
- 1yum升级gcc版本_yum 升级gcc
- 2《从0学MySQL》之最详细MySQL安装教程(Linux),2024年最新2024年你与字节跳动只差这份笔记_linux mysql安装教程
- 3K8S认证|CKA题库+答案| 14. 排查故障节点
- 4kafka 命令行 生产消费数据,查看偏移量,修改偏移量,修改数据保留时间_kafka修改偏移量
- 5python实现的基于蒙特卡洛树搜索(MCTS)与UCB的五子棋游戏_python梦塔卡洛树五子棋
- 6SQL server数据库的权限设置_sql数据库文件权限设置
- 7python 3.7 进行mnist高级训练_python3.7.5 跑深度学习
- 8基于YOLOv5的WiderFace人脸检测检测系统(PyTorch+Pyside6+YOLOv5模型)_yolov5人脸识别
- 9自动化测试常见的面试题(答案+文档)_自动化测试面试题
- 10CC攻击(N个免费代理形成的DDOS)_免费ddos平台攻击
如何使用ChatGPT的API(一)大语言模型如何工作_take the letters in lollipop and reverse them
赞
踩
这篇文章介绍大语言模型的一些概念,包括它是如何工作的,什么是Token等等。
大语言模型如何工作
我们从一个示例开始说起。
