
- 1深入理解SOAP协议:基于XML的分布式通信协议
- 2北京大学&快手发布统一的图文视频生成大模型Video-LaVIT
- 3javaSE基础篇------String,StringBuffer,StringBuilder
- 4P8707 [蓝桥杯 2020 省 AB1] 走方格
- 5..." to discard change" href="/w/花生_TL007/article/detail/458084" target="_blank">Git之git checkout再理解及用法汇总_(use "git checkout --
..." to discard change - 6Windows下部署Appium教程(Android App自动化测试框架搭建)_appium-windows
- 7第二章 单片机的硬件结构_mcs51能够运行的最基本配置是什么
- 8基于Xtrabackup的mysql物理备份详解_xtrabackup --slave-info
- 9【数据结构】排序算法(三)—— 希尔排序_希尔排序法是怎么排的
- 10shiro反序列化检测工具_Shiro rememberMe反序列化攻击检测思路
第2.4章 StarRocks表设计——分区分桶与副本数_starrocks中主键表创建表达式分区
赞
踩
目录
该篇文章介绍StarRocks-2.5.4版本的分区分桶及副本相关内容,有误请指出~
官网文章地址:
一、数据分布
1.1 概述
建表时,通过设置合理的分区和分桶,使数据均衡分布在不同节点上,查询时能够有效裁剪数据扫描量,最大限度的利用集群的并发性能,从而提升查询性能。
1.2 数据分布方式
分布式数据库中常见的数据分布方式有:Round-Robin、Range、List 和 Hash。如下图所示:
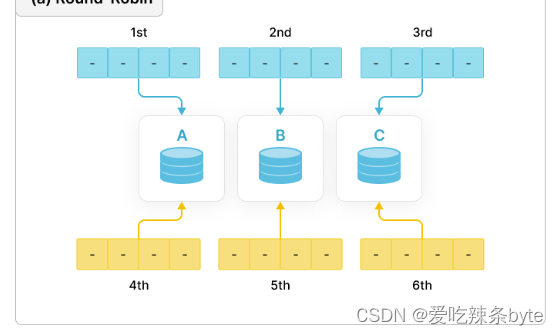
1.2.1 Round-Robin
以轮询的方式把数据逐个放置在相邻节点上。
1.2.2 Range
按照分区进行数据分区,如下图所示,区间[1-3] 、[4-6]分别对应不同的范围(Range)。
适用场景:数据简单有序,并且通常按照连续日期/数值范围来查询和管理数据,range分区是常用的分区方式。

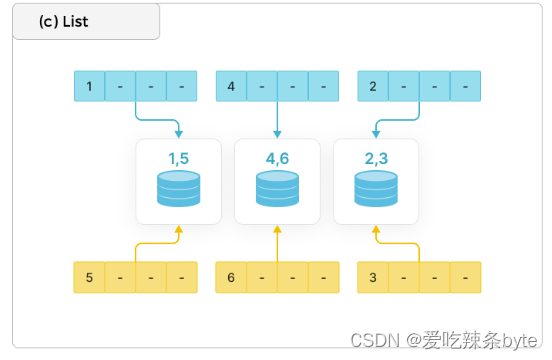
1.2.3 List
直接基于离散的各个取值做数据分布,例如性别,省份等数据就满足这种离散的特性(离散:取值是有限的),每个离散值会映射到一个节点上,多个不同的取值可能也映射到相同节点上。适用场景:按照枚举值来查询和管理数据,比如经常按照国家和城市来查询和管理数据,则可以使用该方式,选择分区列为 city。
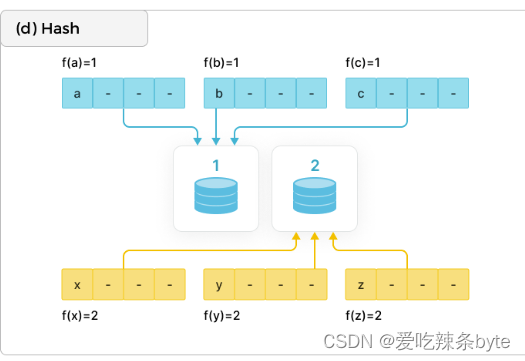
1.2.4 Hash
通过哈希函数把数据映射到不同节点上。
总结:可以根据具体的业务场景需求组合使用这些数据分布方式,常见的组合方式有 Hash+Hash、Range+Hash、Hash+List。
1.3 StarRocks的数据分布方式
StarRocks支持两层的数据划分。第一层是Partition分区,支持Range、List或者不分区(不分区代表全表只有一个分区)。第二层是 Bucket分桶(Tablet),StarRocks-2.5.4版本分桶方式只有Hash哈希分桶。StarRocks常见的两种数据分布方式如下:
1.3.1 不分区+ Hash分桶
概述: 一张表只有一个分区,分区按照分桶键和分桶数量进一步进行数据划分,分桶规则: Hash算法(分桶键)% 分桶数
建表语句:
- #不分区+ Hash分桶,分桶键为site_id
- CREATE TABLE site_access(
- site_id INT DEFAULT '10',
- city_code SMALLINT,
- user_name VARCHAR(32) DEFAULT '',
