
- 1集合框架系列 Map(十):HashMap 1.8
- 2Modbus通讯开发随记1——LibModbus库的学习
- 3运用tensorflow实现自然场景文字检测,keras/pytorch实现crnn+ctc实现不定长中文OCR识别_pytorch 不等长数据做ctc
- 4web安全的攻击与防范
- 5JAVA毕业设计097—基于Java+Springboot+Vue+uniapp的医院挂号小程序系统(源码+数据库)_医疗行业 开源的 预约,挂号,管理系统
- 6React中JSX语法入门
- 7linux安装nfs后,启动pod报错‘selfLink was empty, can‘t make reference‘...
- 8使用Flask-Admin创建强大的后台管理系统
- 9Nginx的root与alias用法+区别案例+返回自定义错误页面_nginx root 优先级
- 10set和map的区别
Database Meets AI: A Survey_knob tuning
赞
踩
文章目录
论文地址
Abstract
数据库和人工智能(AI)可以相互受益。一方面,人工智能可以使数据库更加智能化(AI4DB)。例如,传统的经验数据库优化技术(例如,成本估算、连接顺序选择、旋钮调整、索引和视图选择)无法满足大规模数据库实例、各种应用程序和多样化用户的高性能要求,尤其是在云上。幸运的是,基于学习的技术可以缓解这个问题。另一方面,数据库技术可以优化AI模型(DB4AI)。例如,人工智能很难在实际应用中部署,因为它需要开发人员编写复杂的代码和训练复杂的模型。数据库技术可用于降低使用AI模型的复杂性,加速AI算法,并在数据库中提供AI功能。因此,DB4AI和AI4DB最近都得到了广泛的研究。在本文中,我们回顾了AI4DB和DB4AI的现有研究。对于AI4DB,我们回顾了基于学习的配置优化、优化器、索引/视图顾问和安全性方面的技术。对于DB4AI,我们回顾了面向AI的声明性语言、面向AI的数据治理、训练加速和推理加速。最后,我们提出了研究挑战和未来方向。
Index Terms: Database, Artificial Intelligence, DB4AI, AI4DB
1 INTRODUCTION
人工智能(AI)和数据库(DB)在过去五十年中得到了广泛的研究。首先,数据库系统在许多应用中得到了广泛的应用,因为数据库通过提供用户友好的声明性查询范例和封装复杂的查询优化功能而易于使用。其次,人工智能最近取得了突破,这得益于三大驱动力:大规模数据、新算法和高计算能力。此外,人工智能和数据库可以相互受益。一方面,人工智能可以使数据库更加智能化(AI4DB)。
例如,传统的经验数据库优化技术(例如,成本估算、连接顺序选择、旋钮调整、索引和视图选择)无法满足大型数据库实例、各种应用程序和多样化用户的高性能要求,尤其是在云上。幸运的是,基于学习的技术可以缓解这个问题。例如,深度学习可以提高成本估算的质量,深度强化学习可以用来调整数据库旋钮。另一方面,数据库技术可以优化AI模型(DB4AI)。人工智能很难在实际应用中部署,因为它需要开发人员编写复杂的代码和训练复杂的模型。数据库技术可用于降低使用AI模型的复杂性,加速AI算法,并在数据库中提供AI功能。因此,DB4AI和AI4DB最近都得到了广泛的研究。
1.1 AI for DB
传统的数据库设计基于经验方法、理论和规范,需要人工参与(如DBA)来调整和维护数据库。人工智能技术被用来缓解这些限制——探索比人类更多的设计空间,并取代启发式来解决难题。我们将使用AI优化DB的现有技术分类如下。
Learning-based Database Configuration
- Knob tuning.
数据库有数百个旋钮,需要DBA调整旋钮以适应不同的场景。显然,DBA无法扩展到云数据库上的数百万个数据库实例。最近,数据库社区试图利用基于学习的技术自动调整旋钮,这可以探索更多旋钮组合空间并推荐高质量旋钮值,从而获得比DBA更好的结果。 - Index/View advisor
数据库索引和视图对于实现高性能至关重要。然而,传统数据库高度依赖DBA来构建和维护索引和视图。由于有大量列/表组合,因此推荐和构建适当的索引/视图的成本很高。最近,有一些基于学习的作品自动推荐和维护索引和视图。 - SQL Rewriter
许多SQL程序员无法编写高质量的SQL,因此需要重写SQL查询以提高性能。例如,嵌套查询将被重写为连接查询,以启用SQL优化。现有方法采用基于规则的策略,使用一些预定义的规则重写SQL查询。然而,这些基于规则的方法依赖于高质量的规则,无法扩展到大量规则。因此,深度强化学习可以用于明智地选择适当的规则,并以良好的顺序应用规则
Learning-based Database Optimization
- Cardinality/Cost Estimation
数据库优化器依赖于成本和基数估计来选择优化的计划,但传统技术无法有效捕获不同列/表之间的相关性,因此无法提供高质量的估计。最近,人们提出了基于深度学习的技术,通过使用深度神经网络捕捉相关性来估计成本和基数,从而获得更好的结果。 - Join order selection
一个SQL查询可能有数百万甚至数十亿个可能的计划,高效地找到一个好的计划非常重要。传统的数据库优化器无法为几十个表找到好的计划,因为探索巨大的计划空间的成本相当高。因此,有一些基于深度强化学习的方法可以自动选择好的计划。 - End-to-end Optimizer
一个成熟的优化器不仅要响应成本/基数估计和连接顺序,还需要考虑索引和视图,设计一个端到端优化器非常重要。基于学习的优化器使用深度神经网络优化SQL查询。
Learning-based Database Design
传统的数据库是由数据库架构师根据自己的经验设计的,但数据库架构师只能探索有限的设计空间。最近,一些基于学习的自我设计技术被提出。
- 提出学习索引不仅可以减少索引大小,还可以提高索引性能
- 学习数据结构设计
不同的数据结构可能适用于不同的环境(例如,不同的硬件、不同的读取-/编写应用程序),很难为每个场景设计合适的结构。数据结构炼金术旨在为不同的数据结构创建一个数据推理引擎,用于推荐和设计数据结构。 - 基于学习的事务管理
传统的事务管理技术侧重于事务协议,例如OCC、PCC、MVCC、2PC。最近,一些研究试图利用人工智能技术预测事务并安排事务。他们从现有的数据模式中学习,有效地预测未来的工作负载趋势,并通过平衡冲突率和并发性来有效地调度它们。
Learning-based Database Monitoring
数据库监视器可以捕获数据库运行时指标,如读/写延迟、CPU/内存使用情况,从而在出现异常时(如性能下降和数据库攻击)提醒管理员。然而,传统的监视方法依赖于数据库管理员来监视大多数数据库活动并报告问题,这是不完整和低效的。因此,提出了基于机器学习的技术来优化数据库监控,这决定了何时以及如何监控哪些数据库指标。
Learning-based Database Security
传统的数据库安全技术(如数据屏蔽和审计)依赖于用户定义的规则,但无法自动检测未知的安全漏洞。因此,提出了基于人工智能的算法来发现敏感数据、检测异常,进行访问控制,并避免SQL注入。
1.2 DB for AI
虽然人工智能可以解决许多现实问题,但没有一个广泛部署的人工智能系统可以像DBMS那样应用于不同的领域,因为现有的人工智能系统可复制性差,很难被普通用户使用。为了解决这个问题,可以使用数据库技术来降低使用AI的障碍。
Declarative Query Paradigm
SQL相对容易使用,在数据库系统中被广泛接受。然而,与其他高级机器学习语言相比,SQL缺少一些复杂的处理模式(例如,迭代训练)。幸运的是,SQL可以扩展以支持AI模型,我们还可以设计用户友好的工具来支持SQL语句中的AI模型。
Data Governance
数据质量对于机器学习很重要,数据治理可以提高数据质量,包括数据发现、数据清理、数据集成、数据标记和数据沿袭。
- Data discovery
基于学习的数据发现增强了查找相关数据的能力,有效地在大量数据源中查找相关数据。 - Data cleaning
脏的或不一致的数据会严重影响训练效果。数据清理和集成技术可以检测和修复脏数据,并集成来自多个源的数据以生成高质量的数据。 - Data labeling
借助领域专家、众包(crowdsourcing)和知识库(knowledge base),我们可以适当地利用人力或现有知识为ML算法标记大量的训练数据。 - Data lineage
数据沿袭描述了输入和输出之间的关系,对于确保ML模型正常工作非常重要。通过连接和图形映射等数据库技术,我们可以前后跟踪数据关系。
Model Training
模型训练旨在训练一个好的模型,用于在线推理。模型训练是一个耗时且复杂的过程,因此需要优化技术,包括特征选择、模型选择、模型管理和硬件加速。
- Feature selection
它旨在从大量可能的特征中选择合适的特征。选择和评估可能的特征非常耗时。因此,提出了批处理、物化等技术来解决这个问题。 - Model selection
它旨在从大量可能的模型中选择合适的模型(和参数值)。因此,提出了一些并行技术来加速这一步骤,包括任务并行、批量同步并行、参数服务器和模型跃点并行性。 - Model management
由于模型培训是一个反复试验的过程,需要维护许多已经试验过的模型和参数,因此有必要设计一个模型管理系统来跟踪、存储和搜索ML模型。我们回顾了基于GUI和基于命令的模型管理系统。 - Hardware acceleration.
