
- 1第27天:安全开发-PHP应用&TP框架&路由访问&对象操作&内置过滤绕过&核心漏洞
- 2什么是ChatGPT ?以及它的工作原理介绍
- 3测试用例的设计方法(七种)详细分析_如何设计测试用例
- 43D点云分割之SAGA(cvpr2023) 配置及使用_segment anything in 3d gaussians
- 5MySQL if else的格式_mysql if--else
- 6navicat,mysql导出er图,ER图
- 7stable diffusion本地部署的相关事宜
- 8【项目实战】基于高并发服务器的搜索引擎
- 9Docker Swarm:大规模简化容器的编排_docker swarm 编排
- 10【RabbitMQ】之持久化机制_rabbitmq 数据持久化
基于Python网络爬虫的评论大数据采集分析及可视化_大数据爬虫可视化案例
赞
踩
目录
=================P1 数据获取与保存=================
===================P2 生成词云===================
===================P3 数据展示===================
===================P4其他===================
实例简介:
通过网络爬虫获取目标网页评论区数据(官方账号/知名UP),使用评论区评论内容生成词云,并将数据保存至数据库和XLSX 工作表。再读取数据库内数据并展示到HTML网页;同时将生成的XLSX 工作表上传至HDFS文件管理系统。
(链接:【冰冰vlog.001】带大家看看每个冬天我必去的地方_哔哩哔哩_bilibili)
系统结构图:
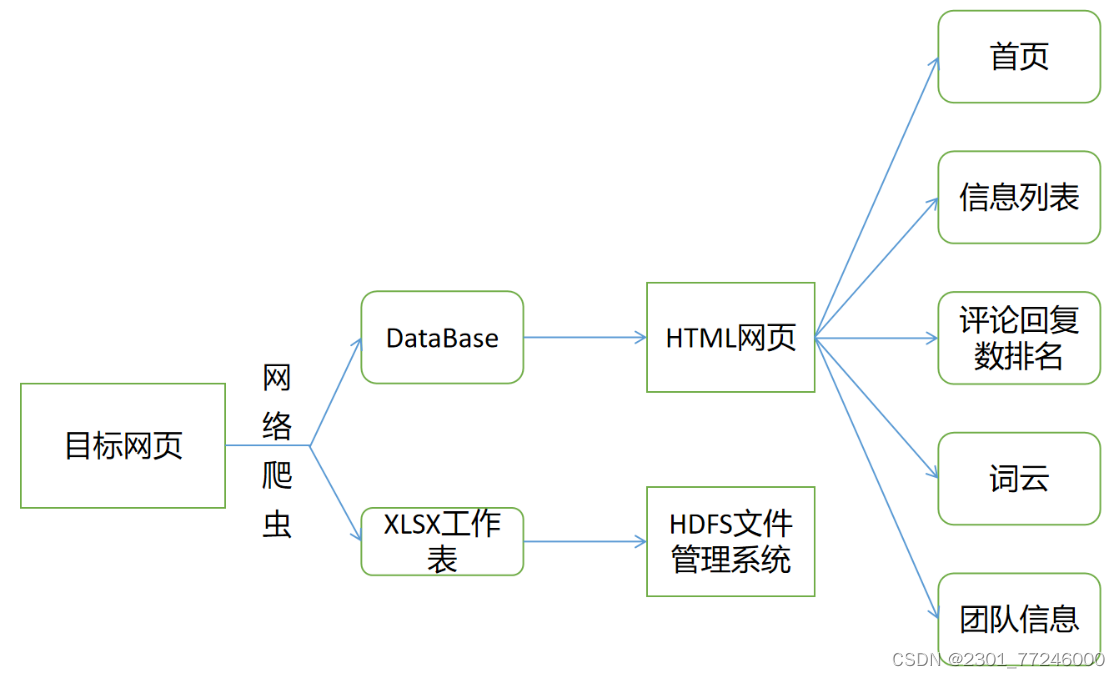
=================P1 数据获取与保存=================
要使用的库
- import re
- import xlwt
- import requests
- import json
- import sqlite3
- import time
- import random
找到目标数据
打开目标网页(B站评论显示为动态加载),使用F12键打开开发者工具,使用开发者工具中的网络工具。

