
- 1python123 从入门到精通挑战台
- 2springBoot项目搭建
- 3NL2SQL进阶系列(4):ConvAI、DIN-SQL、C3-浙大、DAIL-SQL-阿里等16个业界开源应用实践详解[Text2SQL]
- 4request.getRequestDispatcher(Request req,Response res) 和sendRedirect()_request.getrequestdispatcher参数是什么
- 5AI艺术的背后:详解文本生成图像模型【基于GAN】_基于gan的文本到图像生成模型的设计
- 6python+tkinter可视化GUI_你可以使用python的tkinter库来创建可视化窗口, 开始写的语句 import tkinte
- 7Python Anaconda创建虚拟环境及Pycharm使用虚拟环境_anaconda 虚拟环境
- 8【前端CSS基础2(CSS基本选择器和复合选择器)】
- 9EtherCAT I/O 马达控制机器人从站控制器设计_ax58100原理图
- 10python复数类型及其特点_python复数类型
【NLP】seq2seq&attention文本摘要实现_采用seq2seq模型实现长文本特定字段摘要生成
赞
踩
Seq2seq 文本摘要总结
目录
前言
之前尝试用textRank+NMF做长文本摘要,但textRank是基于句子间距离的,其结果是文本中句子的重要性排序,输出的是文本中现成的句子。这对于文章内容的理解是不够的。
当某个思想需要用多个句子表达,或者长文本中包含过于复杂的逻辑时,单靠提取其中的某几个句子时无法满足要求的。其次,textRank提取的摘要缺乏灵活性和概括性。
我们希望从文章“语义”的理解层面做一些改进,于是考虑使用Seq2seq 方法。
我们的训练数据是新浪微博的数据,将标题看成文本的摘要,将内容看作一整个句子,那么训练任务变成由句子到句子的预测。
结构
Seq2seq由encoder 和decoder两个RNN 组成,Encoder将变长序列输出,编码成encoderstate 再由Decoder 输出变长序列。
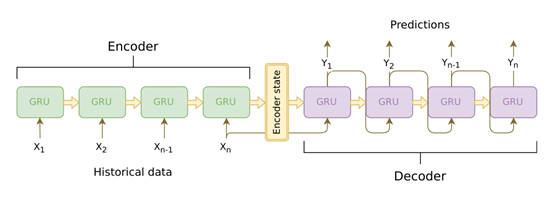
我们的Encoder是一个双向的GRU网络(bidirectional =True),一个网络将句子正序输入,另一个网络将句子逆序输入,目的是为了综合句子中词的过去和未来的上下文信息。
Encoder
Encoder时我们的整体输入如下,实际上,词在embedding之后,输入输出的都是Tensor,本项目中,我们指定(每一个block)输入输出的维数都是hidden_size。

即对应这样的输入形式:
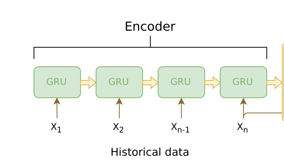
N_layer =2时,Encoder的形式:

由于是双向GRU,我们会对两个方向生成的output进行相加,得到y_i
为了便于GPU一次取出一个t时刻的batch个数据,我们通常把输入从(batch, max_length)变成(max_length, batch),这样使得一个t时刻的batch个数据在内存(显存)中是连续的,从而读取效率更高。

计算图:
- 把词的ID通过Embedding层变成向量。
- 把padding后的数据进行pack。
- 传入GRU进行Forward计算。
- Unpack
- 把双向GRU的结果向量加起来。
- 返回(所有时刻的)输出和最后时刻的隐状态。
实际上,在Embedding之后,输入Encoder 的tensor 应该为如下形式:

每一个timestep, Encoder 都输出一个 “output” vector 和一个 “hidden state” vector(隐状态)。每个时刻的输入是上一个时刻的隐状态和输入,我们通常只利用最后一个时刻的隐状态(实际上,我们如果采用attention机制的话,最后Decoder使用的是每个timestep(block) 的output 计算而得到的context向量,稍后再叙)
- class EncoderRNN(nn.Module):
- def __init__(self, hidden_size, embedding, n_layers=1, dropout=0):
- super(EncoderRNN, self).__init__()
- self.n_layers = n_layers
- self.hidden_size = hidden_size
- self.embedding = embedding
-
- # Initialize GRU; the input_size and hidden_size params are both set to 'hidden_size'
- # 这里表示我们单个block一个timestep的输入和输出向量维度都是hidden_size
- self.gru = nn.GRU(hidden_size, hidden_size, n_layers,
- dropout=(0 if n_layers == 1 else dropout), bidirectional=True)
-
- def forward(self, input_seq, input_lengths, hidden=None):
- # input_seq 是一个batch的输入句子,shape是(max_length, batch_size)
- # max_length是指定的句子的最大长度,也是Encoder的block个数