- pv BIGINT SUM DEFAULT '0'
- )
- AGGREGATE KEY(site_id, city_code, user_name)
- DISTRIBUTED BY HASH(site_id) BUCKETS 10;
1.3.2 Range分区+Hash分桶
概述:一张表拆分成多个分区,每个分区按照分桶键和分桶数量进一步进行数据划分,分桶规则: Hash算法(分桶键)% 分桶数
建表语句:
- #分区键为partition_no,分桶键为cbhtbm:
- create table test.ods_cbht (
- cbhtbm string comment "",
- fbfbm string comment "",
- cbfbm string comment "",
- cbfs string comment "",
- cbqxq datetime comment "",
- cbqxz datetime comment "",
- partition_no bigint comment ""
- ) engine=olap
- duplicate key(cbhtbm)
- comment ""
- partition by range(partition_no) (
- start("110000") end ("160000") every (10000),
- start("210000") end ("240000") every (10000),
- start("310000") end ("380000") every (10000),
- start("410000") end ("470000") every (10000),
- start("500000") end ("550000") every (10000),
- start("610000") end ("660000") every (10000),
- start("710000") end ("720000") every (10000),
- start("810000") end ("830000") every (10000)
- )
- distributed by hash(cbhtbm) buckets 8
- properties (
- "replication_num" = "3",
- "in_memory" = "false",
- "storage_format" = "default"
- );
-

三、分区
3.1 分区概述
逻辑概念,表中数据可以根据分区列(通常是时间和日期)分成一个个更小的数据管理单元。查询时,通过分区裁剪,可以减少扫描的数据量,显著优化查询性能。
(1)分区的主要作用是将一张表按照分区键拆分成不同的管理单元,针对每一个管理单元选择相应的存储策略,比如副本数、分桶数、冷热策略和存储介质等。StarRocks支持在一个集群内使用多种存储介质,将新数据所在分区放在SSD盘上,利用 SSD优秀的随机读写性能来提高查询性能,将旧数据存放在 SATA 盘上,以节省数据存储的成本。
(2)选择合理的分区列可以有效的裁剪查询数据时扫描的数据量。业务系统中⼀般会选择根据时间进行分区,以优化大量删除过期数据带来的性能问题,同时也方便冷热数据分级存储。选择分区单位时需要综合考虑数据量、查询特点、数据粒度等因素。单个分区原始数据量建议维持在100G以内。
- 示例 1:表单月数据量很小,可以按月分区,相比于按天分区,可以减少元数据数量,从而减少元数据管理和调度的资源消耗。
- 示例 2:表单月数据量很大,而大部分查询条件精确到天,如果按天分区,可以做有效的分区裁减,减少查询扫描的数据量。
-
示例 3:数据要求按天过期,可以按天分区。
(3)StarRocks支持手动创建分区、批量创建分区、动态分区
3.2 创建分区
选择合理的分区键可以有效的裁剪扫描的数据量,常见的分区键为时间或者区域,目前支持分区键的数据类型为日期和整数类型。
