
- 1推荐一款强大的Swift网络编程库:SwiftSocket
- 2深入解析NLP情感分析技术:从篇章到属性_情感分析模型
- 3数据结构笔记3 队列(队列的顺序存储、链式存储)_队列顺序存储结构笔记
- 4mysql存储过程_10-18 查询图书表中售价介于50元到70元之间的图书的全部信息
- 5蓝桥杯单片机的几个模块
- 6springcloud 微服务 之 Eureka 配置_eureka配置3份yml怎么分别启动
- 7如何实现单点登录_从门户网站跳转到后台登录系统,单点登录‘
- 8VUE框架解析Vue3使用Proxy代理实现响应式的底层原理------VUE框架_vue3proxy使用的什么方法
- 9很多人在Google Play商店购买或下载APP时出现问题,例如在你新安装的系统恢复APP或想要安装心愿单中的APP时,Play商店出现不能加载等错误,这实在是太烦人了。 所以,我通过搜索,把可_gooleone备份无法加载
- 10注册中心--Eureka、Zookeeper、Nacos、Consul--选型/区别_java服务注册中心zookeeper,euraka,nacos
Python爬虫实战(3) | 爬取一周的天气预报信息_python爬取最高温和最低温
赞
踩
今天我们来爬取中国气象局官网的天气预报信息,我们不但要获取今天的天气信息,还要获取未来6天的天气预报信息
分析网页结构
我们在设计网络爬虫程序之前,首先要分析网页的代码结构
这里我放上官网地址:
http://www.weather.com.cn/
我们这次要获取的是北京市的天气预报信息

不同的城市他们的域名不一样(图中画圈地方),大家可以各自尝试一下
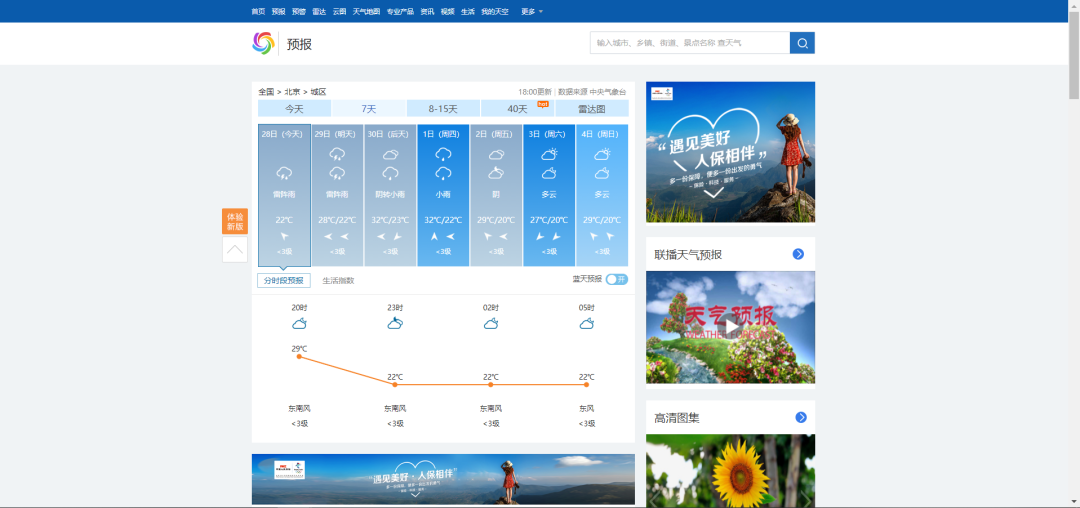
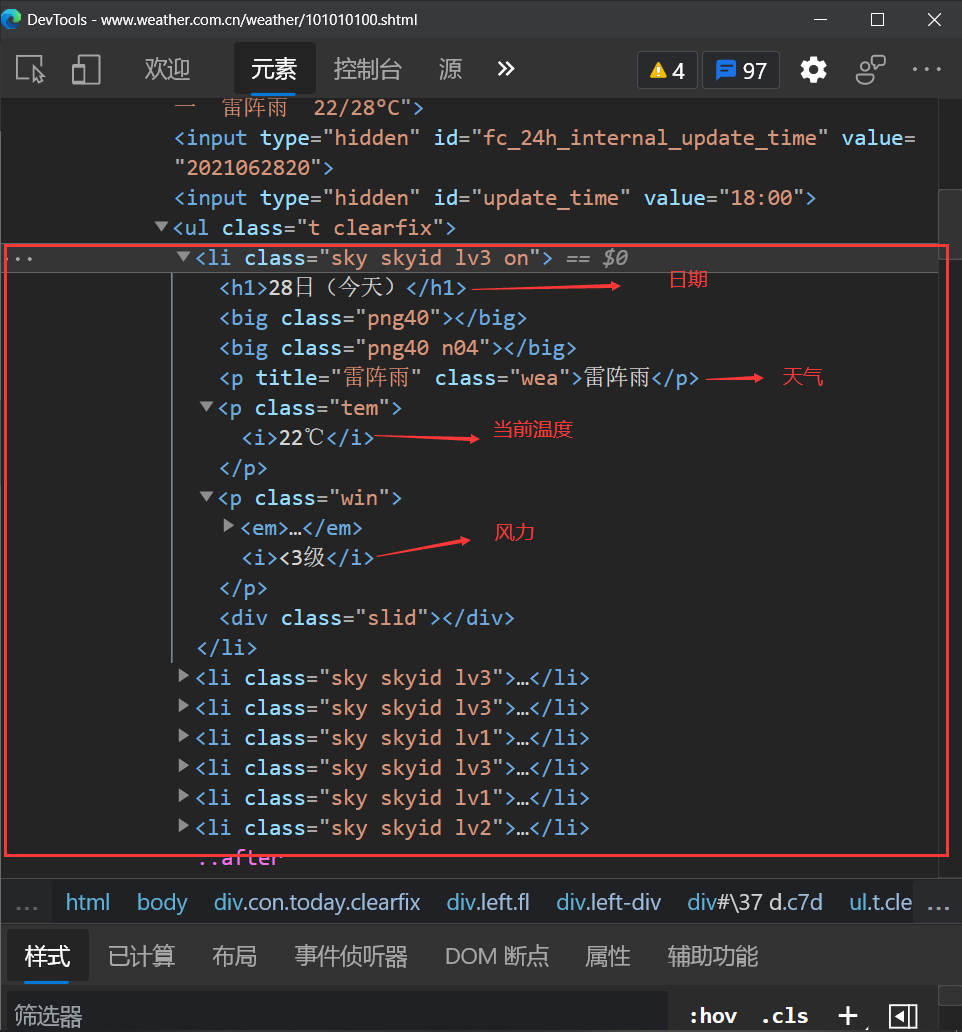
我们按 F12 进入网页代码查看器,当前页面的代码结构如下图
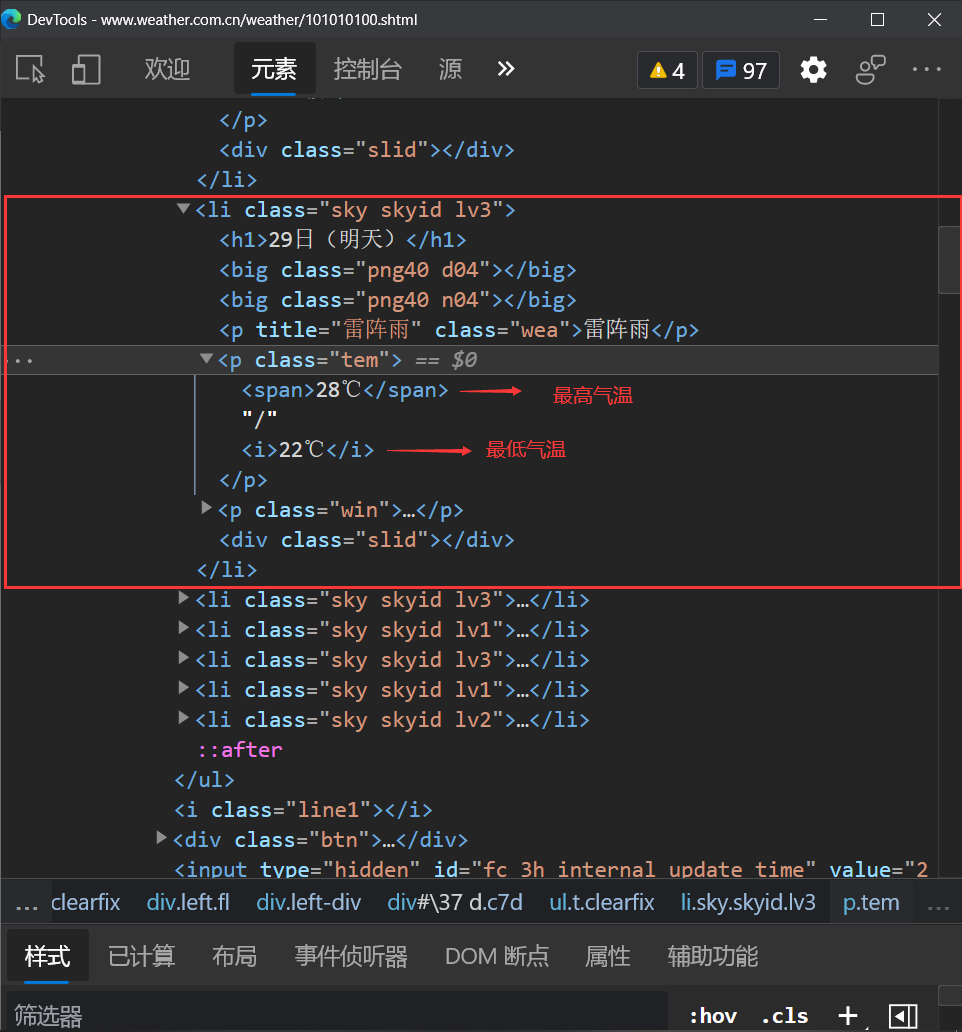
注意,除了今天,未来六天的天气预报中将气温分成了最高气温和最低气温两个
我们可以看到:
当天的天气预报信息存放在<p>标签中,当天的天气情况存放在<p>标签中,其中最高气温存放在<span>标签中,最低气温存放在<i>标签中
代码实现
既然知道了我们要获取的信息的所在标签中,那么就开始我们的爬取过程吧!
首先导入我们的库文件
import requests
import bs4
- 1
- 2
将当前网页下载下来
注意:因为网页中含有中文字符,所以我们在下载网页源码之前先看下它的编码格式,输入当前网页的编码格式 print(res.encoding)
可以看到是 ISO-8859-1 编码格式,所以我们将网页源码获取之后要对其进行编码 encode('ISO-8859-1')
def get_web(url):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59"}
res = requests.get(url, headers=header, timeout=5)