- # Embedding之后变成(max_length, batch, hidden_size)
- # hidden_size 指的是句子的编码向量长度,该值由给定的GRU输入长度确定。
- embedded = self.embedding(input_seq)
- # pack_padded_sequence 将输入向量和长度pack在一起
- #input_lengths是一个长度为batch,值为句子真实长度(包含词的个数)
- packed = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
- outputs, hidden = self.gru(packed, hidden)
- # outputs为(max_length, batch, hidden*num_directions)
- outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs)
- # 因为outputs的第三维是先放前向的hidden_size个结果,然后再放后向的hidden_size个结果
- # 所以outputs[:, :, :self.hidden_size]得到前向的结果
- # outputs[:, :, self.hidden_size:]是后向的结果
- outputs = outputs[:, :, :self.hidden_size] + outputs[:, : ,self.hidden_size:]
- # Return output and final hidden state
- return outputs, hidden

Encoder的输入输出
输入:
input_seq: 一个batch的输入句子,shape是(max_length, batch_size)
input_lengths: 一个长度为batch的list,表示句子的实际长度。
hidden: 初始化隐状态(通常是零),shape是(n_layers x num_directions, batch_size, hidden_size)
输出:
outputs: 最后一层GRU的输出向量(双向的向量加在了一起),shape(max_length, batch_size, hidden_size)
hidden: 最后一个时刻的隐状态,shape是(n_layers x num_directions, batch_size, hidden_size)
# Encoder传入输入和隐变量
# 如果传入的输入是一个Tensor (max_length, batch, hidden_size)
# 那么输出outputs是(max_length, batch, hidden_size*num_directions)。
# 最后我们会将num_directions的结果加起来,最终得到shape(max_length, batch_size, hidden_size)
ATTENTION
数据经过Encoder后生成最后时刻的隐状态后, Decoder开始工作。然后使用RNN计算新的隐状态和输出第一个词,接着用新的隐状态和第一个词计算第二个词,...,直到遇到,结束输出。虽然理论上Encoder最后时刻生成的输出 (context向量)可以编码输入句子的语义,但实际上,他并不能很好的表示语义,随着句子长度的增加,效果会更加不尽人意。
为此我们引入注意力机制,(attention mechanism),Bahdanau et al.首先提出 “attention mechanism” ,其原理是利用每timestep ,Decoder生成的hidden state 与 前面Encoder的最终的hidden state相乘求和,得到关于输入句子的每个词的attention core.

Luong(https://arxiv.org/abs/1508.04025)提出“Global attention”,将当前timestep Decoder 的hidden state 与 前面所有timestep 的Encoder的 output共同计算attention weights.并提出计算方式:
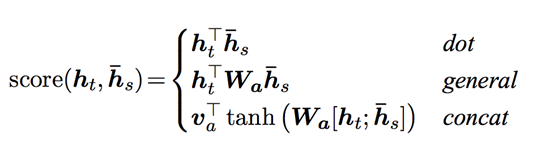
where ht = current target decoder state and hˉs = all encoder states.
Luong还提出“local attention”,由于“Global attention” 每一次decoder 都要用当前的output与之前的所有timestep的Encoder的output 共同计算,计算开销很大,且从上下文的角度出发,每个单词只需要关注与其周围少数几个词的关系即可。于是“local attention”设定一个窗口来调节参与计算attention weights的Encoder的output数量。

- # Luong 注意力layer
- class Attn(torch.nn.Module):
- def __init__(self, method, hidden_size):
- super(Attn, self).__init__()
- self.method = method
- if self.method not in ['dot', 'general', 'concat']:
- raise ValueError(self.method, "is not an appropriate attention method.")
