
- 1机器学习&&深度学习——NLP实战(情感分析模型——textCNN实现)_thunlp 情感分析模型训练
- 2Transformer原理详解
- 3看大神如何用python爬虫爬取京东商品评论_python爬虫爬取京东电商平台商品评论,要求根据商品关键字爬取
- 4数据分析之Tebleau可视化:折线图、饼图、环形图
- 5git:分支切换_git 切换分支
- 6【学习笔记--短文】你知道神经网络中token的作用吗?_token神经网络什么术语
- 7人工智能概念_人工智能 概念
- 8ACE2005数据预处理步骤
- 9脉冲神经网络:MATLAB实现脉冲神经网络(Spiking Neural Network,SNN) 用于图像分类(提供MATLAB代码)_脉冲神经网络代码
- 10实体关系抽取
4. 一起学习机器学习 -- Logistic regression
赞
踩
Prerequisites
Outline
- Section 1: Intro to Logistic Regression
- Section 2: Dataset Generation
- Section 3: Logistic Parametric Function
- Section 4: Optimising Logistic Regression Parameters
- Section 5: Model evaluation
- Extra 1: Receiver Operating Characteristic (ROC)
Logistic regression
The purpose of this notebook is to understand and implement logistic regression. As always, you are not allowed to use any package that has a complete logistic regression framework implemented (e.g., scikit-learn).
Section 1: Intro to Logistic Regression ^
Logistic regression, despite its name, is a linear model for classification rather than regression. In its original form, it is used for binary classifications, i.e., assigning a data point in our test set a binary label (e.g., yes or no, 0 or 1, red or blue). The reason why the term logistic regression is used becomes obvious once we examine the logistic function (often also called sigmoid function):
h
(
z
)
=
1
1
+
e
−
z
h(z) = \frac{1}{1+e^{-z}}
h(z)=1+e−z1
Next, you will implement the logistic function using numpy.
# Importing standard packages
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
# Changing default font sizes
plt.rc('xtick', labelsize=16) # Tick labels
plt.rc('ytick', labelsize=16) # Tick labels
plt.rc('legend', fontsize=14) # Legend
