
- 12024年Q1季度冰箱行业线上市场销售数据分析
- 22021爱分析·云计算厂商全景报告_博云谐云
- 3快速入门 KBQA问答系统的实现_neo4j kbqa
- 4Node.js 开发者需要知道的 13 个常用库
- 5Yolov8优化:融合注意力机制与卷积的最新移动端高效网络架构_cloformer速度
- 6开源模型应用落地-解锁大语言模型的无限潜能
- 7记一次虚拟机CentOs设置静态IP_虚拟机centos设置ip地址
- 8HDFS的Java API操作_hdfs的java apl 操作
- 9verilog I2C_eeprom 手册分析及代码编写思路_eeprom代码
- 10GPIO模拟I2C通信协议(二)_摸拟24c08页读写
redis黑马外卖实战项目源码实现_外卖项目消息队列
赞
踩
文章目录
- 1.项目介绍
- 源码后端地址
- yaml配置
- pom文件
- 1、短信登录
- 2、商户查询缓存
- 3、优惠卷秒杀
- 4、分布式锁
- 5、分布式锁-redission
- 6、秒杀优化
- 7、Redis消息队列
- 秒杀下单 Ultimate VER
- 8. 点赞相关
- 9. 关注相关
- 10、附近商户
- 11、用户签到
- 12、UV统计
- 完整代码
- 代码总思路
- 1.redis实现验证码缓存,token更新
- 2.商铺缓存
- 3.缓存穿透,缓存雪崩,缓存击穿
- 4. 基于互斥锁解决缓存击穿问题
- 5.逻辑过期解决缓存击穿
- 6.超卖问题
- 7.一人一单
- 8.分布式锁集群项目
- 9.redission分布式锁
- 10.秒杀优化基于阻塞队列
- 11.秒杀优化基于消息队列
- 12.点赞用sortedSet
- 13.关注互关用set
- 14.Feed流推送
- 15GEO实现附近商务功能
- 16.BitMap实现用户签到
- 17.UV统计-HyperLogLog
1.项目介绍

- Spring 相关:
Spring Boot 2.x
Spring MVC
数据存储层:
MySQL:存储数据
MyBatis Plus:数据访问框架
Redis 相关:
spring-data-redis:操作 Redis
Lettuce:操作 Redis 的高级客户端
Apache Commons Pool:用于实现 Redis 连接池
Redisson:基于 Redis 的分布式数据网格
工具库:
HuTool:工具库合集
Lombok:注解式代码生成工具
- 短信登录
这一块我们会使用redis共享session来实现
- 商户查询缓存
通过本章节,我们会理解缓存击穿,缓存穿透,缓存雪崩等问题,让小伙伴的对于这些概念的理解不仅仅是停留在概念上,更是能在代码中看到对应的内容
- 优惠卷秒杀
通过本章节,我们可以学会Redis的计数器功能, 结合Lua完成高性能的redis操作,同时学会Redis分布式锁的原理,包括Redis的三种消息队列
- 附近的商户
我们利用Redis的GEOHash来完成对于地理坐标的操作
- UV统计
主要是使用Redis来完成统计功能
- 用户签到
使用Redis的BitMap数据统计功能
- 好友关注
基于Set集合的关注、取消关注,共同关注等等功能,这一块知识咱们之前就讲过,这次我们在项目中来使用一下
- 打人探店
基于List来完成点赞列表的操作,同时基于SortedSet来完成点赞的排行榜功能
源码后端地址
github源码地址
gitee源码地址
yaml配置
server: port: 8081 spring: application: name: hmdp datasource: driver-class-name: com.mysql.cj.jdbc.Driver # url: jdbc:mysql://127.0.0.1:3306/hmdp?useSSL=false&serverTimezone=UTC username: root password: 123456 url: jdbc:mysql://localhost:3306/hmdp?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true redis: host: 192.168.8.130 port: 6379 password: yangroot lettuce: pool: max-active: 10 max-idle: 10 min-idle: 1 time-between-eviction-runs: 10s jackson: default-property-inclusion: non_null # JSON处理时忽略非空字段 mybatis-plus: type-aliases-package: com.hmdp.entity # 别名扫描包 logging: level: com.hmdp: debug pattern: dateformat: mm:ss.SSS
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
pom文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.7.5</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.hmdp</groupId> <artifactId>hm-dianping</artifactId> <version>0.0.1-SNAPSHOT</version> <name>hm-dianping</name> <description>Demo project for Spring Boot</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <exclusions> <exclusion> <artifactId>spring-data-redis</artifactId> <groupId>org.springframework.data</groupId> </exclusion> <exclusion> <artifactId>lettuce-core</artifactId> <groupId>io.lettuce</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-redis</artifactId> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency> <dependency> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> <version>6.1.6.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- <dependency>--> <!-- <groupId>mysql</groupId>--> <!-- <artifactId>mysql-connector-java</artifactId>--> <!-- <scope>runtime</scope>--> <!-- <version>5.1.47</version>--> <!-- </dependency>--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.3</version> </dependency> <!--hutool--> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.17</version> </dependency> <!--redisson--> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.13.6</version> </dependency> <!-- https://mvnrepository.com/artifact/org.aspectj/aspectjweaver --> <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> <version>1.9.9.1</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build> </project>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
1、短信登录
1.1、基于Session实现登录流程
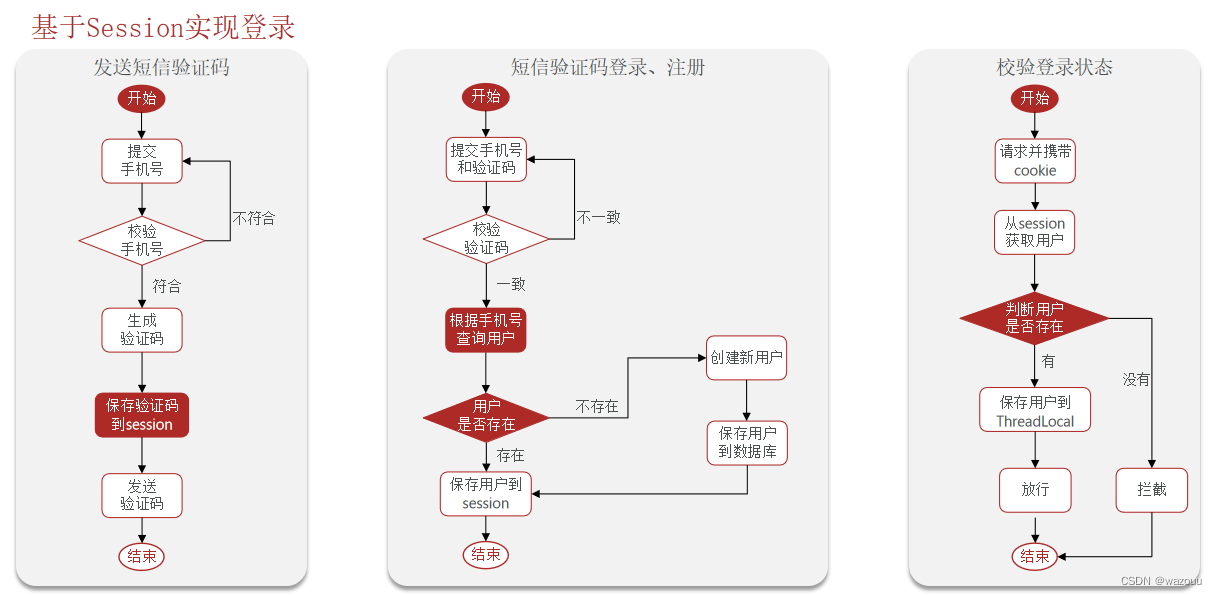
@Override public Result sendCode(String phone, HttpSession session) { // 1.校验手机号 if (RegexUtils.isPhoneInvalid(phone)) { // 2.如果不符合,返回错误信息 return Result.fail("手机号格式错误!"); } // 3.符合,生成验证码 String code = RandomUtil.randomNumbers(6); // 4.保存验证码到 session session.setAttribute("code",code); // 5.发送验证码 log.debug("发送短信验证码成功,验证码:{}", code); // 返回ok return Result.ok(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
1.2.基于session实现登陆的问题
单体应用时用户的会话信息保存在session中,session存在于服务器端的内存中,由于前前后后用户只针对一个web服务器,所以没啥问题。但是一到了web服务器集群的环境下(我们一般都是用Nginx做负载均衡,若是使用了轮询等这种请求分配策略),就会导致用户小a在A服务器登录了,session存在于A服务器中,但是第二次请求被分配到了B服务器,由于B服务器中没有用户小a的session会话,导致用户小a还要再登陆一次.
session 的替代方案 应该满足:数据共享;内存存储;key、value 结构(Redis 恰好就满足这些情况)
1.3 Redis 实现共享 session
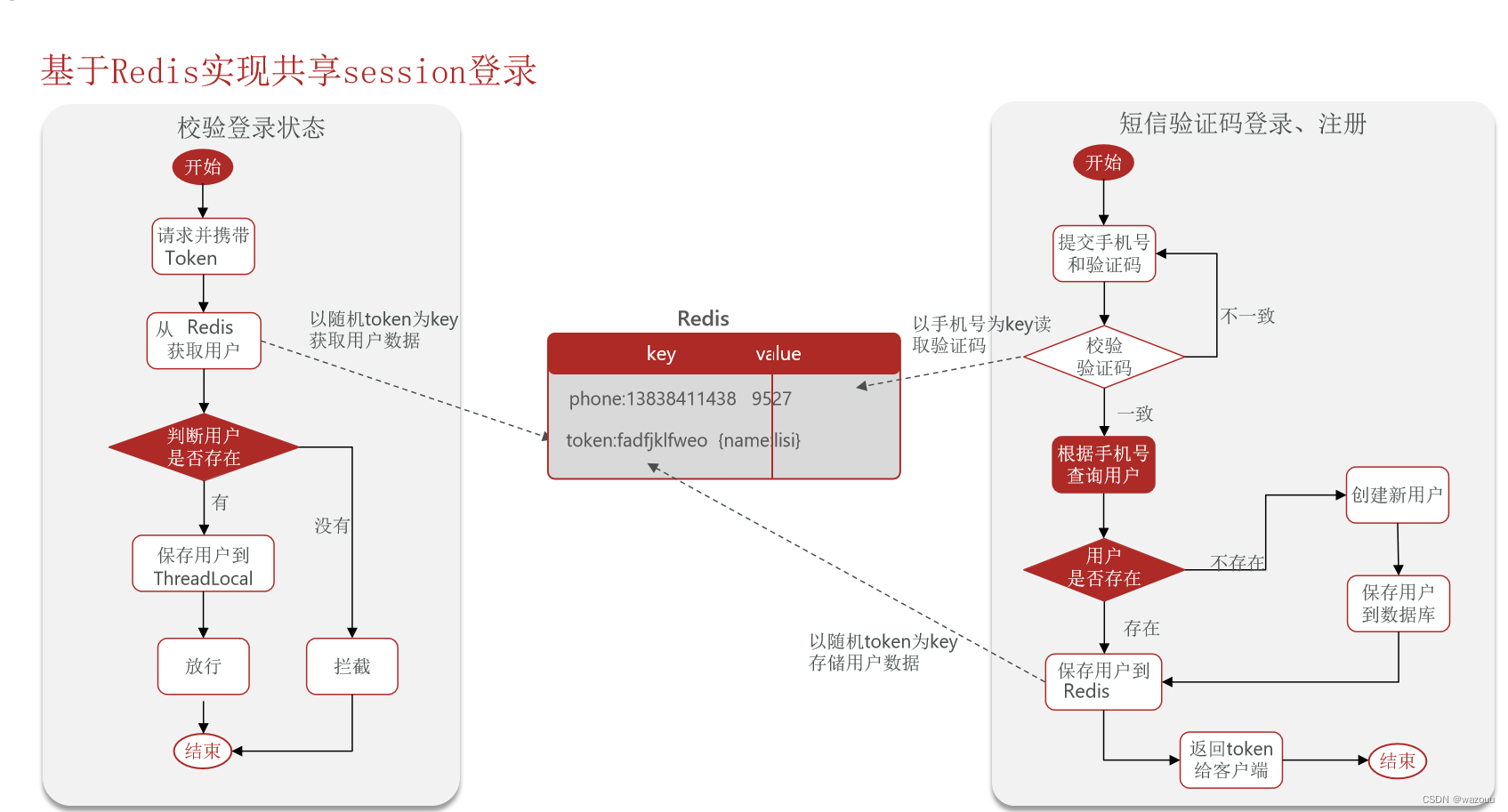
@Resource private StringRedisTemplate stringRedisTemplate; @Override public Result sendCode(String phone, HttpSession session) { // 1.校验手机号 if (RegexUtils.isPhoneInvalid(phone)) { // 2.如果不符合,返回错误信息 return Result.fail("手机号格式错误!"); } // 3.符合,生成验证码 String code = RandomUtil.randomNumbers(6); // 4.保存验证码到 session stringRedisTemplate.opsForValue().set(LOGIN_CODE_KEY + phone, code, LOGIN_CODE_TTL, TimeUnit.MINUTES); // 5.发送验证码 log.debug("发送短信验证码成功,验证码:{}", code); // 返回ok return Result.ok(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
1.4、实现登录拦截功能
在这个方案中,对应路径的拦截,同时刷新登录token令牌的存活时间,但是现在这个拦截器他只是拦截需要被拦截的路径,假设当前用户访问了一些不需要拦截的路径,那么这个拦截器就不会生效,所以此时令牌刷新的动作实际上就不会执行,所以这个方案他是存在问题的.
既然之前的拦截器无法对不需要拦截的路径生效,那么我们可以添加一个拦截器,在第一个拦截器中拦截所有的路径,把第二个拦截器做的事情放入到第一个拦截器中,同时刷新令牌,因为第一个拦截器有了threadLocal的数据,所以此时第二个拦截器只需要判断拦截器中的user对象是否存在即可,完成整体刷新功能。


public class RefreshTokenInterceptor implements HandlerInterceptor { private StringRedisTemplate stringRedisTemplate; public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate) { this.stringRedisTemplate = stringRedisTemplate; } @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { // 1.获取请求头中的token String token = request.getHeader("authorization"); if (StrUtil.isBlank(token)) { return true; } // 2.基于TOKEN获取redis中的用户 String key = LOGIN_USER_KEY + token; Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(key); // 3.判断用户是否存在 if (userMap.isEmpty()) { return true; } // 5.将查询到的hash数据转为UserDTO UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false); // 6.存在,保存用户信息到 ThreadLocal UserHolder.saveUser(userDTO); // 7.刷新token有效期 stringRedisTemplate.expire(key, LOGIN_USER_TTL, TimeUnit.MINUTES); // 8.放行 return true; } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { // 移除用户 UserHolder.removeUser(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
public class LoginInterceptor implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { // 1.判断是否需要拦截(ThreadLocal中是否有用户) if (UserHolder.getUser() == null) { // 没有,需要拦截,设置状态码 response.setStatus(401); // 拦截 return false; } // 有用户,则放行 return true; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
@Configuration public class MvcConfig implements WebMvcConfigurer { @Resource private StringRedisTemplate stringRedisTemplate; @Override public void addInterceptors(InterceptorRegistry registry) { // 登录拦截器 registry.addInterceptor(new LoginInterceptor()) .excludePathPatterns( "/shop/**", "/voucher/**", "/shop-type/**", "/upload/**", "/blog/hot", "/user/code", "/user/login" ).order(1); // token刷新的拦截器 registry.addInterceptor(new RefreshTokenInterceptor(stringRedisTemplate)).addPathPatterns("/**").order(0); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
1.5、隐藏用户敏感信息
我们通过浏览器观察到此时用户的全部信息都在,这样极为不靠谱,所以我们应当在返回用户信息之前,将用户的敏感信息进行隐藏,采用的核心思路就是书写一个UserDto对象,这个UserDto对象就没有敏感信息了,我们在返回前,将有用户敏感信息的User对象转化成没有敏感信息的UserDto对象,那么就能够避免这个尴尬的问题了
1.6 思路
第一次登录 :
两个拦截器都通过(login send)
发送验证码,验证码保存到redis
loginformDto( phone,code, password)从redis获得验证码进行验证
成功后根据phone从数据库查出user,如果不存在创建新用户
得到用户之后,随机生成taken,vlaue是 user>userdto>usermap
返回是taken
第二次刷新:
1.拦截器1,获得token,在redis得到usermap > userdto >保存到线程,刷新token有效期
2.拦截器2,判断用户是否存在,存在就放行。
logininterceper inplement handlerintercept 在pre保存线程 after移除线程(防止线程的泄露)
在mvcconfig里面addIntercepter 用registry.addinterceper(new logininter()).excluepath(需要排除 的路径)
/me返回了user(内存压力过大而且返回容易泄露),可以用.copyProperties(user,userDto.classs),现在存拿都是dto
1.7 UserController(/ login /logout /code )
@Slf4j @RestController @RequestMapping("/user") public class UserController { @Resource private IUserService userService; @Resource private IUserInfoService userInfoService; /** * 发送手机验证码 */ @PostMapping("code") public Result sendCode(@RequestParam("phone") String phone, HttpSession session) { // 发送短信验证码并保存验证码 return userService.sendCode(phone, session); } /** * 登录功能 * @param loginForm 登录参数,包含手机号、验证码;或者手机号、密码 */ @PostMapping("/login") public Result login(@RequestBody LoginFormDTO loginForm, HttpSession session){ // 实现登录功能 return userService.login(loginForm, session); } /** * 登出功能 * @return 无 */ @PostMapping("/logout") public Result logout(){ UserHolder.removeUser(); return Result.fail("退出登录"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
1.8 UserServiceImpl
@Slf4j @Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService { @Resource private StringRedisTemplate stringRedisTemplate; @Override public Result sendCode(String phone, HttpSession session) { // 1.校验手机号 if (RegexUtils.isPhoneInvalid(phone)) { // 2.如果不符合,返回错误信息 return Result.fail("手机号格式错误!"); } // 3.符合,生成验证码 String code = RandomUtil.randomNumbers(6); // 4.保存验证码到 session stringRedisTemplate.opsForValue().set(LOGIN_CODE_KEY + phone, code, LOGIN_CODE_TTL, TimeUnit.MINUTES); // 5.发送验证码 log.debug("发送短信验证码成功,验证码:{}", code); // 返回ok return Result.ok(); } @Override public Result login(LoginFormDTO loginForm, HttpSession session) { // 1.校验手机号 String phone = loginForm.getPhone(); if (RegexUtils.isPhoneInvalid(phone)) { // 2.如果不符合,返回错误信息 return Result.fail("手机号格式错误!"); } // 3.从redis获取验证码并校验 String cacheCode = stringRedisTemplate.opsForValue().get(LOGIN_CODE_KEY + phone); String code = loginForm.getCode(); if (cacheCode == null || !cacheCode.equals(code)) { // 不一致,报错 return Result.fail("验证码错误"); } // 4.一致,根据手机号查询用户 select * from tb_user where phone = ? User user = query().eq("phone", phone).one(); // 5.判断用户是否存在 if (user == null) { // 6.不存在,创建新用户并保存 user = createUserWithPhone(phone); } // 7.保存用户信息到 redis中 // 7.1.随机生成token,作为登录令牌 String token = UUID.randomUUID().toString(true); // 7.2.将User对象转为HashMap存储 UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class); Map<String, Object> userMap = BeanUtil.beanToMap(userDTO, new HashMap<>(), CopyOptions.create() .setIgnoreNullValue(true) .setFieldValueEditor((fieldName, fieldValue) -> fieldValue.toString())); // 7.3.存储 String tokenKey = LOGIN_USER_KEY + token; stringRedisTemplate.opsForHash().putAll(tokenKey, userMap); // 7.4.设置token有效期 stringRedisTemplate.expire(tokenKey, LOGIN_USER_TTL, TimeUnit.MINUTES); // 8.返回token return Result.ok(token); } private User createUserWithPhone(String phone) { // 1.创建用户 User user = new User(); user.setPhone(phone); user.setNickName(USER_NICK_NAME_PREFIX + RandomUtil.randomString(10)); // 2.保存用户 save(user); return user; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
温馨小贴士:关于threadlocal
如果小伙伴们看过threadLocal的源码,你会发现在threadLocal中,无论是他的put方法和他的get方法, 都是先从获得当前用户的线程,然后从线程中取出线程的成员变量map,只要线程不一样,map就不一样,所以可以通过这种方式来做到线程隔离
补充ThreadLocal相关知识22
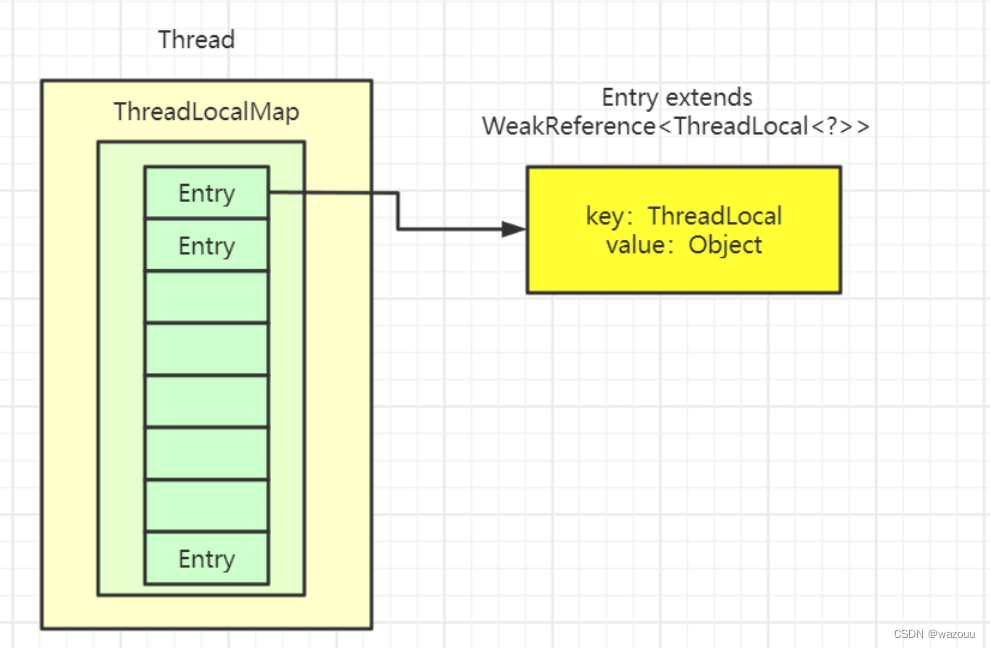
a.ThreadLocal的数据结构
- Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,也就是说每个线程有一个自己的ThreadLocalMap。
- ThreadLocalMap有自己的独立实现,可以简单地将它的key视作ThreadLocal,value为代码中放入的值(实际上key并不是ThreadLocal本身,而是它的一个弱引用)。
- 每个线程在往ThreadLocal里放值的时候,都会往自己的ThreadLocalMap里存,读也是以ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
- ThreadLocalMap有点类似HashMap的结构,只是HashMap是由数组+链表实现的,而ThreadLocalMap中并没有链表结构。
- 我们还要注意Entry, 它的key是ThreadLocal<?> k ,继承自WeakReference, 也就是我们常说的弱引用类型。
b.内存泄露问题
- 由于ThreadLocal的key是弱引用,故在gc时,key会被回收掉,但是value是强引用没有被回收,所以在我们拦截器的方法里必须手动remove()。
原文链接:https://blog.csdn.net/qq_45733304/article/details/126443684
2、商户查询缓存
2.1 认识缓存
缓存(Cache),就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码(例如:
例1:Static final ConcurrentHashMap<K,V> map = new ConcurrentHashMap<>(); 本地用于高并发
例2:static final Cache<K,V> USER_CACHE = CacheBuilder.newBuilder().build(); 用于redis等缓存
例3:Static final Map<K,V> map = new HashMap(); 本地缓存
- 1
- 2
- 3
- 4
- 5
由于其被Static修饰,所以随着类的加载而被加载到内存之中,作为本地缓存,由于其又被final修饰,所以其引用(例3:map)和对象(例3:new HashMap())之间的关系是固定的,不能改变,因此不用担心赋值(=)导致缓存失效;
缓存数据存储于代码中,而代码运行在内存中,内存的读写性能远高于磁盘,缓存可以大大降低用户访问并发量带来的服务器读写压力
2.1.1 如何使用缓存
实际开发中,会构筑多级缓存来使系统运行速度进一步提升,例如:本地缓存与redis中的缓存并发使用
浏览器缓存:主要是存在于浏览器端的缓存
**应用层缓存:**可以分为tomcat本地缓存,比如之前提到的map,或者是使用redis作为缓存
**数据库缓存:**在数据库中有一片空间是 buffer pool,增改查数据都会先加载到mysql的缓存中
**CPU缓存:**当代计算机最大的问题是 cpu性能提升了,但内存读写速度没有跟上,所以为了适应当下的情况,增加了cpu的L1,L2,L3级的缓存
磁盘缓存:
2.2 添加商户缓存
2.2.1 、缓存模型和思路
标准的操作方式就是查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,如果缓存数据不存在,再查询数据库,然后将数据存入redis。

2.1.2、代码如下
代码思路:如果缓存有,则直接返回,如果缓存不存在,则查询数据库,然后存入redis。
@Override public Result queryById(Long id) { String key =CACHE_SHOP_KEY + id; //1.从redis查询商铺缓存 String shopJson = stringRedisTemplate.opsForValue().get(key); //2.判断是否存在 if (StrUtil.isNotBlank(shopJson)){ //3.存在直接返回 Shop shop = JSONUtil.toBean(shopJson, Shop.class); return Result.ok(shop); } //4.不存在返,根据id查询数据库 Shop shop = getById(id); //5.不存在返回错误 if (shop==null){ return Result.fail("店铺不存在"); } //6.存在写入rdis stringRedisTemplate.opsForValue().set("cache:shop:" + id,JSONUtil.toJsonStr(shop)); return Result.ok(shop); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
//缓存练习,写shop-type/list的缓存
@Service public class ShopTypeServiceImpl extends ServiceImpl <ShopTypeMapper, ShopType> implements IShopTypeService { @Resource private StringRedisTemplate stringRedisTemplate; public Result queryshopTypeList(){ //展示所有的店铺信息 String key =CACHE_SHOPTYPE_KEY ; //1.从redis查询商铺缓存 // String shopJson = stringRedisTemplate.opsForValue().get(key); List<String> strshopTypeList = stringRedisTemplate.opsForList().range(key, 0, -1); ArrayList<ShopType> shopTypes = new ArrayList<>(); //2.判断是否存在 if (!strshopTypeList.isEmpty()){ //3.存在直接返回 for (String s:strshopTypeList) { ShopType shopType = JSONUtil.toBean(s, ShopType.class); shopTypes.add(shopType); } return Result.ok(shopTypes); } //4.不存在,查询数据库 List<ShopType> typeList = query().orderByAsc("sort").list(); //5.不存在直接返回错误 if(typeList.isEmpty()){ return Result.fail("不存在分类"); } //6.存在写入rdis for (ShopType s:typeList) { String shopjson = JSONUtil.toJsonStr(s); strshopTypeList.add(shopjson); } stringRedisTemplate.opsForList().rightPushAll(key,strshopTypeList); return Result.ok(typeList); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
2.3 缓存更新策略
缓存更新是redis为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,当我们向redis插入太多数据,此时就可能会导致缓存中的数据过多,所以redis会对部分数据进行更新,或者把他叫为淘汰更合适。
**内存淘汰:**redis自动进行,当redis内存达到咱们设定的max-memery的时候,会自动触发淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式)
**超时剔除:**当我们给redis设置了过期时间ttl之后,redis会将超时的数据进行删除,方便咱们继续使用缓存
**主动更新:**我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题
| 内存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | 不用自己维护。利用 Redis 的内存淘汰机制: 当内存不足时自动淘汰部分数据。 | 下次查询时更新缓存。 给缓存数据添加 TTL 时间,到期后自动删除缓存。 | 编写业务逻辑,在修改数据库的同时,更新缓存。 |

