
- 1机器学习——最优化模型
- 2JVM学习-类加载器_java_home/jre/lib目录可以自己添加类吗
- 3【MMDetection3D】基于单目(Monocular)的3D目标检测入门实战_mmdetection 3d
- 4Linux chown命令详解
- 5AIC和BIC在Python中的应用_python中ar模型aic bic
- 6oracle asm磁盘组三种模式_Oracle数据库高可用性–扩展的RAC和MAA
- 7机器学习算法基于语言模式辅助诊断抑郁症
- 8【透视图像目标检测(0)】卷首语
- 9深入理解PyTorch中的nn.Embedding
- 10IJCAI 2023|CiT-Net: Convolutional Neural Networks Hand in Hand with Vision Transformers for Medical
深入浅出语言模型(三)——语境化词向量表示(CoVe、ELMo、ULMFit、GPT、BERT)_cove 模型
赞
踩
引言
上一节我们讲到了什么叫做静态词向量,静态词向量有个很大的特点就是每个词的表示是固定的,这样就不能解决我们人类语言中的一词多义问题,例如“I hurt my back, while I backed my car”,这句话中前一个"back"是一个名词,表达“后背”的意思;后一个“back”是动词,表达“倒车”的意思。所以这两个词向量应该是不一样的,应该考虑上下文来确定某个词在一个句子中表达什么意思,这样上下文词向量,也叫语境化词向量就应运而生了。
深入浅出语言模型(一)——语言模型及其有趣的应用
深入浅出语言模型(二)——静态语言模型(独热编码、Tf-idf、word2vec、FastText、glove、Gussian Embedding、Pointcare Embedding )
深入浅出语言模型(三)——语境化词向量表示(CoVe、ELMo、ULMFit、GPT、BERT)
深入浅出语言模型(四)——BERT的后浪们(RoBERTa、MASS、XLNet、UniLM、ALBERT、TinyBERT、Electra)
Contextualized Embedding(语境化词向量)
CoVe
2017 年,Salesforce 的 Bryan McCann 等人发表了一篇文章 Learned in Translation: Contextualized Word Vectors,论文首先用一个 Encoder-Decoder 框架在机器翻译的训练语料上进行预训练(如下图a),而后用训练好的模型,只取其中的 Embedding 层和 Encoder 层,同时在一个新的任务上设计一个 task-specific 模型,再将原先预训练好的 Embedding 层和 Encoder 层的输出作为这个 task-specific 模型的输入,最终在新的任务场景下进行训练(如下图b)。
他们尝试了很多不同的任务,包括文本分类,Question Answering,Natural Language Inference 和 SQuAD 等,并在这些任务中,与 GloVe 作为模型的输入时候的效果进行比较。实验结果表明他们提出的 Context Vectors 在不同任务中都带来了不同程度效果的提升(如下图c)。

CoVe 更侧重于如何将现有数据上预训练得到的表征迁移到新任务场景中,这个预训练得到的encoder的信息其实就是一种语境化或者上下文相关的信息。CoVe 似乎通过监督数据上的预训练,取得了让人眼前一亮的结果,是否可以进一步地,撇去监督数据的依赖,直接在无标记数据上预训练呢?