查看内容刷新时服务器向浏览器返回的内容,找到main?csrf=项,点击查看请求url和user-agent(爬虫需要使用该部分内容)。滑动评论区,观察每次展示新评论时url的变换,找到其中的规律。
爬虫设计
1.自定义ask_url(in_url)函数:in_url表示要爬取的网页url链接,函数返回HTML信息,下一步从中挑选需要的内容。User-Agent通过上一部分使用开发者工具获得。
- def ask_url(in_url):
- head = {
- "User-Agent": "Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 112.0.0.0Safari / 537.36Edg / 112.0.1722.68"
- }
- try:
- time.sleep(random_time())
- r = requests.get(in_url, headers=head)
- r.raise_for_status()
- print(r.status_code)
- r.encoding = r.apparent_encoding
- html = r.text
- return html
- except:
- print("ERROR")
-
-

2.从HTML中找到数据。自定义函数getdata(dep),通过正则表达式筛选内容。dep表示需要爬取的页面数目,函数返回列表data_list
- # 从html信息中获得需要的内容,并把获得的内容保存到data_list中
- def getdata(dep):
- data_list = []
- for i in range(dep):
- url1 = 'https://api.bilibili.com/x/v2/reply/main?csrf=885d8049fbe8d890325dbac3ad57a05a&mode=3&next=' + \
- str(i + 1) + '&oid=800760067&plat=1&type=1'
-
- html = ask_url(url1)
-
- data = re.findall(find, html)
- jsonobj = json.loads(data[0])
-
- for item in jsonobj:
-
- data = []
-
- name = item['member']['uname']
- mid = item['mid']
- organisation = item['member']['official_verify']['desc']
- comment = item['content']['message'].replace('\n', '')
- link = 'https://space.bilibili.com/' + str(mid)
- reply_text = item['reply_control']["sub_reply_entry_text"]
- reply_num = re.findall(find_num, reply_text)[0]
-
- if organisation != '':
- data.append(name)
- data.append(link)
- data.append(mid)
- data.append(organisation)
- data.append(comment)
- data.append(int(reply_num))
-
- if not data:
- continue
- else:
- data_list.append(data)
- print('获取数据完成')
- return data_list
用到的正则表达式
- find = re.compile(r'\"replies\":(.*?),\"top\"')
- find_num = re.compile(r'共(.*?)条回复')
保存到数据库
本例使用PyCharm 2023.1专业版,可以直接使用数据库(社区版可能不行)。
以下部分代码是使用Python操作数据库(初始化(建表)、删除表、保存数据)。
- # 数据库初始化
- def db_init(db_path): # db_path表示数据库位置(路径)
- dbpath = db_path
- sql = '''
- create table comment
- (
- id integer primary key autoincrement,
- user_name varchar,
- space_link varchar,
- mid numeric,
- be_organ varchar,
- comment varchar,
- reply_count numeric
-
- )
- '''
- conn = sqlite3.connect(dbpath)
- cursor = conn.cursor()
- cursor.execute(sql)
- conn.commit()
- conn.close()
- print('数据库初始化完成')
-
- # 删除数据库中的表格
- def delete_table(db_path='comment.db'):
- dbpath = db_path
- sql1 = '''drop table comment;'''
- conn = sqlite3.connect(dbpath)
- cursor = conn.cursor()
- cursor.execute(sql1)
- conn.commit()
- conn.close()
-
-
- # 把data_list中的内容保存到已经初始化的数据库中
- def save_date_to_db(data_list, in_path):
-
- db_init(in_path)
- conn = sqlite3.connect(in_path)
- cur = conn.cursor()
-
- for date in data_list:
- for index in range(len(date)):
- if index == 2 or index == 5:
- continue
- date[index] = '"' + str(date[index]) + '"'
- sql = '''
- insert into comment(
- user_name, space_link, mid, be_organ, comment, reply_count)
- values(%s)''' % ",".join('%s' % a for a in date)
- # print(sql)
- cur.execute(sql)
- conn.commit()
- cur.close()
- conn.close()
- print("数据已保存至数据库")
-
保存数据至XLSX工作表
把列表data_list中的数据保存到工作表中。position表示要保存的位置
- # 将data_list中的内容保存到xlsx文件中
- def save_data(data_list, position):
- book = xlwt.Workbook(encoding="utf-8")
- sheet = book.add_sheet("sheet1", cell_overwrite_ok=True)
- col = ("昵称", "空间链接", "mid", "所属机构", "评论内容", "评论回复")
- for i in range(0, len(col)):
- sheet.write(0, i, col[i])
-
- for m in range(len(data_list)):
- print("正在保存第{}条数据到xlsx文件".format(m + 1))
- data = data_list[m]
- for n in range(0, len(col)):
- sheet.write(m + 1, n, data[n])
- book.save(position)
- print('数据已保存至xlsx文件中')
-
保存效果

