
- 1在Kaggle上使用Stable Diffusion进行AI绘图_kaggle stable diffusion
- 2HiveSQL基础Day02
- 3K8s容器及crt工具导出文件_crt导出session
- 4chatgpt赋能python:Python全文替换技巧——优化SEO排名的利器_pythondat全文替换
- 5RK3568平台开发系列讲解(输入系统篇)Framework层获取和处理按键事件流程总结_android rk3568 监听物理键盘事件
- 6[ai笔记13] 大模型架构对比盘点:Encoder-Only、Decoder-Only、Encoder-Decoder
- 7编织效率之梦:Visual Studio与Windows快捷键指南
- 8性格分类--从唐僧四师徒看性格_唐僧师徒四人的mbti
- 9cpu架构的简单介绍_cpu架构有几种
- 10HarmonyOS应用开发-EducationSystem分布式亲子早教系统体验_鸿蒙软件实现education system
ES 8,大数据开发2024面试题
赞
踩
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

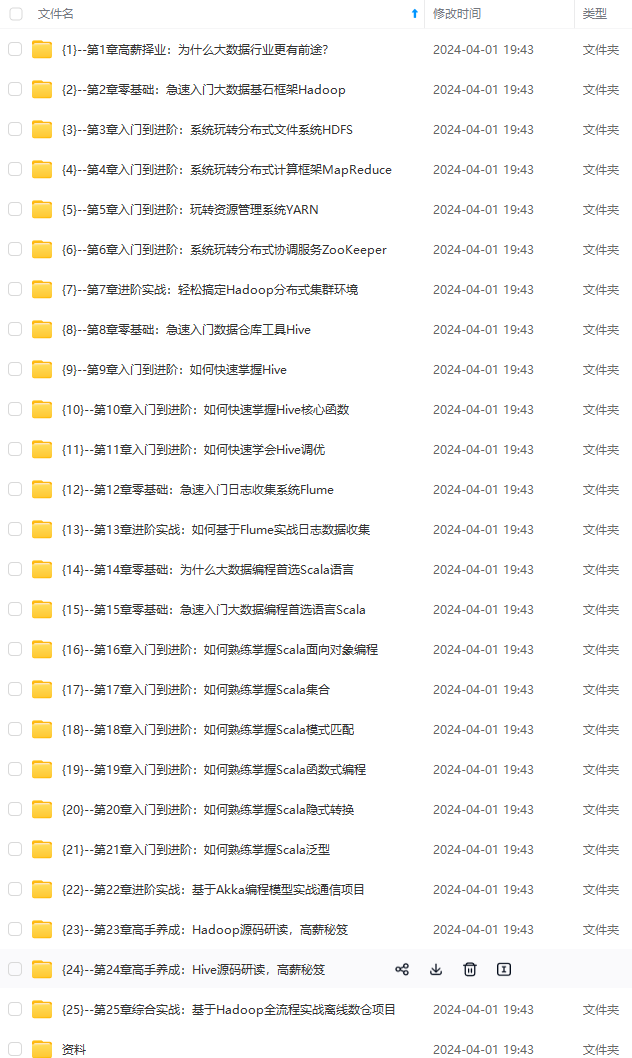
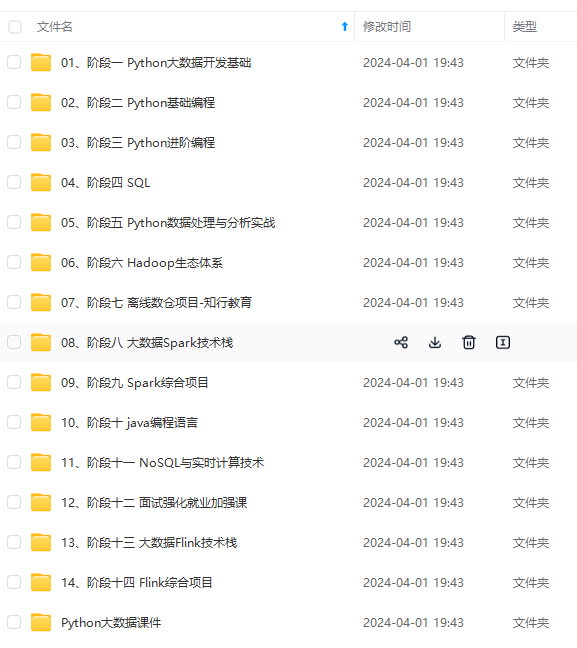
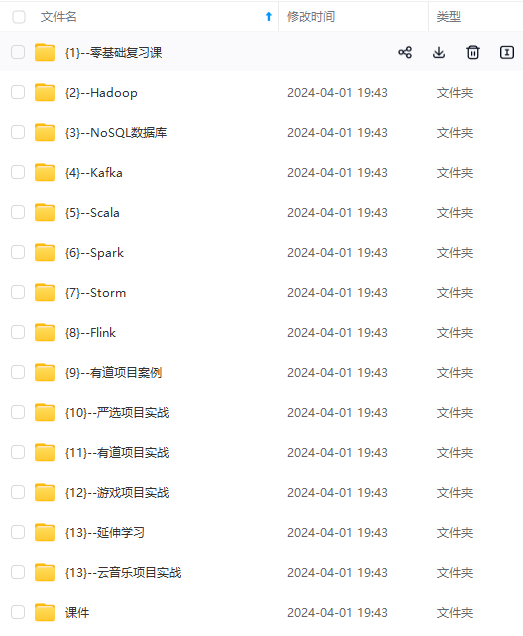
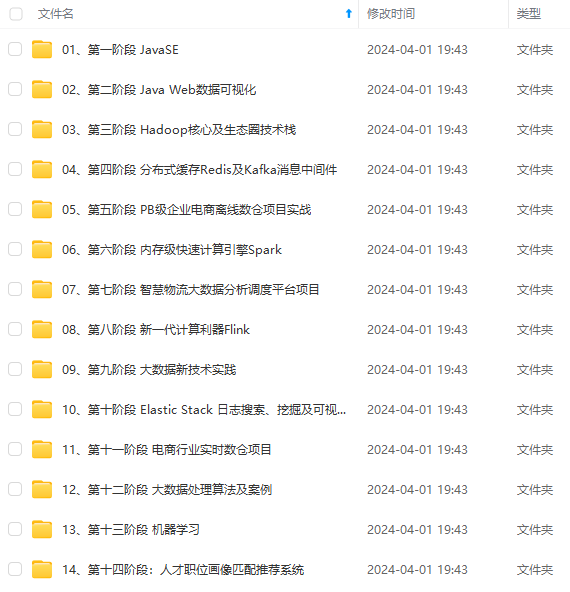
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
1.同一时间序列的文档在分片上彼此相邻,因此在磁盘上彼此相邻存储,因此操作系统页面更加同质并且压缩效果更好,从而大幅降低 TCO。
2.时间序列的分析通常涉及比较每两个连续的文档(样本)、检查给定时间窗口中的最后一个文档等,当下一个文档可能位于任何分片上并且实际上位于任何索引上时,这是相当复杂的。按时间序列和时间戳排序可以改进分析,无论是在性能方面还是在我们添加新聚合的能力方面。
3.最后,作为指标数据时间序列索引生命周期管理的一部分,Elasticsearch 启用下采样操作。当对索引进行下采样时,Elasticsearch 会保留一个文档,其中包含时间序列中每个时间段的统计摘要。然后,支持的聚合可以在数据流上运行,并包括下采样索引和原始数据索引,而用户无需意识到这一点。还支持对下采样索引进行下采样,以达到更粗略的时间分辨率。
Time series data stream (TSDS) | Elasticsearch Guide [8.7] | Elastic | Elasticsearch Guide [8.7] | Elastic")是一项用于优化时间序列数据的 Elasticsearch 索引的功能。这涉及对索引进行排序以实现更好的压缩并使用合成 _source 来减小索引大小。因此,TSDS 指数明显小于包含相同数据的非时间序列指数。TSDS 对于管理大量时间序列数据特别有用。并且提供了采样优化算法,可减少 Elasticsearch 时间序列索引中存储的文档数量,从而缩小索引并改善查询延迟。这种优化是通过预先聚合时间序列索引来实现的,使用 time_series 索引模式来识别时间序列。下采样被配置为 ILM 中的一项操作,使其成为管理 Elasticsearch 中大量时间序列数据的有用工具。