- self.hidden_size = hidden_size
- if self.method == 'general':
- self.attn = torch.nn.Linear(self.hidden_size, hidden_size)
- elif self.method == 'concat':
- self.attn = torch.nn.Linear(self.hidden_size * 2, hidden_size)
- self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size))
- def dot_score(self, hidden, encoder_output):
- # 输入hidden的shape是(1, batch, hidden_size)
- # encoder_outputs的shape是(input_lengths, batch, hidden_size)
- # hidden * encoder_output得到的shape是(input_lengths, batch, hidden_size),然后对第3维求和就可以计算出score。
- return torch.sum(hidden * encoder_output, dim=2)
-
- def general_score(self, hidden, encoder_output):
- energy = self.attn(encoder_output)
- return torch.sum(hidden * energy, dim=2)
-
- def concat_score(self, hidden, encoder_output):
- energy = self.attn(torch.cat((hidden.expand(encoder_output.size(0), -1, -1),
- encoder_output), 2)).tanh()
- return torch.sum(self.v * energy, dim=2)
- # 输入是上一个时刻的隐状态hidden和所有时刻的Encoder的输出encoder_outputs
- # 输出是注意力的概率,也就是长度为input_lengths的向量,它的和加起来是1。
- def forward(self, hidden, encoder_outputs):
- if self.method == 'general':
- attn_energies = self.general_score(hidden, encoder_outputs)
- elif self.method == 'concat':
- attn_energies = self.concat_score(hidden, encoder_outputs)
- elif self.method == 'dot':
- attn_energies = self.dot_score(hidden, encoder_outputs)
- # 把attn_energies从(max_length, batch)转置成(batch, max_length)
- attn_energies = attn_energies.t()
- # 使用softmax函数把score变成概率,shape仍然是(batch, max_length),然后用unsqueeze(1)变成
- # (batch, 1,max_length)
- return F.softmax(attn_energies, dim=1).unsqueeze(1)
有了注意力的子模块之后,我们就可以实现Decoder了。
Decoder
Encoder可以一次把一个序列输入GRU,得到整个序列的输出。但是Decoder t时刻的输入是t-1时刻的输出,在t-1时刻计算完成之前是未知的,因此只能一次处理一个时刻的数据。因此Encoder的GRU的输入是(max_length, batch, hidden_size),而Decoder的输入是(1, batch, hidden_size)。
此外Decoder只能利用前面的信息,所以只能使用单向(而不是双向)的GRU,而Encoder的GRU是双向的,如果两种的hidden_size是一样的,则Decoder的隐单元个数少了一半,那怎么把Encoder的最后时刻的隐状态作为Decoder的初始隐状态呢?这里是把每个时刻双向结果加起来的,因此它们的大小就能匹配了。
计算图:
- 把词ID输入Embedding层
- 使用单向的GRU继续Forward进行一个时刻的计算。
- 使用新的隐状态计算注意力权重
- 用注意力权重得到context向量
- context向量和GRU的输出拼接起来,然后再进过一个全连接网络,使得输出大小仍然是hidden_size
- 使用一个投影矩阵把输出从hidden_size变成词典大小,然后用softmax变成概率
- 返回输出和新的隐状态

Training 时, decoder每一步只能处理一个时刻的数据,因为t时刻计算完了才能计算t+1时刻。Decoder首次输入的是one batch 个SOS,表示句子的开始,生成的output 与 encoder的 output一起计算注意力权重. 用注意力权重得到context向量 ,context向量和GRU的输出拼接起来,然后再进过一个全连接网络,使得输出大小仍然是hidden_size ,使用一个投影矩阵把输出从hidden_size变成词典大小,最后使用softmax函数把得到的score变成概率。 生成第一个词在词典中的权重。具体计算方式,可参考代码注释。
- class DecoderRNN(nn.Module):
- def __init__(self, attn_model, embedding, hidden_size, output_size, n_layers=1, dropout=0.1):
- super(DecoderRNN, self).__init__()
- # attn_model就是前面定义的Attn类的对象。
- self.attn_model = attn_model
- self.hidden_size = hidden_size
- self.output_size = output_size
- self.n_layers = n_layers
- self.dropout = dropout
-
- # 定义Decoder的layers
- self.embedding = embedding
- self.embedding_dropout = nn.Dropout(dropout)
