
- 120.自然语言处理(NLP)面试必备:pointwise 、 pairwise 、listwise_pointwise nlp
- 2【ChatGLM3】(6):使用1个2080Ti-11G版本,运行ChatGLM3-Int8模型,可以正常运行,速度6 words/s,不支持vllm启动,2张卡速度24 words/s_chatglm3-6b多大
- 3git 怎么将分支合并到master分支上_git 分支合并到master
- 4Android Studio 问题记(一)
- 5如何安装Ubuntu20.04(详细图文教程_ubuntu20.04安装教程
- 6月薪过万的测试员,是一种什么样的生活状态?你愿意再战一次吗..._游戏测试1w月薪是什么水平的
- 7python的开发工具软件有哪些,python开发工具包_动态库编程开发工具有哪些
- 8软件系统质量属性_2.面向架构评估的质量属性
- 9计算机毕业设计选题之基于SSM的旅游管理系统【源码+PPT+文档+包运行成功+部署讲解】
- 10数据结构线性表——栈
【腾讯云 TDSQL-C Serverless 产品体验】TDSQL-C MySQL Serverless云数据库化繁为简_td 数据库兼容mysql 吗
赞
踩
一、前言:
随着互联网的发展,企业的规模也在不断的发展,企业内部的在线业务量也随之骤增,海量的数据访问和存储压力已经日益不满足公司业务的需求了,而且搭建传统集中式数据库也增加运维工作量和公司软硬件成本,对于突发的业务,无法满足更快更稳定的业务性能。
企业级数据库在业务使用层面存在的痛点:
- 软硬件成本开销大,比如需要搭建自己的主从MySQL,需要够买云服务器、需要运维人力大量的工作支持
- 改造难度系数高,比如,我们公司用的MySQL,但是想使用PostgreSQL来改造,可以发现有些语法兼容性不足,导致需要对原有业务系统进行大量改造。
- 扩容难:为满足业务的快速增长带来的业务的计算能力与存储能力的需求,用户搭建一主多从、多主多从来进行扩容,而且作业时,需要中断业务数据才能进行完成扩容操作,还需要重启才能生效。
- 迁移困难:比如说我们公司早期有一些人写存储过程,但是在迁移时,非常不方便,进一步增加企业的数据迁移改造成本。
基于这些痛点,我们迫切的想要一款易用的数据库来解决实际的问题。
二、腾讯云联合CSDN进行TDSQL-C产品评测活动:

腾讯云联合CSDN进行TDSQL-C产品评测活动,同时,也让我了解了腾讯云国产数据库有很多特点。
1. 实践与成就:
首先TDSQL-C MySQL 版(TDSQL-C for MySQL)是腾讯云自研的新一代云原生关系型数据库,是自研的数据库,网上查询了一下,拿过很多奖项,而且在不少公司有大数据量的应用场景,可以看到最高的成就就是《第七次全国人口普查》项目的支持。
《第七次全国人口普查》
本次全国人口普查项目,腾讯云数据库提供了“OLTP+OLAP”双引擎融合的企业级分布式数据库管理系统TDSQL,支持了十亿级用户数据、七百万个终端和百万级峰值TPS(每秒事务处理量),平稳、高效支撑第七次全国人口普查工作完成。

2. 三高特性:
TDSQL-C MySQL 版融合了传统数据库、云计算与新硬件技术的优势,100%兼容 MySQL,为用户提供极致弹性、高性能、高可用、高可靠、安全的数据库服务。
3. 超高的性能:
实现超百万 QPS 的高吞吐、PB 级海量分布式智能存储、Serverless 秒级伸缩,助力企业加速完成数字化转型。
三、TDSQL-C MySQL Serverless说明:
云原生数据库Serverless化已经成为当前云数据库的重要演进方向。在云计算时代,不同业务形态对高弹性、高可用性、可扩展性的需求越来越强,按需使用成为企业的刚需要求。在此背景下,采用Serverless架构,能在云数据库高性能之上提供降低成本的更优的方案。
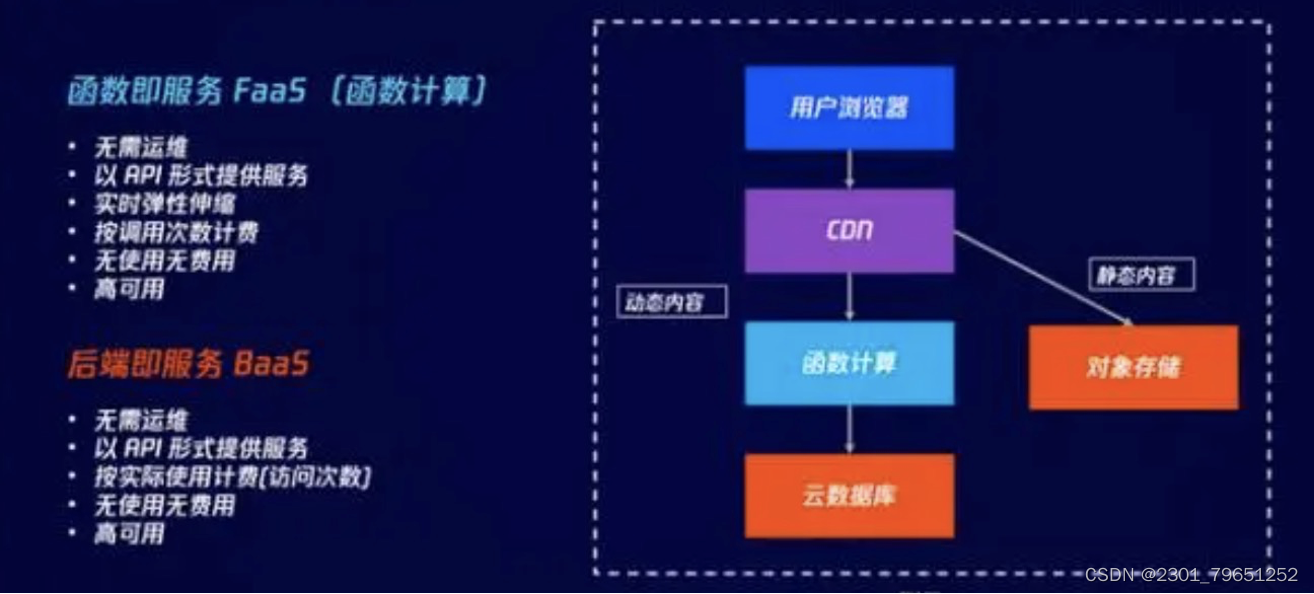
1. 什么是Serverless架构?
