
- 1异地两台电脑如何共享文件?
- 2第九节HarmonyOS 常用基础组件17-ScrollBar
- 33年外包测试走进字节,真的泪目了....._字节测试主要靠外包吗
- 4Android SDK下载安装及配置教程_andorid sdk
- 5华为mate20怎样升级鸿蒙系统,华为Mate20怎么升级鸿蒙系统 Mate20升级鸿蒙系统步骤教程...
- 6通过Cursor 工具使用GPT-4的方法_cursor gpt
- 7鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之XComponent组件_harmonyos xcomponent
- 8离群点检测算法python代码
- 9Vue2/Vue3的区别及使用差异_vue2和3
- 10数据结构进阶篇 之 【栈和队列】的实现讲解(附完整实现代码)
利用Transformer实现机器翻译(法语-英语)的代码实现_transformer实现机器翻译代码
赞
踩
本文代码所需要的库主要为:pytorch(2.0.0),nltk,tqdm。
这篇文章的内容主要是对上一篇Transformer以及self-attention的一些理解文章所提到的内容进行代码实现和解释。
数据预处理
数据预处理部分参考了大佬 苏同学的方法~
一开始的数据预处理其实是采用torchtext中自带的Multi30k数据集。但是这就出现了很多的问题。
首先是torchtext的版本,torch2.0.0对应的版本是0.15.0,而torchtext在0.8和0.14经历了两个API的大变动,torch中的迭代器模块功能也是随着版本有了变化,比如去掉了Field…
这样下来,一开始代码运行下来报了很多错。查了很多资料之后,对代码进行修改之后,结果又报了爬虫错误。索性放弃了。
个人认为,如果要开始理解代码是如何运作的,那么数据的说明就必不可少。毕竟有些时候看着包里的函数和类实在是有些抽象,不知道到底是什么东西。这个时候就需要输出一些中间变量看一看,自己到底是在干什么。如果对一开始的数据不了解不清楚的话,想输出的时候大概率也是会报错的吧…
这里我们主要需要创建的数据有:
- eng_dict、fra_dict(英语、法语对应的词典)
- word2idx(以单词为键,序列为值的索引字典)
- idx2word(以序列为键,单词为值的索引字典)
- train_dataset、test_dataset(训练集、测试集)
- source(原语言单词按对应序列组成的列表)
- target(翻译语言单词按对应序列组成的列表)
- train_loader、test_loader(按训练集和测试集构成的迭代器)
采用的数据集从可以从这里下载。
总体代码概览
import re import unicodedata from io import open import nltk from tqdm import tqdm import torch from torch.utils.data import Dataset,random_split,DataLoader #1-- def unicodeToAscii(s): return ''.join(c for c in unicodedata.normalize('NFD',s) if unicodedata.category(c)!='Mn')#这里为什么是'Mn'呢? def normalization(s): s=unicodeToAscii(s.lower().strip()) s=re.sub(r'[^a-zA-z0-9\s]','',s) return s.strip() #--1 #2-- def tokenization(s): tokens=nltk.word_tokenize(s)#将字符串进行分词,返回一个列表 #如"This is a sentence." -> ['This', 'is', 'a', 'sentence', '.'] return tokens class Dictionary: def __init__(self,name): self.name=name self.word2idx={} self.idx2word={} self.idx=0 self.add_word("<pad>") self.add_word("<sos>") self.add_word("<eos>") def __len__(self): return len(self.word2idx) def add_word(self,word): if not word in self.word2idx: self.word2idx[word]=self.idx self.idx2word[self.idx]=word self.idx+=1 #--2 #3-- def padding(t,maxlen):#按最长数据进行补全数据,补的数据不参与训练。 while len(t)<maxlen: t.append(eng_dict.word2idx["<pad>"]) return t def collate_fn_padding(batch): src=[] trg=[] maxlen=0 for i in batch: print(i) maxlen=max(len(i[0]),len(i[1]),maxlen) for i in range(0,len(batch)): src.append(padding(batch[i][0],maxlen)) trg.append(padding(batch[i][1],maxlen)) return torch.LongTensor(src),torch.LongTensor(trg) class TranslateDatasets(Dataset): def __init__(self,x,y): super(TranslateDatasets,self).