五、开箱即用的安全配置功能
在8.0版本中,ES官方为我们提供了开箱即用的安全功能。在此之前,都要经过一系列复杂的操作,才能拥有安全能力。
在没有安全性的情况下运行 Elasticsearch 会使您的集群暴露给任何可以向 Elasticsearch 发送网络流量的人。在以前的版本中,您必须显式启用 Elasticsearch 安全功能,例如身份验证、授权和网络加密 (TLS)。从 Elasticsearch 8.0 开始, 首次启动 Elasticsearch 时Start the Elastic Stack with security enabled | Elasticsearch Guide [8.0] | Elastic
启动时,我们会生成注册令牌,您可以使用该令牌连接 Kibana 实例或在安全的 Elasticsearch 集群中注册其他节点,而无需生成安全证书或更新 YAML 配置文件。只需在启动新节点或 Kibana 实例时使用生成的注册令牌,Elastic Stack 就会为您处理所有安全配置。开箱即用,您将得到:
- 用户认证
- 用户授权
- 使用 TLS 进行加密的节点间通信
- Elasticsearch 和 Kibana 之间使用 TLS 进行加密通信
需要新的注册令牌吗?使用该 elasticsearch-create-enrollment-token | Elasticsearch Guide [8.0] | Elastic 工具为 Elasticsearch 节点和 Kibana 实例创建注册令牌。
六、底层存储优化与性能提升
1.keyword、match_only_text、 和text字段的存储节省
在8.0版本中更新了倒排索引(一种内部数据结构),以使用更节省空间的编码。这种变化将有利于keyword各个领域、 match_only_text各个领域,以及在较小程度上的text各个领域。在我们使用应用程序日志的基准测试中,这意味着字段索引大小message(映射为match_only_text)减少了 14.4%,磁盘占用空间总体减少了 3.5%。
2.更快地索引geo_point、geo_shape和范围字段
在8.0版本中优化了多维点的索引速度,多维点是用于geo_point、geo_shape和范围字段的内部数据结构。Lucene 级基准测试报告称,这些字段类型的索引速度提高了 10-15%。主要由这些字段组成的 Elasticsearch 索引和数据流可能会显着提高索引速度。
3.管道处理性能提升
在8.3版本中通过避免(深度)递归,改进了具有同步处理器的管道的管道执行逻辑。在我们模拟日志记录用例的夜间基准测试中,这导致摄取管道上花费的 CPU 时间减少了 10%,整体摄取速度提高了 3%。
4.filters/range/date_histogram aggs 性能提升
在8.4版本中,在没有子聚合时,对聚合进行提速。这非常常见,例如,Kibana 的发现选项卡顶部的直方图没有date_histogram任何子聚合。在我们的集会测试中,该特定聚合速度加快了约 85%,从 250 毫秒降至 30 毫秒。
5.使用显式“_id”改进了 get、mget 和索引的性能
在8.7中,将布隆过滤器的误报率_id从约 10% 降低至约 1%,从而减少了段中不存在术语时的 I/O 负载。这可以提高通过 检索文档时的性能_id,这种情况发生在执行 get 或 mget 请求时,或者发出_bulk提供显式 _id 的请求时。
