- 1 高并发架构系列:Kafka、RocketMQ、RabbitMQ的优劣势比较 ...
- 2车载以太网自动化测试套件(SOME/IP)- AETP. TC8 SOME/IP
- 3深度学习-大模型LLM-微调经验分享&总结_大模型llm同时做实体和关系抽取
- 4实时数仓-Flink使用总结_flink实时开发平台
- 5【3DGS】从新视角合成到3D Gaussian Splatting_σ′ = jwσw j
- 6PostgreSQL索引(一)_pgsql 索引
- 7IDEA 连接mysql_driver class 'com.mysql.cj.jdbc.driver' not found
- 8嵌入式之Qt开发_qt嵌入式开发
- 9androidstudio旧版本下载_android studio 旧版本下载
- 10AI大模型探索之路-训练篇21:Llama2微调实战-LoRA技术微调步骤详解
【小贝出品】定制你的对话机器人 - 基于RASA搭建_languagemodelfeaturizer
赞
踩

【小贝出品】定制你的对话机器人 - 基于RASA搭建
源代码 Hands on Setting Up Develop Environment
Open Custom Connector More Concept 工程上的处理
-
Tracker Store
-
Event Broker
-
Model Storage
-
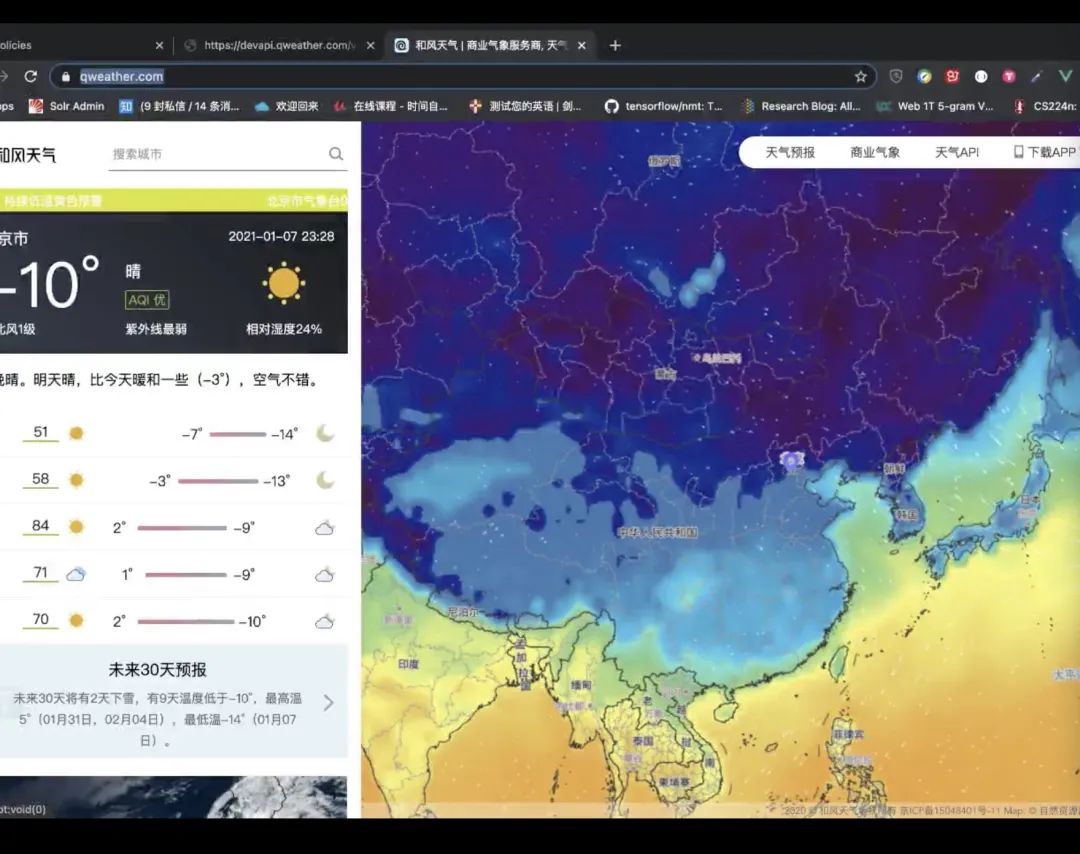
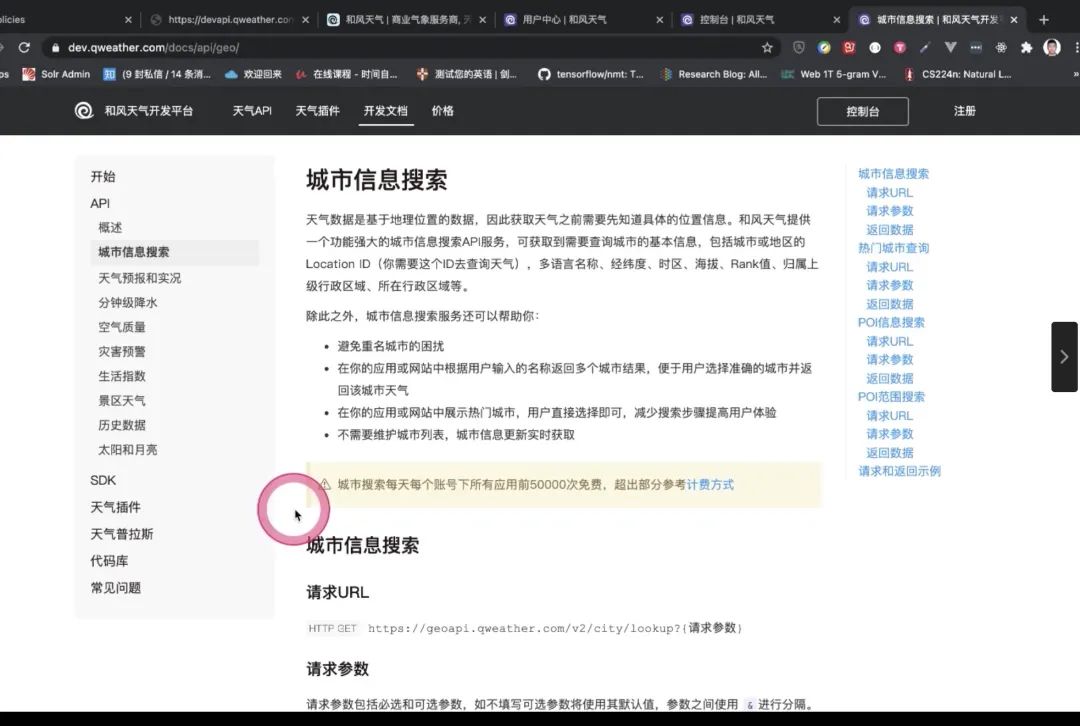
Chitchat and FAQs Asignment 自己的机器人,并且使用active serve去实现对话机器人天气查询功能
RASA
-
What's the weather like tomorrow
-
nlu- DM对话管理(RASA中叫core)拿出来是action-送到NLG(生成对话语言)
-
intent(weather query)
-
entity (tomorrow)实体,与slot区别
变成slot存储到对话机器人当中,slot和entity内容是一样的,slot是一个记忆,保存到记忆当中
core模块,RASA中是用story描述的对话流程,一个intent,对话机器人做什么样的action
两种情况让有slot:
-
从用户说的话当中识别实体
-
作为程序员在代码中注入进去
Setting up Rasa Source Code
Rasa代码写的非常好,不仅是对话机器人;很多工程上的,比如如何写代码,如何写规范的代码;都很值得学习 工程师的艺术感,工匠精神:不仅仅实现功能,同样让代码具有美感;自己写起来也会非常享受,不是搬砖拼凑起来实现功能,而是设计艺术品,值得品鉴的东西。所以学习Rasa工程上的知识
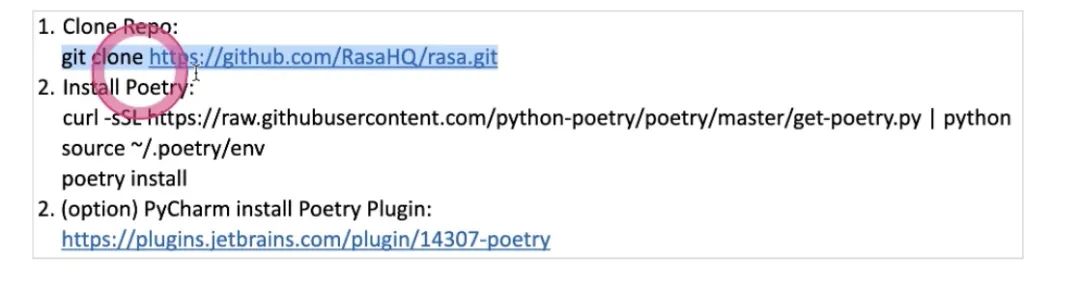
用poetry做包管理,可以把项目需要哪些包,这样的文件记录好,是更先进的包管理工具
-
把包下载之后,
python get-poetry.py -
pycharm提供了类似anaconda的工具,可以去管理poetry去管理环境;但不是官方默认,需要安装第三方插件 poetry.lock记录了其依赖的包
-
poetry install 会自动把其以来的包全都安装好;不像用pip和anaconda是基于pip和anaconda版本来判断;而poetry完全是一致的,类似于yarn和npm;不会出现版本冲突的问题;这也是为什么Rasa选用它做管理。会自动检测到当前项目下面需要的第三方包,并自动升级和补充缺少的包。出现网络问题:科学上网或多上几次
-
你可以贡献给Rasa也可以贡献给xbot,xbot也是用poetry做包管理
-
poetry和pip不一样的是,它添加包的时候不是install 而是add
poetry add fastweb -
poetry和anaconda不冲突,是类似的东西,区别就在于管理机制不太一样
每个环境都隔离的,A环境安装的包,B环境也没有,(anaconda虚拟环境里的包,在pycharm里面配置,显示不出来)anaconda和poetry都是这样。区别在于anaconda会依赖于一系列其他的包,会有内部版本的机制,选择哪个版本去安装;而poetry完全按照用户怎么去定义
Optimize NLU
-
每一个管道都串起来、连起来;串行的、管道式的;
-
用户的一段话- componentA第一个组件- ComponentB- ComponentC;将来可以自己开发自定义的component
-
整个过程是为了寻找到intent和entity
-
-
让对话机器人理解能力先提升,理解的程度在于识别intent更准确,识别entity也更准确
-
NLU的过程其实是通过pipeline机制去做的,pipeline机制会有很多类的名字,这些类的名字是怎么回事呢?
