
- 1鸿蒙~ArkUI 基础 Grid网格布局_arkui grid 设置每行数量
- 2vue动态改变主题颜色_springboot vue 预警数据动态选择颜色变化
- 3基于Ubuntu22.04的Samba服务器搭建教程(新手保姆级教程)_ubuntu samba
- 42021.5.29-参加工信部蓝桥杯青少组国赛(一等奖)_蓝桥杯青少组国赛一等奖难吗
- 5Transformer解读和实战_transformer实战
- 6Albumentations——强大的数据增强库(图像分类、分割、关键点检测、目标检测)
- 7微信小程序对于回调函数异步API的优化
- 8CHATGPR插件-智能代码编写工具_vscode文心一言
- 9scss的常用技巧、循环、判断等
- 10基于F4/F7/H7飞控硬件和px4飞控固件的廉价自主无人机系统(1)-飞控_f4飞控是开源的吗
python产生随机数_使用Python进行垃圾短信识别(下篇)
赞
踩

点击上方关注我们!
今天向大家介绍一个文本挖掘和可视化具体案例:使用python进行垃圾短信识别,即
基于短信文本内容,建立识别模型,准确地识别出垃圾短信,以解决垃圾短信过滤问题。
今天的内容接着之前的上篇,如果没有看过上篇的,感兴趣的小伙伴可以查看一下哦

3
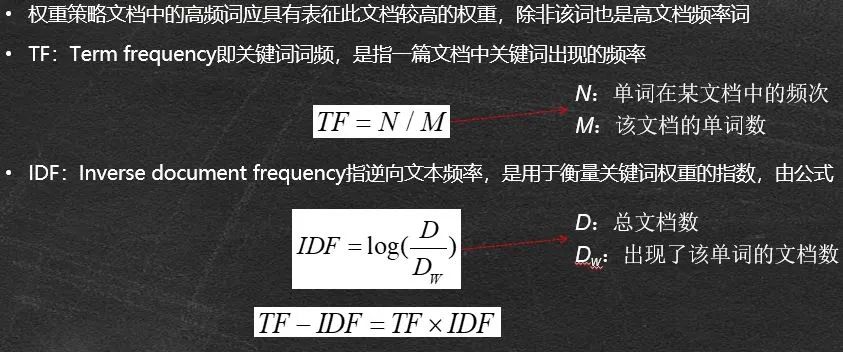
文本的向量表示
在这里使用的方法是:
TF-IDF权重策略。
文本分析实例:
1.sklearn.feature_extraction.text #文本特征提取模块
2.CountVectorizer #转化词频向量函数
3.fit_transform() #转化词频向量方法
4.get_feature_names() #获取单词集合方法
5.toarray() #获取数值矩阵方法
6.TfidfTransformer #转化tf-idf权重向量函数
7.fit_transform(counts) #转成tf-idf权重向量方法
1.分词;去除停用词;
2.转换成词频向量
3.转换成TF-IDF权重矩阵
4.特征提取,构建模型
from sklearn.feature_extraction.text import
CountVectorizer,TfidfTransformer
from sklearn.naive_bayes import GaussianNB
corpus = [
'My dog has flea problems, help please.',
'Maybe not take him to dog park is stupid.',
'My dalmation is so cute. I love him my.',
'Stop posting stupid worthless garbage.',
'Mr licks ate my steak, what can I do?.',
'Quit buying worthless dog food stupid'
]
labels = [0,1,0,1,0,1]
transformer = TfidfTransformer()
#转化tf-idf权重向量函数
vectorizer = CountVectorizer()
#转化词频向量函数
word_vec = vectorizer.fit_transform(corpus)
#转成词向量
words = vectorizer.get_feature_names()
#单词集合
word_cout = word_vec.toarray()
#转成ndarray
tfidf = transformer.fit_transform(word_cout)
#转成tf-idf权重向量
tfidf_ma= tfidf.toarray()
#转成ndarray
clf = GaussianNB().fit(tfidf_ma[:4,:],labels[:4])
res = clf.predict(tfidf_ma[4:,:])
4
模型训练及评价
朴素贝叶斯
Python实现:
原始的朴素贝叶斯只能处理离散数据,当 x1,…,xn 是连续变量时,我们可以使用高斯朴素贝叶斯(Gaussian Naive Bayes)完成分类任务。
当处理连续数据时,一种经典的假设是:与每个类相关的连续变量的分布是基于高斯分布的,故高斯贝叶斯的公式如下:
⭐naive Bayes is a decent classifier, but a bad estimator
高斯朴素贝叶斯
构造方法:sklearn.naive_bayes.GaussianNB
GaussianNB 类构造方法无参数,属性值有:
class_prior_ #每一个类的概率
theta_ #每个类中各个特征的平均
sigma_ #每个类中各个特征的方差
注:GaussianNB 类无score 方法
⭐Python实现——高斯朴素贝叶斯
import numpy as np
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Y = np.array([1, 1, 1, 2, 2, 2])
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(X, Y)
⭐多项式朴素贝叶斯——用于文本分类
构造方法:
sklearn.naive_bayes.MultinomialNB(alpha=1.0 #平滑参数
, fit_prior=True #学习类的先验概率
, class_prior=None) #类的先验概率
⭐Python实现——多项式朴素贝叶斯
import numpy as np
X = np.random.randint(5, size=(6, 100))
y = np.array([1, 2, 3, 4, 5, 6])
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB()
clf.fit(X, y)
模型训练与评价
sklearn. model_selection.train_test_split
随机划分训练集和测试集
⭐train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和testdata,形式为:
⭐X_train,X_test, y_train, y_test = model_selection.train_test_split(x_data, y_target, test_size=0.4, random_state=0)
train_test_split参数解释:
⭐x_data:所要划分的样本特征集
⭐y_target:所要划分的样本结果
⭐test_size:样本占比,如果是整数的话就是样本的数量
⭐random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
在train和test上提取的feature维度不同,所以让它们相同的方法:让两个CountVectorizer共享vocabulary。
⭐cv1 = CountVectorizer(vocabulary=cv.vocabulary_)
cv_test = cv1.fit_transform(x_test)
print(cv_test.toarray()) # 测试集的文档词条矩阵
#cv_test、cv_train向量长度应保持一致
 下面是具体示例代码:
下面是具体示例代码:
from data_process import data_process
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
adata, data_after_stop, lables = data_process()
data_tr, data_te, labels_tr, labels_te = train_test_split(adata, lables, test_size=0.2)
countVectorizer = CountVectorizer()
data_tr = countVectorizer.fit_transform(data_tr)
X_tr = TfidfTransformer().fit_transform(data_tr.toarray()).toarray()
data_te = CountVectorizer(vocabulary=countVectorizer.vocabulary_).fit_transform(data_te)
X_te = TfidfTransformer().fit_transform(data_te.toarray()).toarray()
model = GaussianNB()
model.fit(X_tr, labels_tr)
model.score(X_te, labels_te)


