
- 1关于“error when starting dev server:Error: The package “@esbuild/win32-x64“ could not be found”的错误_the package "@esbuild/win32-x64" could not be foun
- 2Git—与远程仓库建立起联系以gitee为例(初学者)
- 3「Python大数据」LDA主题分析模型_python lde模型
- 4鸿蒙网络状态监听【坚果派】_鸿蒙 axios 实时监听
- 5探秘开源项目:外卖爬虫(Waimai Crawler)——高效获取餐饮信息的新工具
- 6【可变参数模板】
- 7无人机+自组网:基站式自组网电台技术详解
- 8Mysql报错 Error querying database. Cause java.sql.SQLSyntaxErrorException_error querying database. cause: java.sql.sqlsyntax
- 9GitHub上8个强烈推荐的 Python 项目_github python
- 10基于Spring Boot的火车订票管理系统设计与实现
OpenTSDB时序数据库概述
赞
踩
【摘要】 OpenTSDB时序数据库前言OpenTSDB是一个架构在HBase系统之上的实时监控信息收集和展示平台。基于HBase的分布式的,可伸缩的时间序列数据库OpenTSDB使用HBase存储所有的时序(无须采样)来构建一个分布式、可伸缩的时间序列数据库。一、 OpenTSDB介绍1.1 OpenTSDB使用场景OpenTSDB主要针对具有时间特性和需求的数据,例如做监控数据、温度变化类别的数据...
OpenTSDB时序数据库
前言
OpenTSDB是一个架构在HBase系统之上的实时监控信息收集和展示平台。
基于HBase的分布式的,可伸缩的时间序列数据库
OpenTSDB使用HBase存储所有的时序(无须采样)来构建一个分布式、可伸缩的时间序列数据库。
一、 OpenTSDB介绍
1.1 OpenTSDB使用场景
OpenTSDB主要针对具有时间特性和需求的数据,例如做监控数据、温度变化类别的数据存储等。
OpenTSDB的设计目标是用来采集大规模集群中的监控信息(包括集群中的网络设备、操作系统、应用程序),并可实现数据的秒级查询,解决海量监控类数据在普通数据库中存储查询的局限性。
1.2 OpenTSDB存储与扩展
OpenTSDB是基于HBase的时序数据库(时间序列数据库)。
输入数据无需转换,写的是什么数据存的就是什么数据,时序数据以毫秒的精度保存。
它支持秒级数据采集所有Metrics,是以Metirc为单元的存储结果,支持永久存储,运行在Hadoop 和 HBase之上,可以通过添加节点进行扩容,可以实现大数据量下的毫秒级别的查询。
1.3 OpenTSDB数据展现
时间序列数据通常以折线图方式展示,OpenTSDB提供了一个内置的GUI(简单用户界面),用于选择一个或多个指标和标签,以生成图形作为图像。
或者可以使用HTTP API将OpenTSDB绑定到外部开源系统与其交互,例如监视框架,仪表板,统计包或自动化工具。
由于OpenTSDB自身内置的WebUI可视化功能相对简陋,一般采用第三方工具Grafana用作可视化展示及监控报警。
二、OpenTSDB工作原理
OpenTSDB由时间序列守护进程(TSD)和一组命令行实用程序组成。
与OpenTSDB的交互主要通过运行一个或多个TSD来实现,每个TSD都是独立的。没有主服务器,没有共享状态,因此可以根据需要运行尽可能多的TSD来处理工作负载。
每个TSD使用开源数据库HBase或托管Google Bigtable服务来存储和检索时间序列数据。
数据模式经过高度优化,可快速聚合相似的时间序列,从而最大限度地减少存储空间。