还使用GPU和FPGA等硬件加速模型训练。我们分别在行存储和列存储数据库中介绍了硬件加速技术。
Model Inference
模型推理旨在使用经过训练的模型有效地推断结果,数据库中的优化技术包括操作符支持、操作符选择和执行加速。
- Operator support
ML模型可能包含不同类型的操作符(例如,标量、张量),这些操作符具有不同的优化要求。因此,提出了一些数据库内技术来支持AI操作符,包括标量操作、张量运算和张量分区。 - Operator selection
相同的ML模型可以转换为不同的物理操作符,这可能会带来显著的性能差异。在数据库中,操作员选择可以估计资源消耗并明智地安排操作员。 - Execution acceleration
推理加速旨在提高执行效率。一方面,内存数据库将样本/模型数据压缩到内存中,并进行内存优化。另一方面,分布式数据库通过向不同节点分配任务来提高执行效率
1.3 Contributions
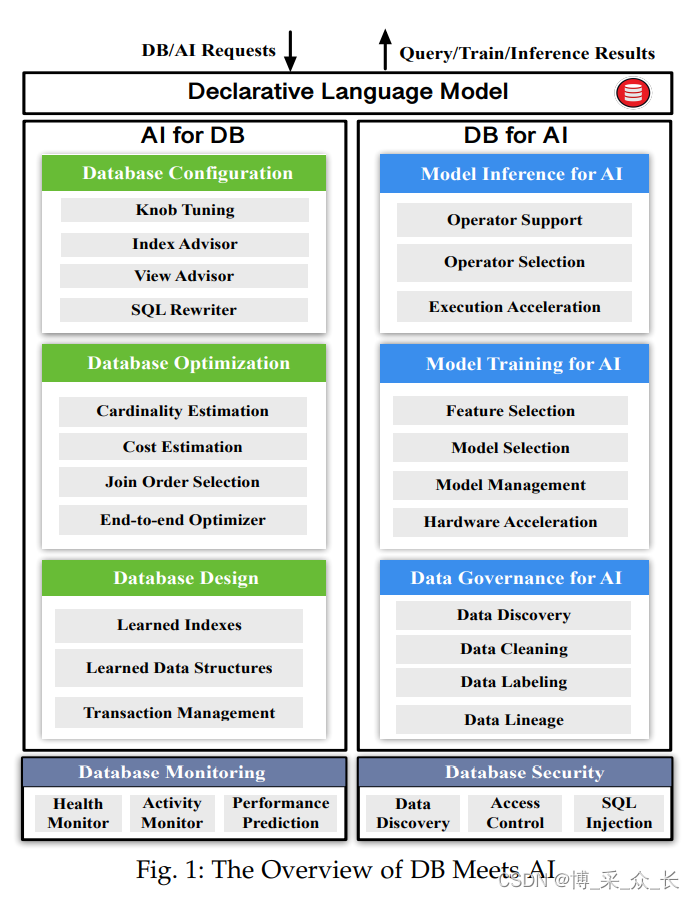
我们做出了以下贡献(见图1)
- 我们回顾了利用AI技术优化数据库的AI4DB技术,包括基于学习的配置调优、优化器和索引/视图顾问(见第2节)
- 我们回顾了利用DB技术使AI易于使用、提高模型性能和加速AI算法的DB4AI技术,包括声明性语言、数据治理、模型训练和推理(见第3节)
- 我们提供了研究挑战和未来方向,包括混合DB和AI数据模型、协同优化以及混合DB和AI系统(见第4节)
2 AI FOR DB
AI技术可用于从多个方面优化数据库,包括(1) learning-based database configuration, (2) learning-based database optimization, (3) learning-based database design, (4) learning-based database monitoring and protection, (5) learning-based security.本节从这些方面回顾了现有的研究。
2.1 Learning-based Database Configuration
基于学习的数据库配置旨在利用机器学习技术自动化数据库配置,例如旋钮调整、索引顾问和视图顾问。
2.1.1 Knob Tuning
数据库和大数据分析系统有数百个可调的系统旋钮(例如Work_Mem,Max_Connections,Active_Statements),它们控制着数据库的许多重要方面(例如,内存分配、I/O控制、日志记录)。传统的手动方法利用DBA根据他们的经验手动调整这些旋钮,但他们总是花太多时间调整旋钮(几天到几周),无法处理云数据库上的数百万个数据库实例。为了解决这个问题,建议使用自调整来自动调整这些旋钮,它使用ML技术不仅可以实现更高的调整性能,而且可以缩短调整时间(从而节省人力并实现在线调整)。我们可以将现有的旋钮调整技术分为四类,包括基于搜索的调整、基于传统ML的调整、基于深度学习的调整和基于强化学习的调整。
Search-based Tuning
为了减少人力,Zhu等人提出了一种递归绑定和搜索优化方法BestConfig,该方法在给定查询工作负载的情况下,从历史数据中找到类似的工作负载,并返回相应的旋钮值。具体来说,给定n个旋钮,BestConfig将每个旋钮的值范围划分为k个区间,这些旋钮区间形成一个具有k的n次幂的子空间(有界空间)的离散空间。然后,在每次迭代中,BestConfig从有界空间中随机选择k个样本,并从k个选择的样本中选择性能最好的样本,表示为C1。在下一次迭代中,它只从靠近C1的有界空间中获取样本。通过这种方式,BestConfig迭代地减少有界空间,最终得到一个好的旋钮组合。然而,这种基于搜索的方法有几个局限性。首先,它是启发式的,可能无法在有限的时间内找到最佳旋钮值。其次,它无法实现高性能,因为它需要搜索整个空间。
Traditional ML-based Tuning
为了解决基于搜索的调整方法中的问题,提出了传统的ML模型来自动调整旋钮(例如,Gaussian process - 高斯过程,decision tree - 决策树)。Aken等人提出了一种基于ML的数据库调优系统OtterTune。OtterTune使用高斯过程(GP)为不同的工作负载推荐合适的旋钮。首先,它选择一些查询模板,其中每个查询模板都包含一个查询工作负载及其相应的旋钮值。其次,它提取数据库的内部状态(例如,读/写的页数、查询缓存的利用率),以反映工作负载特征。从内部状态特征中,OtterTune使用因子分析过滤不相关的特征,然后使用简单的无监督学习方法(如K-means)选择与调整问题最相关的K个特征。OtterTune使用这些K特性来分析工作负载特征。第三,它使用这些选定的特性将当前工作负载映射到最相似的模板。OtterTune直接推荐此模板的旋钮配置为最佳配置。它还将查询工作负载输入到GP模型中,以学习用于更新模型的新配置。形式上,它对模型进行如下训练。给定训练数据(W,W ',C ',R),其中W是工作负载,W '是W的类似工作负载模板,C '是W '的建议配置,C ''是GP模型的推荐配置,R是C '和C ''之间的性能差异。它通过最小化C '和C ''之间的差异来训练模型。
OtterTune使用这些样本来训练模型。
这种基于ML的方法具有良好的泛化能力,可以在不同的数据库环境下运行。此外,它可以有效地利用从历史任务中学到的经验,并将这些经验应用到未来的推理和训练中。然而,它也有一些局限性。首先,它采用了流水线结构。当前阶段获得的最优解不能保证在下一阶段是最优的,不同阶段使用的模型可能无法很好地推广。其次,它需要大量高质量的样本进行训练,而这些样本很难获得。例如,数据库性能受到许多因素的影响(例如,磁盘容量、CPU状态、工作负载特性),由于搜索空间巨大,很难再现类似的场景。第三,它不能有效支持高维和连续空间的旋钮调谐。在使用GP之前,OtterTune仍然需要过滤掉大多数旋钮。例如,它在PostgreSQL上只调谐10个旋钮。
Reinforcement Learning for Tuning
强化学习(RL)通过与环境的连续交互(例如,数据库状态和工作负载),提高了泛化能力。Zhang等人提出了一种基于DRL的数据库调优系统CDBTune。在旋钮调节中使用DRL的主要挑战是设计DRL中的五个模块。CDBTune将数据库优化问题映射到强化学习框架中的五个模块中,如下所示。它以云数据库实例为环境(Environment),实例内部指标为状态(State),调优模型为代理(Agent),旋钮调优为动作(Action),调优后的性能变化为奖励(Reward)。Agent采用神经网络(Actor)作为调整策略,将状态State的度量作为输入,并输出旋钮值。此外,Agent还采用另一个神经网络(Critic)来调整参与者,该网络将旋钮值和内部度量作为输入,并输出奖励。在优化过程中,Agent输入数据库实例的状态state。Agent根据状态输出一个调整操作,并将其应用于数据库实例。然后,它在数据库上执行工作负载,获取性能更改,并将更改作为奖励来更新Agent中的Critic。接下来,Critic更新了Actor,它捕获了旋钮值和内部度量之间的关系。
与传统的监督学习不同,强化学习模型的训练不需要大量的高质量数据。通过试错过程,DRL模型中的学习者重复生成(st、rt、at、st+1),其中st是时间t的数据库状态,rt是时间t的奖励,at是时间t的动作,并使用该动作优化调整策略。通过探索和利用机制,强化学习可以在探索未被探索的空间和利用现有知识之间进行权衡。如果提供一个在线工作负载,CDBTune将运行该工作负载并从数据库中获取度量值。然后CDBTune使用Actor模型来推荐旋钮值。
然而,CDBTune仍有一些局限性。首先,CDBTune只能提供粗粒度调优,例如为工作负载调优旋钮,但不能提供细粒度调优,例如为某些特定查询调优旋钮。其次,以前基于DRL的调优工作直接使用现有模型(例如,Q-learning,DDPG);然而,Q-learning无法支持连续值的输入/输出,在DDPG中,Agent仅根据数据库状态调整数据库,而不考虑工作负载特性。因此,Li等人提出了一种查询感知调优系统QTune来解决上述问题。首先,QTune使用了一个双状态深度强化学习模型(DS-DRL),该模型可以嵌入工作负载特征,并考虑动作(对于内部状态)和工作负载(对于外部度量)的影响。因此,它可以提供更细粒度的调优,并且即使工作负载发生变化,也可以支持在线调优。其次,QTune根据查询的“最佳”旋钮值对查询进行聚类,并支持集群级调整,这将为同一集群中的查询推荐相同的旋钮值,并为不同集群中的查询推荐不同的旋钮值。
总之,与传统方法相比,基于DRL的方法可以大大提高调谐性能。首先,DRL不需要大量的训练数据来训练模型,因为它可以通过在不同的数据库状态下运行工作负载来生成训练样本。
其次,它结合了先进的学习方法(如马尔可夫决策过程、Bellman函数和梯度下降),能够有效地适应数据库的变化。
Deep Learning for Buffer Size Tuning
上述方法侧重于调整通用旋钮。还有一些方法可以调整特定旋钮以优化数据库性能。Tan等人提出了IBMTune,它只调整单个数据库实例的缓冲池大小。它使用深度学习来决定调整数据库的时间,以确保对查询延迟和吞吐量的负面影响最小。首先,它从历史记录中收集数据库状态度量(例如,未命中率)、调优操作和性能的样本。
其次,它使用这些样本训练成对神经网络来预测延迟的上限。网络的输入包括两部分:当前数据库实例和目标数据库实例(调整缓冲池大小后),每个部分都包括性能指标(例如CPU使用率、读取I/O)和当前时间的编码(例如21:59)。网络的输出是预测的响应时间。如果预测的时间太长,iBTune将调整内存大小。iBTune实现了调优性能和调优频率之间的平衡。Kunjir等人提出了一种用于内存分配的多级调优方法RelM。与iBTune不同,RelM首次使用引导贝叶斯优化,根据应用程序类型(例如SQL、shuffling)计算性能度量值(例如shuffle内存使用)。RelM使用这些指标来选择旋钮,并使用DDPG来调整这些选择的旋钮。