我感觉rasa训练很快,其实Rasa用了预训练模型 接口类:
-
在定义pipeline时结构就是串行结构
-
在pipeline又封装了几种概念,用哪些种方法去做事情。因为分的很细,能看字面意思(比如Tokenizer),把nlp里常规操作流程通过pipeline形式定义了出来
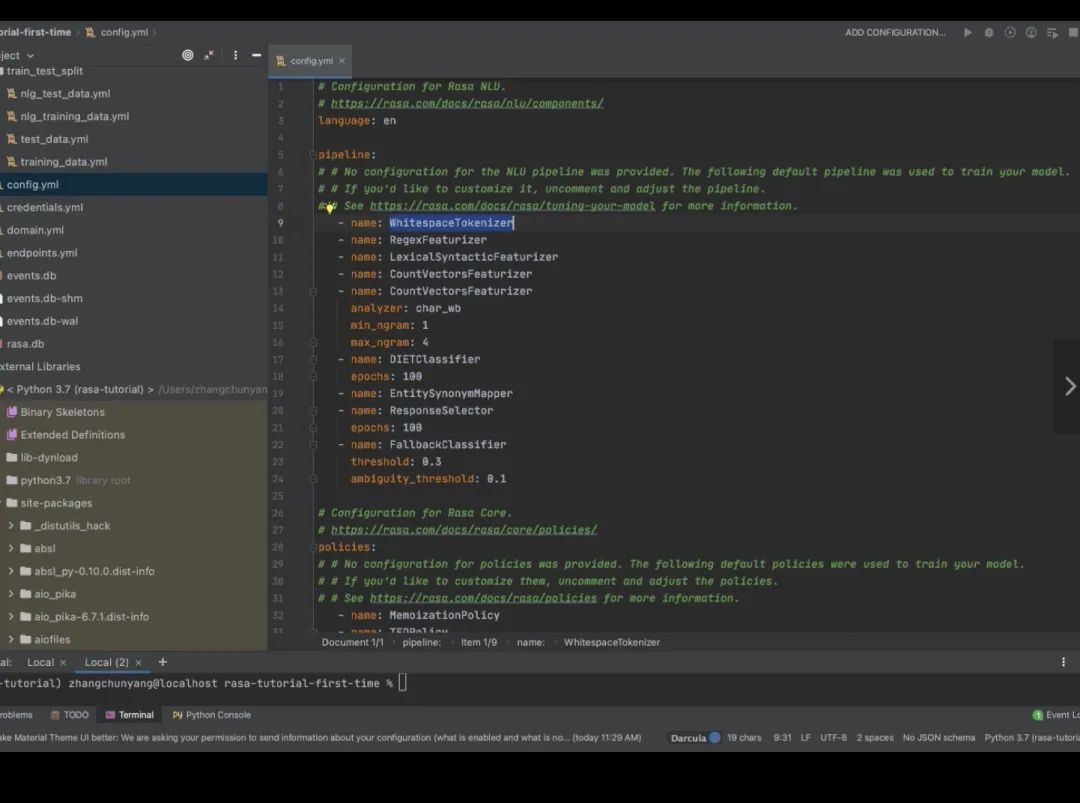
分词:WhitespaceTokenizer 用空格符做分词(对中文来讲没有任何用处;中文- JiebaTokenizer,供中国用户使用nlu功能)
-
MitieTokenizer 常用的包,提供了一些分词、实体抽取、文本分类的方法,更多的使用于英文场景
-
SpacyTokenizer,也是非常好用的nlp库,但是官方不支持中文、 去找,用它的方式去加载,可以指定一个模型,把那个模型加载尽量;使用Rasa时用jieba做分词
对话机器人涵盖了nlp所有东西目前中文分词工具最好的:hanlp,也是xbot里使用的工具
featurizer 把中文转换成embedding的形式
-
SpacyFeaturizer
-
ConveRTFeaturizer被废弃
-
LanguageModelFeaturizer语言模型当成模型的一个feature;如果能找到中文LanguageModel,pre-train的模型(如bert,支持bert
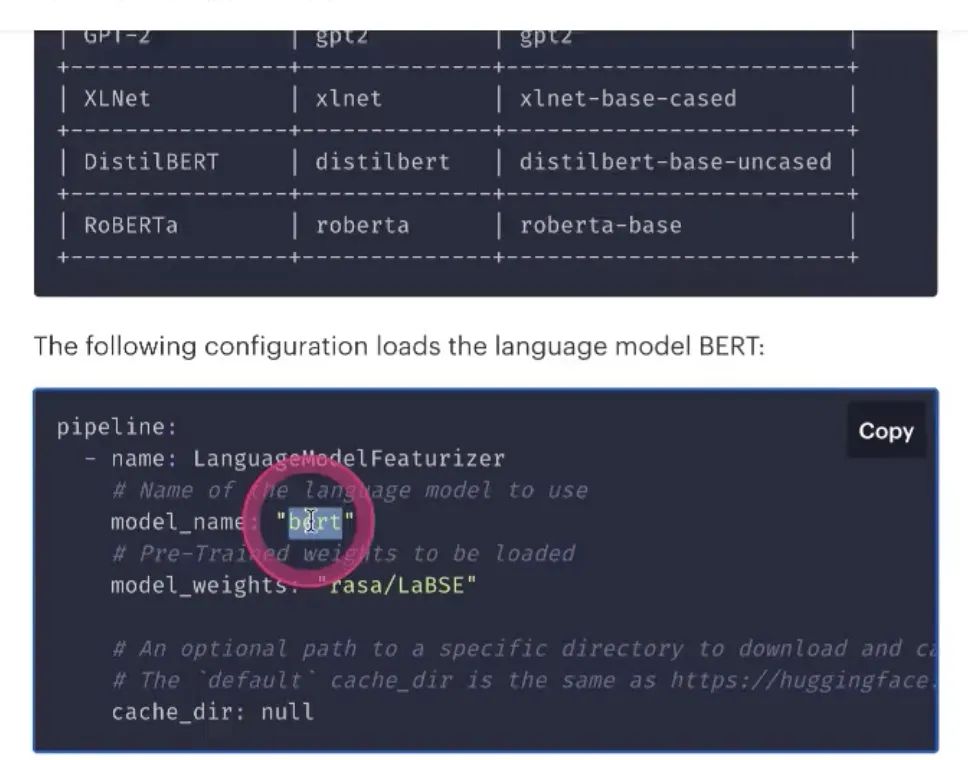

),是可以的
-
RegexFeaturizer 定义一句话,会用正则去描述这句话,把正则当成feature,试图学习到语言的信息;只对英文又好的作用,对中文反而把nlu搞得很惨,反而识别不到
-
CountVectorsFeaturizer n-gram 不能配置
-
LexicalSyntacticFeaturizer 把语法信息加进去,能否得到比较好的分类;英文友好,中文不友好 能用的可能就俩
Improve NLU- Pipeline Approach
一)Intent Classifiers 意图分类;也提供了一些可选择的组件 通常的选择:
-
MitintentClassifier 不推荐,麻烦
-
SklearnIntetnClassifier 适用于数据量小,优点就是速度快,需要的数据不多
-
KeywordIntentClassifier 关键字,去对应到意图上,回到传统时代,通过规则识别到某些关键字,用处不太大
-
DIETClassifier Rasa默认到Classifier,使用dual intent entity transformer;讲到模块,每一个模块,会结合rasa每一个模块去讲;推荐!后面讲nlu模块会详细讲解
FallbackClassifier
一方面识别到,另一方面没识别到,不在intent范围内,主要帮我们解决,如果只写了很多意图,但是用户说的话确实不在intent里面,对用户不友好,fallbackClassifier先识别一下意图是否在定义的意图空间里面,在的话再用别的classifier;不在的话就告诉不支持:作为异常情况引导的分类
Q:这些classifier是模型吗?
- 对,就是一些深度学习的模型
Q:Fallbackclassfier是与其他分类方法独立的还是包含的?