TSD的用户不需要直接访问底层仓库,可以通过简单的telnet风格协议,HTTP API或简单的内置GUI与TSD进行通信,所有通信都发生在同一个端口上(TSD通过查看接收的前几个字节来确定客户端的协议)。
三、OpenTSDB架构
3.1 OpenTSDB架构图

3.2 OpenTSDB组件
3.2.1 Servers
Servers指服务器,上面的C是指Collector,可以理解为OpenTSDB的agent,通过Collector收集数据,推送数据。
3.2.2 TSD
每个实例TSD都是独立的,没有master,没有共享状态(shared state)。
TSD是对外通信的无状态的服务器,Collector可以通过TSD简单的RPC协议推送监控数据。另外TSD还提供了一个web UI页面供数据查询,也可以通过脚本查询监控数据。
3.2.3 HBase
TSD收到监控数据后,是通过AsyncHbase库来将数据写入到HBase。
AsyncHbase是完全异步、非阻塞、线程安全的HBase客户端,使用更少的线程、锁以及内存,可以提供更高的吞吐量,特别对于大量的写操作。
四、OpenTSDB存储核心概念
我们以一个监控系统的背景来介绍这些概念,比如我们需要记录的数据是一个集群里面各个服务器磁盘的使用率。
4.1 Metric
度量(Metric)就是一个监控项,监测数据的指标,譬如服务器的CPU、MEMORY、磁盘使用率,监测环境指标风力、温湿度等。
4.2 Tag
标签(Tag):度量(Metric) 虽然指明了要监测的指标项,但没有指明要针对什么对象的该指标项进行监测。
标签(Tag) 就是用于表明指标项监测针对的具体对象,属于指定度量下的数据子类别, 也可以说是用来区分各个度量(Metric)。
一个标签(Tag) 由一个标签键(TagKey) 和一个对应的标签值(TagValue) 组成,是一种K/V格式的数据,例如“城市(TagKey)=杭州(TagValue)”就是一个标签。
更多标签示例:机房 = A 、IP = 127.0.XX.XX,标签可以有一至多个,最大可设置16对标签。
4.3 Value
值(value)表示一个度量(Metric)对应的实际值,例如磁盘使用率50%、 15 级(风力)和 20 ℃(温度)。
4.4 Timestamp
时间戳(时间序列),指明时间点,用来表示这条数据是什么时候产生的。
4.5 DataPoint
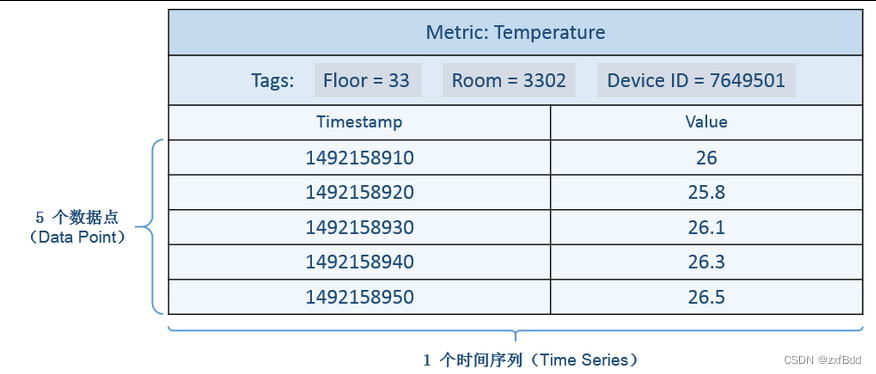
数据点 (Data Point):针对监测对象的某项指标(由度量和标签定义)按特定时间间隔(连续的时间戳)采集的每个度量值就是一个数据点。“ 一个度量 + N 个标签(N >= 1)+ 一个时间戳 + 一个值 ”定义一个数据点。
DataPoint包括以下部分:Metric、Tags、Value、Timestamp,可以理解为一个监控项就是一个DataPoint,最终保存到OpenTSDB的就是由很多的DataPoint组成。
4.6 Time Series(时间序列)
时间序列(Time Series):针对某个监测对象的某项指标(由度量和标签定义)的描述。“一个度量 + N 个标签KV组合(N >= 1)”定义为一个时间序列,某个时间序列上产生的数据值的增加,不会导致时间序列的增加。 时间序列示意图:
4.7 时间精度
时间精度:时间线数据的写入时间精度——毫秒、秒、分钟、小时或者其他稳定时间频度。例如,每秒一个温度数据的采集频度,每 5 分钟一个CPU使用率的采集频度。
4.8 降采样
降采样(Downsampling):当查询的时间区间跨度较长而原始数据时间精度较细时,为了满足业务需求的场景、提升查询效率,就会降低数据的查询展现精度,这就叫做降采样,比如按秒采集一年的数据,按照天级别查询展现。
五、OpenTSDB存储设计
5.1 OpenTSDB表存储设计