2.3.1 、数据库缓存不一致解决方案:
由于我们的缓存的数据源来自于数据库,而数据库的数据是会发生变化的,因此,如果当数据库中数据发生变化,而缓存却没有同步,此时就会有一致性问题存在,其后果是:
用户使用缓存中的过时数据,就会产生类似多线程数据安全问题,从而影响业务,产品口碑等;怎么解决呢?有如下几种方案
Cache Aside Pattern 人工编码方式:缓存调用者在更新完数据库后再去更新缓存,也称之为双写方
Read/Write Through Pattern : 由系统本身完成,数据库与缓存的问题交由系统本身去处理
Write Behind Caching Pattern :调用者只操作缓存,其他线程去异步处理数据库,实现最终一致

2.3.2 、数据库和缓存不一致采用什么方案
综合考虑使用方案一,但是方案一调用者如何处理呢?
操作缓存和数据库时有三个问题需要考虑:
如果采用第一个方案,那么假设我们每次操作数据库后,都操作缓存,但是中间如果没有人查询,那么这个更新动作实际上只有最后一次生效,中间的更新动作意义并不大,我们可以把缓存删除,等待再次查询时,将缓存中的数据加载出来
-
删除缓存还是更新缓存?
- 更新缓存:每次更新数据库都更新缓存,无效写操作较多
- 删除缓存:更新数据库时让缓存失效,查询时再更新缓存
-
如何保证缓存与数据库的操作的同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
应该具体操作缓存还是操作数据库,我们应当是先操作数据库,再删除缓存,原因在于,如果你选择第一种方案,在两个线程并发来访问时,假设线程1先来,他先把缓存删了,此时线程2过来,他查询缓存数据并不存在,此时他写入缓存,当他写入缓存后,线程1再执行更新动作时,实际上写入的就是旧的数据,新的数据被旧数据覆盖了。
- 第一种方案:先删除缓存,再输出数据库
异常情况介绍:在线程 1 删除缓存后,完成对数据库的更新(目标是更新为 v = 20)前。线程 2 恰好此时也查询了缓存,但是这时的缓存已经被线程 1 删除了,所以线程 1 它又直接去查询了数据库,并将数据库中的数据(v = 10)写入了缓存。在线程 2 进行完了上述的操作后,线程 1 才终于完成了对数据库中的数据的更新(v = 20)。此时,缓存中的数据为 v = 10,数据库中的数据为 v = 20,此时数据库和缓存中的数据不一致。
- 第二种方案:先操作数据库,再删除缓存
异常情况介绍:由于某种原因(不如过期时间到了),缓存此时恰好失效了,线程 1 查询不到缓存,线程 1 它需要再去数据库中查询数据后再写入缓存。但是就在线程 1 完成写入缓存的操作前,恰好此时线程 2 来更新数据库的数据(更新 v = 20),之后线程 2 又删除了缓存(此时缓存是空的,所以这里相当于删除了个寂寞)。在线程 2 完成这些操作后,线程 1 才终于将数据库中的旧数据写入了缓存(v = 10)。此时数据库中的数据(v = 20)和缓存中的数据(v = 10)不一致。
可以看出两种方法都有各自的问题,但是由于写的时间要远大于读的时间,所以先操作db再删除cache的出现问题的几率非常小。


- 先操作缓存还是先操作数据库?
- 先删除缓存,再操作数据库
- 先操作数据库,再删除缓存
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7TENK60n-1671001492385)(.\Redis实战篇.assets\1653323595206.png)]
2.4 实现商铺和缓存与数据库双写一致
核心思路如下:
修改ShopController中的业务逻辑,满足下面的需求:
根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
根据id修改店铺时,先修改数据库,再删除缓存
修改重点代码1:修改ShopServiceImpl的queryById方法
设置redis缓存时添加过期时间
修改重点代码2
代码分析:通过之前的淘汰,我们确定了采用删除策略,来解决双写问题,当我们修改了数据之后,然后把缓存中的数据进行删除,查询时发现缓存中没有数据,则会从mysql中加载最新的数据,从而避免数据库和缓存不一致的问题
@Override
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺id不能为空");
}
// 1.更新数据库
updateById(shop);
// 2.删除缓存
stringRedisTemplate.delete(CACHE_SHOP_KEY + id);
return Result.ok();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
小结 缓存更新策略
缓存更新策略的最佳实践方案:

低一致性需求:使用 Redis 自带的内存淘汰机制
高一致性需求:主动更新,并以超时剔除作为兜底方案
读操作:
缓存命中则直接返回
缓存未命中则查询数据库,并写入缓存,设定超时时间
写操作:
先写数据库,然后再删除缓存
要确保数据库与缓存操作的原子性
2.5 缓存穿透问题的解决思路
缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见的解决方案有两种:
-
缓存空对象
-
优点:实现简单,维护方便
-
缺点:
- 额外的内存消耗
- 可能造成短期的不一致
适合命中不高,但可能被频繁更新的数据
-
-
布隆过滤
-
优点:内存占用较少,没有多余key
-
缺点:
- 实现复杂
- 存在误判可能
适合命中不高,但是更新不频繁的数据
-
**缓存空对象思路分析:**当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,简单的解决方案就是哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到缓存了
**布隆过滤:**布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,
假设布隆过滤器判断这个数据不存在,则直接返回
这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突(布隆过滤器算的哈希值,但不是百分百存在)
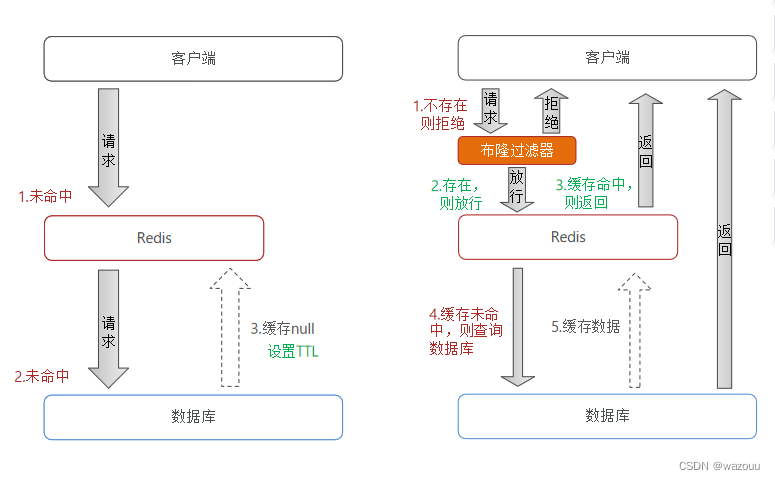
2.6 编码解决商品查询的缓存穿透问题:
核心思路如下:
在原来的逻辑中,我们如果发现这个数据在mysql中不存在,直接就返回404了,这样是会存在缓存穿透问题的
现在的逻辑中:如果这个数据不存在,我们不会返回404 ,还是会把这个数据写入到Redis中,并且将value设置为空,欧当再次发起查询时,我们如果发现命中之后,判断这个value是否是null,如果是null,则是之前写入的数据,证明是缓存穿透数据,如果不是,则直接返回数据。
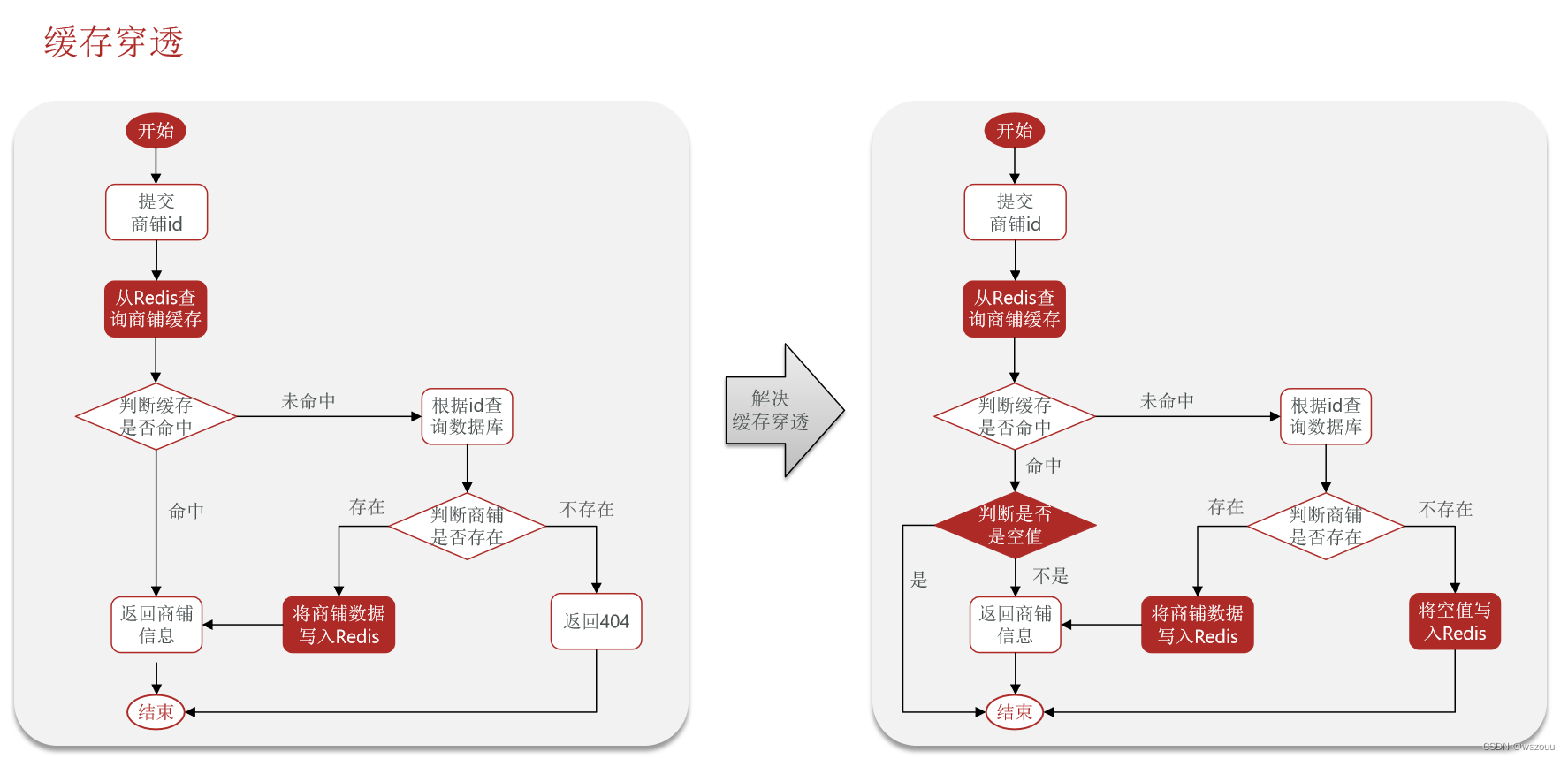
//写的null缓存 @Override public Result queryById(Long id) { String key =CACHE_SHOP_KEY + id; //1.从redis查询商铺缓存 String shopJson = stringRedisTemplate.opsForValue().get(key); //2.判断是否存在 if (StrUtil.isNotBlank(shopJson)){ //isnotBlank只有"abc"true,null "" \t\n都是false //3.存在直接返回 Shop shop = JSONUtil.toBean(shopJson, Shop.class); return Result.ok(shop); } //2.3判断命中的是否是空值 if(shopJson ==null){ //返回一个错误信息 return Result.fail("店铺不存在"); } //4.不存在返,根据id查询数据库 Shop shop = getById(id); //5.不存在返回错误 if (shop==null){ //将空值写入redis stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES); return Result.fail("店铺不存在"); } //6.存在写入rdis stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL,TimeUnit.MINUTES); return Result.ok(shop); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
小结 缓存穿透解决
缓存穿透产生的原因是什么?
- 用户请求的数据在缓存中和数据库中都不存在,不断发起这样的请求,给数据库带来巨大压力
缓存穿透的解决方案有哪些?
- 缓存null值
- 布隆过滤
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
2.7 缓存雪崩问题及解决思路
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存(比如nginx,redis,jvm,数据库)

2.8 缓存击穿问题及解决思路
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案有两种:
- 互斥锁
- 逻辑过期
逻辑分析:假设线程1在查询缓存之后,本来应该去查询数据库,然后把这个数据重新加载到缓存的,此时只要线程1走完这个逻辑,其他线程就都能从缓存中加载这些数据了,但是假设在线程1没有走完的时候,后续的线程2,线程3,线程4同时过来访问当前这个方法, 那么这些线程都不能从缓存中查询到数据,那么他们就会同一时刻来访问查询缓存,都没查到,接着同一时间去访问数据库,同时的去执行数据库代码,对数据库访问压力过大

- 解决方案一、使用锁来解决:
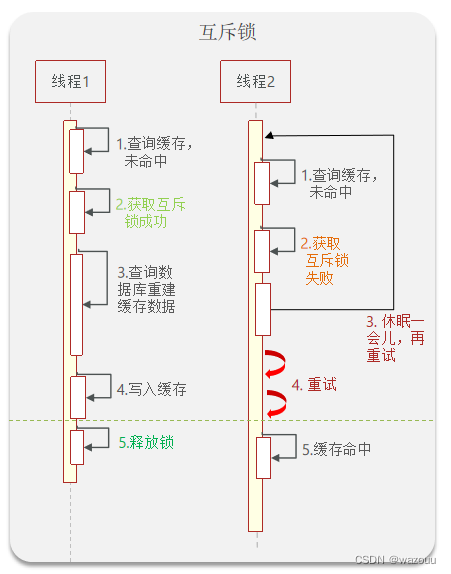
因为锁能实现互斥性。假设线程过来,只能一个人一个人的来访问数据库,从而避免对于数据库访问压力过大,但这也会影响查询的性能,因为此时会让查询的性能从并行变成了串行,我们可以采用tryLock方法 + double check来解决这样的问题。
假设现在线程1过来访问,他查询缓存没有命中,但是此时他获得到了锁的资源,那么线程1就会一个人去执行逻辑,假设现在线程2过来,线程2在执行过程中,并没有获得到锁,那么线程2就可以进行到休眠,直到线程1把锁释放后,线程2获得到锁,然后再来执行逻辑,此时就能够从缓存中拿到数据了。
解决方案二、逻辑过期方案
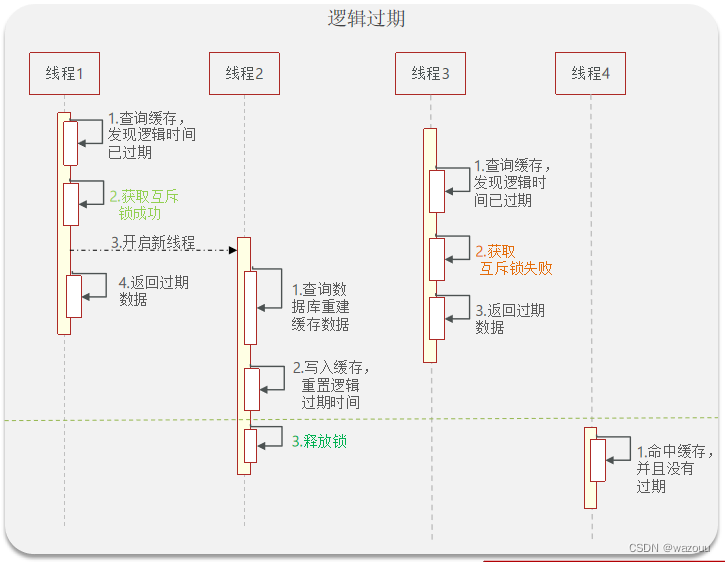
方案分析:我们之所以会出现这个缓存击穿问题,主要原因是在于我们对key设置了过期时间,假设我们不设置过期时间,其实就不会有缓存击穿的问题,但是不设置过期时间,这样数据不就一直占用我们内存了吗,我们可以采用逻辑过期方案。
我们把过期时间设置在 redis的value中,注意:这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理。假设线程1去查询缓存,然后从value中判断出来当前的数据已经过期了,此时线程1去获得互斥锁,那么其他线程会进行阻塞,获得了锁的线程他会开启一个 线程去进行 以前的重构数据的逻辑,直到新开的线程完成这个逻辑后,才释放锁, 而线程1直接进行返回,假设现在线程3过来访问,由于线程线程2持有着锁,所以线程3无法获得锁,线程3也直接返回数据,只有等到新开的线程2把重建数据构建完后,其他线程才能走返回正确的数据。
这种方案巧妙在于,异步的构建缓存,缺点在于在构建完缓存之前,返回的都是脏数据。
进行对比
**互斥锁方案:**由于保证了互斥性,所以数据一致,且实现简单,因为仅仅只需要加一把锁而已,也没其他的事情需要操心,所以没有额外的内存消耗,缺点在于有锁就有死锁问题的发生,且只能串行执行性能肯定受到影响
逻辑过期方案: 线程读取过程中不需要等待,性能好,有一个额外的线程持有锁去进行重构数据,但是在重构数据完成前,其他的线程只能返回之前的数据,且实现起来麻烦

2.9 利用互斥锁解决缓存击穿问题
核心思路:相较于原来从缓存中查询不到数据后直接查询数据库而言,现在的方案是 进行查询之后,如果从缓存没有查询到数据,则进行互斥锁的获取,获取互斥锁后,判断是否获得到了锁,如果没有获得到,则休眠,过一会再进行尝试,直到获取到锁为止,才能进行查询
如果获取到了锁的线程,再去进行查询,查询后将数据写入redis,再释放锁,返回数据,利用互斥锁就能保证只有一个线程去执行操作数据库的逻辑,防止缓存击穿
基于 互斥锁 方式解决缓存击穿问题
- 需求:修改根据 id 查询商铺的业务,基于互斥锁方式来解决缓存击穿问题
- 自定义互斥锁(Redis 中的
setnx就可以办到这点)

操作锁的代码:
核心思路就是利用redis的setnx方法来表示获取锁,该方法含义是redis中如果没有这个key,则插入成功,返回1,在stringRedisTemplate中返回true, 如果有这个key则插入失败,则返回0,在stringRedisTemplate返回false,我们可以通过true,或者是false,来表示是否有线程成功插入key,成功插入的key的线程我们认为他就是获得到锁的线程。
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);这里最好不要直接返回flag,拆箱容易空指针
}
private void unlock(String key) {
stringRedisTemplate.delete(key);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
操作代码:
public Shop queryWithMutex(Long id) { String key = CACHE_SHOP_KEY + id; // 1、从redis中查询商铺缓存 String shopJson = stringRedisTemplate.opsForValue().get("key"); // 2、判断是否存在 if (StrUtil.isNotBlank(shopJson)) { // 存在,直接返回 return JSONUtil.toBean(shopJson, Shop.class); } //判断命中的值是否是空值 if (shopJson != null) { //返回一个错误信息 return null; } // 4.实现缓存重构 //4.1 获取互斥锁 String lockKey = "lock:shop:" + id; Shop shop = null; try { boolean isLock = tryLock(lockKey); // 4.2 判断否获取成功 if(!isLock){ //4.3 失败,则休眠重试 Thread.sleep(50); return queryWithMutex(id); } //4.4 成功,根据id查询数据库 shop = getById(id); // 5.不存在,返回错误 if(shop == null){ //将空值写入redis stringRedisTemplate.opsForValue().set(key,"",CACHE_NULL_TTL,TimeUnit.MINUTES); //返回错误信息 return null; } //6.写入redis stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),CACHE_NULL_TTL,TimeUnit.MINUTES); }catch (Exception e){ throw new RuntimeException(e); } finally { //7.释放互斥锁 unlock(lockKey); } return shop; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
自写的,利用jmeter进行测试
@Override
public Result queryById(Long id) {
//互斥锁解决缓存击穿
Shop shop = queryWithNutex(id);
if (shop==null){
return Result.fail("店铺不存在1");
}
// 7.返回
return Result.ok(shop);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
总结用互斥锁解决缓存击穿
1.商户数据从redis中获得缓存,存在就返回。不存在发现是否为空值(判断缓存穿透)
2.实现缓存重构:
2.1 获得互斥锁(没有获得互斥锁,休眠,再调用方法回溯)
2.2 从数据库查询数据,(数据不存在写null值),存在写入缓存,释放锁
3.0 、利用逻辑过期解决缓存击穿问题
需求:修改根据id查询商铺的业务,基于逻辑过期方式来解决缓存击穿问题
思路分析:当用户开始查询redis时,判断是否命中,如果没有命中则直接返回空数据,不查询数据库,而一旦命中后,将value取出,判断value中的过期时间是否满足,如果没有过期,则直接返回redis中的数据,如果过期,则在开启独立线程后直接返回之前的数据,独立线程去重构数据,重构完成后释放互斥锁。
基于逻辑过期方式解决缓存击穿问题
- 需求:修改根据id查询商铺的业务,基于逻辑过期方式来解决缓存击穿问题

如果封装数据:因为现在redis中存储的数据的value需要带上过期时间,此时要么你去修改原来的实体类,要么你
步骤一、
新建一个实体类,我们采用第二个方案,这个方案,对原来代码没有侵入性。
@Data
public class RedisData {
private LocalDateTime expireTime;
private Object data;
}
- 1
- 2
- 3
- 4
- 5
步骤二、
在ShopServiceImpl 新增此方法,利用单元测试进行缓存预热
#
public void saveShop2Redis(Long id,Long expireSeconds){
//1.查询店铺的数据
Shop shop= getById(id);
//2.封装逻辑过期时间
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));
//3.写入Redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(redisData));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在测试类中
@Test
void testSaveShop(){
shopService.saveShop2Redis(1L,10L);
}
- 1
- 2
- 3
- 4
步骤三:正式代码
ShopServiceImpl
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10); public Shop queryWithLogicalExpire( Long id ) { String key = CACHE_SHOP_KEY + id; // 1.从redis查询商铺缓存 String json = stringRedisTemplate.opsForValue().get(key); // 2.判断是否存在 if (StrUtil.isBlank(json)) { // 3.存在,直接返回 return null; } // 4.命中,需要先把json反序列化为对象 RedisData redisData = JSONUtil.toBean(json, RedisData.class); Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class); LocalDateTime expireTime = redisData.getExpireTime(); // 5.判断是否过期 if(expireTime.isAfter(LocalDateTime.now())) { // 5.1.未过期,直接返回店铺信息 return shop; } // 5.2.已过期,需要缓存重建 // 6.缓存重建 // 6.1.获取互斥锁 String lockKey = LOCK_SHOP_KEY + id; boolean isLock = tryLock(lockKey); // 6.2.判断是否获取锁成功 if (isLock){ CACHE_REBUILD_EXECUTOR.submit( ()->{ try{ //重建缓存 this.saveShop2Redis(id,20L); }catch (Exception e){ throw new RuntimeException(e); }finally { unlock(lockKey); } }); } // 6.4.返回过期的商铺信息 return shop; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
# 自写 @Override public Result queryById(Long id) { //解决缓存穿透 // Shop shop = queryWithPassThrough(id); //互斥锁解决缓存击穿 // Shop shop = queryWithNutex(id); //逻辑过期解决缓存击穿 Shop shop=queryWithLogicalExpire(id); if (shop==null){ return Result.fail("店铺不存在1"); } // 7.返回 return Result.ok(shop); } //做一个线程池 private static final ExecutorService CACHE_REBULD_EXECUTOR= Executors.newFixedThreadPool(10); public Shop queryWithLogicalExpire(Long id){ String key =CACHE_SHOP_KEY + id; //1.从redis查询商铺缓存 String shopJson = stringRedisTemplate.opsForValue().get(key); //2.判断是否存在 if (StrUtil.isBlank(shopJson)){ //isnotBlank只有"abc"true,null "" \t\n都是false //3.不存在直接返回 return null; } //4.命中,先把json反序列化为对象, RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class); JSONObject data = (JSONObject)redisData.getData();//强转 Shop shop=JSONUtil.toBean(data,Shop.class);//因为之前的是RedisData.data是object类型 //合并为 // Shop shop=JSONUtil.toBean((JSONObject) redisData.getData(),Shop.class); LocalDateTime expireTime = redisData.getExpireTime(); //5判断是否过期 if (expireTime.isAfter(LocalDateTime.now())){ //5.1未过期,直接返回店铺信息 return shop; } //5.2已过期,需要缓存重建 //6.缓存重建 //6.1获得互斥锁 String lockkey=LOCK_SHOP_KEY+id; Boolean isLock = tryLock(lockkey); //6.2判断获取锁是否成功 if (isLock){ //6.3成功,开启新线程,实现缓存重建 CACHE_REBULD_EXECUTOR.submit(() ->{ try { this.saveShop2Redis(id,20L); } catch (Exception e) { throw new RuntimeException(e); } finally { //释放锁 unLock(lockkey); } }); //注意获取锁成功的时候应该再次检车redis缓存是否过期,做doublecheck //如果存在则无需重建缓存 } //6.4返回过期商铺信息 return shop; } private Boolean tryLock(String key){ Boolean flag = stringRedisTemplate.opsForValue(). setIfAbsent(key, "1", 10, TimeUnit.SECONDS); return BooleanUtil.isTrue(flag); } private void unLock(String key){ stringRedisTemplate.delete(key);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
总结逻辑过期解决缓存穿透
前期准备:
1.存入的redis数据,value是RedisDate封装类(含data属性(shop)和time(逻辑过期时间))
( redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));)
调用queryById(id)方法,进行逻辑过期的方法queryWithLogicalExpire(Long id)
查询redis中的数据,不存在直接返回(注意因为redisData没有设置ttl,如果没有就不存在)
存在,将缓存数据redisdata反序列化为对象,根据data获得shop
判断携带的逻辑过期时间与此刻时间比较,如果存在就返回
如果此刻时间已经过期,开始缓存重建
2.进行缓存重建
获得互斥锁,如果互斥锁获得不成功,返回旧数据。
获得互斥锁成功,开启新线程(从线程池中得到)
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
- 1
//6.3成功,开启新线程,实现缓存重建 CACHE_REBULD_EXECUTOR.submit(() ->{ try { this.saveShop2Redis(id,20L); } catch (Exception e) { throw new RuntimeException(e); } finally { //释放锁 unLock(lockkey); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
新线程执行 this.saveShop2Redis(id,20L);存入数据和逻辑过期时间到redis缓存
释放锁
关于返回值的问题:
submit:有返回值,返回值(包括异常)被封装于FutureTask对象。适用于有返回结果的任务。
execute:void类型的函数,没有返回值,适用于没有返回的任务。
关于异常处理的问题吗,在业务逻辑必定出异常的情况下:submit:submit的时候并不会抛出异常(此时线程可能处于就绪状态)。只有在get操作的时候会抛出。因为get操作会阻塞等待线程的执行完毕。
execute:在执行的时候会直接抛出。可以通过实现UncaughtExceptionHandler接口来完成异常的捕获。
3.1、封装Redis工具类
基于StringRedisTemplate封装一个缓存工具类,满足下列需求:
- 方法1:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
- 方法2:将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓
存击穿问题
- 方法3:根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透问题
- 方法4:根据指定的key查询缓存,并反序列化为指定类型,需要利用逻辑过期解决缓存击穿问题
将逻辑进行封装
@Slf4j @Component public class CacheClient { private final StringRedisTemplate stringRedisTemplate; private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10); public CacheClient(StringRedisTemplate stringRedisTemplate) { this.stringRedisTemplate = stringRedisTemplate; } public void set(String key, Object value, Long time, TimeUnit unit) { stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit); } public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit) { // 设置逻辑过期 RedisData redisData = new RedisData(); redisData.setData(value); redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time))); // 写入Redis stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData)); } public <R,ID> R queryWithPassThrough( String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit){ String key = keyPrefix + id; // 1.从redis查询商铺缓存 String json = stringRedisTemplate.opsForValue().get(key); // 2.判断是否存在 if (StrUtil.isNotBlank(json)) { // 3.存在,直接返回 return JSONUtil.toBean(json, type); } // 判断命中的是否是空值 if (json != null) { // 返回一个错误信息 return null; } // 4.不存在,根据id查询数据库 R r = dbFallback.apply(id); // 5.不存在,返回错误 if (r == null) { // 将空值写入redis stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES); // 返回错误信息 return null; } // 6.存在,写入redis this.set(key, r, time, unit); return r; } public <R, ID> R queryWithLogicalExpire( String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) { String key = keyPrefix + id; // 1.从redis查询商铺缓存 String json = stringRedisTemplate.opsForValue().get(key); // 2.判断是否存在 if (StrUtil.isBlank(json)) { // 3.存在,直接返回 return null; } // 4.命中,需要先把json反序列化为对象 RedisData redisData = JSONUtil.toBean(json, RedisData.class); R r = JSONUtil.toBean((JSONObject) redisData.getData(), type); LocalDateTime expireTime = redisData.getExpireTime(); // 5.判断是否过期 if(expireTime.isAfter(LocalDateTime.now())) { // 5.1.未过期,直接返回店铺信息 return r; } // 5.2.已过期,需要缓存重建 // 6.缓存重建 // 6.1.获取互斥锁 String lockKey = LOCK_SHOP_KEY + id; boolean isLock = tryLock(lockKey); // 6.2.判断是否获取锁成功 if (isLock){ // 6.3.成功,开启独立线程,实现缓存重建 CACHE_REBUILD_EXECUTOR.submit(() -> { try { // 查询数据库 R newR = dbFallback.apply(id); // 重建缓存 this.setWithLogicalExpire(key, newR, time, unit); } catch (Exception e) { throw new RuntimeException(e); }finally { // 释放锁 unlock(lockKey); } }); } // 6.4.返回过期的商铺信息 return r; } public <R, ID> R queryWithMutex( String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) { String key = keyPrefix + id; // 1.从redis查询商铺缓存 String shopJson = stringRedisTemplate.opsForValue().get(key); // 2.判断是否存在 if (StrUtil.isNotBlank(shopJson)) { // 3.存在,直接返回 return JSONUtil.toBean(shopJson, type); } // 判断命中的是否是空值 if (shopJson != null) { // 返回一个错误信息 return null; } // 4.实现缓存重建 // 4.1.获取互斥锁 String lockKey = LOCK_SHOP_KEY + id; R r = null; try { boolean isLock = tryLock(lockKey); // 4.2.判断是否获取成功 if (!isLock) { // 4.3.获取锁失败,休眠并重试 Thread.sleep(50); return queryWithMutex(keyPrefix, id, type, dbFallback, time, unit); } // 4.4.获取锁成功,根据id查询数据库 r = dbFallback.apply(id); // 5.不存在,返回错误 if (r == null) { // 将空值写入redis stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES); // 返回错误信息 return null; } // 6.存在,写入redis this.set(key, r, time, unit); } catch (InterruptedException e) { throw new RuntimeException(e); }finally { // 7.释放锁 unlock(lockKey); } // 8.返回 return r; } private boolean tryLock(String key) { Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS); return BooleanUtil.isTrue(flag); } private void unlock(String key) { stringRedisTemplate.delete(key); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
在ShopServiceImpl 中
@Resource private CacheClient cacheClient; @Override public Result queryById(Long id) { // 解决缓存穿透 Shop shop = cacheClient .queryWithPassThrough(CACHE_SHOP_KEY, id, Shop.class, this::getById, CACHE_SHOP_TTL, TimeUnit.MINUTES); // 互斥锁解决缓存击穿 // Shop shop = cacheClient // .queryWithMutex(CACHE_SHOP_KEY, id, Shop.class, this::getById, CACHE_SHOP_TTL, TimeUnit.MINUTES); // 逻辑过期解决缓存击穿 // Shop shop = cacheClient // .queryWithLogicalExpire(CACHE_SHOP_KEY, id, Shop.class, this::getById, 20L, TimeUnit.SECONDS); if (shop == null) { return Result.fail("店铺不存在!"); } // 7.返回 return Result.ok(shop); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
//Function<ID,R> dbFallback 是函数,参数ID ,返回值R
//isnotBlank只有"abc"true,null "" \t\n都是false
//lobandaB表达式 id2 -> getById(id2)简写this::getById
//4.命中,先把json反序列化为对象,
RedisData redisData = JSONUtil.toBean(json, RedisData.class);
JSONObject data = (JSONObject)redisData.getData();//强转
R r=JSONUtil.toBean(data,type);//因为之前的是RedisData.data是object类型
//合并为
// Shop shop=JSONUtil.toBean((JSONObject) redisData.getData(),Shop.class);
LocalDateTime expireTime = redisData.getExpireTime();
//5判断是否过期
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3、优惠卷秒杀
3.1 -全局唯一ID
每个店铺都可以发布优惠券:
全局ID生成器,是一种在分布式系统下用来生成全局唯一ID的工具,一般要满足下列特性:

为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其它信息:
8个字节,64个bit

ID的组成部分:符号位:1bit,永远为0
时间戳:31bit,以秒为单位,可以使用69年
序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
3.2 -Redis实现全局唯一Id
@Component public class RedisIdWorker { /** * 开始时间戳 */ private static final long BEGIN_TIMESTAMP = 1640995200L; /** * 序列号的位数 */ private static final int COUNT_BITS = 32; private StringRedisTemplate stringRedisTemplate; public RedisIdWorker(StringRedisTemplate stringRedisTemplate) { this.stringRedisTemplate = stringRedisTemplate; } public long nextId(String keyPrefix) { // 1.生成时间戳 LocalDateTime now = LocalDateTime.now(); long nowSecond = now.toEpochSecond(ZoneOffset.UTC); long timestamp = nowSecond - BEGIN_TIMESTAMP; // 2.生成序列号 // 2.1.获取当前日期,精确到天 String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd")); // 2.2.自增长 long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date); // 3.拼接并返回 return timestamp << COUNT_BITS | count; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
测试类
知识小贴士:关于countdownlatch
countdownlatch名为信号枪:主要的作用是同步协调在多线程的等待于唤醒问题
我们如果没有CountDownLatch ,那么由于程序是异步的,当异步程序没有执行完时,主线程就已经执行完了,然后我们期望的是分线程全部走完之后,主线程再走,所以我们此时需要使用到CountDownLatch
CountDownLatch 中有两个最重要的方法
1、countDown
2、await
await 方法 是阻塞方法,我们担心分线程没有执行完时,main线程就先执行,所以使用await可以让main线程阻塞,那么什么时候main线程不再阻塞呢?当CountDownLatch 内部维护的 变量变为0时,就不再阻塞,直接放行,那么什么时候CountDownLatch 维护的变量变为0 呢,我们只需要调用一次countDown ,内部变量就减少1,我们让分线程和变量绑定, 执行完一个分线程就减少一个变量,当分线程全部走完,CountDownLatch 维护的变量就是0,此时await就不再阻塞,统计出来的时间也就是所有分线程执行完后的时间。
@Test void testIdWorker() throws InterruptedException { CountDownLatch latch = new CountDownLatch(300); Runnable task = () -> { for (int i = 0; i < 100; i++) { long id = redisIdWorker.nextId("order"); System.out.println("id = " + id); } latch.countDown(); }; long begin = System.currentTimeMillis(); for (int i = 0; i < 300; i++) { es.submit(task); } latch.await(); long end = System.currentTimeMillis(); System.out.println("time = " + (end - begin)); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
#自写 package com.hmdp.utils; import lombok.extern.slf4j.Slf4j; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.stereotype.Component; import javax.annotation.Resource; import java.time.LocalDateTime; import java.time.ZoneOffset; import java.time.format.DateTimeFormatter; @Component @Slf4j public class RedisIdWorker2 { /** * 开始时间戳 * @param keyPrefix * @return */ private static final long BEGIN_TIMESTAMP=1640995200L; /** * 序列号的位数 */ private static final int COUNT_BITS=32; @Resource private StringRedisTemplate stringRedisTemplate; public long nextId(String keyPrefix){ //1.生成时间戳 LocalDateTime now = LocalDateTime.now(); long nowSecond = now.toEpochSecond(ZoneOffset.UTC); long timestamp = nowSecond - BEGIN_TIMESTAMP; //2.生成序列号 //2.1获取当前的日期,精确到天 String data = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd")); //2.2自增长 Long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + data); //3.拼接且返回 return timestamp << COUNT_BITS | count; //利用的是位运算,(UUID是16进制的长串值,是字符串而且不是自增,用的比较少) } // public static void main(String[] args) { // LocalDateTime time = LocalDateTime.of(2022, 1, 1, 0, 0); // long secend = time.toEpochSecond(ZoneOffset.UTC); // System.out.println(secend); // // // } } #测试 private ExecutorService es = Executors.newFixedThreadPool(300); @Resource private RedisIdWorker2 redisIdWorker2; /** * 自测 * @throws InterruptedException */ @Test void testIDwoker2() throws InterruptedException { CountDownLatch latch = new CountDownLatch(300); Runnable task=() ->{ for (int i = 0; i <100 ; i++) { long id = redisIdWorker2.nextId("order"); System.out.println("id="+id); } latch.countDown(); }; long begin = System.currentTimeMillis(); for (int i = 0; i <300 ; i++) { es.submit(task); } latch.await(); long end = System.currentTimeMillis(); System.out.println("time="+(end-begin)); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
总结生成订单号
1.利用8个字节,64个bits :0+31时间戳+32序列hao
2.利用时间戳,利用天数的自增长做序号
3.做位运算实现拼接
3.3 添加优惠卷
每个店铺都可以发布优惠券,分为平价券和特价券。平价券可以任意购买,而特价券需要秒杀抢购:
tb_voucher:优惠券的基本信息,优惠金额、使用规则等
tb_seckill_voucher:优惠券的库存、开始抢购时间,结束抢购时间。特价优惠券才需要填写这些信息
平价卷由于优惠力度并不是很大,所以是可以任意领取
而代金券由于优惠力度大,所以像第二种卷,就得限制数量,从表结构上也能看出,特价卷除了具有优惠卷的基本信息以外,还具有库存,抢购时间,结束时间等等字段
接下来我们来看@TableField(exist=false)的作用
比如在实体类中有一个属性为remark,但是在数据库中没有这个字段,但是在执行插入操作时给实体类的remark属性赋值了,那么可以通过在实体类的remark属性上添加
@TableField(exist=false) private String remark;
- 1
- 2
**新增普通卷代码: **VoucherController
@PostMapping
public Result addVoucher(@RequestBody Voucher voucher) {
voucherService.save(voucher);
return Result.ok(voucher.getId());
}
- 1
- 2
- 3
- 4
- 5
新增秒杀卷代码:
VoucherController
@PostMapping("seckill")
public Result addSeckillVoucher(@RequestBody Voucher voucher) {
voucherService.addSeckillVoucher(voucher);
return Result.ok(voucher.getId());
}
- 1
- 2
- 3
- 4
- 5
VoucherServiceImpl
@Override
@Transactional
public void addSeckillVoucher(Voucher voucher) {
// 保存优惠券
save(voucher);
// 保存秒杀信息
SeckillVoucher seckillVoucher = new SeckillVoucher();
seckillVoucher.setVoucherId(voucher.getId());
seckillVoucher.setStock(voucher.getStock());
seckillVoucher.setBeginTime(voucher.getBeginTime());
seckillVoucher.setEndTime(voucher.getEndTime());
seckillVoucherService.save(seckillVoucher);
// 保存秒杀库存到Redis中
stringRedisTemplate.opsForValue().set(SECKILL_STOCK_KEY + voucher.getId(), voucher.getStock().toString());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
#利用postman做增加优惠券
post http://localhost:8081/voucher/seckill
{
"shopId":1,
"title":"3300秒杀",
"subTitle":"周1",
"rules":"全场通用",
"payValue":8000,
"actualValue":10000,
"type":1,
"stock":200,
"beginTime":"2022-11-10T10:09:17",
"endTime":"2022-12-01T14:09:17"
}
注意这个endtime要长于你的真实事件,不然不显示
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.4 实现秒杀下单
下单时需要判断两点:
- 秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
- 库存是否充足,不足则无法下单
下单核心逻辑分析:
当用户开始进行下单,我们应当去查询优惠卷信息,查询到优惠卷信息,判断是否满足秒杀条件
比如时间是否充足,如果时间充足,则进一步判断库存是否足够,如果两者都满足,则扣减库存,创建订单,然后返回订单id,如果有一个条件不满足则直接结束。

VoucherOrderServiceImpl
@Override public Result seckillVoucher(Long voucherId) { // 1.查询优惠券 SeckillVoucher voucher = seckillVoucherService.getById(voucherId); // 2.判断秒杀是否开始 if (voucher.getBeginTime().isAfter(LocalDateTime.now())) { // 尚未开始 return Result.fail("秒杀尚未开始!"); } // 3.判断秒杀是否已经结束 if (voucher.getEndTime().isBefore(LocalDateTime.now())) { // 尚未开始 return Result.fail("秒杀已经结束!"); } // 4.判断库存是否充足 if (voucher.getStock() < 1) { // 库存不足 return Result.fail("库存不足!"); } //5,扣减库存 boolean success = seckillVoucherService.update() .setSql("stock= stock -1") .eq("voucher_id", voucherId).update(); if (!success) { //扣减库存 return Result.fail("库存不足!"); } //6.创建订单 VoucherOrder voucherOrder = new VoucherOrder(); // 6.1.订单id long orderId = redisIdWorker.nextId("order"); voucherOrder.setId(orderId); // 6.2.用户id Long userId = UserHolder.getUser().getId(); voucherOrder.setUserId(userId); // 6.3.代金券id voucherOrder.setVoucherId(voucherId); save(voucherOrder); return Result.ok(orderId); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
3.5 库存超卖问题分析
有关超卖问题分析:在我们原有代码中是这么写的
if (voucher.getStock() < 1) {
// 库存不足
return Result.fail("库存不足!");
}
//5,扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1")
.eq("voucher_id", voucherId).update();
if (!success) {
//扣减库存
return Result.fail("库存不足!");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
假设线程1过来查询库存,判断出来库存大于1,正准备去扣减库存,但是还没有来得及去扣减,此时线程2过来,线程2也去查询库存,发现这个数量一定也大于1,那么这两个线程都会去扣减库存,最终多个线程相当于一起去扣减库存,此时就会出现库存的超卖问题。


超卖问题是典型的多线程安全问题,针对这一问题的常见解决方案就是加锁:而对于加锁,我们通常有两种解决方案:见下图:
悲观锁:
悲观锁可以实现对于数据的串行化执行, Synchronized、Lock 都属于悲观锁都是悲观锁的代表,同时,悲观锁中又可以再细分为公平锁,非公平锁,可重入锁,等等
乐观锁:
认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时去判断有没有其它线程对数据做了修改。如果没有修改则认为是安全的,自己才更新数据。
如果已经被其它线程修改说明发生了安全问题,此时可以重试或异常
乐观锁的关键是判断之前查询得到的数据是否有被修改过,常见的处理方式有两种:版本号 和 CAS
乐观锁:会有一个版本号,每次操作数据会对版本号+1,再提交回数据时,会去校验是否比之前的版本大1 ,如果大1 ,则进行操作成功,这套机制的核心逻辑在于,如果在操作过程中,版本号只比原来大1 ,那么就意味着操作过程中没有人对他进行过修改,他的操作就是安全的,如果不大1,则数据被修改过,当然乐观锁还有一些变种的处理方式比如cas
CAS是英文单词
Compare And Swap的缩写,翻译过来就是比较并替换。
CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。
更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B。
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
- 1
- 2
- 3
- 4
- 5
- 6
课程中的使用方式:
课程中的使用方式是没有像cas一样带自旋的操作,也没有对version的版本号+1 ,他的操作逻辑是在操作时,对版本号进行+1 操作,然后要求version 如果是1 的情况下,才能操作,那么第一个线程在操作后,数据库中的version变成了2,但是他自己满足version=1 ,所以没有问题,此时线程2执行,线程2 最后也需要加上条件version =1 ,但是现在由于线程1已经操作过了,所以线程2,操作时就不满足version=1 的条件了,所以线程2无法执行成功
给数据添加一个 version,当该数据被修改时,version 数值就会被加一。
比如下图的情况:线程一修改过数据,version 已经变成了 2;线程二再去查找 version,发现已经不为 1 了,不会再修改数据了。

