
热门标签
热门文章
- 1计算机网络——路由实验(静态路由,RIP,ospf单区域,多区域 )_静态路由实验
- 2TS+React+d3.js实现数据可视化力导图_react中使用d3js写关系图
- 3【leetcode]189.轮转数组(C语言实现)_leetcode 数组转置实现
- 4SEAL 学习第二天: encoder处理_seal 噪声预算
- 5hadoop伪分布式环境搭建,完整的详细步骤_windows hadoop伪分布式搭建全过程
- 6鼠标滚轮一页去老远+选择文本时需要点两次_框选文本鼠标点2次
- 7数据结构(七)复杂度渐进表示
- 8CNN内部计算及卷积核、通道数关系_卷积核通道数
- 9SSH协议的原理和使用:深入剖析SSH协议的原理和使用方法_ssh 压缩
- 10云计算的未来:对企业,员工和社会的影响_云计算组织影响
当前位置: article > 正文
自然语言处理 文本表示和简单分类_自然语言处理能否判定一段文本的风格
作者:IT小白 | 2024-05-14 03:56:17
赞
踩
自然语言处理能否判定一段文本的风格
1. TF-IDF
TF-IDF全称term frequency-inverse document frequency,词频逆文档频率,是通过单词在文档中出现的频率来衡量其权重,也就是说,IDF的大小与一个词的常见程度成反比,这个词越常见,编码后为它设置的权重会倾向于越小,以此来压制频繁出现的一些无意义的词。在sklearn当中,我们使用feature_extraction.text中类TfidfVectorizer来执行这种编码。
TfidfVectorizer可以把CountVectorizer, TfidfTransformer合并起来,直接生成TF-IDF值。
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
tfidf_vec = TfidfVectorizer()
tfidf_matrix = tfidf_vec.fit_transform(corpus)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.1 代码实践
sample = ["Machine learning is fascinating, it is wonderful"
,"Machine learning is a sensational techonology"
,"Elsa is a popular character"]
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
X = vec.fit_transform(sample)
#使用接口get_feature_names()调用每个列的名称
import pandas as pd
#注意稀疏矩阵是无法输入pandas的
CVresult = pd.DataFrame(X.toarray(),columns = vec.get_feature_names())
CVresult
from sklearn.feature_extraction.text import TfidfVectorizer as TFIDF
vec = TFIDF()
X = vec.fit_transform(sample)
#同样使用接口get_feature_names()调用每个列的名称
TFIDFresult = pd.DataFrame(X.toarray(),columns=vec.get_feature_names())
TFIDFresult
#使用TF-IDF编码之后,出现得多的单词的权重被降低了么?
CVresult.sum(axis=0)/CVresult.sum(axis=0).sum()
TFIDFresult.sum(axis=0) / TFIDFresult.sum(axis=0).sum()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2. 互信息
那么什么是互信息呢?变量x与变量y之间的互信息,可以用来衡量已知变量x时变量y的不确定性减少的程度,同样的,也可以衡量已知变量y时变量x的不确定性减少的程度。
互信息是基于熵而得到的。什么是熵呢?一个随机变量的熵是用来衡量它的不确定性的。比如,对于变量y,熵的计算公式如下
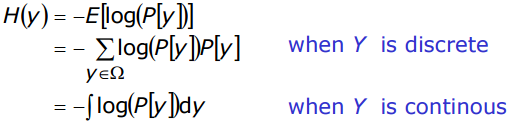
当变量y是离散变量时,则累加即可,而当变量y是连续变量时,则需要通过积分方法来计算。其实,熵可以解释为表示变量y所需二进制位的平均值。
2.1 代码实践
## 使用互信息特征筛选
from sklearn.feature_selection import mutual_info_classif
mutual_values = mutual_info_classif(X_train , y_train)
print(互信息中位数为', np.median(mutual_values))
print('互信息为0的个数为',sum(mutual_values == 0))
## 抽取互信息大于0的idx
idx = [i for i, value in enumerate(mutual_values) if value > 0]
## 特征提取
X_train = X_train[idx]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3. 逻辑回归分类
3.1 n-gram分类
import pickle
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn import linear_model
with open(r'concat_10_data_plus_vam.pkl', 'rb') as f:
data = pickle.load(f)
label = pickle.load(f)
x_train, x_test, y_train, y_test = train_test_split(data, label, random_state=42, test_size=0.5)
vectorizer = CountVectorizer(ngram_range=(1, 2), max_features=50000)
x_train = vectorizer.fit_transform(x_train)
x_test = vectorizer.transform(x_test)
model = linear_model.LogisticRegression(n_jobs=-1)
model.fit(x_train, y_train)
model.score(x_test, y_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
结果为0.9637368731087971
3.2 n-gram + TF-IDF分类
import pickle
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn import linear_model
with open(r'concat_10_data_plus_vam.pkl', 'rb') as f:
data = pickle.load(f)
label = pickle.load(f)
x_train, x_test, y_train, y_test = train_test_split(data, label, random_state=42, test_size=0.5)
vectorizer = TfidfVectorizer(ngram_range=(1, 2), max_features=50000)
x_train = vectorizer.fit_transform(x_train)
x_test = vectorizer.transform(x_test)
model = linear_model.LogisticRegression(n_jobs=-1)
model.fit(x_train, y_train)
model.score(x_test, y_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
结果为0.9632015319583317
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/567168
推荐阅读
相关标签