# print(res.encoding)
content = res.text.encode('ISO-8859-1')
return content
- 1
- 2
- 3
- 4
- 5
- 6
从网页源码中获取所需信息
将网页下载获取下来之后,我们使用 bs4 模块来进行解析并获取我们所需要的数据信息
soup = bs4.BeautifulSoup(content, 'lxml')
- 1
我们先来将日期获取下来,并存放到 list_weather 列表中
我们在for循环语句里面添加了一个条件判断语句是因为除了日期在
标签中,还有很多信息也存放在这个标签中。
但是日期是在前6行,所以在这里我们只需要获取前六行数据就行了
'''
存放日期
'''
list_day = []
i = 0
day_list = soup.find_all('h1')
for each in day_list:
if i <= 6:
list_day.append(each.text.strip())
i += 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
接着将天气情况(也就是阴、雷阵雨这种)获取下来,存放到 list_weather 列表中
'''
存放天气情况
'''
list_weather = []
weather_list = soup.find_all('p', class_='wea')
for i in weather_list:
list_weather.append(i.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
之后将气温也获取下来,存放在 list_tem 中
这里我们需要注意的是:
当天气温只有一个,而未来的天气有最高气温和最低气温

所以在这里我们需要将未来气温的数据(最高气温和最低气温)当成一个列表来存放进 list_tem 列表中
'''
存放温度:最高温度和最低温度
'''
tem_list = soup.find_all('p', class_='tem')
i = 0
list_tem = []
for each in tem_list:
if i == 0:
list_tem.append(each.i.text)
i += 1
elif i > 0:
list_tem.append([each.span.text, each.i.text])
i += 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
最后我们将风力数据获取下来,存放进 list_wind 列表中
'''
存放风力
'''
list_wind = []
wind_list = soup.find_all('p', class_='win')
for each in wind_list:
list_wind.append(each.i.text.strip())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