plt.rc('axes', titlesize=24, labelsize=20) # Title and 'x' and 'y' labels
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
## EDIT THIS FUNCTION
def logistic(z):
return 1. / (1. + np.exp(-z)) ## <-- SOLUTION
- 1
- 2
- 3
Let’s plot the function to see how it behaves.
plt.figure(figsize=(12,8))
z = np.linspace(-6, 6, 1000)
y = logistic(z)
plt.xlabel(r'$z$')
plt.ylabel(r'$h(z)$')
plt.title('Sigmoid function')
plt.grid(alpha=0.5)
plt.plot(z, y);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
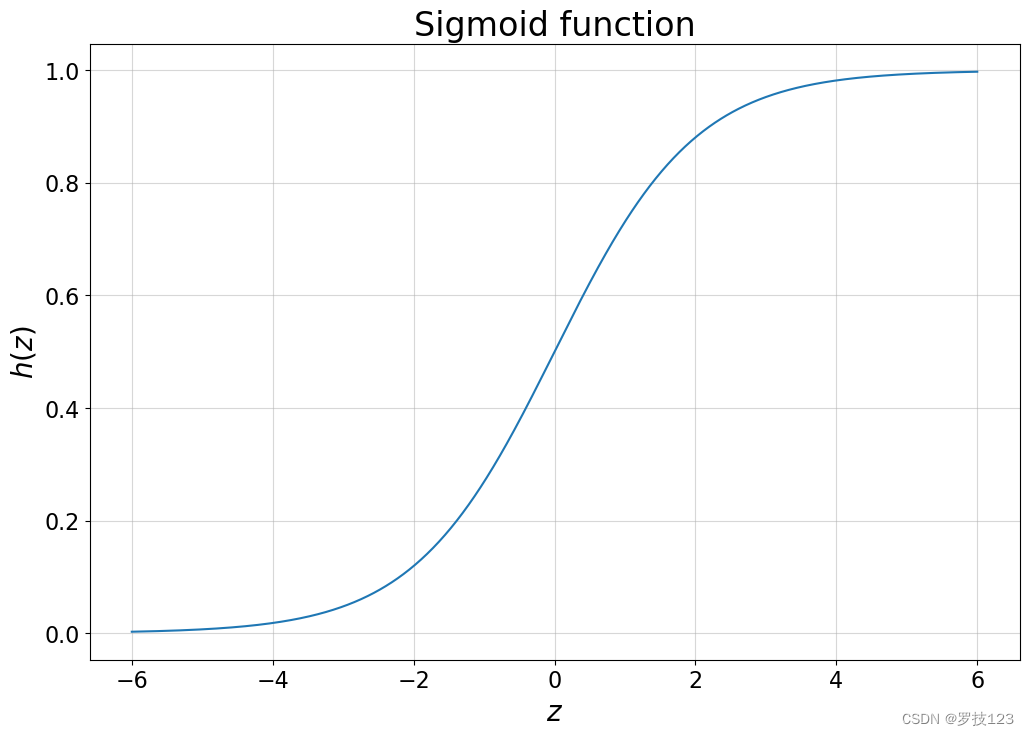
Questions:
- Can you already guess why this regression model is used in binary classification tasks?
- What do the bounds of the logistic function tell you?
Section 2: Dataset Generation ^
Let’s generate now a dataset with
p
=
2
p=2
p=2 features using sklearn’s make_classification function:
X_f, y = make_classification(n_samples=500, n_features=2, n_redundant=0, n_informative=2, n_clusters_per_class=1, random_state=14)
plt.figure(figsize=(12,8))
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('2-class dataset')
plt.scatter(X_f[:,0], X_f[:,1], c=y.reshape(-1), cmap='bwr');
- 1
- 2
- 3
- 4
- 5
- 6
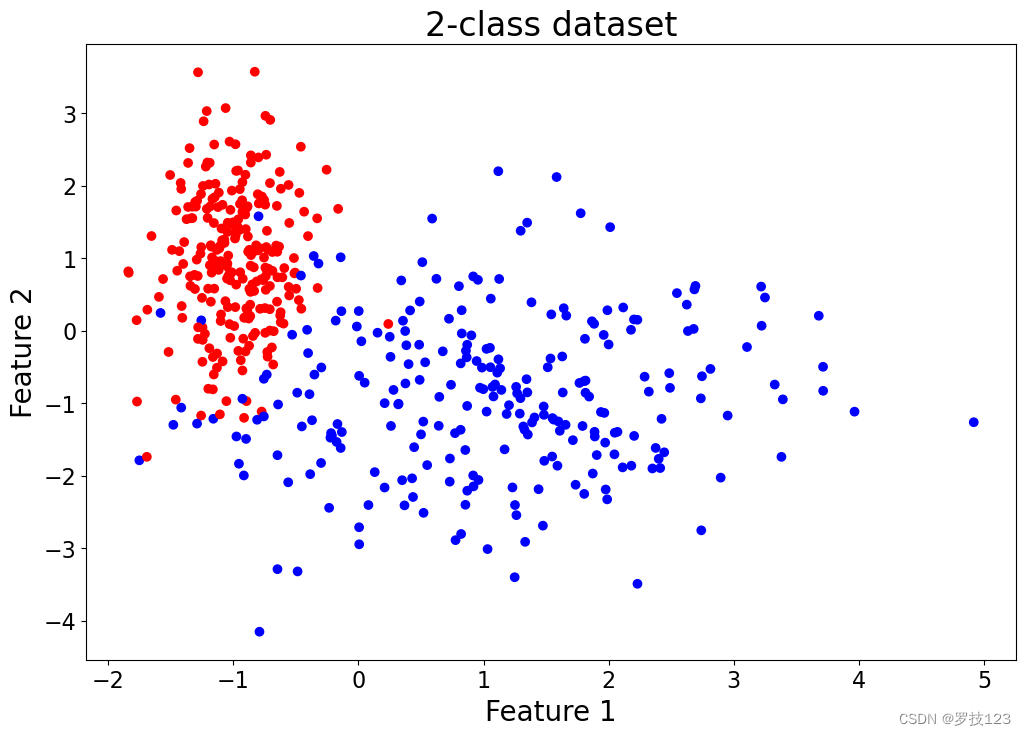
We divide the dataset into training and test set and run our model with our own choice of hyperparameters:
# Adding a first column of ones allowing for a bias/intercept term X = np.hstack((np.ones((X_f.shape[0], 1)), X_f)) # Stacking data 'X' and labels 'y' into one matrix data = np.hstack((X, y[:, np.newaxis])) # Shuffling the rows np.random.shuffle(data) # Splitting into training and test in a 70-30 ratio split_rate = 0.7 train, test = np.split(data, [int(split_rate*(data.shape[0]))]) X_train = train[:,:-1] y_train = train[:, -1] X_test = test[:,:-1] y_test = test[:, -1] y_train = y_train.astype(int) y_test = y_test.astype(int)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
Section 3: Logistic Parametric Function ^