3.6 乐观锁解决超卖问题
修改代码方案一、
VoucherOrderServiceImpl 在扣减库存时,改为:
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1") //set stock = stock -1
.eq("voucher_id", voucherId).eq("stock",voucher.getStock()).update(); //where id = ? and stock = ?
- 1
- 2
- 3
以上逻辑的核心含义是:只要我扣减库存时的库存和之前我查询到的库存是一样的,就意味着没有人在中间修改过库存,那么此时就是安全的,但是以上这种方式通过测试发现会有很多失败的情况,失败的原因在于:在使用乐观锁过程中假设100个线程同时都拿到了100的库存,然后大家一起去进行扣减,但是100个人中只有1个人能扣减成功,其他的人在处理时,他们在扣减时,库存已经被修改过了,所以此时其他线程都会失败
修改代码方案二、
之前的方式要修改前后都保持一致,但是这样我们分析过,成功的概率太低,所以我们的乐观锁需要变一下,改成stock大于0 即可
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1")
.eq("voucher_id", voucherId).update().gt("stock",0); //where id = ? and stock > 0
- 1
- 2
- 3
知识小扩展:
针对cas中的自旋压力过大,我们可以使用Longaddr这个类去解决
Java8 提供的一个对AtomicLong改进后的一个类,LongAdder
大量线程并发更新一个原子性的时候,天然的问题就是自旋,会导致并发性问题,当然这也比我们直接使用syn来的好
所以利用这么一个类,LongAdder来进行优化
如果获取某个值,则会对cell和base的值进行递增,最后返回一个完整的值
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IozzPgqM-1671001492389)(.\Redis实战篇.assets\1653370271627.png)]
CAS的缺点:
1.CPU开销较大
在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复,会给CPU带来很大的压力。2.不能保证代码块的原子性
CAS机制所保证的只是一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证3个变量共同进行原子性的更新,就不得不使用Synchronized了。
3.6 优惠券秒杀-一人一单
需求:修改秒杀业务,要求同一个优惠券,一个用户只能下一单
现在的问题在于:
优惠卷是为了引流,但是目前的情况是,一个人可以无限制的抢这个优惠卷,所以我们应当增加一层逻辑,让一个用户只能下一个单,而不是让一个用户下多个单
具体操作逻辑如下:比如时间是否充足,如果时间充足,则进一步判断库存是否足够,然后再根据优惠卷id和用户id查询是否已经下过这个订单,如果下过这个订单,则不再下单,否则进行下单
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w3RMbaCk-1671001492390)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/一人一单.jpg)]
VoucherOrderServiceImpl
初步代码:增加一人一单逻辑
@Override public Result seckillVoucher(Long voucherId) { // 1.查询优惠券 SeckillVoucher voucher = seckillVoucherService.getById(voucherId); // 2.判断秒杀是否开始 if (voucher.getBeginTime().isAfter(LocalDateTime.now())) { // 尚未开始 return Result.fail("秒杀尚未开始!"); } // 3.判断秒杀是否已经结束 if (voucher.getEndTime().isBefore(LocalDateTime.now())) { // 尚未开始 return Result.fail("秒杀已经结束!"); } // 4.判断库存是否充足 if (voucher.getStock() < 1) { // 库存不足 return Result.fail("库存不足!"); } // 5.一人一单逻辑 // 5.1.用户id Long userId = UserHolder.getUser().getId(); int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count(); // 5.2.判断是否存在 if (count > 0) { // 用户已经购买过了 return Result.fail("用户已经购买过一次!"); } //6,扣减库存 boolean success = seckillVoucherService.update() .setSql("stock= stock -1") .eq("voucher_id", voucherId).update(); if (!success) { //扣减库存 return Result.fail("库存不足!"); } //7.创建订单 VoucherOrder voucherOrder = new VoucherOrder(); // 7.1.订单id long orderId = redisIdWorker.nextId("order"); voucherOrder.setId(orderId); voucherOrder.setUserId(userId); // 7.3.代金券id voucherOrder.setVoucherId(voucherId); save(voucherOrder); return Result.ok(orderId); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
**存在问题:**高并发的情况下,查询数据库时,都不存在订单,仍然会出现一人多单的情况,仍需加锁。乐观锁比较适合更新操作,此处的插入操作选择悲观锁。
**注意:**在这里提到了非常多的问题,我们需要慢慢的来思考,首先我们的初始方案是封装了一个createVoucherOrder方法,同时为了确保他线程安全。首先,初始方案是在 createVoucherOrder 方法上添加 synchronized,这样导致锁的粒度过大。
在seckillVoucher 方法中,添加以下逻辑,这样就能保证事务的特性,同时也控制了锁的粒度
public synchronized Result createVoucherOrder(Long voucherId) {
}
- 1
- 2
于是选择 “一个用户一把锁” 这样的方案。但是必须先保证 锁是同一把:userId.toString() 方法锁获取到的字符串是不同的对象,底层是 new 出来的,intern() 方法是从常量池里获取数据,保证了同一个用户的 userId.toString() 值相同。
@Transactional
@Override
public Result createVoucherOrder(Long voucherId) {
Long userId = UserHolder.getUser().getId();
synchronized(userId.toString().intern()) {
...
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
此外,还需要注意一个点,我们需要将 createVoucherOrder 方法整体包裹起来,确保事务不会出问题;否则会出现 “synchronized 包裹的代码片段执行完毕,事务还未提交,但是锁已经释放了” 的情况。
但是以上代码还是存在问题,问题的原因在于当前方法被spring的事务控制,如果你在方法内部加锁,可能会导致当前方法事务还没有提交,但是锁已经释放也会导致问题,所以我们选择将当前方法整体包裹起来,确保事务不会出现问题:如下:
synchronized (userId.toString().intern()) {
return createVoucherOrder(voucherId);
}
- 1
- 2
- 3
最后,createVoucherOrder 方法实际上是通过 this.createVoucherOrder() 的方式调用的,this 拿到的是原始对象,没有经过动态代理,事务要生效,需要使用代理对象来执行。
synchronized (userId.toString().intern()) {
// 获取代理对象
VoucherOrderService currentProxy = (VoucherOrderService) AopContext.currentProxy();
return currentProxy.createVoucherOrder(voucherId);
}
- 1
- 2
- 3
- 4
- 5
终极版本
@Override public Result seckillVoucher(Long voucherId) { // 1. 根据 优惠券 id 查询数据库 SeckillVoucher seckillVoucher = seckillVoucherService.getById(voucherId); // 2. 判断秒杀是否开始或结束(未开始或已结束,返回异常结果) if (LocalDateTime.now().isBefore(seckillVoucher.getBeginTime())) { return Result.fail("秒杀尚未开始.."); } if (LocalDateTime.now().isAfter(seckillVoucher.getEndTime())) { return Result.fail("秒杀已经结束.."); } // 3. 判断库存是否充足(不充足返回异常结果) if (seckillVoucher.getStock() < 1) { return Result.fail("库存不足.."); } Long userId = UserHolder.getUser().getId(); synchronized (userId.toString().intern()) { // 获取代理对象 VoucherOrderService currentProxy = (VoucherOrderService) AopContext.currentProxy(); return currentProxy.createVoucherOrder(voucherId); } } @Transactional @Override public Result createVoucherOrder(Long voucherId) { Long userId = UserHolder.getUser().getId(); // 4. 一人一单(根据 优惠券id 和 用户id 查询订单;存在,则直接返回) Integer count = query().eq("voucher_id", voucherId).eq("user_id", userId).count(); if (count > 0) { return Result.fail("不可重复下单!"); } // 5. 减扣库存 boolean isAccomplished = seckillVoucherService.update() // SET stock= stock - 1 .setSql("stock = stock - 1") // WHERE voucher_id = ? AND stock > 0 .eq("voucher_id", voucherId).gt("stock", 0) .update(); if (!isAccomplished) { return Result.fail("库存不足.."); } // 6. 创建订单 VoucherOrder voucherOrder = new VoucherOrder(); long orderId = redisIdWorker.nextId("order"); voucherOrder.setId(orderId); voucherOrder.setUserId(userId); voucherOrder.setVoucherId(voucherId); boolean isSaved = save(voucherOrder); if (!isSaved) { return Result.fail("下单失败.."); } // 7. 返回 订单 id return Result.ok(orderId); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
#自写 Long usrId = UserHolder.getUser().getId(); synchronized(usrId.toString().intern()) { IVoucherOrderService proxy = (IVoucherOrderService)AopContext.currentProxy(); return proxy.createVoucherOrder(voucherId); } //但是这个时候的事务优点问题调用的是this剩下,拿到当前的oder对象不是代理对象, // 所以没有事务功能,所以拿到事务的代理对象 同时在pom.xml引入依赖 <!-- https://mvnrepository.com/artifact/org.aspectj/aspectjweaver --> <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> <version>1.9.9.1</version> <scope>runtime</scope> </dependency> # 同时在springboot开注解 @EnableAspectJAutoProxy(exposeProxy = true)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rf3Ehjw7-1671001492391)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/一人一单的并发安全问题.jpg)]
总结超卖和一人一单
超卖:
悲观锁一定发生
乐观锁:认为线程安全不一定会发生因此不加锁,只是在更新数据时去判断有没有其它线程对数据做了修改。如果没有修改则认为是安全的,自己才更新数据。如果已经被其它线程修改说明发生了安全问题,此时可以重试或异常
乐观锁的关键是判断之前查询得到的数据是否有被修改过,常见的处理方式有两种:版本号 和 CAS
CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。
更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B。但是1.CPU开销较大
在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复,会给CPU带来很大的压力。2.不能保证代码块的原子性
CAS机制所保证的只是一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证3个变量共同进行原子性的更新,就不得不使用Synchronized了。
seckillVoucher(Long voucherId) 根据id查询数据库找到秒杀的券,判断时间,库存
获得当前用户,进入synchronized锁,
Long userId = UserHolder.getUser().getId(); synchronized (userId.toString().intern()) { // 获取代理对象 VoucherOrderService currentProxy = (VoucherOrderService) AopContext.currentProxy(); return currentProxy.createVoucherOrder(voucherId); }
- 1
- 2
- 3
- 4
- 5
- 6
(userId.toString() 方法锁获取到的字符串是不同的对象,底层是 new 出来的,intern() 方法是从常量池里获取数据,保证了同一个用户的 userId.toString() 值相同。
createVoucherOrder 方法实际上是通过 this.createVoucherOrder() 的方式调用的,this 拿到的是原始对象,没有经过动态代理,事务要生效,需要使用代理对象来执行。)
调用.createVoucherOrder(voucherId)方法,实现1人1单
查询当前用户,找数据库中是否已经存在订单。没有订单开始创建然后返回。
3.7 集群环境下的并发问题
通过加锁可以解决在单机情况下的一人一单安全问题,但是在集群模式下就不行了。
1、我们将服务启动两份,端口分别为8081和8082:
2、然后修改nginx的conf目录下的nginx.conf文件,配置反向代理和负载均衡:
具体操作(略)
# 自写
service找到该项目的/8081 ctrl+d 在VM options输入 -Dserver.port=8082
在not start 会找到两个,一起启动形成集群
一个81 一个80
#修改server之后如上
注意要把下面两个的注释修改,不然没用
#proxy_pass http://127.0.0.1:8081;
proxy_pass http://backend;
cmd中加载
nginx.exe -s reload
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
有关锁失效原因分析。
一人一单的集群环境下的并发安全问题
由于部署了多个 Tomcat,每个 Tomcat 中都有属于自己的 JVM。
在 服务器A 的 Tomcat 内部,有两个线程,这两个线程使用的是同一份代码,他们的锁对象是同一个,可以实现互斥(线程1 和 线程2);
在 服务器B 的 Tomcat 内部,有两个线程,这两个线程使用的是同一份代码,他们的锁对象是同一个,可以实现互斥(线程3 和 线程4);
线程1/2 和 线程3/4 使用的不是同一份代码,锁对象不是同一个,于是线程1/2 与 线程3/4 之间无法实现互斥;导致 synchronized 锁失效,这种情况下就需要 分布式锁 来解决。通过加锁可以解决在单机情况下的一人一单安全问题,但是在集群模式下就不行了(每个jvm都有自己的锁监视器,集群模式下各个服务器的锁不共享)。
因此,我们的解决方案就是实现一个共享的锁监视器,即:
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YsAYvuXC-1671001492392)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/一人一单的集群环境下并发的安全问题.jpg)]
4、分布式锁
4.1 、基本原理和实现方式对比
分布式锁:满足分布式系统或集群模式下的多进程可见并互斥的锁。
分布式锁的核心思想:所有线程都使用同一把锁,让程序串行执行。
分布式锁需要满足的条件
可见行:多个线程都能看到相同的结果,也就是感知到变化;
互斥:分布式锁的最基本条件,为了让程序串行执行;
高可用:保证程序不易崩溃;
高性能:加锁本身会让性能降低,因此需要分布式锁具有较高的加锁性能和释放锁性能;
安全性。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-beGRxl0N-1671001492395)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/分布式锁.jpg)]
常见的分布式锁有三种
常见的分布式锁
MySQL:MySQL 本身带有锁机制,但是由于 MySQL 性能一般,所以采用分布式锁的情况下,使用 MySQL 作为分布式锁比较少见。
Redis:Redis 作为分布式锁比较常见,利用 setnx 方法,如果 Key 插入成功,则表示获取到锁,插入失败则表示无法获取到锁。
Zookeeper:Zookeeper 也是企业级开发中比较好的一个实现分布式锁的方案。
| MySQL | Redis | Zookeeper | |
|---|---|---|---|
| 互斥 | 利用 MySQL 本身的互斥锁机制 | 利用 setnx 互斥命令 | 利用节点的唯一性和有序性 |
| 高可用 | 好 | 好 | 好 |
| 高性能 | 一般 | 好 | 一般 |
| 安全性 | 断开链接,自动释放锁 | 利用锁超时时间,到期释放 | 临时节点,断开链接自动释放 |
4.2 、Redis分布式锁的实现核心思路
实现分布式锁时需要实现的两个基本方法:
-
获取锁:
-
互斥:确保只能有一个线程获取锁
-
非阻塞:尝试一次,成功返回true,失败返回false
# 添加锁 NX 互斥 EX 设置超时时间 SET lock thread1 NX EX 10- 1
- 2
- 3
-
-
释放锁:
-
手动释放
-
超时释放:获取锁时添加一个超时时间
del key- 1
-
核心思路:
我们利用redis 的setNx 方法,当有多个线程进入时,我们就利用该方法,第一个线程进入时,redis 中就有这个key 了,返回了1,如果结果是1,则表示他抢到了锁,那么他去执行业务,然后再删除锁,退出锁逻辑,没有抢到锁的哥们,等待一定时间后重试即可
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uJ9oaLnz-1671001492396)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/基于 Redis 的分布式锁的实现思路.jpg)]
4.3 实现分布式锁版本
- 加锁逻辑
锁的基本接口
public interface DistributedLock {
/**
* 尝试获取锁
* @param timeoutSeconds 锁的超时时间,过期后自动释放
* @return true 代表获取锁成功;false 代表获取锁失败
*/
boolean tryLock(long timeoutSeconds);
/**
* 释放锁
*/
void unlock();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
SimpleRedisLock
利用setnx方法进行加锁,同时增加过期时间,防止死锁,此方法可以保证加锁和增加过期时间具有原子性
public class SimpleDistributedLockBasedOnRedis implements DistributedLock { private String name; private StringRedisTemplate stringRedisTemplate; public SimpleDistributedLockBasedOnRedis(String name, StringRedisTemplate stringRedisTemplate) { this.name = name; this.stringRedisTemplate = stringRedisTemplate; } private static final String KEY_PREFIX = "lock:"; @Override public boolean tryLock(long timeoutSeconds) { String threadName = Thread.currentThread().getId(); Boolean isSucceeded = stringRedisTemplate.opsForValue().setIfAbsent(KEY_PREFIX + name, threadName, timeoutSeconds, TimeUnit.SECONDS); return Boolean.TRUE.equals(isSucceeded); } @Override public void unlock() { stringRedisTemplate.delete(KEY_PREFIX + name); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
测试
将断点打到 “判断是否获取到锁” 处,发送两次 http://localhost:8080/api/voucher-order/seckill/10 请求,第一次请求打到 8081,第二次请求打到 8082。
8081 获取到的 isLocked 为 true,8082 获取到 isLocked 为 false;
Redis 中存储的 Key 为 lock:order:userId,Value 为 http-nio-8081-exec-1。
- 修改业务代码
@Override public Result seckillVoucher(Long voucherId) { // 1.查询优惠券 SeckillVoucher voucher = seckillVoucherService.getById(voucherId); // 2.判断秒杀是否开始 if (voucher.getBeginTime().isAfter(LocalDateTime.now())) { // 尚未开始 return Result.fail("秒杀尚未开始!"); } // 3.判断秒杀是否已经结束 if (voucher.getEndTime().isBefore(LocalDateTime.now())) { // 尚未开始 return Result.fail("秒杀已经结束!"); } // 4.判断库存是否充足 if (voucher.getStock() < 1) { // 库存不足 return Result.fail("库存不足!"); } Long userId = UserHolder.getUser().getId(); //创建锁对象(新增代码) SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate); //获取锁对象 boolean isLock = lock.tryLock(1200); //加锁失败 if (!isLock) { return Result.fail("不允许重复下单"); } try { //获取代理对象(事务) IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy(); return proxy.createVoucherOrder(voucherId); } finally { //释放锁 lock.unlock(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
将rediss锁代替悲观锁
4.4 Redis分布式锁误删情况说明
逻辑说明:
线程1 获取到锁,持有锁的线程碰到了业务阻塞,业务阻塞的时间超过了该锁的超时时间,触发锁的超时释放。
此时,线程2 获取到锁,执行业务;在线程2 执行业务的过程中,线程1 的业务执行完毕并且释放锁,但是释放的是线程2 的锁。
之后,线程3 获取到锁,执行业务;导致此时有两个线程同时在并行执行业务。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oca9TgJ4-1671001492397)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/Redis 分布式锁的误删问题.jpg)]
解决方案:
解决方案:在每个线程释放锁的时候,需要判断一下当前这把锁是否属于自己,如果不属于自己,就不会进行锁的释放(删除)。
线程1 获取到锁,持有锁的线程碰到了业务阻塞,业务阻塞的时间超过了该锁的超时时间,触发锁的超时释放。
此时,线程2 获取到锁,执行业务;在线程2 执行业务的过程中,线程1 的业务执行完毕并且释放锁,但是此时线程1 需要判断当前这把锁是否属于自己,不属于则不会删除锁。于是线程2 一直持有这把锁直至其业务执行结束后才会释放,并且在释放的时候也需要判断当前要释放的锁是否属于自己。
之后,线程3 获取到锁,执行业务。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pbZqzViX-1671001492398)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/解决Redis 分布式锁误删问题.jpg)]
4.5 解决Redis分布式锁误删问题
核心逻辑:在存入锁时,放入自己线程的标识,在删除锁时,判断当前这把锁的标识是不是自己存入的,如果是,则进行删除,如果不是,则不进行删除。
改进 Redis 分布式锁:
- 在获取锁的时候存入线程标识(用 UUID 表示);
- 在释放锁时先获取锁中的线程标识,判断是否与当前的线程标识一致;
- 一致则释放锁;
- 不一致则不释放锁。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P1GfsTLF-1671001492399)(.\Redis实战篇.assets\1653387398820.png)]
具体代码如下:加锁
private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-";
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
释放锁
public void unlock() {
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁中的标示
String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
// 判断标示是否一致
if(threadId.equals(id)) {
// 释放锁
stringRedisTemplate.delete(KEY_PREFIX + name);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
public class SimpleDistributedLockBasedOnRedis implements DistributedLock { private String name; private StringRedisTemplate stringRedisTemplate; public SimpleDistributedLockBasedOnRedis(String name, StringRedisTemplate stringRedisTemplate) { this.name = name; this.stringRedisTemplate = stringRedisTemplate; } private static final String KEY_PREFIX = "lock:"; private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-"; /** * 获取锁 */ @Override public boolean tryLock(long timeoutSeconds) { // 线程标识 String threadIdentifier = ID_PREFIX + Thread.currentThread().getId(); Boolean isSucceeded = stringRedisTemplate.opsForValue() .setIfAbsent(KEY_PREFIX + name, threadIdentifier, timeoutSeconds, TimeUnit.SECONDS); return Boolean.TRUE.equals(isSucceeded); } /** * 释放锁 */ @Override public void unlock() { // 线程标识 String threadIdentifier = ID_PREFIX + Thread.currentThread().getId(); String threadIdentifierFromRedis = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name); // 比较 锁中的线程标识 与 当前的线程标识 是否一致 if (StrUtil.equals(threadIdentifier, threadIdentifierFromRedis)) { // 释放锁标识 stringRedisTemplate.delete(KEY_PREFIX + name); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
有关代码实操说明:
在我们修改完此处代码后,我们重启工程,然后启动两个线程,第一个线程持有锁后,手动释放锁,第二个线程 此时进入到锁内部,再放行第一个线程,此时第一个线程由于锁的value值并非是自己,所以不能释放锁,也就无法删除别人的锁,此时第二个线程能够正确释放锁,通过这个案例初步说明我们解决了锁误删的问题。
4.6 分布式锁的原子性问题
分布式锁的原子性问题
线程1 执行业务并且判断 “当前 Redis 中的线程标识 与 获取锁时存入 Redis 的线程标识” 一致后,执行 释放锁操作 时出现阻塞,导致锁并未释放。在阻塞的过程中,又因为超时原因导致锁的释放。
此时 线程2 获取到锁,并且执行业务,执行业务的过程锁被中线程 1 释放。
于是 线程3 也能够获取到锁,并且执行业务。最终,又一次导致此时有两个线程同时在并行执行业务。
因此,需要保证 “判断线程标识的一致性 与 释放锁” 操作的原子性。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rZKFNtod-1671001492399)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/分布式锁的原子性问题.jpg)]
4.7 Lua脚本解决多条命令原子性问题
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。Lua是一种编程语言,它的基本语法大家可以参考网站:https://www.runoob.com/lua/lua-tutorial.html,这里重点介绍Redis提供的调用函数,我们可以使用lua去操作redis,又能保证他的原子性,这样就可以实现拿锁比锁删锁是一个原子性动作了,作为Java程序员这一块并不作一个简单要求,并不需要大家过于精通,只需要知道他有什么作用即可。
这里重点介绍Redis提供的调用函数,语法如下:
redis.call('命令名称', 'key', '其它参数', ...)
- 1
例如,我们要执行set name jack,则脚本是这样:
# 执行 set name jack
redis.call('set', 'name', 'jack')
- 1
- 2
例如,我们要先执行set name Rose,再执行get name,则脚本如下:
# 先执行 set name jack
redis.call('set', 'name', 'Rose')
# 再执行 get name
local name = redis.call('get', 'name')
# 返回
return name
- 1
- 2
- 3
- 4
- 5
- 6
编写完脚本后,需要使用 Redis 命令来调用脚本:EVAL script numkeys key [key ...] arg [arg ...]
-
执行
redis.call('set', 'name', 'Michael')# 双引号中间的值为 脚本;后面的 0 代表的是 脚本需要的 Key 类型的参数个数 127.0.0.1:6379> EVAL "return redis.call('set', 'name', 'Michael')" 0 OK 127.0.0.1:6379> get name "Michael"- 1
- 2
- 3
- 4
- 5
如果脚本中的key、value不想写死,可以作为参数传递。key类型参数会放入KEYS数组,其它参数会放入ARGV数组,在脚本中可以从KEYS和ARGV数组获取这些参数:
# name ==> KEYS[1] 、Annabelle ==> ARGV[1] (Lua 的数组下标从 1 开始)
127.0.0.1:6379> EVAL "return redis.call('set', KEYS[1], ARGV[1])" 1 name Annabelle
OK
127.0.0.1:6379> get name
"Annabelle"
- 1
- 2
- 3
- 4
- 5
- 6
接下来我们来回一下我们释放锁的逻辑:
#自写
EVAL "return redis.call('set','name','jack')" 0
EVAL "return redis.call('set',KEYS[1],ARGV[1])" 1 name rose
- 1
- 2
- 3
- 4
- 5
释放锁的业务流程是这样的
1、获取锁中的线程标示
2、判断是否与指定的标示(当前线程标示)一致
3、如果一致则释放锁(删除)
4、如果不一致则什么都不做
如果用Lua脚本来表示则是这样的:
最终我们操作redis的拿锁比锁删锁的lua脚本就会变成这样
-- 这里的 KEYS[1] 就是锁的key,这里的ARGV[1] 就是当前线程标示
-- 获取锁中的标示,判断是否与当前线程标示一致
if (redis.call('GET', KEYS[1]) == ARGV[1]) then
-- 一致,则删除锁
return redis.call('DEL', KEYS[1])
end
-- 不一致,则直接返回
return 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.8 利用Java代码调用Lua脚本改造分布式锁
lua脚本本身并不需要大家花费太多时间去研究,只需要知道如何调用,大致是什么意思即可,所以在笔记中并不会详细的去解释这些lua表达式的含义。
我们的RedisTemplate中,可以利用execute方法去执行lua脚本,参数对应关系就如下图股
-- 锁的 Key -- local key = "lock:order:10" -- local key = KEYS[1] -- 最初存入 Redis 中的线程标识 -- local threadIdentifier = "uuid-http-nio-8081-exec-1" -- local threadIdentifier = ARGV[1] -- 锁中的线程标识 local threadIdentifierFromRedis = redis.call('get', KEYS[1]) -- 比较 最初存入 Redis 中的线程标识 与 目前 Redis 中存储的线程标识 是否一致 if (threadIdentifierFromRedis == ARGV[1]) then -- 一致,则释放锁 del key return redis.call('del', KEYS[1]) end -- 若不一致,则返回 0 return 0 -- 比较线程标示与锁中的标示是否一致 if(redis.call('get', KEYS[1]) == ARGV[1]) then -- 释放锁 del key return redis.call('del', KEYS[1]) end return 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
Java代码
经过以上代码改造后,我们就能够实现 拿锁比锁删锁的原子性动作了~ ublic class SimpleRedisLock implements ILock { private String name; private StringRedisTemplate stringRedisTemplate; public SimpleRedisLock(String name, StringRedisTemplate stringRedisTemplate) { this.name = name; this.stringRedisTemplate = stringRedisTemplate; } private static final String KEY_PREFIX = "lock:"; private static final String ID_PREFIX = UUID.randomUUID().toString(true) + "-"; private static final DefaultRedisScript<Long> UNLOCK_SCRIPT; #基本用的static代码块进行加载 static { UNLOCK_SCRIPT = new DefaultRedisScript<>(); UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua")); UNLOCK_SCRIPT.setResultType(Long.class); } @Override public boolean tryLock(long timeoutSec) { // 获取线程标示 String threadId = ID_PREFIX + Thread.currentThread().getId(); // 获取锁 Boolean success = stringRedisTemplate.opsForValue() .setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS); return Boolean.TRUE.equals(success); } @Override public void unlock() { // 调用lua脚本 stringRedisTemplate.execute( UNLOCK_SCRIPT, // SCRIPT Collections.singletonList(KEY_PREFIX + name), // KEY[1] ID_PREFIX + Thread.currentThread().getId() // ARGV[1] } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
小总结:
基于Redis的分布式锁实现思路:
- 利用set nx ex获取锁,并设置过期时间,保存线程标示
- 释放锁时先判断线程标示是否与自己一致,一致则删除锁
- 特性:
- 利用set nx满足互斥性
- 利用set ex保证故障时锁依然能释放,避免死锁,提高安全性
- 利用Redis集群保证高可用和高并发特性
- 特性:
笔者总结:我们一路走来,利用添加过期时间,防止死锁问题的发生,但是有了过期时间之后,可能出现误删别人锁的问题,这个问题我们开始是利用删之前 通过拿锁,比锁,删锁这个逻辑来解决的,也就是删之前判断一下当前这把锁是否是属于自己的,但是现在还有原子性问题,也就是我们没法保证拿锁比锁删锁是一个原子性的动作,最后通过lua表达式来解决这个问题
测试逻辑:
第一个线程进来,得到了锁,手动删除锁,模拟锁超时了,其他线程会执行lua来抢锁,当第一天线程利用lua删除锁时,lua能保证他不能删除他的锁,第二个线程删除锁时,利用lua同样可以保证不会删除别人的锁,同时还能保证原子性。
总结分布式锁:
redis锁代替悲观锁,解决分布式锁的问题(创建新的simpleredislock对象+代理对象调用方法)
此时出现问题删除锁的时候多线程可能出现锁的误删
在获取锁的时候存入线程标识(用 UUID 表示);
在释放锁时先获取锁中的线程标识,判断是否与当前的线程标识一致;
出现问题“判断线程标识的一致性 与 释放锁” 操作的需要原子性。
用lua脚本执行多条命令的原子性
在判断线程标识和释放锁的操作是lua脚本保证原子性
5、分布式锁-redission
5.1 分布式锁-redission功能介绍
基于setnx实现的分布式锁存在下面的问题:
重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁。假设在 方法A 中调用 方法B。方法A 中,需要先获取锁,执行业务、调用方法B;而方法B 中,又需要获取同一把锁。
此时如果是不可重入锁,调用方法B 时无法获取锁,就会等待锁的释放,而锁无法释放,因为 方法A 还没有执行完毕,造成死锁。所以可重入锁他的主要意义是防止死锁,我们的synchronized和Lock锁都是可重入的。
不可重试:是指目前的分布式只能尝试一次,我们认为合理的情况是:当线程在获得锁失败后,他应该能再次尝试获得锁。
**超时释放:**我们在加锁时增加了过期时间,这样的我们可以防止死锁,但是如果卡顿的时间超长,虽然我们采用了lua表达式防止删锁的时候,误删别人的锁,但是如果锁住的时间太长导致其他线程都在等待,或者锁住的时间太短导致业务未执行完毕锁就释放等隐患。
主从一致性: 如果Redis提供了主从集群,当我们向集群写数据时,主机需要异步的将数据同步给从机,而万一在同步过去之前,主机宕机了,就会出现死锁问题。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zPRfe258-1671001492407)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/基于 setnx 实现的分布式锁存在的问题.jpg)]
Redisson 是一个在 Redis 基础上实现的分布式工具集合。
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
Redission提供了分布式锁的多种多样的功能
Redisson 是一个在 Redis 的基础上实现的 Java 驻内存数据网格(In-Memory Data Grid)。
它不仅提供了一系列的分布式的 Java 常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
分布式锁(Lock)和同步器(Synchronizer)
可重入锁(Reentrant Lock)
公平锁(Fair Lock)
联锁(MultiLock)
红锁(RedLock)
读写锁(ReadWriteLock)
信号量(Semaphore)
可过期性信号量(PermitExpirableSemaphore)
闭锁(CountDownLatch)
5.2 分布式锁-Redission快速入门
1.引入依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
2.配置Redisson客户端:
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
// 配置类
Config config = new Config();
// 添加 Redis 地址:此处是单节点地址,也可以通过 config.useClusterServers() 添加集群地址
config.useSingleServer().setAddress("182.168.8.130:6379").setPassword("yangroot");
// 创建客户端
return Redisson.create(config);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.如何使用Redission的分布式锁
按照名称返回 Lock 实例:RLock lock = redissonClient.getLock(name);
尝试获取锁:boolean isLocked = lock.tryLock(1, 10, TimeUnit.SECONDS);
获取锁失败,失败后的最大等待时间,期间会重试:默认为 -1,即不等待;
锁的自动施放时间:30;
时间单位:秒。
@Resource private RedissionClient redissonClient; @Test void testRedisson() throws Exception{ //获取锁(可重入),指定锁的名称 RLock lock = redissonClient.getLock("anyLock"); //尝试获取锁,参数分别是:获取锁的最大等待时间(期间会重试),锁自动释放时间,时间单位 boolean isLock = lock.tryLock(1,10,TimeUnit.SECONDS); //判断获取锁成功 if(isLock){ try{ System.out.println("执行业务"); }finally{ //释放锁 lock.unlock(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
在 VoucherOrderServiceImpl
注入RedissonClient