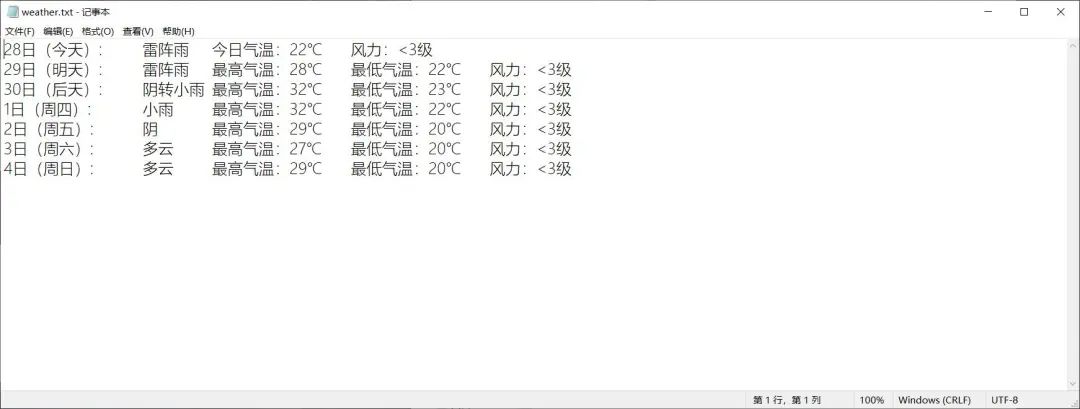
大致输出结果就是这个样子:

最后别忘了将上面的这些数据作为函数的返回值,传到我们的数据保存函数中
return list_day, list_weather, list_tem, list_wind
- 1
将数据保存到本地上
获取数据之后,我们需要将数据保存到本地上,这里我才用的是将记事本的形式,你们也可以保存到 excel 表上
注意:在for循环里面我添加了条件判断语句,就是因为在当天日期中的气温只有一个,而在未来的天气情况中气温却分为了最高气温和最低气温
所以条件判断语句的作用就是使得当天的气温只写进当天天气情况中,而未来几天的气温有最高和最低气温
item = 0
with open('weather.txt', 'a+', encoding='utf-8') as file:
for i in range(0, 7):
if item == 0:
file.write(day[i]+':\t')
file.write(weather[i]+'\t')
file.write("今日气温:"+tem[i]+'\t')
file.write("风力:"+wind[i]+'\t')
file.write('\n')
item += 1
elif item > 0:
file.write(day[i]+':\t')
file.write(weather[i] + '\t')
file.write("最高气温:"+tem[i][0]+'\t')
file.write("最低气温:"+tem[i][1] + '\t')
file.write("风力:"+wind[i]+'\t')
file.write('\n')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
最后来看一下我们的运行结果吧!
源代码
源代代码如下:
# -*- coding:utf-8 -*-
import requests
import bs4
def get_web(url):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59"}
res = requests.get(url, headers=header, timeout=5)
# print(res.encoding)
content = res.text.encode('ISO-8859-1')
return content
def parse_content(content):
soup = bs4.BeautifulSoup(content, 'lxml')
'''
存放天气情况
'''
list_weather = []
weather_list = soup.find_all('p', class_='wea')
for i in weather_list:
list_weather.append(i.text)
'''
存放日期