In logistic regression, we estimate the parameter vector β = [ β 0 , β 1 , … , β p ] T ∈ R p + 1 \boldsymbol \beta=[\beta_0, \beta_1, \dots, \beta_p]^T \in \mathbb R^{p+1} β=[β0,β1,…,βp]T∈Rp+1 as in linear regression. However, the final step involves passing the output through a logistic function. We call the output of this operation h β ( X ) h_{\boldsymbol \beta}(\boldsymbol X) hβ(X):
h β ( X ) : = h ( X β ) h_{\boldsymbol \beta}(\boldsymbol X) := h(\boldsymbol X \boldsymbol \beta) hβ(X):=h(Xβ)
where $\boldsymbol X =
$ and x ( i ) = [ 1 , x 1 ( i ) , … , x p ( i ) ] T ∈ R p + 1 \boldsymbol x^{(i)} = [1, x_1^{(i)}, \dots, x_p^{(i)}]^T \in \mathbb R^{p+1} x(i)=[1,x1(i),…,xp(i)]T∈Rp+1.
Note that h h h is again the logistic function and, consequently, we have a probability of the given data point belonging to one of the two classes, such as red or blue. To label the data points, we can designate those with a probability above 0.5 0.5 0.5 as red and those with a probability of 0.5 0.5 0.5 or below as blue.
In the following cell, write an implementation of h β ( X ) h_{\boldsymbol \beta}(\boldsymbol X) hβ(X).
## EDIT THIS FUNCTION
def predict_log(X, beta):
y_log = logistic(X @ beta) ## <-- SOLUTION
return y_log.squeeze()
- 1
- 2
- 3
- 4
Section 4: Optimising Logistic Regression Parameters ^
Parameter Initialisation
A common technique in Machine Learning is to initialise the parameter vector β \boldsymbol \beta β randomly or with zeros; we do the latter here.