__init__() self.inputs=x#source self.targets=y#targets def __getitem__(self,idx): return self.inputs[idx],self.targets[idx] def __len__(self): return len(self.inputs) #--3 #1-- lines = open('fra2.txt', encoding='utf-8').read().strip().split('\n') #读入数据,按换行进行分类 pairs=[[normalization(s) for s in l.split('\t')] for l in lines] #--1 #2-- eng_dict=Dictionary("eng") fra_dict=Dictionary("fra") sentences_eng=[] sentences_fra=[] for piece in tqdm(pairs):#tqdm是对循环进行可视化 sentence_eng=[] sentence_fra=[] sentence_eng.append(eng_dict.word2idx["<sos>"]) sentence_fra.append(eng_dict.word2idx["<sos>"]) token_eng=tokenization(piece[0])#piece[0]中是英语 token_fra=tokenization(piece[1])#piece[1]中是法语 for token in token_eng: eng_dict.add_word(token) sentence_eng.append(eng_dict.word2idx[token]) for token in token_fra: fra_dict.add_word(token) sentence_fra.append(fra_dict.word2idx[token]) sentence_eng.append(eng_dict.word2idx["<eos>"]) sentence_fra.append(eng_dict.word2idx["<eos>"]) sentences_eng.append(sentence_eng) sentences_fra.append(sentence_fra) #--2 #3-- full_dataset=TranslateDatasets(sentences_eng,sentences_fra) train_size=int(0.8*len(full_dataset)) test_size=len(full_dataset)-train_size train_dataset,test_dataset=random_split(full_dataset,[train_size,test_size]) train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True, collate_fn=collate_fn_padding) test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False, collate_fn=collate_fn_padding) #--3 src_pad_idx=eng_dict.word2idx["<pad>"] trg_pad_idx=fra_dict.word2idx["<pad>"] trg_sos_idx=fra_dict.word2idx["<sos>"] enc_voc_size=len(eng_dict) dec_voc_size=len(fra_dict)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
数据集格式以及其读入
这里的数据集,我为了能够打印数据方便理解,对下载来的数据集进行了一定阉割(其实就是删除了大部分)。大致的数据集长这样:

可以看到数据非常清晰明了:英语+Tab+法语,后面的就是数据来源了,与我们的训练无关。
这样一来Normalization的方向也变的十分清晰,先把数据中的unicode转化为ASCII码,之后用re模块对数据进行处理。
具体解释和方法可见代码中的1- -1部分。
构建词典
这部分的实现在代码中的2- -2部分。
稍微解释一下NLP中一些标识符的含义:
- <sos>、 <bos> 表示一句话的开始
- <eos> 表示一句话的结束
- <unk> 未知字符,代表词典中没有的词
- <pad> 补全字符,用于将句子处理为特定的长度
这里定义了一个Dictionary类,类里有word2idx和idx2word的字典成员变量。定义了add_word方法:如果一个单词在词典中出现过则什么都不做,如果没出现过则按出现顺序编号。这里 <sos>、<eos>、<pad>的序列号分别为1、2、0。
这里的定义还是十分好理解的!
下一个循环实现的功能是:
1.把按行分割的句子加上标识符封装为一个列表,再把每个句子加入到总的句子列表中。
2.将每个词加入英语和法语词典中。
输出一下变量,方便理解。

以英文字典和英文句子为例,eng_dict.word2idx记录了每个单词和序列的键值对,而sentences_eng则是所有句子中单词序列号的索引,如数据集中的第一条“GO!”,在sentences_eng中表示为[1,3,2],其中1为<sos>表示句子的开始,2为<eos>表示句子的结束。
构建迭代器
这部分的实现在代码中的3- -3部分。
构建训练集和测试集直接重新定义了一个继承于torch Dataset的类,类中包含inputs和targets的列表成员变量。并且重写了len和索引数据的方法。
训练集和测试集是从整个测试集中分出的,代码中写train_sizeh和test_size实际是规定了训练集和测试集数据的比例,依据这个比例用torch中的random_split函数进行数据的随机分类。
接下来就是构造迭代器了,torch中可以直接用DataLoader类来定义迭代器。collate_fn的参数是一个函数,这个函数可以自定义。如果该参数写上,那么返回的值实际就是自定义函数的返回值。
在此之后定义的变量则是在train模块中所要用到的常量。
这里引用一下大佬博客中的原话:
这里不必将所有的句子都填充到相同长度,训练时只需要保证每个batch中的所有句子长度相等就可以了。所以我这里使用了dataloder的collate_fn参数,在读取每个batch时将句子进行padding,并将其转化为tensor。
同样,输出一下迭代器的内容。
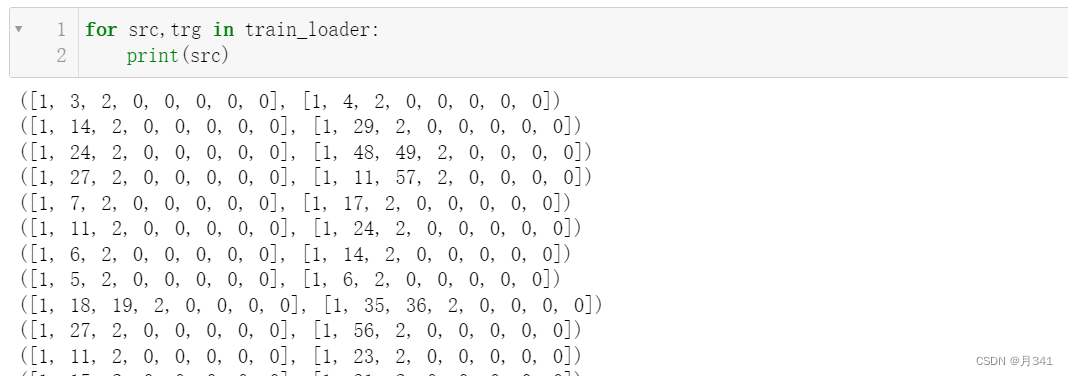
篇幅所限,就截那么多。实则也就是总句子列表中的内容,只不过对句子进行了补齐,并且由于用了random_split的关系,进行了一定的截取,而且每次运行出来的结果是不一样的。
Models
Embedding
Token Embedding
import torch
from torch import nn
class TokenEmbedding(nn.Embedding):
def __init__(self,vocab_size,d_model):
"""
class for token embedding that included positional information
:param vocab_size: size of vocabulary
