
- 1IDEA启动提示Downloading pre-built shared indexes_download pre-built shared indexes
- 2大语言模型LLM《提示词工程指南》学习笔记05
- 3深度强化学习【1】-强化学习入门必备基础(含Python迷宫游戏求解实例)_强化学习 迷宫
- 4Python中f‘‘、str.format()和str%()的字符串格式化详解(1)------占位符及函数str()、repr()、ascii(),对象引用及描述_python f
- 5rabbitmq如何保证消息的可靠性_如何保障rabbitmq消息的保障性?
- 6Git使用个人访问令牌提交代码到仓库_gitlab个人访问令牌
- 7可视化安全管理在生产工作中的重要性
- 8vue ECharts 树图修改某节点样式,选中、聚焦改变节点样式等_echart tree 如果有子节点,显示加号
- 9Dreambooth Stable Diffusion始化训练环境(AutoDL)_dreambooth python版本
- 10vue element form rules表单规则验证,输入框有值,但验证始终不消失问题的个人解决办法_elform有值仍触发校验
PyTorch学习笔记2:nn.Module、优化器、模型的保存和加载、TensorBoard_nn.module优化器
赞
踩
文章目录
一、nn.Module
1.1 nn.Module的调用
pytorch通过继承nn.Module类,定义子模块的实例化和前向传播,实现深度学习模型的搭建。其构建代码如下:
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self, *kargs): # 定义类的初始化函数,...是用户的传入参数
super(Model, self).__init__()#调用父类nn.Module的初始化方法
... # 根据传入的参数来定义子模块
def forward(self, *kargs): # 定义前向计算的输入参数,...一般是张量或者其他的参数
ret = ... # 根据传入的张量和子模块计算返回张量
return ret
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- __init__方法初始化整个模型
- super(Model, self).__init__():调用父类nn.Module的初始化方法,初始化必要的变量和参数
- 定义前向传播模块
1.2 线性回归的实现
import torch
import torch.nn as nn
class LinearModel(nn.Module):
def __init__(self, ndim):
super(LinearModel, self).__init__()
self.ndim = ndim#输入的特征数
self.weight = nn.Parameter(torch.randn(ndim, 1)) # 定义权重
self.bias = nn.Parameter(torch.randn(1)) # 定义偏置
def forward(self, x):
# 定义线性模型 y = Wx + b
return x.mm(self.weight) + self.bias
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 定义权重和偏置self.weight和self.bias。采用标准正态分布torch.randn进行初始化。
- self.weight和self.bias是模型的参数,使用nn.Parameter包装,表示将这些初始化的张量转换为模型的参数。只有参数才可以进行优化(被优化器访问到)
实例化方法如下:
lm = LinearModel(5) # 定义线性回归模型,特征数为5
x = torch.randn(4, 5) # 定义随机输入,迷你批次大小为4
lm(x) # 得到每个迷你批次的输出
- 1
- 2
- 3
- 使用model.named_parameters()或者model.parameters()获取模型参数的生成器。区别是前者包含参数名和对应的张量值,后者只含有张量值。
- 优化器optimzer直接接受参数生成器作为参数,反向传播时根据梯度来优化生成器里的所有张量。
- model.train()的作用是启用 Batch Normalization 和 Dropout。model.eval()的作用是不启用 Batch Normalization 和 Dropout。
- named_buffers和buffers获取张量的缓存(不参与梯度传播但是会被更新的参数,例如BN的均值和方差)register_buffers可以加入这种张量
- 使用apply递归地对子模块进行函数应用(可以是匿名函数lambda)
对于model.train()和model.eval()用法和区别进一步可以参考:《Pytorch:model.train()和model.eval()用法和区别》
对于上面定义的线性模型来举例:
lm.named_parameters() # 获取模型参数(带名字)的生成器 #<generator object Module.named_parameters at 0x00000279A1809510> list(lm.named_parameters()) # 转换生成器为列表 [('weight', Parameter containing: tensor([[-1.0407], [ 0.0427], [ 0.4069], [-0.7064], [-1.1938]], requires_grad=True)), ('bias', Parameter containing: tensor([-0.7493], requires_grad=True))] lm.parameters() # 获取模型参数(不带名字)的生成器 list(lm.parameters()) # 转换生成器为列表 [Parameter containing: tensor([[-1.0407], [ 0.0427], [ 0.4069], [-0.7064], [-1.1938]], requires_grad=True), Parameter containing: tensor([-0.7493], requires_grad=True)] lm.cuda()#模型参数转到GPU上 list(lm.parameters()) # 转换生成器为列表

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
-
model.train()是保证BN层能够用到每一批数据的均值和方差。对于Dropout,model.train()是在训练中随机去除神经元,用一部分网络连接来训练更新参数。如果被删除的神经元(叉号)是唯一促成正确结果的神经元。一旦我们移除了被删除的神经元,它就迫使其他神经元训练和学习如何在没有被删除神经元的情况下保持准确。这种dropout提高了最终测试的性能,但它对训练期间的性能产生了负面影响,因为网络是不全的
-
在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变(model.eval()时,框架会自动把BN和Dropout固定住,不会取平均,直接使用在训练阶段已经学出的mean和var值)
二、损失函数
pytorch损失函数有两种形式:
- torch.nn.functional调用的函数形式.传入神经网络预测值和目标值来计算损失函数
- torch.nn库里面的模块形式。新建模块的实例,调用模块化方法计算
最后输出的是标量,对一个批次的损失函数的值有两种归约方式:求和和求均值。
- 回归问题一般调用torch.nn.MSEloss模块。使用默认参数创建实例,输出的是损失函数对一个batch的均值。
import torch
import torch.nn as nn
mse = nn.MSELoss() # 初始化平方损失函数模块
#class torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
t1 = torch.randn(5, requires_grad=True) # 随机生成张量t1
tensor([ 0.6582, 0.0529, -0.9693, -0.9313, -0.7288], requires_grad=True)
t2 = torch.randn(5, requires_grad=True) # 随机生成张量t2
tensor([ 0.8095, -0.3384, -0.9510, 0.1581, -0.1863], requires_grad=True)
mse(t1, t2) # 计算张量t1和t2之间的平方损失函数
tensor(0.3315, grad_fn=<MseLossBackward>)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 二分类问题:
- 使用 torch.nn.BCELoss二分类交叉熵损失函数。输出的是损失函数的均值。接受两个张量。前一个是正分类标签的概率值(预测值必须经过 nn.Sigmoid()输出概率),后者是二分类标签的目标数据值(1是正分类)。两个都必须是浮点类型。
- torch.nn.BCEWithLogitsLoss:自动在损失函数内部实现sigmoid函数的功能,可以增加计算的稳定性。因为概率接近0或1的时候,二分类交叉熵损失函数接受的对数部分容易接近无穷大,造成数值不稳定。使用torch.nn.BCEWithLogitsLoss可以避免此种情况
t1s = torch.sigmoid(t1)
t2 = torch.randint(0, 2, (5, )).float() # 随机生成0,1的整数序列,并转换为浮点数
bce=torch.nn.BCELoss()
(t1s, t2) # 计算二分类的交叉熵
bce_logits = nn.BCEWithLogitsLoss() # 使用交叉熵对数损失函数
bce_logits(t1, t2) # 计算二分类的交叉熵,可以发现和前面的结果一致
- 1
- 2
- 3
- 4
- 5
- 6
- 多分类问题
- torch.nn.NLLLoss:负对数损失函数,计算之前预测值必须经过softmax函数输出概率值( torch.nn.functional.log_softmax或torch.nn.LogSoftmax(dim=dim)函数)
- torch.nn.CrossEntropyLoss:交叉熵损失函数,内部已经整合softmax输出概率,不需要再另外对预测值进行softmax计算。
N=10 # 定义分类数目
t1 = torch.randn(5, N, requires_grad=True) # 随机产生预测张量
t2 = torch.randint(0, N, (5, )) # 随机产生目标张量
t1s = torch.nn.functional.log_softmax(t1, -1) # 计算预测张量的LogSoftmax
nll = nn.NLLLoss() # 定义NLL损失函数
nll(t1s, t2) # 计算损失函数
ce = nn.CrossEntropyLoss() # 定义交叉熵损失函数
ce(t1, t2) # 计算损失函数,可以发现和NLL损失函数的结果一致
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
三、优化器
更多学习率优化器和调度器参考《torch.optim官方文档》
3.1.1 SGD优化器
以波士顿房价问题举例,构建SGD优化器。第一个参数是模型的参数生成器(lm.parameters()调用),第二个参数是学习率。训练时通过 optim.step()进行优化计算。
from sklearn.datasets import load_boston boston = load_boston() lm = LinearModel(13) criterion = nn.MSELoss() optim = torch.optim.SGD(lm.parameters(), lr=1e-6) # 定义优化器 data = torch.tensor(boston["data"], requires_grad=True, dtype=torch.float32) target = torch.tensor(boston["target"], dtype=torch.float32) for step in range(10000): predict = lm(data) # 输出模型预测结果 loss = criterion(predict, target) # 输出损失函数 if step and step % 1000 == 0 : print("Loss: {:.3f}".format(loss.item())) optim.zero_grad() # 清零梯度 loss.backward() # 反向传播 optim.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
torch.optim.SGD(params,lr=<required parameter>,momentum=0,
dampening=0,weight_decay=0,nesterov=False)
#momentum:动量因子
#dampening:动量抑制因子
#nesterov:设为True时使用nesterov动量
- 1
- 2
- 3
- 4
- 5
- 6
3.1.2 Adagrad优化器
torch.optim.Adagrad(
params,lr=0.01,lr_decay=0,weight_decay=0,
initial_accumulator_value=0,eps=1e-10)
#lr_decay:学习率衰减速率
#weight_decay:权重衰减
#initial_accumulator_value:梯度初始累加值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.2 分层学习率
对不同参数指定不同的学习率:
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
- 1
- 2
- 3
- 4
这意味着model.base的参数将使用 的默认学习率1e-2, model.classifier的参数将使用 的学习率1e-3,0.9所有参数将使用动量 。
3.3 学习率调度器torch.optim.lr_scheduler
更多学习率优化器和调度器参考《torch.optim官方文档》
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
#没经过30的个迭代周期,学习率降为原来的0.1倍。每个epoch之后学习率都会衰减。
or epoch in range(100):
train(...)