def initialise(size):
"""
Argument:
size: Size of the parameter vector beta
Returns:
beta: Initialised vector of shape (size, 1)
"""
beta = np.zeros((size, 1))
return beta
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Parameter Optimisation
From the lecture notes, we know that the logistic regression parameters can be estimated by maximising the log-likelihood function. We can then consider the negative log-likelihood loss function and minimise the associated mean sample loss:
E
(
L
)
=
−
1
N
∑
i
=
1
N
y
(
i
)
log
h
β
(
x
(
i
)
)
+
(
1
−
y
(
i
)
)
log
(
1
−
h
β
(
x
(
i
)
)
)
E(L) = - \frac{1}{N}\sum_{i=1}^N y^{(i)} \log h_{\boldsymbol \beta}(\boldsymbol x^{(i)}) + (1-y^{(i)}) \log (1-h_{\boldsymbol \beta}(\boldsymbol x^{(i)}))
E(L)=−N1i=1∑Ny(i)loghβ(x(i))+(1−y(i))log(1−hβ(x(i)))
Which has as gradient
∇
β
E
(
L
)
=
1
N
∑
i
=
1
N
(
h
β
(
x
(
i
)
)
−
y
(
i
)
)
x
(
i
)
\nabla_{\boldsymbol \beta} E(L) = \frac{1}{N}\sum_{i=1}^N (h_{\boldsymbol \beta}(\boldsymbol x^{(i)}) - y^{(i)})\boldsymbol x^{(i)}
∇βE(L)=N1i=1∑N(hβ(x(i))−y(i))x(i)
Implement the mean sample loss function and its gradient in the next cell as part of a larger operation which we shall call propagate, often also called a forward pass.
## EDIT THIS FUNCTION def propagate(X, y, beta): """ Arguments: X: Data of shape (N, p+1) y: True label vector of size N beta: Parameter vector, a numpy array of size p+1 Returns: mean_loss: Mean sample loss for the negative log-likelihood dbeta: Gradient of the mean sample loss with respect to beta """ y_log = predict_log(X, beta) # Mean sample loss function mean_loss = - np.mean(y * np.log(y_log) + (1-y) * np.log(1 - y_log)) # Derivatives dbeta = np.mean(X.T * (y_log - y), axis=1).reshape(-1, 1) #* ... ## <-- SOLUTION mean_loss = np.squeeze(mean_loss) # Store gradients in a dictionary grads = {'dbeta': dbeta} return grads, mean_loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
We can now conduct the actual optimisation and update the β \boldsymbol \beta β with a learning rate α \alpha α, which we shall set to 0.1 0.1 0.1. You are required to implement the updating procedure for β \boldsymbol \beta β:
β : = β − α ∇ β E ( L ) \boldsymbol \beta := \boldsymbol \beta - \alpha \nabla_{\boldsymbol \beta} E(L) β:=β−α∇βE(L)
## EDIT THIS FUNCTION def optimise(X, y, beta, num_iterations=1000, learning_rate=0.1, print_loss=False): """ Arguments: X: Data of shape (N, p+1) y: True label vector of size N beta: Parameter vector, a numpy array of size p+1 num_iterations: Number of iterations learning_rate: Step size in updating procedure print_loss: 'True' to print the mean loss every 100 iterations Returns: params: Dictionary containing the parameter vector beta grads: Dictionary containing the gradient mean_loss_history: List of all the mean loss values computed during the optimisation (can be used to plot the learning curve) """ mean_loss_history = [] for i in range(num_iterations): # Calculating the loss and gradients (hint: use your existing functions) grads, mean_loss = propagate(X, y, beta) ## <-- SOLUTION # Retrieving derivatives from grads dbeta = grads['dbeta'] # Updating procedure beta = beta - learning_rate * dbeta ## <-- SOLUTION # Record the loss values if i % 100 == 0: mean_loss_history.append(mean_loss) # Printing the loss every 100 iterations if print_loss and i % 100 == 0: print ('Mean loss after iteration %i: %f' %(i, mean_loss)) # Saving parameters and gradients in dictionary params = {'beta': beta} grads = {'dbeta': dbeta} return params, grads, mean_loss_history
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
Section 5: Model Evaluation ^
Having calculated the parameters for our training set, we can predict the labels for the test set.