ML-based Tuning for Other Systems
除了数据库调优之外,还有许多其他数据系统的调优方法,如Hadoop和Spark。大数据系统也有许多旋钮(例如Hadoop中>190,Spark中>200),这可能会对性能产生重大影响。然而,大数据系统的调优与数据库调优不同。(1) Spark等大数据系统的工作负载更加多样化(例如,MLlib上的机器学习任务、Spark流媒体上的实时分析、GraphX上的图形处理任务),它们需要针对不同的任务和环境调整系统。(2) 现有的数据库优化方法主要在单节点上,而大多数大数据系统采用分布式架构。(3) 性能指标各不相同–大数据系统关注资源消耗和负载平衡,而数据库优化则优化吞吐量和延迟。
Herodotou等人[50]提出了一种用于Hadoop的自调整系统Starfish。对于作业级调整,Starfish在运行作业时捕获在线功能(例如,作业、数据和集群特征),并根据估计的资源消耗(例如,时间、CPU、内存)调整参数。对于工作流级别的调整,可以将工作流分发到不同的集群节点。因此,Starfish学习基于本地特性和分布式系统特性跨节点调度数据的策略。对于工作负载级别的调整,Starfish主要根据这些工作流的访问模式和网络配置来调整系统参数,如节点编号、节点配置。为了调整这些参数,它模拟实际的工作场景,并根据数据库优化器预测的执行成本估计调整后的数据库性能。
对于Spark调优,Gu等人提出了一种基于机器学习的模型来调优运行在Spark上的应用程序的配置。首先,它使用N个神经网络,每个神经网络以参数的默认值作为输入,并输出推荐的参数组合。其次,它使用随机森林模型来估计N个推荐组合的性能,并选择最佳组合来实际调整配置。这种方法对于分布式集群非常有用,在分布式集群中,可以根据每个节点的状态调整每个网络。

2.1.2 Index Selection
在DBMS中,索引对于加快查询执行速度至关重要,选择合适的索引对实现高性能非常重要。我们首先定义了索引选择问题。考虑一组表,让C表示这些表中的列集和 size(c ∈ C) 表示列 c 的索引大小 c ∈ C。给定一个查询工作负载Q,让 benefit(q ∈ Q、 c ∈ C) 表示在 c 列上为查询 q 构建索引的好处,即在 c 列上有索引和没有索引的情况下执行查询 q 的好处。给定空间预算 B,索引选择问题旨在找到列的子集 C’ 来构建索引,以便在将总索引大小保持在B以内的同时最大化收益,即
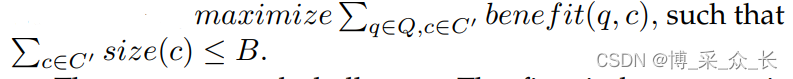
有几个挑战。第一个是如何估计benefit(q,c),一个众所周知的方法是使用假设指数,它将索引信息添加到DBMS的数据字典中,而不是创建实际的索引,因此DBMS中的查询优化器可以识别索引的存在并估计查询执行的成本,而无需构建实际的索引。索引的估计好处是减少了使用和不使用假设索引执行查询的估计成本。二是解决上述优化问题。有两种主要的解决方案来应对这些挑战,离线索引选择和在线索引选择。离线索引选择方法要求DBA提供一个具有代表性的工作负载,并通过分析该工作负载来选择索引方案。在线索引选择方法监控数据库管理系统,并根据工作负载的变化选择索引方案。离线方法和在线方法的主要区别在于,离线方法只选择和具体化一个索引计划,而在线方法根据工作负载的变化动态创建或删除一些索引。
Offline Index Selection
它依赖于DBA从查询日志中选择一些频繁的查询作为代表性工作负载,并使用该工作负载选择索引。Chaudhuri等人提出了一种针对Microsoft SQL server的索引选择工具AutoAdmin。其主要思想是为每个查询选择性能良好的索引方案,然后扩展到Q中的多个查询。首先,对于每个查询qi∈ Q、 AutoAdmin从SQL查询中提取可索引列。其次,AutoAdmin使用简单的枚举算法枚举可索引列的集合作为候选列,例如,I={{i1、i2、i3、i4}、{i3、i4、i5、i6}、…}。然后,AutoAdmin选择I中的索引方案,该方案对该查询具有最大的好处。第三,对于每个查询,它都有一个相应的最优索引策略,然后对于Q中的所有查询,AutoAdmin根据好处选择top-k方案。然后,对于每个top-k方案,AutoAdmin使用贪婪算法递增添加可索引列,直到大小等于阈值B。最后,将选择效益最高且在存储预算范围内的方案。Zilio等人将索引选择问题建模为背包问题,并提出了DB2 Advisor。与AutoAdmin类似,DB2 Advisor首先列举索引方案及其优点。然后,将索引选择问题建模为背包问题。更具体地说,它涉及每一个候选模式索引为项目,以模式的大小为项目权重,以模式的效益为值。然后DB2使用动态编程来解决这个问题。
脱机方法的缺点是它们不够灵活,无法处理工作负载的动态变化。更糟糕的是,选择具有代表性的工作负载将增加DBA的负担。为了解决这些问题,以下提出了一些在线方法。
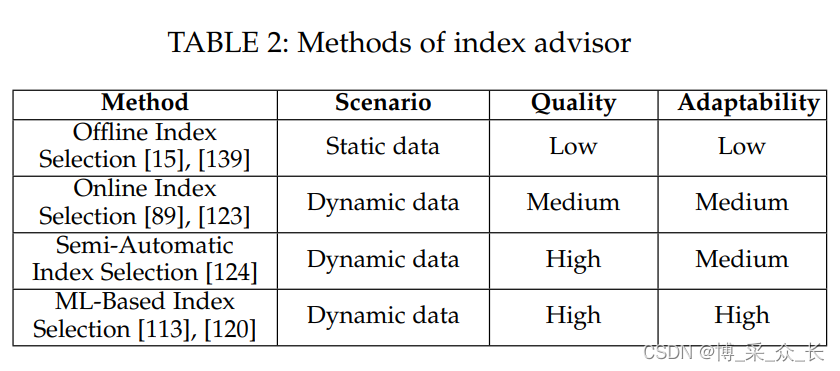
Online Index Selection
在线索引选择方法很多,可分为三类:传统在线索引选择方法、半自动索引选择方法和基于ML的索引选择方法。传统的在线索引选择方法不断分析工作负载,并根据工作负载的变化动态更新索引方案。Luhring等人提出了一种基于“观察 - 预测 - 反应”的软指标自主管理方法。首先,它从查询中提取可索引列并枚举候选索引方案。然后,它使用贪心策略选择具有最高估计收益的方案,并将其添加到最终结果中。最后,当DBMS的工作负载不重时,所选择的索引方案就会具体化。Schnaitte等人提出了COLT,它支持基于当前索引方案自动在线实施新索引。它将索引选择问题建模为背包问题,如我们在脱机索引选择(DB2)中所述,并应用动态规划来获得索引方案。一旦导出最终索引方案,它将立即匹配。然而,传统的在线方法没有考虑DBA的经验。此外,索引方案的持续更改可能会影响DBMS的稳定性,并导致高开销。
Schnaitter提出了一种半自动索引选择算法WFIT。WFIT还可以在线工作,并考虑DBA的反馈。它实时监控DBMS,动态分析工作负载,并列举一些候选方案来优化索引结构。但在实现索引方案之前,WFIT需要DBA来判断列是否应该被索引。然后在随后的索引选择过程中,WFIT将根据DBA的经验从索引方案中删除不应索引的列。类似地,它还可以将应该索引的列添加到索引方案中。与传统方法相比,WFIT不需要选择具有代表性的工作负载,从而减少了DBA的负担。虽然半自动索引选择方法考虑了DBA的经验,但这些经验可能没有用处。基于ML的索引选择方法可以自动学习一些经验,而不是DBA的反馈,并应用这些经验来验证索引是否有用。
基于ML的索引选择方法自动从历史数据中学习经验,而不是从DBA的反馈中学习经验。Pedrozo等人提出了一种基于学习分类器系统(LCS)和遗传算法的索引选择方法ITLCS。首先,ITLCS使用LCS在列级别生成索引规则。每个规则由两部分组成:(i)来自DBA的索引相关信息,例如,“列中空元组的百分比”,“列的数据类型”;(ii)操作表示是否创建或删除索引。其次,ITLCS使用遗传算法消除LCS规则,并生成合成规则作为最终索引策略。然而,很难生成规则。Sadri等人提出了一种基于强化学习的索引选择方法。首先,在没有专家规则的情况下,它们将工作负载特征表示为查询的到达率,列特征表示为每列的访问频率和选择性。其次,他们使用马尔可夫决策过程模型(MDP)学习查询、列的特征,并输出一组表示创建/删除索引的操作。
2.1.3 View Advisor
在基于时空权衡原则利用视图提高查询性能的数据库管理系统中,视图物化非常重要。明智地选择物化视图可以在可接受的开销内显著提高查询性能。然而,很难为普通用户自动生成物化视图。现有方法依赖DBA生成和维护物化视图。不幸的是,即使是DBA也无法处理大型数据库,尤其是拥有数百万数据库实例并支持数百万用户的云数据库。因此,它需要视图顾问,它会自动为给定的查询工作负载识别适当的视图。
视图顾问已经研究了多年,Oracle DB和IBM DB2等现代DBMS提供了支持物化视图的工具。视图顾问中有两个主要任务:(1)候选视图生成。视图顾问应该从历史工作负载中发现候选视图。(2)视图选择。由于系统资源的限制,无法具体化所有候选视图,因此视图顾问会选择一个子集候选视图作为具体化视图,以最大程度地提高性能。
Candidate View Generation
由于所有可能视图的数量呈指数级增长,因此视图生成的目标是生成一组高质量的候选视图,用于将来的查询。主要有两种方法。
- 确定经常出现在工作负载中的等效子查询。Dokeroglu等人提出了一种启发式方法,该方法包括分枝定界、遗传算法、爬山算法和混合遗传爬山算法,以找到一个接近最优的多查询执行计划,其中查询共享共同的计算任务。它们将查询分解为包含选择、投影、连接、排序和数据传送的子查询。接下来,为了使这些子查询有更多机会共享公共任务,它们为每个查询生成替代查询计划。他们的计划生成器与一个成本模型交互,该模型通过考虑其子查询的潜在重用能力来估计查询成本。然后,他们在这些备选计划中检测常见任务,并搜索成本较低的全局计划,其中查询共享常见任务
- 重写子查询以使视图回答更多查询。直接从查询中提取的子查询仍然不够通用,因为即使有微小的差异,它们也无法推广到其他查询。为了缓解这个问题,Zilio等人通过合并相似的视图、更改选择条件、添加“group by”子句来概括提取的视图。这减少了资源消耗,更多的查询可以利用这些视图。
View Selection
由于系统资源限制,候选视图无法全部物化。因此,视图顾问应该选择能够带来良好性能的视图子集来动态地具体化和维护它们。视图选择问题旨在选择候选视图的子集作为物化视图。假设有一个工作负载和一些候选视图,表示为(Q,V),其中Q={q}是工作负载中的查询集,V={v}是候选视图集。V’ 是选定要具体化的视图的子集。C(q,V’)是在存在一组物化视图V’的情况下回答q的代价。 M(v)是物化视图v的维护成本。| v |是视图v将在磁盘空间中占据的大小。τ是磁盘空间约束,因此选定视图的总大小不能超过。视图选择问题的目标是选择要具体化的视图子集,以最小化响应工作负载的成本,同时不超过磁盘空间限制。
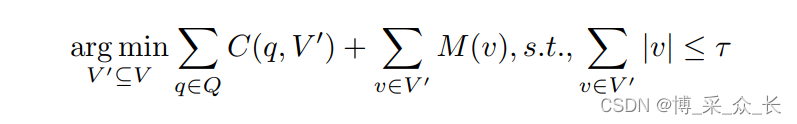