validate(...)
scheduler.step()
- 1
- 2
- 3
- 4
- 5
- 6
大多数学习率调度器都可以称为背靠背(也称为链式调度器)。结果是每个调度器都被一个接一个地应用于前一个调度器获得的学习率。
例子:
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler1 = ExponentialLR(optimizer, gamma=0.9)
scheduler2 = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler1.step()
scheduler2.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
四 、数据加载torch.utils.data
本节也可以参考《编写transformers的自定义pytorch训练循环(Dataset和DataLoader解析和实例代码)》
4.1 DataLoader参数
PyTorch 数据加载实用程序的核心是torch.utils.data.DataLoader 类。它代表一个 Python 可迭代的数据集,支持:
- map类型和可迭代类型数据集
- 自定义数据加载顺序
- 自动batching
- 单进程和多进程数据加载
train_loader = DataLoader(dataset=train_data, batch_size=6, shuffle=True ,num_workers=4)
test_loader = DataLoader(dataset=test_data, batch_size=6, shuffle=False,num_workers=4)
- 1
- 2
下面看看dataloader代码:
class DataLoader(object):
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None,*, prefetch_factor=2,persistent_workers=False)
self.dataset = dataset
self.batch_size = batch_size
self.num_workers = num_workers
self.collate_fn = collate_fn
self.pin_memory = pin_memory
self.drop_last = drop_last
self.timeout = timeout
self.worker_init_fn = worker_init_fn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- dataset:Dataset类,PyTorch已有的数据读取接口,决定数据从哪里读取及如何读取;
- batch_size:批大小;默认1
- num_works:是否多进程读取数据;默认0使用主进程来导入数据。大于0则多进程导入数据,加快数据导入速度
- shuffle:每个epoch是否乱序;默认False。输入数据的顺序打乱,是为了使数据更有独立性,但如果数据是有序列特征的,就不要设置成True了。一般shuffle训练集即可。
- drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据;
- collate_fn:将得到的数据整理成一个batch。默认设置是False。如果设置成True,系统会在返回前会将张量数据(Tensors)复制到CUDA内存中。
- batch_sampler,批量采样,和batch_size、shuffle等参数是互斥的,一般采用默认None。batch_sampler,但每次返回的是一批数据的索引(注意:不是数据),应该是每次输入网络的数据是随机采样模式,这样能使数据更具有独立性质。所以,它和一捆一捆按顺序输入,数据洗牌,数据采样,等模式是不兼容的。
- sampler,默认False。根据定义的策略从数据集中采样输入。如果定义采样规则,则洗牌(shuffle)设置必须为False。
- pin_memory,内存寄存,默认为False。在数据返回前,是否将数据复制到CUDA内存中。
- timeout,是用来设置数据读取的超时时间的,但超过这个时间还没读取到数据的话就会报错。
- worker_init_fn(数据类型 callable),子进程导入模式,默认为Noun。在数据导入前和步长结束后,根据工作子进程的ID逐个按顺序导入数据。
想用随机抽取的模式加载输入,可以设置 sampler 或 batch_sampler。如何定义抽样规则,可以看sampler.py脚本,或者这篇帖子:《一文弄懂Pytorch的DataLoader, DataSet, Sampler之间的关系》
4.2 两种数据集类型
DataLoader 构造函数最重要的参数是dataset,它表示要从中加载数据的数据集对象。PyTorch 支持两种不同类型的数据集:
- map-style datasets:映射类型数据集。每个数据有一个对应的索引,通过输入具体的索引,就可以得到对应的数据
其构造方法如下:
class Dataset(object):
def __getitem__(self, index):
# index: 数据缩索引(整数,范围为0到数据数目-1)
# ...
# 返回数据张量
def __len__(self):
# 返回数据的数目
# ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
主要重写两个方法:
- __getitem__:python内置的操作符方法,对应索引操作符[]。通过输入整数索引,返回具体某一条数据。具体的内部逻辑根据数据集类型决定
- __len__:返回数据总数
更具体的可以参考《torch.utils.data.Dataset》
- iterable-style datasets:可迭代数据集:实现__iter__()协议的子类的实例。不需要__getitem__和__len__方法,其实类似python的迭代器
- 不同于映射,索引之间相互独立。多线程载入时,多线程独立分配索引。迭代中索引右前后关系,需要考虑如何分割数据。
- 这种类型的数据集特别适用于随机读取代价高昂甚至不可能的情况,以及批量大小取决于获取的数据的情况。
- 在调用iter(dataset)时可以返回从数据库、远程服务器甚至实时生成的日志中读取的数据流
class MyIterableDataset(torch.utils.data.IterableDataset): def __init__(self, start, end): super(MyIterableDataset).__init__() assert end > start, \ "this example code only works with end >= start" self.start = start self.end = end def __iter__(self): worker_info = torch.utils.data.get_worker_info() if worker_info is None: # 单进程数据载入 iter_start = self.start iter_end = self.end else: # 多进程,分割数据 #根据不同工作进程序号worker_id,设置不同进程数据迭代器取值范围。保证不同进程获取不同的迭代器。 per_worker = int(math.ceil((self.end - self.start) \ / float(worker_info.num_workers))) worker_id = worker_info.id iter_start = self.start + worker_id * per_worker iter_end = min(iter_start + per_worker, self.end) return iter(range(iter_start, iter_end))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
更多详细信息,请参阅IterableDataset
4.3 数据加载顺序和 Sampler
- 对于iterable-style datasets,数据加载顺序完全由用户定义的 iterable 控制。这允许更容易地实现块读取和动态批量大小(例如,通过每次产生批量样本)。
- map 类型数据,torch.utils.data.Sampler 类用于指定数据加载中使用的索引/键的序列。它们表示数据集索引上的可迭代对象。例如,在随机梯度下降 (SGD) 的常见情况下,Sampler可以随机排列索引列表并一次产生一个,或者为小批量 SGD 产生少量索引。
将根据shufflea的参数自动构建顺序或混洗采样器DataLoader。或者,用户可以使用该sampler参数来指定一个自定义Sampler对象,该对象每次都会生成下一个要获取的索引/键。
一次Sampler生成批量索引列表的自定义可以作为batch_sampler参数传递。也可以通过batch_size和 drop_last参数启用自动批处理。
4.4 批处理和collate_fn
经由参数 batch_size,drop_last和batch_sampler,DataLoader支持批处理数据
当启用自动批处理时,每次都会使用数据样本列表调用 collate_fn。预计将输入样本整理成一个批次,以便从数据加载器迭代器中产生。
例如,如果每个数据样本由一个 3 通道图像和一个完整的类标签组成,即数据集的每个元素返回一个元组 (image, class_index),则默认 collate_fn 将此类元组的列表整理成单个元组一个批处理图像张量和一个批处理类标签张量。特别是,默认 collate_fn 具有以下属性:
-
它总是预先添加一个新维度作为批次维度。
-
它会自动将 NumPy 数组和 Python 数值转换为 PyTorch 张量。
-
它保留了数据结构,例如,如果每个样本是一个字典,它输出一个具有相同键集但批量张量作为值的字典(如果值不能转换为张量,则为列表)。列表 s、元组 s、namedtuple s 等也是如此。
用户可以使用自定义 collate_fn 来实现自定义批处理,例如,沿着除第一个维度之外的维度进行整理,填充各种长度的序列,或添加对自定义数据类型的支持。
五、模型的保存和加载
5.1 模块、张量的序列化和反序列化
- PyTorch模块和张量本质是torch.nn.Module和torch.tensor类的实例。PyTorch自带了一系列方法, 可以将这些类的实例转化成字成串。所以这些实例可以通过Python序列化方法进行序列化和反序列化。
- 张量的序列化: 本质上是把张量的信息,包括数据类型和存储位置、以及携带的数据,转换为字符串,然后使用Python自带的文件IO函数进行存储。当然也是这个过程是可逆的。
torch.save(obj, f, pickle_module=pickle, pickle_protocol=2)
torch.load(f, map_location=None, pickle_module=pickle, **pickle_load_args)
- 1
- 2
-
torch.save参数
- pytorch中可以被序列化的对象,包括模型和张量
- 存储文件路径
- 序列化的库,默认pickle
- pickle协议,版本0-4
-
torch.load函数
- 文件路径
- 张量存储位置的映射(默认CPU,也可以是GPU)
- pickle参数,和save时一样。
如果模型保存在GPU中,而加载的当前计算机没有GPU,或者GPU设备号不对,可以使用map_location=‘cpu’。
PyTorch默认有两种模型保存方式:
- 保存模型的实例
- 保存模型的状态字典state_dict:state_dict包含模型所有参数名和对应的张量,通过调用load_state_dict可以获取当前模型的状态字典,载入模型参数。
5.2 state_dict保存模型参数
torch.save(model.state_dict(), PATH)
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()
- 1
- 2
- 3
- 4
- 保存模型状态字典state_dict :只保存模型学习到的参数,与模块关联较小,即不依赖版本。
- PyTorch 中最常见的模型保存使‘.pt’或者是‘.pth’作为模型文件扩展名
- 在运行推理之前,务必调用 model.eval() 去设置 dropout 和 batch normalization 层为评
估模式。如果不这么做,可能导致 模型推断结果不一致
5.2 保存/加载完整模型
以 Python `pickle 模块的方式来保存模型。这种方法的缺点是:
- 序列化数据受 限于某种特殊的类而且需要确切的字典结构。当在其他项目使用或者重构之后,您的代码可能会以各种方式中断。
- PyTorch模块的实现依赖于具体的版本。所依一个版本保存的模块序列化文件,在另一个版本可能无法载入。
torch.save(model, PATH)
# 模型类必须在此之前被定义
model = torch.load(PATH)
model.eval()
- 1
- 2
- 3
- 4
5.3 Checkpoint 用于推理/继续训练
- 在训练时,不仅要保存模型相关的信息,还要保存优化器相关的信息。因为可能要从检查点出发,继续训练。所以可以保存优化器本身的状态字典,存储包括当前学习率、调度器等信息。
- 最新记录的训练损失,外部的 torch.nn.Embedding 层等等都可以保存。
- PyTorch 中常见的保存checkpoint 是使用 .tar 文件扩展名。
- 要加载项目,首先需要初始化模型和优化器,然后使用 torch.load() 来加载本地字典
一个模型的检查点代码如下:
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
...