3.2.1 手动创建分区
- #分区键event_day,类型是DATE
- CREATE TABLE site_access(
- event_day DATE,
- site_id INT DEFAULT '10',
- city_code VARCHAR(100),
- user_name VARCHAR(32) DEFAULT '',
- pv BIGINT SUM DEFAULT '0'
- )
- AGGREGATE KEY(event_day, site_id, city_code, user_name)
- PARTITION BY RANGE(event_day)
- (
- PARTITION p1 VALUES LESS THAN ("2020-01-31"),
- PARTITION p2 VALUES LESS THAN ("2020-02-29"),
- PARTITION p3 VALUES LESS THAN ("2020-03-31")
- )
- DISTRIBUTED BY HASH(site_id) BUCKETS 10;
3.2.2 批量创建分区
-
建表时批量创建日期分区
当分区键为日期类型时,建表时通过 start、end指定批量分区的开始日期和结束日期,every子句指定分区增量值。并且every子句中用 interval关键字表示日期间隔,目前仅支持日期间隔的单位为day、week、month、year。
- #如下,批量分区的开始日期为2021-01-01和结束日期为2021-01-04,增量值为一天:
- create table site_access (
- datekey date,
- site_id int,
- city_code smallint,
- user_name varchar(32),
- pv bigint default '0'
- )
- engine=olap
- duplicate key(datekey, site_id, city_code, user_name)
- partition by range (datekey) (
- start ("2021-01-01") end ("2021-01-04") every (interval 1 day)
- )
- distributed by hash(site_id) buckets 10
- properties (
- "replication_num" = "3"
- );
-
-
- #则相当于在建表语句中使用如下partition by子句:前闭后开
- partition by range (datekey) (
- partition p20210101 values [('2021-01-01'), ('2021-01-02')),
- partition p20210102 values [('2021-01-02'), ('2021-01-03')),
- partition p20210103 values [('2021-01-03'), ('2021-01-04'))
- )
-
建表时批量创建区划分区
当分区键为区域类型时,建表时通过 start、end指定批量分区的开始和结束,every子句指定分区增量值。
- create table test.ods_cbht (
- cbhtbm string comment "",
- fbfbm string comment "",
- cbfbm string comment "",
- cbfs string comment "",
- cbqxq datetime comment "",
- cbqxz datetime comment "",
- partition_no bigint comment ""
-
- ) engine=olap