当我们写一个提示“我喜欢吃”,然后要求一个大型语言模型根据这个提示填写后面可能的内容。它可能会说,“带奶油奶酪的百吉饼,或者我妈妈做的菜”。
但是这个模型是如何学会做到这一点的呢?
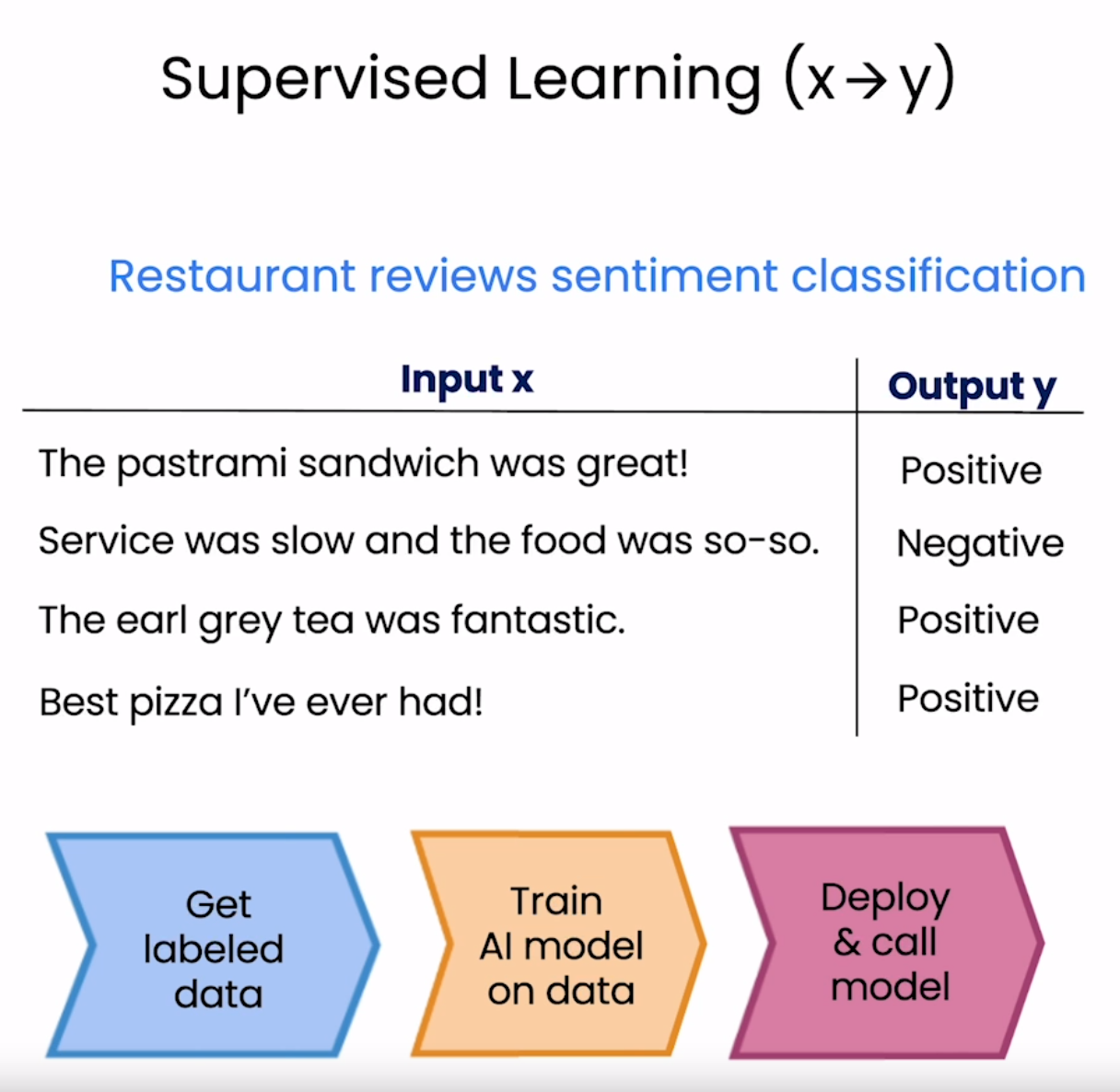
训练大型语言模型的主要工具实际上是监督学习。在监督学习中,计算机使用带标签的训练数据来学习输入-输出或X-Y的映射关系。例如,如果你正在使用监督学习来学习对餐厅评论进行情感分类,你可能会收集一个像这样的训练集,其中一条评论如“熏牛肉三明治很棒!”被标记为积极情感的评论,依此类推。而“服务很慢,食物一般般。”则被标记为消极情感,“伯爵红茶太棒了。”则被标记为积极情感。监督学习的过程通常是获取带标签的数据,然后在数据上训练AI模型。训练完成后,你可以部署和调用模型,并给它一个新的餐厅评论,比如“最好吃的披萨!”。然后它正确判定了这是积极情感。
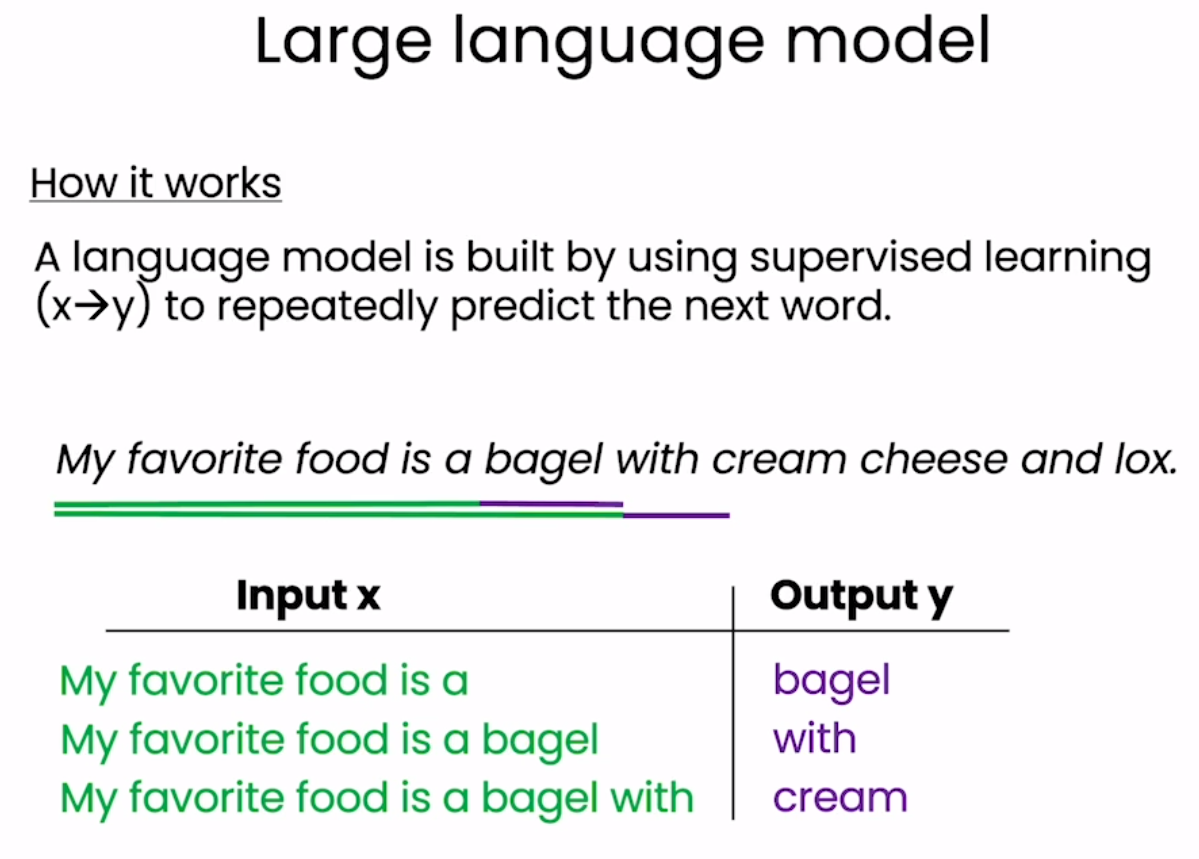
事实证明,监督学习是训练大型语言模型的核心构建模块。具体来说,可以通过使用监督学习来重复预测下一个单词来构建大型语言模型。假设在训练集中有大量的文本数据,有一句话是“My favorite food is a bagel with cream cheese and lox.”。然后,这句话被转化为一系列的训练示例。这时给定一个句子片段,“My favorite food is a”,则下一个预测出来的单词就是“bagel”。然后当给定句子片段或句子前缀,“My favorite food is a bagel”,下一个预测的单词将是“with”,依此类推。 在拥有数百亿甚至更多单词的大型训练集的情况下,你可以创建一个庞大的训练集,从一个句子或一段文本的一部分开始,反复要求语言模型学习预测下一个单词。

所以今天有两种主要类型的大型语言模型。第一种是“基础LLM”,第二种是越来越多使用的“指令调整LLM”。
基础LLM根据文本训练数据反复预测下一个单词。所以如果我给它一个提示,“从前有一只独角兽”,然后通过反复一次预测一个单词,它可能会给出一个关于一只独角兽在一个神奇森林中与她的独角兽朋友们一起生活的故事。
然而,这种方法的一个缺点是,如果你用“What is the capital of France?”这样的提示,很可能在互联网上有一个关于法国的问答题目列表。所以它可能会用“What is France’s largest city? what is France’s population?”等来完成这个提示。 但是你真正想要的是它告诉你法国的首都,而不是列出所有这些问题。
但指令调整LLM尝试遵循指令,它会说,“法国的首都是巴黎。”

如何从基础LLM转变为指令调整LLM?