是先要用fallback然后再用其他分类方法DIETclassfier-先做是否在意图空间内,
通常放在前面一些,先做fallback识别,再做其他识别
Rasa自己不做训练,都是用开源模型 end2end:问题--空间太大,完全基于语料做生成,不可控;因为对话机器人要跟用户接触,不可控,所以工业界不用,在研究领域比较热,最后一节课会讲一讲end2end模型
二)实体识别
-
……
-
SpacyEntityExtracter
-
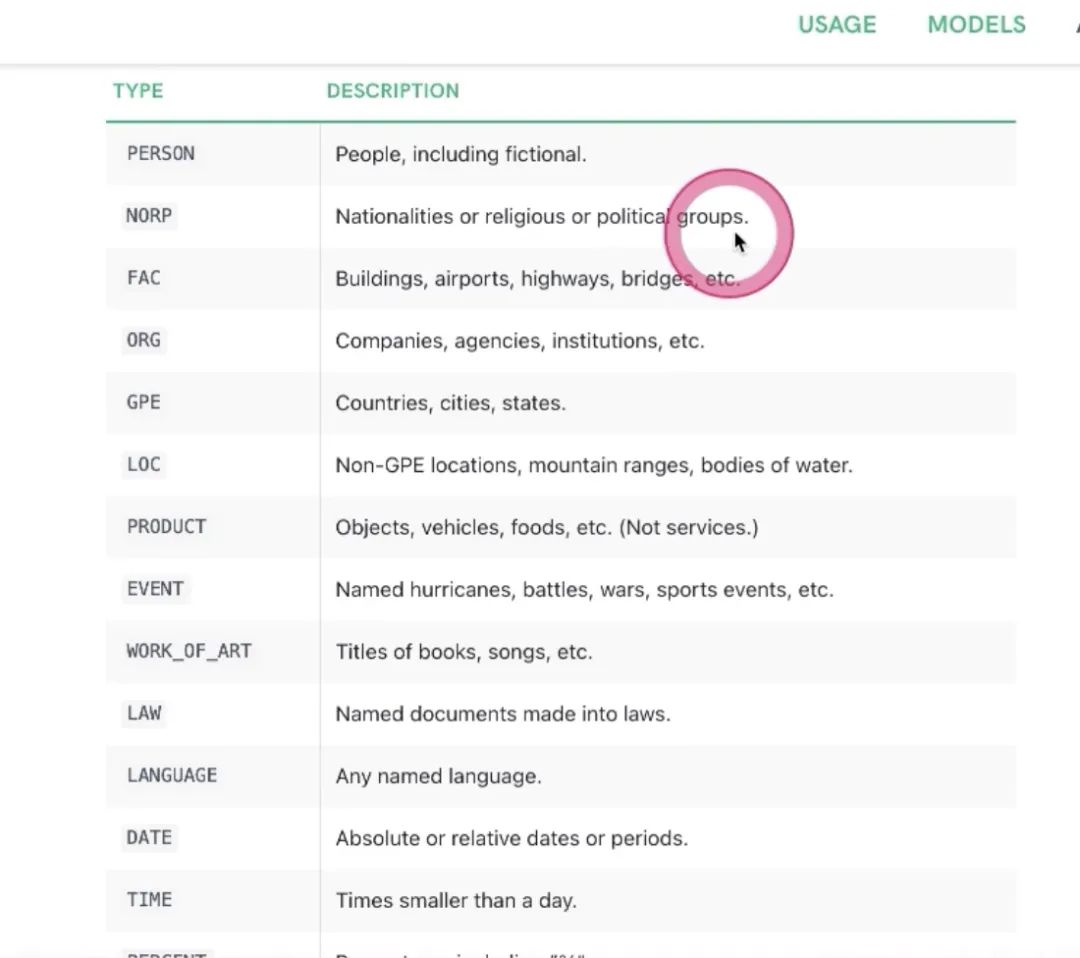
-
有人名、国家名、建筑名……看需要识别哪些实体,写到里面去,如果不写的话,默认全部都识别;但是全部都识别,会导致模型相对慢一些;如果能定义好自己的空间,模型相对快一些。不支持中文
-
CRFEntityExtractor
-
DucklingTHTTExtractor
-
DIETClassifier 不仅仅把分类做完,同时把实体识别也做出来,联合joint,这种模型任务更难,准确率更精准 Combined Intent Classifier 既能得到entity也能得到intent。支持中文以上是nlu的一些组件,components;通过pipeline把它们串起来,更好地
Choosing the Right components 怎么选择正确的组件(best practice) 对于中文的用户,可选择不多 对于英文用户,优先选择spaceTokenizer
选择feature主要方式是看数据量
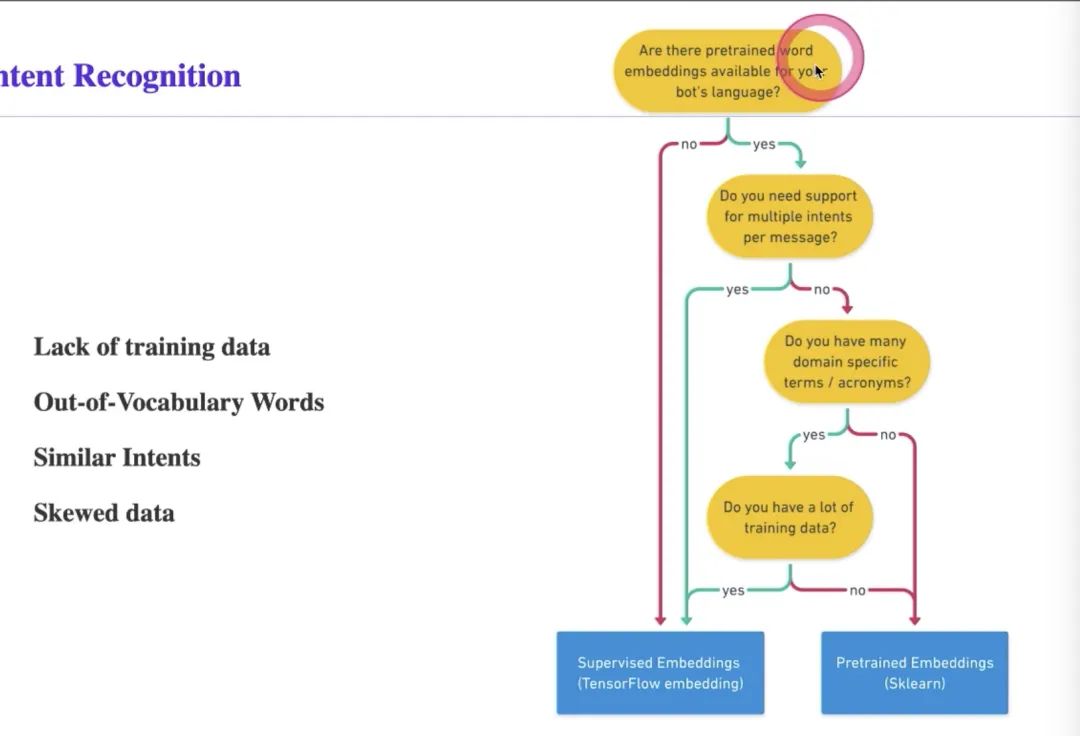
此图帮助选components组件:
1)先看是否有pre-train模型
2)对应language model
3)一句话是否有两个意图的情况;
4)如果没有,有没有专业领域的词,domain specific terms 专业词,pre-train的模型 embedding并没有做很好,很多这样的专业名词,
5)有没有很多这样的数据,有没有用深度学习的方式去做,如果没有那么多数据去训练专业名词,则用sklearn
Intent Recognition常见问题 :
1) lack of training data