## EDIT THIS FUNCTION def predict(X_test, beta): """ Arguments: X_test: Test set of shape (N_test, p+1) beta: Parameter vector, a numpy array of size p+1 Returns: y_pred: Vector containing all binary predictions (0/1) for X_test """ N_test = X_test.shape[0] y_pred = np.zeros((N_test, 1)) beta = beta.reshape(X_test.shape[1], 1) # Predicting the probabilities y_log = predict_log(X_test, beta) y_pred = y_log.round().reshape(1, -1) # <-- SOLUTION return y_pred
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
A pythonic way to define an algorithm is placing all functions in one model that has all hyperparameters as arguments. This allows you to quickly evaluate different hyperparameters and optimise over these. So, let’s do this:
def model(X_train, y_train, X_test, y_test, num_iterations=2000, learning_rate=0.1, print_loss=False): # Initialising parameters with zeros beta = initialise(X_train.shape[1]) # Gradient descent parameters, grads, mean_loss_history = optimise(X_train, y_train, beta, num_iterations, learning_rate, print_loss=print_loss) # Retrieving parameter vector beta from dictionary 'parameters' beta = parameters['beta'] # Predicting test and training set examples y_pred_test = predict(X_test, beta) y_pred_train = predict(X_train, beta) # Printing train/test accuracy print('Training accuracy: {} %'.format(100 - np.mean(np.abs(y_pred_train - y_train)) * 100)) print('Test accuracy: {} %'.format(100 - np.mean(np.abs(y_pred_test - y_test)) * 100)) # Saving all the information d = {'mean_loss_history': mean_loss_history, 'y_pred_test': y_pred_test, 'y_pred_train': y_pred_train, 'beta': beta, 'learning_rate': learning_rate, 'num_iterations': num_iterations} return d
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
# Running the model
d = model(X_train, y_train, X_test, y_test, num_iterations=500, learning_rate=0.1, print_loss=True)
- 1
- 2
Mean loss after iteration 0: 0.693147
Mean loss after iteration 100: 0.187386
Mean loss after iteration 200: 0.159911
Mean loss after iteration 300: 0.148395
Mean loss after iteration 400: 0.141816
Training accuracy: 95.42857142857143 %
Test accuracy: 94.66666666666667 %
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Let’s see how our loss has changed over the training iterations:
loss_history = np.squeeze(d['mean_loss_history'])
plt.figure(figsize=(12,8))
plt.ylabel('Mean training loss')
plt.xlabel('Iterations (in hundreds)')
plt.title('Learning curve for learning rate = ' + str(d['learning_rate']))
plt.plot(loss_history);
- 1
- 2
- 3
- 4
- 5
- 6
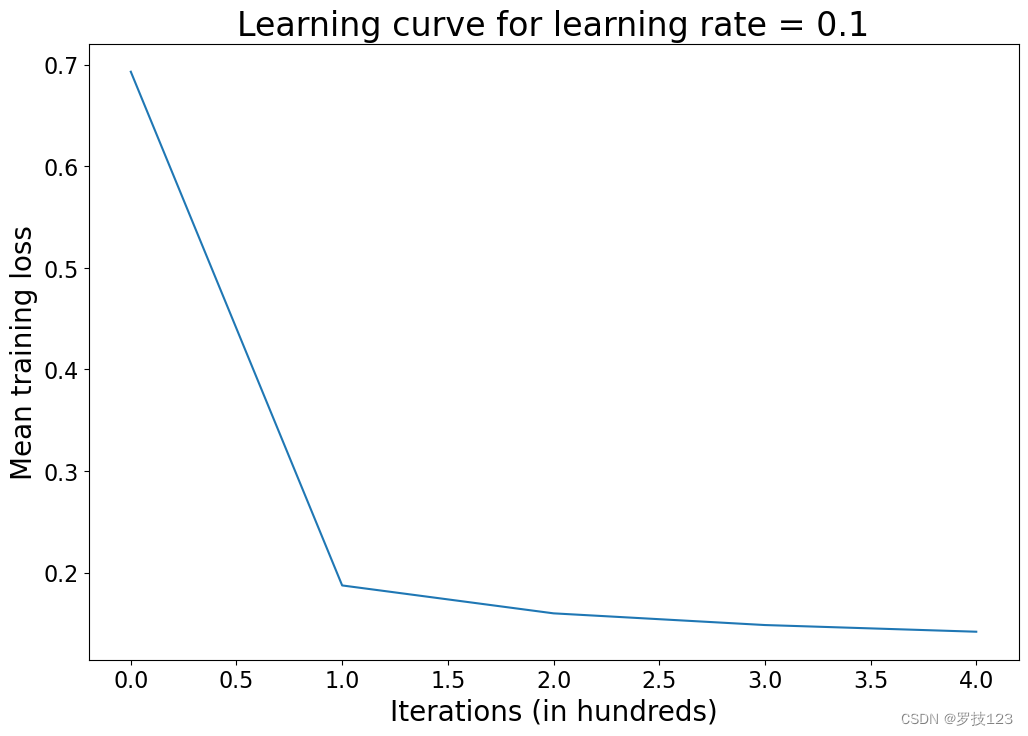
Questions:
- What insights do you gain from this learning curve?