我们需要估计视图的效益和成本,由于复杂的系统环境约束和视图之间的交互,视图选择问题是NP难问题。由于这是一个NP难问题,有许多启发式方法可以获得近似最优解。Jindal等人将视图选择问题作为一个整数线性规划(ILP)问题进行求解,并使用另一种方程形式。1、目标是通过选择视图的子集V’来最小化回答工作负载的成本,以具体化。此外,他们还研究了给定每个查询q的问题,该问题具体化了视图V’ q ⊆ V’ 应选择V’来回答查询。但解决这个ILP问题非常耗时,因此他们将其分解为多个较小的ILP问题,并提出了一种近似算法BIGSUBS。该算法使用迭代方法,每次迭代有两个步骤。在每次迭代中,第一步是通过概率方法确定是否应在当前解决方案中具体化视图,这类似于遗传算法中的变异操作。概率的计算基于:(1)视图占用了多少磁盘空间,以及(2)视图的实用性,这是使用此视图时查询成本的估计减少量。在临时确定视图选择状态后,第二步是通过ILP解算器解决剩余的较小ILP问题。在第二步中,给定每个查询,算法将决定使用哪个视图来回答查询,并估计每个选定视图的效用。然后,该实用程序将反馈给下一次迭代,以选择候选视图,直到选定的视图及其相应的查询没有变化,或者迭代次数达到阈值。解决较小的ILP问题的时间复杂度更容易接受,且解决方案接近最优。
但是,上述方法是一种离线方法,需要花费数小时来分析工作负载。为了支持在线工作负载,他们提出了一个在线计算重用框架CLOUDVIEWS。工作流程类似(Jindal等人将视图选择问题作为一个整数线性规划(ILP)问题进行求解,并使用另一种方程形式)。它还首先生成候选视图,然后给出一个查询,研究如何为查询选择合适的视图。CLOUDVIEWS将查询计划图分解为多个子图,并选择高频子图作为候选视图。然后,它通过收集和分析以前执行的工作负载中的信息,如编译时和运行时统计信息,在线估计候选视图的效用和成本。给定候选视图及其估计的效用和成本,它们将视图选择问题转化为背包问题,其中效用被视为视图的值,成本被视为视图的权重,磁盘空间约束被视为容量。为了提高视图选择问题的效率,他们还提出了一些启发式算法。假设ui是vi和| vi |的实用程序是vi的成本。他们选择得分最高的k个视图。分数可以是ui或ui/|vi|。 然而,缺点是它们关注重复性工作负载,这意味着它无法快速适应具有不同查询模式和分布的新工作负载。
为了解决这些限制,Yuan等人建议使用强化学习(RL)来解决视图选择和维护问题。首先,他们使用wide-deep model来估计使用物化视图回答查询的好处。其次,他们将视图选择建模为整数线性规划(ILP)问题,并使用强化学习来寻找最佳策略。
当准备创建新的物化视图但磁盘预算不足时,可能需要逐出一些物化视图。对于视图逐出,提出了一种基于信用的模型,该模型在达到存储限制时逐出具有最低信用的物化视图。视图的信用是其未来效用和创建的总和。更高的信用意味着,如果我们逐出视图,我们将牺牲更多的效用,但如果我们保留视图,成本会更高。它类似于DQM中的奖励函数,可以用类似的方式计算。然而,因为他们使用工作负载的实际运行时来训练RL模型,所以假设数据库环境不会改变。这导致冷启动步骤中模型培训的成本高昂。

2.1.4 SQL Rewrite
许多数据库用户,尤其是云用户,可能无法编写高质量的SQL查询,SQL重写器旨在将SQL查询转换为等效形式(例如,pushing down the filters,将嵌套查询转换为联接查询),这些查询可以在数据库中高效执行。大多数现有的SQL重写方法都采用基于规则的技术,这些技术在给定一组查询重写规则的情况下,找到可以应用于查询的规则,并使用该规则重写查询。然而,评估各种重写操作组合的成本很高,传统方法往往无法进行次优化。此外,重写规则与应用程序高度相关,很难有效识别新场景中的规则。因此,可以使用机器学习从两个方面优化SQL重写。(1) 规则选择:由于有许多重写规则,因此可以使用强化模型来做出重写决策。在每个步骤中,代理都会估计不同重写方法的执行成本,并选择成本最低的方法。该模型迭代生成重写解决方案,并根据结果更新其决策策略。(2) 规则生成:根据不同场景的重写规则集,使用LSTM模型学习查询、编译器、硬件功能和相应规则之间的相关性。然后,对于一个新场景,LSTM模型捕获门单元内的特征并预测适当的重写规则。
2.2 Learning-based Database Optimization
基于学习的数据库优化旨在利用机器学习技术解决数据库优化中的难题,如成本/基数估计、连接顺序选择和端到端优化器。
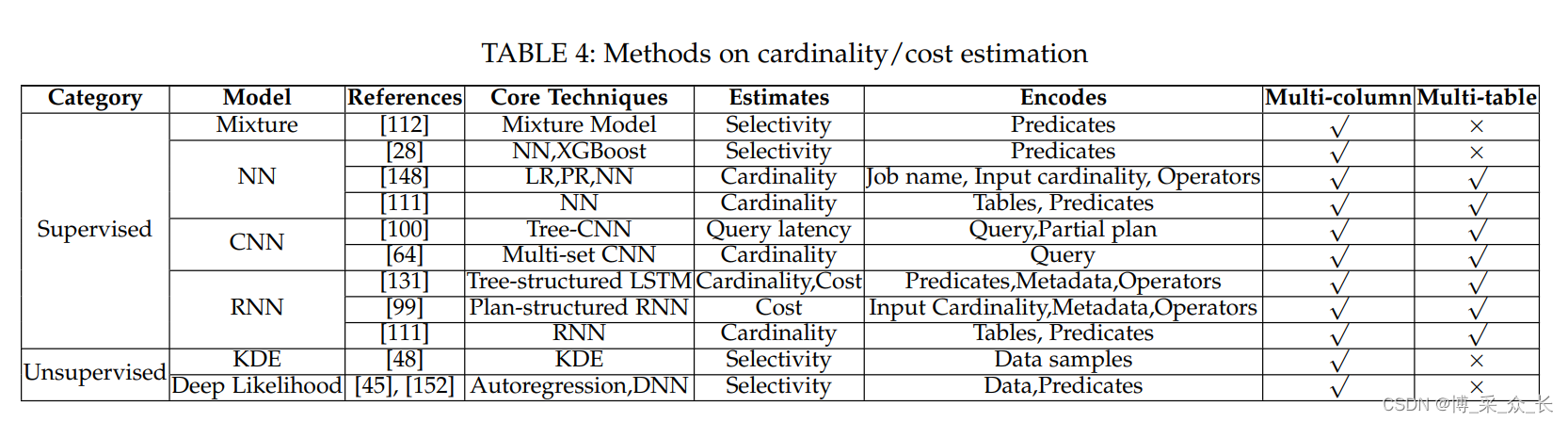
2.2.1 Cardinality and Cost Estimation
基数估计是数据库中最具挑战性的问题之一,它通常被称为现代查询优化器的“致命弱点”,已经研究了几十年。传统的基数估计方法可分为三类,即数据草图法、直方图法、和抽样法。然而,它们有以下缺点。首先,数据草图和基于直方图的方法只能处理一列的数据分布,而对于多列表甚至多表联接,由于列的相关性,它们会产生较大的错误。其次,虽然基于采样的方法可以通过索引捕获多列和多表的相关性,但由于0元组问题,它们不能很好地用于稀疏或复杂的查询。
成本估算预测查询物理执行计划的资源使用情况,包括I/O使用情况和CPU使用情况。传统的成本估算方法利用建立在估算基数基础上的成本模型来对物理操作员进行整合。与估计基数相比,估计成本为指导计划选择提供了更多的直接运行开销。
最近,数据库研究人员提议使用深度学习技术来估计基数和成本。基于学习的基数估计可分为有监督方法和无监督方法。
Supervised Methods
根据所采用的模型,我们可以进一步将监督方法分为以下几类。
- Mixture Model
Park等人提出了一种基于查询的混合模型方法。该方法通过最小化模型与观测分布之间的差异,使用混合模型来拟合观测谓词及其选择性。它可以避免多维直方图的开销。但是,这些方法不支持LIKE、EXISTS和ANY关键字 - Fully Connected Neural Network
Ortiz等人使用全连接的神经网络建立基数估计模型,并将编码查询作为输入特征。他们进行实验来测试模型大小和估计误差之间的权衡。Dutt等人提出了一种基于多维数值范围预测的回归模型,用于选择性估计。回归模型可以在较小的空间和时间内给出估计的选择性,并且可以学习多列的相关性,这优于属性值独立假设的方法。然而,这种方法很难捕获连接相关性。Wu等人提出了一种基于学习的共享云工作负载方法CardLearner,该方法从工作负载中提取重叠子查询,并根据结构对其进行分类。每类子查询都是一个模板,CardLearner为每个模板训练基数估计模型。这样,CardLearner就可以用共享模板取代子查询的传统基数估计。然而,这种方法的有效性受到工作量的限制。 - Convolutional Neural Network (CNN)
Kipf等人提出了一种多集CNN来学习连接的基数。该模型将查询分为三部分:选定表、连接条件和筛选谓词。每个部分由一个卷积网络表示,并在平均池化后连接。这是第一种以端到端的方式表示整个查询并学习基数的方法,它可以以较低的计算开销给出准确的基数。然而,这种方法很难直接用于基于计划的查询优化场景,因为父节点不能在查询计划中使用子节点的表示。Marcus等人提出了一种名为Neo的端到端查询优化器。作为强化学习模型的重要组成部分,他们提出了一种同时包含查询编码和部分计划编码的神经网络,以评估当前查询的最佳性能。对于计划编码,他们使用CNN逐层聚合连接。对于谓词编码,它们利用word2vec模型训练的行向量,并利用所选行的平均值对每个谓词进行编码。然而,行向量表示对于在线编码来说非常耗时。 - Recurrent Neural Network
Ortiz等人提出了一种基于RNN的模型来估计左深平面的基数。在每次迭代中,一个节点将添加到计划树中,节点序列是RNN模型的输入。Marcus等人提出了一种基于RNN的成本模型,该模型基于传统RDBMS中的估计基数和其他统计参数。该模型将查询计划编码为树结构的深层神经网络。然而,它不编码谓词,依赖于RDBMS估计的基数,不准确的估计基数会给成本估计带来很大误差。Sun等人提出了一种基于树结构LSTM的端到端学习成本估计器。它使用物理运算符和谓词学习每个子计划的表示,并使用另一个估计层同时输出估计基数和成本。此外,该方法还通过单词嵌入对谓词中的关键字进行编码。
Unsupervised Methods
也有研究使用无监督密度模型拟合数据集的底层分布,但它们很难支持像多重连接这样的复杂查询。Heimel等人提出了一种基于核心密度估计器(KDE)的选择性估计器,这种估计器可以轻量级地构造和维护数据库的变化,并通过选择最佳带宽参数对核心密度估计器模型进行数值优化,以获得更好的估计质量。KDE能够快速适应下划线数据分布,易于构建和维护,并且对数据相关性具有鲁棒性。Hasan等人和Yang等人利用自回归密度模型来表示列之间的联合数据分布。该模型返回一个包含输入元组的链规则中存在的条件密度列表。为了支持范围谓词,该模型通过利用学习的密度模型,采用渐进抽样来选择有意义的样本,甚至可以处理倾斜的数据。但是,它不能支持高维数据或多表联接。
上述方法已经取得了很大的改进,但它们只支持简单/固定的查询,并且具有不同关键字的查询可能会在查询规划器中使用不同的技术(例如,集合论基数)。因此,Hayek等人使用了两种方法来处理一般查询。首先,他们使用深度学习方案预测查询结果中的唯一率R。使用重复行,其中查询表示为(属性、表、联接、谓词)的集合。其次,他们通过将唯一率乘以重复结果来扩展现有的基数方法。
2.2.2 Join Order Selection
连接顺序选择在已经研究多年的数据库系统中起着非常重要的作用。传统方法通常基于基数估计和成本模型,通过一些修剪技术搜索所有可能连接顺序的解空间。例如,基于动态规划(DP)的算法通常选择最佳方案,但计算开销较高。此外,由于错误的成本估算,DP算法生成的计划可能具有较大的成本。启发式方法GEQO、QuickPick-1000和GOO可能会更快地生成计划,但可能不会生成好的计划。
为了解决这些问题,近年来提出了基于机器学习的方法来提高连接顺序选择的性能,该方法利用机器学习从以前的示例中学习,并克服了由于估计不准确而导致的偏差。此外,基于学习的方法可以在较短的时间内有效地选择更好的计划。我们可以将现有的方法分为离线学习方法和在线学习方法。