@Resource private RedissonClient redissonClient; @Override public Result seckillVoucher(Long voucherId) { // 1.查询优惠券 SeckillVoucher voucher = seckillVoucherService.getById(voucherId); // 2.判断秒杀是否开始 if (voucher.getBeginTime().isAfter(LocalDateTime.now())) { // 尚未开始 return Result.fail("秒杀尚未开始!"); } // 3.判断秒杀是否已经结束 if (voucher.getEndTime().isBefore(LocalDateTime.now())) { // 尚未开始 return Result.fail("秒杀已经结束!"); } // 4.判断库存是否充足 if (voucher.getStock() < 1) { // 库存不足 return Result.fail("库存不足!"); } Long userId = UserHolder.getUser().getId(); //创建锁对象 这个代码不用了,因为我们现在要使用分布式锁 //SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate); RLock lock = redissonClient.getLock("lock:order:" + userId); //获取锁对象 boolean isLock = lock.tryLock(); 参数可以三个,第一个重试时间,释放锁,单位 //加锁失败 if (!isLock) { return Result.fail("不允许重复下单"); } try { //获取代理对象(事务) IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy(); return proxy.createVoucherOrder(voucherId); } finally { //释放锁 lock.unlock(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
5.3 分布式锁-redission可重入锁原理
在Lock锁中,他是借助于底层的一个voaltile的一个state变量来记录重入的状态的,比如当前没有人持有这把锁,那么state=0,假如有人持有这把锁,那么state=1,如果持有这把锁的人再次持有这把锁,那么state就会+1 ,如果是对于synchronized而言,他在c语言代码中会有一个count,原理和state类似,也是重入一次就加一,释放一次就-1 ,直到减少成0 时,表示当前这把锁没有被人持有。
在redission中,我们的也支持支持可重入锁
在分布式锁中,他采用hash结构用来存储锁,其中大key表示这把锁是否存在,用小key表示当前这把锁被哪个线程持有,所以接下来我们一起分析一下当前的这个lua表达式
这个地方一共有3个参数
KEYS[1] : 锁名称
ARGV[1]: 锁失效时间
ARGV[2]: id + “:” + threadId; 锁的小key
exists: 判断数据是否存在 name:是lock是否存在,如果==0,就表示当前这把锁不存在
redis.call(‘hset’, KEYS[1], ARGV[2], 1);此时他就开始往redis里边去写数据 ,写成一个hash结构
Lock{
id + **":"** + threadId : 1
}
- 1
- 2
- 3
- 4
如果当前这把锁存在,则第一个条件不满足,再判断
redis.call(‘hexists’, KEYS[1], ARGV[2]) == 1
此时需要通过大key+小key判断当前这把锁是否是属于自己的,如果是自己的,则进行
redis.call(‘hincrby’, KEYS[1], ARGV[2], 1)
将当前这个锁的value进行+1 ,redis.call(‘pexpire’, KEYS[1], ARGV[1]); 然后再对其设置过期时间,如果以上两个条件都不满足,则表示当前这把锁抢锁失败,最后返回pttl,即为当前这把锁的失效时间
如果小伙帮们看了前边的源码, 你会发现他会去判断当前这个方法的返回值是否为null,如果是null,则对应则前两个if对应的条件,退出抢锁逻辑,如果返回的不是null,即走了第三个分支,在源码处会进行while(true)的自旋抢锁。
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
之前jdk的之前判断,是否同一个线程,会记录线程的标识和重入次数+1
释放锁的时候将value-1,还要判断是否value=0
用hash结构
所以需要lua脚本保证完整性
locak key-=KEYS[1]; -- 锁的key locak ThreadID-=AGRV[1]; -- 线程的唯一标识 local releaseTime=AGRV[2];-- 锁的自动释放时间 --locak key-=KEYS[1]; -- 锁的key --locak ThreadID-=AGRV[1]; -- 线程的唯一标识 --local releaseTime=AGRV[2];-- 锁的自动释放时间 if(redis.call('exists',key) ==0) then --不存在获取锁 redis.call('hset',key,ThreadID,'1'); --设置有效期 redis.call('expire',key,releaseTime); return 1;--返回结果 end; --锁已经存在判断是否是自己的 if(redis.call('hexists',key,ThreadID) ==1) then --是自己,获取锁,重入次数+1 redis.call('hincrby',key,ThreadID,'1'); --设置有效期 redis.call('expire',key,releaseTime); return 1;--返回结果 end; return 0; --不是自己的锁
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
-- 释放锁
if(redis.call('HEXISTS',key,ThreadID)==0) then
return nil; --如果已经不是自己的,直接返回
end;
--是自己的锁,重入次数-1
local count=redis.call('HINCRBY',key,ThreadID,-1);
--判断是否重入的次数已经位0
if(count >0) then
--大于0说明不能释放锁,重置有效期然后返回
redis.call('EXPIRE',key,releaseTime);
return nil;
else --等于0说明可以释放锁
redis.call('DEL',key);
return nil;
end;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
@Slf4j @SpringBootTest public class RedissonTest { @Resource private RedissonClient redissonClient; private RLock lock; @BeforeEach // 创建 Lock 实例(可重入) void setUp() { lock = redissonClient.getLock("anyLock"); } @Test void methodOne() throws InterruptedException { boolean isLocked = lock.tryLock(); if (!isLocked) { log.error("Fail To Get Lock~"); return; } try { log.info("Get Lock Successfully~"); methodTwo(); } finally { log.info("Release Lock~"); lock.unlock(); } } @Test void methodTwo() throws InterruptedException { boolean isLocked = lock.tryLock(); if (!isLocked) { log.error("Fail To Get Lock!"); return; } try { log.info("Get Lock Successfully!"); } finally { log.info("Release Lock!"); lock.unlock(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
可重入锁的实现思路
- 在 Lock 锁中,借助于一个 state 变量来记录重入的状态,如果当前没有人持有该把锁,state = 0;若有人持有该把锁,state = 1;如果持有该把锁的人再次持有这把锁,state + 1。
- 对于 synchronized 而言,底层 C 语言代码中有一个 count,与 state 原理类似,重入一次加一,释放一次减一,直至为 0,表示当前这把锁无人持有。
- 释放锁(删除)的时机:state 为 0。
- 采用 Hash 结构存储锁:Key 中存储锁名称、Field 中存储线程标识、Value 中存储重入数,即 state。
使用 可重入锁 执行上述代码:methodOne() 中获取到锁后 state + 1 ==> state = 1;调用 methodTwo(),在 methodTwo() 中获取到锁后再次 state + 1 ===> state = 2;
methodTwo() 中执行业务后释放锁 state - 1 ===> state = 1;methodOne() 中执行业务后 state - 1 ===> state = 0,此时 Redis 中的锁已经被删除。
5.4 分布式锁-redission锁重试和WatchDog机制
锁重试
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x2TUL0zg-1671001492409)(http://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/Redisson%23tryLock%20%E9%94%81%E9%87%8D%E8%AF%95.png)]
说明:由于课程中已经说明了有关tryLock的源码解析以及其看门狗原理,所以笔者在这里给大家分析lock()方法的源码解析,希望大家在学习过程中,能够掌握更多的知识
抢锁过程中,获得当前线程,通过tryAcquire进行抢锁,该抢锁逻辑和之前逻辑相同
1、先判断当前这把锁是否存在,如果不存在,插入一把锁,返回null
2、判断当前这把锁是否是属于当前线程,如果是,则返回null
所以如果返回是null,则代表着当前这哥们已经抢锁完毕,或者可重入完毕,但是如果以上两个条件都不满足,则进入到第三个条件,返回的是锁的失效时间,同学们可以自行往下翻一点点,你能发现有个while( true) 再次进行tryAcquire进行抢锁
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(-1, leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return;
}
- 1
- 2
- 3
- 4
- 5
- 6
接下来会有一个条件分支,因为lock方法有重载方法,一个是带参数,一个是不带参数,如果带带参数传入的值是-1,如果传入参数,则leaseTime是他本身,所以如果传入了参数,此时leaseTime != -1 则会进去抢锁,抢锁的逻辑就是之前说的那三个逻辑
if (leaseTime != -1) {
return tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
- 1
- 2
- 3
如果是没有传入时间,则此时也会进行抢锁, 而且抢锁时间是默认看门狗时间 commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout()
ttlRemainingFuture.onComplete((ttlRemaining, e) 这句话相当于对以上抢锁进行了监听,也就是说当上边抢锁完毕后,此方法会被调用,具体调用的逻辑就是去后台开启一个线程,进行续约逻辑,也就是看门狗线程
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(waitTime,
commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(),
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) {
return;
}
// lock acquired
if (ttlRemaining == null) {
scheduleExpirationRenewal(threadId);
}
});
return ttlRemainingFuture;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
此逻辑就是续约逻辑,注意看commandExecutor.getConnectionManager().newTimeout() 此方法
Method( new TimerTask() {},参数2 ,参数3 )
指的是:通过参数2,参数3 去描述什么时候去做参数1的事情,现在的情况是:10s之后去做参数一的事情
因为锁的失效时间是30s,当10s之后,此时这个timeTask 就触发了,他就去进行续约,把当前这把锁续约成30s,如果操作成功,那么此时就会递归调用自己,再重新设置一个timeTask(),于是再过10s后又再设置一个timerTask,完成不停的续约
那么大家可以想一想,假设我们的线程出现了宕机他还会续约吗?当然不会,因为没有人再去调用renewExpiration这个方法,所以等到时间之后自然就释放了。
WatchDog
对抢锁过程进行监听,抢锁完毕后,scheduleExpirationRenewal(threadId) 方法会被调用来对锁的过期时间进行续约,在后台开启一个线程,进行续约逻辑,也就是看门狗线程。
// 续约逻辑
commandExecutor.getConnectionManager().newTimeout(new TimerTask() {... }, 锁失效时间 / 3, TimeUnit.MILLISECONDS);
Method(new TimerTask(){}, 参数2, 参数3)
- 1
- 2
- 3
- 4
- 5
通过参数2、参数3 去描述,什么时候做参数1 的事情。
锁的失效时间为 30s,10s 后这个 TimerTask 就会被触发,于是进行续约,将其续约为 30s;
若操作成功,则递归调用自己,重新设置一个 TimerTask 并且在 10s 后触发;循环往复,不停的续约
private void renewExpiration() { ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName()); if (ee == null) { return; } Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() { @Override public void run(Timeout timeout) throws Exception { ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName()); if (ent == null) { return; } Long threadId = ent.getFirstThreadId(); if (threadId == null) { return; } RFuture<Boolean> future = renewExpirationAsync(threadId); future.onComplete((res, e) -> { if (e != null) { log.error("Can't update lock " + getName() + " expiration", e); return; } if (res) { // reschedule itself renewExpiration(); } }); } }, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS); ee.setTimeout(task); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
#自写
Radisson分布式锁原理:
可重入:利用hash结构记录线程id和重入次数
可重试:利用信号量和PubSub功能实现等待、唤醒,获取锁失败的重试机制
超时续约:利用watchDog,每隔一段时间(releaseTime / 3),重置超时时间
- 1
- 2
- 3
- 4
- 5
- 6
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aDju53DV-1671001492410)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/Redisson%20%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81%E5%8E%9F%E7%90%86.jpg)]
总结redission分布式锁
1.引入依赖
2.配置redission客户端
@Configuration public class RedissonConfig { @Bean public RedissonClient redissonClient(){ // 配置类 Config config = new Config(); // 添加 Redis 地址:此处是单节点地址,也可以通过 config.useClusterServers() 添加集群地址 config.useSingleServer().setAddress("182.168.8.130:6379").setPassword("yangroot"); // 创建客户端 return Redisson.create(config); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.将原来的simpleredislocky锁换成redissonClient.getLock();
// 创建锁对象 RLock redisLock = redissonClient.getLock("lock:order:" + userId); // 尝试获取锁 boolean isLock = redisLock.tryLock();
- 1
- 2
- 3
- 4
1.redissonClient 将Hash结构存储锁,key是判断锁是否存在,小key 判断这个锁是否是自己的,value判断入重数
(Key 中存储锁名称、Field 中存储线程标识、Value 中存储重入数,即 state)
可重入:利用hash结构记录线程id和重入次数
可重试:利用信号量和PubSub功能实现等待、唤醒,获取锁失败的重试机制
超时续约:利用watchDog,每隔一段时间(releaseTime /3),重置超时时间3.可重试:
1.抢锁过程中,获得当前线程,通过tryAcquire进行抢锁,该抢锁逻辑和之前逻辑相同
1、先判断当前这把锁是否存在,如果不存在,插入一把锁,返回null
2、判断当前这把锁是否是属于当前线程,如果是,则返回null
所以如果返回是null,则代表着当前这哥们已经抢锁完毕,或者可重入完毕,但是如果以上两个条件都不满足,则进入到第三个条件,返回的是锁的失效时间,while( true) 再次进行tryAcquire进行抢锁
接下来会有一个条件分支,因为lock方法有重载方法,一个是带参数,一个是不带参数,如果带带参数传入的值是-1,如果传入参数,则leaseTime是他本身,所以如果传入了参数,此时leaseTime != -1 则会进去抢锁,抢锁的逻辑就是之前说的那三个逻辑
如果是没有传入时间,则此时也会进行抢锁, 而且抢锁时间是默认看门狗时间 commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout()
ttlRemainingFuture.onComplete((ttlRemaining, e) 这句话相当于对以上抢锁进行了监听,也就是说当上边抢锁完毕后,此方法会被调用,具体调用的逻辑就是去后台开启一个线程,进行续约逻辑,也就是看门狗线程
5.5 分布式锁-redission锁的MutiLock原理
为了提高redis的可用性,我们会搭建集群或者主从,现在以主从为例
此时我们去写命令,写在主机上, 主机会将数据同步给从机,但是假设在主机还没有来得及把数据写入到从机去的时候,此时主机宕机,哨兵会发现主机宕机,并且选举一个slave变成master,而此时新的master中实际上并没有锁信息,此时锁信息就已经丢掉了。
为了解决这个问题,redission提出来了MutiLock锁,使用这把锁咱们就不使用主从了,每个节点的地位都是一样的, 这把锁加锁的逻辑需要写入到每一个主丛节点上,只有所有的服务器都写入成功,此时才是加锁成功,假设现在某个节点挂了,那么他去获得锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性。
那么MutiLock 加锁原理是什么呢?笔者画了一幅图来说明
当我们去设置了多个锁时,redission会将多个锁添加到一个集合中,然后用while循环去不停去尝试拿锁,但是会有一个总共的加锁时间,这个时间是用需要加锁的个数 * 1500ms ,假设有3个锁,那么时间就是4500ms,假设在这4500ms内,所有的锁都加锁成功, 那么此时才算是加锁成功,如果在4500ms有线程加锁失败,则会再次去进行重试.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1Qy5dS6c-1671001492411)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/Redisson%20%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81%E4%B8%BB%E4%BB%8E%E4%B8%80%E8%87%B4%E6%80%A7%E9%97%AE%E9%A2%98.jpg)]
总结MutiLock锁
#自写
1.在redisCilent 做三个虚拟机的redisNode
2.引入redisCilent,1redisCilent2,redisCilent3
3.在beforeacher获得三个getlock()
4.lock1,lock2,lock3
5.创建联锁
lock=redisCilent.getMultilock(lock1,lock2,lock3).(成为一个集合)
(底层是new RedissonMulitiLOck(lock1..))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
#配置客户端 @Configuration public class RedisConfiguration { @Bean public RedissonClient redissonClient() { // 配置类 Config config = new Config(); // 添加 Redis 地址:此处是单节点地址,也可以通过 config.useClusterServers() 添加集群地址 config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword("root"); // 创建客户端 return Redisson.create(config); } @Bean public RedissonClient redissonClientTwo() { Config config = new Config(); config.useSingleServer().setAddress("redis://127.0.0.1:6380").setPassword("root"); return Redisson.create(config); } @Bean public RedissonClient redissonClientThree() { Config config = new Config(); config.useSingleServer().setAddress("redis://127.0.0.1:6381").setPassword("root"); return Redisson.create(config); } } # 创建联锁并且进行测试 @Slf4j @SpringBootTest public class RedissonTest { @Resource private RedissonClient redissonClient; @Resource private RedissonClient redissonClientTwo; @Resource private RedissonClient redissonClientThree; RLock multiLock; @BeforeEach void setUp() { RLock lock = redissonClient.getLock("anyLock"); RLock lockTwo = redissonClientTwo.getLock("anyLock"); RLock lockThree = redissonClientThree.getLock("anyLock"); // 创建联锁 MultiLock RLock multiLock = redissonClient.getMultiLock(lock, lockTwo, lockThree); } @Test void methodOne() throws InterruptedException { boolean isLocked = multiLock.tryLock(1L, TimeUnit.SECONDS); if (!isLocked) { log.error("Fail To Get Lock~"); return; } try { log.info("Get Lock Successfully~"); methodTwo(); } finally { log.info("Release Lock~"); multiLock.unlock(); } } @Test void methodTwo() throws InterruptedException { boolean isLocked = multiLock.tryLock(1L, TimeUnit.SECONDS); if (!isLocked) { log.error("Fail To Get Lock!"); return; } try { log.info("Get Lock Successfully!"); } finally { log.info("Release Lock!"); multiLock.unlock(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 1)不可重入Redis分布式锁:
原理:利用setnx的互斥性;利用ex避免死锁;释放锁时判断线程标示
缺陷:不可重入、无法重试、锁超时失效- 2)可重入的Redis分布式锁:
原理:利用hash结构,记录线程标示和重入次数;利用watchDog延续锁时间;利用信号量控制锁重试等待
缺陷:redis宕机引起锁失效问题- 3)Redisson的multiLock:
原理:多个独立的Redis节点,必须在所有节点都获取重入锁,才算获取锁成功
缺陷:运维成本高、实现复杂
6、秒杀优化
6.1 秒杀优化-异步秒杀思路
我们来回顾一下下单流程
当用户发起请求,此时会请求nginx,nginx会访问到tomcat,而tomcat中的程序,会进行串行操作,分成如下几个步骤
1、查询优惠卷
2、判断秒杀库存是否足够
3、查询订单
4、校验是否是一人一单
5、扣减库存
6、创建订单
以上操作都是串行执行的,并且 1、3、5、6 的操作都需要与数据库进行交互,从而导致程序执行的很慢。
秒杀优化方案
将耗时较短的逻辑判断放到 Redis 中,比如 2、4 中的操作,只要这样的逻辑能够完成,意味着一定能够完成下单,只需要进行快速的逻辑判断,无需等待下单逻辑全部走完即可返回成功;再在后台开一个线程,后台线程负责慢慢的执行 Queue 中的消息。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qnMHsz4L-1671001492413)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/%E7%A7%92%E6%9D%80%E4%BC%98%E5%8C%96%E6%96%B9%E6%A1%88.jpg)]
秒杀优化的实现思路
- 新增优惠券的同时,将优惠券信息保存到 Redis 中;
基于 Lua 脚本,判断秒杀库存、一人一单,决定用户是否抢购成功,如果 Lua 执行返回 0,则有购买资格; - 用户下单后,判断库存是否充足,只需要在 Redis 中根据 Key 去找到对应的 Value 是否大于 0 即可。
- 若不充足,直接结束;若充足,则继续在 Redis 中判断用户是否可以下单,如果 Set 集合中不存在这个 Value(用户 ID),说明该用户可以下单。
- 如果有购买资格,将订单信息存入阻塞队列,并且返回 订单 ID(此时已经秒杀业务已经结束,何时进行异步下单操作数据库不再重要);
- 开启线程任务,不断从阻塞队列中获取信息,实现异步下单。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mbxWTsdj-1671001492414)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/%E7%A7%92%E6%9D%80%E4%BC%98%E5%8C%96%E6%96%B9%E6%A1%88%E7%9A%84%E5%AE%9E%E7%8E%B0%E6%80%9D%E8%B7%AF.jpg)]
6.2 秒杀优化-Redis完成秒杀资格判断
需求:
-
新增秒杀优惠券的同时,将优惠券信息保存到Redis中
-
基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
-
如果抢购成功,将优惠券id和用户id封装后存入阻塞队列
-
开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
VoucherServiceImpl
@Override @Transactional public void addSeckillVoucher(Voucher voucher) { // 保存优惠券 save(voucher); // 保存秒杀信息 SeckillVoucher seckillVoucher = new SeckillVoucher(); seckillVoucher.setVoucherId(voucher.getId()); seckillVoucher.setStock(voucher.getStock()); seckillVoucher.setBeginTime(voucher.getBeginTime()); seckillVoucher.setEndTime(voucher.getEndTime()); seckillVoucherService.save(seckillVoucher); // 保存秒杀库存到Redis中 //SECKILL_STOCK_KEY 这个变量定义在RedisConstans中 //private static final String SECKILL_STOCK_KEY ="seckill:stock:" stringRedisTemplate.opsForValue().set(SECKILL_STOCK_KEY + voucher.getId(), voucher.getStock().toString()); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
完整lua表达式
-- 1.参数列表 -- 1.1.优惠券id local voucherId = ARGV[1] -- 1.2.用户id local userId = ARGV[2] -- 1.3.订单id local orderId = ARGV[3] -- 2.数据key -- 2.1.库存key local stockKey = 'seckill:stock:' .. voucherId -- 2.2.订单key local orderKey = 'seckill:order:' .. voucherId -- 3.脚本业务 -- 3.1.判断库存是否充足 get stockKey if(tonumber(redis.call('get', stockKey)) <= 0) then -- 3.2.库存不足,返回1 return 1 end -- 3.2.判断用户是否下单 SISMEMBER orderKey userId if(redis.call('sismember', orderKey, userId) == 1) then -- 3.3.存在,说明是重复下单,返回2 return 2 end -- 3.4.扣库存 incrby stockKey -1 redis.call('incrby', stockKey, -1) -- 3.5.下单(保存用户)sadd orderKey userId redis.call('sadd', orderKey, userId) -- 3.6.发送消息到队列中, XADD stream.orders * k1 v1 k2 v2 ... redis.call('xadd', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId) return 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
当以上lua表达式执行完毕后,剩下的就是根据步骤3,4来执行我们接下来的任务了
VoucherOrderServiceImpl
@Override public Result seckillVoucher(Long voucherId) { //获取用户 Long userId = UserHolder.getUser().getId(); long orderId = redisIdWorker.nextId("order"); // 1.执行lua脚本 Long result = stringRedisTemplate.execute( SECKILL_SCRIPT, Collections.emptyList(), voucherId.toString(), userId.toString(), String.valueOf(orderId) ); int r = result.intValue(); // 2.判断结果是否为0 if (r != 0) { // 2.1.不为0 ,代表没有购买资格 return Result.fail(r == 1 ? "库存不足" : "不能重复下单"); } //TODO 保存阻塞队列 // 3.返回订单id return Result.ok(orderId); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
6.3 秒杀优化-基于阻塞队列实现秒杀优化
VoucherOrderServiceImpl
判断是否有购买资格,如果有购买资格,将订单信息存入阻塞队列,并且返回 订单 ID。
开启线程任务,不断从阻塞队列中获取信息,实现异步下单。
@Service @SuppressWarnings("ALL") @Slf4j public class VoucherOrderServiceImpl extends ServiceImpl<VoucherOrderMapper, VoucherOrder> implements VoucherOrderService { @Resource private SeckillVoucherService seckillVoucherService; @Resource private RedisIdWorker redisIdWorker; @Resource private StringRedisTemplate stringRedisTemplate; @Resource private RedissonClient redissonClient; // Lua 脚本 private static final DefaultRedisScript<Long> SECKILL_SCRIPT; static { SECKILL_SCRIPT = new DefaultRedisScript<>(); SECKILL_SCRIPT.setLocation(new ClassPathResource("SeckillVoucher.lua")); SECKILL_SCRIPT.setResultType(Long.class); } // 异步处理线程池,此处获得是单线程 private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor(); // 在当前类初始完毕后执行 VoucherOrderHandler 中的 run 方法 @PostConstruct //在类初始化之后执行,因为当这个类初始化好了之后,随时都是有可能要执行的 public void init() { SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler()); } // 阻塞队列:当一个线程尝试从队列中获取元素时:若队列中没有元素线程就会被阻塞,直到队列中有元素时线程才会被唤醒并且去获取元素。 private BlockingQueue<VoucherOrder> orderTasks = new ArrayBlockingQueue<>(1024 * 1024); // 从队列中获取信息 public class VoucherOrderHandler implements Runnable { @Override public void run() { while (true) { try { // 获取队列中的订单信息 VoucherOrder voucherOrder = orderTasks.take(); // 创建订单 handleVoucherOrder(voucherOrder); } catch (Exception e) { log.error("订单处理异常", e); } } } private void handleVoucherOrder(VoucherOrder voucherOrder) { Long userId = voucherOrder.getUserId(); RLock lock = redissonClient.getLock("lock:order:" + userId); boolean isLocked = lock.tryLock(); if (!isLocked) { log.error("不允许重复下单!"); return; } try { // 该方法非主线程调用,代理对象需要在主线程中获取。 //注意:由于是spring的事务是放在threadLocal中,此时的是多线程,事务会失效 // //目前属于子线程代理对象拿不到,所以我们应该在主线程拿到代理对象(自己加的) currentProxy.createVoucherOrder(voucherOrder); } finally { lock.unlock(); } } } // 代理对象 private VoucherOrderService currentProxy; @Override public Result seckillVoucher(Long voucherId) { // 1. 执行 Lua 脚本 Long userId = UserHolder.getUser().getId(); long orderId = redisIdWorker.nextId("order"); Long executeResult = stringRedisTemplate.execute( SECKILL_SCRIPT, Collections.emptyList(), voucherId.toString(), userId.toString() ); // 2. Lua 脚本的执行结果不为 0 则没有购买资格 int result = executeResult.intValue(); if (result != 0) { return Result.fail(result == 1 ? "库存不足!" : "请勿重复下单!"); } // 3. 将下单信息保存到阻塞队列中 VoucherOrder voucherOrder = new VoucherOrder(); voucherOrder.setId(orderId); voucherOrder.setUserId(userId); voucherOrder.setVoucherId(voucherId); orderTasks.add(voucherOrder); // 4. 获取代理对象 currentProxy = (VoucherOrderService) AopContext.currentProxy(); // 5. 返回订单号(告诉用户下单成功,业务结束;执行异步下单操作数据库) return Result.ok(orderId); } @Transactional @Override public void createVoucherOrder(VoucherOrder voucherOrder) { Long userId = voucherOrder.getUserId(); // 1. 一人一单 Integer count = query() .eq("voucher_id", voucherOrder.getVoucherId()) .eq("user_id", userId) .count(); if (count > 0) { log.error("不可重复下单!"); return; } // 2. 减扣库存 boolean isAccomplished = seckillVoucherService.update() .setSql("stock = stock - 1") .eq("voucher_id", voucherOrder.getVoucherId()).gt("stock", 0) .update(); if (!isAccomplished) { log.error("库存不足!"); return; } // 3. 下单 boolean isSaved = save(voucherOrder); if (!isSaved) { log.error("下单失败!"); return; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
总结秒杀优化
- 新增秒杀优惠券的同时,将优惠券信息保存到 Redis 中
- 基于 Lua 脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
- 如果抢购成功,将优惠券 id 和用户 id 封装后存入阻塞队列
- 开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
- voucherOrderService.seckillVoucher(voucherId);在seckillVoucher(voucherId)方法下
- 先进行static{}代码库,执行lua脚本
- 然后进行@PostConstruct的init()方法
public void init() { SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler()); } private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();//单线程 //submit和execute都是提交任务的方法 //execute()只能是runnable参数,任务不可返回执行结果 //submit()可以callable和runnable参数,callable任务可返回执行结果 //开启执行new VoucherOrderHandler()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.执行new VoucherOrderHandler()
// 从队列中获取信息 public class VoucherOrderHandler implements Runnable { @Override public void run() { while (true) { try { // 获取队列中的订单信息 VoucherOrder voucherOrder = orderTasks.take(); // 创建订单 handleVoucherOrder(voucherOrder); } catch (Exception e) { log.error("订单处理异常", e); } } } // 阻塞队列:当一个线程尝试从队列中获取元素时:若队列中没有元素线程就会被阻塞,直到队列中有元素时线程才会被唤醒并且去获取元素。 // private BlockingQueue<VoucherOrder> orderTasks = new ArrayBlockingQueue<>(1024 * 1024); //创建阻塞队列执行task()方法 orderTasks.take(); //take(基于阻塞的方式获取队列中的元素,如果队列未空,则task方法一直阻塞,直到队列中有新的数据可以消费 //执行// 创建订单 //handleVoucherOrder(voucherOrder);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
5.handleVoucherOrder()
private void handleVoucherOrder(VoucherOrder voucherOrder) { Long userId = voucherOrder.getUserId(); RLock lock = redissonClient.getLock("lock:order:" + userId); boolean isLocked = lock.tryLock(); if (!isLocked) { log.error("不允许重复下单!"); return; } try { // 该方法非主线程调用,代理对象需要在主线程中获取。 //注意:由于是spring的事务是放在threadLocal中,此时的是多线程,事务会失效 // //目前属于子线程代理对象拿不到,所以我们应该在主线程拿到代理对象(自己加的) currentProxy.createVoucherOrder(voucherOrder); } finally { lock.unlock(); } } } //主线程执行 currentProxy.createVoucherOrder(voucherOrder);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
6.执行订单方法 createVoucherOrder(VoucherOrder voucherOrder)
@Transactional @Override public void createVoucherOrder(VoucherOrder voucherOrder) { Long userId = voucherOrder.getUserId(); // 1. 一人一单 Integer count = query() .eq("voucher_id", voucherOrder.getVoucherId()) .eq("user_id", userId) .count(); if (count > 0) { log.error("不可重复下单!"); return; } // 2. 减扣库存 boolean isAccomplished = seckillVoucherService.update() .setSql("stock = stock - 1") .eq("voucher_id", voucherOrder.getVoucherId()).gt("stock", 0) .update(); if (!isAccomplished) { log.error("库存不足!"); return; } // 3. 下单 boolean isSaved = save(voucherOrder); if (!isSaved) { log.error("下单失败!"); return; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
7.完成init之后,执行seckillVoucher(voucherId)
8.执行脚本返回资格,如果有资格进行创建订单,将订单加入到阻塞队列中,返回订单号。
小总结:
秒杀业务的优化思路是什么?
- 先利用Redis完成库存余量、一人一单判断,完成抢单业务
- 再将下单业务放入阻塞队列,利用独立线程异步下单
- 基于阻塞队列的异步秒杀存在哪些问题?
- 内存限制问题
- 数据安全问题
7、Redis消息队列
7.1 Redis消息队列-认识消息队列
什么是消息队列:字面意思就是存放消息的队列。最简单的消息队列模型包括3个角色:
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息

