
热门标签
热门文章
- 1python 用户信息管理系统【各个函数剖析 + 完整代码 零基础适用篇】_简易版用户管理系统python
- 2Qt隐藏标题栏,鼠标实现窗口右下角放缩窗口_qdialog隐藏标题栏
- 3Qt源代码研究-------QMainWindow
- 4mysql实战——Mysql8.0高可用之双主+keepalived_keepalived 都设置为backup
- 5git安装教程 Windows 附安装包链接
- 6CleanMyMac X详细测评 CleanMyMac X常见问题 CleanMyMac X有必要买吗 cleanmymac和腾讯柠檬哪个好
- 7最强整理:对Android开发的现状和未来发展的思考,算法太TM重要了_android 应用层开发,算法重要吗
- 8YAML语法记录
- 9HarmonyOS实战开发-静态库(SDK)的创建和使用_harmonyos sdk
- 10Java二进制以及TXT文件操作_java 二进制转换成txt
当前位置: article > 正文
Hadoop3:客户端向HDFS写数据流的流程讲解(较枯燥)
作者:IT小白 | 2024-05-27 09:06:03
赞
踩
Hadoop3:客户端向HDFS写数据流的流程讲解(较枯燥)
一、场景描述
我们登陆HDFS的web端,上传一个大文件。
二、流程图
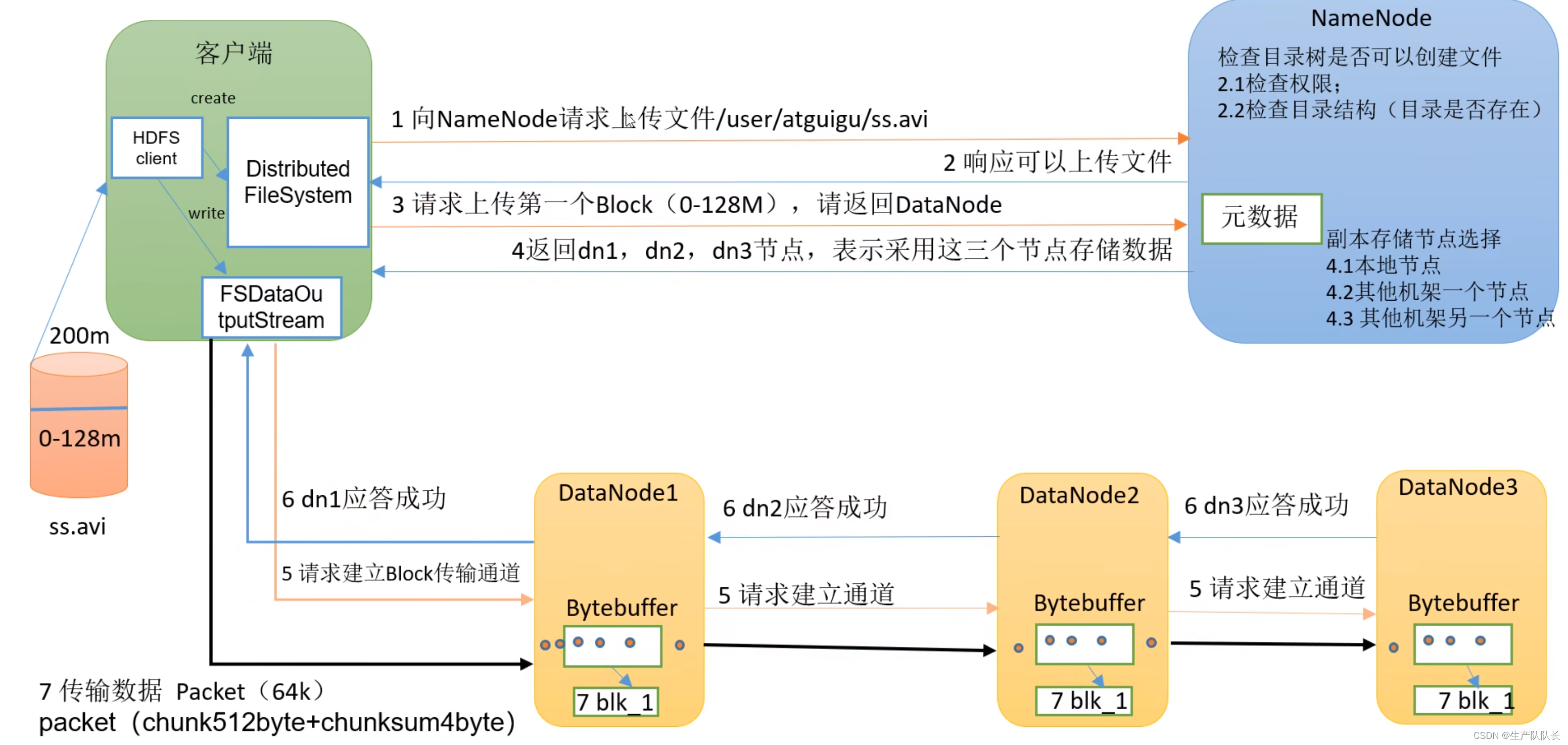
三、讲解
流程1(Client与NameNode交互)
1、HDFS client创建DistributedFileSystem,通过dfs与NameNode进行2次(一来一回4次)对话(request和response),如图所示。
2、第1次请求,NameNode会进行2.1和2.2的检查工作。
3、第2次请求,上传一个Block,NameNode选定的存储数据的节点(DataNode),返回给client。
流程2(Client与DataNode交互)
4、HDFS client创建FSDataOutputStream(一种输出流),通过它和集群中选定的存储数据的DataNode交互
5、首先,和选定的DataNode打通数据流通道。
这里,client只需要和最近的节点直接交互,其他副本节点和该节点交互,无需和client交互。这里涉及到最近节点距离计算。
6、开始传输数据给最近节点,这里传输的时候,DataNode会先存一份在内存,同时,用内存的数据,写入磁盘和传输到其他DataNode节点。就是图中第7步。
7、所有节点存储完成后,依次返回ack(了解消息队列的,比如kafka,都知道ack是什么吧),告知存储结果。最终由最近节点,反馈给client存储结果。
8、当一个Block传完之后,客户端会再次请求NameNode,再次上传一个Block。重复步骤3-8,直到,完整的文件传输完毕。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/630844
推荐阅读
相关标签