- duplicate key(cbhtbm)
- comment ""
- partition by range(partition_no) (
- start("110000") end ("160000") every (10000),
- start("210000") end ("240000") every (10000),
- start("310000") end ("380000") every (10000),
- start("410000") end ("470000") every (10000),
- start("500000") end ("550000") every (10000),
- start("610000") end ("660000") every (10000),
- start("710000") end ("720000") every (10000),
- start("810000") end ("830000") every (10000)
- )
- distributed by hash(cbhtbm) buckets 8
- properties (
- "replication_num" = "3",
- "in_memory" = "false",
- "storage_format" = "default"
- );
3.2.3 动态分区
可以按需对新数据动态创建分区,同时 StarRocks 会自动删除过期分区,从而确保数据的实效性,实现对分区的生命周期管理(Time to Life,简称 “TTL”),降低运维管理的成本。详细配置见文章:
四、分桶
4.1 分桶概述
物理概念,同一个分区中的数据通过分桶,划分成更小的数据管理单元。并且分桶以多副本形式(默认为3)均匀分布在 BE 节点上,保证数据的高可用。
分区按照分桶键和分桶数量进一步进行数据划分,一个分区按分桶方式被分成了多个桶 bucket,每个桶的数据称之为一个Tablet。StarRocks一般采用Hash算法作为分桶算法。在同一分区内,分桶键哈希值相同的数据会划分到同一个Tablet(数据分片),Tablet 以多副本冗余的形式存储,是数据均衡和恢复的最⼩单位,数据导入和查询最终都下沉到所涉及的 Tablet 副本上。ps:建表时,如果使用哈希分桶,则必须指定分桶键。
4.2 设置分桶键
4.2.1 哈希分桶
对每个分区的数据,StarRocks会根据分桶键和分桶数量进行哈希分桶。哈希分桶中,使用特定的列值作为输入,通过哈希函数计算出一个哈希值,然后将数据根据该哈希值分配到相应的桶中。
(1)优点
- 提高查询性能。相同分桶键值的行会被分配到一个分桶中,在查询时能减少扫描数据量。
- 均匀分布数据。通过选取较高基数(唯一值的数量较多)的列作为分桶键,能更均匀的分布数据到每一个分桶中。
(2)如何选择分桶键
- 如果查询比较复杂,则建议选择高基数的列为分桶键,保证数据在各个分桶中尽量均衡,提高集群资源利用率。
- 如果查询比较简单,则建议选择经常作为查询条件的列为分桶键,提高查询效率。
如果数据倾斜情况严重,可以使用多个列作为数据的分桶键,但是建议不超过 3 个列。
(3)注意事项
- 建表时,如果使用哈希分桶,则必须指定分桶分桶列
- 分桶列必须为key列,可以为多列
- 分桶列多的适用于低并发高吞吐量场景,因为数据分布在多个桶中,并发查询多个桶,单个查询速度快
- 分桶列少的适用于高并发场景,因为一个查询可能只命中一个桶,多个查询之间查询不同的桶,磁盘的IO影响小,所以并发就高
- 组成分桶键的列仅支持整型、decimal(数值型)、date/datetime(日期型)、char/varchar/string (字符串)数据类型
(4)案例
案例一:假设site_id为高基数列,site_access表采用site_id作为分桶键
- #假设site_id为高基数列,site_access表采用site_id作为分桶键