狭义的Serverless分为FaaS和BaaS,基本特点就是无需运维、以API方式提供服务、按实际使用计费、无使用无费用等。
举个例子,用户浏览网页,可能涉及CDN资源。如果是静态内容,从对象存储下载照片、视频;如果是动态内容,则触发一个函数计算,云函数将从云数据库获取相应的资源,生成用户所需的动态内容。其中,云函数为FaaS,对象存储和云数据库则为BaaS。
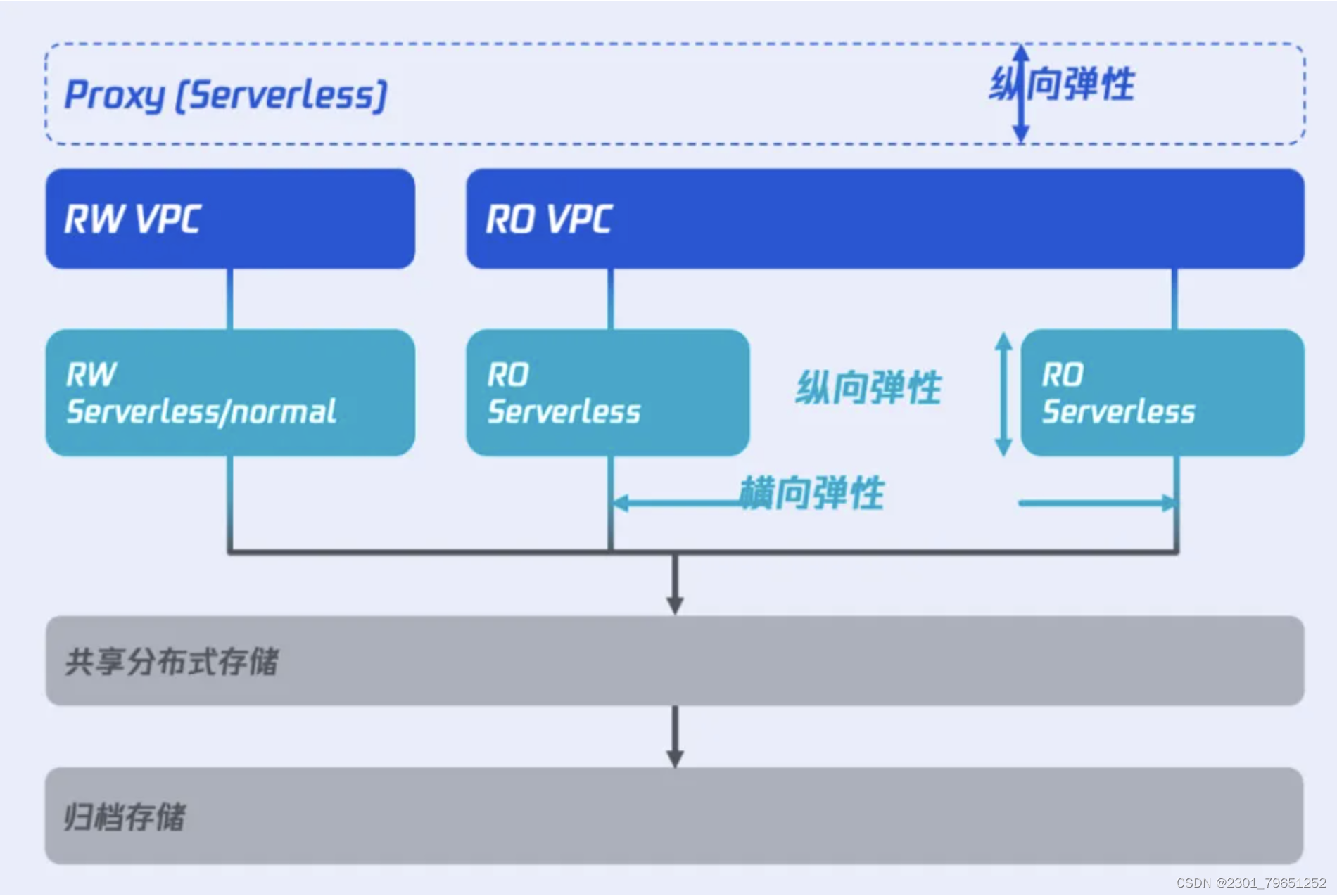
2. TDSQL-C MySQL Serverless的特性:
传统云数据库的容器架构与Serverless架构结合,将使云原生数据库在弹性伸缩、自动扩缩容等性能上带来新的价值。
Serverless架构的好处是当实例暂停后,数据会进行归档存储,用户无需再为高额的分布式存储进行付费,可在原实例暂停后的存储费用上降低成本80%,启动时可瞬时恢复服务,无需等待数据全量恢复。
TDSQL-C Serverless可全面承载核心业务场景,将Serverless技术覆盖到全部数据库应用场景。TDSQL-C已助力好未来、富途、虎扑等企业降低使用成本。好未来公司内部业务已稳定运行在新升级的TDSQL-C Serverless架构上,节省成本在50%以上。
从官方的介绍来看,TDSQL-C Serverless具有以下的特性,来给公司的业务进行降低使用成本,帮助客户提升效率、优化成本。
(1). 资源扩缩范围(CCU)
可调整 CCU 弹性扩缩容的范围,Serverless 集群会在该范围内根据实际业务压力自动增加或减少 CCU。
CCU(TDSQL-C Compute Unit)为 Serverless 的计算计费单位:
- 一个 CCU 近似等于1个 CPU 和 2GB 内存的计算资源
- 每个计费周期的 CCU 使用数量为:数据库所使用的 CPU 核数 与 内存大小的1/2 二者中取最大值
在成本上,超级节点实现了全新的单节点混合计费,既支持打包预付费,也支持对超出限额的容器进行精确的按量计费和配额控制,让资源管理灵活可控的同时又有最优成本;在弹性上,超级节点集成国内首个FinOps领域开源项目Crane的能力,可以智能预测客户弹性比例,并在高峰来前提前应对,保障客户业务扩展期的使用稳定性。
(2). 弹性策略
Serverless 集群会持续监控用户的 CPU、内存等 workload 负载情况,根据一定的规则触发自动扩缩容策略。
- Serverless 服务的弹性策略是利用监控计算层实现的。通过监控业务负载情况,系统对计算资源进行自动扩缩容,并对该时刻所消耗的资源进行计费。
- 当没有数据库请求时,监控服务会触发计算资源的回收,并通知接入层。当用户再次访问时,接入层则会唤醒集群,再次提供访问。
- Serverless 服务的弹性策略一开始会根据用户购买时选择的容量范围,将 CPU、内存资源限制到最大规格,极大程度降低因 CPU 和内存扩容带来的时间影响和使用限制。