使用队列的好处在于 **解耦:**所谓解耦,举一个生活中的例子就是:快递员(生产者)把快递放到快递柜里边(Message Queue)去,我们(消费者)从快递柜里边去拿东西,这就是一个异步,如果耦合,那么这个快递员相当于直接把快递交给你,这事固然好,但是万一你不在家,那么快递员就会一直等你,这就浪费了快递员的时间,所以这种思想在我们日常开发中,是非常有必要的。
这种场景在我们秒杀中就变成了:我们下单之后,利用redis去进行校验下单条件,再通过队列把消息发送出去,然后再启动一个线程去消费这个消息,完成解耦,同时也加快我们的响应速度。
这里我们可以使用一些现成的mq,比如kafka,rabbitmq等等,但是呢,如果没有安装mq,我们也可以直接使用redis提供的mq方案,降低我们的部署和学习成本。
7.2 Redis消息队列-基于List实现消息队列
基于List结构模拟消息队列
消息队列(Message Queue),字面意思就是存放消息的队列。而Redis的list数据结构是一个双向链表,很容易模拟出队列效果。
队列是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。
不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。

基于List的消息队列有哪些优缺点?
优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
缺点:
-
无法避免消息丢失
-
只支持单消费者
# 自写 redis-cli -h 192.168.8.130 -p 6379 -a yangroot 1: BRPOP l1 20 2:LPUSH l1 1 2- 1
- 2
- 3
- 4
- 5
7.3 Redis消息队列-基于PubSub的消息队列
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
SUBSCRIBE channel [channel] :订阅一个或多个频道
PUBLISH channel msg :向一个频道发送消息
PSUBSCRIBE pattern[pattern] :订阅与pattern格式匹配的所有频道
使用 SUBSCRIBE 命令,启动两个消费者并且订阅同一个队列;此时两个消费者都会被堵塞住,等待新消息的到来。 127.0.0.1:6379> SUBSCRIBE queue Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "queue" 3) (integer) 1 使用 PUBLISH 命令启动一个生产者,发布一条消息。 127.0.0.1:6379> PUBLISH queue msg1 (integer) 1 1 2 两个消费者解除堵塞,收到生产者发送的新消息。 127.0.0.1:6379> SUBSCRIBE queue Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "queue" 3) (integer) 1 1) "message" 2) "queue" 3) "msg1" 消费者使用 PSUBSCRIBE 命令 订阅 queue.* 相关的队列信息,之后生产者分别向 queue.p1 和 queue.p2 发布消息。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