Offline-Learning Methods
一些研究从之前的查询中学习,以提高未来查询的性能。Stillger等人提出了一种学习优化器LEO,它利用查询执行的反馈来改进查询优化器的成本模型。它使用两层方法来指导计划搜索。一层表示来自数据库的统计信息,另一层是从过去的执行中分析的系统目录。当查询到来时,LEO使用统计和系统目录的组合来估计基数和成本,并生成一个计划。执行查询后,LEO将与准确的成本进行比较,并估计此查询计划的成本,然后更新系统目录。
受LEO基于反馈的方法的启发,DQ和ReJoin建议使用神经网络和强化学习来优化连接顺序。DQ和ReJoin都使用先前计划的成本作为训练数据来训练神经网络,以便评估每个连接顺序。DQ使用一个热向量G来表示每个连接状态。向量中的每个单元格表示联接树中每个表的存在和操作选择。然后使用以G为输入的多层感知器(MLP)测量每个连接状态,并使用DQN指导连接顺序的选择。一旦生成计划,计划的成本将被视为训练神经网络的反馈。与DQ不同,ReJoin的输入由深度向量和查询向量组成。深度向量表示联接树中每个表的深度信息,查询向量表示查询信息。ReJoin使用近端策略优化(PPO)来指导连接顺序的选择。结果表明,与PostgreSQL优化器相比,DQ和ReJoin都能生成良好的连接顺序,且成本低,效率高。然而,ReJoin和DQ中的神经网络结构简单,不能充分表示连接树的结构,也不能学习查询计划的延迟。
此外,上述两种方法不能支持模式的更新。为了解决这个问题,RTOS使用两阶段训练,通过精心设计的神经网络结构,在延迟上生成更好的连接顺序。为了解决ReJoin和DQ中DNN设计无法捕捉连接树结构的问题,RTOS提出了一种利用TreeLSTM表示连接状态的模型。RTOS首先设计列、表和连接树的表示。然后,在获得表示后,使用DQN指导连接顺序的生成。接下来,RTOS首先使用cost对DNN进行预训练,然后利用延迟信息在线训练神经网络。结果表明,该算法可以在低延迟的情况下生成更好的连接顺序。
Online-learning Methods
这类方法侧重于使用自适应查询处理来学习连接顺序,即使在执行查询的过程中也可以更改连接顺序。Avnur等人提出了一种称为Eddy的自适应查询处理机制,它将查询的执行和优化结合在一起。它在联机执行查询期间学习并生成连接顺序。Eddy将查询过程拆分为多个操作符,例如,三个关系之间的两个连接操作符。Eddy使用两种路由方法来控制这些操作符处理即将到来的元组的顺序:Naive Eddy和Lotty Eddy。Naive Eddy可以以较少的代价将更多的元组路由到操作符;而Lotty Eddy可以以较小的选择性将更多的元组路由到算子。然而,这两种路由方法是针对特定场景设计的,需要设计通用的路由算法来处理更复杂的场景。
Tzoumas等人将查询执行与Eddy建模为强化学习问题(Eddy-RL),并从查询执行中自动学习路由方法,无需任何人工设计。Eddy将Eddy本身定义为 agent,元组的进度定义为 state,查询中的操作符定义为 actions,执行时间定义为 reward(成本)。决定操作符顺序的路由方法正是这个RL问题所要解决的。Eddy-RL使用Q-learning来解决这个RL问题。它将Q函数定义为所有操作符成本的总和。通过最小化Q函数,它指导每次选择哪个操作符。但是,上面的样式优化器不会分析预期执行时间之间的关系,并且优化不会丢弃中间结果。
Trummer等人提出了一种基于Eddy-RL的强化学习模型SkinnerDB。SkinnerDB使用树的置信上界(UCT),而不是Eddy-RL中的Q-learning,因为UCT为所有选择的累积后悔提供了理论保证。SkinnerDB将查询执行划分为许多小时间段,并在每个时间段中选择一个连接顺序来执行。Skinner-DB使用时间片中连接顺序的实际性能训练UCT,以指导更好的连接顺序选择。最后,Skinner-DB合并每个时间片中生成的元组以生成最终结果。
2.2.3 Learning-based Optimizer
虽然许多研究人员尝试使用机器学习方法来解决成本/基数估计和连接顺序选择问题,但在物理计划优化中仍有许多因素需要考虑,例如索引和视图选择。连接顺序选择方法提供逻辑计划,依靠数据库优化器选择物理操作符和索引,并利用成本模型生成最终的物理计划。最近,Marcus等人提出了一种端到端优化程序NEO,它不使用任何成本模型和基数估计来生成最终的物理计划。NEO也是一种基于ReJoin的离线学习方法。与RTOS类似,NEO也使用树CNN捕捉结构信息。它使用行向量来表示谓词。为了生成物理计划,NEO使用一个热向量来表示神经网络中的每个物理操作符选择和索引选择。然后,NEO执行DNN引导的搜索,不断以最小值扩展状态以找到物理计划。此外,在没有来自成本模型的任何信息的情况下,NEO使用PostgreSQL的计划来预训练神经网络,并使用延迟作为反馈来训练神经网络。这种端到端方法从延迟中学习以生成整个物理计划,该计划可以应用于任何环境,并且对估计错误具有鲁棒性。
2.3 Learning-based Design
基于学习的设计旨在利用机器学习技术设计数据库组件,例如索引。
2.3.1 Learned Data Structure
数据库社区和机器学习社区研究基于学习的结构,例如学习的B树,使用基于学习的模型替换传统索引,以减少索引大小并提高性能。
Learned B+tree
Kraska等人提出indexes are models,其中B+树索引可以看作是将每个查询键映射到其页面的模型。对于排序数组,位置id越大意味着键值越大,范围索引应该有效地近似于累积分布函数(CDF)。基于这一观察结果,Kraska等人提出了一种递归模型索引,该索引使用学习模型来估计密钥的页面id。在内存环境下,该方法的性能优于B+树。然而,它不支持数据更新,也不显示二级索引的有效性。
Galakatos中提出的另一个学习索引,Fitting-tree,提供了严格的错误界限和可预测的性能,并且支持两种数据插入策略。对于就地插入策略,Fitting-tree保持在页面的每一端都有额外的插入空间,以便在不违反页面错误的情况下进行就地插入。然而,对于大型段,插入成本可能很高。增量插入策略在每个段中保持一个固定大小的缓冲区,密钥将插入缓冲区并保持排序。一旦缓冲区溢出,它就必须拆分和合并段。与Fitting-tree类似,Alex-index还为插入的键保留空间。不同的是,Alex-index中的保留空间是分散的,插入的密钥将直接放入模型预测的位置。如果该位置被占用,则会插入更多间隙(对于有间隙的阵列)或扩展自身(对于压缩内存阵列)。Alex-index可以更灵活地平衡空间和效率之间的权衡。
Tang等人提出了一个称为Doraemon的工作负荷感知学习指数。Doraemon可以通过在训练数据中复制多次频繁访问的查询来合并读访问模式,频繁查询会对错误做出更大的贡献,并且比其他查询更容易优化。Doraemon根据相似的数据分布需要相同的模型结构的观察结果,对相似的数据分布重用预先训练的模型。
Learned Secondary Index
Wu等人提出了一种称为Hermit的简洁二级索引机制,该机制利用分层回归搜索树(TRS树)来捕获列相关性和异常值。TRS树是一种机器学习增强型树索引。每个叶节点包含一个学习的线性回归模型,该模型将目标值映射到相关值。每个内部节点维护指向子节点的固定数量的指针。Hermit使用三个步骤回答查询,首先搜索TRS树以将目标列映射到现有索引,利用现有索引获取候选元组,最后验证元组。Hermit在内存和基于磁盘的RDBMS中都很有效。
Learned Hashmap
Kraska等人建议将密钥的CDF近似为哈希函数,以便在每个哈希桶中均匀分布所有密钥,并减少冲突。
Learned Bloom Filters
Bloom过滤器是一种常用的索引,用于确定给定集合中是否存在值。但是传统的bloom过滤器可能会占用大量内存用于位数组和哈希函数。为了减小布卢姆过滤器的尺寸,Kraska等人提出了一种基于学习的布卢姆过滤器。他们训练一个二进制分类器模型来识别数据集中是否存在查询。新的查询需要首先通过分类器,否定的查询需要进一步通过传统的Bloom过滤器,以保证不存在误报。Mitzenmacher等人提出了一种形式化的数学方法,以指导如何改进学习过的Bloom过滤器的性能。他们提出了一种包含三层的三明治结构。第一层是传统的Bloom过滤器,旨在删除数据集中不存在的大多数查询,第二层是神经网络,旨在删除误报,最后一层是另一个传统的Bloom过滤器,旨在确保没有误报。他们提供了数学和直观的分析,以证明夹层结构优于双层布卢姆过滤器。
此外,他们还设计了Bloom过滤器,该过滤器不仅可以确定键的存在,还可以返回与数据集中的键相关的值。然而,从头开始训练Bloom过滤器对于具有高吞吐量的短暂输入流来说并不实用,这激发了Rae等人的工作,他们提出了一种具有少量快照神经数据结构的学习Bloom过滤器,以支持数据更新。
对于多维数据集,逐个搜索一组单个Bloom过滤器会耗费大量空间和时间。Macke等人提出了一种利用三明治结构对多维数据进行有效学习的Bloom过滤器。对于属性嵌入,它们通过字符级RNN表示高基数属性中的值,以减小模型大小。此外,他们选择最佳分类器截止阈值,以最大化真阳性率和假阳性率之间的KL差异。为了减少索引数据中噪声的影响,他们为每个正训练样本引入了一个移位参数。
Learned Index for Spatial Data
传统的空间索引,如R-tree、kd-tree、g-tree,无法捕捉底层数据的分布,基于学习的技术可以进一步优化查找时间和空间开销。例如,Wang等人提出了一种学习的ZM索引,该索引首先将多维地理空间点映射为具有Z-ordering的一维向量,然后构建神经网络索引以拟合分布并预测查询位置。
Learned Index for High-dimensional Data
