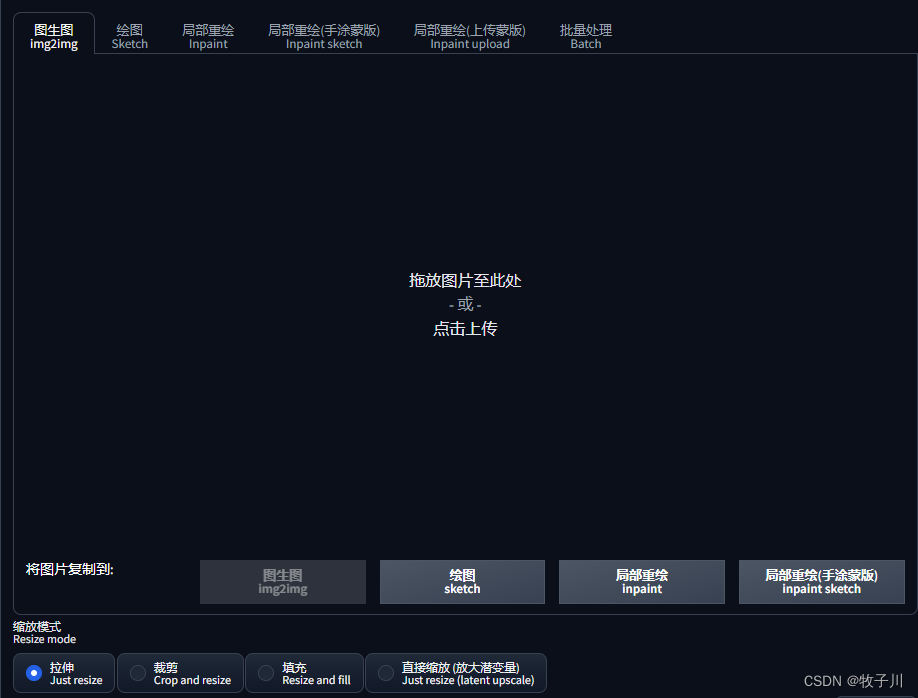
绘图、局部重绘、局部重绘(手涂蒙版):都是可以在线对原图进行修改;
局部重绘(上传蒙版):是上传原图和修改后端蒙版图
批量处理:对本地目录下的所有图片进行处理
缩放模式(Resize mode):对图片的尺寸的修改
4. 界面4
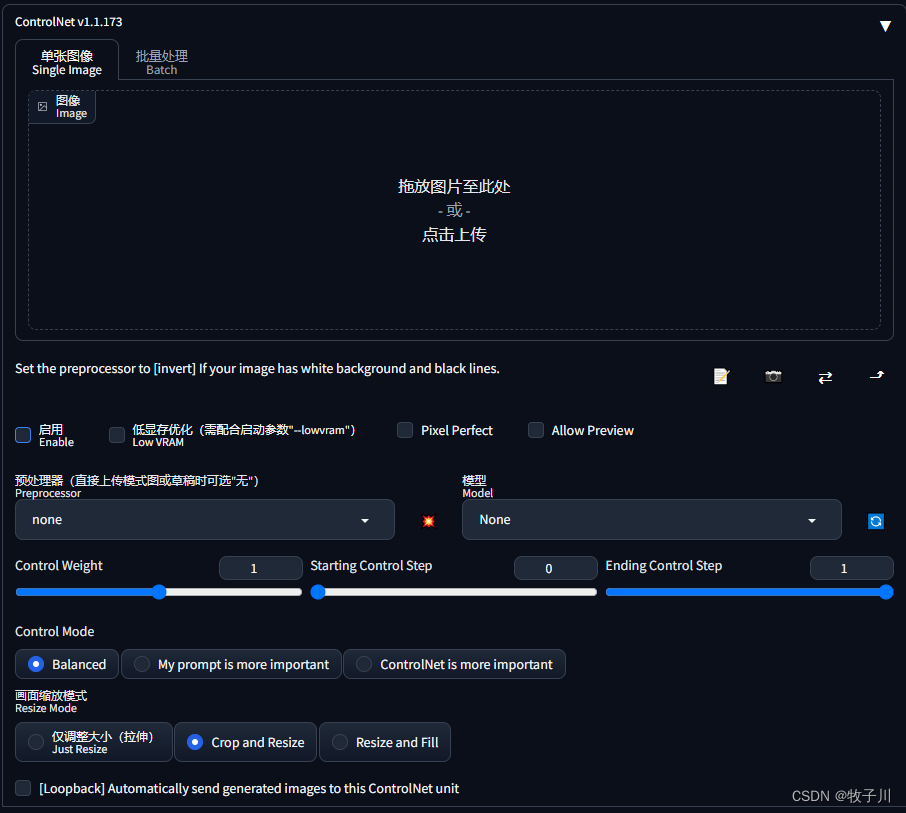
启用(Enable):勾选此选项后,点击 “生成” 按钮时,ControlNet 才会生效。 反色模式(Invert Input Color):将图像颜色进行反转后应用。 RGB 转 BGR(RGB to BGR):把颜色通道进行反转,在 NormalMap 模式可能会用到。 低显存优化(Low VRAM):低显存模式,如果你的显卡内存小于等于4GB,建议勾选此选项。 无提示词的猜测模式(Guess Mode):也就是盲盒模式,不需要任何正面与负面提示词,出图效果随机,很有可能产生意想不到的惊喜效果! 预处理器(Preprocessor):在此列表我们可选择需要的预处理器,每个 ControlNet 的预处理器都有不同的功能,后续将会详细介绍。 模型(Model):配套各预处理器需要的专属模型。该列表内的模型必须与预处理选项框内的名称选择一致,才能保证正确生成预期结果。如果预处理与模型不一致其实也可以出图,但效果无法预料,且一般效果并不理想。 权重(Weight):权重,代表使用 ControlNet 生成图片时被应用的权重占比。 引导介入时机(Guidance Start(T)):在理解此功能之前,我们应该先知道生成图片的 Sampling steps 采样步数功能,步数代表生成一张图片要刷新计算多少次,Guidance Start(T) 设置为 0 即代表开始时就介入,默认为 0,设置为 0.5 时即代表 ControlNet 从 50% 步数时开始介入计算。 引导退出时机(Guidance End(T)):和引导介入时机相对应,如设置为1,则表示在100%计算完时才会退出介入也就是不退出,默认为 1,可调节范围 0-1,如设置为 0.8 时即代表从80% 步数时退出介入。 缩放模式(Resize Mode):用于选择调整图像大小的模式:默认使用(Scale to Fit (Inner Fit))缩放至合适即可,将会自动适配图片。 