- create table site_access(
- event_day date,
- site_id int default '10',
- city_code varchar(100),
- user_name varchar(32) default '',
- pv bigint sum default '0'
- )
- aggregate key(event_day, site_id, city_code, user_name)
- partition by range(event_day) (
- partition p1 values less than ("2020-01-31"),
- partition p2 values less than ("2020-02-29"),
- partition p3 values less than ("2020-03-31")
- )
- distributed by hash(site_id);
案例二:如果site_id分布十分不均匀,那么采用上述分桶方式会造成数据分布出现严重的倾斜,进而导致系统局部的性能瓶颈。需要调整分桶的字段,以将数据打散,避免性能问题。 例如,可以采用site_id、city_code组合作为分桶键,将数据划分得更加均匀。
- # 如果site_id分布十分不均匀,那么采用上述分桶方式会造成数据分布出现严重的倾斜,进而导致系统局部的性能瓶颈。需要调整分桶的字段,以将数据打散,避免性能问题。
- # 例如,可以采用site_id、city_code组合作为分桶键,将数据划分得更加均匀。
- create table site_access
- (
- site_id int default '10',
- city_code smallint,
- user_name varchar(32) default '',
- pv bigint sum default '0'
- )
- aggregate key(site_id, city_code, user_name)
- distributed by hash(site_id,city_code);
案例一 采用 site_id的分桶方式对于短查询十分有利,能够减少节点之间的数据交换,提高集群整体性能;案例二 采用 site_id、city_code的组合分桶方式对于长查询有利,能够利用分布式集群的整体并发性能。
短查询是指扫描数据量不大、单机就能完成扫描的查询。
长查询是指扫描数据量大、多机并行扫描能显著提升性能的查询。
4.3 确定分桶数量
4.3.1 建表时
方式一:自动设置分桶数量
自 2.5.7 版本起,支持根据机器资源和数据量自动设置分区中分桶数量。假设 BE 数量为 X,StarRocks 推断分桶数量的策略如下:
X <= 12 tablet_num = 2X
X <= 24 tablet_num = 1.5X
X <= 36 tablet_num = 36
X > 36 tablet_num = min(X, 48)
- create table site_access(
- site_id int default '10',
- city_code smallint,
- user_name varchar(32) default '',
- pv bigint sum default '0'
- )
- aggregate key(site_id, city_code, user_name)
- distributed by hash(site_id,city_code); --无需手动设置分桶数量
-
- # 如果需要开启该功能,配置FE动态参数 enable_auto_tablet_distribution=true。 建表后执行show partitions来查看为分区自动设置的分桶数量。
方式二:手动设置分桶数量