- Try different learning rates, run the model again, and plot the learning curve. What can you observe?
- Use different random states when you generate the data and run the model again. What can you observe?
- Increase the number of features in your generated data and evaluate the accuracies again. How do they change?
- Generate data with sklearn’s
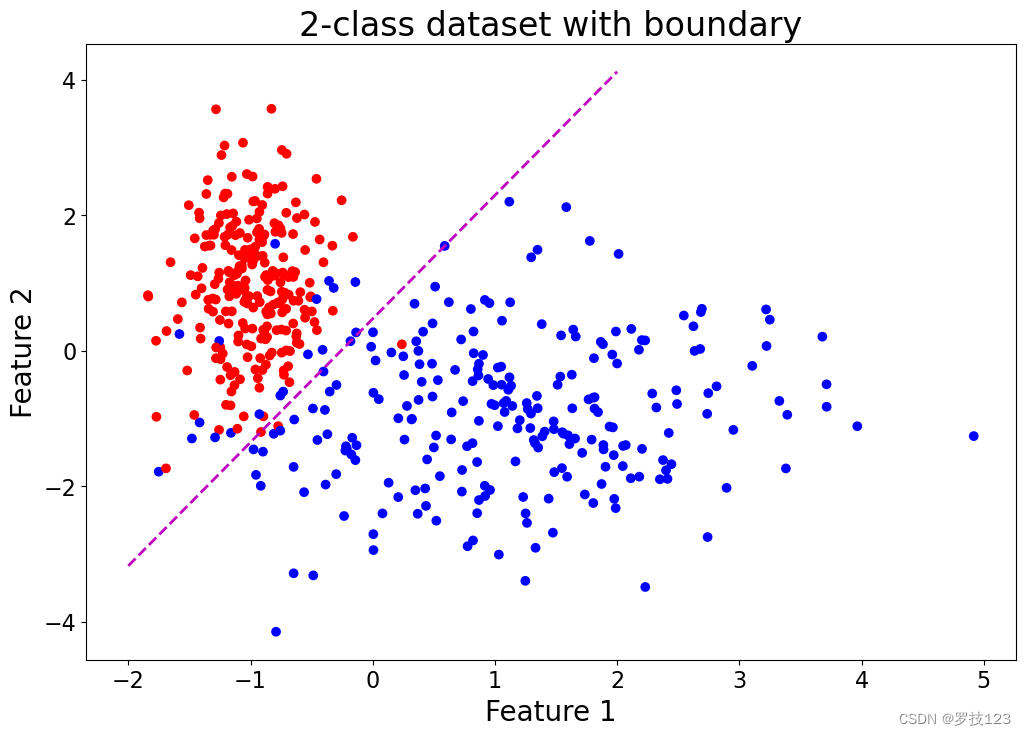
make_moonsfunction (noise > 0.1 > 0.1 >0.1) and evaluate how well logistic regression performs on this dataset. - By performing logistic regression, we have estimated the parameter vector β \boldsymbol \beta β that defines a decision boundary. This is illustrated in the cell below. What does this boundary (the dashed line) mean?