6.Encode using 40, 48 and 56 bits per value
在8.8版本中,做了编码的提升。
使用编码如下: * 对于每个值采用 [33, 40] 位的值,使用每个值 40 位进行编码 * 对于每个值采用 [41, 48] 位的值,使用每个值 48 位进行编码 * 对于采用 [ 49, 56] 每个值位,使用每个值 56 位进行编码
这是对 ForUtils 使用的编码的改进,ForUtils 不对每个值超过 32 位的值应用任何压缩。
请注意,每个值的 40、48 和 56 位表示字节的精确倍数(每个值 5、6 和 7 个字节)。因此,我们总是使用比长值所需的 8 个字节少 3、2 或 1 个字节的值来写入值。
看看存储字节的节省,对于 128 个(长)值的块,我们通常会存储 128 x 8 字节 = 1024 字节,而现在我们有以下内容: * 每个值 40 位:写入 645 字节而不是 1024 字节,节省379 字节 (37%) * 每个值 48 位:写入 772 字节而不是 1024,节省 252 字节 (24%) * 每个值 56 位:写入 897 字节而不是 1024,节省 127 字节 (12%)
还将压缩应用于规格指标,假设每个值超过 32 位的压缩值对于浮点值效果很好,因为浮点值的表示方式(IEEE 754 格式)。
7.并发索引和搜索下更好的索引和搜索性能
在8.9版本中,提升并发索引和搜索的性能。当像匹配短语查询或术语查询这样的查询针对常量关键字字段时,我们可以跳过分片上的查询执行,其中查询被重写以不匹配任何文档。我们利用包括常量关键字字段的索引映射,并以这样的方式重写查询:如果常量关键字字段与索引映射中定义的值不匹配,我们将重写查询以匹配任何文档。这将导致分片级别请求在数据节点上执行查询之前立即返回,从而完全跳过分片。在这里,我们利用尽可能跳过分片的功能来避免不必要的分片刷新并改善查询延迟(通过不执行任何与搜索相关的 I/O)。避免这种不必要的分片刷新可以改善查询延迟,因为搜索线程不再需要等待不必要的分片刷新。不匹配查询条件的分片将保持搜索空闲状态,索引吞吐量不会受到刷新的负面影响。在引入此更改之前,查询命中多个分片,包括那些没有与搜索条件匹配的文档的分片(考虑使用索引模式或具有许多支持索引的数据流),可能会导致“分片刷新风暴”,从而增加查询延迟搜索线程等待所有分片刷新完成后才能启动和执行搜索操作。引入此更改后,搜索线程只需等待包括相关数据的分片刷新完成。请注意,分片预过滤器的执行以及重写发生的相应“可以匹配”阶段取决于所涉及的分片总数以及是否至少有一个分片返回非空结果(请参阅 pre_filter_shard_size设置为了解如何控制这种行为)。Elasticsearch 在所谓的“可以匹配”阶段对数据节点进行重写操作,利用这样一个事实:此时我们可以访问索引映射并提取有关常量关键字字段及其值的信息。这意味着我们仍然将搜索查询从协调器节点“扇出”到相关数据节点。在协调器节点上不可能基于索引映射重写查询,因为协调器节点缺少索引映射信息。
七、更高效的快照
8.5版本中,快照操作的开销已显着减少。快照现在以更高效的顺序运行,并且需要的网络流量比以前少得多。
八、更丰富的地图搜索功能
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
外链图片转存中…(img-fEqriRrM-1713282563604)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!



