
热门标签
热门文章
- 1【rpm】源码包制作rpm包|修改rpm、重新制作rpm包_linux rpm封装的时候图标路径怎么修改
- 2Meta最新模型LLaMA细节与代码详解_llama模型结构
- 3人工智能 AI 概念梳理_ai概念
- 4苹果携手百度 两家将共享广告营收
- 5待记录_23设计模式雨神
- 6自然语言处理中的神经网络和卷积神经网络
- 7 最好用的编辑器之一:Vim-Go环境搭建
- 8Python机器学习入门指南(全)_python 机器学习
- 9【自然语言处理】【多模态】多模态综述:视觉语言预训练模型
- 10【回归预测】基于TPA-LSTM(时间注意力注意力机制长短期记忆神经网络)实现数据多输入单输出回归预测附matlab代码_基于注意力机制优化长短期记忆网络
当前位置: article > 正文
LLM的理论古往今来(持续更新ing...)_head-to-tail: how knowledgeable are large language
作者:IT小白 | 2024-04-06 23:46:02
赞
踩
head-to-tail: how knowledgeable are large language models (llm)? a.k.a. will
要真说追是很难追上的,反正就……
作为一个笔记集锦。
文中的年份并不严格与内容对应,尤其在跨年的情况下。
数值推理、序列标注/信息抽取相关论文不写在本篇。
在我写prompt技巧的博文(prompt工程(持续更新ing…))中出现过的论文也不在本篇中再度赘述。
2024年
- 评估
- (AAAI) Avoiding Data Contamination in Language Model Evaluation: Dynamic Test Construction with Latest Materials:LatestEval评估方法,利用最新文本避免数据污染
- 长文本
- Soaring from 4K to 400K: Extending LLM’s Context with Activation Beacon
- (印度理工学院) Large Language Models aren’t all that you need:这篇就是说在传统NER方法上叠加trick其实能超越LLM
- (谷歌) LLM Augmented LLMs: Expanding Capabilities through Composition:LLM helps LLM。通过cross attention组合LLM
2023年
- 综述
- (人大高瓴人工智能学院)《A Survey of Large Language Models》及其中文版《大语言模型综述》
A Survey of Large Language Models
https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey_Chinese_0418.pdf - Domain Specialization as the Key to Make Large Language Models Disruptive: A Comprehensive Survey
- On the Origin of LLMs: An Evolutionary Tree and Graph for 15,821 Large Language Models
- (华为) Aligning Large Language Models with Human: A Survey
- A Survey on Evaluation of Large Language Models
- A Survey on Multimodal Large Language Models
- A Comprehensive Overview of Large Language Models
- Igniting Language Intelligence: The Hitchhiker’s Guide From Chain-of-Thought Reasoning to Language Agents
- The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
- Data Management For Large Language Models: A Survey
- (ACM Computing Surveys) Survey of Hallucination in Natural Language Generation
- (人大高瓴人工智能学院)《A Survey of Large Language Models》及其中文版《大语言模型综述》
- 集锦
- 教程
- The Curse of Recursion: Training on Generated Data Makes Models Forget:(第一个版本的标题比较劲爆)大意就是说用LLM生成的数据再训练LLM会使LLM效果越来越烂
- Intelligence Primer
- 长文本
- Blockwise Parallel Transformer (BPT):Blockwise Parallel Transformer for Long Context Large Models
- The Impact of Positional Encoding on Length Generalization in Transformers:比较了不同PE的长度泛化效果
- (微软)LongNet: Scaling Transformers to 1,000,000,000 Tokens:线性计算复杂性,dilated attention(注意力随距离增加指数下降)
- LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models
- 综述:Advancing Transformer Architecture in Long-Context Large Language Models: A Comprehensive Survey
- (2023 TACL) Lost in the Middle: How Language Models Use Long Contexts
- (2023 ACL) Sen2Pro: A Probabilistic Perspective to Sentence Embedding from Pre-trained Language Model:将句子表征为向量空间的probability density distribution。这个方法不用retrain,可以直接插到LLM上
- 为什么现在的LLM都是Decoder only的架构? - 知乎
- transformer中的attention为什么scaled? - 知乎
- 模型蒸馏
- 模型量化
- ChatGPT大家族系列
- 黑客 George Hotz 爆料 GPT-4 由 8 个 MoE 模型组成,真的吗? - 知乎:听OpenAI讲,这就是大力出奇迹!
- Let’s Verify Step by Step
- ICL
- 微调
- Symbol tuning improves in-context learning in language models
- 优化器
- MiniChain
- (ICLR) Self-Consistency Improves Chain of Thought Reasoning in Language Models
从语言模型中对不同的输出集(利用采样生成多种不同的推理路径)进行采样,并返回集合中最一致的答案→其实是集成方法,代替CoT的贪心策略
ReadPaper AI讲解论文:https://readpaper.com/paper/666189129860624384 - RLHF
- CoT论文列表:https://github.com/Timothyxxx/Chain-of-ThoughtsPapers
- The Flan Collection: Designing Data and Methods for Effective Instruction Tuning:prompt集合
- (ACL) Self-Instruct: Aligning Language Models with Self-Generated Instructions:bootstraping扩展指令
- Exploring Format Consistency for Instruction Tuning:数据集间指令格式统一
- Instruction Tuning for Large Language Models: A Survey
- Tied-Lora: Enhacing parameter efficiency of LoRA with weight tying
- (EACL) DyLoRA: Parameter Efficient Tuning of Pre-trained Models using Dynamic Search-Free Low-Rank Adaptation
- Full Parameter Fine-tuning for Large Language Models with Limited Resources:LOMO方法
- 检索+生成
- (ICLR) Generate rather than Retrieve: Large Language Models are Strong Context Generators:认为以前的工作都是先检索后阅读,本文先生成上下文文档,再阅读生成的文档,生成最终答案
基于聚类的prompt方法:选择不同的prompt,以使生成的文档涵盖不同的视角,从而提高recall
ReadPaper AI讲解论文:https://readpaper.com/paper/4670624394054221825 - Retrieval meets Long Context Large Language Models
- Model-enhanced Vector Index
- Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models:思路是如果检索到不相关的信息可能会误导LLM,此外LLM本身可能不知道它自身与知识库能提供的知识够不够回答问题。本文提出CON方法来提高RAG的鲁棒性:为检索到的文档生成连续阅读笔记,评估其与问题的相关性,整合生成答案
- Learning to Filter Context for Retrieval-Augmented Generation
- (苹果) Context Tuning for Retrieval Augmented Generation
- Large Language Models for Information Retrieval: A Survey
- RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models:高质量语料,包含LLM+RAG的自动回复,标注了幻觉强度等
- (ICLR) Quantifying Memorization Across Neural Language Models
- (ICLR) Generate rather than Retrieve: Large Language Models are Strong Context Generators:认为以前的工作都是先检索后阅读,本文先生成上下文文档,再阅读生成的文档,生成最终答案
- (ICLR) APE
Large Language Models Are Human-Level Prompt Engineers:总之就是用LLM自己写prompt - (普林斯顿) InstructEval: Systematic Evaluation of Instruction Selection Methods:评估prompt
参考阅读博文:放弃评测大模型,普林斯顿大学已经开始评估Prompt了,提出Prompt评估框架 - TELeR: A General Taxonomy of LLM Prompts for Benchmarking Complex Tasks
参考阅读博文:GPT-4使用效果不好?美国奥本大学提出Prompt分类法,另辟蹊径构建Prompt设计指南 - 推荐系统
- Is ChatGPT a Good Recommender? A Preliminary Study
- 新闻推荐
- (SIGIR) Prompt4NR
Prompt Learning for News Recommendation
- (SIGIR) Prompt4NR
- LLM+KG
- 可靠性1
- Measuring Faithfulness in Chain-of-Thought Reasoning:衡量CoT推理的忠实性
发现有时模型会忽略生成的推理,就硬是照着自己想的来说(模型越大越容易发生这种事)
解决方案是选择合适的模型 - Question Decomposition Improves the Faithfulness of Model-Generated Reasoning
给出了解决方案:将问题分解为子问题,并分别解答
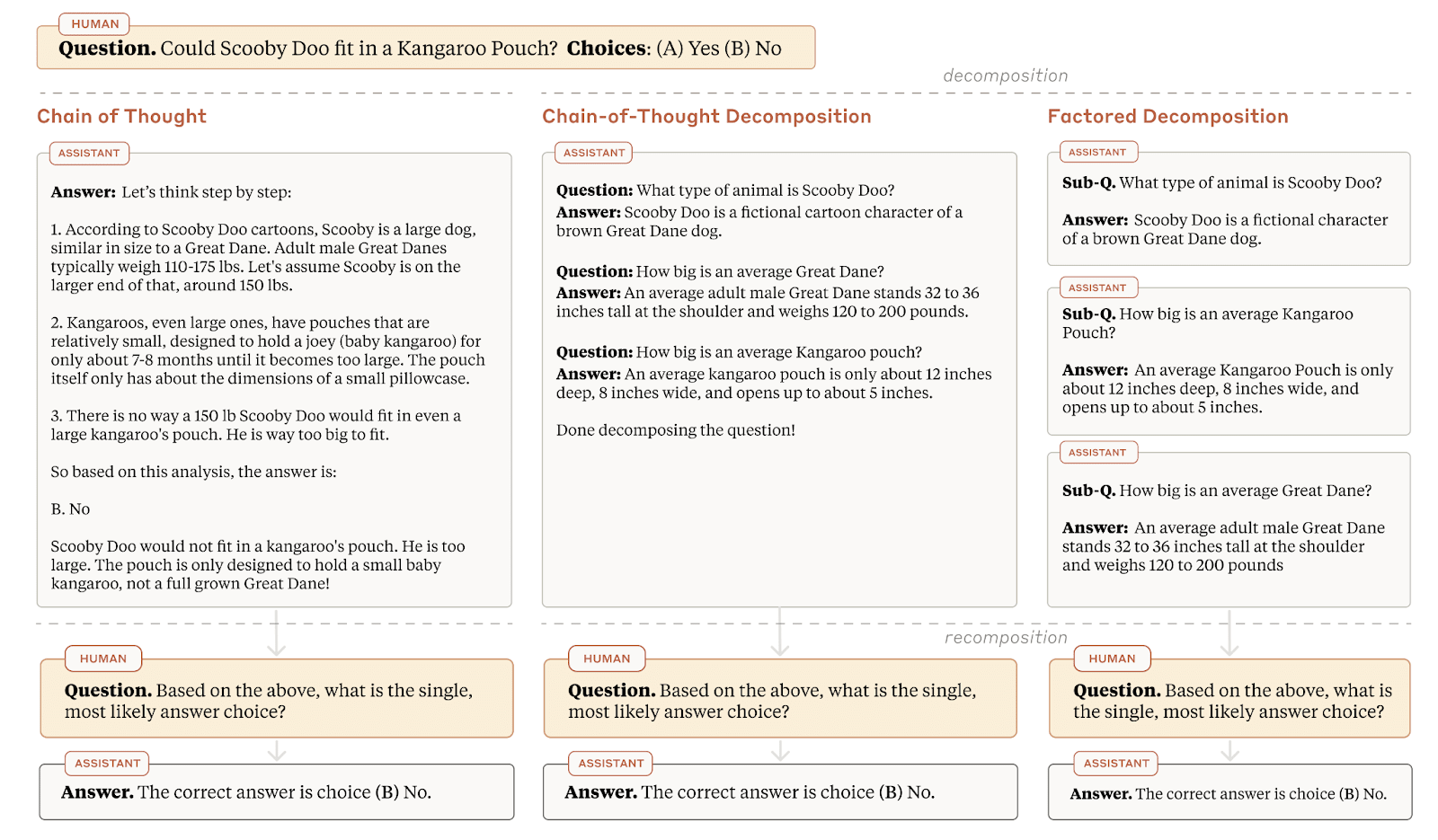
- (Meta) Head-to-Tail: How Knowledgeable are Large Language Models (LLM)? A.K.A. Will LLMs Replace Knowledge Graphs?:认为LLM不能替代LM,因为它不可靠,而且这不可靠很难优化(就常规优化LLM的方法很难解决不可靠问题本身)。
- 幻觉问题的综述:
- Fine-tuning Language Models for Factuality:评估文本事实真实性,微调语言模型使其产生较少的事实性错误
- Measuring Faithfulness in Chain-of-Thought Reasoning:衡量CoT推理的忠实性
- 评测
(微软) A Survey on Evaluation of Large Language Models
(天大) Evaluating Large Language Models: A Comprehensive Survey
GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs - Toolformer
Toolformer: Language Models Can Teach Themselves to Use Tools:LLM自学使用小工具
Graph-ToolFormer: To Empower LLMs with Graph Reasoning Ability via Prompt Dataset Augmented by ChatGPT - Large Language Models as Optimizers:用自然语言描述优化任务(这个提示也可以优化),让LLM自己优化,一步一步迭代
- agent
- Detecting Pretraining Data from Large Language Models:检测某段文本是否被LLM用于预训练
- (Meta) The ART of LLM Refinement: Ask, Refine, and Trust
- 可解释性:(Anthropic) Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
- 模型加速:Accelerating Generative AI with PyTorch II: GPT, Fast | PyTorch
- LM-Cocktail: Resilient Tuning of Language Models via Model Merging:这篇的思路是微调模型会出现灾难性遗忘问题,所以本文将base模型和微调模型的参数加权平均,发现效果很好。但是相关fuse工作这样的结论早就有了,supermario(阿里)的就是直接求平均
- Contrastive Chain-of-Thought Prompting:idea被scoop原来就是这样的感觉吗(喃喃)
- Ghostbuster: Detecting Text Ghostwritten by Large Language Models:检索LLM生成的文本
- Scalable Extraction of Training Data from (Production) Language Models:鼓励ChatGPT泄漏训练数据
- Prompt Engineering a Prompt Engineer
- (微软) Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine:这一篇是用提示工程在专业领域上解决任务的
- SparQ Attention: Bandwidth-Efficient LLM Inference:推理加速
- Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
- Why “classic” Transformers are shallow and how to make them go deep
- MoDS: Model-oriented Data Selection for Instruction Tuning
- Are Emergent Abilities of Large Language Models a Mirage?
- Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models
- Improving Text Embeddings with Large Language Models
2022年
- prompt
- (ACM Computing Surveys) Re33:读论文 Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Languag
- (CHI LBW) PromptChainer: Chaining Large Language Model Prompts through Visual Programming:这个是将多个LLM链接(也就是先过一个LLM,然后再过一个LLM……etc)的可视化编程工具
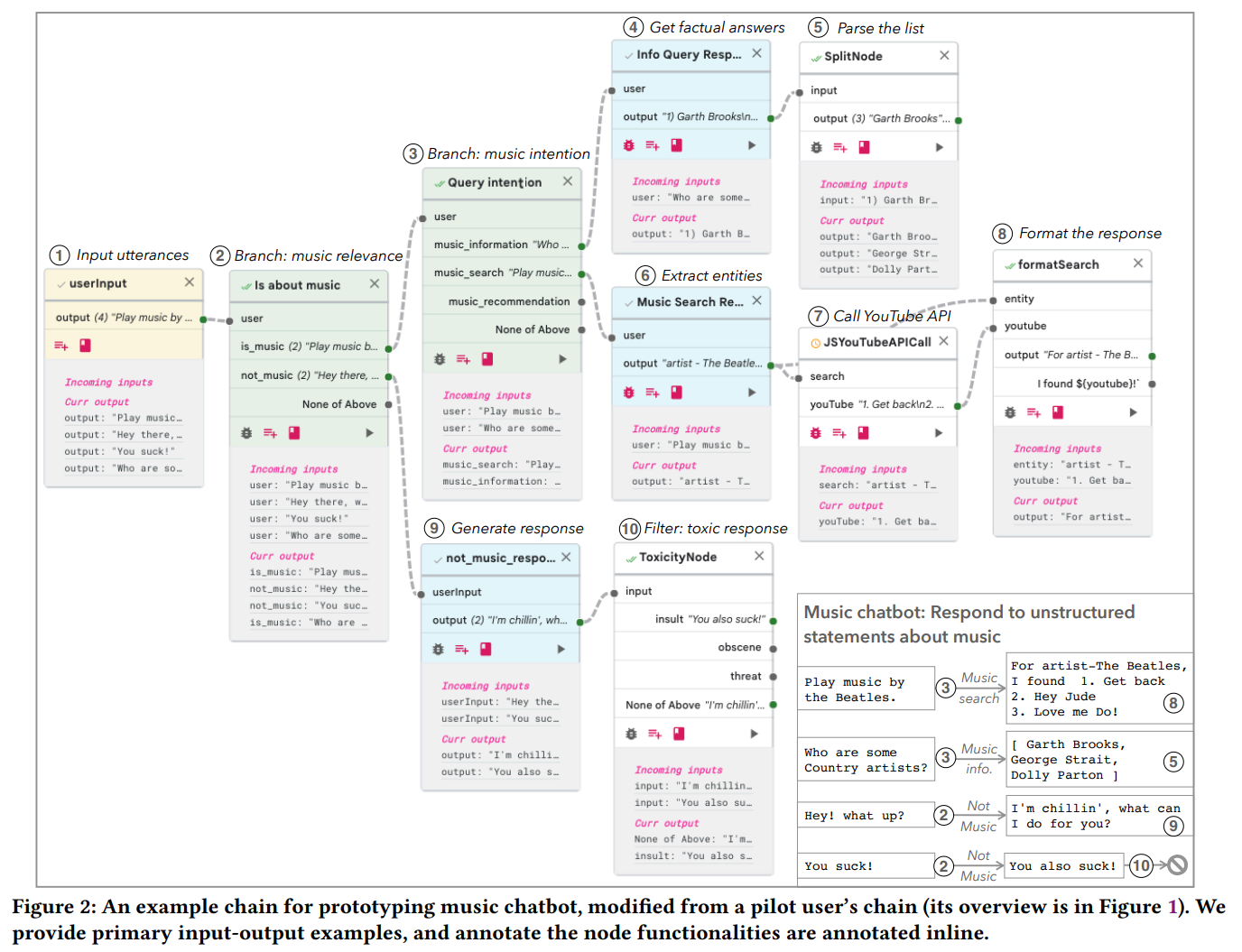
- LangChain
- LLamaIndex
- 预训练 / 微调策略
- (ICLR) LoRA: Low-Rank Adaptation of Large Language Models
- RLHF / instruction following / 指令对齐
(NeurIPS) Training language models to follow instructions with human feedback
官方博文:Aligning language models to follow instructions - Scaling Instruction-Finetuned Language Models
- instruction-based finetuning / instruction tuning / FLAN:通过instruction(可以理解成“简介”之类的)描述一堆数据集,LM在上面微调,然后LM就能在别的用instruction描述的数据集上面的表现效果也有所提升。就提升LM的零样本学习效果(拿来做实验用的是LaMDA模型)
论文:(ICLR 谷歌) Finetuned Language Models Are Zero-Shot Learners
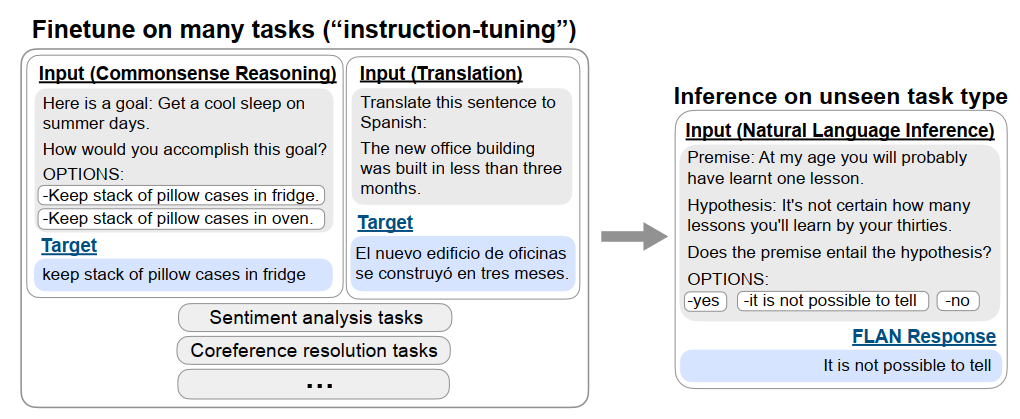
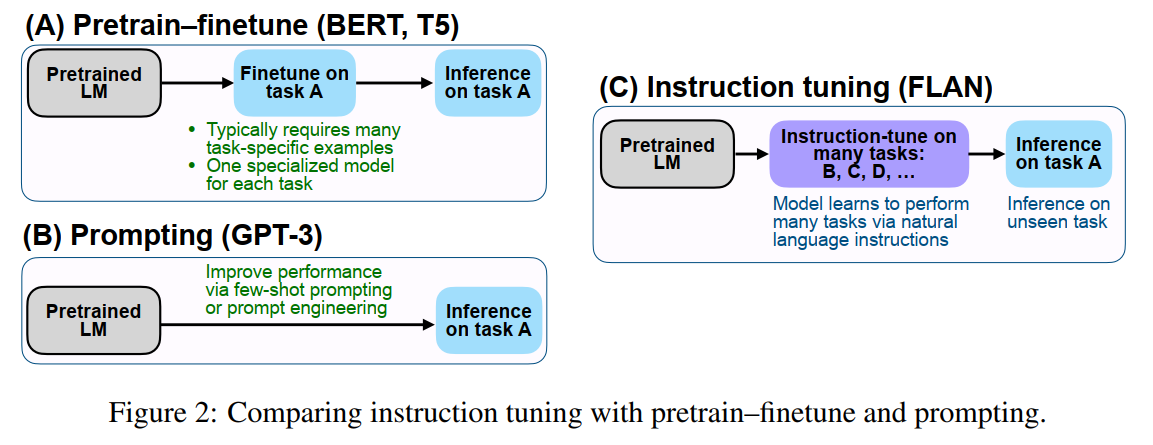
- 检索
- (DeepMind) RETRO
Improving language models by retrieving from trillions of tokens:检索文档chunk,调节AR语言模型。
用BERT将token数据库嵌入chunk中
chunked cross-attention mechanism
- (DeepMind) RETRO
- 涌现能力:(TMLR) Emergent Abilities of Large Language Models
2021年
- prefix-tuning
- LoRA: Low-Rank Adaptation of Large Language Models
- prompt
- (EACL) Language Models as Knowledge Bases: On Entity Representations, Storage Capacity, and Paraphrased Queries
关注LLM中的知识如何表示,以及LLM的知识存量(和LLM规模基本线性增长) - (EMNLP Findings) Retrieval Augmentation Reduces Hallucination in Conversation:用检索解决幻觉问题
2020年
- (ACL) Re26:读论文 Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks:大致是说LLM在通用域上预训练之后,在领域和任务上再继续预训练会提升模型效果
- Adapter
- RAG
- Scaling Laws for Neural Language Models
2019年
- Adapter:怎么说呢感觉就是在LLM里新加了一个模块,然后只调这个模块,不调全局参数。
这样使得微调效率upup - LAnguage Model Analysis (LAMA)
- 论文:(2019 EMNLP) Language Models as Knowledge Bases?:探查语言模型中的关系知识。具体的解决方案就是将问题作为填空题给出,让模型计算mask位置的结果。结果是LLM做得还不错(我感觉如果用新的LLM可能会效果更好)
- (NAACL) Linguistic Knowledge and Transferability of Contextual Representations:对比了BERT / ELMo / GPT(文中叫OpenAI transformer),主要探讨了语言模型编码了什么特征和不同层、不同预训练任务的transferibility问题
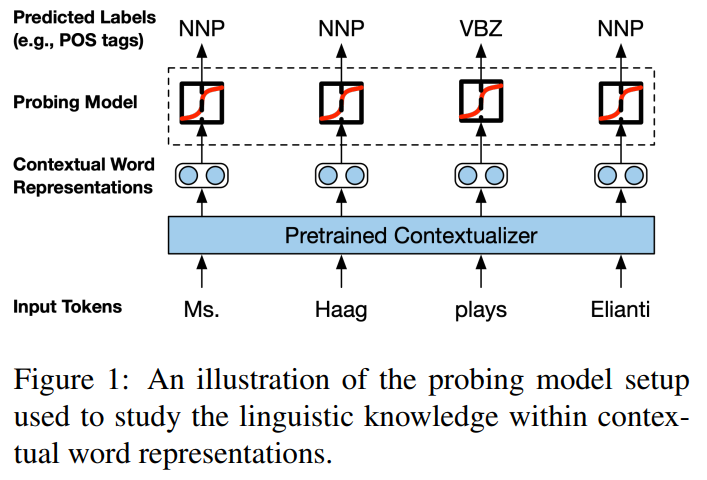
(这篇论文的实验也太多了,就算以现在的目光来看也只能感慨真是有钱有时间!)
参考讲解博文:ELMo/GPT/BERT对比 - 知乎 - (ACL 香侬科技) Is Word Segmentation Necessary for Deep Learning of Chinese Representations?:得到了字几乎总是优于词的结论(苏神认为这篇的实验不足,这篇实验对比字嵌入和词嵌入都用得是随机初始化的嵌入矩阵,这导致以词为单位的模型嵌入层参数更多,容易过拟合。但事实上一般用的都是预训练好的词向量,但这篇文章里没有关注到这个场景。苏神后来做的WoBERT认为以词为单位其实效果更好)
- (ACL) Barack’s Wife Hillary: Using Knowledge Graphs for Fact-Aware Language Modeling
2018年
2016年
- A Neural Knowledge Language Model:将知识图提供的符号知识与 RNN 语言模型相结合。通过预测要生成的单词是否具有潜在事实,模型可以通过复制预测事实的描述来生成此类与知识相关的单词
- Reference-Aware Language Models:参考外部信息实现LM
参考资料
- 我还没读的集成类内容:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/375078
推荐阅读
相关标签