- self.gru = nn.GRU(hidden_size, hidden_size, n_layers, dropout=(0 if n_layers == 1 else dropout))
- self.concat = nn.Linear(hidden_size * 2, hidden_size)
- self.out = nn.Linear(hidden_size, output_size)
- self.attn = Attn(attn_model, hidden_size)
-
- def forward(self, input_step, last_hidden, encoder_outputs):
- # 注意:decoder每一步只能处理一个时刻的数据,因为t时刻计算完了才能计算t+1时刻。
- # input_step的shape是(1, batch),1是当前输入的词ID(来自上一个时刻的输出)
- # 通过embedding层变成(1, batch, embedding_size),然后进行dropout,shape不变。设定embedding_size = embedding_size
- embedded = self.embedding(input_step)
- embedded = self.embedding_dropout(embedded)
- # 得到rnn_output的shape是(1, batch, embedding_size)
- # hidden是(2, batch, hidden_size),因为是两层的GRU,n_layers = 2。
- rnn_output, hidden = self.gru(embedded, last_hidden)
- # 计算注意力权重, 根据前面的分析,attn_weights的shape是(batch, 1, max_length)
- attn_weights = self.attn(rnn_output, encoder_outputs)
- context = attn_weights.bmm(encoder_outputs.transpose(0, 1))
- # encoder_outputs是(max_length, batch, hidden_size)
- # encoder_outputs.transpose(0, 1)后的shape是(batch, max_length, hidden_size)
- # attn_weights.bmm后是(batch, 1, hidden_size)
- # bmm是批量的矩阵乘法,第一维是batch,我们可以把attn_weights看成batch个(1,max_length)的矩阵
- # 把encoder_outputs.transpose(0, 1)看成batch个(10, hidden_size)的矩阵
- # 那么bmm就是batch个(1, max_length)矩阵 x (max_length, hidden_size)矩阵最终得到(batch, 1, hidden_size)
- # 把context向量和GRU的输出拼接起来
- rnn_output = rnn_output.squeeze(0)
- context = context.squeeze(1)
- concat_input = torch.cat((rnn_output, context), 1)
- # rnn_output从(1, batch, hidden_size)变成(batch, hidden_size)
- # context从(batch, 1, hidden_size)变成(batch, hidden_size)
- # 拼接得到(batch, 2*hidden_size)
- concat_output = torch.tanh(self.concat(concat_input))
- # self.concat(concat_input)的输出是(batch, hidden_size),控制输出大小
- # 然后用tanh把输出返回变成(-1,1),concat_output的shape是(batch, hidden_size)
- # out是(hidden_size, 词典大小), output是(batch,词典大小)
- output = self.out(concat_output)
- # 用softmax变成概率,表示当前时刻输出每个词的概率。
- output = F.softmax(output, dim=1)
- # 返回 output和新的隐状态
- return output, hidden
在数据输入模型训练之前,我们需要做一些工作,主要是设定句子的最大长度(将大于阈值长度的文本切断,小于阈值长度的文本进行padding),去除一些标点符号,分词,组成sequence pair(一个长度为2的list,第一个值为正文的分词序列,第二个值为对应的title)
随后我们创建一个工具类,主要用来统计词,建立所有词的词典,及词对应的id.同时将数量词,句子开头,结尾,pad词添加token。
随后我们为Encoder 和Decoder 的输入输出分别构建对应的数据格式。对于Decoder的输出,我们建立2值Tensor:mask,其size与结果(test时Decoder的输出)对应的Tensor 一样,方便之后的loss计算
seq2seq有两个RNN,Encoder RNN是没有直接定义损失函数的,它是通过影响Decoder从而影响最终的输出以及loss。我们用交叉熵来计算loss:
- def maskNLLLoss(inp, target, mask):
- # 计算实际的词的个数,因为padding是0,非padding是1,因此sum就可以得到词的个数
- nTotal = mask.sum()
- crossEntropy = -torch.log(torch.gather(inp, 1, target.view(-1, 1)).squeeze(1))
- # torch.gather表示从inp 中选择出target 位置对应的值
- loss = crossEntropy.masked_select(mask).mean()
-
- loss = loss.to(device)
- return loss, nTotal.item()
为了增加模型的收敛速度,我们使用 teacher forcing 和 gradient clipping的trick。
在训练的时候我们会限制Decoder的输出,使得Decoder的输出长度和”真实”答案(即title对应的长度)一样长。但是我们在训练的时候如果让Decoder自行输出,那么收敛可能会比较慢,因为Decoder在t时刻的输入来自t-1时刻的输出。如果前面预测错了,那么后面很可能都会错下去。我们使用teacher forcing,