OpenTSDB使用HBase进行数据存储,在HBase中存放tsdb、tsdb-uid、tsdb-meta、tsdb-tree四张表,主要用到的核心存储是两张表,tsdb和tsdb-uid。
假设我们要存放以下的数据:
Metric:proc.loadavg.1m
Timestamp:1234567890 (2009-02-14 07:31:30)
Value:0.42
Tags:host=web42,pool=static
| Metric(指标) | proc.loadavg.1m | 50 |
| 时间戳 | TimeStamp | 1234567890 |
| 标签key | tagk | host |
| 标签value | tagv | web42 |
| 标签key | tagk | pool |
| 标签value | tagv | static |
5.1.1 OpenTSDB分配UID时遵循如下规则
UID全称为Unique Identifier。这些UID信息被保存在OpenTSDB的元数据表中,默认表名为”tsdb-uid”。
1)metrics、tagKey和tagValue的UID分别独立分配。
2)每个metrics名称(tagKey/tagValue)的UID值都是唯一。不存在不同的metrics(tagKey/tagValue)使用相同的UID,也不存在同一个metrics(tagKey/tagValue)使用多个不同的UID。
3)UID值的范围是0x000000到0xFFFFFF,即默认地,UID被编码为3字节,metrics(或tagKey、tagValue)最多只能存在16777216个不同的值。也可以修改参数配置改为4字节。
5.1.2 tsdb-uid表
tsdb-uid中保存的是metric,tagk,tagv的一些映射关系,意在缩短rowkey的长度。
OpenTSDB使用一个字典表tsdb-uid,将metrics和tag映射成3位整数的uid,存储指标数据时按uid存储,节省了大量存储空间,同时提高了查询效率。
tsdb-uid表结构如下:

tsdb-uid表包含两个列族”id”和“name“,其中列族name将uid映射到一个字符串,这里的uid就是我们在tsdb表中用作rowkey的。
列族id则是将字符串映射到uid。这两个列族的数据其实是相互对应的,两者存储的值和rowKey是互反的。
这里再说明一下这张表的作用:
tsdb-uid是 tsdb 的辅助表,用于查找uid对应的指标或者指标对应的uid,它就是用于存储一些映射关系,由于这张表的存在,可以节省存储空间。我们的metric,tag会在数据中重复出现多次,但它在tsdb-uid这张表中只会存一次,并且会有一个唯一的uid与之对应。
这样在tsdb中再存储这个数据的时候,我们反复存储的就不是这个值而是这个uid,很多情况下这个uid的长度远远小于这个值的长度,这样就在一定程度上节省了很多空间。
在前面提到这里的uid默认是3字节整数,2^23是8百多万,但是这个数据并不是说我们只能存储8百多万条数,而是8百多万种数据(这个数据量是指metric或是tag的种类),相同的metric和tag对应的是同一个uid,而2^23是说可以有这个量的uid存在,而这些uid可以对应多少条数据取决于数据中数据项的重复程度。
5.1.3 tsdb表
tsdb是实际存储数据的表,对于一小时内相同metrics和tags的datapoint,在tsdb表中OpenTSDB会合并成一行数据,并且更进一步,将所有列的数据会合并成一列,通过合并数据行和列减少了大量冗余key的存储,节省大量存储空间。tsdb表结构如下:
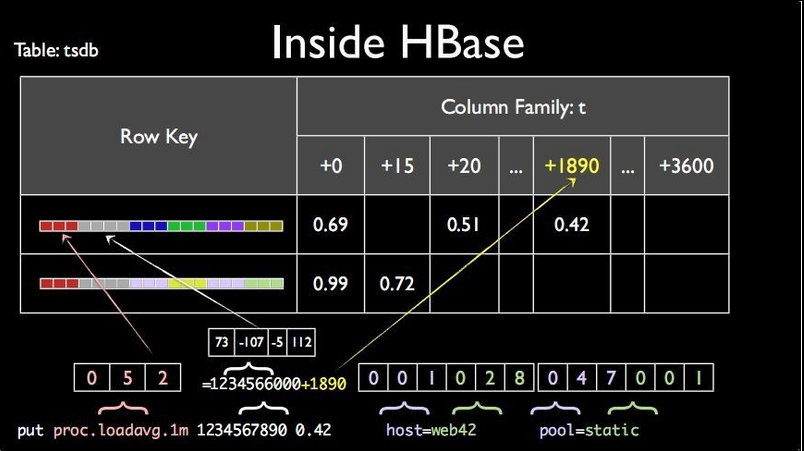
tsdb表包含一个列族“t”,在HBase中列族名字越短,所占用的字节数也就越短,越有利于存储。