高维数据的最近邻搜索(NNS)问题旨在高效地找到查询的k个最近点。解决近似NNS问题的传统方法可分为三类,包括基于哈希的索引、基于分区的索引和基于图的索引。一些研究使用机器学习技术改进了前两类指标。Schlemper等人提出了一种端到端的深度哈希方法,该方法使用有监督的卷积神经网络。它结合了两种损失——相似性损失和比特率损失,因此可以对数据进行离散化,同时最小化冲突概率。Sablayrolles等人提出了一种类似的端到端深度学习架构,该架构学习Catalyster函数,以提高后续编码阶段的质量。他们引入了从Kozachenko Leonenko差分熵估计器导出的损失,以支持球形输出空间中的一致性。Dong等人少了高维空间划分问题,以平衡图划分和监督分类问题。他们首先使用图划分算法KaHIP将KNN图划分为平衡的小分区,然后学习神经模型预测查询的KKN落在分区中的概率,并搜索概率较大的分区。
Learned KV-store Design
Idreos等人表明,键值对存储的数据结构可以从基本组件构建,学习到的成本模型可以指导构建方向。它们将design space定义为可以由基本设计组件(如围栏指针、链接和时域划分)描述的所有设计,而design continuums是连接多个设计的design space的子空间。为了设计数据结构,他们首先确定总成本的瓶颈以及可以调整哪个旋钮来缓解它,然后朝一个方向调整旋钮,直到达到其边界或总成本达到最小。此过程类似于梯度下降,可以自动执行。
2.3.2 Learned Transaction Management
随着CPU内核数量的增加,繁重工作负载的并发控制变得更具挑战性。有效的工作负载调度可以避免冲突,从而大大提高性能。我们从事务预测和事务调度两个方面介绍了所学的事务管理技术。
Transaction Prediction
事务预测对于数据库优化(例如,资源控制、事务调度)非常重要。传统的工作量预测方法是基于规则的。例如,基于规则的方法使用数据库引擎的领域知识(例如,内部延迟、资源利用率)来识别与工作负载特性(例如内存利用率)相关的信号t。该方法直接使用内存利用率来预测未来的工作负载趋势。然而,当工作负载发生变化时,基于规则的方法会浪费大量时间来重建统计模型,因此Ma等人提出了一个基于ML的系统QB5000,该系统可以预测不同工作负载的未来趋势。QB5000主要包含三个组件,前置处理器、集群和预报器。首先,Pre-Processor记录传入的查询特征(例如语法树、到达率),并使用相同的模板聚合查询,以近似工作负载特征。其次,Cluster使用改进的DBSCAN算法对到达率相似的模板进行聚类。第三,Forecaster预测每个集群中查询的到达率模式。QB5000尝试了六种不同的预测模型,其中训练数据是来自过去观察的历史工作量。
Transaction Scheduling
传统的数据库系统要么按顺序安排工作负载(不能考虑潜在的冲突),要么根据数据库优化器预测的执行成本安排工作负载。但传统的数据库优化器基于一致性和独立性等假设来估计成本,当连接属性之间存在相关性时,这可能是错误的。因此,Sheng等人提出了一种基于机器学习的事务调度方法,该方法可以平衡并发性和冲突率。首先,他们使用监督算法估计冲突概率:他们构建一个分类器M来识别任何成对事务(Ti,Tj)是否将被中止,其中Ti是事务查询的向量表示。通过观察提交或中止事务时收集信息的系统日志来收集训练数据,每个样本是一个抽象的三元组,如(中止事务的特征:f(Ti),冲突事务的特征:f(Tj),标签:abort),其中f(T)是事务T的向量表示,它们在可接受的中止率下以最大吞吐量将事务分配到执行队列中。假设(T*i、 T*j)具有最高的中止概率,他们放置T∗i在进入队列∗j之后,因此它们从不同时执行。
2.4 Database Monitoring
数据库监控记录系统的运行状态并检查工作负载,以确保数据库的稳定性,这对于数据库优化和诊断非常重要。例如,旋钮调整依赖于数据库监控指标,例如系统负载、读/写块。我们将数据库监控大致分为三种情况—数据库健康监控、活动监控和性能预测。
Database Health Monitor
数据库运行状况监视器(DHM)记录与数据库运行状况相关的指标,例如每秒的查询数、查询延迟,以优化数据库或诊断故障。在[93]中,他们假设具有类似关键性能指标(例如cpu.usage、mysql.tps)的间歇性慢速查询具有相同的根本原因。因此,他们采用两阶段诊断:(i)在离线阶段,他们从故障记录中提取慢速SQL,使用KPI状态对其进行聚类,并要求DBA为每个集群指定根本原因;(ii)在联机阶段,对于传入的慢速SQL,他们根据KPI状态的相似性得分将其与集群C匹配。如果匹配,则使用C的根本原因通知DBA。否则,它们将生成一个新集群,并要求DBA指定根本原因。然而,它不能防止潜在的数据库故障,并且高度依赖DBA的经验。然而,监视许多数据库指标的成本相当高,因为监视也会消耗资源。为了解决这个问题,Taft等人提出了一种弹性数据库系统P-Store,它将数据库监控与工作负载预测相结合。基本思想是主动监控数据库以适应工作负载的变化。
Database Activity Monitor
与运行状况监视器不同,数据库活动监视器(DAM)从外部监视和控制数据库活动(例如,创建新帐户、查看敏感信息),这对于保护敏感数据至关重要。我们将DAM分为两类,活动选择和活动跟踪。对于活动选择,有不同级别的数据库活动(例如,DBA活动、包括DML、DDL和DCL在内的用户事务)。传统的DAM方法需要根据触发规则记录额外系统上的所有活动。例如,公司可能会创建一个规则,每当DBA对返回5个以上结果的信用卡列执行select查询时,该规则会生成警报。然而,记录所有活动仍然是一个沉重的负担,这带来了数据库和监测系统之间频繁的数据交换。因此,为了自动选择和记录有风险的活动,Hagit等人将数据库监控视为多武装匪徒问题(MAB)。MAB模型是一种决策算法,它通过探索当前策略和探索新策略来选择有风险的数据库活动。目标是训练风险得分最大的最优策略。因此,对于MAB模型,在每一步中,它都会对一些风险最高的用户进行抽样,以利用该策略,并对一些用户进行抽样,以探索更好的策略。对于活动跟踪,在决定要监视哪些活动之后,我们需要跟踪高风险的活动并优化数据库性能。
Performance Prediction
查询性能预测对于满足服务级别协议(SLA)至关重要,尤其是对于并发查询。传统的预测方法只捕获逻辑I/O指标(例如,页面访问时间),忽略了许多与资源相关的特性,无法获得准确的结果。因此,Marcus等人使用深度学习来预测并发场景下的查询延迟,包括子/父操作符之间的交互和并行计划。然而,它采用了管道结构(导致信息丢失),无法捕获操作员之间的关系,如数据共享/冲突特征。因此,Zhou等人提出了一种基于图嵌入的性能预测方法。他们使用一个图模型来描述并发查询,其中顶点是操作符,边捕获操作符相关性(例如,数据传递、访问冲突、资源竞争)。他们使用图卷积网络嵌入工作负载图,从图中提取与性能相关的特征,并根据这些特征预测性能。
2.5 Learning-based Security
基于学习的数据库安全旨在利用机器学习技术确保数据库的机密性、完整性和可用性。我们回顾了有关敏感数据发现、访问控制和SQL注入的最新工作。
Learning-based Sensitive Data Discovery
由于敏感数据泄漏会造成巨大的财务和个人信息损失,因此保护数据库中的敏感数据非常重要。敏感数据发现旨在自动检测和保护机密数据。传统的方法使用一些用户定义的规则(如ID、信用卡和密码)来检测敏感数据。例如,DataSunrise2是一个基于搜索的数据发现框架。它首先定义了一些模式(例如,“3[47][0− 9] {13}$”,“\d∗.\d∗$”) 定义敏感数据,然后使用规则通过搜索数据上的模式来检测敏感数据。然而,这种方法有几个局限性。首先,搜索所有数据的成本太高,并且需要用户指定候选搜索列来修剪搜索空间。其次,它无法自动更新新数据的规则,因此,如果对某些未知的敏感数据没有用户定义的规则,则可能会丢失敏感数据。Bhaskar等人提出了一种利用机器学习发现敏感数据模式的算法。他们采用拉普拉斯模型来学习数据记录的实际访问频率,然后可以将频繁访问的记录作为候选敏感数据。首先,他们将数据发现表述为一个评分问题:对于数据集T中的每个数据记录r,r被分配一个评分q(T,r),其值是数据库中的访问频率。其次,由于抽象数据集可能仍然是指数大的,因此它们递归地对k个模式进行采样,这些模式到目前为止尚未从数据集中选择。每次,对于k个模式,他们用拉普拉斯模型计算频率,拉普拉斯模型根据损失值调整噪声率以拟合真实值。第三,为了简化实现,他们直接将独立的拉普拉斯噪声添加到每个模式r的q(T,r)中,并选择具有最高扰动频率的k个模式,这代表了最高的附加风险。通过这种方式,它们可以在资源有限的情况下提高数据发现的准确性。
Access Control
它旨在防止未经授权的用户访问数据,包括表级和记录级访问控制。有几种传统的访问控制方法,如基于协议的访问控制方法、基于角色的访问控制方法、基于查询的访问控制方法和基于目的的访问控制方法。然而,这些方法主要基于静态规则,高级技术(如身份模拟、元数据修改、非法入侵)可能会伪造访问优先级,传统方法无法有效防止这些攻击。最近,人们提出了机器学习算法来估计访问请求的合法性。Colombo等人提出了一种基于目的的访问控制模型,该模型将控制策略细化,以调节数据请求。由于不同的操作和数据内容可能导致不同的私人问题,此方法旨在了解合法访问目的。
SQL Injection
SQL注入是数据库常见的有害漏洞。攻击者可以通过绕过其他信息或干扰SQL语句来修改或查看超出其优先级的数据,例如检索隐藏数据、破坏应用程序逻辑、联合攻击等。例如,应用程序允许用户通过填写SQL语句来访问产品信息,如“SELECT price,abstract from product where pname='?'and released=1”。但攻击者可以通过在pname值中添加额外信息来检索未发布产品的隐藏信息,如“SELECT price,abstract from product where pname='car’−− and is released=’yes’;“,其中“−−” 是SQL中的注释指示符,它消除了“released=1”的限制。然而,传统方法是基于规则的(例如,参数化查询),并且有两个限制。首先,扫描非法参数需要很长时间。其次,非法参数的变体很多,不可枚举,因此传统的特征匹配方法无法识别所有攻击。最近,主要有两种利用机器学习技术的SQL注入检测方法,包括分类树、模糊神经网络。Moises等人提出了一种用于检测SQL注入的分类算法。查询参数中的逻辑故障或错误筛选器经常导致SQL攻击。因此,他们基于从SQL查询中提取的标记构建分类器树,以预测可能的SQL注入。培训样本是具有典型SQL注入和风险级别(危险/正常/无)的查询,这些查询是从数据库日志中收集的。然而,该方法需要大量的训练数据,不能将知识推广到不同的检测目标。为了解决训练样本有限的问题,Batista等提出了一种用于SQL攻击的模糊神经网络(FNN)。其基本思想是用模糊规则识别攻击模式,并将这些规则存储在神经网络中。