2) out-of-vocabulary words 并没有见过用户所说的词(生词),第一种方法是增加语料,使语言模型泛化能力更强;第二是使用embedding/pre-train的模型,已经学习到语言里面的特性,有相对好的泛化能力,大量减少oov现象
3)similar Intents 定义意图意思太相近,导致分类的不准确,碰到这样的情况,首先看能不能把这两种分类做合并,成一个意图,看看能否在实体部分做区分;在设计意图的时候去考虑 4)skewed data 容易出现数据不均衡;模型偏向于语料比较多的意图;不要出现语料不均的问题
Q:多少语料算多,多少算少。
--比如先十条,baseline,看是否能达到要求,比如都能达到80%以上,可以先分享出去,给到测试人员,让测试人员做测评工作;不停迭代,同时收集很多很多语料,语料越来越多。然后上线去做,线上又收集到很多数据,再去做,不停迭代
Q:rasa如何使用?
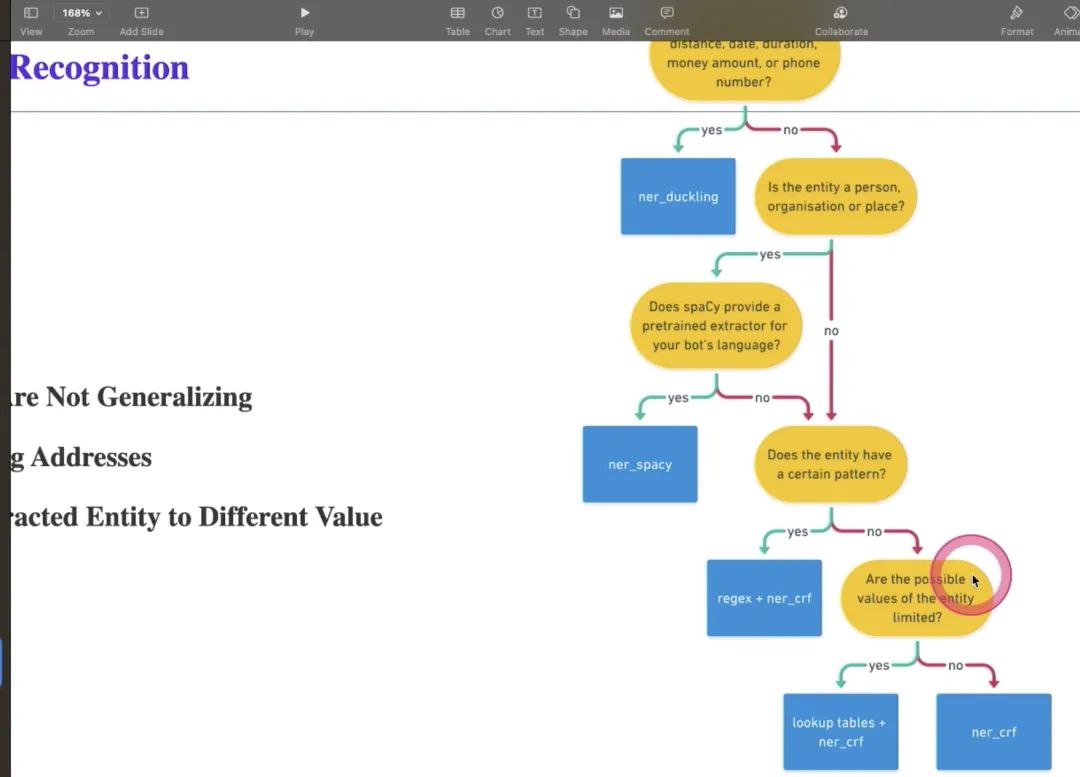
看entity实体是否是有限的集合,如果是有限的集合,使用lookup table,是有限的空间内,是枚举型的,如果没有这些则用NER/CIF, 帮我们做意图的分类和抽取
Q:数据不均衡要做不均衡学习吧,数据增强的一些方法,Smote ADASYN之类的
A:数据增强肯定是解决数据不均衡的方法;但是在对话里做数据增强是比较难的-- 超纲,后面讲,先按Rasa讲
Custom Components自己去写
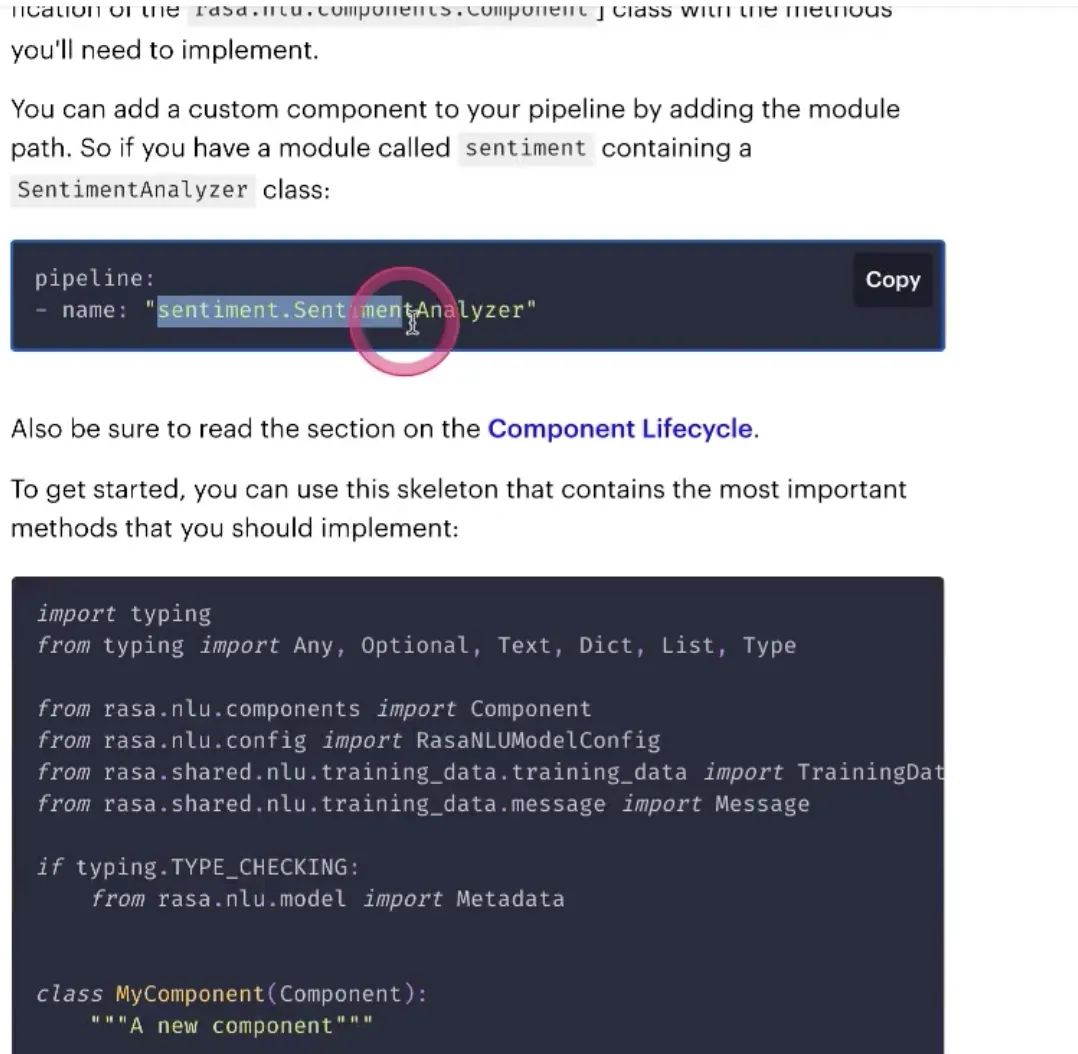
需要把模块名加到pipeline里,类路径的名字,去写component
再查再问 怎么做inference,分类entities,转换成rasa期待的一种格式;还有persist怎么存储训练好的格式,save成各种各样的文件,如何save如何做持久化;load如何加载,按照tensorflow和按照??存的load方法完全不一样
Q:自己写component有例子吗?
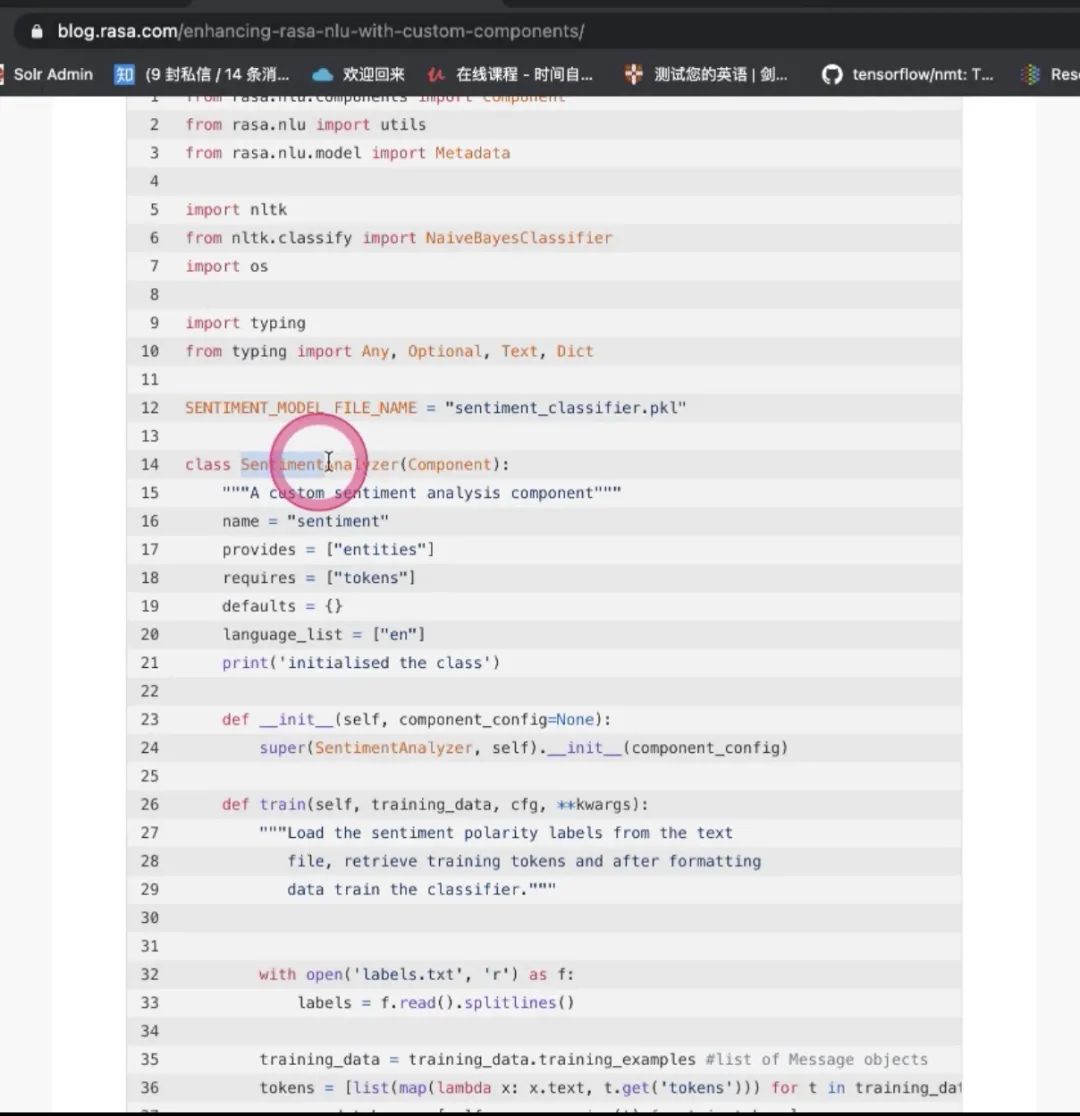
-
实现的是情感分析的component,依赖于entity,language_list
-
train如何train,用了nltk(微软的库)做朴素贝叶斯训练
-
然后process怎么做推理工作,预测的过程
-