ELMo
严格意义上来说刚才讲的CoVe并不是一个语言模型,因为它是一个有监督的模型(我们在第一节说过语言模型是一个经典的无监督模型),CoVe利用的是Encoder+Decoder的机器翻译模型进行预训练。Elmo和他的区别是他仅仅利用的是seq2seq的Encoder,并且是一个自监督训练,是一个严格意义上的语言模型。在EMLo中,他们使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,这里的模型目标是预测对应位置的下一个单词(也就是T1的向量应该预测出E2的单词)。
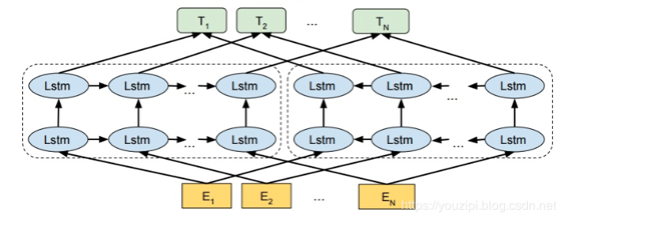
目标函数就是取这两个方向语言模型的最大似然。
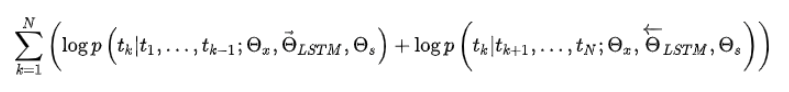
在预训练好这个语言模型之后,ELMo就可以用作词表示,其实就是把这个双向语言模型的每一中间层进行一个求和,句子中每个单词都能得到对应的三个Embedding: 最底层是单词的 Word Embedding,往上走是第一层双向LSTM中对应单词位置的 Embedding,**这层编码单词的句法信息更多一些;**再往上走是第二层LSTM中对应单词位置的 Embedding,这层编码单词的语义信息更多一些。(不同层表示不一样的,如在双向LSTM神经网络中,词性标注在较低层编码好,而词义消歧义用上层编码更好)。最简单的也可以使用最高层的表示来作为ELMo。然后在进行有监督的NLP任务时,可以将ELMo直接当做特征拼接到具体任务模型的词向量输入或者是模型的最高层表示上。
总结一下,不像传统的词向量,每一个词只对应一个词向量,ELMo利用预训练好的双向语言模型,然后根据具体输入从该语言模型中可以得到上下文依赖的当前词表示(对于不同上下文的同一个词的表示是不一样的),再当成特征加入到具体的NLP有监督模型里。
我们现在来看Elmo的话,他有两个明显的缺点:
- 一个非常明显的缺点在特征抽取器选择方面,LSTM的特征抽取能力远远低于Transformer。
- 拼接方式粗暴的拼接双向融合可能效果并不是最佳。
Elmo的训练方式是一种自回归(Autoregressive)模型,通过语言模型从左到右的一种预测方式。
ULMFit
差不多和 ELMo 同期,另一个同样非常惊艳的工作也被提出来,因为他的效果很好,这里我们简单说一下他的思想。和 ELMo 相同的地方在于,ULMFit 同样使用了语言模型,并且预训练的模型主要也是LSTM,基本思路也是预训练完成后在具体任务上进行 finetune,但不同之处也有很多。
首先,ULMFit 的预训练和 finetune 过程主要分为三个阶段,分别是在大规模语料集上(比如 Wikitext 103,有 103 million 个词)先预训练,然后再将预训练好的模型在具体任务的数据上利用语言模型来 finetune(第一次 finetune,叫做 LM finetune),再根据具体任务设计的模型上,将预训练好的模型作为这个任务模型的多层,再一次 finetune(第二次 finetune,如果是分类问题的话可以叫做 Classifier finetune),整个过程如下所示:

GPT
这是OpenAI 团队所做的工作。他们的目标是学习一个通用的表示,能够在大量任务上进行应用。这篇论文的亮点主要在于,他们利用了Transformer网络代替了LSTM作为语言模型来更好的捕获长距离语言结构。然后在进行具体任务有监督微调时使用了语言模型作为附属任务训练目标。最后再12个NLP任务上进行了实验,9个任务获得了SOTA。
按照论文的说法,GPT 使用的 Transformer 是只用了 Decoder,因为对于语言模型来讲,确实不需要 Encoder 的存在。而具体模型,他们参考了 2018 年早些时候谷歌的 Generating Wikipedia by Summarizing Long Sequences,GPT 名称中的 Generative 便是源自这篇文章,二者都有用到生成式方法来训练模型,也就是生成式 Decoder。

上图展示了 GPT 的预训练过程,其实和 ELMO 是类似的,主要不同在于三点:
- 特征抽取器不是用的 RNN,而是用的 Transformer,上面提到过它的特征抽取能力要强于 RNN,这个选择很明显是很明智的;
- ELMO使用上下文对单词进行预测,而 GPT 则只采用 Context-before 这个单词的上文来进行预测,而抛开了下文。
