
热门标签
热门文章
- 1服务器上更新了js、html、css文件,访问时不是最新的文件_服务器响应的不是最新的资源
- 2知识点总结:Java核心技术(卷1)_java核心技术卷1
- 3【二进制部署k8s-1.29.4】一、安装前软件准备及系统初始化
- 4Monkey测试结果分析_monkey 结果分析
- 5Java和Android笔试题_安卓语法 笔试题
- 6京东h5st加密参数分析与批量商品价格爬取(文末含纯算法)_京东 h5st
- 7swagger2 knife4j 集成配置_swagger2 配置 kneif4j
- 8MySQL系列之索引
- 9利用栈和队模拟一个停车场(数据结构报告)_以栈模拟停车场,以队列模拟车场外的便道,按照从终端读入的输入数据序列进行模拟管
- 10sql操作数据_sql创建一个操作表action
当前位置: article > 正文
python爬虫之爬取微博评论(4)_结合网络爬虫技术,实现对微博上某个话题评论的爬取。
作者:IT小白 | 2024-06-03 01:18:37
赞
踩
结合网络爬虫技术,实现对微博上某个话题评论的爬取。
一、获取单页评论
随机选取一个微博,例如下面这个
【#出操死亡女生家属... - @冷暖视频的微博 - 微博 (weibo.com)
1、fn+f12,然后点击网络,搜索评论内容,然后预览,就可以查看到网页内容里面还有评论内容
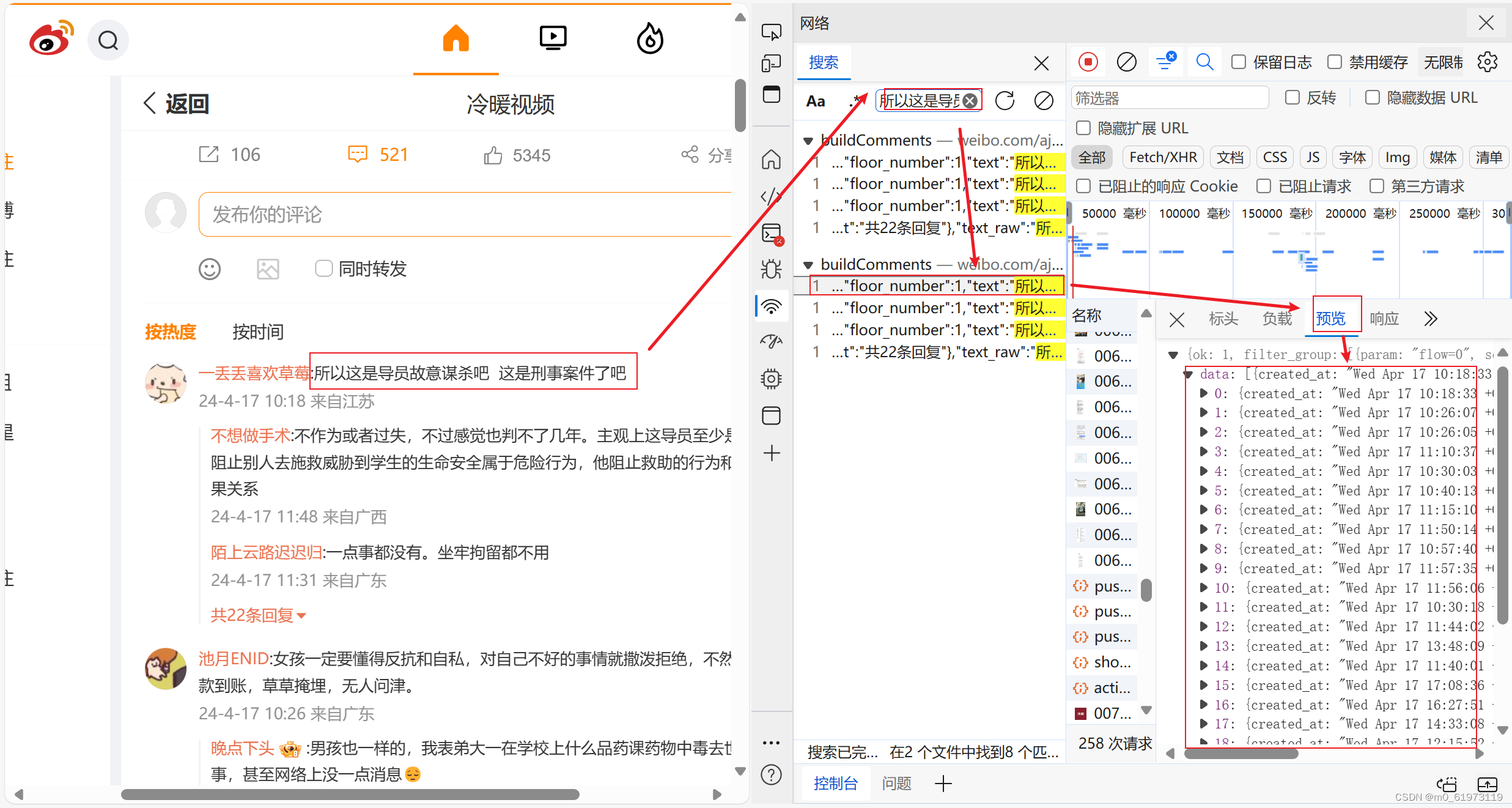
2、编写代码,获取网页信息,url是点击网络,然后点击标头,就会出现一个请求url
- # requets是一个爬虫的第三方库,需要单独安装
- import requests
-
- # url是一访问网站的地址
- url = 'https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=5024086457849590&is_show_bulletin=2&is_mix=0&count=10&uid=6532102014&fetch_level=0&locale=zh-CN'
- # 1.发送请求