得到的结果,之后做convert to rasa,支持json格式,输出给到下一个component,就是通过这样的标准格式一步一步去传递
-
json_pickle去做持久化,有了持久化之后怎么做load,用反序列化加载出来,读到模型里面去
以上一系列过程都是怎么去优化NLU
Expand your NLU Data
一)更好的模型
二) 更多的数据:https://rasa.com/docs/rasa/generating-nlu-data
三)Share your Bot to More people把你的对话机器人分享给更多的人
四)NLU Data Augmentation 数据增强,可以做nlu的data augmentation
五)Reinforce Learning 可以生成一些数据,从而帮我们产生更多的数据
怎么把数据分成训练集和测试集,按照20%和80%比例分成训练集和测试集rasa data split nlurasa versiontrain_test_split 就是80% 20%分开,用test数据集做测试 在调nlu过程中有一个命令很重要:
rasa shell nlu
-
使得我们可以单独测试nlu模型性能是否ok,能否按照我们想要的把用户意图和实体都抽取出来
-
字典就是component返回的字典
-
把“你好”分类的类别,分类到great,每一个分类置信度
-
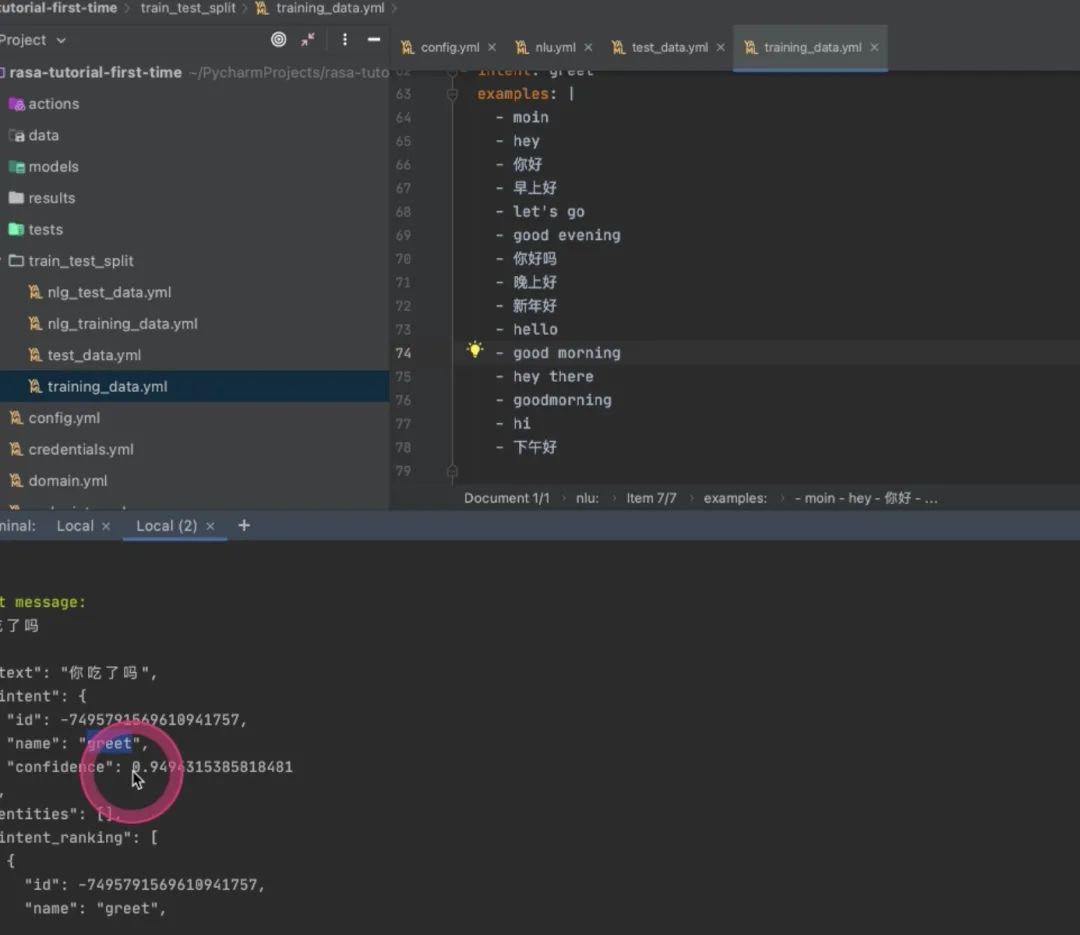
可以不停地测,比如输入“你好吗”,这个是greet;
-
“你吃了吗”,在train里没有但是仍然得到90%+置信度的greet还是很不错的
-
“台北的天气好吗”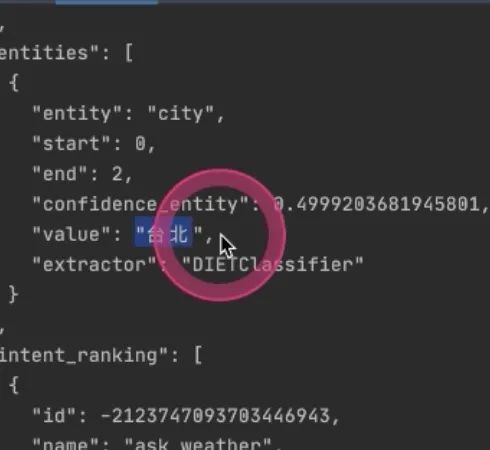
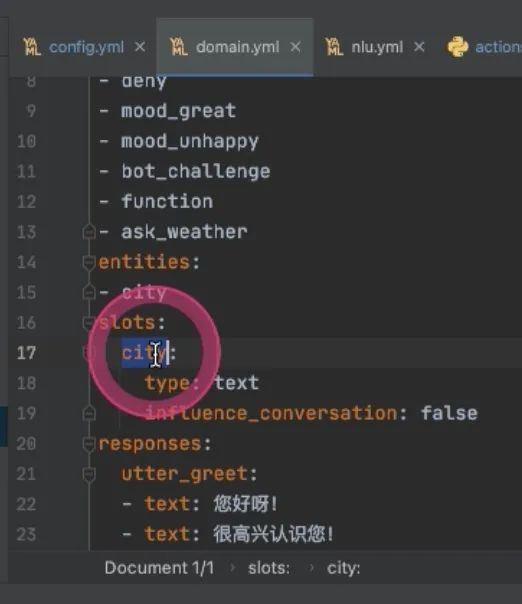
entity也出来了 怎么变成slot?此时需要在domain里面,在slot下面写上entity的名字,influence_conversation是否影响对话:通常不影响False,后续在slot里面就能拿
policy模块所做的事情?写比较多,会比较慢,是并行的,不是串行的,选择置信度最高的结果作为下一个action 当所有policy都预测到同一个confidence,priority优先级是在源码里定义的,先执行rulePolicy再执行……最后TEDPolicy,是深度学习带记忆的policy