tsdb表中RowKey的设计:RowKey的设计规则是 metric + timestamp + tagk1 + tagv1… + tagkN + tagvN。
但是OpenTSDB并不是简单地将这些数据组合起来,OpenTSDB为了节省存储空间,将每个部分都做了映射。
这里面除了timestamp,每一项都在tsdb-uid表中有一个映射。默认是每一个值都映射到一个3字节的整数,就是24位,2^23是800W+,但是我们可以自己配置字节数,比如我们可以用四个字节,那就是几十亿的数据量。
映射关系为:proc.loadavg.1m-->052、 host-->001、 web42-->028、 pool-->047、static→001。
这样Rowkey的设计还有一个好处,就是各个项的长度是固定的,对于原来的每一个metric,tag key,tag value的长度都是不固定的,这不利于通过字节偏移量来直接定位它们。(否则需要使用特定的分隔符来对各个项进行分割,而且为了避免输入信息中可能存在特定的分隔符导致解析出错,还要对所有输入信息的分割符进行转义处理)。
tsdb表中Column的设计:
为了方便后期更进一步的节省空间,OpenTSDB将一个小时的数据,保存在一行里面。
列的设计依赖于Timestamp,将一行数据表示为一个小时的,用Timestamp除以小时(一小时 = 60秒 * 60分钟 = 3600 秒 ) ,就可以得到这条数据是哪一个小时,余数作为列名。那么1234567890(2009-02-14 07:31:30)得到的是1234566000整点时间戳(2009-02-14 07:00:00),余数1890(1234566000+1890 = 1234567890(2009-02-14 07:31:30))。
那么1234566000会放在rowKey中,1890秒会作为列名,即小时内秒数被当作了Column,表示这条数据是在这个小时里面的第1890秒。
这里的设计是充分利用了HBase列可以动态扩充的特点。我们并不知道这一个小时会有多少条数据,但是同一时间段来的数据余数肯定不一样,这样就可以不断地添加列。
5.1.4 tsdb-tree表
它是一张索引表,用于展现树状构造的,类似于文件系统,以方便其他系统使用,这里咱们不做深刻的剖析。(备注:此表暂无实际运用案例,默认未开启该特性。)
通过配置项tsd.core.tree.enable_processing来打开是否需要往此表里面写入数据。
5.1.5 tsdb-meta表
用于存储时间序列索引和元数据,默认未开启该特性。(备注:此表暂无实际运用案例)
这个表是OpenTSDB中不同时间序列的一个索引,可以用来存储一些额外的信息,该表只有一个列族name,两个列,分别为ts_meta、ts_ctr。
这个表里面的数据是可以根据配置项配置来控制是否生成与否,生成几个列,具体的配置项有:
tsd.core.meta.enable_realtime_ts
tsd.core.meta.enable_tsuid_incrementing
tsd.core.meta.enable_tsuid_tracking
RowKey和tsdb表一样,其中不包含时间戳:<metric_uid> <tagk1><tagv1> [...<tagkN><tagvN>]。
ts_meta Column 和UIDMeta相似,其为UTF-8编码的JSON格式字符串。
ts_ctr Column 计数器,用来记录一个时间序列中存储的数据个数,其列名为ts_ctr,为8位有符号的整数。
六、使用注意事项
1) 默认提供的HBase建表语句是没有预分区的,这样会导致大批量数据写入的时候有热点问题,建议进行预分区。
2) OpenTSDB 只有4 张HBase 表,所有的数据都存放在tsdb一张表,这就意味在OpenTSDB 这个层级上是无法更小的粒度来区别对待不同业务,比如不同的业务建不同的表存储数据。