- 当集群触发到自动弹性的负载阈值后,Buffer pool 会根据监控提前进行分钟级调整。在这个方案下用户使用数据库可以无感知进行 CPU 扩容,并且不会因为连接突增导致实例 OOM。

通过上面可以看出,由于CCU和存储都是弹性的,所以费用也是弹性的。
(3). 自动启停
Serverless 服务支持自定义实例自动暂停时间,无连接时实例会自动暂停。当有任务连接接入时,实例会秒级无间断自动唤醒。
四、实战手册:
本次我们使用python 语言 进行TDSQL Serverless MySQL 进行体验, 实现思路如下:
- 读取多个本地的 excel 文件 ,并将读取的数据存储到TDSQL 中
- 从TDSQL 读取存储的数据
- 将读取的数据生成词云图,并展示
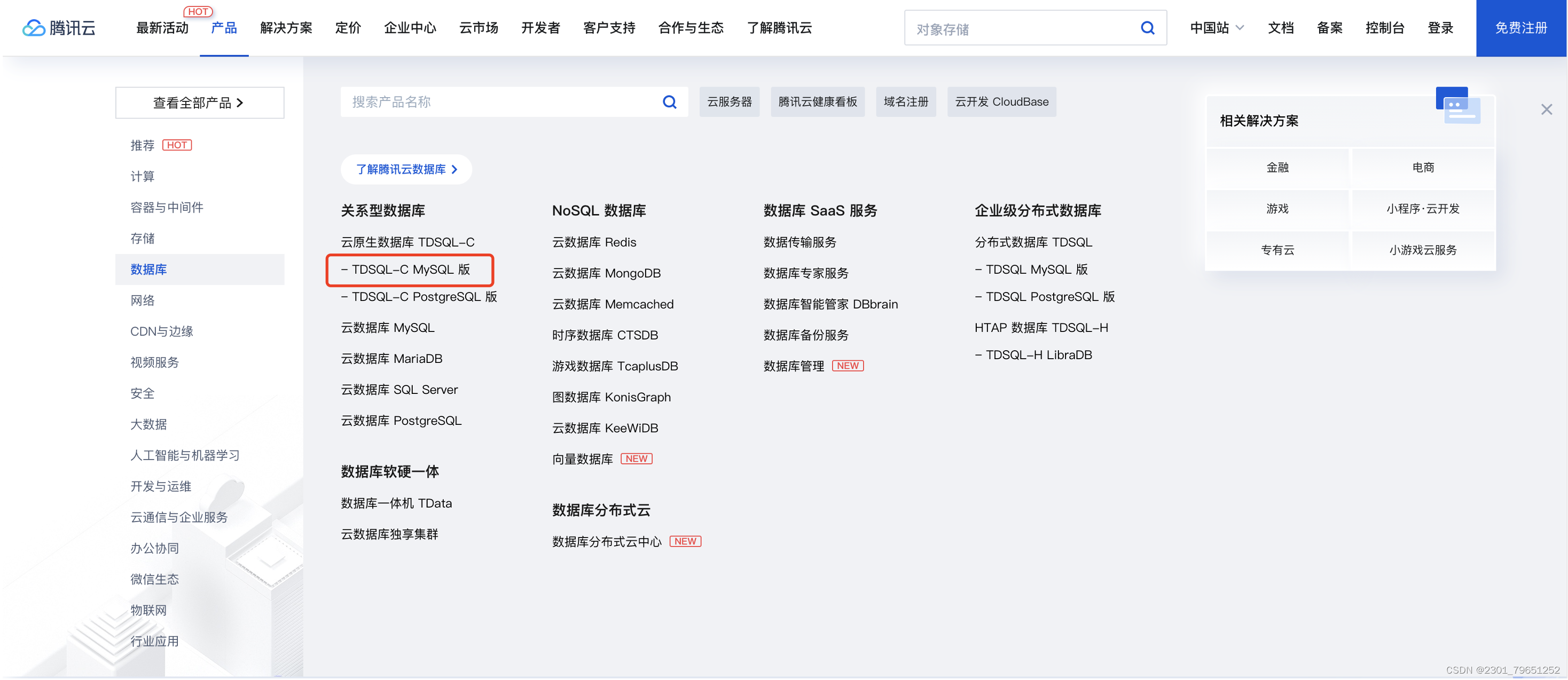
注意选择Serverless 的实例形态,数据库引擎为MySQL的。
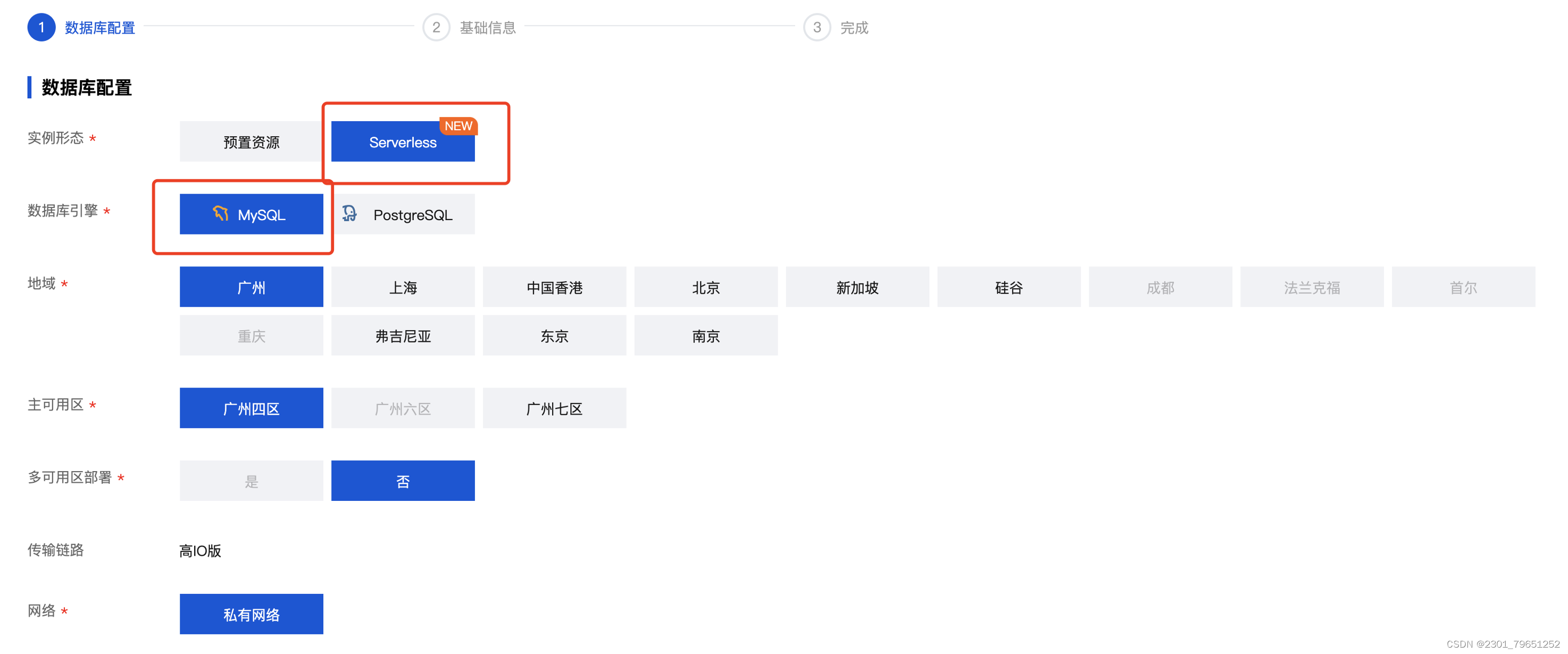
数据库版本可以选择5.7和8.02个版本,算力配置的话,上面有提到CCU(TDSQL-C Compute Unit)为 Serverless 的计算计费单位,一个 CCU 近似等于1个 CPU 和 2GB 内存的计算资源,每个计费周期的 CCU 使用数量为:数据库所使用的 CPU 核数 与 内存大小的1/2 二者中取最大值。
自动暂停的时间为数据库在设定的时间内未使用将会自动进入暂停状态,暂停后计算将不再计费。
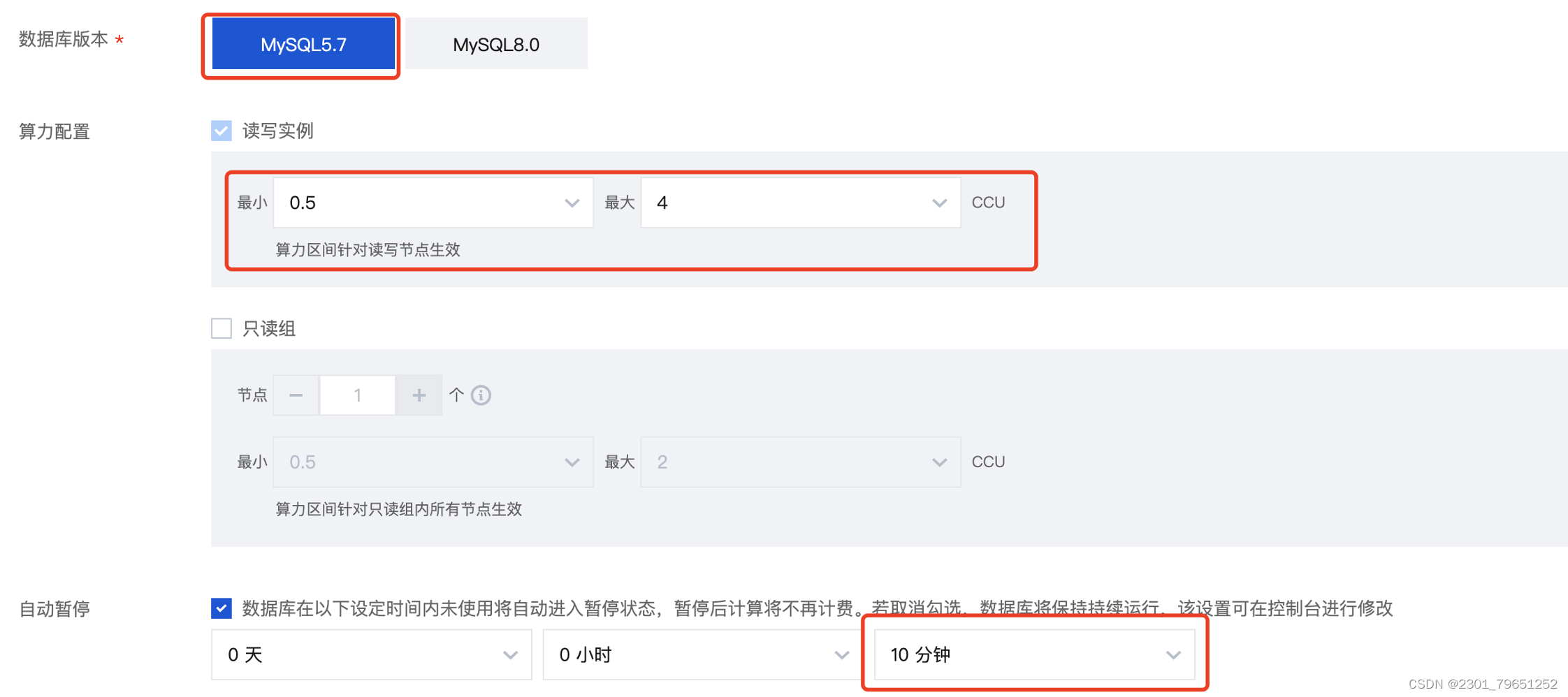
开启存储资源包,存储资源固定额度的包,用来优先抵扣按量付费产品中实际产生的用量,资源包额度消耗完毕后会继续按照按量付费模式计费。存储资源包会按照每小时实际使用的存储量进行抵扣,相比于按量付费模式更为划算,使用更为灵活。
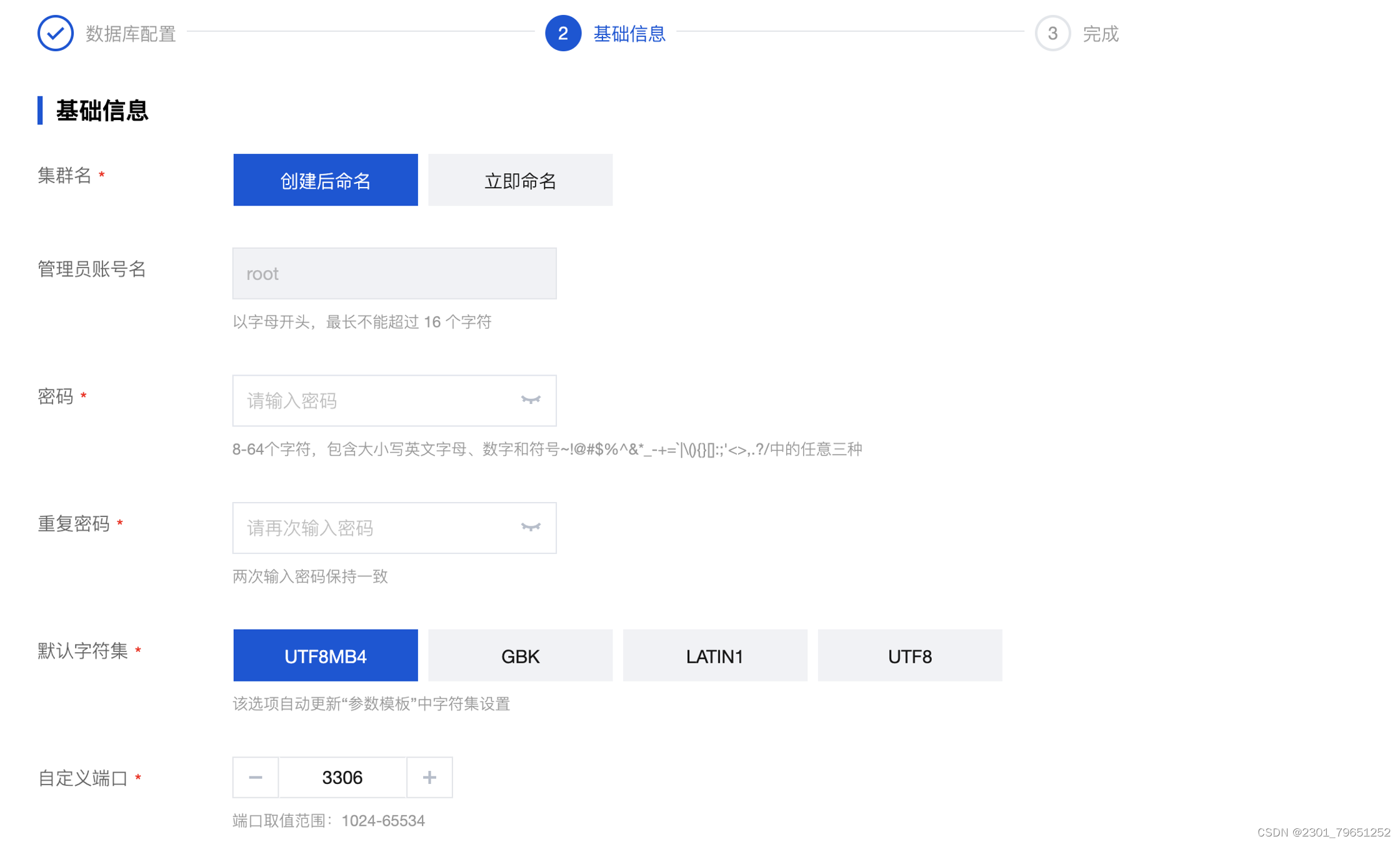
设置密码,一般选择UTF8MB4字符集,可以自定义端口。
开通成功后在控制台显示:

开通外网地址,这样就可以远程访问数据库了。


下载python相关依赖,在项目根目录,终端中运行:
pip install PyMySQL==1.1.0
pip install pandas==2.0.1
pip install wordcloud==1.9.1.1
pip install numpy==1.23.5
pip install matplotlib==3.7.2
pip install Pillow==9.5.0
- 1
- 2
- 3
- 4
- 5
- 6
创建读取excel文件的函数,在 server.py 中编写代码:
def excelTomysql():
path = '词频' # 文件所在文件夹