- response = requests.get(url=url)
- response.encoding = 'gbk' #防止中文乱码
- # 2.打印网页数据
- print(response.text)
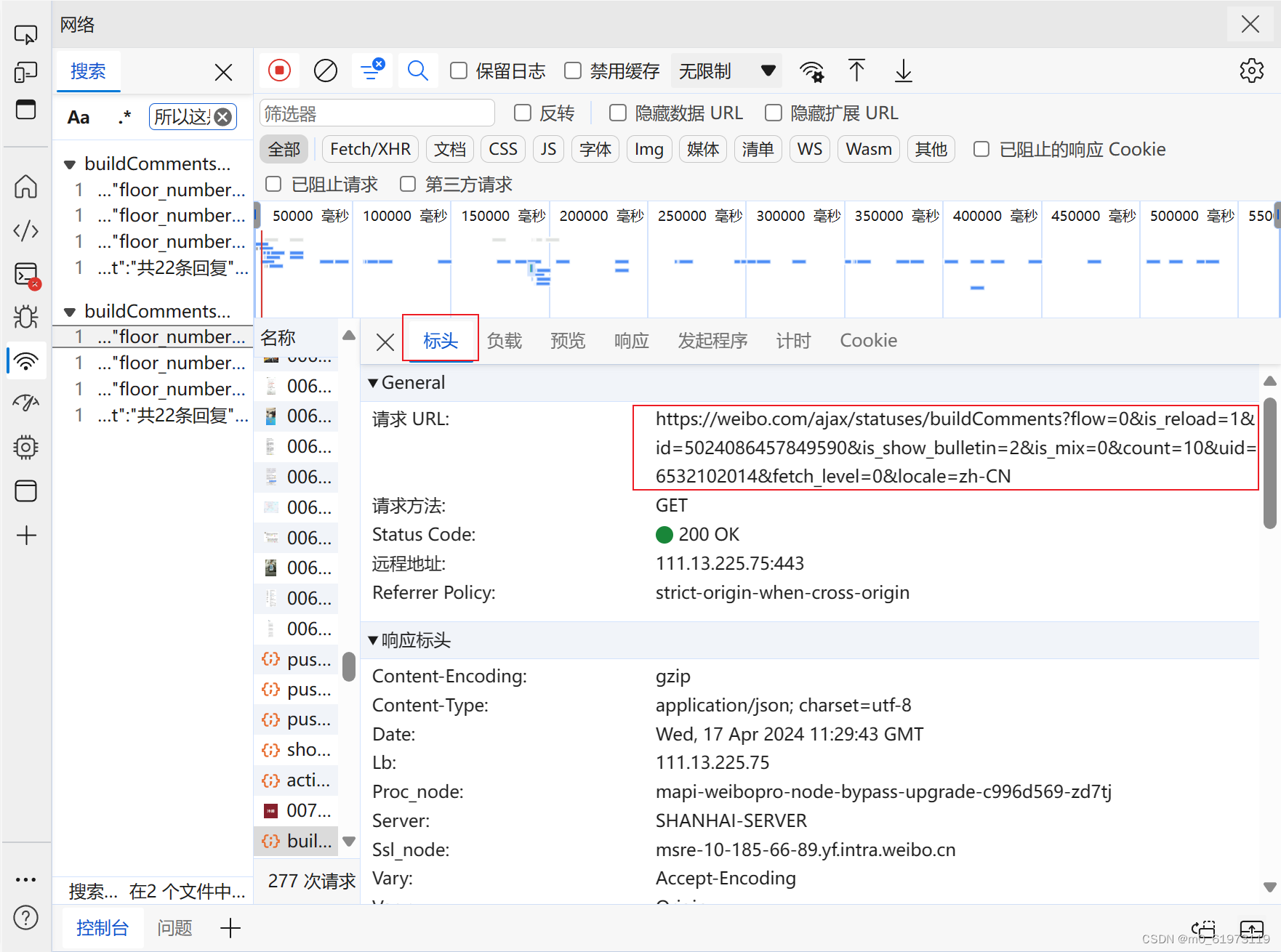

3、但是我们发现这个并不是像我们想的一样,将网页的文本用文字的方式呈现,那么接下来我们要用到一个方法,让我们能够用文字的方式输出网页数据----->定义请求头。为什么要定义请求头,因为从网站的设置初衷,它是不想服务于我们的爬虫程序的,网站正常只想服务于客户的访问服务,那么我们要将我们的爬虫程序伪装成为正常的服务。通常我们只需要设置 cookie 、referee、user-agent就够了(如果有些特殊的网站可能需要我们有其他的参数)
点击网络,点击标头,标头界面向下划动,找到 cookie 、referer 、user-agent 。
- import requests
-
- # 请求头
- headers = {
- # 用户身份信息
- 'cookie': 'XSRF-TOKEN=ZcbKzr5C4_40k_yYwTHIEj7k; PC_TOKEN=4496aa7595; login_sid_t=e6e7e18ba091dcafc2013982ea8fa895; cross_origin_proto=SSL; WBStorage=267ec170|undefined; _s_tentry=cn.bing.com; UOR=cn.bing.com,weibo.com,cn.bing.com; Apache=1040794478428.4973.1713353134174; SINAGLOBAL=1040794478428.4973.1713353134174; ULV=1713353134177:1:1:1:1040794478428.4973.1713353134174:; wb_view_log=1287*8051.9891666173934937; SUB=_2A25LG8JKDeRhGeFJ71MX9S3Lzj2IHXVoWVuCrDV8PUNbmtANLVnQkW9Nf_9NjBaZTVOL8AH-RMG38C00YruaYRtp; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5kReTqg1GgdNOFZ.hiJO0G5NHD95QNS0BpSo-0S0-pWs4DqcjMi--NiK.Xi-2Ri--ciKnRi-zNS0MXeKqfe0MfeBtt; ALF=02_1715945242; WBPSESS=FH255CAr_cfIbZ29-Y520e5NsKBGpFZni0Bmim3vDfjXHIPxgSSGqvAfC_UQmc3W2RLUzLHkkX4YI-_Pn1KHeHJhkeHw5kFxeJYgMYDr9t5bvBCMRkcG_IvV3Y2XiVRlu9ZS91UwfD5AH5MY7jhkfw==',
- # 防盗链
- 'referer': 'https://weibo.com/6532102014/Oa6B7wW2i',
- # 浏览器基本信息
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'
- }
-
- url = 'https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=5024086457849590&is_show_bulletin=2&is_mix=0&count=10&uid=6532102014&fetch_level=0&locale=zh-CN'
- # 1.发送请求
- response = requests.get(url=url, headers=headers)
-
- # 2.打印网页数据
-
- print(response.json()['data'][0]['text_raw'])

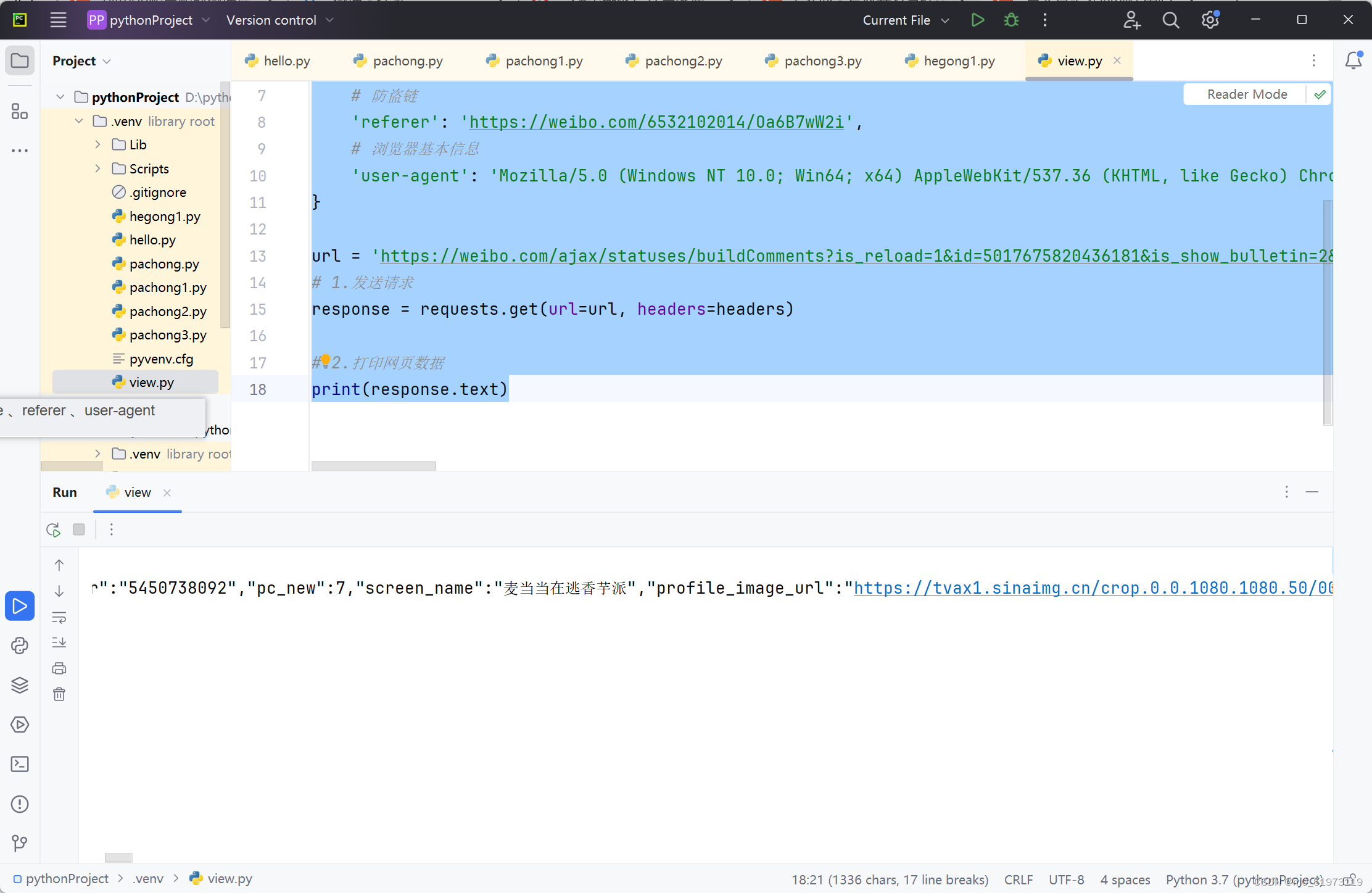
4、获取更多字节内容,然后存储到excel表格中
- import requests
- import csv
-
- f = open('评论.csv', mode='a', encoding='utf-8-sig', newline='')
