
- 1推荐开源项目:PyCryptodome——Python加密库的卓越替代品
- 2NameError: name xxxxxx is not defined
- 3大神之路-起始篇 | 第2章.计算机科学导论之【数字系统】学习笔记_计算机导论中数码的数量怎么理解
- 42023年中国研究生数学建模等待成绩的心路历程(二十届华为杯)_2023华为杯数学建模竞赛成绩
- 5杠上Google I/O?OpenAI抢先一天直播,ChatGPT或将具备通话功能
- 6Java开发9年经验,三轮技术面+HR面试成功砍下阿里巴巴Offer!_java 9年面试
- 7neo4j3.0 java使用,neo4j 3.0中的存储过程
- 8盘点分布式文件存储系统____分布式文件存储系统简介
- 9网络安全专业名词解释_计算机靶机是什么意思
- 10SQL Server使用教程_初学者必备
京东面试题:ElasticSearch深度分页解决方案
赞
踩
上面的查询表示从搜索结果中取第100条开始的10条数据。
「那么,这个查询语句在ES集群内部是怎么执行的呢?」
在ES中,搜索一般包括两个阶段,query 和 fetch 阶段,可以简单的理解,query 阶段确定要取哪些doc,fetch 阶段取出具体的 doc。
❝
Query阶段
❞
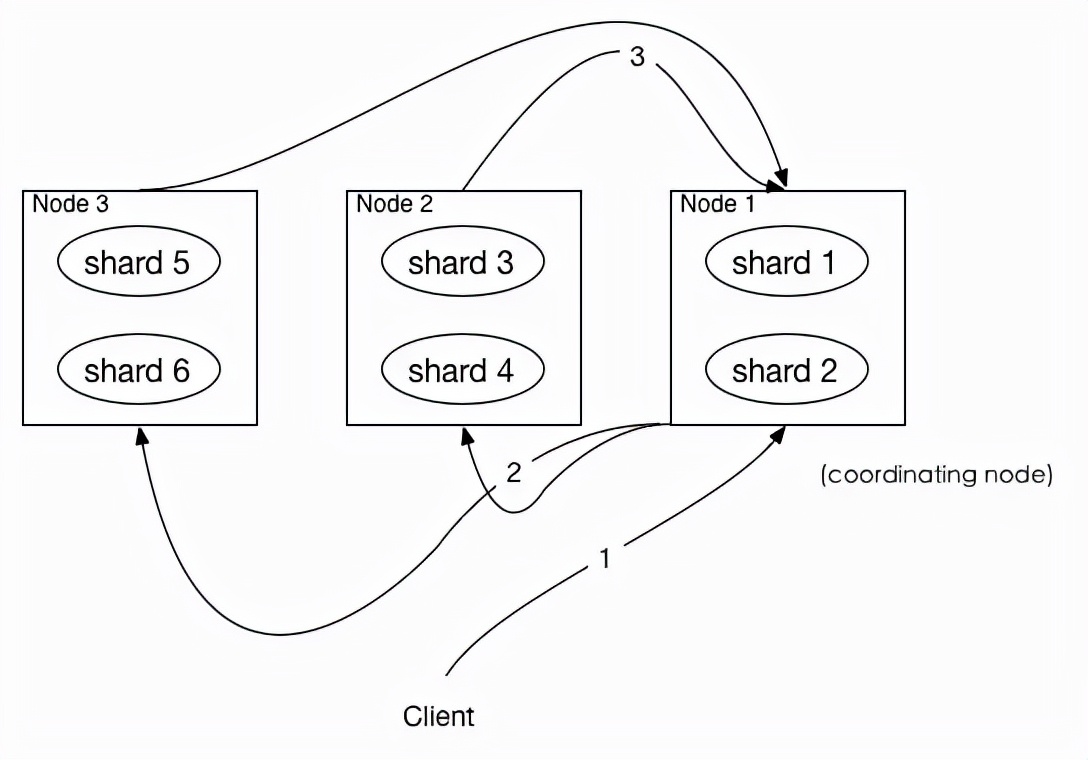
如上图所示,描述了一次搜索请求的 query 阶段:·
-
Client 发送一次搜索请求,node1 接收到请求,然后,node1 创建一个大小为from + size的优先级队列用来存结果,我们管 node1 叫 coordinating node。
-
coordinating node将请求广播到涉及到的 shards,每个 shard 在内部执行搜索请求,然后,将结果存到内部的大小同样为from + size的优先级队列里,可以把优先级队列理解为一个包含top N结果的列表。
-
每个 shard 把暂存在自身优先级队列里的数据返回给 coordinating node,coordinating node 拿到各个 shards 返回的结果后对结果进行一次合并,产生一个全局的优先级队列,存到自身的优先级队列里。
在上面的例子中,coordinating node 拿到(from + size) * 6条数据,然后合并并排序后选择前面的from + size条数据存到优先级队列,以便 fetch 阶段使用。
另外,各个分片返回给 coordinating node 的数据用于选出前from + size条数据,所以,只需要返回唯一标记 doc 的_id以及用于排序的_score即可,这样也可以保证返回的数据量足够小。