'''
list_day = []
i = 0
day_list = soup.find_all('h1')
for each in day_list:
if i <= 6:
list_day.append(each.text.strip())
i += 1
# print(list_day)
'''
存放温度:最高温度和最低温度
'''
tem_list = soup.find_all('p', class_='tem')
i = 0
list_tem = []
for each in tem_list:
if i == 0:
list_tem.append(each.i.text)
i += 1
elif i > 0:
list_tem.append([each.span.text, each.i.text])
i += 1
# print(list_tem)
'''
存放风力
'''
list_wind = []
wind_list = soup.find_all('p', class_='win')
for each in wind_list:
list_wind.append(each.i.text.strip())
# print(list_wind)
return list_day, list_weather, list_tem, list_wind
def get_content(url):
content = get_web(url)
day, weather, tem, wind = parse_content(content)
item = 0
with open('weather.txt', 'a+', encoding='utf-8') as file:
for i in range(0, 7):
if item == 0:
file.write(day[i]+':\t')
file.write(weather[i]+'\t')
file.write("今日气温:"+tem[i]+'\t')
file.write("风力:"+wind[i]+'\t')
file.write('\n')
item += 1
elif item > 0:
file.write(day[i]+':\t')
file.write(weather[i] + '\t')
file.write("最高气温:"+tem[i][0]+'\t')
file.write("最低气温:"+tem[i][1] + '\t')
file.write("风力:"+wind[i]+'\t')
file.write('\n')
if __name__ == "__main__":
url = "http://www.weather.com.cn/weather/101010100.shtml"
print("正在爬取数据...........................")
get_content(url)
print("爬取完毕!!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90