3 DB FOR AI
现有的机器学习平台很难使用,因为用户必须编写代码(例如Python)才能利用AI算法进行数据发现/清理、建模训练和模型推理。为了降低使用AI的障碍,数据库社区扩展了数据库技术,以封装AI算法的复杂性,并允许用户使用声明性语言(如SQL)来利用AI算法。在本节中,我们总结了用于降低AI使用复杂性的数据库技术。
3.1 Declarative Language Model
传统的机器学习算法大多是用编程语言(例如Python、R)实现的,并且有一些局限性。首先,它们需要工程技术来定义完整的执行逻辑,例如,模型训练的迭代模式,以及矩阵乘法和展平等张量运算。其次,机器学习算法必须从数据库系统加载数据,数据导入/导出成本可能很高。
因此,提出了面向AI的声明性语言模型,以通过扩展SQL语法实现机器学习的民主化。我们将声明性语言模型分为两类,混合语言模型、统一语言模型和拖放方法。
Hybrid language model
混合语言模型,例如BigQuery ML,包含AI和DB操作。通常,对于每个查询,它将语句拆分为AI操作和DB操作。然后,它在AI平台(如TensorFlow、Keras)上执行AI操作,并在数据库上执行DB操作。混合语言模型的优点是易于实现,但缺点是它们必须频繁地在DB和AI平台之间迁移数据,从而导致效率低下。
Unified language model
为了充分利用数据管理技术,提出了统一的语言模型,以支持数据库中的人工智能查询,而无需进行数据迁移。Hellerstein等人提出了一种数据库内分析方法MADlib,它提供了一套基于SQL的机器学习算法,分三步进行。(1)AI操作符需要频繁的矩阵计算,包括乘法、换位等,MADlib在PostgreSQL中实现了一个定制的稀疏矩阵库。例如,线性代数是用C中的基本算术循环编码的。(2)MADlib抽象了数据库中的许多AI操作符,包括数据采集、访问、采样和模型定义、训练、推理。(3) MADlib支持数据库中的迭代训练。对于具有n次迭代的训练过程,MADlib首先声明一个虚拟表。然后,对于每个迭代,它将m个样本的训练结果(例如,神经单元的梯度)作为视图进行维护,并将虚拟表与视图连接起来以更新模型参数。
Drag-and-Drop Interface
一些SQL语句仍然很复杂(例如嵌套结构、多个连接),没有经验的用户很难理解。因此,有一些研究使用拖放方法来使用AI技术。电子表格是许多数据分析师不可或缺的工具。BigQuery ML提供了一种虚拟电子表格技术,即连接表,它将电子表格界面的简单性与数据库系统中的机器学习算法相结合。首先,它在一个虚拟电子表格中向用户呈现数十亿行数据,用户可以在其中浏览数据。然后,它自动将用户执行的数据操作转换为SQL语句,并将其发送到数据库。通过这种方式,可以使用传统的工作表功能(例如公式、数据透视表和图形)分析数据。
3.2 Data Governance
AI模型依赖于高质量的数据,数据治理旨在发现、清理、集成和标记数据,以获得高质量的数据,这对于部署AI模型非常重要.
Data Discovery
假设一个AI开发人员打算构建一个AI模型。给定一个数据集语料库,用户需要找到相关的数据集来构建AI模型。数据发现旨在根据应用程序和用户需求,从数据仓库中自动找到相关数据集。许多公司提出了数据发现系统,如微软的Infogather和谷歌的Goods。前者主要从属性层面进行模式补足,目的是从海量的Web表语料库中丰富表中的属性。后者是一种数据集级方法,它存储数据集之间的数据集方案、相似性和出处等信息,然后用户可以搜索和管理所需的数据集。然而,这类系统的发现过程是内置的,存储的信息是预定义的,它们无法推广到常见用例,因为可以表示数据集之间的有限关系。为此,Fernandez等人提出了Aurum,这是一个数据发现系统,它根据用户的需求提供灵活的查询来搜索数据集。它利用企业知识图(EKG)捕获各种关系,以支持广泛的查询。EKG是一个超图,其中每个节点表示一个表列,每条边表示两个节点之间的关系,超边连接层次相关的节点,例如同一表中的列。
Data Cleaning
请注意,大多数数据都是脏的和不一致的,脏的或不一致的数据将导致不可靠的决策和有偏见的分析。因此,有必要清理数据。数据清理的管道包括错误检测和错误修复(调查见[57])。大多数数据清理方法主要集中于清理整个数据集。然而,数据清理依赖于任务,不同的任务可能会使用不同的清理技术来修复数据的不同部分。因此,Wang等人为机器学习任务提出了一个清理框架ActiveClean。给定一个具有凸损失的数据集和机器学习模型,它选择最能提高模型性能的记录进行迭代清理。
ActiveClean由4个模块组成:采样器、清洁器、更新器和估计器。采样器用于选择要清理的一批记录。选择标准是通过清除记录后可以做出多少改进来衡量的,即梯度的变化,这是由估计器估计的。然后,清洁器将检查并修复所选记录。接下来,更新程序根据这些已验证的脏数据更新渐变。重复上述四个步骤,直到预算用完。
Data Labeling
如今,一些复杂的机器学习算法,如深度学习,总是需要大量的训练数据来训练一个好的模型。因此,如何获得如此大量的标签数据是一个具有挑战性的问题。获取训练数据的方法主要有三种:领域专家、非专家和不间断监督。首先,领域专家可以提供高质量的标签,从而生成性能良好的模型。然而,要求专家标记大量数据的成本总是太高,因此主动学习技术被扩展到利用少量标记数据来训练模型。其次,得益于商业公共众包平台,如亚马逊Mechanical Turk(AMT)3众包(见[76]中的调查)是解决此类任务的有效方法,它利用数百或数千名员工来标记数据。第三,远程监控利用知识(如Freebase或特定领域的知识)自动标记数据。传统上,监督学习需要大量的训练数据,代价昂贵。无监督方法不需要训练数据,但通常性能较差。远程监控结合了它们的优点。假设我们希望在Freebase的帮助下,使用远程监控从没有标记数据的语料库中提取关系。在训练步骤中,如果文档中的句子包含两个实体,这两个实体是Freebase关系之一的实例,它将从句子中提取特征,添加关系的特征向量并执行训练。然后,在训练步骤中,给定一些实体对作为候选实体,它们使用这些特征来预测基于训练模型的关系。
Data Lineage
数据沿袭旨在描述机器学习管道之间的关系。例如,假设我们检测到工作流的错误结果,然后想要对其进行调试。回顾生成错误的源数据非常有益。此外,如果有一些脏的输入数据,识别相应的输出数据以防止错误的结果是很有帮助的。总之,数据沿袭描述的关系可以分为两类。(1) 向后关系返回生成给定输出记录的输入数据子集;(2) 转发关系返回从给定输入记录生成的输出记录子集。有几种数据沿袭方法可以在输入和输出数据之间建立关系,包括惰性方法和细粒度数据沿袭方法。懒惰方法将沿袭查询视为关系查询,并直接在输入关系上执行它们。优点是基本查询不会产生开销,但缺点是沿袭查询执行的计算成本。渴望线性捕获方法构建沿袭图以加速沿袭查询,并使用图上的路径支持向后和向前查询。细粒度数据沿袭系统将沿袭捕获逻辑和物理操作符紧密集成在数据库中,并使用轻量级和写效率高的索引来实现低开销沿袭捕获。
3.3 Model Training for AI
模型训练是应用人工智能算法必不可少的步骤,包括特征选择、模型选择、模型管理和模型加速。在本节中,我们总结了现有的模型训练技术。
Feature Selection
特征选择(FS)选择可能显著影响模型性能的特征。为了便于表示,给定一个关系表R的数据集,我们将整个特征集定义为F={f1,f2…fn}。FS的目标是选择一个最优子集F∗ ⊆ F、 从而培养出性能最佳的模型。此外,我们使用RF’⊆R表示对应于特征子集F’的子数据集F’ ⊆ F、 一般来说,FS过程包括以下步骤。(1)生成特征子集F’和相应的数据集RF’。(2) 通过在RF’上建立ML模型来评估F’。(3) 反复重复上述两个步骤,直到达到预定义的模型性能或评估了所有特征子集。
由于特征子集的数量为O(2n),由于搜索空间大,使用蛮力方法枚举每个子集的成本太高。因此,在ML社区中,已经提出了许多方法,通过生成一些候选特征子集来减少搜索空间(调查见[47])。最近,有人提出了几项工作,以利用数据库优化技术从特征子集枚举和特征子集评估加速FS过程。具体而言,使用批处理和物化技术来降低特征子集枚举成本。利用基于主动学习的方法加速特征子集评估过程。接下来,我们将详细介绍它们。
Model Selection
模型选择旨在生成模型并设置其超参数,以最大限度地提高给定特定测量的质量。有两类方法,传统的模型选择和神经结构搜索(NAS)。前者侧重于从支持向量机、随机森林、KNN等传统ML模型中选择最佳模型。后者旨在自动构建性能良好的神经架构,包括模型结构设计和超参数设置,这是当前ML和DB界的热门话题。在本次调查中,我们将重点关注基于NAS的DB技术。在ML社区中,已经提出了许多自动匹配的机器学习技术,以实现性能良好的模型或减少每次训练一个模型的延迟,如网格/随机搜索、强化学习方法、贝叶斯优化等(调查见[52])。然而,该问题的一个关键瓶颈是模型选择吞吐量,即每单位时间测试的训练配置数量。高吞吐量允许用户在固定时间内测试更多配置,这使得整个训练过程高效。提高吞吐量的直接方法是并行,流行的并行策略包括任务并行、批量同步并行、模型跳并行和参数服务器。
Model Management