Pub/Sub 的最大优点 :支持 多组生产者、消费者处理消息;
Pub/Sub 的最大缺点 :丢数据。
消费者下线、Redis 宕机、消息堆积 都会导致数据丢失。
Pub/Sub 的实现十分简单,没有基于任何数据结构,也没有任何的数据存储,只是单纯的为生产者和消费者建立 数据转发通道,将符合规则的数据,从一端发到另一端。
一个完整的发布、订阅消息处理流程
消费者订阅指定队列,Redis 就会记录一个映射关系 —— 队列 — 消费者;
生产者向这个队列发布消息,从 Redis 的映射关系中找出对应的消费者,将消息转发给消费者。
注意:消费者必须先订阅队列,生产者才能发布消息,否则消息会丢失。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
基于PubSub的消息队列有哪些优缺点?
优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
7.4 Redis消息队列-基于Stream的消息队列
Stream 是 Redis5.0 引入的一种新的 数据类型,可以实现一个功能非常完善的消息队列。
Stream 通过 XADD(发布消息) 和 XREAD(读取消息) 完成最简单的生产、消费模型。
发送消息的命令: XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] \*|ID field value [field value ...]
key:队列名称;[NOMKSTREAM]:若队列不存在,是否自动创建队列,默认自动创建(不用管);[MAXLEN|MINID [=|~] threshold [LIMIT count]]:设置消息队列的最大消息数量(不用管);*|ID:消息的唯一 ID,*代表由 Redis 自动生成,格式是时间戳-递增数字,例如:1666161469358-0;field value [field value ...]:发送到队列中的消息,称为 Entry。格式为多个 Key-Value 键值对。
# 创建名为 users 的队列并向该队列送一个消息,ID 由 Redis 自动生成;内容为: { name: Jack, age: 21}
XADD users * name Jack age 21
127.0.0.1:6379> XADD users * name Jack
"1666169070359-0"
127.0.0.1:6379> XADD users * name Rose
"1666169072899-0"
1234567
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
读取消息的方式之一:XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
[COUNT count]:每次读取消息的最大数量;[BLOCK milliseconds]:当没有消息时,是否阻塞 和 阻塞时长;STREAMS key [key ...]:从哪个队列读取消息,Key 就是队列名;ID [ID ...]:起始ID,只返回大于该 ID 的消息;0 代表从第一个消息开始,$ 代表从最新的消息开始。
127.0.0.1:6379> XREAD COUNT 1 STREAMS users 0
1) 1) "queue"
2) 1) 1) "1666169070359-0"
2) 1) "name"
2) "Jack"
127.0.0.1:6379> XREAD COUNT 2 STREAMS users 0
1) 1) "queue"
2) 1) 1) "1666169070359-0"
2) 1) "name"
2) "Jack"
2) 1) "1666169072899-0"
2) 1) "name"
2) "Rose"
12345678910111213
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
阻塞读取最新消息:XREAD COUNT 1 BLOCK STREAMS queue $
// 业务开发中可以循环调用 XREAD 的阻塞读取方式查询最新消息,从而实现持续监听队列的效果(伪代码)
while(true) {
// 尝试获取队列中的最新消息,最多阻塞 2s
Object msg = redis.execute("XREAD COUNT 1 BLOCK 2000 STREAMS queue $");
// 2s 内未获取到消息,继续循环
if(msg == null) {
continue;
}
handleMessage(msg);
}
12345678910
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注意:指定起始 ID 为 $ 时,代表读取最新消息,如果处理一条消息的过程中,又有超过一条以上的消息到达队列,则下次获取时也只能获取到最新的一条,出现 漏读 问题。
STREAM 类型消息队列的 XREAD 命令的特点:
- 永久保存在队列中,消息可回溯;
- 一个消息可以被多个消费者读取;
- 可以阻塞读取;
- 有消息漏读风险。
7.5 Stream 的 消费者组模式
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。具备以下特点:
-
消息分流:队列中的 消息会分流给组内不同的消费者,而不是重复消费,从而加快消息处理的速度。
-
消息标示:消费者组会维护一个标示,记录最后一个被处理的消息,即使消费者宕机重启,还会从标示之后读取消息,确保每一个消息都会被消费。(解决漏读问题)
-
消息确认:消费者获取消息后,消息处于
pending状态,并存入一个pending-list。当处理完成后需要通过 XACK 命令来确认消息,标记消息为已处理,才会从pending-list中移除。(解决消息丢失问题) -
创建消费组:
XGROUP CREATE key groupName ID [MKSTREAM]key:队列名称;groupName:消费组名称;ID:起始 ID 标示,$代表队列中的最后一个消息,0代表队列中的第一个消息;[MKSTREAM]:队列中不存在时自动创建队列。
-
其他命令:
- 删除指定的消费组:
XGROUP DESTROY key groupName - 给指定的消费组添加消费者:
XGROUP CREATECONSUMER key groupName consumerName - 删除消费组中的指定消费者:
XGROUP DELCONSUMER key groupName consumerName
- 删除指定的消费组:
-
从消费者组中读取消息:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]-
group:消费组名称; -
consumer:消费者名称,如果消费者不存在,会自动创建一个消费者; -
count:本次查询的最大数量; -
BLOCK milliseconds:当没有消息时的最长等待时间; -
NOACK:无需手动 ACK,获取到消息后自动确认; -
STREAMS key:指定队列名称; -
ID- 1
:获取消息的起始ID:
>:从下一个未消费的消息开始;- 其他:根据 ID 从
pending-list中获取已消费但未确认的消息;例如0,从pending-list中的第一个消息开始。
# 发送消息到队列 127.0.0.1:6379> XADD queue * name Jack "1666172276809-0" 127.0.0.1:6379> xadd queue * name Rose "1666172286673-0" # 读取队列中的消息 127.0.0.1:6379> XREAD COUNT 2 STREAMS queue 0 1) 1) "queue" 2) 1) 1) "1666172276809-0" 2) 1) "name" 2) "Jack" 2) 1) "1666172286673-0" 2) 1) "name" 2) "Rose" # 创建消费者组 127.0.0.1:6379> XGROUP CREATE queue queueGroup 0 OK # 从消费者组中读取消息 # 监听 queue 队列:消费者组为 queueGroup、消费者为 consumerOne(若不存在则自动创建)、每次读取 1 条消息、阻塞时间为 2s、从下一个未消费消息开始。 127.0.0.1:6379> XREADGROUP GROUP queueGroup consumerOne COUNT 1 BLOCK 2000 STREAMS queue > 1) 1) "queue" 2) 1) 1) "1666172276809-0" 2) 1) "name" 2) "Jack" # 消费者为 consumerTwo 127.0.0.1:6379> XREADGROUP GROUP queueGroup consumerTwo COUNT 1 BLOCK 2000 STREAMS queue > 1) 1) "queue" 2) 1) 1) "1666172286673-0" 2) 1) "name" 2) "Rose" # 消费者为 consumerThree 127.0.0.1:6379> XREADGROUP GROUP queueGroup consumerThree COUNT 1 BLOCK 2000 STREAMS queue > (nil) (2.04s) 123456789101112131415161718192021222324252627282930313233343536373839
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
-
-
消费者获取到消息后,消息处于
pending状态,将pending状态的消息标记为已处理并且从pending-list中删除(命令的返回值是成功确认的消息数):XACK key group ID [ID ...]127.0.0.1:6379> XACK queue queueGroup 1666172276809-0 1666172286673-0 (integer) 2 12- 1
- 2
- 3
STREAM 类型消息队列的 XREADGROUP 命令的特点:
- 永久保存在队列中,消息可回溯;
- 多消费者争抢消息,加快读取速度;
- 可以阻塞读取;
- 没有消息漏读风险;
- 有消息确认机制,能够保证消息至少被消费一次。
| List | PubSub | Stream | |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 阻塞读取 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间,可以利用多消费者加快处理 | 受限于消费者缓冲区 | 受限于队列长度,可以利用消费者组提高消费速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |
消费者监听消息的基本思路(伪代码)
while (true) { // 监听 queue 队列:消费者组为 queueGroup、消费者为 consumerOne(若不存在则自动创建)、每次读取 1 条消息、阻塞时间为 2s、从下一个未消费消息开始。 Object msg = redis.call("XREADGROUP GROUP queueGroup consumerOne COUNT 1 BLOCK 2000 STREAMS queue >"); if (msg == null) { // null 说明没有消息,继续下一次循环 continue; } try { // 处理消息(处理完后必须 XACK) HandleMessage(msg); } catch (Exception e) { while (true) { // 监听 queue 队列:消费者组为 queueGroup、消费者为 consumerOne(不存在则自动创建)、每次读取 1 条消息、从 pending-list 中的第一个消息开始。 Object msg = redis.call("XREADGROUP GROUP queueGroup consumerOne COUNT 1 STREAMS queue 0"); if (msg == null) { // null 说明没有异常,所有消息都已确认,结束循环 break; } try { // 处理消息(处理完后必须 XACK) HandleMessage(msg); } catch (Exception e) { // 再次出现异常,继续循环 continue; } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
7.6 基于Redis的Stream结构作为消息队列,实现异步秒杀下单
创建一个 Stream 类型的消息队列,名为
stream.orders。
127.0.0.1:6379> XGROUP CREATE stream.orders orderGroup 0 MKSTREAM
OK
12
- 1
- 2
- 3
修改秒杀下单的 Lua 脚本,在认定有抢购资格后,直接向
stream.orders中添加消息,内容包括voucherId、userId、orderId。
local voucherId = ARGV[1] local userId = ARGV[2] local orderId = ARGV[3] local stockKey = "seckill:stock:" .. voucherId local orderKey = "seckill:order:" .. voucherId -- 判断库存是否充足(不足,返回 1) if (tonumber(redis.call('GET', stockKey)) <= 0) then return 1; end; -- 判断用户是否下单(重复下单,返回 2) if (redis.call('SISMEMBER', orderKey, userId) == 1) then return 2; end; -- 下单成功:扣减库存、保存用户。 redis.call('INCRBY', stockKey, -1); redis.call('SADD', orderKey, userId); -- 发送消息到 stream.orders 队列中(*:消息的唯一ID 由 Redis 自动生成):XADD stream.orders * key field ... redis.call('XADD', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId); return 0; @Override public Result seckillVoucher(Long voucherId) { // 1. 执行 Lua 脚本(有购买资格:向 stream.orders 中添加消息,内容包括 voucherId、userId、orderId) Long userId = UserHolder.getUser().getId(); long orderId = redisIdWorker.nextId("order"); Long executeResult = stringRedisTemplate.execute( SECKILL_SCRIPT, Collections.emptyList(), voucherId.toString(), userId.toString(), String.valueOf(orderId) ); // 2. Lua 脚本的执行结果不为 0,则没有购买资格 int result = executeResult.intValue(); if (result != 0) { return Result.fail(result == 1 ? "库存不足!" : "请勿重复下单!"); } // 3. 获取代理对象 currentProxy = (VoucherOrderService) AopContext.currentProxy(); // 4. 返回订单号(告诉用户下单成功,业务结束;执行异步下单操作数据库) return Result.ok(orderId); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
项目启动时,开启一个线程任务,尝试获取
stream.orders中的消息,完成下单。
// 从队列中获取信息 public class VoucherOrderHandler implements Runnable { String queueName = "stream.orders"; String groupName = "orderGroup"; String consumerName = "consumerOne"; @Override public void run() { while (true) { try { // 1. 获取消息队列中的订单信息 // XREAD GROUP orderGroup consumerOne COUNT 1 BLOCK 2000 STREAMS stream.orders > // 队列 stream.orders、消费者组 orderGroup、消费者 consumerOne、每次读 1 条消息、阻塞时间 2s、从下一个未消费的消息开始。 List<MapRecord<String, Object, Object>> readingList = stringRedisTemplate.opsForStream().read( Consumer.from(groupName, consumerName), StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)), StreamOffset.create(queueName, ReadOffset.lastConsumed()) ); // 2. 判断消息是否获取成功 if (readingList.isEmpty() || readingList == null) { // 获取失败说明没有消息,则继续下一次循环 continue; } // 3. 解析消息中的订单信息 // MapRecord:String 代表 消息ID;两个 Object 代表 消息队列中的 Key-Value MapRecord<String, Object, Object> record = readingList.get(0); Map<Object, Object> recordValue = record.getValue(); VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(recordValue, new VoucherOrder(), true); // 4. 获取成功则下单 handleVoucherOrder(voucherOrder); // 5. 确认消息 XACK stream.orders orderGroup id stringRedisTemplate.opsForStream().acknowledge(groupName, consumerName, record.getId()); } catch (Exception e) { log.error("订单处理异常", e); handlePendingMessages(); } } } private void handlePendingMessages() { while (true) { try { // 1. 获取 pending-list 中的订单信息 // XREAD GROUP orderGroup consumerOne COUNT 1 STREAM stream.orders 0 List<MapRecord<String, Object, Object>> readingList = stringRedisTemplate.opsForStream().read( Consumer.from(groupName, consumerName), StreamReadOptions.empty().count(1), StreamOffset.create(queueName, ReadOffset.from("0")) ); // 2. 判断消息是否获取成功 if (readingList.isEmpty() || readingList == null) { // 获取失败 pending-list 中没有异常消息,结束循环 break; } // 3. 解析消息中的订单信息并下单 MapRecord<String, Object, Object> record = readingList.get(0); Map<Object, Object> recordValue = record.getValue(); VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(recordValue, new VoucherOrder(), true); handleVoucherOrder(voucherOrder); // 4. XACK stringRedisTemplate.opsForStream().acknowledge(queueName, groupName, record.getId()); } catch (Exception e) { log.error("订单处理异常(pending-list)", e); try { // 稍微休眠一下再进行循环 Thread.sleep(20); } catch (Exception ex) { ex.printStackTrace(); } } } } ... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
秒杀下单 Ultimate VER
SeckillVoucher.lua
local voucherId = ARGV[1] local userId = ARGV[2] local orderId = ARGV[3] local stockKey = "seckill:stock:" .. voucherId local orderKey = "seckill:order:" .. voucherId -- 判断库存是否充足(不足,返回 1) if (tonumber(redis.call('GET', stockKey)) <= 0) then return 1; end; -- 判断用户是否下单(重复下单,返回 2) if (redis.call('SISMEMBER', orderKey, userId) == 1) then return 2; end; -- 下单成功:扣减库存、保存用户。 redis.call('INCRBY', stockKey, -1); redis.call('SADD', orderKey, userId); -- 发送消息到 stream.orders 队列中(*:消息的唯一ID 由 Redis 自动生成):XADD stream.orders * key field ... redis.call('XADD', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId); return 0;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
VoucherOrderService
@Service @SuppressWarnings("ALL") @Slf4j public class VoucherOrderServiceImpl extends ServiceImpl<VoucherOrderMapper, VoucherOrder> implements VoucherOrderService { @Resource private SeckillVoucherService seckillVoucherService; @Resource private RedisIdWorker redisIdWorker; @Resource private StringRedisTemplate stringRedisTemplate; @Resource private RedissonClient redissonClient; // Lua 脚本 private static final DefaultRedisScript<Long> SECKILL_SCRIPT; static { SECKILL_SCRIPT = new DefaultRedisScript<>(); SECKILL_SCRIPT.setLocation(new ClassPathResource("SeckillVoucher.lua")); SECKILL_SCRIPT.setResultType(Long.class); } // 代理对象 private VoucherOrderService currentProxy; @Override public Result seckillVoucher(Long voucherId) { // 1. 执行 Lua 脚本(有购买资格:向 stream.orders 中添加消息,内容包括 voucherId、userId、orderId) Long userId = UserHolder.getUser().getId(); long orderId = redisIdWorker.nextId("order"); Long executeResult = stringRedisTemplate.execute( SECKILL_SCRIPT, Collections.emptyList(), voucherId.toString(), userId.toString(), String.valueOf(orderId) ); // 2. Lua 脚本的执行结果不为 0,则没有购买资格 int result = executeResult.intValue(); if (result != 0) { return Result.fail(result == 1 ? "库存不足!" : "请勿重复下单!"); } // 3. 获取代理对象 currentProxy = (VoucherOrderService) AopContext.currentProxy(); // 4. 返回订单号(告诉用户下单成功,业务结束;执行异步下单操作数据库) return Result.ok(orderId); } // 异步处理线程池 private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor(); // 在当前类初始完毕后执行 VoucherOrderHandler 中的 run 方法 @PostConstruct public void init() { SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler()); } // 从队列中获取信息 public class VoucherOrderHandler implements Runnable { String queueName = "stream.orders"; String groupName = "orderGroup"; String consumerName = "consumerOne"; @Override public void run() { while (true) { try { // 1. 获取消息队列中的订单信息 // XREAD GROUP orderGroup consumerOne COUNT 1 BLOCK 2000 STREAMS stream.orders > // 队列 stream.orders、消费者组 orderGroup、消费者 consumerOne、每次读 1 条消息、阻塞时间 2s、从下一个未消费的消息开始。 List<MapRecord<String, Object, Object>> readingList = stringRedisTemplate.opsForStream().read( Consumer.from(groupName, consumerName), StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)), StreamOffset.create(queueName, ReadOffset.lastConsumed()) ); // 2. 判断消息是否获取成功 if (readingList.isEmpty() || readingList == null) { // 获取失败说明没有消息,则继续下一次循环 continue; } // 3. 解析消息中的订单信息 // MapRecord:String 代表 消息ID;两个 Object 代表 消息队列中的 Key-Value MapRecord<String, Object, Object> record = readingList.get(0); Map<Object, Object> recordValue = record.getValue(); VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(recordValue, new VoucherOrder(), true); // 4. 获取成功则下单 handleVoucherOrder(voucherOrder); // 5. 确认消息 XACK stream.orders orderGroup id stringRedisTemplate.opsForStream().acknowledge(groupName, consumerName, record.getId()); } catch (Exception e) { log.error("订单处理异常", e); handlePendingMessages(); } } } private void handlePendingMessages() { while (true) { try { // 1. 获取 pending-list 中的订单信息 // XREAD GROUP orderGroup consumerOne COUNT 1 STREAM stream.orders 0 List<MapRecord<String, Object, Object>> readingList = stringRedisTemplate.opsForStream().read( Consumer.from(groupName, consumerName), StreamReadOptions.empty().count(1), StreamOffset.create(queueName, ReadOffset.from("0")) ); // 2. 判断消息是否获取成功 if (readingList.isEmpty() || readingList == null) { // 获取失败 pending-list 中没有异常消息,结束循环 break; } // 3. 解析消息中的订单信息并下单 MapRecord<String, Object, Object> record = readingList.get(0); Map<Object, Object> recordValue = record.getValue(); VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(recordValue, new VoucherOrder(), true); handleVoucherOrder(voucherOrder); // 4. XACK stringRedisTemplate.opsForStream().acknowledge(queueName, groupName, record.getId()); } catch (Exception e) { log.error("订单处理异常(pending-list)", e); try { // 稍微休眠一下再进行循环 Thread.sleep(20); } catch (Exception ex) { ex.printStackTrace(); } } } } private void handleVoucherOrder(VoucherOrder voucherOrder) { Long userId = voucherOrder.getUserId(); RLock lock = redissonClient.getLock("lock:order:" + userId); boolean isLocked = lock.tryLock(); if (!isLocked) { log.error("不允许重复下单!"); return; } try { // 该方法非主线程调用,代理对象需要在主线程中获取。 currentProxy.createVoucherOrder(voucherOrder); } finally { lock.unlock(); } } } @Transactional @Override public void createVoucherOrder(VoucherOrder voucherOrder) { Long userId = voucherOrder.getUserId(); // 1. 一人一单 Integer count = query() .eq("voucher_id", voucherOrder.getVoucherId()) .eq("user_id", userId) .count(); if (count > 0) { log.error("不可重复下单!"); return; } // 2. 减扣库存 boolean isAccomplished = seckillVoucherService.update() .setSql("stock = stock - 1") .eq("voucher_id", voucherOrder.getVoucherId()).gt("stock", 0) .update(); if (!isAccomplished) { log.error("库存不足!"); return; } // 3. 下单 boolean isSaved = save(voucherOrder); if (!isSaved) { log.error("下单失败!"); return; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
总结基于消息队列进行异步秒杀
之前用的是阻塞队列,现在用的是redis的stram消息队列
8. 点赞相关
8.1 发布、查看笔记
tb_blog:笔记表,包含比较重的标题、文字、图片等;tb_blog_comments:其他用户对笔记的评论。- 上传图片接口地址:
http://localhost:8080/api/upload/blog- 发布笔记接口地址:
http://localhost:8080/api/blog
@Slf4j @RestController @RequestMapping("upload") public class UploadController { @PostMapping("/blog") public Result uploadImage(@RequestParam("file") MultipartFile image) { try { // 获取原始文件名称 String originalFilename = image.getOriginalFilename(); // 生成新文件名 String fileName = createNewFileName(originalFilename); // 保存文件 image.transferTo(new File(SystemConstants.IMAGE_UPLOAD_DIR, fileName)); // 返回结果 log.debug("文件上传成功,{}", fileName); return Result.ok(fileName); } catch (IOException e) { throw new RuntimeException("文件上传失败", e); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
目前需求:点击笔记,进入详情页面,实现该页面的查询接口。
| 请求方式 | 请求路径 | 请求参数 | 返回值 |
|---|---|---|---|
| GET | /blog/{id} | id(@PathVariable) | 笔记信息(包含用户信息) |
Blog 实体类中添加两个属性,icon 和 name,并且添加 @TableField(exist = false) 注解,表示该注解不属于 tb_blog 表中的字段。
注意操作时,需要修改SystemConstants.IMAGE_UPLOAD_DIR 自己图片所在的地址,在实际开发中图片一般会放在nginx上或者是云存储上。(此处可改为本地地址)
/** * 用户图标 */ @TableField(exist = false) private String icon; /** * 用户姓名 */ @TableField(exist = false) private String name; 1234567891011 @GetMapping("/{id}") public Result queryById(@PathVariable("id") Long id) { return blogService.queryById(id); } // BlogService @Override public Result queryById(Long id) { Blog blog = getById(id); if (blog == null) { return Result.fail("笔记不存在!"); } queryBlogWithUserInfo(blog); return Result.ok(blog); } private void queryBlogWithUserInfo(Blog blog) { Long userId = blog.getUserId(); User user = userService.getById(userId); blog.setIcon(user.getIcon()); blog.setName(user.getNickName()); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
8.2 点赞
初始代码:
http://localhost:8080/blog/like/{id}目前存在的问题:一个用户可以无限点赞,目前的逻辑发起的请求只是将
liked字段的值+1。
@PutMapping("/like/{id}")
public Result likeBlog(@PathVariable("id") Long id) {
return blogService.likeBlog(id);
}
@Override
public Result likeBlog(Long id) {
// update set tb_blog liked = liked + 1 where id = ?
update().setSql("liked = liked + 1").eq("id", id).update();
return Result.ok();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
需求
- 同一个用户只能点赞一次,再次点赞则取消点赞;
- 若当前用户已经点赞,则点赞按钮高亮显示(前段实现,判断
Blog类中的isLike属性的值)。
实现步骤
- 为 Blog 类添加一个
isLike属性,标识是否被当前用户点赞; - 修改点赞功能,利用 Redis 的 Set 集合判断是否点过赞;用户点赞,未点过赞则点赞数 +1,已点过赞则点赞数 -1;
- Set 集合:无序不可重复,支持 交集、并集、差集等功能。
- 修改根据 ID 查询 Blog 的业务,判断当前登录用户是否点过赞,赋值给
isLike属性; - 修改分页查询 Blog 业务,判断当前登录用户是否点过赞,赋值给
isLike属性。
Blog类中添加一个isLike属性
/**
* 是否点赞
*/
@TableField(exist = false)
private Boolean isLike;
12345
- 1
- 2
- 3
- 4
- 5
- 6
判断用户是否对该 Blog 点赞过
/** * 判断用户是否对该 Blog 点赞过 */ private void isBlogLiked(Blog blog) { String key = BLOG_LIKED_KEY + blog.getId(); UserDTO user = UserHolder.getUser(); if (user == null) { // 用户未登录,无需查询是否点过赞 return; } Long userId = user.getId(); Boolean isLiked = stringRedisTemplate.opsForSet().isMember(key, userId.toString()); blog.setIsLike(BooleanUtil.isTrue(isLiked); } /** * 展示热门 Blog */ @Override public Result queryHotBlog(Integer current) { Page<Blog> page = query() .orderByDesc("liked") .page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE)); List<Blog> records = page.getRecords(); records.forEach(blog -> { this.queryBlogWithUserInfo(blog); this.isBlogLiked(blog); }); return Result.ok(records); } /** * 展示 Blog 详情页(根据 ID) */ @Override public Result queryById(Long id) { Blog blog = getById(id); if (blog == null) { return Result.fail("笔记不存在!"); } queryBlogWithUserInfo(blog); isBlogLiked(blog); return Result.ok(blog); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
实现点赞功能
@Override public Result likeBlog(Long id) { // 1. 判断当前登录用户是否点过赞。 Long userId = UserHolder.getUser().getId(); String key = BLOG_LIKED_KEY + id; Boolean isLiked = stringRedisTemplate.opsForSet().isMember(key, userId.toString()); // 2. 未点过赞:点赞,数据库点赞数 +1,将用户保存到 Redis 的 Set 集合中。 if (BooleanUtil.isFalse(isLiked)) { Boolean isSucceed = update().setSql("liked = liked + 1").eq("id", id).update(); if (BooleanUtil.isTrue(isSucceed)) { stringRedisTemplate.opsForSet().add(key, userId.toString()); } } else { // 3. 已点过赞:取消赞,数据库点赞数 -1,将用户从 Redis 的 Set 集合中移除。 Boolean isSucceed = update().setSql("liked = liked - 1").eq("id", id).update(); if (BooleanUtil.isTrue(isSucceed)) { stringRedisTemplate.opsForSet().remove(key, userId.toString()); } } return Result.ok(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
8.3 点赞排行榜
在笔记的详情页面,应该显示给该笔记点赞的人,比如:显示最早给该笔记点赞的用户的 TOP 5。
之前的点赞放在 Set 集合中,但是 Set 集合是无序不可重复的,此处需要使用可排序的 Set 集合,即 SortedSet。
#自写
用zadd z1 m1 z2 m2 z3 m3
zscore z1 返回1
zrange 0 3 返回m1 m2 m3
- 1
- 2
- 3
- 4
| List | Set | SortedSet | |
|---|---|---|---|
| 排序方式 | 按照顺序排序 | 无法排序 | 根据 score 值排序 |
| 唯一性 | 不唯一 | 唯一 | 唯一 |
| 查找方式 | 按照索引查找 或 首尾查找 | 根据元素查找 | 根据元素查找 |
修改点赞业务逻辑
private void isBlogLiked(Blog blog) { String key = BLOG_LIKED_KEY + blog.getId(); UserDTO user = UserHolder.getUser(); if (user == null) { // 用户未登录,无需查询是否点过赞 return; } Long userId = user.getId(); Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString()); blog.setIsLike(score != null); } @Override public Result likeBlog(Long id) { // 1. 判断当前登录用户是否点过赞。 Long userId = UserHolder.getUser().getId(); String key = BLOG_LIKED_KEY + id; // `ZSCORE key member` :获取 SortedSet 中指定元素的 score 值(如果不存在,则代表未点过赞)。 Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString()); // 2. 未点过赞:点赞,数据库点赞数 +1,将用户保存到 Redis 的 Set 集合中。 if (score == null) { Boolean isSucceed = update().setSql("liked = liked + 1").eq("id", id).update(); if (BooleanUtil.isTrue(isSucceed)) { stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis()); } } else { // 3. 已点过赞:取消赞,数据库点赞数 -1,将用户从 Redis 的 Set 集合中移除。 Boolean isSucceed = update().setSql("liked = liked - 1").eq("id", id).update(); if (BooleanUtil.isTrue(isSucceed)) { stringRedisTemplate.opsForZSet().remove(key, userId.toString()); } } return Result.ok(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
接口详情
| 请求方式 | 请求路径 | 请求参数 | 返回值 |
|---|---|---|---|
| GET | /blog/likes/{id} | id(@PathVariable) | List<UserDeto>(给该笔记点赞的 TopN 用户的集合) |
@GetMapping("/likes/{id}")
public Result queryBlogLikes(@PathVariable("id") Long id) {
return blogService.queryBlogLikes(id);
}
1234
- 1
- 2
- 3
- 4
- 5
注意:
select id from tb_user where id in (5, 2, 1)的查询结果顺序为:1、2、5;select id from tb_user where id in (5, 2, 1) ORDER BY FIELD(id, 5, 2, 1);的查询结果顺序为:5、2、1,指定根据何种字段排序以及字段值。
/** * Blog 详情页展示最早点赞的 5 个用户 */ @Override public Result queryBlogLikes(Long id) { String key = BLOG_LIKED_KEY + id; // 1. 查询最早五个点赞的用户 Set<String> topFive = stringRedisTemplate.opsForZSet().range(key, 0, 4); if (topFive == null || topFive.isEmpty()) { return Result.ok(Collections.emptyList()); } // 2. 解析出其中的 用户ID List<Long> userIdList = topFive.stream() .map(Long::valueOf) .collect(Collectors.toList()); String userIdStrWithComma = StrUtil.join(", ", userIdList); // 3. 根据 ID 批量查询 List<UserDTO> userDTOList = userService.query() .in("id", userIdList) .last("ORDER BY FIELD(id, " + userIdStrWithComma + ")") .list() .stream() .map(user -> BeanUtil.copyProperties(user, UserDTO.class)) .collect(Collectors.toList()); return Result.ok(userDTOList); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
总结点赞相关
用的SortedSET,有score便于排序
9. 关注相关
9.1 关注 和 取关
关注是 User 表之间的关系,通过
tb_follow表进行标识;关注的实现需要通过两个接口实现:关注与取关、判断是否关注。
关注与取关:http://localhost:8080/api/follow/{id}/{boolean}
判断是否关注:http://localhost:8080/api/follow/or/not/{id}
tb_follow 表:
id | user_id | follow_user_id |
|---|---|---|
| 主键ID | 用户ID | 关联的用户ID |
@RestController @RequestMapping("/follow") public class FollowController { @Resource private FollowService followService; /** * 关注或取关 * @param followUserId 需要关注 or 取关的 用户ID * @param isFollowed 是否关注 */ @PutMapping("/{id}/{isFollowed}") public Result followOrNot(@PathVariable("id") Long followUserId, @PathVariable("isFollowed") Boolean isFollowed) { return followService.followOrNot(followUserId, isFollowed); } /** * 判断是否关注该用户 * @param followUserId 关注用户的ID */ @GetMapping("/or/not/{id}") public Result isFollowed(@PathVariable("id") Long followUserId) { return followService.isFollowed(followUserId); } } @Override public Result followOrNot(Long followUserId, Boolean isFollowed) { Long userId = UserHolder.getUser().getId(); // 判断是关注还是取关 if (BooleanUtil.isTrue(isFollowed)) { // 关注,增加 Follow follow = new Follow(); follow.setUserId(userId); follow.setFollowUserId(followUserId); save(follow); } else { // 取关,删除 remove(new LambdaQueryWrapper<Follow>().eq(Follow::getUserId, userId).eq( Follow::getFollowUserId, followUserId)); } return Result.ok(); } @Override public Result isFollowed(Long followUserId) { Long userId = UserHolder.getUser().getId(); Integer count = lambdaQuery().eq(Follow::getUserId, userId).eq(Follow::getFollowUserId, followUserId).count(); return Result.ok(count > 0); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
9.2 共同关注
关注时,将当前用户所关注的用户ID存入到 Redis 中:以当前用户的 ID 为 Key,关注用户的 ID 为 value。
取关时,将其从 Redis 中删除。
注意:为了实现共同关注功能,使用 Set,因为 Set 中有 SINTER - 交集、SDIFFER - 差集、SUNION - 并集 命令。
@Override public Result followOrNot(Long followUserId, Boolean isFollowed) { Long userId = UserHolder.getUser().getId(); String key = "follow:" + userId; // 判断是关注还是取关 if (BooleanUtil.isTrue(isFollowed)) { // 关注,增加 Follow follow = new Follow(); follow.setUserId(userId); follow.setFollowUserId(followUserId); boolean isSucceed = save(follow); // 添加到 Redis 中(当前用户ID 为 key,关注用户ID 为 value) if (Boolean.TRUE.equals(isSucceed)) { stringRedisTemplate.opsForSet().add(key, followUserId.toString()); } } else { // 取关,删除 boolean isSucceed = remove(new LambdaQueryWrapper<Follow>().eq(Follow::getUserId, userId).eq(Follow::getFollowUserId, followUserId)); if (BooleanUtil.isTrue(isSucceed)) { // 从 Redis 中删除 stringRedisTemplate.opsForSet().remove(key, followUserId.toString()); } } return Result.ok(); } @Override public Result isFollowed(Long followUserId) { Long userId = UserHolder.getUser().getId(); Integer count = lambdaQuery().eq(Follow::getUserId, userId).eq(Follow::getFollowUserId, followUserId).count(); return Result.ok(count > 0); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
使用
SINTER key [key ...]求出两个用户间的共同关注。
| 请求方式 | 请求路径 | 请求参数 | 返回值 |
|---|---|---|---|
| GET | /follow/common/{id} | id(目标用户ID,@PathVariable) | List<UserDTO> 两个用户的共同关注 |
/** * 获取两个用户之间的共同关注用户 * @param followUserId 关注用户的ID */ @GetMapping("/common/{id}") public Result commonFollow(@PathVariable("id") Long followUserId) { return followService.commonFollow(followUserId); } @Override public Result commonFollow(Long followUserId) { Long userId = UserHolder.getUser().getId(); String selfKey = "follow:" + userId; String aimKey = "follow:" + followUserId; Set<String> userIdSet = stringRedisTemplate.opsForSet().intersect(selfKey, aimKey); if (userIdSet.isEmpty() || userIdSet == null) { // 无交集 return Result.ok(Collections.emptyList()); } List<UserDTO> userDTOList = userService.listByIds(userIdSet) .stream() .map(user -> BeanUtil.copyProperties(user, UserDTO.class)) .collect(Collectors.toList()); return Result.ok(userDTOList); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
总结用关注set(key用户,value关注用户名)
互相关注的时候用stringRedisTemplate.opsForSet().intersect(selfKey, aimKey);
注意:为了实现共同关注功能,使用 Set,因为 Set 中有
SINTER - 交集、SDIFFER - 差集、SUNION - 并集命令。
@Override public Result follow(Long followUserId, Boolean isFollow) { // 1.获取登录用户 Long userId = UserHolder.getUser().getId(); String key = "follows:" + userId; // 1.判断到底是关注还是取关 if (isFollow) { // 2.关注,新增数据 Follow follow = new Follow(); follow.setUserId(userId); follow.setFollowUserId(followUserId); boolean isSuccess = save(follow); if (isSuccess) { // 把关注用户的id,放入redis的set集合 sadd userId followerUserId stringRedisTemplate.opsForSet().add(key, followUserId.toString()); } } else { // 3.取关,删除 delete from tb_follow where user_id = ? and follow_user_id = ? boolean isSuccess = remove(new QueryWrapper<Follow>() .eq("user_id", userId).eq("follow_user_id", followUserId)); if (isSuccess) { // 把关注用户的id从Redis集合中移除 stringRedisTemplate.opsForSet().remove(key, followUserId.toString()); } } return Result.ok(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
具体的关注代码:
FollowServiceImpl
@Override public Result followCommons(Long id) { // 1.获取当前用户 Long userId = UserHolder.getUser().getId(); String key = "follows:" + userId; // 2.求交集 String key2 = "follows:" + id; Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2); if (intersect == null || intersect.isEmpty()) { // 无交集 return Result.ok(Collections.emptyList()); } // 3.解析id集合 List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList()); // 4.查询用户 List<UserDTO> users = userService.listByIds(ids) .stream() .map(user -> BeanUtil.copyProperties(user, UserDTO.class)) .collect(Collectors.toList()); return Result.ok(users); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
9.3 关注推送 - Feed 流
关注推送也叫做 Feed 流(投喂),通过无线下拉刷新获取新的信息。
- 传统模式:需要用户通过搜索引擎或其他方式检索自己需要的内容;
- Feed 模式:通过系统分析用户想要什么,直接将内容推送给用户,从而使用户能更加节约时间,不需要再主动寻找。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CYvBzn3d-1671001492415)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/%E4%BC%A0%E7%BB%9F%E6%A8%A1%E5%BC%8F%20VS%20Feed%E6%A8%A1%E5%BC%8F.jpg)]
9.3.1 Feed 流的实现方案
Feed流的实现有两种模式:
Feed流产品有两种常见模式:
Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
- 优点:信息全面,不会有缺失。并且实现也相对简单
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
- 优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
- 缺点:如果算法不精准,可能起到反作用
本例中的个人页面,是基于关注的好友来做Feed流,因此采用Timeline的模式。该模式的实现方案有三种:
我们本次针对好友的操作,采用的就是Timeline的方式,只需要拿到我们关注用户的信息,然后按照时间排序即可
本例中的个人页面,是基于关注的好友来做 Feed 流,因此采用 Timeline 的模式。
-
该模式的实现方案有三种:拉模式、推模式、推拉结合
-
拉模式:也叫做读扩散