}, PATH)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
加载
model = TheModelClass(*args, **kwargs)
optimizer = TheOptimizerClass(*args, **kwargs)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval()#或model.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
或者是:
save_info = { # 保存的信息
"iter_num": iter_num, # 迭代步数
"optimizer": optimizer.state_dict(), # 优化器的状态字典
"model": model.state_dict(), # 模型的状态字典
}
# 保存信息
torch.save(save_info, save_path)
# 载入信息
save_info = torch.load(save_path)
optimizer.load_state_dict(save_info["optimizer"])
model.load_state_dict(sae_info["model"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
5.4 在一个文件中保存多个模型
torch.save({
'modelA_state_dict': modelA.state_dict(),
'modelB_state_dict': modelB.state_dict(),
'optimizerA_state_dict': optimizerA.state_dict(),
'optimizerB_state_dict': optimizerB.state_dict(),
...
}, PATH)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
加载
modelA = TheModelAClass(*args, **kwargs)
modelB = TheModelBClass(*args, **kwargs)
optimizerA = TheOptimizerAClass(*args, **kwargs)
optimizerB = TheOptimizerBClass(*args, **kwargs)
checkpoint = torch.load(PATH)
modelA.load_state_dict(checkpoint['modelA_state_dict'])
modelB.load_state_dict(checkpoint['modelB_state_dict'])
optimizerA.load_state_dict(checkpoint['optimizerA_state_dict'])
optimizerB.load_state_dict(checkpoint['optimizerB_state_dict'])
modelA.eval()
modelB.eval()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
当保存一个模型由多个 torch.nn.Modules 组成时,例如GAN(对抗生成网络)、sequence-to-sequence (序列到序列模型), 或者是多个模 型融合, 可以采用与保存常规检查点相同的方法。换句话说,保存每个模型的 state_dict 的字典和相对应的优化器。如前所述,可以通 过简单地将它们附加到字典的方式来保存任何其他项目,这样有助于恢复训练。
六、TensorBoard的安装和使用
参考《PyTorch学习笔记(九) ---- 使用 TensorBoard 可视化模型,数据和训练》
TensorBoard安装:
pip install tensorflow-tensorboard
pip install tensorboard
- 1
- 2
安装完之后import tensorboard时报错ImportError: TensorBoard logging requires TensorBoard version 1.15 or above试了几种方法。最后关掉ipynb文件,新建一个ipynb文件复制代码运行就好了。
6.1 TensorBoard详解
TensorBoard是分为前段显示和后端数据记录的,因此其Pipeline也分为两步:
后端数据记录:TensorBoard中把后端服务器抽象成了一个类:SummaryWriter。声明之后就会开启后端数据记录的服务。
- 实例化SummaryWriter
#从tensorboard构造一个摘要写入器SummaryWriter。
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
- 1
- 2
- 3
参数解析如下:
class SummaryWriter(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')log_dir (str):指定了数据保存的文件夹的位置,不存在则创建。- 没指定时,默认的保存的文件夹是./runs/现在的时间_主机名,例如:Feb04_22-42-47_Alienware。
- 每次运行之后都会创建一个新的文件夹。有时候从不同的角度来调整模型,因此最好不要用默认log文件夹,而是使用具有含义的二级结构,例如:runs/exp1。