它不管模型在t-1时刻做什么预测都把t-1时刻的正确答案作为t时刻的输入。但是一直用teacher forcing也有问题,因为在真实的Decoder的是是没有老师来帮它纠正错误的。所以我们加一个teacher_forcing_ratio参数随机的来确定本次训练是否teacher forcing。

另外使用到的一个技巧是梯度裁剪(gradient clipping) 。这个技巧通常是为了防止梯度爆炸(exploding gradient),它把参数限制在一个范围之内,从而可以避免梯度的梯度过大或者出现NaN等问题。算法步骤如下。
首先设置一个梯度阈值:clip_gradient
在后向传播中求出各参数的梯度,这里我们不直接使用梯度进去参数更新,我们求这些梯度的l2范数
然后比较梯度的l2范数||g||与clip_gradient的大小
如果前者大,求缩放因子clip_gradient/||g||, 由缩放因子可以看出梯度越大,则缩放因子越小,这样便很好地控制了梯度的范围
最后将梯度乘上缩放因子便得到最后所需的梯度
Training
整个模型的步骤:
把整个batch的输入传入encoder
把decoder的输入设置为特殊的,初始隐状态设置为encoder最后时刻的隐状态
decoder每次处理一个时刻的forward计算
如果是teacher forcing,把上个时刻的"正确的"词作为当前输入,否则用上一个时刻的输出作为当前时刻的输入
计算loss
反向计算梯度
对梯度进行裁剪
更新模型(包括encoder和decoder)参数
- def train(input_variable, lengths, target_variable, mask, max_target_len, encoder, decoder, embedding,
- encoder_optimizer, decoder_optimizer, batch_size, clip, max_length=MAX_LENGTH):
-
- # 梯度清空
- encoder_optimizer.zero_grad()
- decoder_optimizer.zero_grad()
-
- # 设置device,从而支持GPU,当然如果没有GPU也能工作。
- input_variable = input_variable.to(device)
- lengths = lengths.to(device)
- target_variable = target_variable.to(device)
- mask = mask.to(device)
-
- # 初始化变量
- loss = 0
- print_losses = []
- n_totals = 0
- # encoder的Forward计算
- encoder_outputs, encoder_hidden = encoder(input_variable, lengths)
- # Decoder的初始输入是SOS,我们需要构造(1, batch)的输入,表示第一个时刻batch个输入。
- decoder_input = torch.LongTensor([[SOS_token for _ in range(batch_size)]])
- decoder_input = decoder_input.to(device)
- # 从Encoder的hidden 中选出后decoder.n_layers个hidden作为decoder的初始hidden
- decoder_hidden = encoder_hidden[:decoder.n_layers]
- # 确定是否teacher forcing
- use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
- # 一次处理一个时刻
- if use_teacher_forcing:
- for t in range(max_target_len):
- decoder_output, decoder_hidden = decoder(
- decoder_input, decoder_hidden, encoder_outputs
- )
- # Teacher forcing: 下一个时刻的输入是当前正确答案
- decoder_input = target_variable[t].view(1, -1)
- # 计算累计的loss
- mask_loss, nTotal = maskNLLLoss(decoder_output, target_variable[t], mask[t])
- loss += mask_loss
- print_losses.append(mask_loss.item() * nTotal)
- n_totals += nTotal
- else:
- for t in range(max_target_len):
- decoder_output, decoder_hidden = decoder(
- decoder_input, decoder_hidden, encoder_outputs
- )
- # 不是teacher forcing: 下一个时刻的输入是当前模型预测概率最高的值
- _, topi = decoder_output.topk(1)
- decoder_input = torch.LongTensor([[topi[i][0] for i in range(batch_size)]])
- decoder_input = decoder_input.to(device)
- # 计算累计的loss
- mask_loss, nTotal = maskNLLLoss(decoder_output, target_variable[t], mask[t])
- loss += mask_loss
- print_losses.append(mask_loss.item() * nTotal)
- n_totals += nTotal
-
- # 反向计算
- loss.backward()
-
- # 对encoder和decoder进行梯度裁剪
- _ = torch.nn.utils.clip_grad_norm_(encoder.parameters(), clip)
- _ = torch.nn.utils.clip_grad_norm_(decoder.parameters(), clip)
-
- # 更新参数
- encoder_optimizer.step()
- decoder_optimizer.step()
-
- return sum(print_losses) / n_totals
我们将原始数据划分,loader后,迭代训练,生成最终model并存储checkpoint.