beta = np.squeeze(d['beta'])
plt.figure(figsize=(12,8))
x1 = np.asarray([-2,2])
m = -beta[1]/beta[2]
c = -beta[0]/beta[2]
x2 = m*x1 + c
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.scatter(X[:,1], X[:,2], c=y.reshape(-1), cmap='bwr');
plt.plot(x1, x2, 'm--', lw=2)
plt.title('2-class dataset with boundary')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
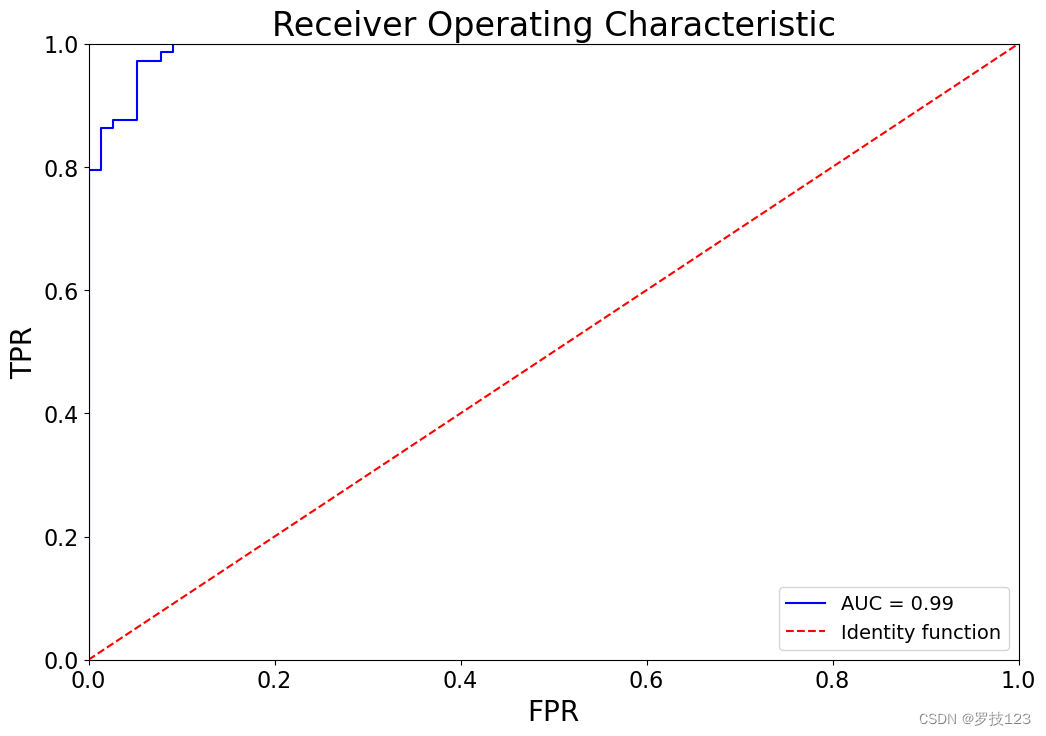
Extra 1: Receiver Operating Characteristic (ROC) ^
Now we can raise interesting questions about accuracy as a metric that we have already used. Recall our functions predict and predict_log, where predict rounds the probabilities computed by predict_log. Rounding means that if the probability is greater than or equal 0.5, then we assign a label of 1 to this example. Consider now two testing examples introduced to the model
x
(
i
)
\boldsymbol x^{(i)}
x(i) and
x
(
j
)
\boldsymbol x^{(j)}
x(j) both sampled with label 1, and the model produces as probabilities
h
β
(
x
(
i
)
)
=
0.49
h_{\boldsymbol \beta}(\boldsymbol x^{(i)}) = 0.49
hβ(x(i))=0.49 and
h
β
(
x
(
j
)
)
=
0.001
h_{\boldsymbol \beta}(\boldsymbol x^{(j)}) = 0.001
hβ(x(j))=0.001. After rounding, using accuracy as a metric will treat both examples equally as false negatives. However, this would neglect the closeness of
h
β
(
x
(
i
)
)
=
0.49
h_{\boldsymbol \beta}(\boldsymbol x^{(i)}) = 0.49
hβ(x(i))=0.49 to the decision boundary, as opposed to
h
β
(
x
(
j
)
)
=
0.001
h_{\boldsymbol \beta}(\boldsymbol x^{(j)}) = 0.001
hβ(x(j))=0.001.