这就是训练指令调整LLM(如ChatGPT)的过程。 首先,你需要在大量数据上训练一个基础LLM,可能是数百亿个单词,甚至更多。这个过程可能需要数月时间在一个大型超级计算系统上进行。 在训练完基础LLM之后,你可以通过在一个较小的示例集上对模型进行微调来进一步训练模型,使其按照输入的指令输出结果。例如,你可以编写很多关于指令的示例和对应的良好回答。这样就创建了一个训练集来进行额外的微调,使其学会在遵循指令时预测下一个单词。之后,为了提高LLM输出的质量,一个常见的过程是获取人类对许多不同LLM输出质量的评价,比如输出是否有帮助、诚实和无害等标准。然后,你可以进一步调整LLM,增加其生成更高评级输出的概率。而最常用的技术是RLHF(Reinforcement Learning from Human Feedback,从人类反馈中进行强化学习)。从基础LLM到指令调整LLM的过程可能只需要几天时间,并且使用更小规模的数据集和计算资源。
什么是Token
ChatGPT处理不了反转单词的任务。
response = get_completion("Take the letters in lollipop and reverse them") #这里希望chatgpt反转输出单词lollipop
print(response)
- 1
- 2
回答:
The reversed letters of "lollipop" are "pillipol".
- 1
很明显pillipol并不是正确答案。正确答案应该是popillol。
为什么ChatGPT这么牛逼却处理不了这样一个简单的问题呢?
这就要引入Token的概念了。简单来说,ChatGPT处理信息(也就是我们输入的prompt)不是按照一个单词一个单词处理的。这点和人处理文字信息非常不同。人是一个单词一个单词,一个汉字一个汉字来理解文字信息和处理文字信息的。而ChatGPT是按Token来处理信息的。一个稍长的英文单词可能被分成多个Token。

上图的例子中,prompting被分成了三个Token。

而lollipop则被分成了上图所示的三部分。看到这里,就知道ChatGPT的处理文字的方式决定了它无法完成反转单词的任务。
response = get_completion("""Take the letters in \
l-o-l-l-i-p-o-p and reverse them""")
- 1
- 2
回答:
p-o-p-i-l-l-o-l
- 1
上面的测试代码用-将字母隔开,以便划分Token时让每个字母作为一个Token。
这时ChatGPT回答的就是正确的了。
通常情况下,一个Token包含大概4个字母或者一个单词的4分之3。
这里其实有一个技术细节,就是ChatGPT预测后面的内容时是通过预测下一个Token来的。这也是为什么OpenAI的API调用是按照Token来计费的。也就是处理一个Token收一个Token的钱。注意,算钱是是把输入和输出的Token都算钱的。
OpenAI的网站上提到“Only pay for what you use.”。看来也挺切合的。

这是最常用的gpt-3.5-turbo模型的价格。
同时,不同的模型单次处理的Token数(输入的Token+输出的Token之和)是有上限的。比如gpt-3.5-turbo模型单次处理Token的上限是4000个Token。
另外python中有个tokenizer 包是可以计算一句话的Token数的。下面的代码演示了这个包的用法。
def get_completion_and_token_count(messages, model="gpt-3.5-turbo", temperature=0, max_tokens=500): response = openai.ChatCompletion.create( model=model, messages=messages, temperature=temperature, max_tokens=max_tokens, ) content = response.choices[0].message["content"] token_dict = { 'prompt_tokens':response['usage']['prompt_tokens'], 'completion_tokens':response['usage']['completion_tokens'], 'total_tokens':response['usage']['total_tokens'], } return content, token_dict

