
- 1Centos7安装RabbitMQ最新版3.8.5,史上最简单实用安装步骤_centos7 rabbitmq3.8.5安装
- 2SQL Server 新建登录名以及用户授权_sql server 登录
- 3关于stc89c52驱动舵机代码_stc89c52控制舵机
- 4玩转MySQL:如何正确应用索引_如何关闭 index skip scan扫描
- 5一步一步实现STM32-FOTA系列教程之BIN文件解包_fota bin
- 6如何使用 Docker 来安装 ONLYOFFICE Workspace 12.0?
- 7latex自定义参考文献_latex 参考文献
- 8Pod控制器应用进阶三_container image already present on machine
- 9【网络原理】网络通信,网络协议,协议分层,网络设备的分层,封装和分用
- 10探索XQuartz:Mac OS上的开源X窗口系统
mysql中括号_玩转Mysql系列 第23篇:mysql索引管理详解
赞
踩
Mysql系列的目标是:通过这个系列从入门到全面掌握一个高级开发所需要的全部技能。
欢迎大家加我微信itsoku一起交流java、算法、数据库相关技术。
这是Mysql系列第23篇。
环境:mysql5.7.25,cmd命令中进行演示。
代码中被[]包含的表示可选,|符号分开的表示可选其一。
关于索引的,可以先看一下前2篇文章:
什么是索引?
mysql索引原理详解
本文主要介绍mysql中索引常见的管理操作。
索引分类
分为聚集索引和非聚集索引。
聚集索引
每个表有且一定会有一个聚集索引,整个表的数据存储在聚集索引中,mysql索引是采用B+树结构保存在文件中,叶子节点存储主键的值以及对应记录的数据,非叶子节点不存储记录的数据,只存储主键的值。当表中未指定主键时,mysql内部会自动给每条记录添加一个隐藏的rowid字段(默认4个字节)作为主键,用rowid构建聚集索引。
聚集索引在mysql中又叫主键索引。
非聚集索引(辅助索引)
也是b+树结构,不过有一点和聚集索引不同,非聚集索引叶子节点存储字段(索引字段)的值以及对应记录主键的值,其他节点只存储字段的值(索引字段)。
每个表可以有多个非聚集索引。
mysql中非聚集索引分为
单列索引
即一个索引只包含一个列。
多列索引(又称复合索引)
即一个索引包含多个列。
唯一索引
索引列的值必须唯一,允许有一个空值。
数据检索的过程
看一张图:
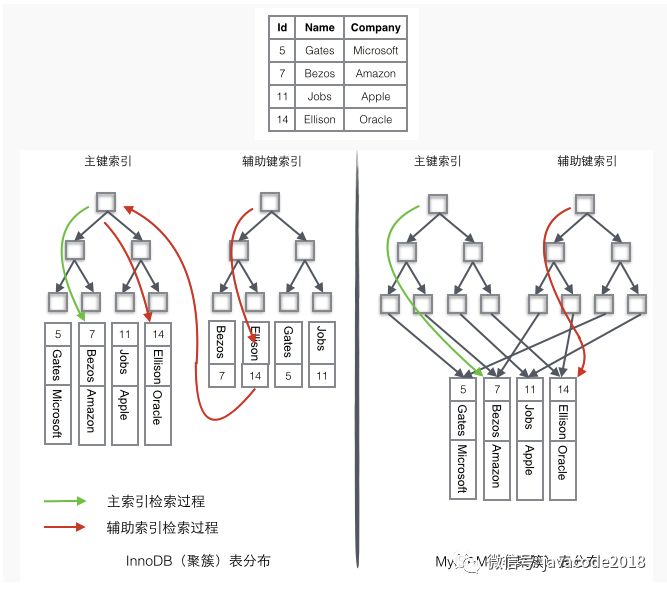
上面的表中有2个索引:id作为主键索引,name作为辅助索引。
innodb我们用的最多,我们只看图中左边的innodb中数据检索过程:
如果需要查询id=14的数据,只需要在左边的主键索引中检索就可以了。
如果需要搜索name='Ellison'的数据,需要2步:
先在辅助索引中检索到name='Ellison'的数据,获取id为14
再到主键索引中检索id为14的记录
辅助索引相对于主键索引多了第二步。
索引管理
创建索引
方式1:
create [unique] index 索引名称 on 表名(列名[(length)]);方式2:
alter 表名 add [unique] index 索引名称 on (列名[(length)]);如果字段是char、varchar类型,length可以小于字段实际长度,如果是blog、text等长文本类型,必须指定length。
[unique]:中括号代表可以省略,如果加上了unique,表示创建唯一索引。
如果table后面只写一个字段,就是单列索引,如果写多个字段,就是复合索引,多个字段之间用逗号隔开。
删除索引
drop index 索引名称 on 表名;查看索引
查看某个表中所有的索引信息如下:
show index from 表名;索引修改
可以先删除索引,再重建索引。
示例
准备200万数据
/*建库javacode2018*/上图中使用存储过程循环插入了200万记录,表中有4个字段,除了sex列,其他列的值都是没有重复的,表中还未建索引。
插入的200万数据中,id,name,email的值都是没有重复的。
无索引我们体验一下查询速度
1;上面我们按id查询了一条记录耗时770毫秒,我们在id上面创建个索引感受一下速度。
创建索引
我们在id上面创建一个索引,感受一下:
create index idx1 on test1 (id);上面的查询是不是非常快,耗时1毫秒都不到。
我们在name上也创建个索引,感受一下查询的神速,如下:
create unique index idx2 on test1(name);查询快如闪电,有没有,索引是如此的神奇。
创建索引并指定长度