coordinating node 计算好自己的优先级队列后,query 阶段结束,进入 fetch 阶段。
❝
Fetch阶段
❞
query 阶段知道了要取哪些数据,但是并没有取具体的数据,这就是 fetch 阶段要做的。
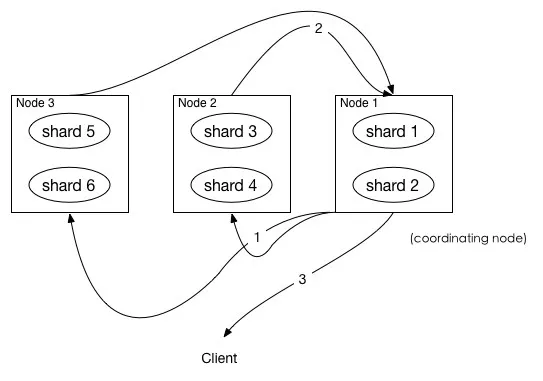
上图展示了 fetch 过程:
-
coordinating node 发送 GET 请求到相关shards。
-
shard 根据 doc 的_id取到数据详情,然后返回给 coordinating node。
-
coordinating node 返回数据给 Client。
coordinating node 的优先级队列里有from + size 个_doc _id,但是,在 fetch 阶段,并不需要取回所有数据,在上面的例子中,前100条数据是不需要取的,只需要取优先级队列里的第101到110条数据即可。
需要取的数据可能在不同分片,也可能在同一分片,coordinating node 使用 「multi-get」 来避免多次去同一分片取数据,从而提高性能。
「这种方式请求深度分页是有问题的:」
我们可以假设在一个有 5 个主分片的索引中搜索。当我们请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,并且返回给 协调节点,协调节点对 50 个结果排序得到全部结果的前 10 个。
现在假设我们请求第 1000 页—结果从 10001 到 10010 。所有都以相同的方式工作除了每个分片不得不产生前10010个结果以外。然后协调节点对全部 50050 个结果排序最后丢弃掉这些结果中的 50040 个结果。
「对结果排序的成本随分页的深度成指数上升。」
「注意1:」
size的大小不能超过index.max_result_window这个参数的设置,默认为10000。
如果搜索size大于10000,需要设置index.max_result_window参数
PUT _settings
{
“index”: {
“max_result_window”: “10000000”
}
}
「注意2:」
_doc将在未来的版本移除,详见:
-
https://www.elastic.co/cn/blog/moving-from-types-to-typeless-apis-in-elasticsearch-7-0
-
https://elasticsearch.cn/article/158