Receiver Operating Characteristic (ROC) curve aims to capture the model output probabilities (or scores) into the quantification of the model performance. In lecture notes, you have learned that ROC curve can be constructed by computing True Positive Rate (TPR) and False Positive Rate (FPR) for a range of thresholds. An ideal model would have Area Under the Curve (AUC) of 1, while a model with random decisions would have an AUC of 0.5.
Let’s consider the following procedure to construct a ROC curve:
- Define the set of thresholds. This can be uniformly spaced thresholds between 1 and 0. However, the number of threshold values to consider remains a parameter. Alternatively, we may consider only the distinct probability values in
y_log.
For example, if the computed
y_logfor four-examples is[0.8, 0.4, 0.9, 0.8], then we have{0.4, 0.8, 0.9}as distinct values. If we scan the range of thresholds from 1 to 0 using very small steps, we can see that the FPR and TPR will remain unchanged unless we cross these values{0.9, 0.8, 0.4}. This means we can just use the distinct values iny_log(sorted in decreasing order) as threshold values to evaluate the list of TPR and FPR that we need to construct the ROC curve.
- Starting from the greatest to the least threshold, compute the TPR and FPR and store them in an array or list.
- At this point, AUC can be computed using the Trapezoidal rule (see numpy.trapz).
def roc_curve(y_true, y_log): """ Arguments: y_true: Ground truth labels with size N y_log: Probabilities produced by logistic regression model with size N Returns: auc: Area Under the Curve (AUC) tpr_l: List of true positive rate (TPR) values for each scanned threshold fpr_l: List of false positive rate (FPR) values for each scanned threshold thresholds: Scanned thresholds sorted in decreasing order """ # List of distinct values in y_log, sorted sorted in decreasing order thresholds = reversed(sorted(set(y_log))) # <-- SOLUTION tpr_l, fpr_l = [], [] for threshold in thresholds: # Thresholding y_thresholded = (y_log >= threshold) # True positives tp = np.sum(y_true & y_thresholded) # True negatives tn = np.sum((~y_true) & (~y_thresholded)) # False positives fp = np.sum((~y_true) & y_thresholded) # False negatives fn = np.sum(y_true & (~y_thresholded)) tpr = tp / (tp + fn) # <-- SOLUTION fpr = fp / (tn + fp) # <-- SOLUTION tpr_l.append(tpr) fpr_l.append(fpr) # Compute AUC using Trapezoidal rule auc = np.trapz(tpr_l, fpr_l) return auc, tpr_l, fpr_l, thresholds
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
y_log = predict_log(X_test, d['beta'])
auc, tpr, fpr, th = roc_curve(y_test, y_log)
plt.figure(figsize=(12,8))
plt.title(f'Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label=f'AUC = {auc:0.2f}')
plt.plot([0, 1], [0, 1], 'r--', label='Identity function')
plt.legend(loc='lower right')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('TPR')
plt.xlabel('FPR')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Questions:
- Compare the AUC you get with
sklearn.metrics.roc_curveandsklearn.metrics.auc. - Plot the ROC curve for training and test on the same plot. What can you observe?
- Can you replicate your results using sklearn?
- Based on sklearn’s documentation, can you see any differences in the algorithms that are implemented in sklearn?