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
messages = [
{'role':'system',
'content':"""You are an assistant who responds\
in the style of Dr Seuss."""},
{'role':'user',
'content':"""write me a very short poem \
about a happy carrot"""},
]
response, token_dict = get_completion_and_token_count(messages)
print(response)
print(token_dict)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Oh, the happy carrot, so bright and orange, Grown in the garden, a joyful forage. With a smile so wide, from top to bottom, It brings happiness, oh how it blossoms! In the soil it grew, with love and care, Nurtured by sunshine, fresh air to share. Its leaves so green, reaching up so high, A happy carrot, oh my, oh my! With a crunch and a munch, it's oh so tasty, Filled with vitamins, oh so hasty. A healthy snack, a delight to eat, The happy carrot, oh so sweet! So let's celebrate this veggie delight, With every bite, a happy sight. For the happy carrot, we give a cheer, A joyful veggie, oh so dear! {'prompt_tokens': 37, 'completion_tokens': 160, 'total_tokens': 197}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
角色定义
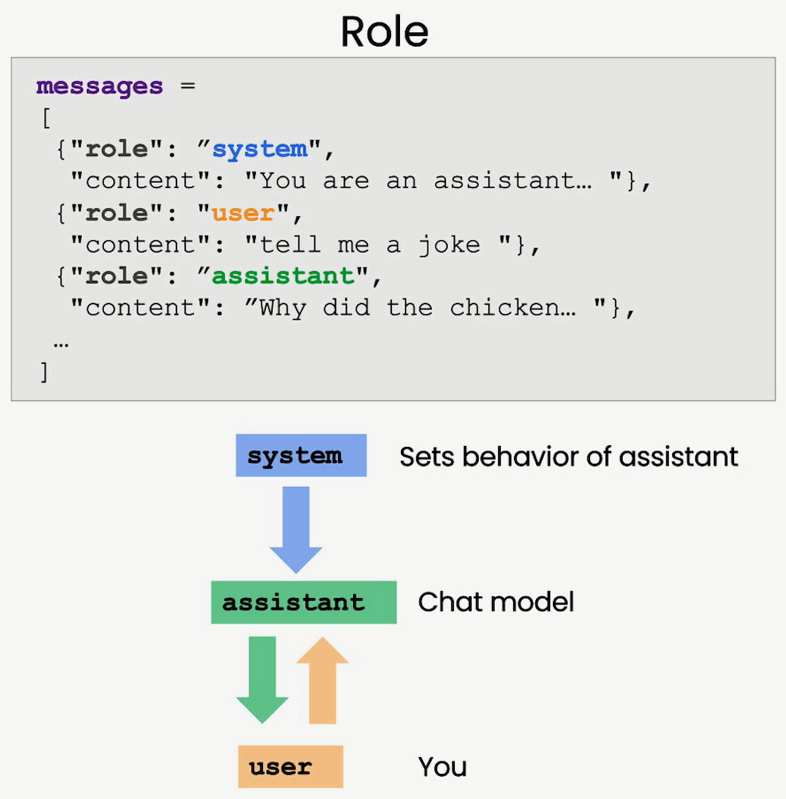
下面是一个消息列表的例子,首先是一个系统消息,它提供了整体指示。在这条消息之后,我们有用户和助手之间的多轮对话,这个对话会一直进行下去。如果你曾经使用过ChatGPT的网页界面,那么你的消息就是用户消息,ChatGPT的消息就是助手消息。系统消息有助于设定助手的行为和个性,并且它在对话中充当高级指令。你可以将其视为在助手耳边私下交流并引导其回复,而用户并不知道系统消息的存在。作为用户,如果你曾经使用过ChatGPT,你可能不知道ChatGPT的系统消息内容。系统消息的好处在于,它为开发者提供了一种在对话中框定对话范围的方式,而不用让这些框定的话语成为对话的一部分。这样,你可以引导助手,私下指导其回复,而不让用户察觉。
messages = [
{'role':'system', 'content':'You are an assistant that speaks like Shakespeare.'},
{'role':'user', 'content':'tell me a joke'},
{'role':'assistant', 'content':'Why did the chicken cross the road'},
{'role':'user', 'content':'I don\'t know'} ]
response = get_completion_from_messages(messages, temperature=1)
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
回答:
#response.choices[0].message 中的完整内容
{
"content": "To get to the other side, my good sir!",
"role": "assistant"
}
To get to the other side, my good sir!