深度分页问题
======
Elasticsearch 的From/Size方式提供了分页的功能,同时,也有相应的限制。
举个例子,一个索引,有10亿数据,分10个 shards,然后,一个搜索请求,from=1000000,size=100,这时候,会带来严重的性能问题:CPU,内存,IO,网络带宽。
在 query 阶段,每个shards需要返回 1000100 条数据给 coordinating node,而 coordinating node 需要接收10 * 1000,100 条数据,即使每条数据只有 _doc _id 和 _score,这数据量也很大了?
「在另一方面,我们意识到,这种深度分页的请求并不合理,因为我们是很少人为的看很后面的请求的,在很多的业务场景中,都直接限制分页,比如只能看前100页。」
比如,有1千万粉丝的微信大V,要给所有粉丝群发消息,或者给某省粉丝群发,这时候就需要取得所有符合条件的粉丝,而最容易想到的就是利用 from + size 来实现,不过,这个是不现实的,这时,可以采用 Elasticsearch 提供的其他方式来实现遍历。
深度分页问题大致可以分为两类:
-
「随机深度分页:随机跳转页面」
-
「滚动深度分页:只能一页一页往下查询」
「下面介绍几个官方提供的深度分页方法」
Scroll
======
❝
Scroll遍历数据
❞
我们可以把scroll理解为关系型数据库里的cursor,因此,scroll并不适合用来做实时搜索,而更适合用于后台批处理任务,比如群发。
这个分页的用法,「不是为了实时查询数据」,而是为了**「一次性查询大量的数据(甚至是全部的数据」**)。
因为这个scroll相当于维护了一份当前索引段的快照信息,这个快照信息是你执行这个scroll查询时的快照。在这个查询后的任何新索引进来的数据,都不会在这个快照中查询到。
但是它相对于from和size,不是查询所有数据然后剔除不要的部分,而是记录一个读取的位置,保证下一次快速继续读取。
不考虑排序的时候,可以结合SearchType.SCAN使用。
scroll可以分为初始化和遍历两部,初始化时将**「所有符合搜索条件的搜索结果缓存起来(注意,这里只是缓存的doc_id,而并不是真的缓存了所有的文档数据,取数据是在fetch阶段完成的)」**,可以想象成快照。
在遍历时,从这个快照里取数据,也就是说,在初始化后,对索引插入、删除、更新数据都不会影响遍历结果。
「基本使用」
POST /twitter/tweet/_search?scroll=1m
{
“size”: 100,
“query”: {
“match” : {
“title” : “elasticsearch”
}
}
}
初始化指明 index 和 type,然后,加上参数 scroll,表示暂存搜索结果的时间,其它就像一个普通的search请求一样。
会返回一个_scroll_id,_scroll_id用来下次取数据用。
「遍历」
POST /_search?scroll=1m
{
“scroll_id”:“XXXXXXXXXXXXXXXXXXXXXXX I am scroll id XXXXXXXXXXXXXXX”
}
这里的scroll_id即 上一次遍历取回的_scroll_id或者是初始化返回的_scroll_id,同样的,需要带 scroll 参数。
重复这一步骤,直到返回的数据为空,即遍历完成。
「注意,每次都要传参数 scroll,刷新搜索结果的缓存时间」。另外,「不需要指定 index 和 type」。
设置scroll的时候,需要使搜索结果缓存到下一次遍历完成,「同时,也不能太长,毕竟空间有限。」
「优缺点」
缺点:
-
「scroll_id会占用大量的资源(特别是排序的请求)」
-
同样的,scroll后接超时时间,频繁的发起scroll请求,会出现一些列问题。
-
「是生成的历史快照,对于数据的变更不会反映到快照上。」
「优点:」
适用于非实时处理大量数据的情况,比如要进行数据迁移或者索引变更之类的。
Scroll Scan
===========
ES提供了scroll scan方式进一步提高遍历性能,但是scroll scan不支持排序,因此scroll scan适合不需要排序的场景
「基本使用」
Scroll Scan 的遍历与普通 Scroll 一样,初始化存在一点差别。
POST /my_index/my_type/_search?search_type=scan&scroll=1m&size=50
{
“query”: { “match_all”: {}}
}
需要指明参数:
-
search_type:赋值为scan,表示采用 Scroll Scan 的方式遍历,同时告诉 Elasticsearch 搜索结果不需要排序。
-
scroll:同上,传时间。
-
size:与普通的 size 不同,这个 size 表示的是每个 shard 返回的 size 数,最终结果最大为 number_of_shards * size。
「Scroll Scan与Scroll的区别」
-
Scroll-Scan结果**「没有排序」**,按index顺序返回,没有排序,可以提高取数据性能。
-
初始化时只返回 _scroll_id,没有具体的hits结果
-
size控制的是每个分片的返回的数据量,而不是整个请求返回的数据量。
Sliced Scroll
=============
如果你数据量很大,用Scroll遍历数据那确实是接受不了,现在Scroll接口可以并发来进行数据遍历了。
每个Scroll请求,可以分成多个Slice请求,可以理解为切片,各Slice独立并行,比用Scroll遍历要快很多倍。
POST /index/type/_search?scroll=1m
{
“query”: { “match_all”: {}},
“slice”: {
“id”: 0,
“max”: 5
}
}
POST ip:port/index/type/_search?scroll=1m
{
“query”: { “match_all”: {}},
“slice”: {
“id”: 1,
“max”: 5
}
}
上边的示例可以单独请求两块数据,最终五块数据合并的结果与直接scroll scan相同。
其中max是分块数,id是第几块。
❝
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

线程、数据库、算法、JVM、分布式、微服务、框架、Spring相关知识

一线互联网P7面试集锦+各种大厂面试集锦

学习笔记以及面试真题解析

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
这些内容对你有帮助,可以扫码获取!!(备注Java获取)**
线程、数据库、算法、JVM、分布式、微服务、框架、Spring相关知识
[外链图片转存中…(img-Ccx6KzxX-1712753270510)]
一线互联网P7面试集锦+各种大厂面试集锦
[外链图片转存中…(img-9mrxBbQl-1712753270510)]
学习笔记以及面试真题解析
[外链图片转存中…(img-mgpdjXzU-1712753270510)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!