comment (string):给默认的log_dir添加的后缀,如果我们已经指定了log_dir具体的值,那么这个参数就不会有任何的效果purge_step (int):- 可视化数据不是实时写入,而是有个队列。积累的数据超过队列限制的时候,触发数据文件写入。如果写入的可视化数据崩溃,purge_step步数之后的数据将会被舍弃。
- 例如在某一个epoch中,进行到第T + X 个step的时候由于各种原因(内存溢出)导致崩溃,那么当服务重启之后,就会从T个step重新开始将数据写入文件,而中间的X ,即purge_step指定的step内的数据都被被丢弃。
max_queue (int):在记录数据的时候,在内存中开的队列的长度,当队列满了之后就会把数据写入磁盘(文件)中。flush_secs (int):表示写入tensorboard文件的时间间隔(s),默认是120秒,即两分钟。filename_suffix (string):添加到log_dir中每个文件的后缀,默认为空。更多文件名称设置要参考tensorboard.summary.writer.event_file_writer.EventFileWriter类。
-
添加数据。实例化SummaryWriter类使用实例化方法添加数据,这些方法都以add_开头,例如:add_scalar、add_scalars、add_image……具体来说,所有的方法有:
- add_scalar,add_scalars:添加标量数据,比如loss、acc等
- add_histogram:添加直方图
- add_graph():创建Graphs,Graphs中存放了网络结构
- 其它方法
这些方法有共同的参数:


-
前端查看数据
tensorboard-logdir./run:启动tensorboard服务器。默认端口6006。访问http://127.0.0.1:6006可以看到tensorboard网页界面。writer.close()可关闭服务
6.2 TensorBoard使用示例
也可参考yolov5教程,里面有使用tensorboard和clearML。
from sklearn.datasets import load_boston from torch.utils.tensorboard import SummaryWriter import torch import torch.nn as nn #定义线性回归模型 class LinearModel(nn.Module): def __init__(self, ndim): super(LinearModel, self).__init__() self.ndim = ndim self.weight = nn.Parameter(torch.randn(ndim, 1)) # 定义权重 self.bias = nn.Parameter(torch.randn(1)) # 定义偏置 def forward(self, x): # 定义线性模型 y = Wx + b return x.mm(self.weight) + self.bias boston = load_boston() lm = LinearModel(13) criterion = nn.MSELoss() optim = torch.optim.SGD(lm.parameters(), lr=1e-6) data = torch.tensor(boston["data"], requires_grad=True, dtype=torch.float32) target = torch.tensor(boston["target"], dtype=torch.float32) writer = SummaryWriter() # 构造摘要生成器,定义TensorBoard输出类 for step in range(10000): predict = lm(data) loss = criterion(predict, target) writer.add_scalar("Loss/train", loss, step) # 输出损失函数 writer.add_histogram("Param/weight", lm.weight, step) # 输出权重直方图 writer.add_histogram("Param/bias", lm.bias, step) # 输出偏置直方图 if step and step % 1000 == 0 : print("Loss: {:.3f}".format(loss.item())) optim.zero_grad() loss.backward() optim.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
colab上加载tensorboard:
%load_ext tensorboard
%tensorboard --logdir runs/swin_s
- 1
- 2
也可在命令行调用:
# 打开cmd命令
tensorboard --logdir=.\Chapter2\runs --bind_all
#TensorBoard 2.2.2 at http://DESKTOP-OHLNREI:6006/ (Press CTRL+C to quit)
- 1
- 2
- 3
6.3 常用API
SummaryWriter添加数据的API都以add_开头,具体有:
- 标量类:add_scalar、add_scalars、add_custom_scalars、add_custom_scalars_marginchart、add_custom_scalars_multilinechart、
- 数据显示类:
- 图像:add_image、add_images、add_image_with_boxes、add_figure
- 视频:add_video
- 音频:add_audio
- 文本:add_text
- Embedding:add_embedding
- 点云:add_mesh
- 统计图:add_histogram、add_histogram_raw、add_pr_curve、add_pr_curve_raw
- 网络图:add_onnx_graph、add_graph
- 超参数图:add_hparams
6.3.1 add_scalar()和add_scalars()写入标量
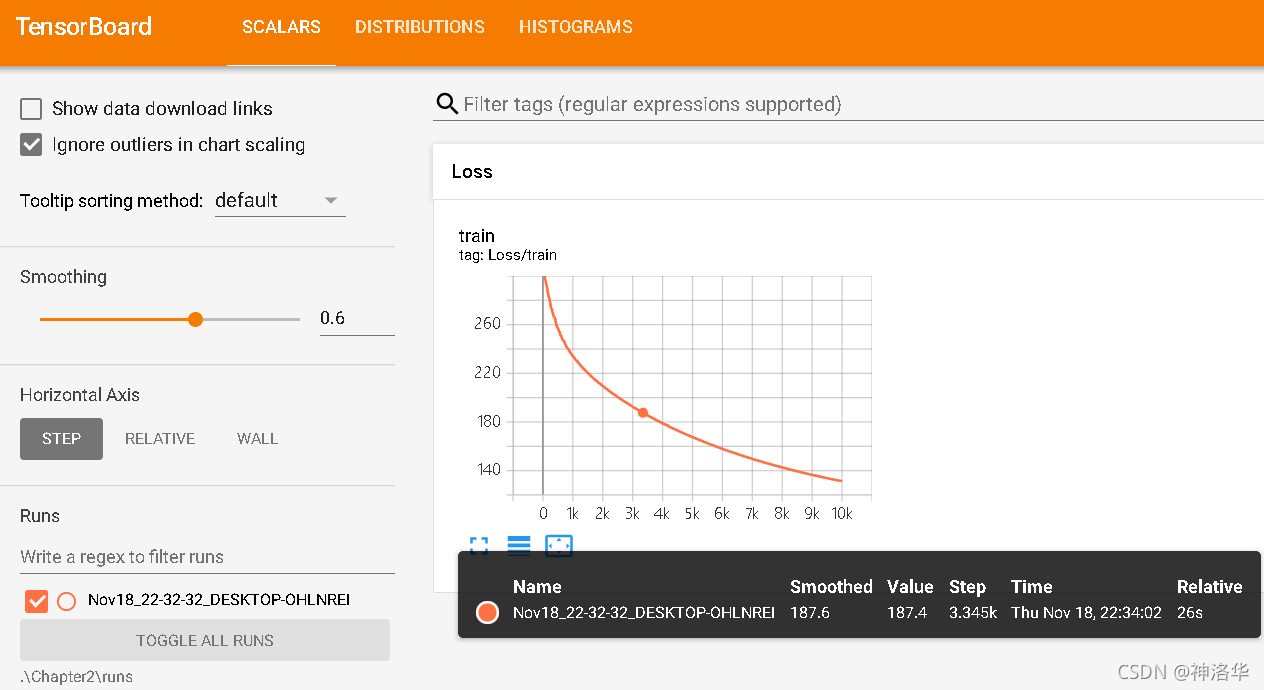
- add_scalar()
add_scalar(tag, scalar_value, global_step=None, walltime=None)
- 1
于在tensorboard中加入loss,其中常用参数有:
- tag:不同图表的标签,如下图所示的Train_loss。
- scalar_value:标签的值,浮点数
- global_step:当前迭代步数,标签的x轴坐标
- walltime:迭代时间函数。如果不传入,方法内部使用time.time()返回一个浮点数代表时间
writer.add_scalar('Train_loss', loss, (epoch*epoch_size + iteration))
- 1
- add_scalars()
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
- 1
和上一个方法类似,通过传入一个主标签(main_tag),然后传入键值对是标签和标量值的一个字典(tag_scalar_dict),对每个标量值进行显示。
6.3.2 add_histogram()写入直方图
显示张量分量的直方图和对应的分布
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
- 1
- bins:产生直方图的方法,可以是tensorflow、auto、fd
- max_bins:最大直方图分段数
6.3.3 add_graph 写入计算图
传入pytorch模块及输入,显示模块对应的计算图
- model:pytorch模型
- input_to_model:pytorch模型的输入
if Cuda:
graph_inputs = torch.from_numpy(np.random.rand(1,3,input_shape[0],input_shape[1])).type(torch.FloatTensor).cuda()
else:
graph_inputs = torch.from_numpy(np.random.rand(1,3,input_shape[0],input_shape[1])).type(torch.FloatTensor)
writer.add_graph(model, (graph_inputs,))
- 1
- 2
- 3
- 4
- 5
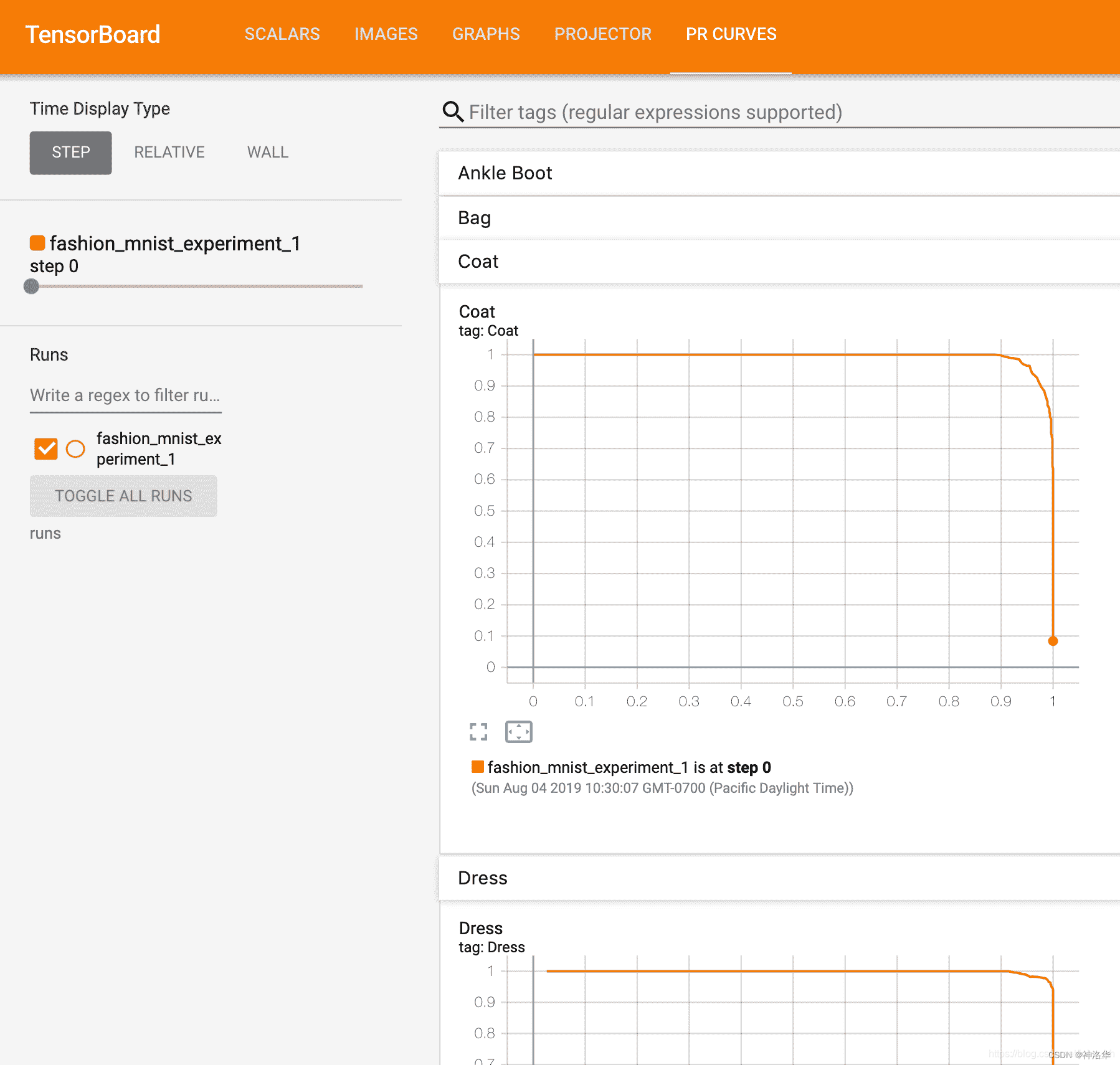
6.3.4 add_pr_curve查看每个类别的P-R曲线
显示准确率-召回率曲线(Prediction-Recall Curve)。
add_pr_curve(tag, labels, predictions, global_step=None, num_thresholds=127,
weights=None, walltime=None)
- 1
- 2
- labels:目标值
- predictions:预测值
- num_thresholds:曲线中间插值点数
- weights:每个点的权重
# 1\. gets the probability predictions in a test_size x num_classes Tensor # 2\. gets the preds in a test_size Tensor # takes ~10 seconds to run class_probs = [] # 预测概率 class_preds = [] # 预测类别标签 with torch.no_grad(): for data in testloader: images, labels = data output = net(images) class_probs_batch = [F.softmax(el, dim=0) for el in output] _, class_preds_batch = torch.max(output, 1) class_probs.append(class_probs_batch) class_preds.append(class_preds_batch) test_probs = torch.cat([torch.stack(batch) for batch in class_probs]) test_preds = torch.cat(class_preds) # helper function def add_pr_curve_tensorboard(class_index, test_probs, test_preds, global_step=0): ''' Takes