- 1
- 2
- 3
- 4
- 5
- 6
- 7
如何更安全地加载OpenAI的key
OpenAI的key是调用OpenAI接口的唯一凭证。泄漏了可能会造成不小的金钱损失,所以要妥善保管。
下图演示了两种加载OpenAI的key的方式。
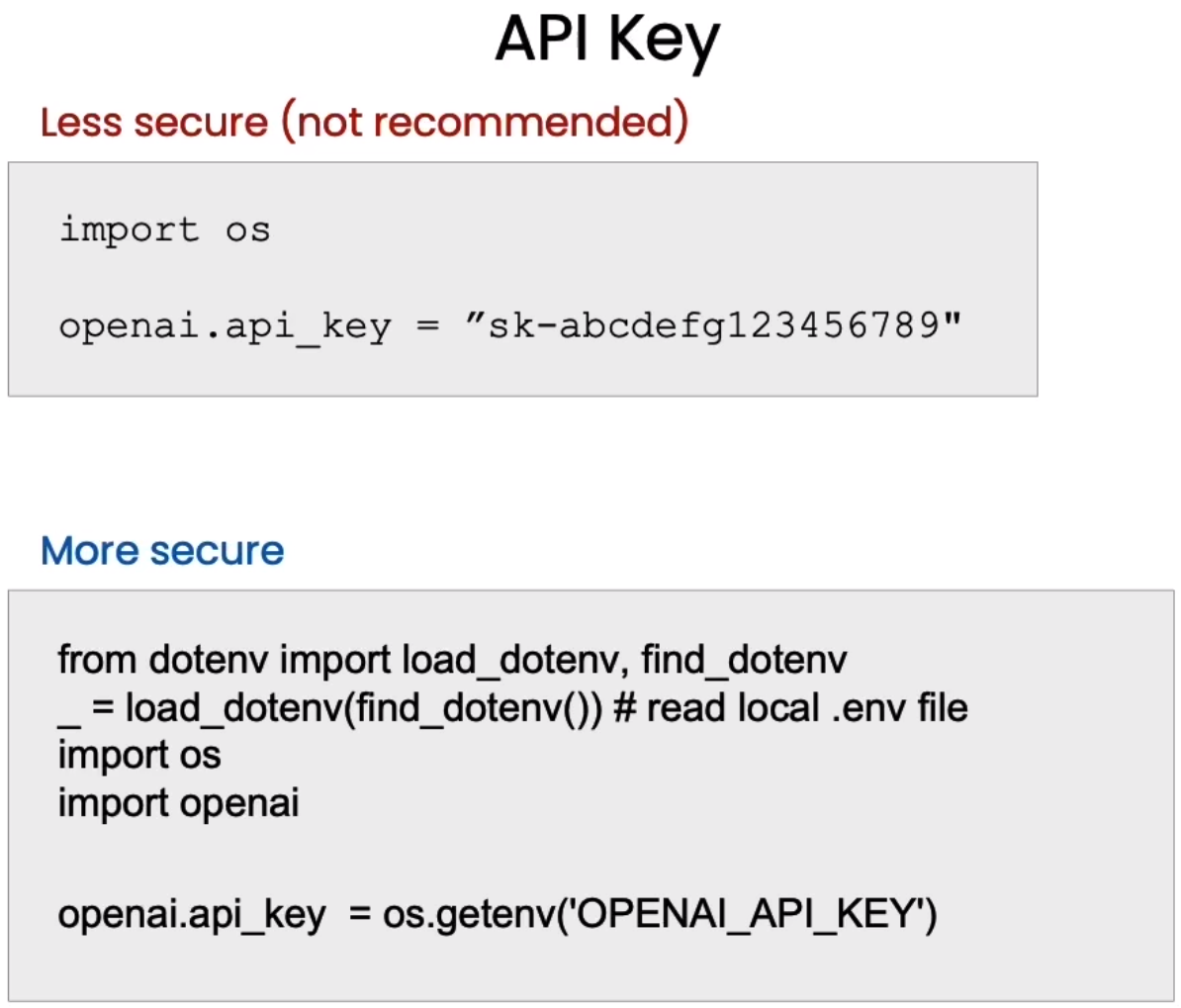
下面这种方式明显是更安全的。OpenAI的key不会暴露在代码中,而是由一个单独的.env文件来维护。
注意,安装dotenv包需要用下面的命令来安装。
pip install python-dotenv
- 1
加载key的代码
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