files = [path + "/" + i for i in os.listdir(path)] # 获取文件夹下的文件名,并拼接完整路径
for file_path in files:
print(file_path)
filename = os.path.basename(file_path)
table_name = os.path.splitext(filename)[0] # 使用文件名作为表名,去除文件扩展名
# 使用pandas库读取Excel文件
data = pd.read_excel(file_path, engine="openpyxl", header=0) # 假设第一行是列名
columns = {col: "VARCHAR(255)" for col in data.columns} # 动态生成列名和数据类型
create_table(table_name, columns) # 创建表
save_to_mysql(data, table_name) # 将数据保存到MySQL数据库中,并使用文件名作为表名
print(filename + ' uploaded and saved to MySQL successfully')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
根据excel文件名创建数据库表名:
def create_table(table_name, columns): # 建立MySQL数据库连接 conn = pymysql.connect(**db_config) cursor = conn.cursor() # 组装创建表的 SQL 查询语句 query = f"CREATE TABLE IF NOT EXISTS {table_name} (" for col_name, col_type in columns.items(): query += f"{col_name} {col_type}, " query = query.rstrip(", ") # 去除最后一个逗号和空格 query += ")" # 执行创建表的操作 cursor.execute(query) # 提交事务并关闭连接 conn.commit() cursor.close() conn.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
将读取的excel 数据保存到数据库对应的表中:
def save_to_mysql(data, table_name): # 建立MySQL数据库连接 conn = pymysql.connect(**db_config) cursor = conn.cursor() # 将数据写入MySQL表中(假设数据只有一个Sheet) for index, row in data.iterrows(): query = f"INSERT INTO {table_name} (" for col_name in data.columns: query += f"{col_name}, " query = query.rstrip(", ") # 去除最后一个逗号和空格 query += ") VALUES (" values = tuple(row) query += ("%s, " * len(values)).rstrip(", ") # 动态生成值的占位符 query += ")" cursor.execute(query, values) # 提交事务并关闭连接 conn.commit() cursor.close() conn.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
读取数据库中存入的数据:
def query_data(): # 建立MySQL数据库连接 conn = pymysql.connect(**db_config) cursor = conn.cursor() # 查询所有表名 cursor.execute("SHOW TABLES") tables = cursor.fetchall() data = [] dic_list = [] table_name_list = [] for table in tables: # for table in [tables[-1]]: table_name = table[0] table_name_list.append(table_name) query = f"SELECT * FROM {table_name}" # # 执行查询并获取结果 cursor.execute(query) result = cursor.fetchall() if len(result) > 0: columns = [desc[0] for desc in cursor.description] table_data = [{columns[i]: row[i] for i in range(len(columns))} for row in result] data.extend(table_data) dic = {} for i in data: dic[i['word']] = float(i['count']) dic_list.append(dic) conn.commit() cursor.close() conn.close() return dic_list, table_name_list
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
执行函数,并生成词云图:
if __name__ == '__main__': ##excelTomysql()方法将excel写入到mysql excelTomysql() print("excel写入到mysql成功!") # query_data()方法将mysql中的数据查询出来,每张表是一个dic,然后绘制词云 result_list, table_name_list = query_data() print("从mysql获取数据成功!") for i in range(len(result_list)): maskImage = np.array(Image.open('background.PNG')) # 定义词频背景图 # 定义词云样式 wc = wordcloud.WordCloud( font_path='PingFangBold.ttf', # 设置字体 mask=maskImage, # 设置背景图 max_words=500, # 最多显示词数 max_font_size=100) # 字号最大值 # 生成词云图 wc.generate_from_frequencies(result_list[i]) # 从字典生成词云 # 保存图片到指定文件夹 wc.to_file("词云图/{}.png".format(table_name_list[i])) print("生成的词云图【{}】已经保存成功!".format(table_name_list[i] + '.png')) # 在notebook中显示词云图 plt.imshow(wc) # 显示词云 plt.axis('off') # 关闭坐标轴 plt.show() # 显示图像
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
最终生成的效果:

五、压测:
1. 压测的定义:
压测就是基于一些工具模拟一个系统每秒发出一定数量的请求到数据库上去,观察它的CPU负载、磁盘IO负载、网络IO负载和内存负载等情况,测试出数据库在目前的机器配置下,大致的负载压力如何,性能表现如何,每秒最多可以处理多少请求。
2. 压测性能指标:
- QPS(Query Per Second):数据库每秒可以处理多少个SQL语句
- TPS(Transaction Per Second):数据库每秒可以处理多少事务量
- 吞吐量:机器的磁盘存储每秒可以读写多少字节的数据量
3. 接口压测,模拟流量跌宕。
压测脚本:
package main import ( "fmt" "gorm.io/driver/mysql" "gorm.io/gorm" // "gorm.io/gorm/logger" ) func main() { dns := fmt.Sprintf("%s:%s@tcp(%s)/%s?charset=%s&parseTime=True&loc=Local", "root", "密码", "主机名:端口号", "test_db", "utf8") db, _ := gorm.Open(mysql.Open(dns), &gorm.Config{ // Logger: logger.Default.LogMode(logger.Silent), }) sqlDB, _ := db.DB() // SetMaxIdleConns sets the maximum number of connections in the idle connection pool. sqlDB.SetMaxIdleConns(10) // SetMaxOpenConns sets the maximum number of open connections to the database. sqlDB.SetMaxOpenConns(100) for { result := db.Exec("select * from tests as a, tests as b, users as c, tests as d, tests as e where a.name1 = e.name1 and a.name1 = d.name1 and a.name1 = b.name1 and a.id = c.id and a.name1 like '%44444%' limit 1") fmt.Println("查询成功", result.RowsAffected) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
为了演示效果,开通了3台服务器,从1核到4核,逐渐压力递增上去。
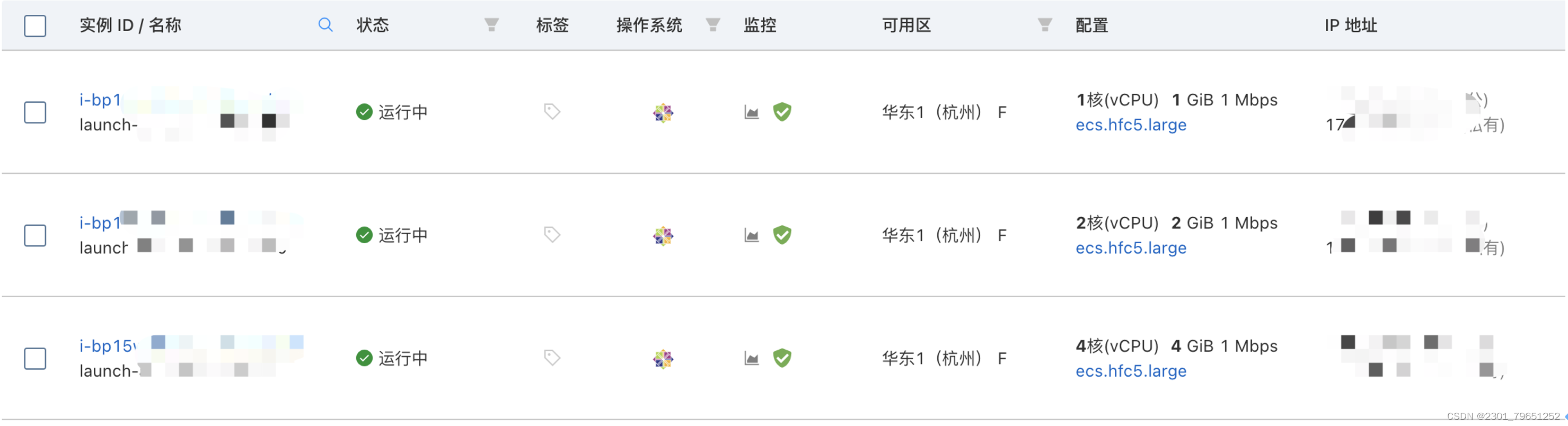
以下依次为1核G、2核2G、4核4G的服务器,可以看出接口的消耗时间,依次减少。
可以看到CPU的值也是从0到3.5%,再到93%,压测往上涨。

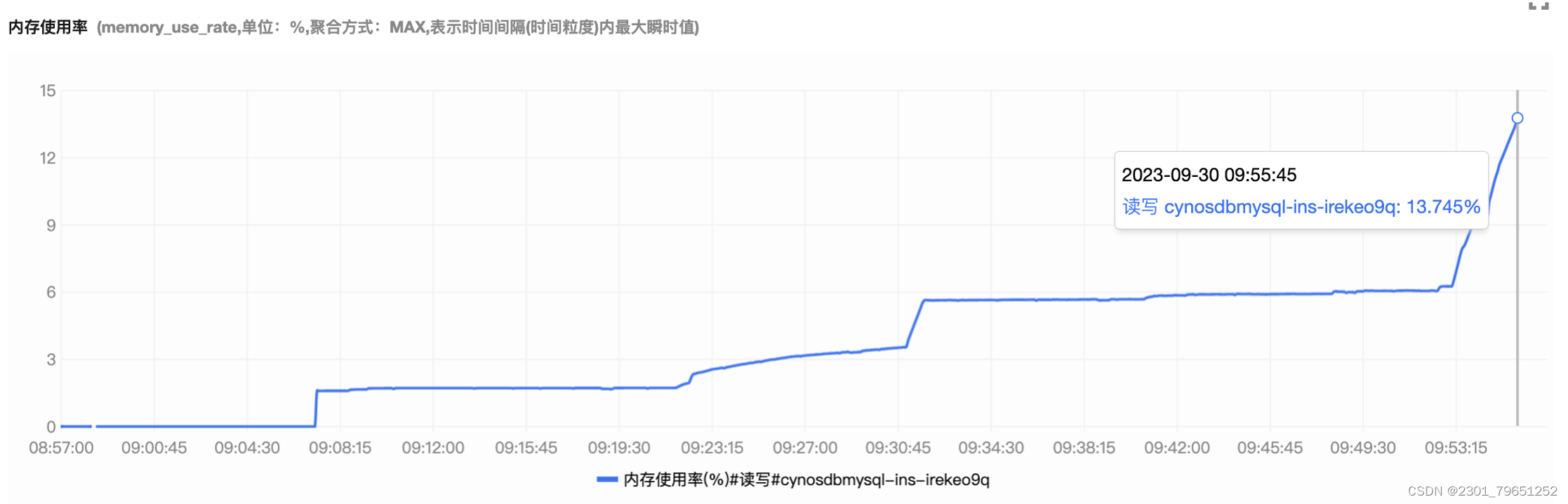
可以看到内存使用率的值也是从0到1.7%,再到13.7%,压测往上涨。
可以看到CCU的值也是从0到0.2,再到3.75,压测往上涨。
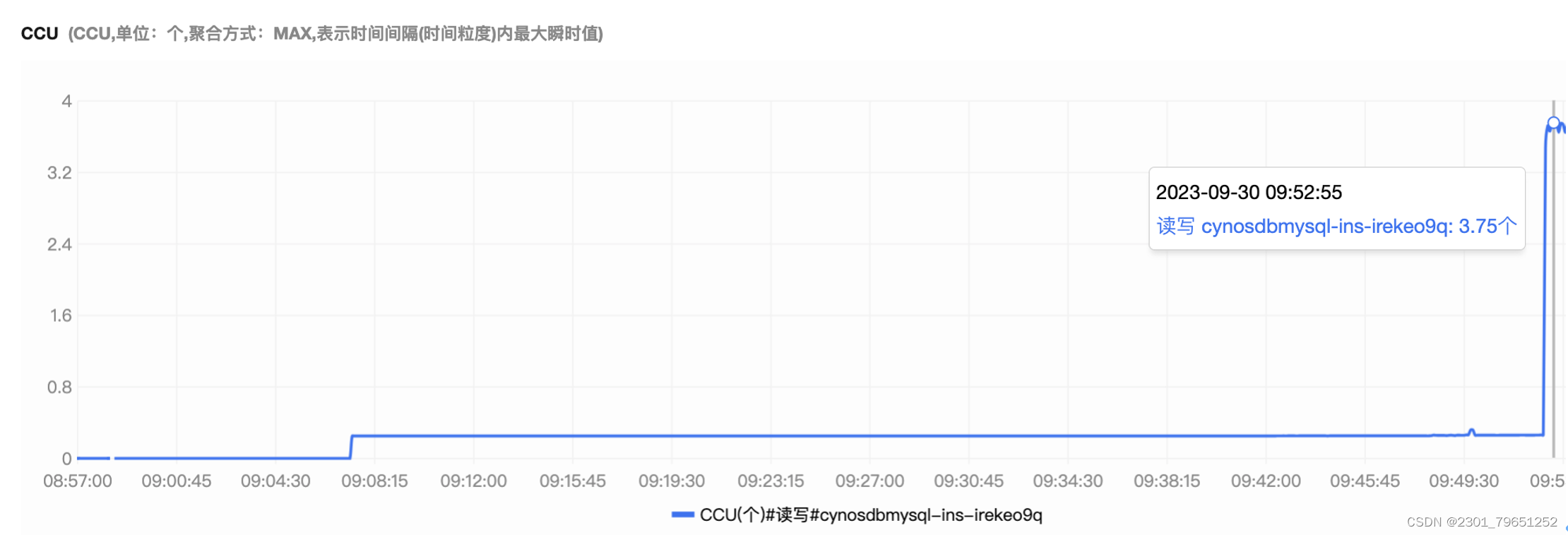
上面也有提到,CCU(TDSQL-C Compute Unit)为 Serverless 的计算计费单位,一个 CCU 近似等于1个 CPU 和 2GB 内存的计算资源。这样来看的话,我们用多少就收多少钱。
六、sysbench测试:
sysbench 是一个开源的、模块化的、跨平台的多线程性能测试工具,可以用来进行CPU、内存、磁盘I/O、线程、数据库的性能测试,目前支持的数据库有MySQL、Oracle和PostgreSQL。以下操作都将以支持MySQL数据库为例进行。
# 设置 yum repo 仓库
curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bash