确定分桶数量方式可以是:首先预估每个分区的数据量,然后按照每10 GB原始数据划分一个 Tablet计算,从而确定分桶数量。 单个Tablet的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐。
- -- 手动指定分桶个数的创建语法
- distributed by hash(site_id) buckets 20
4.3.2 建表后
- 新增一个分区时,参照上述的建表分桶设置规则
- 已建分区:已创建分区的分桶数量不能修改
五、建表调优
基于业务实际情况,在设计表结构时选择合理的分区键和分桶键,可以有效提高集群整体性能。
5.1 数据倾斜
如果业务场景中单独采用倾斜度大的列做分桶,很大程度会导致访问数据倾斜,可以采用多列组合的方式进行分桶,将数据打散,使得各Tablet 数据更加均匀。
5.2 高并发
分区和分桶应该尽量覆盖查询语句所带的条件,这样可以有效减少扫描数据,提高并发。
5.3 高吞吐
尽量把数据打散,让集群以更高的并发扫描数据,完成相应计算。
5.4 元数据管理
Tablet 过多会增加 FE/BE 的元数据管理和调度的资源消耗。
六、分区分桶及副本之间的关系
数据库information_schema存储了关于StarRocks实例中所有对象的大量元数据信息。可以在表tables_config查看表的分区、分桶信息。

- 表,分区,分桶以及副本的关系:
Table (逻辑描述) -- > Partition(分区:管理单元) --> Bucket(分桶:每个分桶就是一个数据分片:Tablet,数据划分的最小逻辑单元)
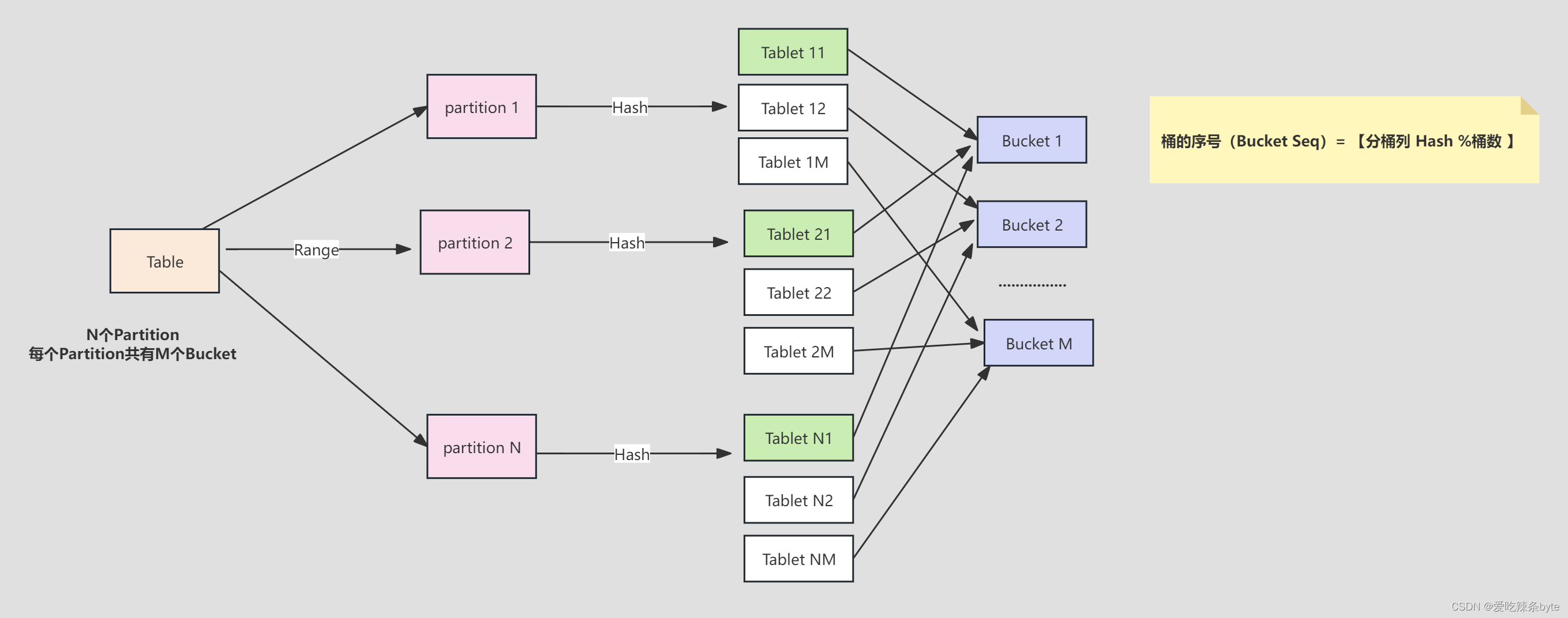
以一个具体的案例说明:
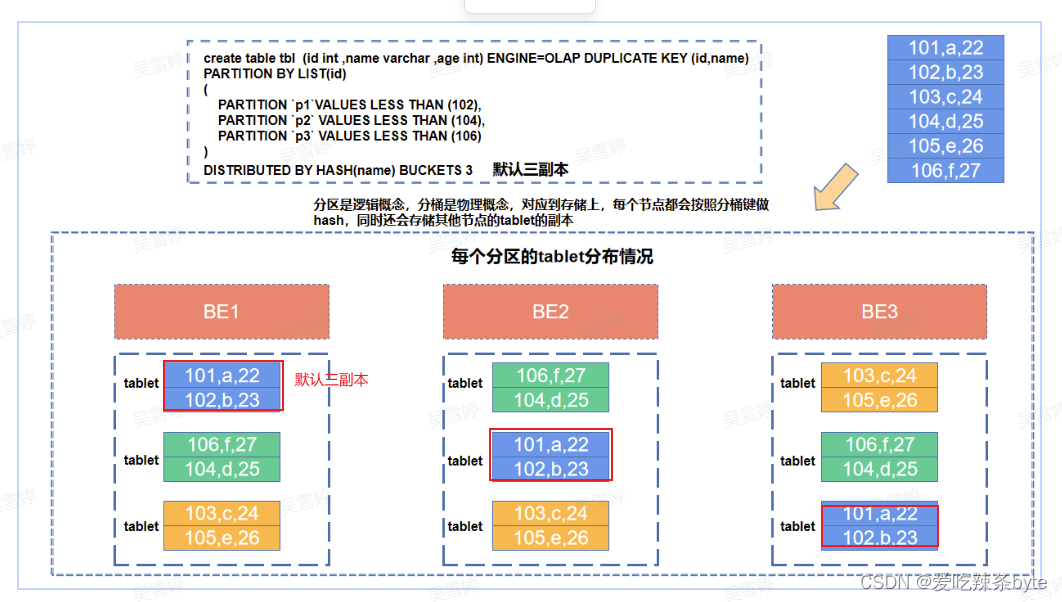
分区是逻辑概念,分桶是物理概念。每个分区partition内部会按照分桶键,采用哈希分桶算法将数据划分为多个桶bucket,每个桶的数据称之为一个数据分片tablet(实际的物理存储单元)。根据建表设置的副本数,计算有多少个副本在其他节点上(负载均衡)。如上图所示,当BE节点数和副本数一致时,每个BE节点会保留这个表对应的所有的tablet的数据(自身hash分桶对应的tablet数据和其他节点tablet的副本)。
一个表的Tablet总数量等于 = Partition num * Bucket num* Replica Num ,上述案例就等于 3*3*3 =27
- 表,分区,分桶,tablet,rowset,segment文件的关系:
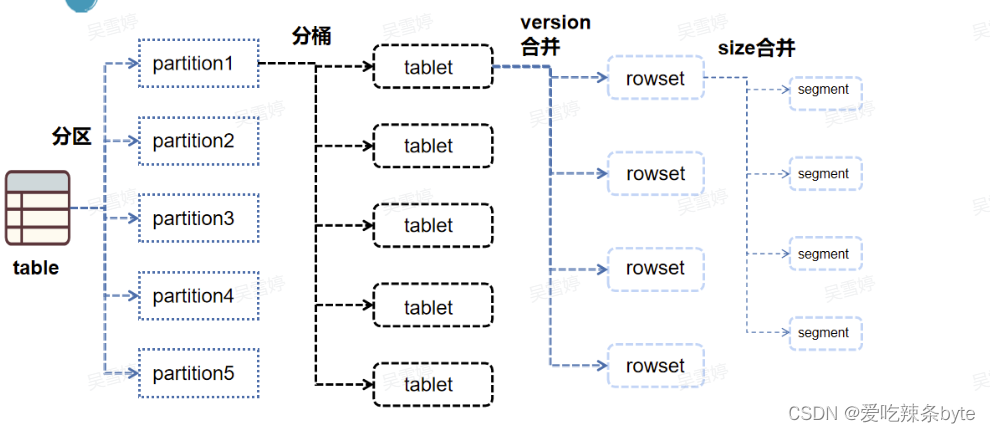
数据在导入时,最先落到磁盘上的是当前导入批次生成的rowset文件,每一次导入事务的成功,都会生成一个带有版本号的rowset文件。rowset文件由多个segment文件组成,segment文件是由segment writer生成的文件块。
七、总结
starrocks支持两级分区存储,第一层为range 分区(partition),第二层为hash 分桶(bucket)。
(1)range 分区用于将数据划分成不同区间,逻辑上等同于将原始表划分成了多个子表。在生产环境中,多数用户会根据按时间进行分区。基于时间进行分区有以下好处:
- 可区分冷热数据。
- 可使用 StarRocks 分级存储(SSD + SATA)功能。
- 按分区删除数据时,更加迅速。
(2)hash分桶指根据hash值将数据划分成不同的 Bucket。
- 建议采用区分度大的列做分桶,避免出现数据倾斜。
- 为方便数据恢复,建议单个 Bucket 保持较小的 Size,应保证其中数据压缩后大小保持在 100MB 至 1GB 左右。建议在建表或增加分区时合理考虑 Bucket 数目,其中不同分区可指定不同的 Bucket 数量。
注:参考文章:
第2.4章:StarRocks表设计--分区分桶与副本数_strrocks 建表分区-CSDN博客