in a "class_index" from 0 to 9 and plots the corresponding precision-recall curve ''' tensorboard_preds = test_preds == class_index tensorboard_probs = test_probs[:, class_index] writer.add_pr_curve(classes[class_index], tensorboard_preds, tensorboard_probs, global_step=global_step) writer.close() # plot all the pr curves for i in range(len(classes)): add_pr_curve_tensorboard(i, test_probs, test_preds)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
现在,您将看到一个“ PR Curves”选项卡,其中包含每个类别的精度回召曲线。 继续戳一下; 您会发现在某些类别中,模型的“曲线下面积”接近 100%,而在另一些类别中,该面积更低:
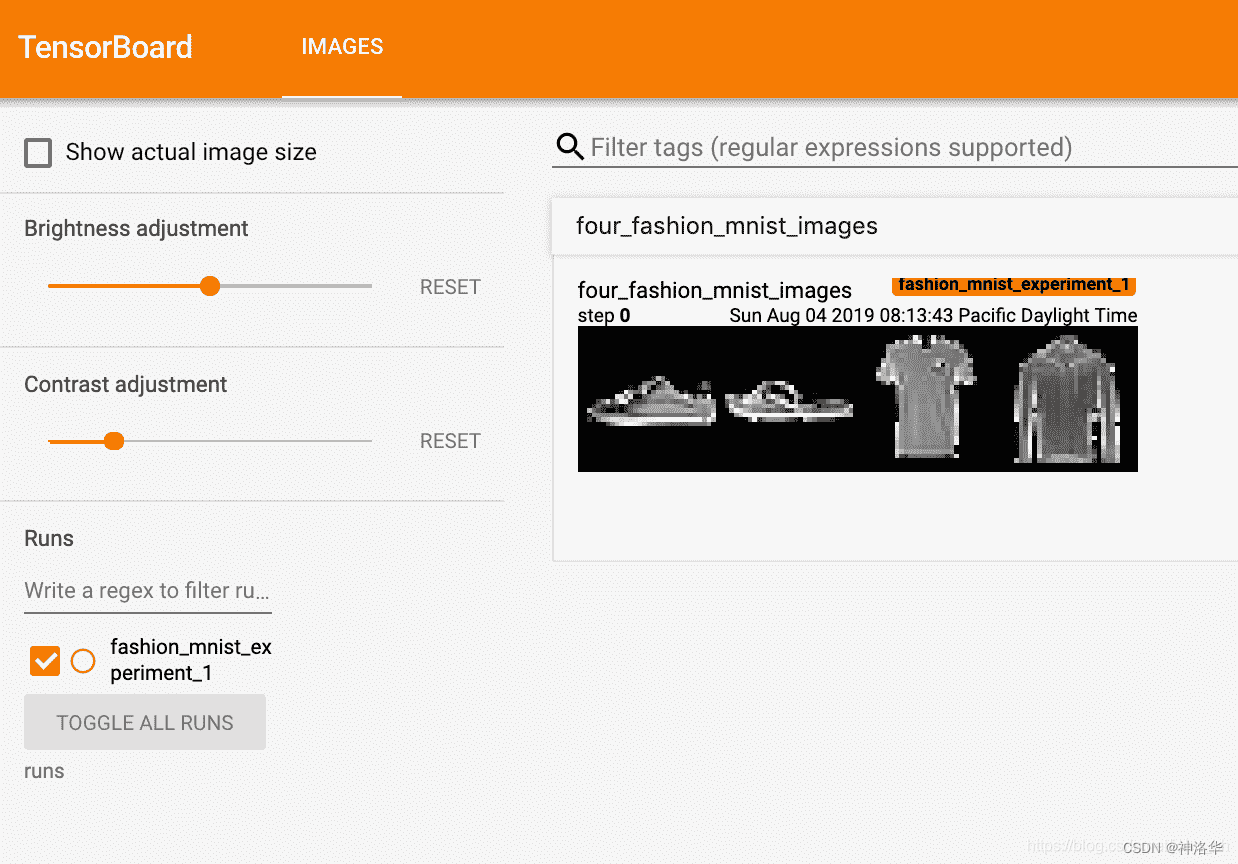
6.3.5 add_image写入图片
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# create grid of images
img_grid = torchvision.utils.make_grid(images)
# show images
matplotlib_imshow(img_grid, one_channel=True)
# write to tensorboard
writer.add_image('four_fashion_mnist_images', img_grid)
tensorboard --logdir=runs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
6.3.6 修改端口
有的时候,在服务器上训练模型的时候为了避免和别人的TensorBoard的端口撞了,我们需要指定新的端口。或者有的时候我们在docker容器里跑TensorBoard,我们通过一个端口映射到主机上去,这个时候就需要指定TensorBoard使用特定的端口。格式为:tensorboard --logdir=数据文件夹 --port=端口。例如:
tensorboard --logdir=./Feb05_01-00-48_Alienware/ --port=10000
- 1
6.3.7 对比多次运行曲线
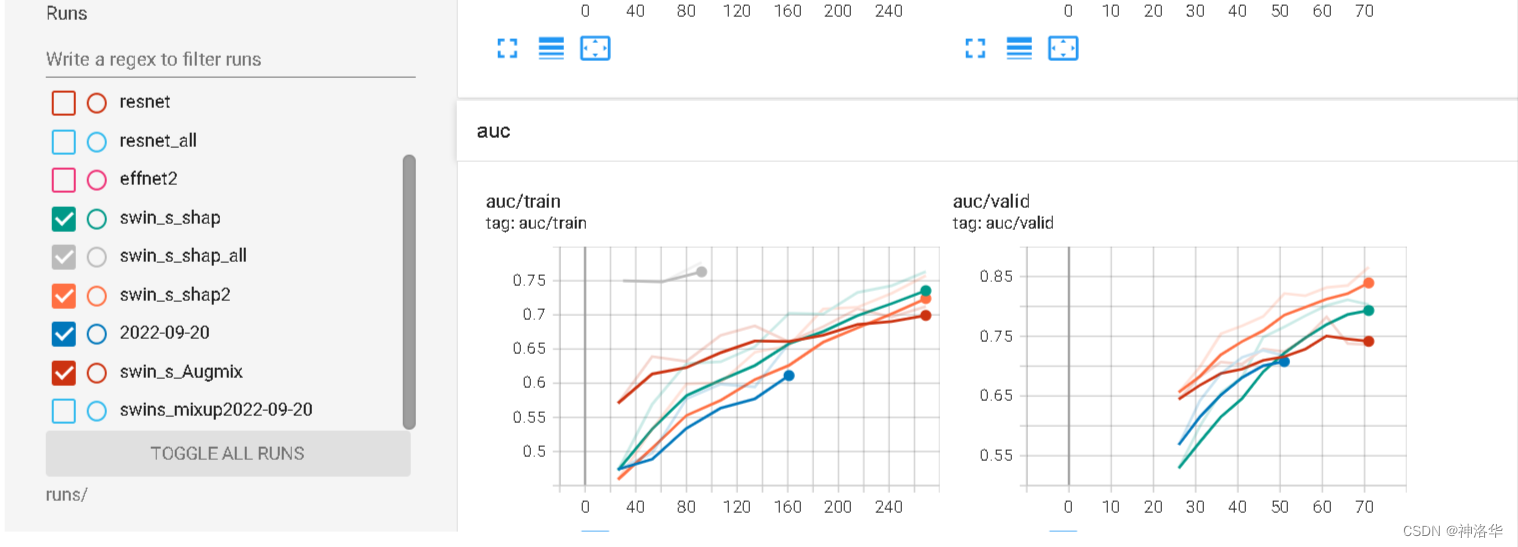
- 自己跑的时候,需要试验各种超参数来找出最优组合。每次跑一行行看各种loss、acc曲线是比较累,效果也不好。TensorBoard可以加载多次运行结果进行对比一目了然。
- 需要注意的是,如果log日志在一个文件夹,其它日志的曲线只显示为背景,也无法筛选,所以每次运行得选择不同的log_dir。而同一个模型也会跑多次,光以模型名命名也不行,所以考虑加入时间
save_name=swins_mixup # 代表swin_transformer模型的S Type(一共有T、S、L三种模型大小),以及数据增强用了Mixup
board_time = "{0:%Y-%m-%dT%H-%M-%S/}".format(datetime.now())
comment=f'save_nmae={save_name} lr={lr} transforms={transforms}' # 这个写了好像没啥用
writer = SummaryWriter(log_dir='runs/'+save_name+board_time,comment=comment)
- 1
- 2
- 3
- 4
运行
%load_ext tensorboard
%tensorboard --logdir runs/
- 1
- 2
下图那些背景现就是同一个文件夹的不同log文件显示的曲线。所以说要对比,log日志不能在一个文件夹。
6.4 使用 TensorBoard 检查模型架构
TensorBoard 的优势之一是其可视化复杂模型结构的能力。 让我们可视化我们构建的模型。
writer.add_graph(net, images)
writer.close()
- 1
- 2
现在刷新 TensorBoard 后,您应该会看到一个“ Graphs”标签,如下所示:
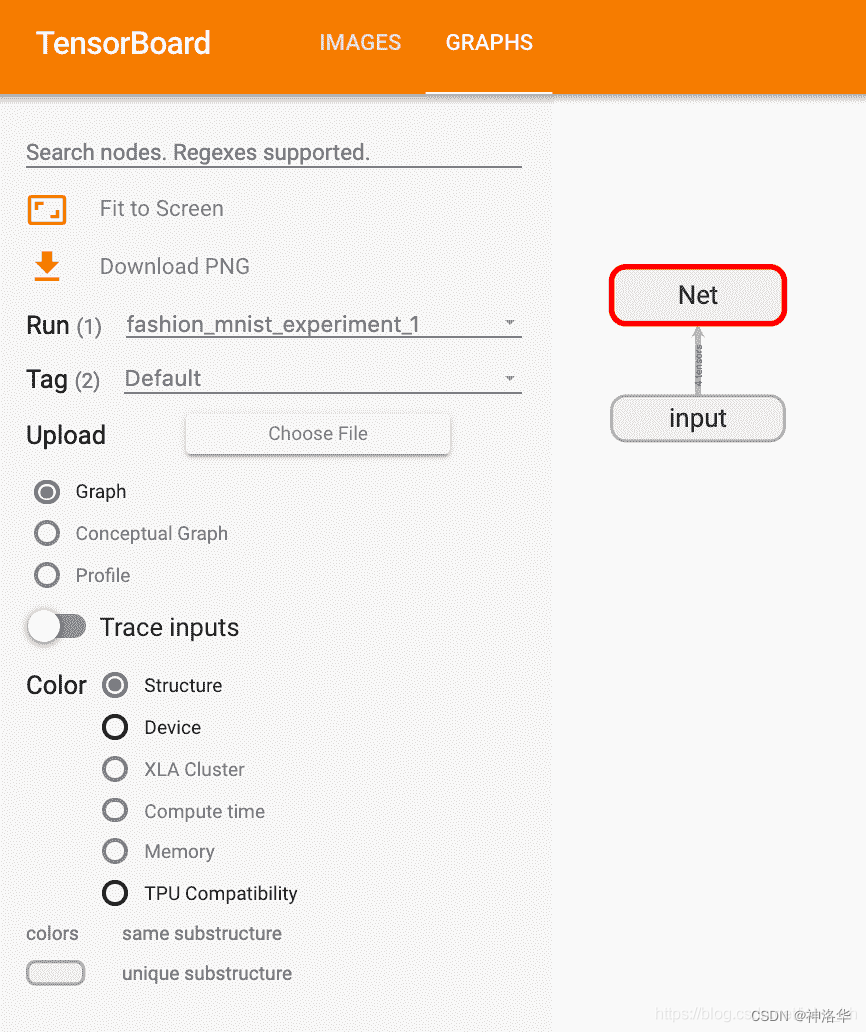
继续并双击“ Net”以展开它,查看组成模型的各个操作的详细视图。
6.5 add_embedding 可视化高维数据的低维表示
TensorBoard 具有非常方便的功能,可在低维空间中可视化高维数据,例如图像数据; 接下来我们将介绍。