DM模块会讲具体的算法,是Facebook出的一篇论文,借鉴了Facebook论文做的工作,就叫TED Policy,得到SOTA结果--可以搜一下论文
有发论文需求可以加入xbot里面去;中文的rasa
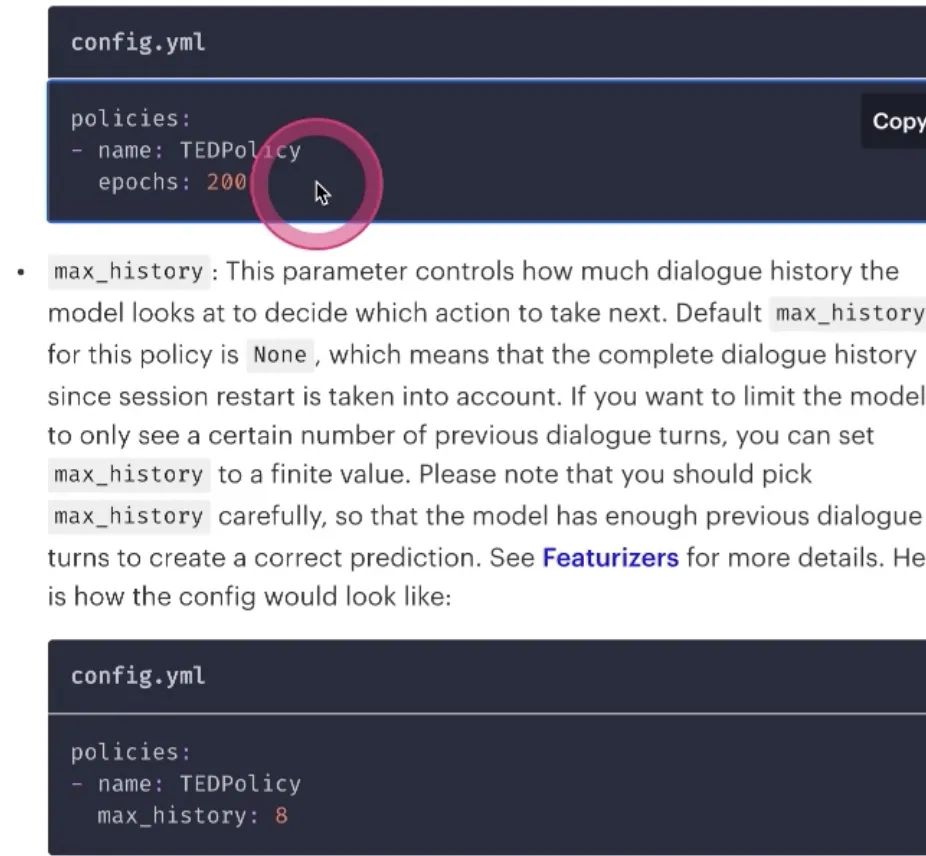
epoch训练多少轮,取决于story
-
max_history TEDPolicy会记住上下文的信息,然后做判断,max history记忆上下文,是记忆多少轮;有些对话场景是任务的对话场景,平均来看三轮可以完成的任务,如果记录的是十轮对话场景,就不值得这么大的值;默认是max_history轮次,实际往往不需要这么多 number_of_transformer_layer 用多少层的transformer做这个事情,需要研究算法
-
Memoizaiton Policy 更多是依据规则;可能会产生超出story范围之外的结果;可以用memorization的方式去做,可以匹配intent action去走,没有泛化能力
生成下面的action,只是规则带来的泛化性,不是算法带来的泛化性
-
rule-based policies是完全规则的形式 主要用来讲nlu的时候,可以定义很多rule
custom Policies
policy也是可以自定义的
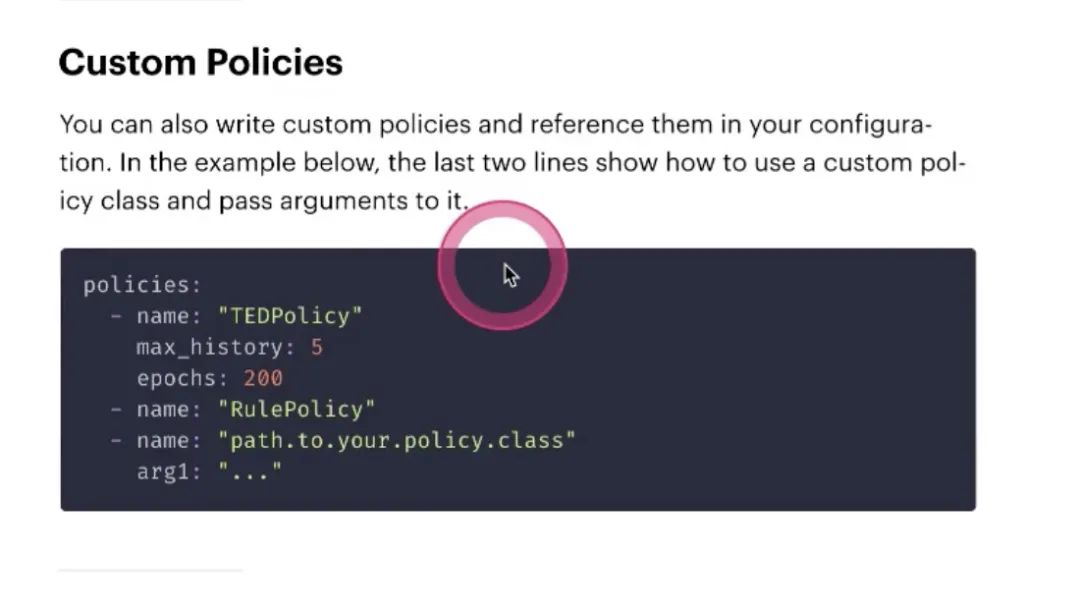
先不讲,后面真正讲policy算法的时候再讲,放到rasa框架里自己实现policy
以上是模型方面, 数据方面:如何获取更多的story,同nlu:
-
Share your Bot to More people
-
Stories Data Augmentation
-
Reinforce Learning
Action
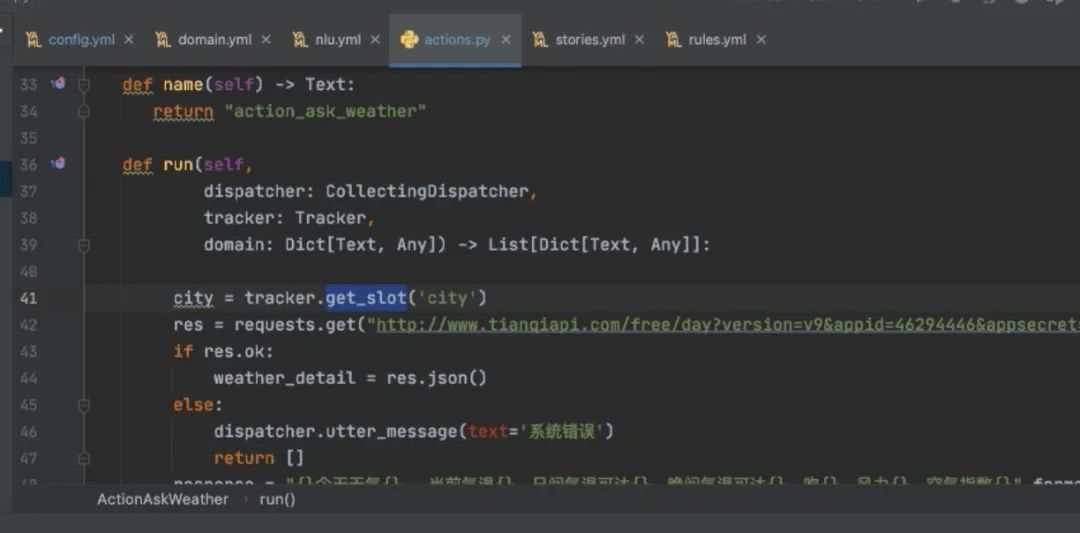
对话机器人需要查接口,才能做查天气的工作 action_ 与前面是一致的 rasa知道你在,在此方法里用这样的方式,查询天气的逻辑写出来即可 写完这样的东西之后,要执行 rasa run actions微服务概念,每一个action都是一个单独的服务,每一个action就可以多布置几台,这时候就会启动服务,就跑在了5055端口上,rasa就会在命中了number_form