- 与ELMo当成特征的做法不同,OpenAI GPT不需要再重新对任务构建新的模型结构,而是直接在transformer这个语言模型上的最后一层接上softmax作为任务输出层,然后再对这整个模型进行微调。
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention
整个模型的训练过程分为两步:
- 无监督的预训练:给定句子 U = [ u 1 , u 2 , . . . , u n ] U=[u1, u2, ..., un] U=[u1,u2,...,un],GPT 训练语言模型时需要最大化下面的似然函数。
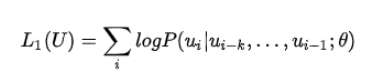
- 有监督的微调:GPT 经过预训练之后,会针对具体的下游任务对模型进行微调。微调的过程是有监督学习,训练样本包括单词序列 [ x 1 , x 2 , . . . , x m ] [x1, x2, ..., xm] [x1,x2,...,xm] 和 类标 y y y。
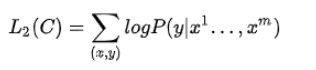
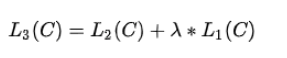
这个任务的一个小缺点就是对于某些类型的任务需要对输入数据的结构作调整。例如 对于文本蕴涵任务,需要将前提和假设用一个Delim分割向量拼接后进行输入;对于文本相似度任务,在两个方向上都使用Delim拼接后,进行输入;对于像问答多选择的任务,就是将每个答案和上下文进行拼接进行输入。
为什么Transformer要比LSTM捕获特征更优秀?
1, 首先LSTM作为一个序列模型很难捕捉长距离依赖的关系,例如一个句子中主语在前面,如果句子很长的话,句子后半段的处理将会丢失掉主语的信息,所以会出现一些错误的判断和语义理解等等。LSTM也容易出现梯度消失和梯度爆炸等问题。梯度更新的过程就是捕获单词之间的关系过程(任何神经网络结构的本质都是特征提取,更新梯度的过程就是学习的过程,我们建模的目标就是通过模型学习特征到标签的映射关系),所以梯度计算不准确就很难很好捕获单词关系。
2. LSTM作为一个序列模型,有一个天然的缺点是不可以并行处理。
对于缺陷1,Transformer使用了self-attention,在自注意力中,一个句子任意两个单词之间的关系都是平等的关系,不会出现无法捕捉长距离依赖的关系。
对于缺陷2,Transformer虽然也是基于序列设计的,但是可以并行的。
BERT
动机
以前的语言模型大多都是自回归的模型,我们也在前面分析过,都是利用单向的语言信息(例如从左到右生成),这样没有充分利用上下文信息,例如我们想知道一个填空里该填哪个词,那么我们需要知道他前面的单词和后面的单词来确定,BERT的动机就是更好的利用语言双向信息来进行建模。BERT采用的主要模型是双向Transformer的Encoder。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。作为一个Word2Vec的替代者,其在NLP领域的11个方向大幅刷新了精度,可以说是近年来最优突破性的技术之一了。

可能很多人认为ELMo也是一种双向模型啊,一个从左到右,另外一个从右到左。但两个方向的loss计算相互独立,所以并没有做到真正意义上的双向模型。BERT的作者指出这种两个方向相互独立或只有单层的双向编码可能没有发挥最好的效果,如果将使用多层双向LSTM,会引入一个问题,导致模型最终可以间接地“窥探”到需要预测的词。每个位置上的输出就已经带有了原本这个位置上的词的信息了。这样的“窥探”会导致模型预测词的任务变得失去意义,因为模型已经看到每个位置上是什么词了。
输入
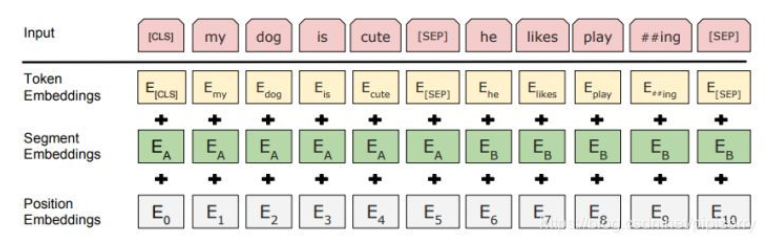
ERT的输入的编码向量是3个嵌入特征的单位和,这三个词嵌入特征是:WordPiece 嵌入、位置嵌入(Position Embedding)、分割嵌入(Segment Embedding)。其中添加的两个特殊符号[CLS]和[SEP],其中[CLS]表示该特征用于分类模型,对非分类模型,该符合可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。
预训练任务
Task 1: Masked Language Model/完形填空