# helper function def select_n_random(data, labels, n=100): ''' Selects n random datapoints and their corresponding labels from a dataset ''' assert len(data) == len(labels) perm = torch.randperm(len(data)) return data[perm][:n], labels[perm][:n] # select random images and their target indices images, labels = select_n_random(trainset.data, trainset.targets) # get the class labels for each image class_labels = [classes[lab] for lab in labels] # log embeddings features = images.view(-1, 28 * 28) writer.add_embedding(features, metadata=class_labels, label_img=images.unsqueeze(1)) writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
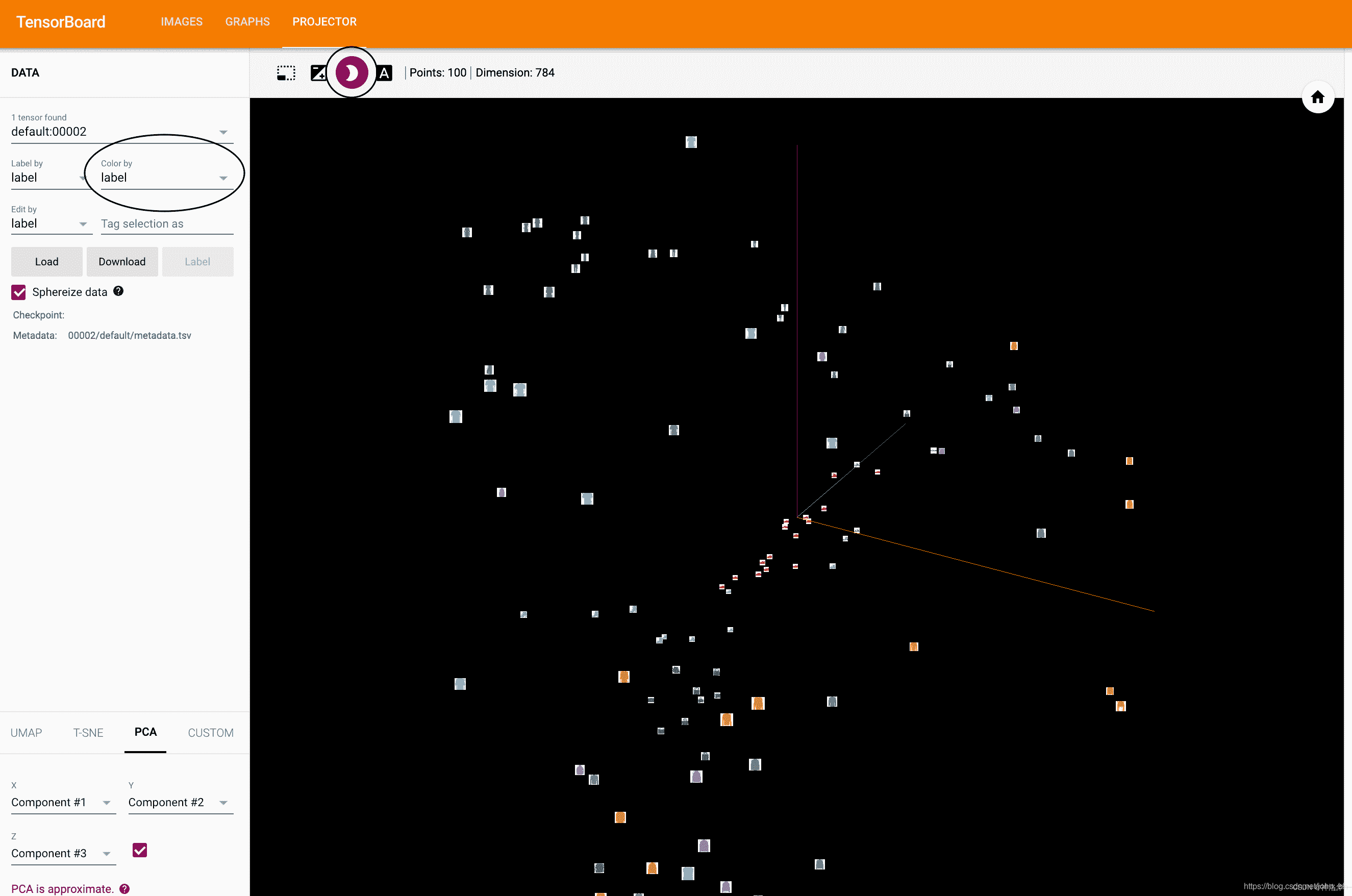
现在,在 TensorBoard 的“投影仪”选项卡中,您可以看到这 100 张图像-每个图像 784 维-向下投影到三维空间中。 此外,这是交互式的:您可以单击并拖动以旋转三维投影。 最后,有两个技巧可以使可视化效果更容易看到:在左上方选择“颜色:标签”,并启用“夜间模式”,这将使图像更容易看到,因为它们的背景是白色的:
6.6 跟踪训练,并通过plot_classes_preds函数查看模型预测
# helper functions def images_to_probs(net, images): ''' Generates predictions and corresponding probabilities from a trained network and a list of images ''' output = net(images) # convert output probabilities to predicted class _, preds_tensor = torch.max(output, 1) preds = np.squeeze(preds_tensor.numpy()) return preds, [F.softmax(el, dim=0)[i].item() for i, el in zip(preds, output)] def plot_classes_preds(net, images, labels): ''' Generates matplotlib Figure using a trained network, along with images and labels from a batch, that shows the network's top prediction along with its probability, alongside the actual label, coloring this information based on whether the prediction was correct or not. Uses the "images_to_probs" function. ''' preds, probs = images_to_probs(net, images) # plot the images in the batch, along with predicted and true labels fig = plt.figure(figsize=(12, 48)) for idx in np.arange(4): ax = fig.add_subplot(1, 4, idx+1, xticks=[], yticks=[]) matplotlib_imshow(images[idx], one_channel=True) ax.set_title("{0}, {1:.1f}%\n(label: {2})".format( classes[preds[idx]], probs[idx] * 100.0, classes[labels[idx]]), color=("green" if preds[idx]==labels[idx].item() else "red")) return fig
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
在训练过程中,我们将生成一幅图像,显示该批次中包含的四幅图像的模型预测与实际结果。
running_loss = 0.0 for epoch in range(1): # loop over the dataset multiple times for i, data in enumerate(trainloader, 0): # get the inputs; data is a list of [inputs, labels] inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() if i % 1000 == 999: # every 1000 mini-batches... # ...log the running loss writer.add_scalar('training loss', running_loss / 1000, epoch * len(trainloader) + i) # ...log a Matplotlib Figure showing the model's predictions on a # random mini-batch writer.add_figure('predictions vs. actuals', plot_classes_preds(net, inputs, labels), global_step=epoch * len(trainloader) + i) running_loss = 0.0 print('Finished Training')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
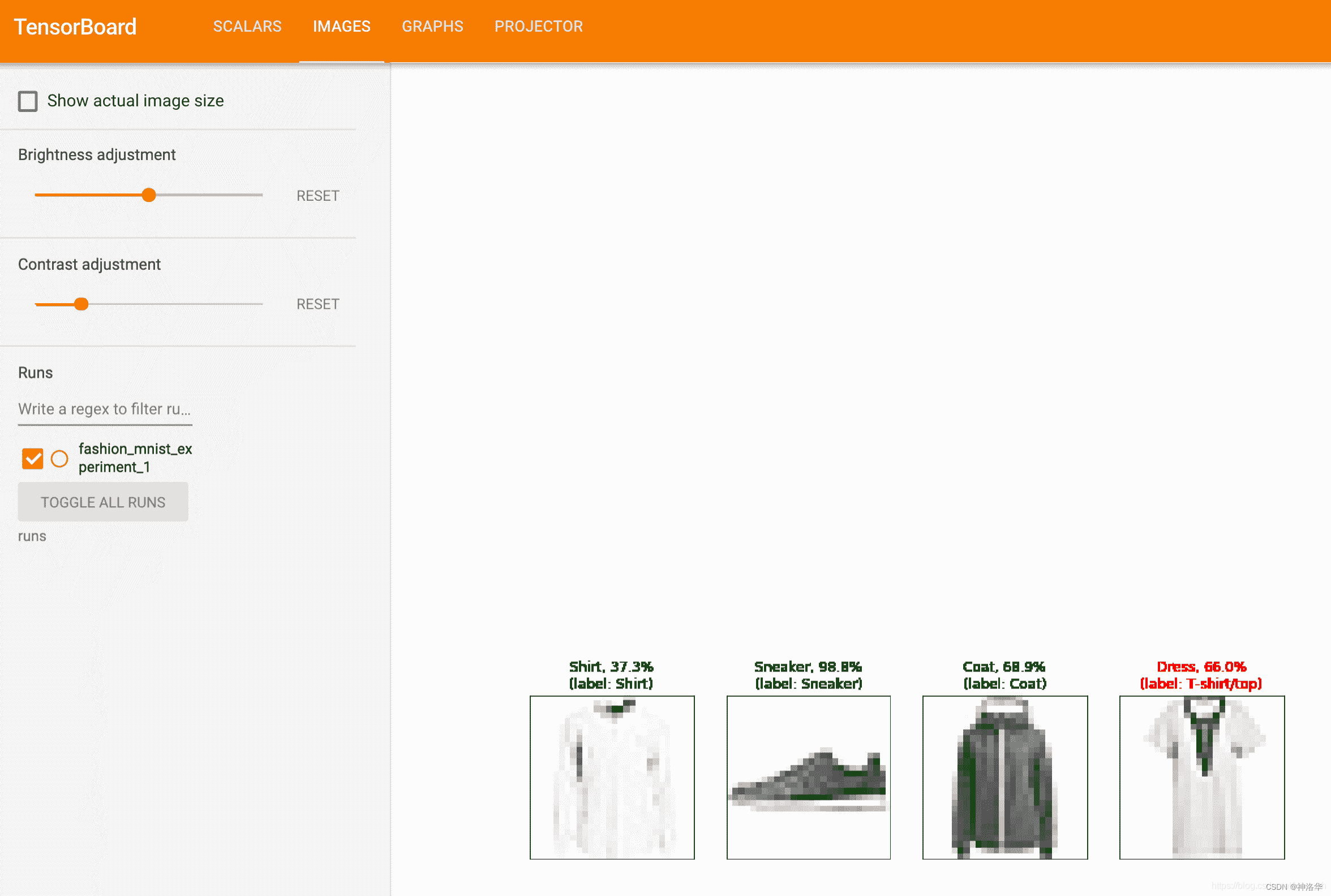
我们可以查看整个学习过程中模型在任意批次上所做的预测。 查看“图像”选项卡,然后在“预测与实际”可视化条件下向下滚动以查看此内容; 这向我们表明,例如,仅经过 3000 次训练迭代,该模型就能够区分出视觉上截然不同的类,例如衬衫,运动鞋和外套
6.7 tensorboard界面简介
右上方三个依次是:
- SCALARS:损失函数图像
- DISTRIBUTIONS:权重分布(随时间)
- HISTOGRAMS:权重直方图分布
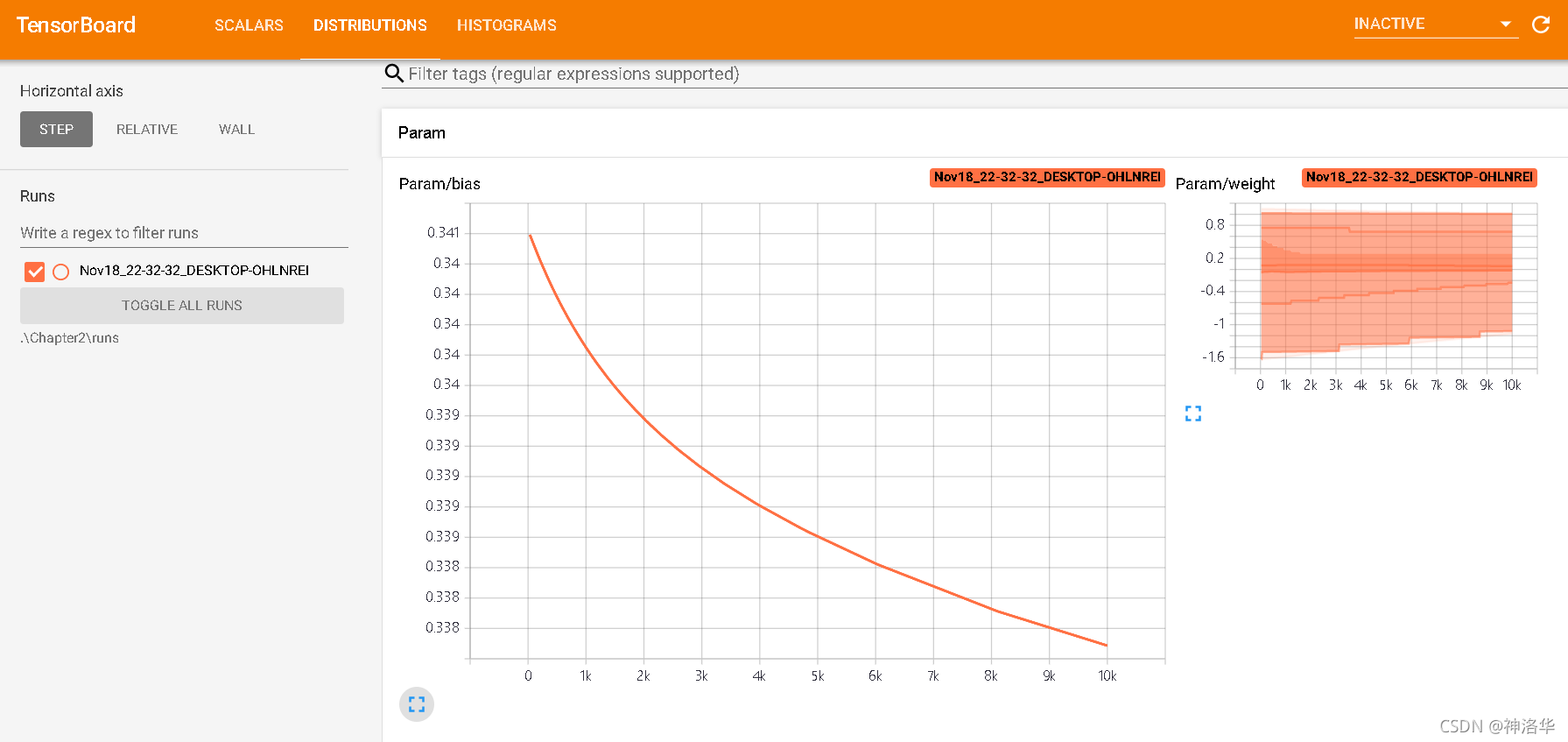
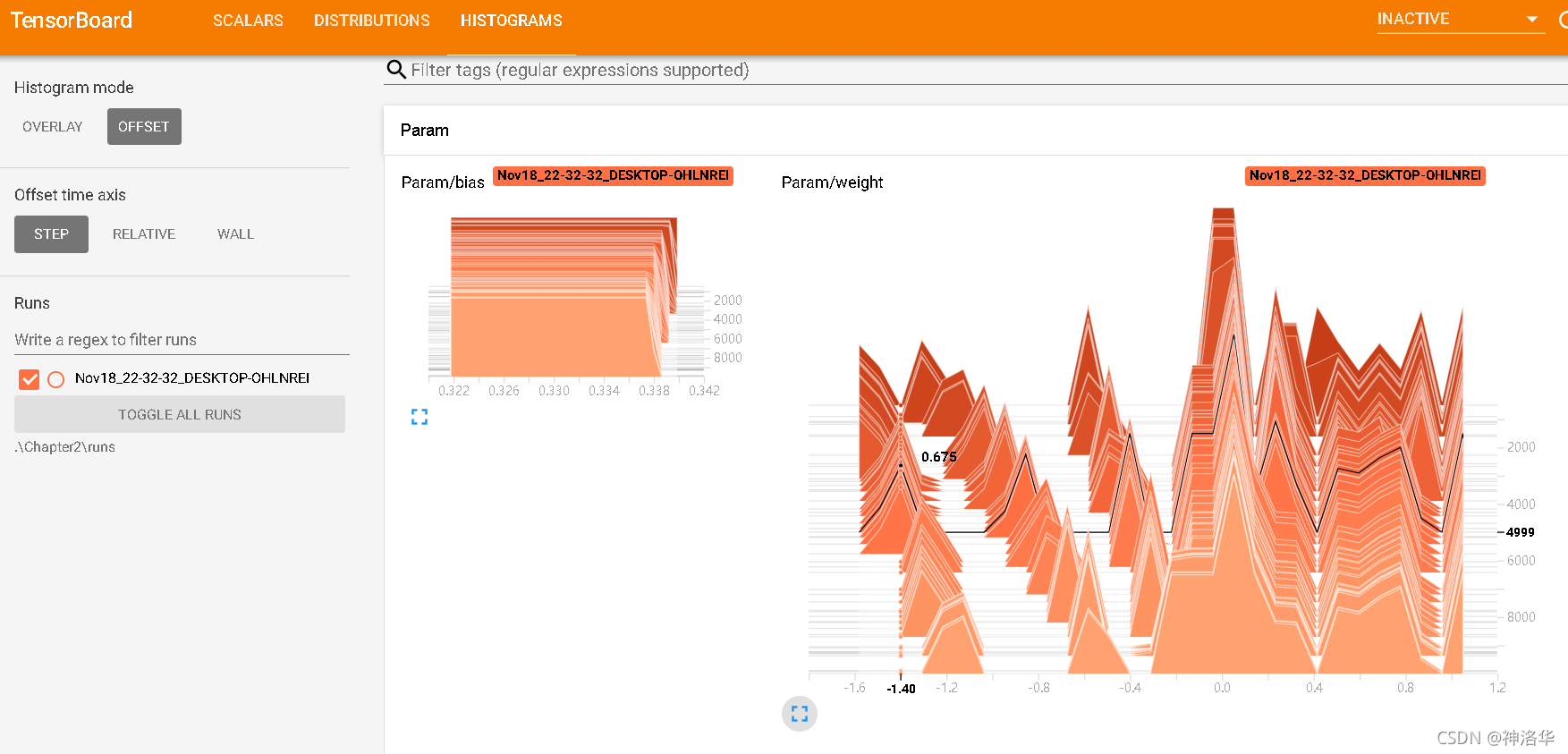
权重分布和直方图应该是随着训练一直变化,直到分布稳定。如果一直没有变化,可能模型结构有问题或者反向传播有问题。
Scalars:这个面板是最常用的面板,主要用于将神经网络训练过程中的acc(训练集准确率)val_acc(验证集准确率),loss(损失值),weight(权重)等等变化情况绘制成折线图。
- Ignore outlines in chart scaling(忽略图表缩放中的轮廓),可以消除离散值
- data downloadlinks:显示数据下载链接,用来下载图片
- smoothing:图像的曲线平滑程度,值越大越平滑。每个mini-batch的loss不一定下降,smoothing越大时,代表平均的mini-batch越多。
- Horizontal Axis:水平轴表示方式。
- STEP:表示迭代次数
- RELATIVE:表示按照训练集和测试集的相对值
- WALL:表示按照时间。
七、图像转换与增广
7.1 AUGMIX
参考《AUGMIX:A SIMPLE DATA PROCESSING METHOD TO IMPROVE ROBUSTNESS AND UNCERTA》

最新提出的数据增广方法有,如上图:
- CutOut:随机在图片上找一个矩形区域丢掉。
- MixUp:将两张图片按照一定比率进行像素融合,融合后的图带有两张图片的标签
- CutMix:与CutOut类似,不同的地方是将这个矩形区域填充为另一张图片的像素,本人亲测,稳定有涨点!
- AugMix:将一张原图进行变换、旋转、多色调3个分支的并行操作,然后按照一定比例融合,最后与原图按照一定比率融合,操作如下图:
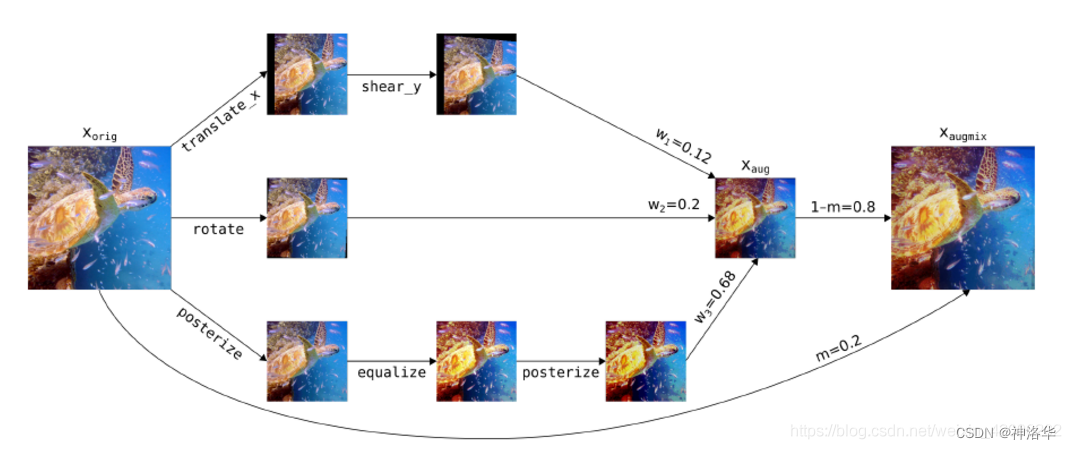
大概流程就是对原图进行k个数据增广操作,然后使用k个权重进行融合得到aug图像。最终与原图进行一定比率融合得到最终augmix图像。论文中使用Jensen-Shannon Divergence Consistency Loss这个损失函数,用来计算augmix后图像与原图的JS散度,需要保证augmix图像与原图的相似性。
7.2 mixup
Mixup实现:
!pip install torchtoolbox
from torchtoolbox.tools import mixup_data, mixup_criterion
alpha = 0.2
for i, (data, labels) in enumerate(train_data):
data = data.to(device, non_blocking=True)
labels = labels.to(device, non_blocking=True)
data, labels_a, labels_b, lam = mixup_data(data, labels, alpha)
optimizer.zero_grad()
outputs = model(data)
loss = mixup_criterion(Loss, outputs, labels_a, labels_b, lam)
loss.backward()
optimizer.update()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
7.3 cutout/ArcLoss, CosLoss, L2Softmax
from torchvision import transforms
from torchtoolbox.transform import Cutout
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
Cutout(),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(0.4, 0.4, 0.4),
transforms.ToTensor(),
normalize,
])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
from torchtoolbox.nn.loss import ArcLoss, CosLoss, L2Softmax
- 1