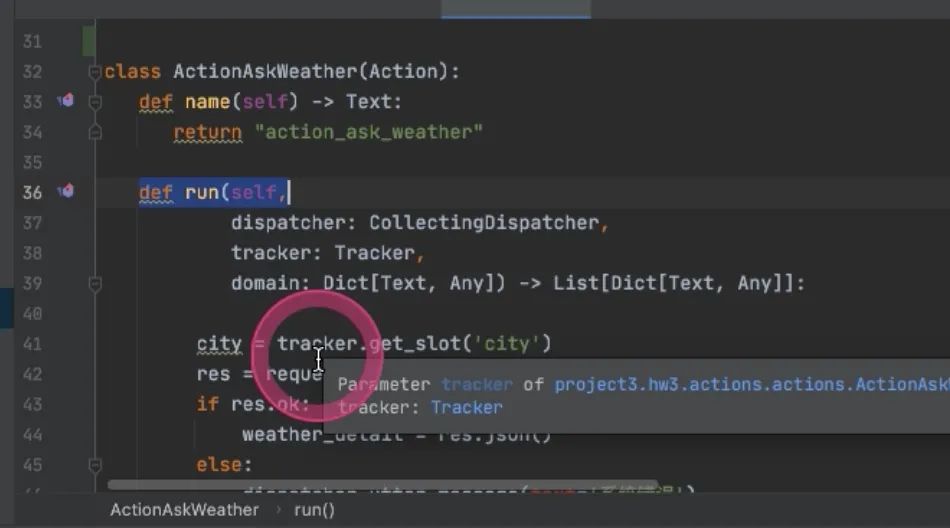
就会进到run里面,做实体识别的时候已经拿到,tracker就是在rasa里定义的关于记忆的东西,叫记录仪,去get_slot,拿到命名的city的slot,找到比如“台北”,然后就可以去调第三方接口,把台北传进去,然后通过dispatcher,rasa的action server 跟rasa交互的工具,然后就会跟用户说这句话,
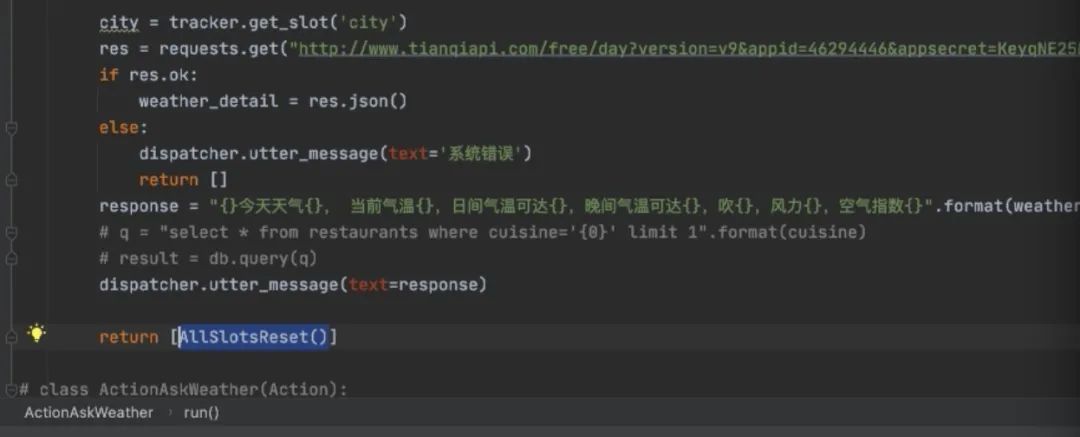
return 返回的是事件--**是在Rasa系统里与Rasa交互的东西 [AllSlotReset]**词槽信息都清空
Events
都被表征成一系列事件/暗号
-
SlotSet 想给slot里填一个值,都通过event机制去与rasa交互
-
reminderScheduled 比如小度音响,明早八点叫我起床,在某一个时间点去做一个事情,等到那个时间就会响应某一个action
-
ReminderCancelled 能创建一个日程,还能取消一个日程,通过这样一个slot告诉把event取消掉
-
UserUtternceReverted
-
ActionReverted重复一个action,可能有些场景会用到
-
Restarted重启整个对话机器人,用到的场景比较少
-
SessionStarted 重新开启一个session,要把当前slot都忘记,除非设置一个全局slot
-
BotUttered bot度用户说了句什么话 the texter sent to the user
目前看rasa里events这个系统是不完善的,将来想要做扩展的地方,也是我们需要在xbot里实现更多场景的一个地方
Knowledge Base Actions
如何做KBQA 用知识库回答用户问题
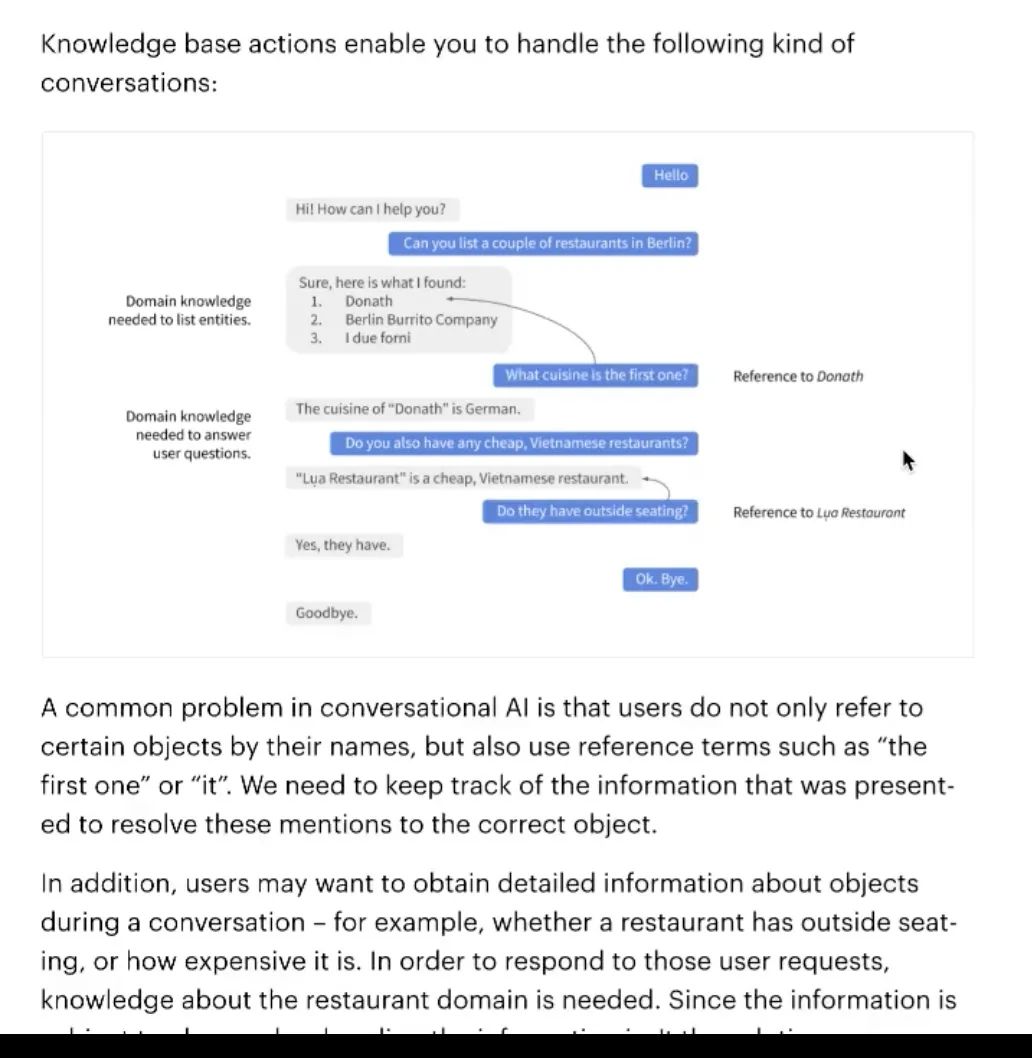
如何实现上图查询过程?只要写一个json文件,按照这样的格式
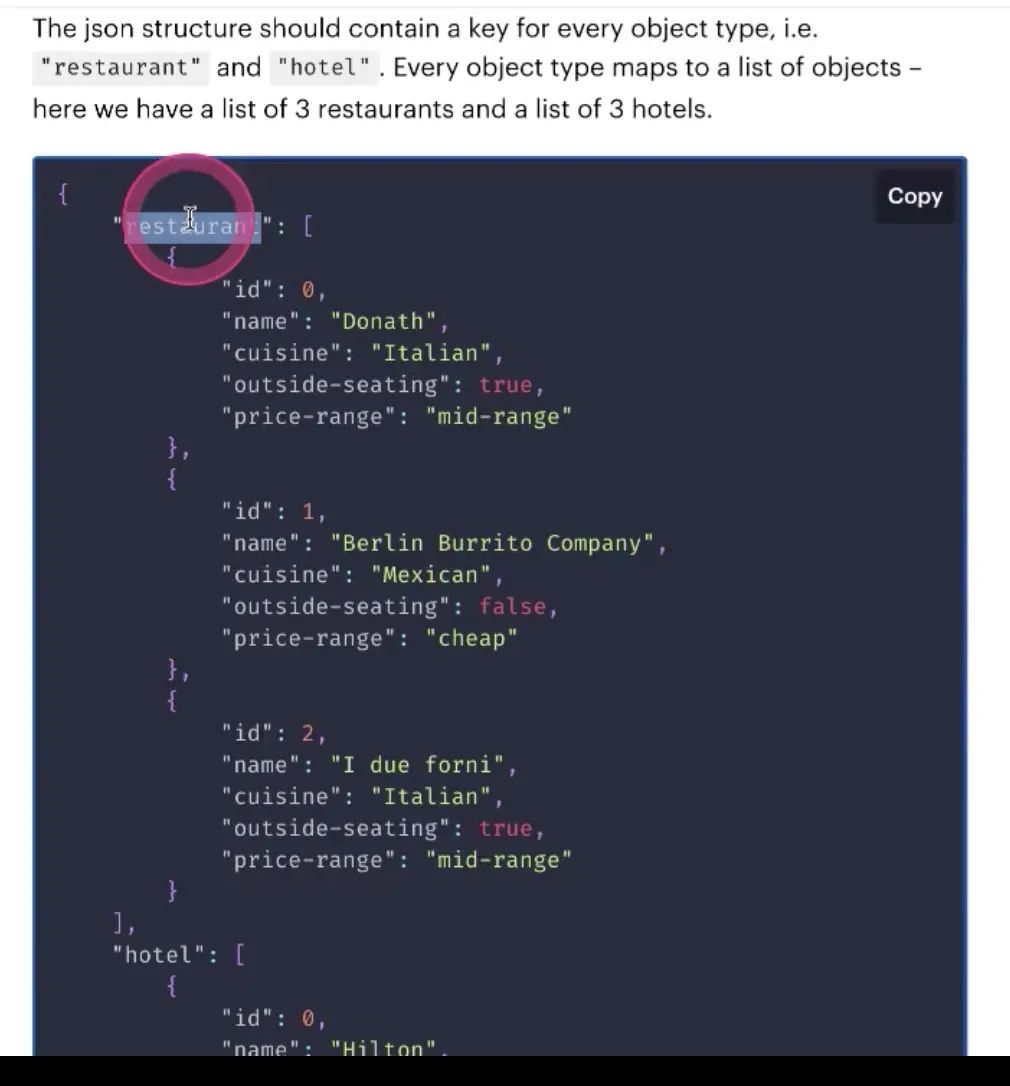
一些key-value对, using Action kb
Leverage information
