
- 1区块链游戏解说:Axie Infinity 是什么
- 2CentOS8防火墙配置_centos8 firewall status running
- 3会议排座位系统图书馆座位预约系统哪个好?_会议排座次系统
- 4hbase 列族 版本数,TTL和二级索引_hbase最大版本数为什么是1
- 5让谷歌浏览器不再显示不安全内容的提示_--allow-running-insecure-content
- 62020-9-19_2020丨9丨22' 变为数组
- 7AlpacaEval Leaderboard大模型排行榜_alpacaeval logo leaderboard
- 8《牛客题霸-算法篇》刷题之NC140 排序
- 9MySQL 5种索引应用_mysql有哪些索引类型,分别有什么作用
- 10防重 Token 令牌如何实现幂等性?_前端什么时候获取唯一的token 来处理幂等
Scrapy_redis+scrapyd搭建分布式架构爬取知乎用户信息_scrapy-redis分布式局域网多台电脑之间怎么建立关联的
赞
踩
相关背景:前几天写了个用scrapy爬取知乎用户信息的爬虫(http://blog.csdn.net/qq_40717846/article/details/78950519),今天结合这个爬虫,写一个利用scrapy-redis+scrapyd构建分布式爬取知乎用户信息的爬虫。
相关准备:
win10操作系统,腾讯云服务器,redis,redis dedktop manager,Mongodb
1.在项目开始之前,请确保win10以及服务器都安装了redis以及mongodb,并且以win10为主机,win10的redis能够远程连接服务器的redis。
win 10安装Redis:https://github.com/rgl/redis/downloads
centos 安装Redis:直接运行命令:
yum install redis -y- 1
即可,安装完成后默认启动redis服务器。
2.安装完成之后都需要把redis.conf文件中的bind 127.0.0.1注释掉

修改后,重启redis服务器
systemctl restart redis
3.centos中的redis需要设置密码,用于win10的redis desktop远程连接:

4.用Redis Desktop Manager连接Redis(CentOS):
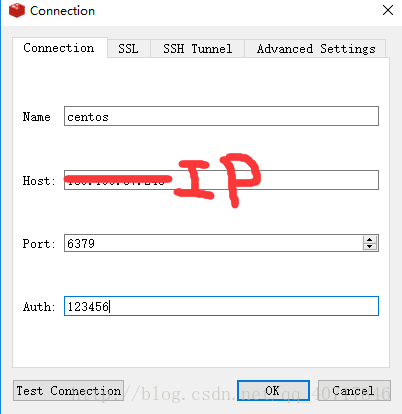
可参考:https://www.cnblogs.com/h-change/p/6077874.html
分布式原理:
scrapy-redis实现分布式,其实从原理上来说很简单,这里为描述方便,我们把自己的核心服务器称为master,而把用于跑爬虫程序的机器称为slave。
我们知 道,采用scrapy框架抓取网页,我们需要首先给定它一些start_urls,爬虫首先访问start_urls里面的url,再根据我们的具体逻辑,对里面的元素、或者是其他的二级、三级页面进行抓取。而要实现分布式,我们只需要在这个starts_urls里面做文章就行了。
我们在master上搭建一个redis数据库(注意这个数据库只用作url的存储,不关心爬取的具体数据,不要和后面的mongodb或者mysql混淆),并对每一个需要爬取的网站类型,都开辟一个单独的列表字段。通过设置slave上scrapy-redis获取url的地址为master地址。这样的结果就是,尽管有多个slave,然而大家获取url的地方只有一个,那就是服务器master上的redis数据库。
并且,由于scrapy-redis自身的队列机制,slave获取的链接不会相互冲突。这样各个slave在完成抓取任务之后,再把获取的结果汇总到服务器上(这时的数据存储不再在是redis,而是mongodb或者 mysql等存放具体内容的数据库了)
这种方法的还有好处就是程序移植性强,只要处理好路径问题,把slave上的程序移植到另一台机器上运行,基本上就是复制粘贴的事情。
分析思路:
1.使用两台机器,一台是win10,一台是centos7的服务器,分别在两台机器上部署scrapy来进行分布式抓取一个网站.
2.centos7的ip地址为139.199.57.248,用来作为redis的slave端,win10的机器作为master.
3.master的爬虫运行时会把提取到的url封装成request放到redis中的数据库:“dmoz:requests”,并且从该数据库中提取request后下载网页,再把网页的内容存放到redis的另一个数据库中“dmoz:items”.
4.slave从master的redis中取出待抓取的request,下载完网页之后就把网页的内容发送回master的redis.
5.重复上面的3和4,直到master的redis中的“dmoz:requests”数据库为空,再把master的redis中的“dmoz:items”数据库写入到mongodb中.
6.master里的reids还有一个数据“dmoz:dupefilter”是用来存储抓取过的url的指纹(使用哈希函数将url运算后的结果),是防止重复抓取的.
实现步骤:
1.先从Github上把前几天写的代码,clone到本地:
git clone https://github.com/dik111/Zhihu.git- 1
2.新建分支,以便不影响之前的代码:
git checkout -b distributed#新建分支
git branch#切换到分支- 1
- 2
3.修改setting.py文件:
SCHEDULER = "scrapy_redis.scheduler.Scheduler"#修改调度器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"#用于去重的class
'scrapy_redis.pipelines.RedisPipeline': 301#爬取结果存储到Redis
REDIS_URL = 'redis://root:123456@139.199.57.248:6379'
- 1
- 2
- 3
- 4
- 5
执行爬虫程序,可以看到Redis中多了zhihu这个文件
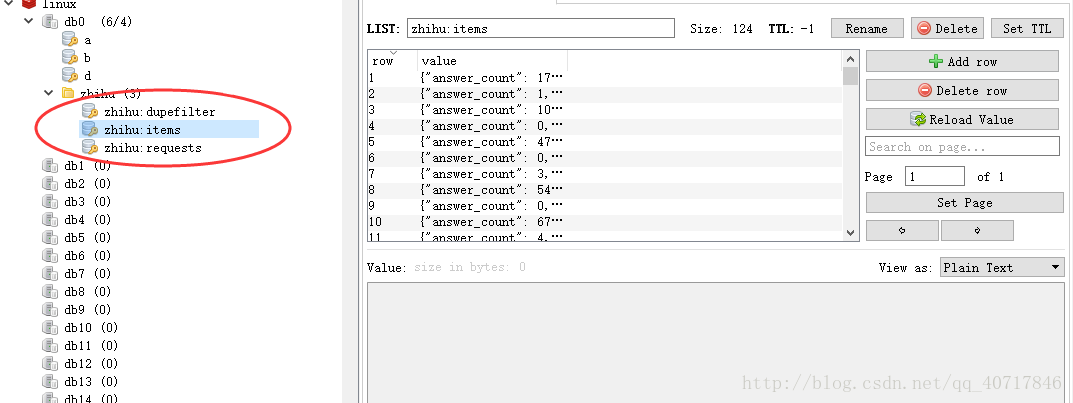
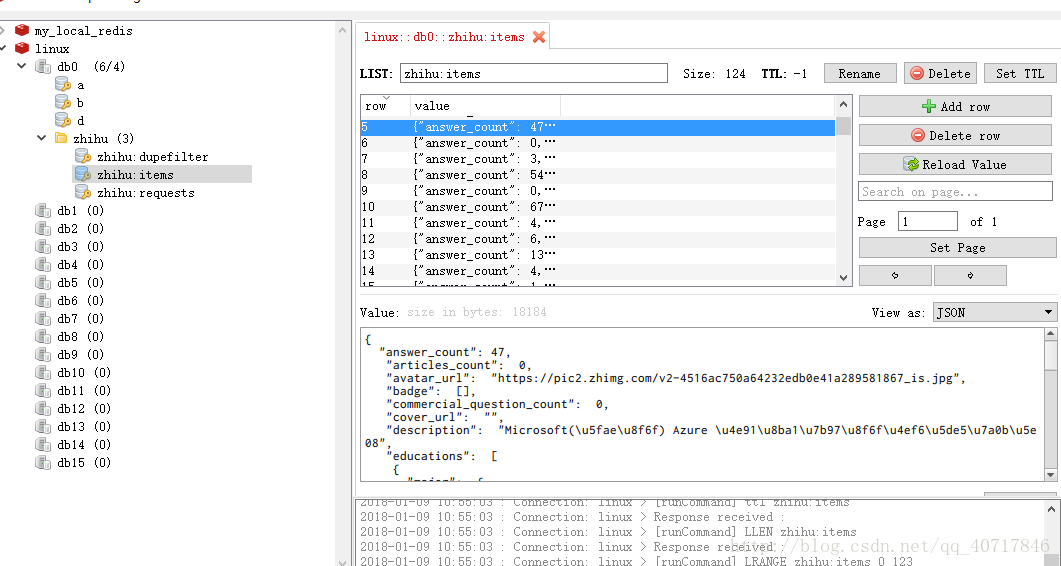
其中zhihu:dupefilter就是上文所说的用来存储抓取过的url的指纹(使用哈希函数将url运算后的结果),是防止重复抓取的。
4.把分支代码更新到Github:
git status
git add -A
git commit -m "add distributed"
git push origin distributed- 1
- 2
- 3
- 4
5.把代码部署到服务器:
5.1首先打开mongodb的配置文件mongodb.conf,把blind1270.0.1注释掉,以便远程连接mongodb。
5.2在linux系统下创建新的文件夹,并且把项目clone下来。
sudo git clone https://github.com/Germey/Zhihu.git -b distributed- 1
6.运行爬虫程序
scrapy crawl zhihu- 1
到这里一个简单的分布式框架已经搭建完成啦!
7.因为已经远程连接了mongodb,因此主机上面的redis已经不需要把从机的数据远程过来了,所以把之前的redis pipelines注释掉
#'scrapy_redis.pipelines.RedisPipeline': 301- 1
相关进阶
在上面的例子中,我们是用git来更新部署代码的,但是当主机非常多的时候,这样的操作显示有点繁琐,因此,在这里我推荐使用scrapyd来进行分布式的部署。
1.安装scrapyd:
pip install scrapyd- 1
2.启动scrapyd,并且访问远程端口:

3.修改scrapy.cfg文件:
url = http://http://127.0.0.1:6800/addversion.json
project = zhihuuser- 1
- 2
4.安装scrapyd_client
5.启动:scrapyd-deploy

更多相关的用法请到:http://scrapyd.readthedocs.io/en/stable/