数据分析师通常以迭代的方式构建机器学习模型。给定一个ML任务,他们首先从一些整洁的模型开始,指定训练/测试数据和损失函数。其次,根据数据对模型进行评估。根据结果,分析员修改模型并重复上述步骤,直到得到性能良好的模型。然而,数据分析员很难回顾之前的评估结果以获得一些见解,因为之前构建的模型尚未记录。因此,提出了模型管理来跟踪、存储和搜索大量的ML模型,以便人们可以方便地分析、修改和共享他们的模型。在这一部分中,我们将模型管理系统分为两类,即基于GUI的系统和基于命令的系统。
Hardware Acceleration
计算机体系结构社区研究如何利用硬件加速器(如FPGA)来加速ML模型。对于训练时间长的ML任务,数据存储在RDBMS中,数据科学家可以使用硬件加速任务。为了使ML的硬件加速易于在RDBMS中使用,Mahajan提出了DAnA,一种将ML查询作为输入的框架,调用FPGA加速器获取数据并自动进行ML计算。更具体地说,DAnA首先设计了一种结合SQL和Python的高级编程语言,以定义所需的ML算法和数据,其中SQL部分指定如何检索和管理数据,Python部分描述ML算法。其次,DAnA解析查询并使用Striders,这是一种连接FPGA和数据库的硬件机制。具体来说,Striders直接将训练数据从缓冲池检索到加速器,而无需访问CPU。然后导出特征向量和标签。最后,设计了一个执行模型,将线程级和数据级并行性结合起来,以加速ML算法。对于列存储数据库,Kara et.al提出了一个框架ColumnML,该框架研究如何利用硬件加速广义线性模型(GLM)的训练。对于按列存储的数据,采用随机坐标下降法(SCD)求解GLMs算法。ColumnML提出了一种基于分区的SCD来改进缓存的局部性。此外,列存储数据被压缩和加密,这导致CPU转换用于训练的数据的效率较低。因此,ColumnML利用FPGA动态转换数据。
3.4 DB Techniques for Accelerating Model Inference
模型推理是使用预先训练好的模型来预测测试样本,包括操作员支持、操作员选择和执行加速。
Operator Support
数据库社区研究在数据库内进行模型推理,并利用优化技术加速模型推理。与传统的数据库操作(如筛选、连接、排序)不同,AI模型涉及更复杂的操作符类型,包括标量(0维)/向量(1维)/矩阵(2维)/张量(N维)运算。首先,数据库本机支持标量操作,可以优化执行。其次,向量和张量数据可以转换为矩阵:向量是一维的特殊矩阵,而张量可以分解为多个矩阵。因此,现有的大多数研究都集中在优化矩阵数据上。模型推理中的矩阵运算包括数据预处理、前向传播和模型训练,这通常很耗时。传统AI系统依赖GPU等新硬件来提高执行性能。Boehm等人提出了一种数据库内机器学习系统SystemML。SystemML通过用户定义的聚合函数支持矩阵操作,这些函数在列级别提供并行数据处理。首先,SystemML根据操作的访问模式对操作进行分类,如按单元的矩阵加法和转置。然后,SystemML通过代数重写优化这些操作,调整矩阵乘法链的操作符顺序,并将它们编译成一个由分组、求和和计数等低级聚合操作符组成的DAG。因此,SystemML可以在数据库中高效地执行矩阵运算符。
Operator Selection
同一个ML模型可以转换为不同的物理运算符。例如,线性回归可以解释为线性正则化算子或导数算子。然而,人工智能系统并不直接考虑操作符的选择,而是将这项工作交给GPU等硬件来完成,GPU可以将稀疏张量展平,并将张量分解转换为更简单的矩阵乘法。但硬件级别的选择往往陷入局部优化,无法估计总体资源需求,并且会出错。数据库优化器可以有效地估计执行成本,并在本地优化操作员选择。Boehm等人提出了一种数据库中的操作员选择方法。首先,它们根据数据稀疏性、集群大小或内存的资源估计函数来选择操作。例如,它估计M(X)上每个操作的内存消耗,M(X)表示单个块矩阵的内存估计,M(Xp)表示块分区矩阵的内存估计。目标是在内存限制下选择总执行时间最小的操作组合。其次,在Spark中,它们通过尽可能多地将选定的操作替换为Spark的操作符(如Map、Reduce、Shuffle),进一步提高了执行效率。第三,为了避免重复读取HDFS、文本解析和无序操作(这些操作非常耗时),它们会在每次持久读取后注入检查点。如果任何检查点报告三个操作符中的一个,Spark中的优化器将在下一次迭代中删除/替换该操作符。
Execution Acceleration
与模型训练不同,模型推理需要选择ML模型并执行前向传播来预测不同的问题。现有的执行加速技术包括内存方法和分布式方法。前者旨在将数据压缩到内存中,并尽可能多地进行内存计算。后者将任务路由到不同的节点,并使用并行计算减少数据处理和模型计算的负担。
4 RESEARCH CHALLENGES AND FUTURE WORK
4.1 AI4DB
利用AI技术优化数据库仍然存在一些挑战。
Training Data
大多数人工智能模型需要大规模、高质量、多样化的训练数据来实现高性能。然而,很难在AI4DB中获取训练数据,因为这些数据要么是安全关键的,要么依赖于DBA。例如,在数据库旋钮调整中,应根据DBA的经验获取训练样本。因此,很难获得大量的训练样本。此外,为了构建有效的模型,培训数据应涵盖不同的场景、不同的硬件环境和不同的工作负载。它需要使用一个小的训练数据集来获得高质量模型的新方法。
Adaptability
适应性是一个巨大的挑战,例如,适应动态数据更新、其他数据集、新硬件环境和其他数据库系统。我们需要应对以下挑战。如何使数据集上经过训练的模型(例如优化器、成本估算)适应其他数据集?如何使硬件环境中经过培训的模型适应其他硬件环境?如何使一个经过训练的数据库模型适应其他数据库?如何使经过培训的模型支持动态数据更新?
Model Convergence
一个学习模型是否能够收敛是非常重要的。如果模型无法收敛,我们需要提供替代方法,以避免做出延迟和不准确的决策。例如,在旋钮调节中,如果模型不收敛,我们就不能利用该模型进行在线旋钮建议。
Learning for OLAP
传统的OLAP侧重于关系数据分析。然而,在大数据时代,出现了许多新的数据类型,例如图形数据、时间序列数据、时空数据,它需要新的数据分析技术来分析这些多模型数据。此外,除了传统的聚集查询外,许多应用程序还需要使用机器学习算法来增强数据分析,例如图像分析。因此,集成AI和DB技术以提供新的数据分析功能相当具有挑战性。
Learning for OLTP
事务建模和调度对于OLTP系统非常重要,因为不同的事务可能会有冲突。有希望利用学习技术优化OLTP查询,例如,一致快照,现场查询处理。然而,它不能自由地建模和调度事务,它调用了更高效的模型,可以在多个核心和多台机器中即时建模和调度事务。
4.2 DB4AI
In-database Training
在数据库内支持人工智能训练是一项挑战,包括模型存储、模型更新和并行训练。首先,在数据库中存储模型是一个挑战,这样模型就可以被多租户训练和使用,我们需要考虑安全和隐私问题。其次,更新模型很有挑战性,尤其是当数据动态更新时。
Accelerate AI Training using Database Techniques
大多数研究都集中在人工智能算法的有效性上,而对算法的效率关注不多,这也是非常重要的。它要求利用数据库技术来提高人工智能算法的性能,例如索引和视图。例如,自动驾驶车辆需要大量的示例进行培训,这相当耗时。实际上,它只需要一些重要的例子,例如夜间或雨天的培训案例,但没有太多多余的例子。因此,我们可以对样本和特征进行索引,以便进行有效的训练。然而,很难定义哪些示例是重要的,例如雨天缺少井盖。因此,它需要通过示例进行搜索,在给出一些示例后,可以根据示例找到训练样本。此外,不同用户重复使用经过良好训练的人工智能模型也是一个挑战。
AI Optimizer
现有研究使用用户定义函数(UDF)来支持人工智能模型,但这些模型并没有得到有效优化。它要求将AI模型实现为操作员内部数据库,并为每个操作员设计物理操作员。最重要的是,它需要推下人工智能运营商,并估计人工智能运营商的成本/基数。它需要一个AI优化器来优化AI训练和推理。此外,在分布式环境中有效支持AI操作员更为重要。
Fault-tolerant Learning
现有的学习模型训练没有考虑容错性。当执行分布式训练时,一个进程崩溃,整个任务将失败。我们可以结合数据库系统的容错技术来提高数据库内学习的鲁棒性。为了确保在可预测和不可预测的灾难下的业务连续性,数据库系统必须保证容错和灾难恢复能力。
4.3 Hybrid DB and AI
Hybrid Relational and Tensor Model
数据库采用关系模型,许多AI模型使用张量模型。传统CPU擅长处理关系模型,AI芯片擅长处理张量模型。然而,传统的CPU不能有效地处理张量模型,AI芯片不能有效地处理关系模型。它需要有效的方法来加速AI芯片上的关系运算,跨传统CPU和AI芯片调度不同的操作符,并支持关系模型和张量模型。此外,研究一种统一的数据模型来支持标量、向量、大规模张量和其他不同类型的数据是很有希望的。
Hybrid DB&AI Inference
许多应用程序需要DB和AI操作,例如,查找住院时间超过3天的医院的所有患者。本地方法是预测每个患者的住院时间,然后删减住院时间大于3的患者。显然,这种方法成本很高,需要一种新的优化模型来优化DB和AI,包括新的优化模型、AI操作符下推、AI成本估算和AI索引/视图。
Hybrid DB&AI System
大多数应用程序同时使用AI和DB操作符,因此需要一个能够支持这两个操作符的端到端混合AI和DB系统。它需要设计一种声明性语言,例如,扩展SQL以支持AI操作符的AISQL、协同优化这两种操作的AI和DB运算限制器、调度这两种类型任务的有效(分布式)执行引擎以及适当的存储引擎。
5 CONCLUSION
本文总结了AI4DB和DB4AI的最新技术。前者侧重于利用AI技术解决计算复杂度高的数据处理问题,例如旋钮调整、成本估算、连接顺序选择、索引顾问和视图顾问。后者侧重于使用DB技术来降低使用AI的复杂性并加速AI模型,例如声明式AI,以及加速AI训练和推理。我们还提供了AI4DB、DB4AI以及混合DB和AI优化中的一些研究挑战和开放问题。
Acknowledgement. 感谢刘家斌、韩越、项羽、王家义、牛泽平的讨论和校对。本文得到了中国国家科学基金会(61925205,61632016)、华为和好未来教育的支持。