# 安装
sudo yum -y install sysbench
# 安装完检查是否成功
sysbench --version
- 1
- 2
- 3
- 4
- 5
- 6
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=主机地址 --mysql-port=端口 --mysql-user=root --mysql-password=root --mysql-db=test_db --tables=20 --table_size=2500000 oltp_read_write --db-ps-mode=disable prepare
- 1
- –db-driver=mysql : 表示数据库的驱动类型
- –time=300 : 这个参数表示持续访问的时间 300秒
- –threads=10 : 表示使用10个线程模拟并发访问
- –report-interval=1 : 表示每隔一秒输出以此压测情况
- –tables=20 --table_size=1000000 : 表示构建20个表,并且每个表中构建出 250万条测试数据
- oltp_read_write : 表示执行oltp 数据库的读写测试
- –db-ps-mode=disable : 禁止 ps 模式
- prepare : 表示按照命令设置去构建出我们的数据,也就是对前面所有命令的执行方案
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=主机地址 --mysql-port=端口 --mysql-user=root --mysql-password=root --mysql-db=test_db --tables=20 --table_size=2500000 oltp_read_write --db-ps-mode=disable run
- 1
可以看到以下CCU的效率马上就充上来了,按35的算力来计算费用。
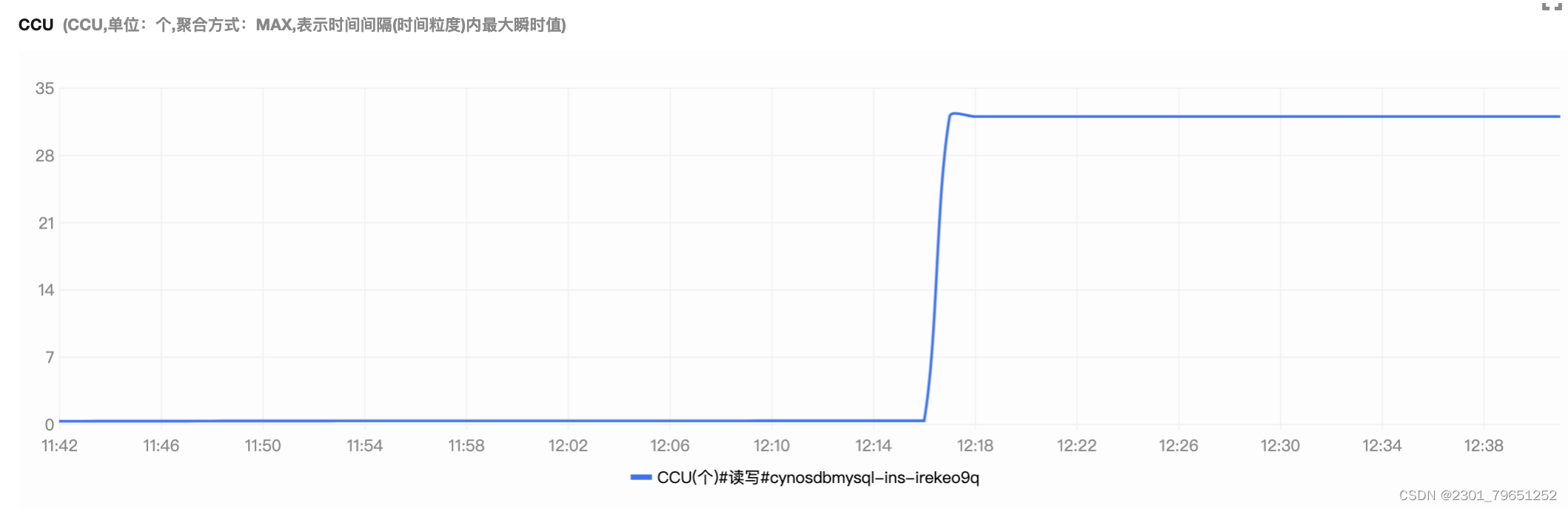

对于企业在成本不可控,浪费资源,可以使用云原生数据库 TDSQL-C MySQL Serverless使用计算存储分离的架构,计算资源和存储资源解耦,可以提供PB级的存储容量供用户按需使用。而 Serverless 架构是将计算资源做到极致弹性,和购买的实例规格解耦,根据用户数据库实际的负载,自动启停和自动扩缩容,按使用计费。其中计算资源主要是 CCU(CPU+内存),CPU 可以由 cgroup 或者 docker 等技术限制,内存分配给数据库进程,大部分由 Buffer Pool 模块使用,目的是缓存用户数据,Buffer Pool 内存的分配与释放过程涉及用户数据的分布,搬迁,还有内核中全局资源的互斥等。
- 不允许mysql ...
赞
踩