将工作表上传至HDFS文件管理系统
在Linux系统,完成大数据平台(Hadoop)相关配置,打开终端,通过命令进行文件上传、下载操作,表格在hdfs保存路径:/user/data/comment.xlsx
-
- start-dfs.sh 启动hdfs
- Jps 查看进程
- hdfs dfs -ls /user 查看hdfs目录内容
- hdfs dfs -put /home/jerry/桌面/comment.xlsx /user/data 上传文件至目标目录
- hdfs dfs -rm -f /user/data/comment.xlsx 删除目标文件
- hdfs dfs -ls /user/data 查看目录内容
- hdfs dfs -get /user/data/comment.xlsx /home/jerry/下载 把文件下载至路径/home/jerry/下载
- 登陆网站 http://localhost:9870 查看文件
- hdfs dfs -chmod 777 /user/data 给目标文件夹增加权限
主函数
- def main():
- print("请输入要爬取的页面数目(请输入小于23的正整数):")
- depth = int(input()) # 获取爬取页面数目
- list1 = getdata(depth)
- print('共获得%d条数据' % len(list1))
- # 数据的保存路径,xlsx路径和数据库路径
- path = r"C:\Users\C11\Desktop\co.xlsx"
- path_to_db = "comment.db"
-
- save_data(list1, path) # 保存数据到指定路径的xlsx文件中
-
- delete_table()
- save_date_to_db(list1, path_to_db) # 保存数据到指定路径的数据库中
-
- print('共用时:', time.perf_counter() - start)
-
-
-
- main() # 调用主函数
- print('FINISH')
测试发现,dep大于等于23时会报错。
想知道有没有方法解决!!!!

执行效果(dep=11)

===================P2 生成词云===================
要使用的库
- import re
- import numpy as np
- import requests
- import jieba
- import json
- from matplotlib import pyplot as plt
- from wordcloud import WordCloud
- from PIL import Image
- import time
- import random
程序代码如下,生成词云
- start = time.perf_counter()
- exception = re.compile(r'\[.*?\]')
- find = re.compile(r'\"replies\":(.*?),\"top\"')
-
- # 获取网页内容
- def ask_url(in_url):
- head = {
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.34"
- }
- try:
- r = requests.get(in_url, headers=head)
- r.raise_for_status()
- print(r.status_code)
- r.encoding = r.apparent_encoding
- html = r.text
- except:
- print("ERROR")
- return html
-
- # 将字符串分割
- def word_cut(in_text):
- cut = jieba.cut(in_text)
- string = ' '.join(cut)
- return string
-
- # 生成词云
- def word_cloud(str1):
- # 要使用的图片模板(背景颜色必须为白色)
- img = Image.open(r'C:\Users\C11\Desktop\QQpicture1.jpg')
- img_array = np.array(img)
- wordcloud = WordCloud(
- background_color='white',
- stopwords=['的', '了', '是', '我', '在'],
- mask=img_array,
- font_path='STHUPO.TTF', # 设置字体样式,从C:\Windows\Fonts 路径下寻找字体
-
- )
- wordcloud.generate_from_text(str1)
- # fig = plt.figure(1)
- plt.imshow(wordcloud)
- plt.axis('off')
- plt.savefig(r"C:\Users\C11\Desktop\comment.jpg", dpi=1100)
-
- # 将html中的评论连接成一个字符串
- def connect_word(text, count_num):
- data = re.findall(find, text)
- jsonobj = json.loads(data[0])
- s1 = ''
- in_count = count_num
- for item in jsonobj:
- d = item['content']
- # print(item['content'])
- # print(type(item['content']))
- in_count += 1
- s1 += d['message']
- s1 = re.sub(exception, '', s1)
- s1 = s1.replace('\n', '').replace('声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/434993推荐阅读
相关标签

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