然后利用model对新数据进行文本摘要。我们使用贪心算法解码。
- class GreedySearchDecoder(nn.Module):
- def __init__(self, encoder, decoder):
- super(GreedySearchDecoder, self).__init__()
- self.encoder = encoder
- self.decoder = decoder
-
- def forward(self, input_seq, input_length, max_length):
- # Encoder的Forward计算
- encoder_outputs, encoder_hidden = self.encoder(input_seq, input_length)
- # 把Encoder最后时刻的隐状态作为Decoder的初始值
- decoder_hidden = encoder_hidden[:decoder.n_layers]
- # 因为我们的函数都是要求(time,batch),因此即使只有一个数据,也要做出二维的。
- # Decoder的初始输入是SOS
- decoder_input = torch.ones(1, 1, device=device, dtype=torch.long) * SOS_token
- # 用于保存解码结果的tensor
- all_tokens = torch.zeros([0], device=device, dtype=torch.long)
- all_scores = torch.zeros([0], device=device)
- # 循环,这里只使用长度限制,后面处理的时候把EOS去掉了。
- for _ in range(max_length):
- # Decoder forward一步
- decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden,
- encoder_outputs)
- # decoder_outputs是(batch=1, vob_size)
- # 使用max返回概率最大的词和得分
- decoder_scores, decoder_input = torch.max(decoder_output, dim=1)
- # 把解码结果保存到all_tokens和all_scores里
- all_tokens = torch.cat((all_tokens, decoder_input), dim=0)
- all_scores = torch.cat((all_scores, decoder_scores), dim=0)
- # decoder_input是当前时刻输出的词的ID,这是个一维的向量,因为max会减少一维。
- # 但是decoder要求有一个batch维度,因此用unsqueeze增加batch维度。
- decoder_input = torch.unsqueeze(decoder_input, 0)
- # 返回所有的词和得分。
- return all_tokens, all_scores
一个训练过程:
1) 把输入传给Encoder,得到所有时刻的输出和最后一个时刻的隐状态。
2) 把Encoder最后时刻的隐状态作为Decoder的初始状态。
3) Decoder的第一输入初始化为SOS。
4) 定义保存解码结果的tensor
5) 循环直到最大解码长度
a) 把当前输入传入Decoder
b) 得到概率最大的词以及概率
c) 把这个词和概率保存下来
d) 把当前输出的词作为下一个时刻的输入
6) 返回所有的词和概率
evaluate
实现一个evaluate函数,由它来完成提取。我们需要把一个句子变成输入需要的格式——shape为(batch, max_length),即使只有一个输入也需要增加一个batch维度。我们首先把句子分词,然后变成ID的序列,然后转置成合适的格式。
此外我们还需要创建一个名为lengths的tensor,来表示输入的实际长度。接着我们构造类GreedySearchDecoder的实例searcher,然后用searcher来进行解码得到输出的ID,最后我们把这些ID变成词并且去掉EOS之后的内容。
- def evaluate(encoder, decoder, searcher, voc, sentence, max_length=MAX_LENGTH):
- ### Format input sentence as a batch
- # words -> indexes
- indexes_batch = [util.indexesFromSentence(voc, sentence)]
- # Create lengths tensor
- lengths = torch.tensor([len(indexes) for indexes in indexes_batch])
- # Transpose dimensions of batch to match models' expectations
- input_batch = torch.LongTensor(indexes_batch).transpose(0, 1)
- # Use appropriate device
- input_batch = input_batch.to(device)
- lengths = lengths.to(device)
- # Decode sentence with searcher
- tokens, scores = searcher(input_batch, lengths, max_length)
- # indexes -> words
- decoded_words = [voc.index2word[token.item()] for token in tokens]
- return decoded_words
我们用少量微博的数据来训练模型,定义模型层数仅为2,得到的结果可以初步成文,但组织混乱,且难以体现原文整体信息。
接下来将从:
数据集的准备(通过人工标注,增加数据集等方式)。
在GPU上利用更过的layer来获得更好的效果。
结合textRank 对于关键词句的识别权重来优化模型。
待我优化模型后,上传代码...