一共三个选项:Just Resize,Scale to Fit (Inner Fit),Envelope (Outer Fit) 画布宽度和高度(Canvas Width 和 Canvas Height):画布宽高设置,请注意这里的宽高,并不是指 SD 生成图片的图像宽高比。该宽高代表 ControlNet 引导时所使用的控制图像的分辨率,假如你用 SD 生成的图片是 1000x2000 分辨率,那么使用 ControlNet 引导图像时,对显存的消耗将是非常大的;我们可以将引导控制图像的分辨率设置为 500x1000 ,也就是缩放为原本图像一半的分辨率尺寸去进行引导,这有利于节省显存消耗。 创建空白画布(Create Blank Canvas):如果之前使用过 ControlNet 功能,那么将会在 ControlNet 的图像区域留有历史图片,点击该按钮可以清空之前的历史,也就是创建一张空白的画布。 预览预处理结果(Preview Annotator Result):点击该按钮可以预览生成的引导图。例如:如果使用 Canny 作为预处理器,那么点击该按钮之后,可以看到一张通过 Canny 模型提取的边缘线图片。 隐藏预处理结果(Hide Annotator Result):点击该按钮可以隐藏通过 Preview 按钮生成的预览图像窗口(不建议隐藏)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 界面5

反推提示词:
⒈使用CLIP模型从图片中反推图片用到的正向提示词
⒉使用DeepBooru模型从图片中反推图片用到的正向提示词
模板风格(Styles):就是提示词的模板
①、②:读取你上一张图的所有参数信息(包括提示词)
③:删除、清空关键词
④:模型选择管理
⑤:提示词模板,将已选择的模板风格写入当前提示词
⑥:提示词模板,将当前提示词(prompt )保存为模板风格
- 界面6
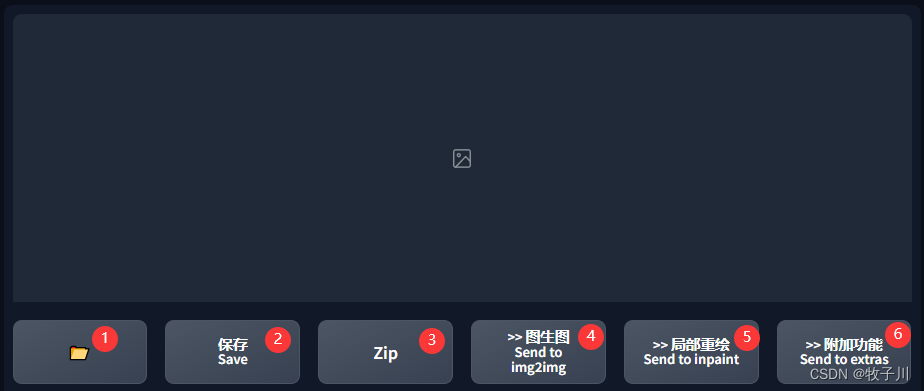
①:打开图像输出目录
②:保存当前选择的图片,会在下方出现图片链接,点击Download即可下载
③:将图片保存为压缩包格式
④:选择当前图片作为图生图的初始图片
⑤:选择当前图片作为图生图的初始图片,并能在图片上进行绘制
⑥:选择当前图片作为图生图附加功能进行绘制
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/313485
推荐阅读
相关标签