“the first one”要知道指代的是第一个
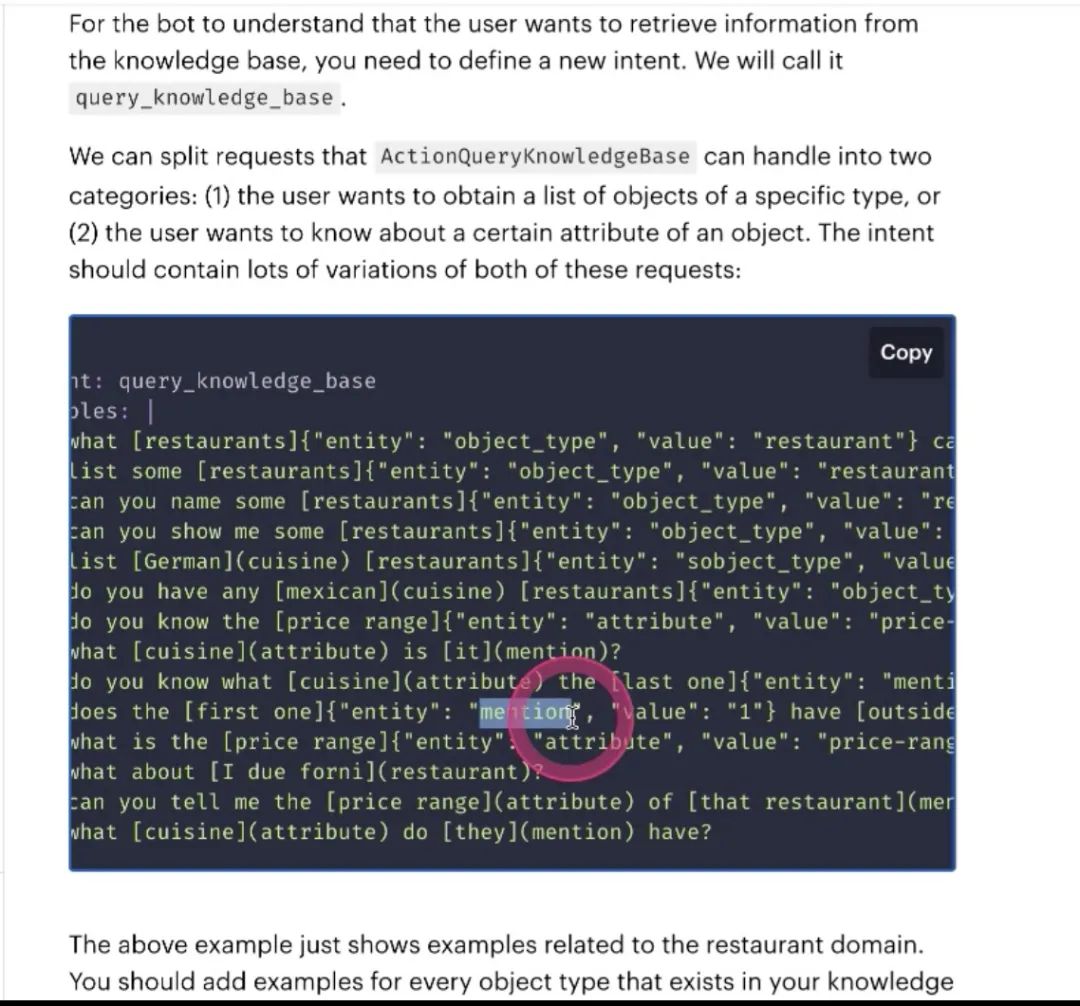
怎么构建数据集 拿到这个实体,就能够自动找到返回的第一个
-
需要在语料里标注的,value是restaurant,就能找到要从哪个restaurant里拿数据,要在语料里定义好这个东西
-
第二个是mention,指代消息,the first one, the second one
-
attribute: 就是在数据库里的一些信息,就会自动去找price-range,从属性里去拿,返回一句话
接下来你写的action server是什么样子的
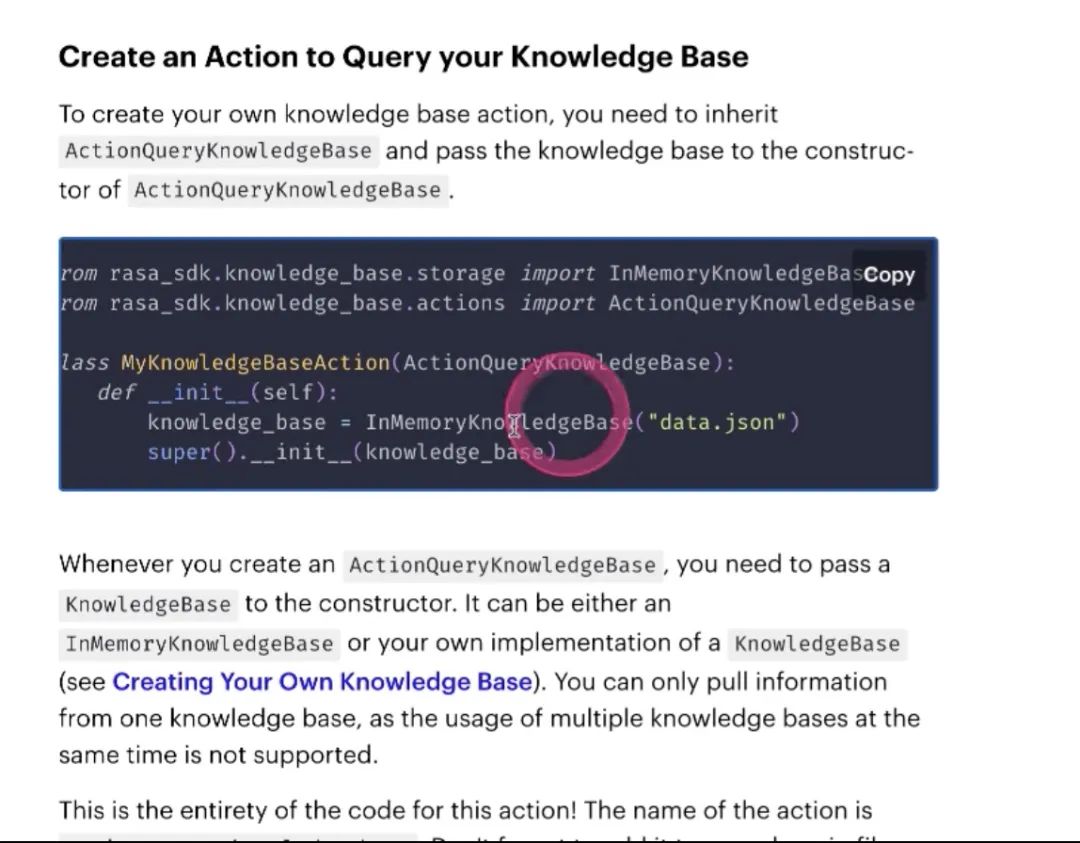
继承ActionQueryKnowledgeBAse
可以自动帮我们做查询,做查询的query,再返回信息
以上就是配置过程,先配语料,entity slot在domain里定义好,把action写到story里面去,关于知识库的查询动作就可以实现了
Q::FormAction不太明白原理
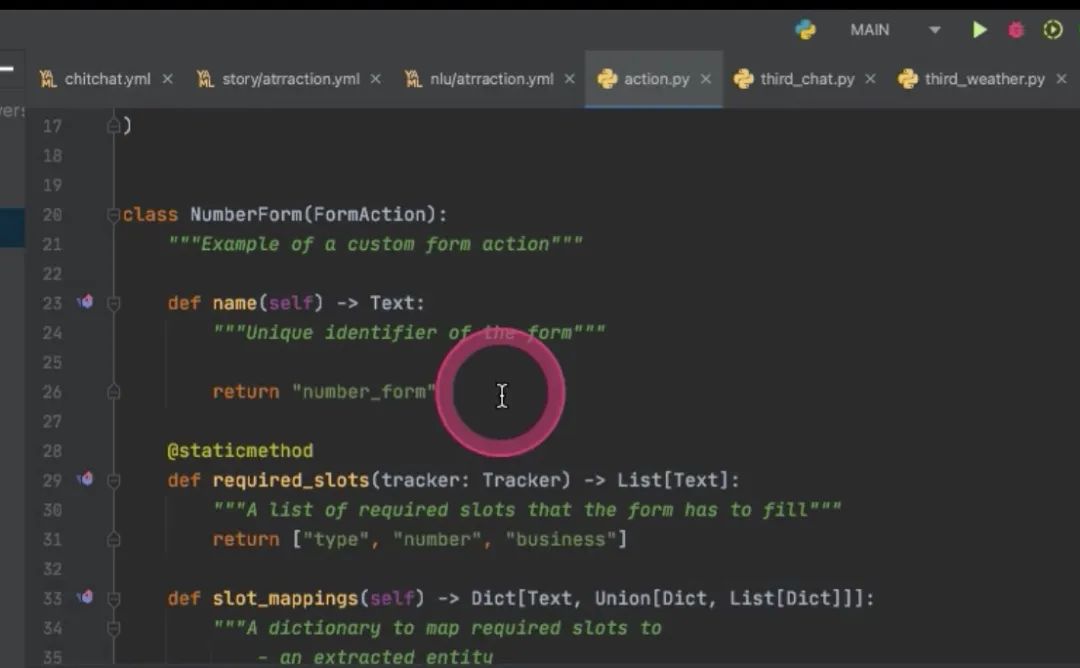
定义的比action复杂些 首先action name,有name才嫩写到story里面去 表单,填一些类别,电话号码,电话号码的数值,要查询哪些业务,做提交,提交完之后要做哪些回复,做哪些操作
Q:action是从哪里定义获取的slot的
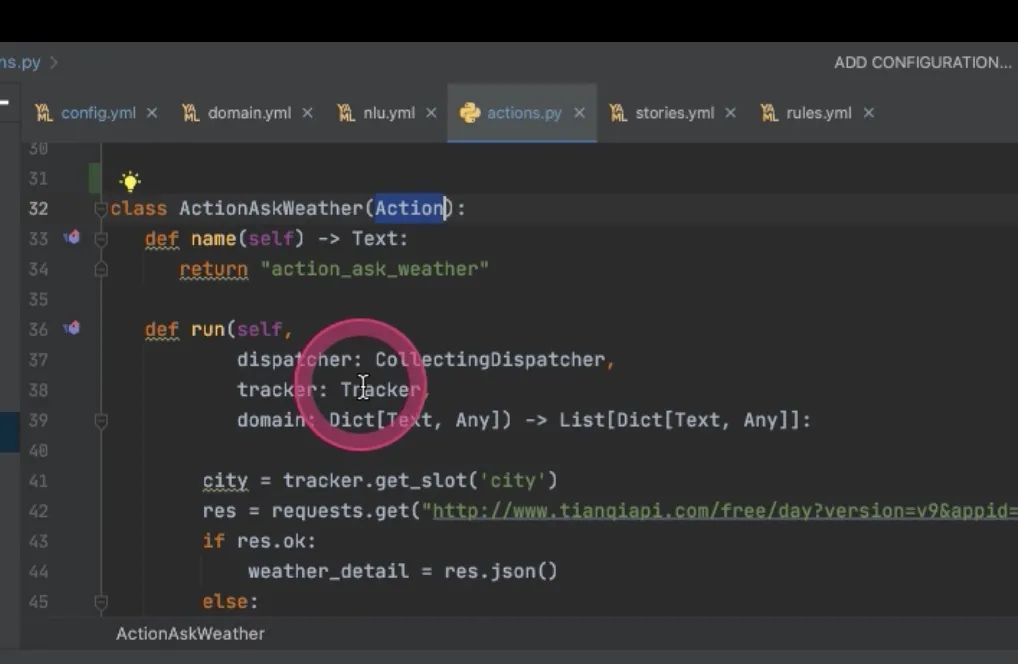
action会把tracker(rasa里的信息)当作参数传递进来 把entity当作slot永久记忆下来
rasa后端是tf,没用pytorch
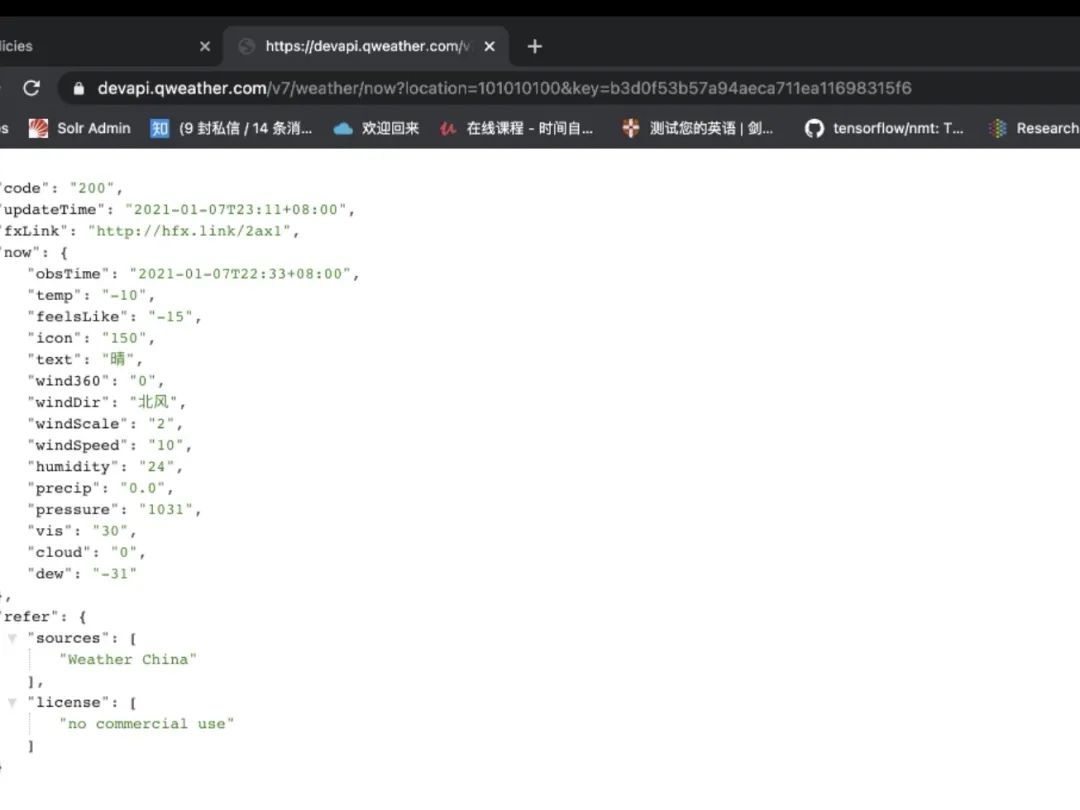
conditional 带有条件的方式 天气查询的接口
更多资料
https://github.com/RasaHQ/rasa
https://github.com/RasaHQ/rasa-demo
https://github.com/sfrpl/rasa-chatbot
https://zhuanlan.zhihu.com/p/75517803
推荐阅读


加入微信学习交流请扫描助手二维码: