
- 1算法—链表操作
- 22023年第十四届蓝桥杯省赛Python大学B组真题解析_蓝桥杯pythonb组松散子序列的代码分析
- 3AVL树_avl tree全称
- 4API请求报错 Required request body is missing_required request body is missing: public com.jhict
- 5springboot--跨域_springboot什么是跨域问题
- 6NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE-论文翻译
- 7【FPGA】xilinx Vivado UART IP核使用_fpga uartlite ip
- 8IVX低代码平台开发——微信小程序实现抽奖功能_ivx官网
- 9uniapp首次进入App应用提示授权照片和文件权限,关闭授权提示_手机app上传图片显示权限关闭
- 10BUUCTF-[极客大挑战 2019]PHP1_[极客大挑战 2019]php 1
从RAD-NeRF到实时对话数字人:环境配置与源码详解“_er-nerf 数字人 镜像
赞
踩
随着人工智能技术的飞速发展,实时对话虚拟数字人demo成为了热门话题。本文将详细解析这个demo所使用的技术,并探讨其未来的应用前景。
一、引言
实时对话虚拟数字人demo是一种能够实时与用户进行对话的虚拟形象。通过先进的AI技术,这个demo能够理解用户的语言,并给出自然的回应。在本文中,我们将深入探讨这个demo所涉及的关键技术,以及如何实现它们。
二、核心技术解析
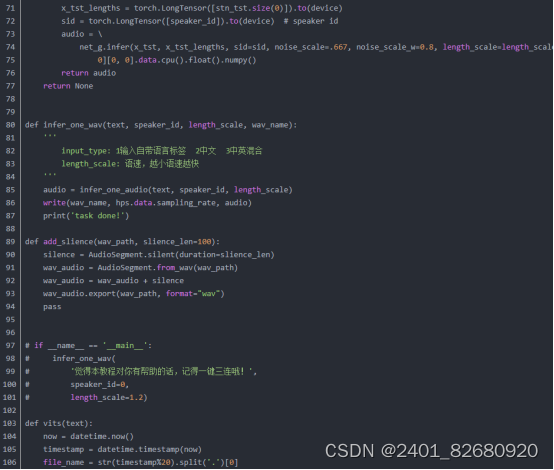
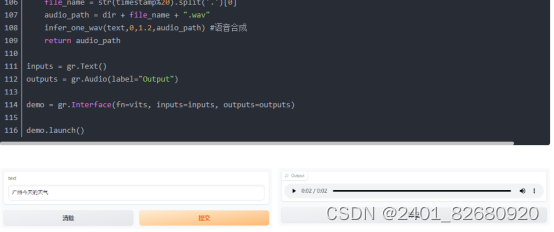
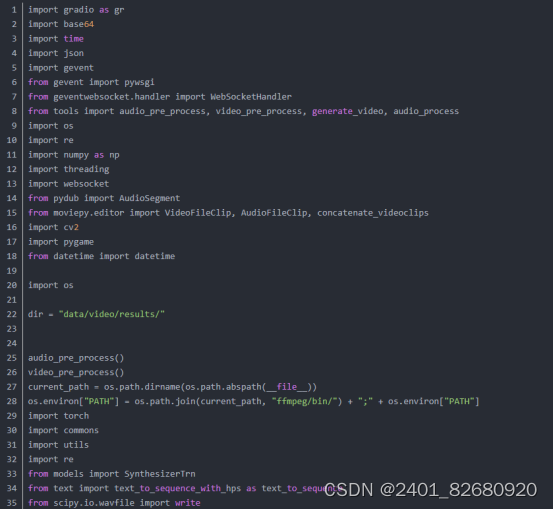
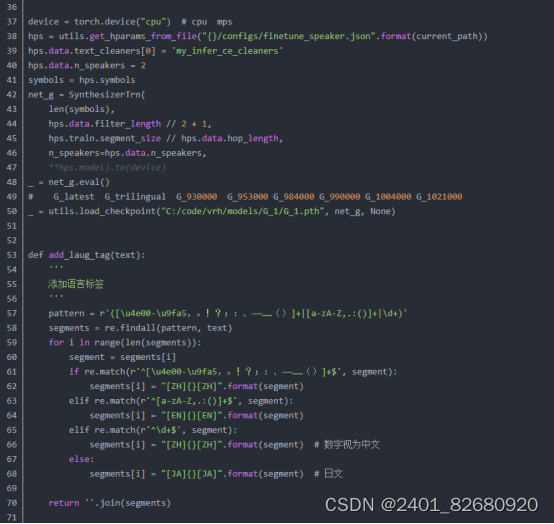
4.把项目git下来后,我们试试用VITS做个语音合成,这里使用gradio来辅助创建个demo。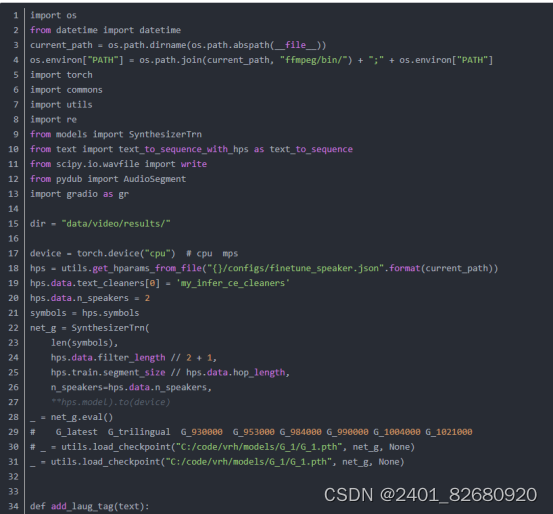

- NeRF技术:NeRF是一种用于从多视角图像中生成3D场景的方法。通过训练神经网络,NeRF能够将2D图像转换为3D场景,为虚拟数字人提供了逼真的动态效果。
- VITS语音合成技术:VITS是一种基于Transformer的语音合成技术。它能够将文本转换为高质量的语音,为用户提供流畅的语音交互体验。
- ChatGLM2-6B语言模型:ChatGLM2-6B是一种基于Transformer的语言模型,具有60亿参数。它能够进行自然语言理解与生成,使虚拟数字人能够进行智能对话。
- 声音克隆技术:声音克隆是一种能够从少量数据中快速训练语音模型的技术。通过声音克隆技术,我们可以为虚拟数字人提供个性化的语音风格。

语音合成
1.VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种结合变分推理(variational inference)、标准化流(normalizing flows)和对抗训练的高表现力语音合成模型。VITS通过隐变量而非频谱串联起来语音合成中的声学模型和声码器,在隐变量上进行随机建模并利用随机时长预测器,提高了合成语音的多样性,输入同样的文本,能够合成不同声调和韵律的语音。
2.声学模型是声音合成系统的重要组成部分:

-
它使用预先训练好的语音编码器 (vocoder声码器) 将文本转化为语音。
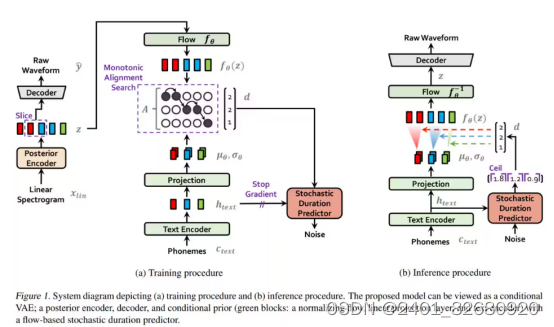
3.VITS 的工作流程如下:
将文本输入 VITS 系统,系统会将文本转化为发音规则。将发音规则输入预先训练好的语音编码器 (vocoder),vocoder 会根据发音规则生成语音信号的特征表示。将语音信号的特征表示输入预先训练好的语音合成模型,语音合成模型会根据特征表示生成合成语音。VITS 的优点是生成的语音质量较高,能够生成流畅的语音。但是,VITS 的缺点是需要大量的训练语料来训练 vocoder 和语音合成模型,同时需要较复杂的训练流程。
合成视频
1.RAD-NeRF是可以对视频中所出现的说话者进行实时的人像合成。它是一种基于神经网络从一组二维图像重建三维体景。
RAD-NeRF使用一个网络来预测正在可视化的相机视点的所有像素颜色和密度,当镜头围绕主题旋转时,想要显示的所有视点都是这样做的,这是非常需要计算力的,因为在每次学习预测图像中每个坐标的多个参数。此外,在这种情况下,这不仅仅是一个NeRF产生一个3D场景。还必须匹配音频输入,使嘴唇、嘴巴、眼睛和动作与人说的话相匹配。
网络不再预测所有像素的密度和颜色与特定帧的音频相匹配,而是使用两个独立的新压缩空间,称为网格空间,或基于网格的NeRF。再将坐标转换成较小的3D网格空间,将音频转换成较小的2D网格空间,然后将其发送到渲染头部。这意味着网络永远不会将音频数据与空间数据合并在一起,这将以指数方式增加大小,为每个坐标添加二维输入。因此,减少音频特征的大小,同时保持音频和空间特征的分离,将使这种方法更加有效。
但是,如果使用包含较少信息的压缩空间,结果如何会才能更好呢?在NeRF中添加一些可控制的特征,如眨眼控制,与以前的方法相比,模型将学习更真实的眼睛行为。这对能还原更加真实的人尤其重要。

RAD-NeRF所做的第二个改进(模型概述中的绿色矩形)是使用相同的方法用另一个 NERF 建模躯干,而不是试图用用于头部的相同 NERF 建模躯干,这将需要更少的参数和不同的需求,因为这里的目标是动画移动的头部而不是整个身体。由于躯干在这些情况下是相当静态的,他们使用一个更简单和更有效的基于 NERF 的模块,只在2D 中工作,直接在图像空间中工作,而不是像平时通常使用 NERF 那样使用摄像机光线来产生许多不同的角度,这对躯干来说是不需要的。然后,重新组合头部与躯干,以产生最后的视频。
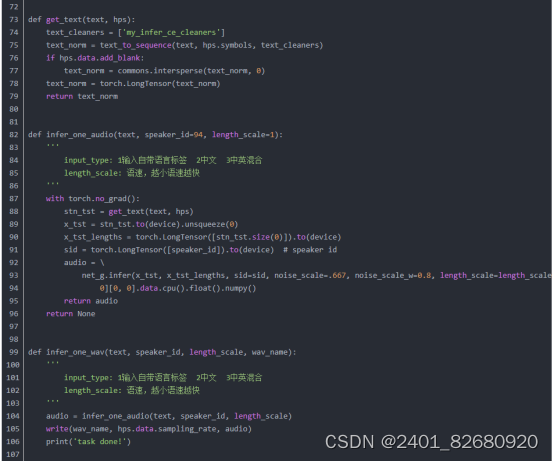
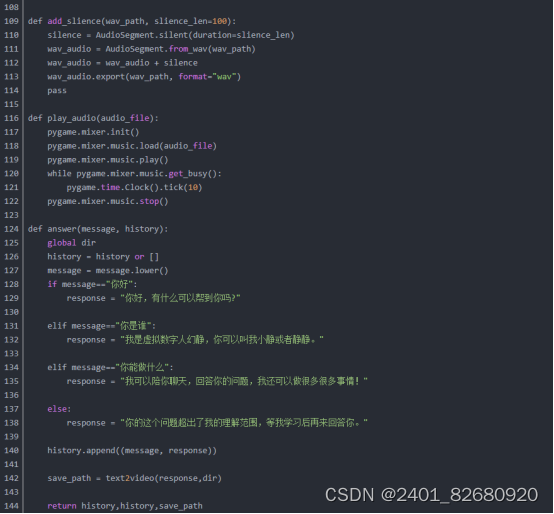
2.当模型训练完之后,只需要data目录下的transforms_train.json文件和微调身体的后的模型文件就可以开始写推理代码了。步骤如下:
输入语音或文字(这里为了方便演示,只写了文字输入的接口)
获取输入的信息,调LLM(大型语文模型)来回答 (该项目当前还没有引入LLM,只写了几句固定的回答,之后有时间会把LLM与本地知识库加上)。
对获取的回答进行语音合成,并生成用于驱动视频的.npy文件。
使用.npy与transforms_train.json里面的数据合成视频,输出
 。
。

源码
1.当前的源码包含了语音合成与视频合成两个模型,环境依赖最难装的部分应该是pytorch3d,这个可以参考我之前的博客:
数字人解决方案——基于真人视频的三维重建数字人源码与训练方法_知来者逆的博客-CSDN博客
2.源码在win10,cuda 11.7,cudnn 8.5,python3.10,conda环境下测试运行成功。源码下载地址:
https://download.csdn.net/download/matt45m/88078575
下载源码后,创建conda环境:

windows下安装pytorch3d,这个依赖还是要在刚刚创建的conda环境里面进行安装。

如果下载pytorch3d很慢,可以使用这个百度网盘下载:链接:https://pan.baidu.com/s/1z29IgyviQe2KQa6DilnRSA 提取码:dm4q
如果安装中间报错退出,这里建议安装vs 生成工具。