- 1
- 2
- 3
- 4
.env文件中的内容
OPENAI_API_KEY="sk-xxx"
- 1
如今开发AI应用程序的现状
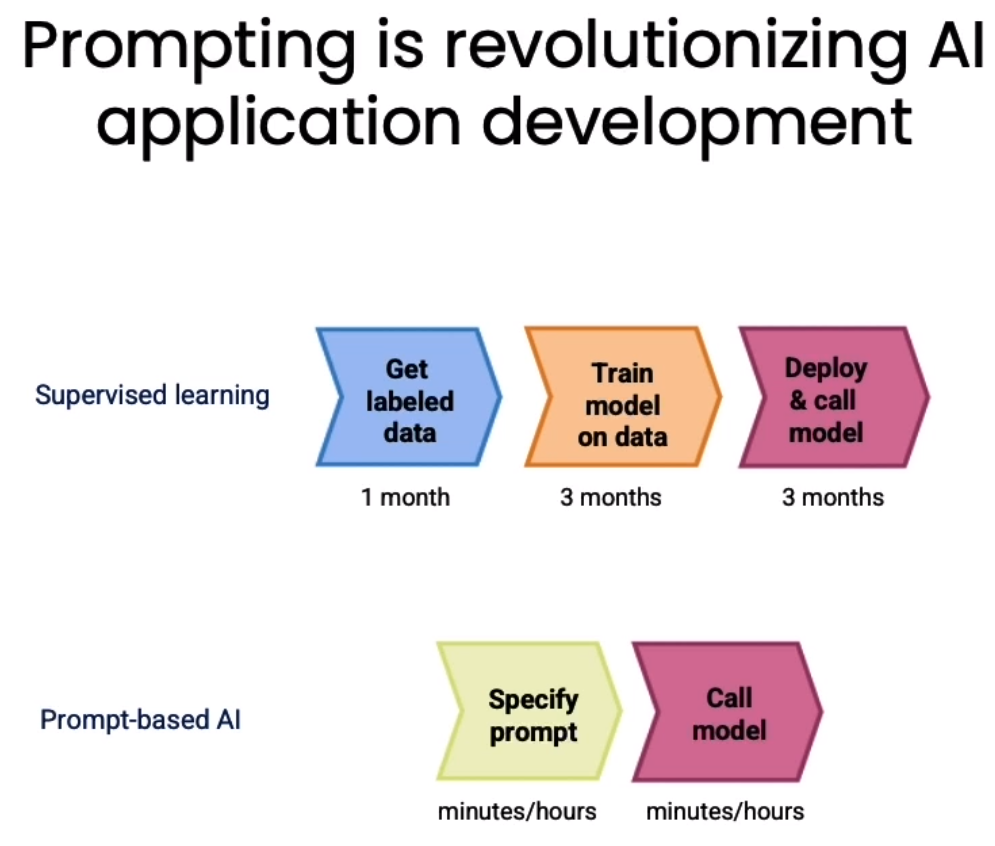
过去开发AI应用,首先要收集数据,标注数据,训练模型,最后再部署模型来使用。耗时长,需要掌握的知识和技能比较多,门槛高。
现在开发AI应用只需要会写Prompt和基础的编程能力就可以了。
时代在进步,咱得跟上。
参考:
文章中不好放全部的示例代码,我的公众号《首飞》内回复 “api” 关键字可获取本篇文章完整的示例代码(格式为ipynb)。
觉得有用就点个赞吧!
我是首飞,一个帮大家填坑的工程师。