所谓MLM是指在训练的时候随即从输入预料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。在BERT的实验中,15%的WordPiece Token会被随机Mask掉(而不是把像cbow一样把每个词都预测一遍),假如有 1 万篇文章,每篇文章平均有 100 个词汇,随机遮盖 15% 的词汇,模型的任务是正确地预测这 15 万个被遮盖的词汇。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,80%的时候会直接替换为[Mask],10%的时候将其替换为其它任意单词,10%的时候会保留原始Token。
MLM的一些直观小想法:
- 为什么没有被100%MASK—>这样的话在fine-tuning的时候模型就会有一些没有见过的单词。加入随机Token的原因是因为Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token,随机词替换会给模型增加一点点噪声,但是因为此时模型不知道哪个词是被随机换了。迫使模型更多地依赖于上下文信息去预测词汇,这样就赋予了模型一定的纠错能力
- 替换其它单词带来的负面影响—>至于单词带来的负面影响,因为一个单词被随机替换掉的概率只有15%*10% =1.5%,这个负面影响其实是可以忽略不计的。
- 为什么说BERT收敛得比left-to-right模型要慢—>15%的中间有5%被替换成了错误的词,给训练增加了难度;而且15%的词也是随机位置,比顺序的预测难度大。
Task2:Next Sentence Prediction
ext Sentence Prediction(NSP)的任务是判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。
对比:word2vec的一个精髓是引入了一个优雅的负采样任务来学习词向量(word-level representation),BERT使用句子级负采样任务学到句子表示。
Fine-Tune
在海量单预料上训练完BERT之后,便可以将其应用到NLP的各个任务中了,具体微调方式和GPT一样,对于句子关系类任务,很简单,和GPT类似,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出,把第一个起始符号对应的Transformer最后一层位置上面串接一个softmax分类层即可。对于分类问题,与GPT一样,只需要增加起始和终结符号,输出部分和句子关系判断任务类似改造等等。
思考
BERT严格意义上并不是一个语言模型,它的核心思想来自DAE(denoising autoencoder)。BERT的优点就是 用的是Transformer,也就是相对rnn更加高效、能捕捉更长距离的依赖。对比起之前的预训练模型,它捕捉到的是真正意义上的bidirectional context信息,这里不再赘述。
这里我们简单聊聊BERT的一些缺陷和限制。
- 在训练的时候加了个[MASK],而在测试的时候没有[MASK],也就是说[MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现。这样会导致训练和测试存在一个偏差(discrepancy)。
- BERT模型其实有一个预测token的独立假设。就是说一个句子中会有多个[MASK],这些不同的MASK之间也是有依赖关系的,但是预测MASK是独立的,这些MASK之间的依赖关系没有考虑进来。
这里我们简单说一说语言模型的两种方法:Autoregressive vs Autoencoding。
自回归模型类似(ELMo、GPT),自编码模型类似(BERT)。自回归模型的缺点很明显了,就是不能同时考虑上下文;自编码模型的缺点就是刚才说的那两条,例如我们无论是预测”New“还是预测”York“都是利用的”is a city“三个单词,这样没有考虑到”New“和”York“两个单词之间的依赖关系。

我们在简单总结一下:
Autoregressive
优点:比较适合做一个生成任务(本身训练就是类似语言模型的生成)
缺点:不能同时考虑上下文。
Autoencoding
优点:同时考虑了上下文
缺点:
- 不适合生成任务(生成任务都是单向生成的,考虑上下文做生成是不合常理的)
- token的独立假设,这些MASK之间的依赖关系没有考虑进来。
- 训练和测试存在一个偏差(discrepancy)。