通过email检索一下数据
'javacode1000085@163.com';耗时1秒多,回头去看一下插入数据的sql,我们可以看到所有的email记录,每条记录的前面15个字符是不一样的,结尾是一样的(都是@163.com),通过前面15个字符就可以定位一个email了,那么我们可以对email创建索引的时候指定一个长度为15,这样相对于整个email字段更短一些,查询效果是一样的,这样一个页中可以存储更多的索引记录,命令如下:
create index idx3 on test1 (email(15));然后看一下查询效果:
'javacode1000085@163.com';耗时不到1毫秒,神速。
查看表中的索引
我们看一下test1表中的所有索引,如下:
mysql> show index from test1;+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+| test1 | 0 | idx2 | 1 | name | A | 1992727 | NULL | NULL | | BTREE | | || test1 | 1 | idx1 | 1 | id | A | 1992727 | NULL | NULL | | BTREE | | || test1 | 1 | idx3 | 1 | email | A | 1992727 | 15 | NULL | YES | BTREE | | |+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+3 rows in set (0.00 sec)可以看到test1表中3个索引的详细信息(索引名称、类型,字段)。
删除索引
我们删除idx1,然后再列出test1表所有索引,如下:
mysql> drop index idx1 on test1;Query OK, 0 rows affected (0.01 sec)Records: 0 Duplicates: 0 Warnings: 0mysql> show index from test1;+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+| test1 | 0 | idx2 | 1 | name | A | 1992727 | NULL | NULL | | BTREE | | || test1 | 1 | idx3 | 1 | email | A | 1992727 | 15 | NULL | YES | BTREE | | |+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+2 rows in set (0.00 sec)本篇主要是mysql中索引管理相关一些操作,属于基础知识,希望大家掌握。
下篇文章介绍:
一个表应该创建哪些索引?
有索引时sql应该怎么写?
我的sql为什么不走索引?需要知道内部原理
where条件涉及多个字段多个索引时怎么走?
多表连接查询、子查询,怎么去利用索引,内部过程是什么样的?
like查询中前面有%的时候为何不走索引?
字段中使用函数的时候为什么不走索引?
字符串查询使用数字作为条件的时候为什么不走索引?、
索引区分度、索引覆盖、最左匹配、索引排序又是什么?原理是什么?
关于上面各种索引选择的问题,我们会深入其原理,让大家知道为什么是这样?而不是只去记一些优化规则,而不知道其原因,知道其原理用的时候更加得心应手一些。
Mysql系列目录
第1篇:mysql基础知识
第2篇:详解mysql数据类型(重点)
第3篇:管理员必备技能(必须掌握)
第4篇:DDL常见操作
第5篇:DML操作汇总(insert,update,delete)
第6篇:select查询基础篇
第7篇:玩转select条件查询,避免采坑
第8篇:详解排序和分页(order by & limit)
第9篇:分组查询详解(group by & having)
第10篇:常用的几十个函数详解
第11篇:深入了解连接查询及原理
第12篇:子查询
第13篇:细说NULL导致的神坑,让人防不胜防
第14篇:详解事务
第15篇:详解视图
第16篇:变量详解
第17篇:存储过程&自定义函数详解
第18篇:流程控制语句
第19篇:游标详解
第20篇:异常捕获及处理详解
第21篇:什么是索引?
第22篇:mysql索引原理详解
mysql系列大概有20多篇,喜欢的请关注一下,欢迎大家加我微信itsoku或者留言交流mysql相关技术!
路人甲java

▲长按图片识别二维码关注
路人甲java:工作10年的前阿里P7分享Java、算法、数据库方面的技术干货!坚信用技术改变命运,让家人过上更体面的生活!