:param d_model: dimensions of model
"""
super(TokenEmbedding,self).__init__(vocab_size,d_model)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这个embedding层包含了原始数据的位置信息。
vocab_size:词典中包含数据的数量。
d_model:模型的尺度。
表示词嵌入模型,输入单词数为vocab_size,每个单词用d_model个向量表示。
Positional Encoding
class PositionalEncoding(nn.Module): def __init__(self,d_model,max_len,device): """ constructor of sin encoding class :param d_model: dimension of model :param max_len: max sequence length :param device: hardware device setting """ super(PositionalEncoding,self).__init__() #same size with input matrix(for adding with input matrix) self.encoding=torch.zeros(max_len,d_model,device=device) self.encoding.requires_gradu=False#这里不需要计算梯度 #1D=>2D unsqeeze to represnet word's position pos=torch.arange(0,max_len,device=device) pos=pos.float().unsqueeze(dim=1) _2i=torch.arange(0,d_model,step=2,device=device).float() #i means index of d_model(比如 embedding size=50,i=[0,50]) #step=2 means i mulitiplied with two(same with 2*i) #compute positional encoding to consider positional information of words self.encoding[:,0::2]=torch.sin(pos/(10000**(_2i/d_model))) self.encoding[:,1::2]=torch.sin(pos/(10000**(_2i/d_model))) def forward(self, x): # self.encoding # [max_len = 512, d_model = 512] batch_size, seq_len = x.size() # [batch_size = 128, seq_len = 30] return self.encoding[:seq_len, :] # [seq_len = 30, d_model = 512] # it will add with tok_emb : [128, 30, 512]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
这里则是Positional Encoding的实现,原理公式可以参照上一篇博客。
Transformer Embedding
class TransformerEmbedding(nn.Module): """ token embedding + positional encoding (sinusoid) positional encoding can give positional information to network """ def __init__(self,vocab_size,d_model,max_len,drop_prob,device): """ class for word embedding that included positional information :param vocab_size: size of vocabulary :param d_model: dimensions of model """ super(TransformerEmbedding,self).__init__() self.tok_emb=TokenEmbedding(vocab_size,d_model) self.pos_emb=PositionalEncoding(d_model,max_len,device) self.drop_out=nn.Dropout(p=drop_prob) def forward(self,x): tok_emb=self.tok_emb(x) pos_emb=self.pos_emb(x) return self.drop_out(tok_emb+pos_emb)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
其实这一个Embedding层就是上述两个层的相加,得到最后的词嵌入模型。
Layer
LayerNorm
import torch from torch import nn import math class LayerNorm(nn.Module): def __init__(self,d_model,eps=1e-12): super(LayerNorm,self).__init__() self.gamma=nn.Parameter(torch.ones(d_model)) self.beta=nn.Parameter(torch.zeros(d_model)) self.eps=eps def forward(self,x): mean=x.mean(-1,keepdim=True) var=x.var(-1,unbiased=False,keepdim=True) out=(x-mean)/torch.sqrt(var+self.eps) out=self.gamma*out+self.beta return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这部分是对编码器的每个子层进行残差连接和标准化。
这里放一张图,是代码原理的公式。
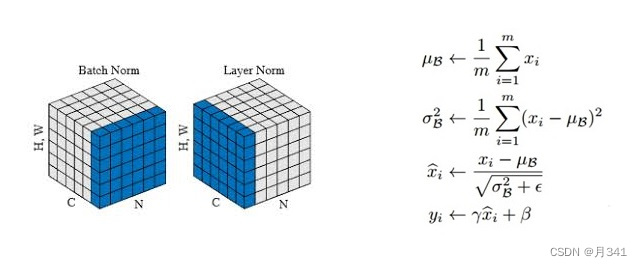
对图中的变量做出解释:
μ
\mu
μB:样本均值
σ
\sigma
σB2:样本方差(未修正)
代码中是用变量mean和var来表示的。
对照着公式,可以很清楚的看到代码的实现过程。
Position-Wise Feed-Forward
class PositionWiseFeedForward(nn.Module):
def __init__(self,d_model,hidden,drop_prob=0.1):
super(PositionWiseFeedForward,self).__init__()
self.linear1=nn.Linear(d_model,hidden)
self.linear2=nn.Linear(hidden,d_model)
self.relu=nn.ReLU()
self.dropout=nn.Dropout(p=drop_prob)
def forward(self,x):
x=self.linear1(x)
x=self.relu(x)
x=self.dropout(x)
x=self.linear2(x)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这是位置前馈网络所对应的公式:
F F N ( x ) = m a x ( 0 , x W FFN(x)=max(0,xW FFN(x)=max(0,xW 1 + b +b +b 1) W W W 2 + b +b +b 2
其实就是对输入进行两次线性变换。
代码中通过nn.Linear()进行线性变换;nn.ReLu()进行线性整流,保留非负部分。
也是比较清晰的。
Scale Dot-Product Attention
class ScaleDotProductAttention(nn.Module): """ compute scale dot product attention Query : given sentence that we focused on (decoder) Key : every sentence to check relationship with Qeury(encoder) Value : every sentence same with Key (encoder) """ def __init__(self): super(ScaleDotProductAttention,self).__init__() self.softmax=nn.Softmax(dim=-1) def forward(self,q,k,v,mask=None,e=1e-12): #输入是4个维度的tensor [batch_size,head,length,d_tensor] batch_size,head,length,d_tensor=k.size() #1. dot product Query with key^T to compute similarity k_t=k.transpose(2,3)#转置 score=(q@k_t)/math.sqrt(d_tensor)#@为矩阵乘法 #2. apply masking(可选) if mask is not None: score=score.masked_fill(mask==0,-10000) #3. pass them softmax to make [0,1] range score=self.softmax(score) #4. multiply with Value v=score @ v return v,score
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
Scale Dot-Product Attention所对应的公式:
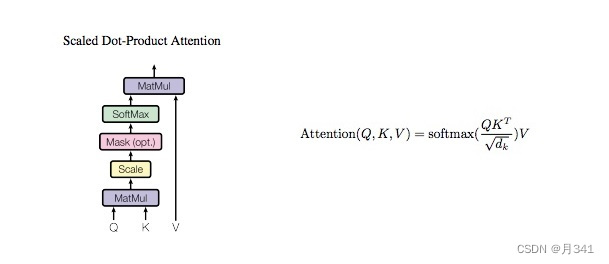
首先计算 Q 和 K 之间的点积,为了防止其结果过大,会除以 d k \sqrt{d_k} dk ,其中 d k d_k dk为K向量的维度。
然后利用 Softmax 操作将其结果归一化为概率分布,再乘以矩阵 V 就得到权重求和的表示。
代码中还提到了mask的操作,其实对结果的影响是不大的。
Multi-Head Attention
class MultiHeadAttention(nn.Module): def __init__(self,d_model,n_head): super(MultiHeadAttention,self).__init__() self.n_head=n_head self.attention=ScaleDotProductAttention() self.w_q=nn.Linear(d_model,d_model) self.w_k=nn.Linear(d_model,d_model) self.w_v=nn.Linear(d_model,d_model) self.w_concat=nn.Linear(d_model,d_model) def split(self,tensor): """ split tensor by number of head :param tensor: [batch_size, length, d_model] :return: [batch_size, head, length, d_tensor] """ batch_size,length,d_model=tensor.size() d_tensor=d_model//self.n_head#整除 tensor=tensor.view(batch_size,length,self.n_head,d_tensor).transpose(1,2) return tensor def concat(self,tensor): """ inverse function of self.split(tensor : torch.Tensor) :param tensor: [batch_size, head, length, d_tensor] :return: [batch_size, length, d_model] """ batch_size,head,length,d_tensor=tensor.size() d_model=head*d_tensor tensor=tensor.transpose(1,2).contiguous().view(batch_size,length,d_model) return tensor def forward(self,q,k,v,mask=None): #1. dot product with weight matrices q,k,v=self.w_q(q),self.w_k(k),self.w_v(v) #2. split tensor by number of heads q,k,v=self.split(q),self.split(k),self.split(v) #3. do scale dot product to cmpute similarity out,attention=self.attention(q,k,v,mask=mask) #4.concat and pass to linear layer out=self.concat(out) out=self.w_concat(out) #5.visualize attention map #暂不实现 return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
原理可见上一篇博客,这里给出代码实现的公式:
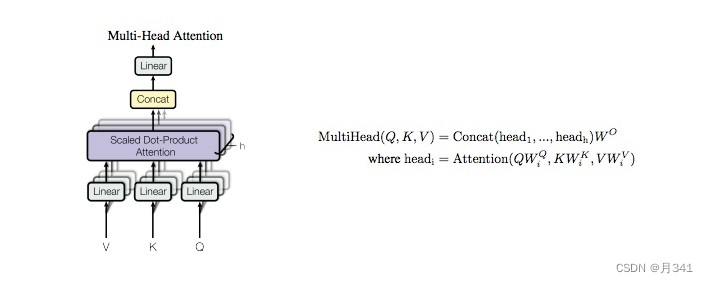
将QKV三个矩阵按head进行划分后,用上文定义的Scale Dot-Produc Attention计算self-Attention
Concat这里的意思是连接,因为计算Attention后还多了一个维度head,这里需要去掉维度head变回原来的数据维度。
最后再进行线性变换即可。
model
Encoder
import torch from torch import nn from layer import LayerNorm,MultiHeadAttention,PositionWiseFeedForward from embedding import TransformerEmbedding class EncoderLayer(nn.Module): def __init__(self,d_model,ffn_hidden,n_head,drop_prob): super(EncoderLayer,self).__init__() self.attention=MultiHeadAttention(d_model=d_model,n_head=n_head) self.norm1=LayerNorm(d_model=d_model) self.dropout1=nn.Dropout(p=drop_prob) self.ffn=PositionWiseFeedForward(d_model=d_model,hidden=ffn_hidden,drop_prob=drop_prob) self.norm2=LayerNorm(d_model=d_model) self.dropout2=nn.Dropout(p=drop_prob) def forward(self,x,src_mask): #1. compute self attention _x=x x=self.attention(q=x,k=x,v=x,mask=src_mask) #2. add and norm x=self.dropout1(x) x=self.norm1(x+_x) #3. positionwise feed forward network _x=x x=self.ffn(x) #4. add and norm x=self.dropout2(x) x=self.norm2(x+_x) return x class Encoder(nn.Module): def __init__(self,enc_voc_size,max_len,d_model,ffn_hidden,n_head,n_layers,drop_prob,device): super().__init__() self.emb=TransformerEmbedding(d_model=d_model,max_len=max_len,vocab_size=enc_voc_size,drop_prob=drop_prob,device=device) self.layers=nn.ModuleList([EncoderLayer(d_model=d_model,ffn_hidden=ffn_hidden,n_head=n_head,drop_prob=drop_prob) for _ in range(n_layers)]) def forward(self,x,src_mask): x=self.emb(x) for layer in self.layers: x=layer(x,src_mask) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
Decoder
class DecoderLayer(nn.Module): def __init__(self,d_model,ffn_hidden,n_head,drop_prob): super(DecoderLayer,self).__init__() self.self_attention=MultiHeadAttention(d_model=d_model,n_head=n_head) self.norm1=LayerNorm(d_model=d_model) self.dropout1=nn.Dropout(p=drop_prob) self.enc_dec_attention=MultiHeadAttention(d_model=d_model,n_head=n_head) self.norm2=LayerNorm(d_model=d_model) self.dropout2=nn.Dropout(p=drop_prob) self.ffn=PositionWiseFeedForward(d_model=d_model,hidden=ffn_hidden,drop_prob=drop_prob) self.norm3=LayerNorm(d_model=d_model) self.dropout3=nn.Dropout(p=drop_prob) def forward(self,dec,enc,trg_mask,src_mask): #1.compute self attention _x=dec x=self.self_attention(q=dec,k=dec,v=dec,mask=trg_mask) #2.add and norm x=self.dropout1(x) x=self.norm1(x+_x) if enc is not None: #3. compute encoder-decoder attention _x=x x=self.enc_dec_attention(q=x,k=enc,v=enc,mask=src_mask) #4. add and norm x=self.dropout2(x) x=self.norm2(x+_x) #5. positionwise feed forward network _x=x x=self.ffn(x) #6. add and norm x=self.dropout3(x) x=self.norm3(x+_x) return x class Decoder(nn.Module): def __init__(self,dec_voc_size,max_len,d_model,ffn_hidden,n_head,n_layers,drop_prob,device): super().__init__() self.emb=TransformerEmbedding(d_model=d_model,max_len=max_len,vocab_size=dec_voc_size,drop_prob=drop_prob,device=device) self.layers=nn.ModuleList([DecoderLayer(d_model=d_model,ffn_hidden=ffn_hidden,n_head=n_head,drop_prob=drop_prob) for _ in range(n_layers)]) self.linear=nn.Linear(d_model,dec_voc_size) def forward(self,trg,enc_src,trg_mask,src_mask): trg=self.emb(trg) for layer in self.layers: trg=layer(trg,enc_src,trg_mask,src_mask) #pass to LM head output=self.linear(trg) return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
EncoderLayer和DecoderLayer是每一个层中都要做的事,这里的实现只需要将上文中定义过的类和函数进行组合。
Encoder和Decoder类中是对每一个层进行整合连接。
具体组合方式和Transformer model的图差不多:
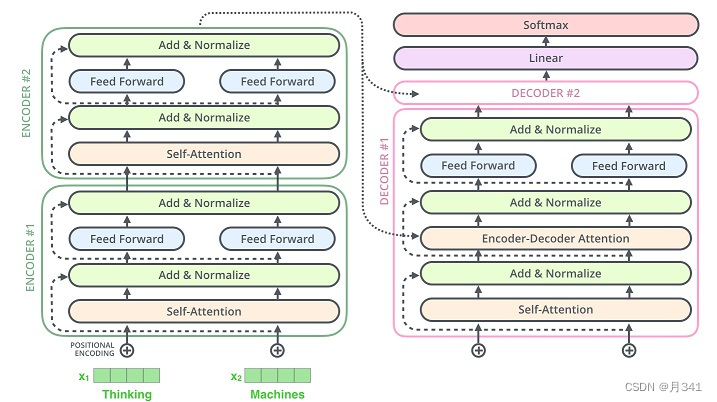
Transformer
class Transformer(nn.Module): def __init__(self,src_pad_idx,trg_pad_idx,trg_sos_idx,enc_voc_size,dec_voc_size,d_model,n_head,max_len,ffn_hidden,n_layers,drop_prob,device): super().__init__() self.src_pad_idx=src_pad_idx self.trg_pad_idx=trg_pad_idx self.trg_sos_idx=trg_sos_idx self.device=device self.encoder=Encoder(d_model=d_model,n_head=n_head,max_len=max_len,ffn_hidden=ffn_hidden, enc_voc_size=enc_voc_size,drop_prob=drop_prob,n_layers=n_layers,device=device) self.decoder=Decoder(d_model=d_model,n_head=n_head,max_len=max_len,ffn_hidden=ffn_hidden, dec_voc_size=dec_voc_size,drop_prob=drop_prob,n_layers=n_layers,device=device) def make_src_mask(self,src): src_mask=(src!=self.src_pad_idx).unsqueeze(1).unsqueeze(2) return src_mask def make_trg_mask(self,trg): trg_pad_mask=(trg!=self.trg_pad_idx).unsqueeze(1).unsqueeze(3).to(self.device) trg_len=trg.shape[1] trg_sub_mask=torch.tril(torch.ones(trg_len,trg_len)).type(torch.ByteTensor).to(self.device) trg_mask=trg_pad_mask & trg_sub_mask return trg_mask def forward(self,src,trg): src_mask=self.make_src_mask(src) trg_mask=self.make_trg_mask(trg) enc_src=self.encoder(src,src_mask) output=self.decoder(trg,enc_src,trg_mask,src_mask) return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
Transformer类中是将Encoder和Decoder整合在一起,其实还是有很多细节需要注意的。
Train and Test
Bleu
import math from collections import Counter import numpy as np def bleu_stats(hypothesis,reference): #Compute statistics for BLEU #BLEU:bilingual evaluation understudy,即:双语互译质量评估辅助工具(双语替换测评)。它是用来评估机器翻译质量的工具。 #BLEU的设计思想:机器翻译结果越接近专业人工翻译的结果,则越好。 stats=[] stats.append(len(hypothesis)) stats.append(len(reference)) for n in range(1,5): s_ngrams=Counter([tuple(hypothesis[i:i+n]) for i in range(len(hypothesis)+1-n)]) r_ngrams=Counter([tuple(reference[i:i+n]) for i in range(len(reference)+1-n)]) stats.append(max([sum((s_ngrams&r_ngrams).values()),0])) stats.append(max([len(hypothesis)+1-n,0])) return stats def bleu(stats): #Compute BLEU given n-gram statistics if len(list(filter(lambda x:x==0,stats)))>0: return 0 (c,r)=stats[:2] log_bleu_prec=sum([math.log(float(x)/y) for x,y in zip(stats[2::2],stats[3::2])])/4. return math.exp(min([0,1-float(r)/c])+log_bleu_prec) def get_bleu(hypotheses, reference): """Get validation BLEU score for dev set.""" stats = np.array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) for hyp, ref in zip(hypotheses, reference): stats += np.array(bleu_stats(hyp, ref)) return 100 * bleu(stats) def epoch_time(start,end): elapsed_time=end-start elapsed_mins=int(elapsed_time/60) elapsed_secs=int(elapsed_time-(elapsed_mins*60)) return elapsed_mins,elapsed_secs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
这里用到了bleu分数来对最后的结果进行评测,一般不用手动实现,包里会自带。但是这里还是手动实现了一下。如何实现不用管,只需要知道分数越高,结果越好。一般来说是0-1之间的数,但是这里乘了个100,变成了0-100的数。
Train
这里就是训练测试的主程序了。
import math import time import torch from torch import nn,optim from torch.optim import Adam from data_try import * from models.model import Transformer from util import get_bleu from util import epoch_time import numpy as np #这里是一些定义的常量 device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu") batch_size=128 max_len=256 d_model=512 n_layers=6 n_heads=8 ffn_hidden=2048 drop_prob=0.1 init_lr=1e-5 factor=0.9 adam_eps=5e-9 patience=10 warmup=100 epoch=8 clip=1 weight_dacay=5e-4 inf=float("inf") #1-- def count_parameters(model): return sum(p.numel() for p in model.parameters() if p.requires_grad) def initialize_weights(m): if hasattr(m,"wieght") and m.weight.dim()>1: nn.init.kaiming_uniform(m.weight.data) model=Transformer(src_pad_idx=src_pad_idx, trg_pad_idx=trg_pad_idx, trg_sos_idx=trg_sos_idx, d_model=d_model, enc_voc_size=enc_voc_size, dec_voc_size=dec_voc_size, max_len=max_len, ffn_hidden=ffn_hidden, n_head=n_heads, n_layers=n_layers, drop_prob=drop_prob, device=device).to(device) print(f'The model has {count_parameters(model):,} trainable parameters') model.apply(initialize_weights) optimizer=Adam(params=model.parameters(),lr=init_lr,weight_decay=weight_dacay,eps=adam_eps) scheduler=optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,verbose=True,factor=factor,patience=patience) criterion=nn.CrossEntropyLoss(ignore_index=src_pad_idx) #--1 #2-- def train(model,iterator,optimizer,criterion,clip): model.train() epoch_loss=0 i=0 for src,trg in iterator: i+=1 src=src.to(device) trg=trg.to(device) optimizer.zero_grad() output=model(src,trg[:,:-1]) output_reshape=output.contiguous().view(-1,output.shape[-1]) trg=trg[:,1:].contiguous().view(-1) loss=criterion(output_reshape,trg) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(),clip) optimizer.step() epoch_loss+=loss.item() print('step :',round((i/len(iterator))*100,2),'% , loss :',loss.item()) return epoch_loss/len(iterator) def idx_to_word(x,vocab): words=[] for i in x.cpu().numpy(): word=vocab.idx2word[i] if '<' not in word: words.append(word) words=" ".join(words) return words def evaluate(model,iterator,criterion): model.eval() epoch_loss=0 batch_bleu=[] with torch.no_grad(): for src,trg in iterator: trg1=trg src=src.to(device) trg=trg.to(device) output=model(src,trg[:,:-1]) output_reshape=output.contiguous().view(-1,output.shape[-1]) trg=trg[:,1:].contiguous().view(-1) loss=criterion(output_reshape,trg) epoch_loss+=loss.item() total_bleu=[] for j in range(batch_size): try: trg_words=idx_to_word(trg1[j],fra_dict) output_words=output[j].max(dim=1)[1] output_words=idx_to_word(output_words,fra_dict) bleu=get_bleu(hypotheses=output_words.split(),reference=trg_words.split()) total_bleu.append(bleu) except: pass total_bleu=sum(total_bleu)/len(total_bleu) batch_bleu.append(total_bleu) batch_bleu=sum(batch_bleu)/len(batch_bleu) return epoch_loss/len(iterator),batch_bleu def run(total_epoch,best_loss): train_losses,test_losses,bleus=[],[],[] for step in range(total_epoch): start_time=time.time() train_loss=train(model,train_loader,optimizer,criterion,clip) valid_loss,bleu=evaluate(model,test_loader,criterion) end_time=time.time() if step>warmup: scheduler.step(valid_loss) train_losses.append(train_loss) test_losses.append(valid_loss) bleus.append(bleu) epoch_mins,epoch_secs=epoch_time(start_time,end_time) if valid_loss<best_loss: best_loss=valid_loss #torch.save(model.state_dict(),'saved/model-{0}.pt'.format(valid_loss)) #将训练好的模型进行存储,下次就不用重新训练了。 f=open("result/train_loss.txt",'w') f.write(str(train_losses)) f.close() f = open('result/bleu.txt', 'w') f.write(str(bleus)) f.close() f = open('result/test_loss.txt', 'w') f.write(str(test_losses)) f.close() print(f'Epoch: {step + 1} | Time: {epoch_mins}m {epoch_secs}s') print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}') print(f'\tVal Loss: {valid_loss:.3f} | Val PPL: {math.exp(valid_loss):7.3f}') print(f'\tBLEU Score: {bleu:.3f}') #--2 run(epoch,inf)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
1- -1
这部分是训练之前对模型的定义和初始化。
count_parameters函数用于计算模型中所用到的参数数量,这个参数是包中调好的。
这里的优化器用了Adam,损失函数用交叉熵损失。
2- -2
这部分开始训练和测试。
train函数部分
src和trg变量在数据预处理部分已经有过展示,是翻译前后每个句子的向量表示。这里to(device)的方法是把变量放到GPU上,因为torch要求所有变量必须在一个设备上(CPU或GPU),否则会抛出异常。
output和trg是两个tensor,表示经过Transformer模型后得出的翻译结果和标准的译文。
这里以输出变量的形式说明,每一步的操作干了什么。
train函数开始第二行的trg变量:
trg1

对trg变量进行变换。

通过对比可以看到,trg[:,1:].contiguous().view(-1)的操作,把所有维度的数据增加至了同一个维度,并且通过切片删除了1的数据(因为1是<sos>)。
output_reshape的变量就比较抽象了,数据也很大,只显示了一部分。

和trg相比,差的不是一星半点。这是因为数据集过小,并且我只取了一个epoch,并没有反向传播进行参数的修改,相当于没开始训练,只是简单演示。
evaluate函数部分
函数中前面的内容和train差不多,主要是后面的部分。
这一部分的功能是获得Bleu分数。
为什么要用到try-catch语句呢?
因为我们并不知道每一个句子的长度大小,所以在每一批训练测试中,用最大的批尺寸来进行代替。但是有些句子不会有这么大的长度,如果不用try-catch会抛出超过列表下标的异常,下方的代码就不会运行。
进行分数的评测我们需要统一标准,所以这里统一用词典中的序列来作为标准。
这里通过写idx_to_word()函数,来获取序列。
有一些细节需要注意。trg变量已经经过变换,但是计算的时候要求原变量。所以要在开始做变量复制。
在idx_to_word函数中,为什么要写x.cpu().numpy()呢?因为数据trg是tensor张量,而tensor张量不是可迭代对象,直接运行会报错。所以需要转化成numpy数组。但是问题又来了,trg是gpu上的变量,gpu上的变量是无法转化为numpy数组的,所以只能先转到cpu上。
同样,打印一些变量。

这里是一些循环中的变量,可以看出翻译前后的效果。Bleu是根据图中的结果来计算分数的。