- 推模式:也叫做写扩散。

- 推拉结合模式:也叫做读写混合,兼具推和拉两种模式的优点。

- Feed 流的实现方案
| 拉模式 | 推模式 | 推拉结合 | |
|---|---|---|---|
| 写比例 | 低 | 高 | 中 |
| 读比例 | 高 | 低 | 中 |
| 用户读取延迟 | 高 | 低 | 低 |
| 实现难度 | 复杂 | 简单 | 很复杂 |
| 使用场景 | 很少使用 | 用户量少、没有大V | 过千万的用户量,有大V |
9.4 好友关注-推送到粉丝收件箱
需求:
- 修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
- 收件箱满足可以根据时间戳排序,必须用Redis的数据结构实现
- 查询收件箱数据时,可以实现分页查询
@PostMapping
public Result saveBlog(@RequestBody Blog blog) {
// 获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 保存探店笔记
blogService.save(blog);
return Result.ok();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Feed流的滚动分页
Feed 流中的数据会不断更新,所以数据的角标也在变化,因此不能采用传统的分页模式。

满足这种条件的 Redis 中的数据结构就是 SortedSet
@Override public Result saveBlog(Blog blog) { // 1.获取登录用户 UserDTO user = UserHolder.getUser(); blog.setUserId(user.getId()); // 2.保存探店笔记 boolean isSuccess = save(blog); if(!isSuccess){ return Result.fail("新增笔记失败!"); } // 3.查询笔记作者的所有粉丝 select * from tb_follow where follow_user_id = ? List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list(); // 4.推送笔记id给所有粉丝 for (Follow follow : follows) { // 4.1.获取粉丝id Long userId = follow.getUserId(); // 4.2.推送 String key = FEED_KEY + userId; stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis()); } // 5.返回id return Result.ok(blog.getId()); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
9.5好友关注-实现分页查询收邮箱
分页查询收件箱:在个人主页的 “关注” 中,查询并展示推送的 Blog。
-
第一次查询的
lastId为当前时间戳,每次查询后,lastId为上一次查询的最小时间戳; -
偏移量
offset为 上一次查询的最小值的元素个数,下一次查询时需要跳过这些已经查询过的数据。请求方式 请求路径 请求参数 返回值 GET /blog/of/followlastId(上一次查询的最小时间戳);offset(偏移量)List<Blog>(小于指定时间戳的 Blog 集合);minTime(本次查询的最小时间戳);offset(偏移量)
一、定义出来具体的返回值实体类
@Data
public class ScrollResult {
private List<?> list;
private Long minTime;
private Integer offset;
}
- 1
- 2
- 3
- 4
- 5
- 6
BlogController
注意:RequestParam 表示接受url地址栏传参的注解,当方法上参数的名称和url地址栏不相同时,可以通过RequestParam 来进行指定
@GetMapping("/of/follow")
public Result queryBlogOfFollow(
@RequestParam("lastId") Long max, @RequestParam(value = "offset", defaultValue = "0") Integer offset){
return blogService.queryBlogOfFollow(max, offset);
}
- 1
- 2
- 3
- 4
- 5
BlogServiceImpl
@Override public Result queryBlogOfFollow(Long max, Integer offset) { // 1.获取当前用户 Long userId = UserHolder.getUser().getId(); // 2.查询收件箱 ZREVRANGEBYSCORE key Max Min LIMIT offset count String key = FEED_KEY + userId; Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet() .reverseRangeByScoreWithScores(key, 0, max, offset, 2); // 3.非空判断 if (typedTuples == null || typedTuples.isEmpty()) { return Result.ok(); } // 4.解析数据:blogId、minTime(时间戳)、offset List<Long> ids = new ArrayList<>(typedTuples.size()); long minTime = 0; // 2 int os = 1; // 2 for (ZSetOperations.TypedTuple<String> tuple : typedTuples) { // 5 4 4 2 2 // 4.1.获取id ids.add(Long.valueOf(tuple.getValue())); // 4.2.获取分数(时间戳) long time = tuple.getScore().longValue(); if(time == minTime){ os++; }else{ minTime = time; os = 1; } } os = minTime == max ? os : os + offset; // 5.根据id查询blog String idStr = StrUtil.join(",", ids); List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list(); for (Blog blog : blogs) { // 5.1.查询blog有关的用户 queryBlogUser(blog); // 5.2.查询blog是否被点赞 isBlogLiked(blog); } // 6.封装并返回 ScrollResult r = new ScrollResult(); r.setList(blogs); r.setOffset(os); r.setMinTime(minTime); return Result.ok(r); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
10、附近商户
10.1、附近商户-GEO数据结构的基本用法
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
GEO Geolocation,代表地理位置,允许存储地理坐标。GEO 底层的实现原理是 ZSET,可以使用 ZSET 的命令操作 GEO。
- GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
- GEODIST:计算指定的两个点之间的距离并返回
- GEOHASH:将指定member的坐标转为hash字符串形式并返回
- GEOPOS:返回指定member的坐标
- GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.以后已废弃
- GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
- GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能
10.2、 附近商户-导入店铺数据到GEO
#自写在redis做一个测试
将经纬度变成sorece存入zset
- 1
- 2
- 3
- 4
GEOADD key longitude latitude member [longitude latitude member ...]:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member);
GEOADD China:City 116.40 39.90 Beijing
(integer) 1
GEOADD China:City 121.47 31.23 Shanghai 106.50 29.53 Chongqing 114.08 22.547 Shenzhen 120.15 30.28 Hangzhou 125.15 42.93 Xian 102.71 25.04 Kunming
- 1
- 2
- 3
GEODIST key member1 member2 [unit]:计算指定的两个点之间的距离并返回;
GEODIST China:City Beijing Shanghai km
"1067.3788"
GEODIST China:City Shanghai Kunming km
"1961.3500"
- 1
- 2
- 3
- 4
- 5
-
GEOHASH key member [member ...]:将指定 member 的坐标转为 hash 字符串形式并返回;# 降低内存存储压力,会损失一些精度,但是仍然指向同一个地区。 127.0.0.1:6379> GEOHASH China:City Beijing Shanghai Kunming 1) "wx4fbxxfke0" 2) "wtw3sj5zbj0" 3) "wk3n3nrhs60"- 1
- 2
- 3
- 4
- 5
- 6
-
GEOPOS key member [member ...]:返回指定 member 的坐标;
127.0.0.1:6379> GEOPOS China:City Beijing
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
127.0.0.1:6379> GEOPOS China:City Shanghai Kunming Hangzhou
1) 1) "121.47000163793563843"
2) "31.22999903975783553"
2) 1) "102.70999878644943237"
2) "25.03999958679589355"
3) 1) "120.15000075101852417"
2) "30.2800007575645509"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- GEORADIUS key longitude latitude radius [unit] [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC]:指定圆心、半径,找到该圆范围内包含的所有 member,并按照与圆心的距离排序后返回(6.2 后弃用);
127.0.0.1:6379> GEOSEARCH China:City FROMLONLAT 116.397904 39.909005 BYRADIUS 1000 km WITHDIST 1) 1) "Beijing" 2) "1.0174" 2) 1) "Xian" 2) "803.0689" 127.0.0.1:6379> GEOSEARCH China:City FROMLONLAT 116.397904 39.909005 BYBOX 2000 2000 km WITHDIST 1) 1) "Shanghai" 2) "1068.3526" 2) 1) "Beijing" 2) "1.0174" 3) 1) "Xian" 2) "803.0689 127.0.0.1:6379> GEOSEARCH China:City FROMMEMBER Beijing BYBOX 2000 2000 km WITHDIST 1) 1) "Shanghai" 2) "1067.3788" 2) 1) "Beijing" 2) "0.0000" 3) 1) "Xian" 2) "803.3746"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的 Key(6.2 新功能)。
HmDianPingApplicationTests
@Test void loadShopData() { // 1.查询店铺信息 List<Shop> list = shopService.list(); // 2.把店铺分组,按照typeId分组,typeId一致的放到一个集合 Map<Long, List<Shop>> map = list.stream().collect(Collectors.groupingBy(Shop::getTypeId)); // 3.分批完成写入Redis for (Map.Entry<Long, List<Shop>> entry : map.entrySet()) { // 3.1.获取类型id Long typeId = entry.getKey(); String key = SHOP_GEO_KEY + typeId; // 3.2.获取同类型的店铺的集合 List<Shop> value = entry.getValue(); List<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>(value.size()); // 3.3.写入redis GEOADD key 经度 纬度 member for (Shop shop : value) { // stringRedisTemplate.opsForGeo().add(key, new Point(shop.getX(), shop.getY()), shop.getId().toString()); locations.add(new RedisGeoCommands.GeoLocation<>( shop.getId().toString(), new Point(shop.getX(), shop.getY()) )); } stringRedisTemplate.opsForGeo().add(key, locations); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
10.3 附近商户-实现附近商户功能
SpringDataRedis的2.3.9版本并不支持Redis 6.2提供的GEOSEARCH命令,因此我们需要提示其版本,修改自己的POM
将数据库中的数据导入到 Redis 中:按照商家类型分组,类型相同的商家作为一组,以 typeId 为 Key,商家地址为 Value。
可以安装一个dependency analyzer
第一步:导入pom
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <exclusions> <exclusion> <artifactId>spring-data-redis</artifactId> <groupId>org.springframework.data</groupId> </exclusion> <exclusion> <artifactId>lettuce-core</artifactId> <groupId>io.lettuce</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-redis</artifactId> <version>2.6.2</version> </dependency> <dependency> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> <version>6.1.6.RELEASE</version> </dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
第二步:
ShopController
@GetMapping("/of/type")
public Result queryShopByType(
@RequestParam("typeId") Integer typeId,
@RequestParam(value = "current", defaultValue = "1") Integer current,
@RequestParam(value = "x", required = false) Double x,
@RequestParam(value = "y", required = false) Double y
) {
return shopService.queryShopByType(typeId, current, x, y);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
ShopServiceImpl
@Override public Result queryShopByType(Integer typeId, Integer current, Double x, Double y) { // 1.判断是否需要根据坐标查询 if (x == null || y == null) { // 不需要坐标查询,按数据库查询 Page<Shop> page = query() .eq("type_id", typeId) .page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE)); // 返回数据 return Result.ok(page.getRecords()); } // 2.计算分页参数 int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE; int end = current * SystemConstants.DEFAULT_PAGE_SIZE; // 3.查询redis、按照距离排序、分页。结果:shopId、distance String key = SHOP_GEO_KEY + typeId; GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo() // GEOSEARCH key BYLONLAT x y BYRADIUS 10 WITHDISTANCE .search( key, GeoReference.fromCoordinate(x, y), new Distance(5000), RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end) ); // 4.解析出id if (results == null) { return Result.ok(Collections.emptyList()); } List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent(); if (list.size() <= from) { // 没有下一页了,结束 return Result.ok(Collections.emptyList()); } // 4.1.截取 from ~ end的部分 List<Long> ids = new ArrayList<>(list.size()); Map<String, Distance> distanceMap = new HashMap<>(list.size()); list.stream().skip(from).forEach(result -> { // 4.2.获取店铺id String shopIdStr = result.getContent().getName(); ids.add(Long.valueOf(shopIdStr)); // 4.3.获取距离 Distance distance = result.getDistance(); distanceMap.put(shopIdStr, distance); }); // 5.根据id查询Shop String idStr = StrUtil.join(",", ids); List<Shop> shops = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list(); for (Shop shop : shops) { shop.setDistance(distanceMap.get(shop.getId().toString()).getValue()); } // 6.返回 return Result.ok(shops); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
11、用户签到
11.1、用户签到-BitMap功能演示 BitMap 数据结构
CREATE TABLE `tb_sign` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_id` bigint unsigned NOT NULL COMMENT '用户id',
`year` year NOT NULL COMMENT '签到的年',
`month` tinyint NOT NULL COMMENT '签到的月',
`date` date NOT NULL COMMENT '签到的日期',
`is_backup` tinyint unsigned DEFAULT NULL COMMENT '是否补签',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=COMPACT;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
我们按月来统计用户签到信息,签到记录为1,未签到则记录为0.
把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路就称为位图(BitMap)。这样我们就用极小的空间,来实现了大量数据的表示
Redis中是利用string类型数据结构实现BitMap,因此最大上限是512M,转换为bit则是 2^32个bit位。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-De1InN17-1671001492416)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/%E7%AD%BE%E5%88%B0%E8%A1%A8%20BitMap.jpg)]
BitMap的操作命令有:
SETBIT key offset value向指定位置offset存入一个 0 或 1;GETBIT key offset:获取指定位置offset的 Bit 值;BITCOUNT key [start end]:统计 BitMap 中值为 1 的 Bit 位的数量;BITFIELD key [GET type offset]:操作(查询、修改、自增) BitMap 中 Bit 数组中指定位置offset的值;type:u为无符号,i为有符号;符号后的数字为
- BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
- BITOP :将多个BitMap的结果做位运算(与 、或、异或)
BITPOS key bit [start] [end]:查找 Bit 数组中指定范围内的第一个 0 或 1 出现的位置。
#自写 192.168.8.130:6379> setbit bm1 0 1 (integer) 0 192.168.8.130:6379> setbit bm1 1 1 (integer) 0 192.168.8.130:6379> setbit bm1 2 1 (integer) 0 192.168.8.130:6379> setbit bm1 5 1 (integer) 0 192.168.8.130:6379> setbit bm1 6 1 (integer) 0 192.168.8.130:6379> setbit bm1 7 1 (integer) 0 192.168.8.130:6379> getbit bm1 2 (integer) 1 192.168.8.130:6379> bitcount bm1 (integer) 6 192.168.8.130:6379> bitfield bm1 get u2 0 1) (integer) 3 192.168.8.130:6379> bitfield bm1 get u2 0 1) (integer) 3 192.168.8.130:6379> bitfield bm1 get u3 0 1) (integer) 7 192.168.8.130:6379> bitfield bm1 get u4 0 1) (integer) 14 192.168.8.130:6379> ut2 0 从0开始读两个 1+2=3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
11.2 、用户签到-实现签到功能
需求:实现签到接口,将当前用户当天签到信息保存到Redis中
思路:我们可以把年和月作为bitMap的key,然后保存到一个bitMap中,每次签到就到对应的位上把数字从0变成1,只要对应是1,就表明说明这一天已经签到了,反之则没有签到。
BitMap 底层基于 String 数据结构,因此其操作也都封装到在字符串的相关操作中。
代码
UserController
@PostMapping("/sign")
public Result sign(){
return userService.sign();
}
- 1
- 2
- 3
- 4
UserServiceImpl
@Override
public Result sign() {
// 1.获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 2.获取日期
LocalDateTime now = LocalDateTime.now();
// 3.拼接key
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
String key = USER_SIGN_KEY + userId + keySuffix;
// 4.获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 5.写入Redis SETBIT key offset 1
stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);
return Result.ok();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
#自写
签到之后查看数据
binary 今天五号
sign:1013:202212
00001000 8个bit一字节,要将位置补全
- 1
- 2
- 3
- 4
- 5
11.3 用户签到-签到统计
**问题1:**什么叫做连续签到天数?
从最后一次签到开始向前统计,直到遇到第一次未签到为止,计算总的签到次数,就是连续签到天数。
Java逻辑代码:获得当前这个月的最后一次签到数据,定义一个计数器,然后不停的向前统计,直到获得第一个非0的数字即可,每得到一个非0的数字计数器+1,直到遍历完所有的数据,就可以获得当前月的签到总天数了
**问题2:**如何得到本月到今天为止的所有签到数据?
BITFIELD key GET u[dayOfMonth] 0
假设今天是10号,那么我们就可以从当前月的第一天开始,获得到当前这一天的位数,是10号,那么就是10位,去拿这段时间的数据,就能拿到所有的数据了,那么这10天里边签到了多少次呢?统计有多少个1即可。
问题3:如何从后向前遍历每个bit位?
注意:bitMap返回的数据是10进制,哪假如说返回一个数字8,那么我哪儿知道到底哪些是0,哪些是1呢?我们只需要让得到的10进制数字和1做与运算就可以了,因为1只有遇见1 才是1,其他数字都是0 ,我们把签到结果和1进行与操作,每与一次,就把签到结果向右移动一位,依次内推,我们就能完成逐个遍历的效果了。
需求:实现下面接口,统计当前用户截止当前时间在本月的连续签到天数
有用户有时间我们就可以组织出对应的key,此时就能找到这个用户截止这天的所有签到记录,再根据这套算法,就能统计出来他连续签到的次数了
BitMap 返回的数据是 10 进制的,只需要让得到的 10 进制数字 和 1 进行与运算,每与一次就将签到结果右移一位,实现遍历。
代码
UserController
@GetMapping("/sign/count")
public Result signCount(){
return userService.signCount();
}
- 1
- 2
- 3
- 4
UserServiceImpl
@Override public Result signCount() { // 1.获取当前登录用户 Long userId = UserHolder.getUser().getId(); // 2.获取日期 LocalDateTime now = LocalDateTime.now(); // 3.拼接key String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM")); String key = USER_SIGN_KEY + userId + keySuffix; // 4.获取今天是本月的第几天 int dayOfMonth = now.getDayOfMonth(); // 5.获取本月截止今天为止的所有的签到记录,返回的是一个十进制的数字 BITFIELD sign:5:202203 GET u14 0 List<Long> result = stringRedisTemplate.opsForValue().bitField( key, BitFieldSubCommands.create() .get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0) ); if (result == null || result.isEmpty()) { // 没有任何签到结果 return Result.ok(0); } Long num = result.get(0); if (num == null || num == 0) { return Result.ok(0); } // 6.循环遍历 int count = 0; while (true) { // 6.1.让这个数字与1做与运算,得到数字的最后一个bit位 // 判断这个bit位是否为0 if ((num & 1) == 0) { // 如果为0,说明未签到,结束 break; }else { // 如果不为0,说明已签到,计数器+1 count++; } // 把数字右移一位,抛弃最后一个bit位,继续下一个bit位 num >>>= 1; } return Result.ok(count); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
num << 1; // 左移运算符,num << 1,相当于num乘以2
num >> 1; //右移运算符,num >> 1,相当于num除以2
num >>> 1; //无符号右移,忽略符号位,空位都以0补齐
>>>num
其中,>>>num,是无符号右移操作符,>>>3表示无符号右移三位,无符号则在二进制码前面的空缺位补0。
>>num
对于>>num,是有符号右移操作符。对于正数,右移num位后在前面的空缺位补0,对于负数,右移num位后在前面补1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
11.4 额外加餐-关于使用bitmap来解决缓存穿透的方案
回顾缓存穿透:
发起了一个数据库不存在的,redis里边也不存在的数据,通常你可以把他看成一个攻击
解决方案:
-
判断id<0
-
如果数据库是空,那么就可以直接往redis里边把这个空数据缓存起来
第一种解决方案:遇到的问题是如果用户访问的是id不存在的数据,则此时就无法生效
第二种解决方案:遇到的问题是:如果是不同的id那就可以防止下次过来直击数据
所以我们如何解决呢?
我们可以将数据库的数据,所对应的id写入到一个list集合中,当用户过来访问的时候,我们直接去判断list中是否包含当前的要查询的数据,如果说用户要查询的id数据并不在list集合中,则直接返回,如果list中包含对应查询的id数据,则说明不是一次缓存穿透数据,则直接放行。
现在的问题是这个主键其实并没有那么短,而是很长的一个 主键
哪怕你单独去提取这个主键,但是在11年左右,淘宝的商品总量就已经超过10亿个
所以如果采用以上方案,这个list也会很大,所以我们可以使用bitmap来减少list的存储空间
我们可以把list数据抽象成一个非常大的bitmap,我们不再使用list,而是将db中的id数据利用哈希思想,比如:
id % bitmap.size = 算出当前这个id对应应该落在bitmap的哪个索引上,然后将这个值从0变成1,然后当用户来查询数据时,此时已经没有了list,让用户用他查询的id去用相同的哈希算法, 算出来当前这个id应当落在bitmap的哪一位,然后判断这一位是0,还是1,如果是0则表明这一位上的数据一定不存在, 采用这种方式来处理,需要重点考虑一个事情,就是误差率,所谓的误差率就是指当发生哈希冲突的时候,产生的误差。
12、UV统计
12.1 、UV统计-HyperLogLog
首先我们搞懂两个概念:
- UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
- PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
通常来说UV会比PV大很多,所以衡量同一个网站的访问量,我们需要综合考虑很多因素,所以我们只是单纯的把这两个值作为一个参考值
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖,那怎么处理呢?
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。相关算法原理大家可以参考:https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
UV 统计在服务器端比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存;但是如果所有访问过该网站的用户都保存到 Redis 中,数据量会十分大。
HyperLogLog(HLL) 用于确定非常大的集合的基数,而不需要存储其所有值。
基数:假设数据集 {1,3,5,7,5,7,8},那么这个数据集的基数集为 {1,3,5,7,8},基数(不重复的元素)为 5。
Redis 中的 HyperLogLog 是基于 String 数据结构实现的,单个 HLL 的内存永远小于 16 KB,内存占用非常非常低。
但是它的测量存在小于 0.81% 的误差,不过对于 UV 统计而言,几乎可以忽略。
192.168.8.130:6379> PFADD hl1 e1 e2 e3 e4 e5 (integer) 1 192.168.8.130:6379> PFCOUNT hl1 (integer) 5 192.168.8.130:6379> PFADD hl1 e1 e2 e3 e4 e5 (integer) 0 192.168.8.130:6379> PFCOUNT hl1 (integer) 5 192.168.8.130:6379> 意思是过滤复制 127.0.0.1:6379> pfadd set1 e1 e2 e3 e4 e5 (integer) 1 127.0.0.1:6379> pfadd set2 e4 e5 e6 e7 e8 (integer) 1 # 合并 set1 set2 得到并集 set3 127.0.0.1:6379> pfmerge set3 set1 set2 OK 127.0.0.1:6379> pfcount set3 (integer) 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
12.2 UV统计-测试百万数据的统计
测试思路:我们直接利用单元测试,向HyperLogLog中添加100万条数据,看看内存占用和统计效果如何
@Test void millionDataHyperLogLogTest() { String[] users = new String[1000]; int j = 0; for (int i = 0; i < 1000000; i++) { j = i % 1000; users[j] = "user_" + i; // 分批导入,每 1000 条数据写入一次 if (j == 999) { stringRedisTemplate.opsForHyperLogLog().add("hll", users); } } Long hllSize = stringRedisTemplate.opsForHyperLogLog().size("hll"); System.out.println("size = " + hllSize); // size = 997593 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 测试之前 和 测试之后的内存占用:1106056 、1118960;
- HyperLogLog 占用内存:
(1118960 - 1106056) / 1024 = 12.6KB
经过测试:我们会发生他的误差是在允许范围内,并且内存占用极小
项目的总结
src ├── main │ ├── java │ │ └── com Comment ├── config :存放项目依赖相关配置; │ ├── LocalDateTimeSerializerConfig.java :解决 Json timestamp 转 LocalDateTime 的报错问题; │ ├── MybatisPlusConfiguration.java :配置 MyBatis Plus 分页插件; │ ├── RedisConfiguration.java :创建单例 Redisson 客户端; │ ├── WebExceptionAdvice.java :全局响应拦截器; │ └── WebMvcConfiguration.java :配置了登录、自动刷新登录 Token 的拦截器。 │ ├── controller :存放 Restful 风格的 API 接口; │ ├── dto :存放业务封装类,如 Result 通用响应封装(不推荐学习它的写法); │ ├── entity :存放和数据库对应的 Java POJO; │ ├── interceptor :登录拦截器 & 自动刷新 Redis 登录 Token 有效期; │ ├── mapper :存放操作数据库的代码; │ ├── service :存放业务逻辑处理代码; │ ├── BlogCommentsService.java │ ├── BlogService.java : 基于 Redis 实现点赞、按时间排序的点赞排行榜;基于 Redis 实现拉模式的 Feed 流; │ ├── FollowService.java :基于 Redis 集合实现关注、共同关注; │ ├── ShopService.java : 基于 Redis 缓存优化店铺查询性能;基于 Redis GEO 实现附近店铺按距离排序; │ ├── UserService.java : 基于 Redis 实现短信登录(分布式 Session); │ ├── VoucherOrderService.java :基于 Redis 分布式锁、Redis + Lua 两种方式,结合消息队列,共同实现了秒杀和一人一单功能; │ ├── VoucherService.java :添加优惠券,并将库存保存在 Redis 中,为秒杀做准备。 │ └── utils :存放项目内通用的工具类; ├── CacheClient.java :封装了通用的缓存工具类,涉及泛型、函数式编程等知识点; ├── DistributedLock.java ├── RedisConstants.java :保存项目中用到的 Redis 键、过期时间等常量; ├── RedisData.java ├── RedisIdWorker.java :基于 Redis 的全局唯一自增 ID 生成器; ├── SimpleDistributedLockBasedOnRedis.java :简单的 Redis 锁实现,了解即可,一般用 Redisson; └── UserHolder.java :线程内缓存用户信息。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
完整代码
UserDto
package com.hmdp.dto;
import lombok.Data;
@Data
public class UserDTO {
private Long id;
private String nickName;
private String icon;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
User
@Data @EqualsAndHashCode(callSuper = false) @Accessors(chain = true) @TableName("tb_user") public class User implements Serializable { private static final long serialVersionUID = 1L; /** * 主键 */ @TableId(value = "id", type = IdType.AUTO) private Long id; /** * 手机号码 */ private String phone; /** * 密码,加密存储 */ private String password; /** * 昵称,默认是随机字符 */ private String nickName; /** * 用户头像 */ private String icon = ""; /** * 创建时间 */ private LocalDateTime createTime; /** * 更新时间 */ private LocalDateTime updateTime; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
UserHolder
public class UserHolder {
private static final ThreadLocal<UserDTO> tl = new ThreadLocal<>();
public static void saveUser(UserDTO user){
tl.set(user);
}
public static UserDTO getUser(){
return tl.get();
}
public static void removeUser(){
tl.remove();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
RegexUtils
mport cn.hutool.core.util.StrUtil; public class RegexUtils { /** * 是否是无效手机格式 * @param phone 要校验的手机号 * @return true:符合,false:不符合 */ public static boolean isPhoneInvalid(String phone){ return mismatch(phone, RegexPatterns.PHONE_REGEX); } /** * 是否是无效邮箱格式 * @param email 要校验的邮箱 * @return true:符合,false:不符合 */ public static boolean isEmailInvalid(String email){ return mismatch(email, RegexPatterns.EMAIL_REGEX); } /** * 是否是无效验证码格式 * @param code 要校验的验证码 * @return true:符合,false:不符合 */ public static boolean isCodeInvalid(String code){ return mismatch(code, RegexPatterns.VERIFY_CODE_REGEX); } // 校验是否不符合正则格式 private static boolean mismatch(String str, String regex){ if (StrUtil.isBlank(str)) { return true; } return !str.matches(regex); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
Result
@Data @NoArgsConstructor @AllArgsConstructor public class Result { private Boolean success; private String errorMsg; private Object data; private Long total; public static Result ok(){ return new Result(true, null, null, null); } public static Result ok(Object data){ return new Result(true, null, data, null); } public static Result ok(List<?> data, Long total){ return new Result(true, null, data, total); } public static Result fail(String errorMsg){ return new Result(false, errorMsg, null, null); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
LoginFormDTO
@Data
public class LoginFormDTO {
private String phone;
private String code;
private String password;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
代码总思路
1.redis实现验证码缓存,token更新
- 验证码存入redis中(phone,code)
- 验证码成功,进行token(token,map(user))
- 第一个拦截器拦截所有路径,从请求头获取toekn,更新toekn(携带的用户保存),都放行
- 第二个拦截器特定路径,判断有用户就放行
2.商铺缓存
1.缓存的更新:内存淘汰,超时剔除 ,主动更新
2.主动更新:
Cache Aside Pattern Read/Write Through Pattern Write Behind Catching Pattern 由缓存的调用者,在更新数据库的同时更新缓存 缓存与数据库整合为一个服务,由服务来维护一致性。调用者使用该服务,无需关心缓存一致性问题。 调用者只凑走缓存,由其他线程异步的将缓存数据持久到数据库中,保证最终一致性。
3.选择删除缓存,先更新数据库,再删除缓存
- 更新缓存:每次更新数据库时都更新缓存,无效写操作较多
- 删除缓存:每次更新数据库时都让缓存失效,查询时再更新缓存。
如何保证缓存和数据库的操作同时成功或失败?- 单体系统:将缓存与数据库操作放在一个事务;
- 分布式系统:利用 TCC 等分布式事务方案。
- 先删除缓存,再操作数据库;
4.缓存更新策略的最佳实践方案
- 低一致性需求:使用 Redis 自带的内存淘汰机制;
- 高一致性需求:使用主动更新策略,并以超时剔除作为兜底方案。
读操作:- 缓存命中则直接返回;
- 缓存未命中则查询数据库,并写入缓存,设定超时时间。
写操作:- 先写数据库,然后再删缓存;
- 确保数据库与缓存操作的原子性。
5.再shop的更新时候删除缓存
3.缓存穿透,缓存雪崩,缓存击穿
1.缓存穿透
缓存穿透:查询某个 Key 对应的数据,Redis 缓存中没有相应的数据,则直接到数据库中查询;数据库中也不存在要查询的数据,数据库会返回空,Redis 也不会缓存这个空结果;导致每次通过这个 Key 查询数据都会直接到数据库中查询。给数据库带来巨大的压力,可能最终会导致数据库崩溃。
Redis 缓存穿透的两种方法
- 缓存空对象:发送请求,未命中缓存,未命中数据库,为了防止不断的请求,将 null 缓存到 Redis 中;之后的请求将会直接命中 Redis 缓存中的 null 值。
- 实现简单,维护方便;
- 缓存中包含过多的 null 值,会造成额外的内存消耗(可以设置 TTL 解决);
- 可能造成短期的不一致(可以通过 先操作数据库,后删除缓存 解决)。
- 布隆过滤:
- 内存占用较少,没有多余的 key;
- 实现复杂;
- 存在误判的可能。
@Override public Result queryById(Long id) { // 缓存穿透 Shop shop = dealWithCachePenetrationByNullValue(id); return Result.ok(shop); } /** * 通过缓存空对象解决 Redis 的缓存穿透问题 */ public Shop dealWithCachePenetrationByNullValue(Long id) { String key = CACHE_SHOP_KEY + id; // 1. 从 Redis 中查询店铺缓存; String shopJson = redisTemplate.opsForValue().get(key); // 2. 若 Redis 中存在(命中),则将其转换为 Java 对象后返回; if (StrUtil.isNotBlank(shopJson)) { Shop shop = JSONUtil.toBean(shopJson, Shop.class); return shop; } // 3. 命中缓存后判断是否为空值 if (ObjectUtil.equals(shopJson, "")) { return null; } // 4. 若 Redis 中不存在(未命中),则根据 id 从数据库中查询; Shop shop = getById(id); // 5. 若 数据库 中不存在,将空值写入 Redis(缓存空对象) if (shop == null) { redisTemplate.opsForValue().set(key, "", TTL_TWO, TimeUnit.MINUTES); return null; } // 6. 若 数据库 中存在,则将其返回并存入 Redis 缓存中。 redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), TTL_THIRTY, TimeUnit.MINUTES); return shop; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
2.缓存雪崩:
缓存雪崩:大量的 Key 在同一时间内大面积的失效 或者 Redis 服务宕机,导致后面的请求直接打到数据库,造成数据库短时间内承受大量的请求。
解决方案:
- 给不同的 Key 的 TTL 添加随机值,避免同时失效;
- 利用 Redis 集群提高服务的可用性;
- 给缓存业务添加降级限流策略;
- 给业务添加多级缓存。
3.缓存击穿
缓存击穿问题,也叫 热点 Key 问题;就是一个被 高并发访问 并且 缓存中业务较复杂的 Key 突然失效,大量的请求在极短的时间内一起请求这个 Key 并且都未命中,无数的请求访问在瞬间打到数据库上,给数据库带来巨大的冲击。
缓存击穿的解决方案
互斥锁:查询缓存未命中,获取互斥锁,获取到互斥锁的才能查询数据库重建缓存,将数据写入缓存中后,释放锁。
逻辑过期:查询缓存,发现逻辑时间已经过期,获取互斥锁,开启新线程;在新线程中查询数据库重建缓存,将数据写入缓存中后,释放锁;在释放锁之前,查询该数据时,都会将过期的数据返回。
4. 基于互斥锁解决缓存击穿问题
核心:利用 Redis 的 setnx 方法来表示获取锁。该方法的含义是:如果 Redis 中没有这个 Key,则插入成功;如果有这个 Key,则插入失败。通过插入成功或失败来表示是否有线程插入 Key,插入成功的 Key 则认为是获取到锁的线程;释放锁就是将这个 Key 删除,因为删除 Key 以后其他线程才能再执行 setnx 方法。
/** * 获取互斥锁 */ private boolean tryLock(String key) { Boolean flag = redisTemplate.opsForValue().setIfAbsent(key, "1", TTL_TEN, TimeUnit.SECONDS); return BooleanUtil.isTrue(flag); } /** * 释放互斥锁 */ private void unLock(String key) { redisTemplate.delete(key); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
1.请求打进来,先去 Redis 中查,未命中;
2.获取互斥锁:将一个 Key 为 LOCK_SHOP_KEY + id 的数据写入 Redis 中,此时其他线程就无法拿到这个 Key,也就无法继续后续操作;
3.获取失败就进行休眠,休眠结束后通过递归再次请求;
4.获取成功,查询数据库、将需要查询的那个数据写入 Redis;
5.最后,删除通过 setnx 创建的那个 Key。@Override public Result queryById(Long id) { // 缓存击穿(Mutex) Shop shop = dealWithCacheHotspotInvalidByMutex(id); return Result.ok(shop); } /** * 通过互斥锁解决 Redis 的缓存击穿问题 */ public Shop dealWithCacheHotspotInvalidByMutex(Long id) { String key = CACHE_SHOP_KEY + id; // 1. 从 Redis 中查询店铺缓存; String shopJson = redisTemplate.opsForValue().get(key); // 2. 若 Redis 中存在(命中),则将其转换为 Java 对象后返回; if (StrUtil.isNotBlank(shopJson)) { return JSONUtil.toBean(shopJson, Shop.class); } // 3. 命中缓存后判断是否为空值 if (ObjectUtil.equals(shopJson, "")) { return null; } // 4. 若 Redis 中不存在(缓存未命中),实现缓存重建 // 4.1 获取互斥锁 String lockKey = LOCK_SHOP_KEY + id; Shop shop = null; try { boolean isLocked = tryLock(lockKey); // 4.2 获取失败,休眠重试 if (!isLocked) { Thread.sleep(50); return dealWithCacheHotspotInvalidByMutex(id); } // 4.3 获取成功,从数据库中根据 id 查询数据 shop = getById(id); // 4.4 若 数据库 中不存在,将空值写入 Redis(缓存空对象) if (shop == null) { redisTemplate.opsForValue().set(key, "", TTL_TWO, TimeUnit.MINUTES); return null; } // 4.5 若 数据库 中存在,则将其返回并存入 Redis 缓存中。 redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), TTL_THIRTY, TimeUnit.MINUTES); } catch (Exception e) { throw new RuntimeException(e); } finally { // 5. 释放互斥锁 unLock(lockKey); } return shop; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
5.逻辑过期解决缓存击穿
- 可以认为存储到 Redis 中的 Key 永久有效的,其过期时间是可以代码控制的,而非通过 TTL 控制。
- 因此 Redis 存储的数据需要带上一个逻辑过期时间,即 Shop 实体类中需要一个逻辑过期时间属性。
- 可以新建一个 RedisData,该类包含两个属性 —— expireTime 和 Data,对原来的代码没有入侵性。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R2EpP1Ux-1671001492417)(https://itsawaysu.oss-cn-shanghai.aliyuncs.com/note/基于逻辑过期解决缓存击穿问题.jpg)]
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10); public <R, ID> R queryWithLogicalExpire( String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) { String key = keyPrefix + id; // 1.从redis查询商铺缓存 String json = stringRedisTemplate.opsForValue().get(key); // 2.判断是否存在 if (StrUtil.isBlank(json)) { // 3.不存在,直接返回 return null; } // 4.命中,需要先把json反序列化为对象 RedisData redisData = JSONUtil.toBean(json, RedisData.class); R r = JSONUtil.toBean((JSONObject) redisData.getData(), type); LocalDateTime expireTime = redisData.getExpireTime(); // 5.判断是否过期 if(expireTime.isAfter(LocalDateTime.now())) { // 5.1.未过期,直接返回店铺信息 return r; } // 5.2.已过期,需要缓存重建 // 6.缓存重建 // 6.1.获取互斥锁 String lockKey = LOCK_SHOP_KEY + id; boolean isLock = tryLock(lockKey); // 6.2.判断是否获取锁成功 if (isLock){ // 6.3.成功,开启独立线程,实现缓存重建 CACHE_REBUILD_EXECUTOR.submit(() -> { try { // 查询数据库 R newR = dbFallback.apply(id); // 重建缓存 this.setWithLogicalExpire(key, newR, time, unit); } catch (Exception e) { throw new RuntimeException(e); }finally { // 释放锁 unlock(lockKey); } }); } // 6.4.返回过期的商铺信息 return r; } // 逻辑过期解决缓存击穿 // Shop shop = cacheClient // .queryWithLogicalExpire(CACHE_SHOP_KEY, id, Shop.class,this::getById,CACHE_SHOP_TTL,TimeUnit.MINUTES );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
6.超卖问题
使用 Jmeter 进行测试能够发现:秒杀优惠券的库存为 负数,生成的订单数量超过 100 份。
多线程下单出现超卖问题
悲观锁:每次拿数据的时候都会上锁,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程;
乐观锁:每次拿数据的时候都不会上锁,但在更新时会判断在此期间有没有其他线程更新这个数据;如果存在冲突,则采取一个补偿措施(比如告知用户失败)。
乐观锁的关键是判断之前查询得到的数据是否被修改过;
一般有 2 种实现方式:版本号法 和 CAS 法。
- 通过版本号法实现乐观锁
查询数据,获取当前需要操作数据的 版本号;
更新数据时同时需要更新版本号;
若执行更新时的版本号 与 最初查询获取到的版本号不同,则更新失败。假设库存为 1,有线程1、2、3,时刻 t1、t2、t3、t4。
线程1 在 t1 查询库存,库存为 1,版本号为 1;线程2 在 t2 查询库存,库存为 1,版本号为 1;线程3 在 t2 查询库存,库存为 1,版本号为 1。
线程1 在 t3 下单,库存扣减为0,版本号为 2;
线程2 和 线程3 在 t4 下单,版本号为 2,与最初查询到的版本号不同,执行失败。# id = 10, stock = 1, version = 1 SELECT id, stock, version FROM tb_scekill_voucher; # id = 10, stock = 0, version = 2 UDATE SET tb_seckill_voucher stock = stock - 1, version = version + 1 WHERE id = 10 AND version = 1;
- 1
- 2
- 3
- 4
- 5
- 6
CAS Compare And Set
通过以上描述发现,stock 能够替代 version 字段 —— 查询、然后更新、更新时检查其是否与最初查询的值一致。
查询获取 stock;
更新 stock;
若执行更新时的 stock 与最初查询到的 stock 的值不同,则更新失败。
假设库存为 1,有线程1、2、3,时刻 t1、t2、t3、t4。线程1 在 t1 查询库存,库存为 1;线程2 在 t2 查询库存,库存为 1;线程3 在 t2 查询库存,库存为 1。
线程1 在 t3 下单,库存扣减为0;
线程2 和 线程3 在 t4 下单,库存为 0,与最初查询到的库存不同,执行失败。乐观锁解决超卖问题
使用乐观锁:进行测试会发现,库存尚未不足时就会导致很多线程更新失败 —— 若有十个线程查询到的
stock为100,只要有一个更新成功,其他全部失败。// 4. 减扣库存 boolean isAccomplished = seckillVoucherService.update() // SET stock= stock - 1 .setSql("stock = stock - 1") // WHERE voucher_id = ? AND stock = ? .eq("voucher_id", voucherId).eq("stock",seckillVoucher.getStock()) .update(); if (!isAccomplished) { return Result.fail("库存不足.."); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
此处不会超卖:基于数据库的
update语句自带行锁,一旦某个用户对某行进行update操作,其他用户只能查询但不能update被加锁的数据行。
只需要让stock > 0即可~CAS的缺点:
1.CPU开销较大
在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复,会给CPU带来很大的压力。2.不能保证代码块的原子性
CAS机制所保证的只是一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证3个变量共同进行原子性的更新,就不得不使用Synchronized了。// 4. 减扣库存boolean isAccomplished = seckillVoucherService.update() // SET stock= stock - 1 .setSql("stock = stock - 1") // WHERE voucher_id = ? AND stock > 0 .eq("voucher_id", voucherId).gt("stock", 0) .update(); if (!isAccomplished) { return Result.fail("库存不足.."); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
7.一人一单
**存在问题:**高并发的情况下,查询数据库时,都不存在订单,仍然会出现一人多单的情况,仍需加锁。乐观锁比较适合更新操作,此处的插入操作选择悲观锁。
**注意:**在这里提到了非常多的问题,我们需要慢慢的来思考,首先我们的初始方案是封装了一个createVoucherOrder方法,同时为了确保他线程安全。首先,初始方案是在 createVoucherOrder 方法上添加 synchronized,这样导致锁的粒度过大。
在seckillVoucher 方法中,添加以下逻辑,这样就能保证事务的特性,同时也控制了锁的粒度
public synchronized Result createVoucherOrder(Long voucherId) {
}
- 1
- 2
于是选择 “一个用户一把锁” 这样的方案。但是必须先保证 锁是同一把:userId.toString() 方法锁获取到的字符串是不同的对象,底层是 new 出来的,intern() 方法是从常量池里获取数据,保证了同一个用户的 userId.toString() 值相同。
@Transactional
@Override
public Result createVoucherOrder(Long voucherId) {
Long userId = UserHolder.getUser().getId();
synchronized(userId.toString().intern()) {
...
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
此外,还需要注意一个点,我们需要将 createVoucherOrder 方法整体包裹起来,确保事务不会出问题;否则会出现 “synchronized 包裹的代码片段执行完毕,事务还未提交,但是锁已经释放了” 的情况。
但是以上代码还是存在问题,问题的原因在于当前方法被spring的事务控制,如果你在方法内部加锁,可能会导致当前方法事务还没有提交,但是锁已经释放也会导致问题,所以我们选择将当前方法整体包裹起来,确保事务不会出现问题:如下:
synchronized (userId.toString().intern()) {
return createVoucherOrder(voucherId);
}
- 1
- 2
- 3
最后,createVoucherOrder 方法实际上是通过 this.createVoucherOrder() 的方式调用的,this 拿到的是原始对象,没有经过动态代理,事务要生效,需要使用代理对象来执行。
synchronized (userId.toString().intern()) {
// 获取代理对象
VoucherOrderService currentProxy = (VoucherOrderService) AopContext.currentProxy();
return currentProxy.createVoucherOrder(voucherId);
}
- 1
- 2
- 3
- 4
- 5
终极版本
@Override public Result seckillVoucher(Long voucherId) { // 1. 根据 优惠券 id 查询数据库 SeckillVoucher seckillVoucher = seckillVoucherService.getById(voucherId); // 2. 判断秒杀是否开始或结束(未开始或已结束,返回异常结果) if (LocalDateTime.now().isBefore(seckillVoucher.getBeginTime())) { return Result.fail("秒杀尚未开始.."); } if (LocalDateTime.now().isAfter(seckillVoucher.getEndTime())) { return Result.fail("秒杀已经结束.."); } // 3. 判断库存是否充足(不充足返回异常结果) if (seckillVoucher.getStock() < 1) { return Result.fail("库存不足.."); } Long userId = UserHolder.getUser().getId(); synchronized (userId.toString().intern()) { // 获取代理对象 VoucherOrderService currentProxy = (VoucherOrderService) AopContext.currentProxy(); return currentProxy.createVoucherOrder(voucherId); } } @Transactional @Override public Result createVoucherOrder(Long voucherId) { Long userId = UserHolder.getUser().getId(); // 4. 一人一单(根据 优惠券id 和 用户id 查询订单;存在,则直接返回) Integer count = query().eq("voucher_id", voucherId).eq("user_id", userId).count(); if (count > 0) { return Result.fail("不可重复下单!"); } // 5. 减扣库存 boolean isAccomplished = seckillVoucherService.update() // SET stock= stock - 1 .setSql("stock = stock - 1") // WHERE voucher_id = ? AND stock > 0 .eq("voucher_id", voucherId).gt("stock", 0) .update(); if (!isAccomplished) { return Result.fail("库存不足.."); } // 6. 创建订单 VoucherOrder voucherOrder = new VoucherOrder(); long orderId = redisIdWorker.nextId("order"); voucherOrder.setId(orderId); voucherOrder.setUserId(userId); voucherOrder.setVoucherId(voucherId); boolean isSaved = save(voucherOrder); if (!isSaved) { return Result.fail("下单失败.."); } // 7. 返回 订单 id return Result.ok(orderId); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
#自写 Long usrId = UserHolder.getUser().getId(); synchronized(usrId.toString().intern()) { IVoucherOrderService proxy = (IVoucherOrderService)AopContext.currentProxy(); return proxy.createVoucherOrder(voucherId); } //但是这个时候的事务优点问题调用的是this剩下,拿到当前的oder对象不是代理对象, // 所以没有事务功能,所以拿到事务的代理对象 同时在pom.xml引入依赖 <!-- https://mvnrepository.com/artifact/org.aspectj/aspectjweaver --> <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> <version>1.9.9.1</version> <scope>runtime</scope> </dependency> # 同时在springboot开注解
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
8.分布式锁集群项目
- 单体项目的时候可以用
- 线程1/2 和 线程3/4 使用的不是同一份代码,锁对象不是同一个,于是线程1/2 与 线程3/4 之间无法实现互斥;导致
synchronized锁失效,这种情况下就需要 分布式锁 来解决。SimpleRedisLock**
利用setnx方法进行加锁,同时增加过期时间,防止死锁,此方法可以保证加锁和增加过期时间具有原子性
redis锁代替悲观锁,解决分布式锁的问题(创建新的simpleredislock对象+代理对象调用方法)
此时出现问题删除锁的时候多线程可能出现锁的误删
在获取锁的时候存入线程标识(用 UUID 表示);
在释放锁时先获取锁中的线程标识,判断是否与当前的线程标识一致;
出现问题“判断线程标识的一致性 与 释放锁” 操作的需要原子性。
用lua脚本执行多条命令的原子性
在判断线程标识和释放锁的操作是lua脚本保证原子性
9.redission分布式锁
- 1)不可重入Redis分布式锁:
原理:利用setnx的互斥性;利用ex避免死锁;释放锁时判断线程标示
缺陷:不可重入、无法重试、锁超时失效- 2)可重入的Redis分布式锁:
原理:利用hash结构,记录线程标示和重入次数;利用watchDog延续锁时间;利用信号量控制锁重试等待
缺陷:redis宕机引起锁失效问题- 3)Redisson的multiLock:
原理:多个独立的Redis节点,必须在所有节点都获取重入锁,才算获取锁成功
缺陷:运维成本高、实现复杂
10.秒杀优化基于阻塞队列
- 新增秒杀优惠券的同时,将优惠券信息保存到 Redis 中
- 基于 Lua 脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
- 如果抢购成功,将优惠券 id 和用户 id 封装后存入阻塞队列
- 开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
- 完成init之后,执行seckillVoucher(voucherId)
- 执行脚本返回资格,如果有资格进行创建订单,将订单加入到阻塞队列中,返回订单号。
小总结:
- 先利用Redis完成库存余量、一人一单判断,完成抢单业务
- 再将下单业务放入阻塞队列,利用独立线程异步下单
- 基于阻塞队列的异步秒杀存在哪些问题?
- 内存限制问题
- 数据安全问题
11.秒杀优化基于消息队列
用消息队列代替阻塞队列
12.点赞用sortedSet
之前的点赞放在 Set 集合中,但是 Set 集合是无序不可重复的,此处需要使用可排序的 Set 集合,即 SortedSet。
13.关注互关用set
总结用关注set(key用户,value关注用户名)
互相关注的时候用stringRedisTemplate.opsForSet().intersect(selfKey, aimKey);
注意:为了实现共同关注功能,使用 Set,因为 Set 中有
SINTER - 交集、SDIFFER - 差集、SUNION - 并集命令。
14.Feed流推送
本例中的个人页面,是基于关注的好友来做 Feed 流,因此采用 Timeline 的模式。
- 该模式的实现方案有三种:拉模式、推模式、推拉结合
feed流滚动分页用满足这种条件的 Redis 中的数据结构就是 SortedSet
15GEO实现附近商务功能
Geolocation**,代表地理位置,允许存储地理坐标。GEO 底层的实现原理是 ZSET,可以使用 ZSET 的命令操作 GEO。
将数据库中的数据导入到 Redis 中:按照商家类型分组,类型相同的商家作为一组,以
typeId为 Key,商家地址为 Value。
16.BitMap实现用户签到
BitMap 返回的数据是 10 进制的,只需要让得到的 10 进制数字 和 1 进行与运算,每与一次就将签到结果右移一位,实现遍历。
17.UV统计-HyperLogLog
- UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
- PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
参考博主:(文章)[https://blog.csdn.net/weixin_45033015?type=blog]