- csv_write = csv.writer((f))
- csv_write.writerow(['id', 'screen_name', 'text_raw', 'like_counts', 'total_number', 'created_at'])
-
- # 请求头
- headers = {
- # 用户身份信息
- 'cookie': 'XSRF-TOKEN=ZcbKzr5C4_40k_yYwTHIEj7k; PC_TOKEN=4496aa7595; login_sid_t=e6e7e18ba091dcafc2013982ea8fa895; cross_origin_proto=SSL; WBStorage=267ec170|undefined; _s_tentry=cn.bing.com; UOR=cn.bing.com,weibo.com,cn.bing.com; Apache=1040794478428.4973.1713353134174; SINAGLOBAL=1040794478428.4973.1713353134174; ULV=1713353134177:1:1:1:1040794478428.4973.1713353134174:; wb_view_log=1287*8051.9891666173934937; SUB=_2A25LG8JKDeRhGeFJ71MX9S3Lzj2IHXVoWVuCrDV8PUNbmtANLVnQkW9Nf_9NjBaZTVOL8AH-RMG38C00YruaYRtp; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5kReTqg1GgdNOFZ.hiJO0G5NHD95QNS0BpSo-0S0-pWs4DqcjMi--NiK.Xi-2Ri--ciKnRi-zNS0MXeKqfe0MfeBtt; ALF=02_1715945242; WBPSESS=FH255CAr_cfIbZ29-Y520e5NsKBGpFZni0Bmim3vDfjXHIPxgSSGqvAfC_UQmc3W2RLUzLHkkX4YI-_Pn1KHeHJhkeHw5kFxeJYgMYDr9t5bvBCMRkcG_IvV3Y2XiVRlu9ZS91UwfD5AH5MY7jhkfw==',
- # 防盗链
- 'referer': 'https://weibo.com/6532102014/Oa6B7wW2i',
- # 浏览器基本信息
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'
- }
-
- url = 'https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=5024086457849590&is_show_bulletin=2&is_mix=0&count=10&uid=6532102014&fetch_level=0&locale=zh-CN'
-
-
- # 1.发送请求
- response = requests.get(url=url, headers=headers)
- # 2.获取数据
-
- # 3.提取数据
- json_data = response.json()
- data_list = json_data['data']
-
- for data in data_list:
- text_raw = data['text_raw']
- id = data['id']
- created_at = data['created_at']
- like_counts = data['like_counts']
- total_number = data['total_number']
- screen_name = data['user']['screen_name']
- print(id, screen_name, text_raw, like_counts, total_number, created_at)
- # 4.保存数据
- csv_write.writerow([id, screen_name, text_raw, like_counts, total_number, created_at])
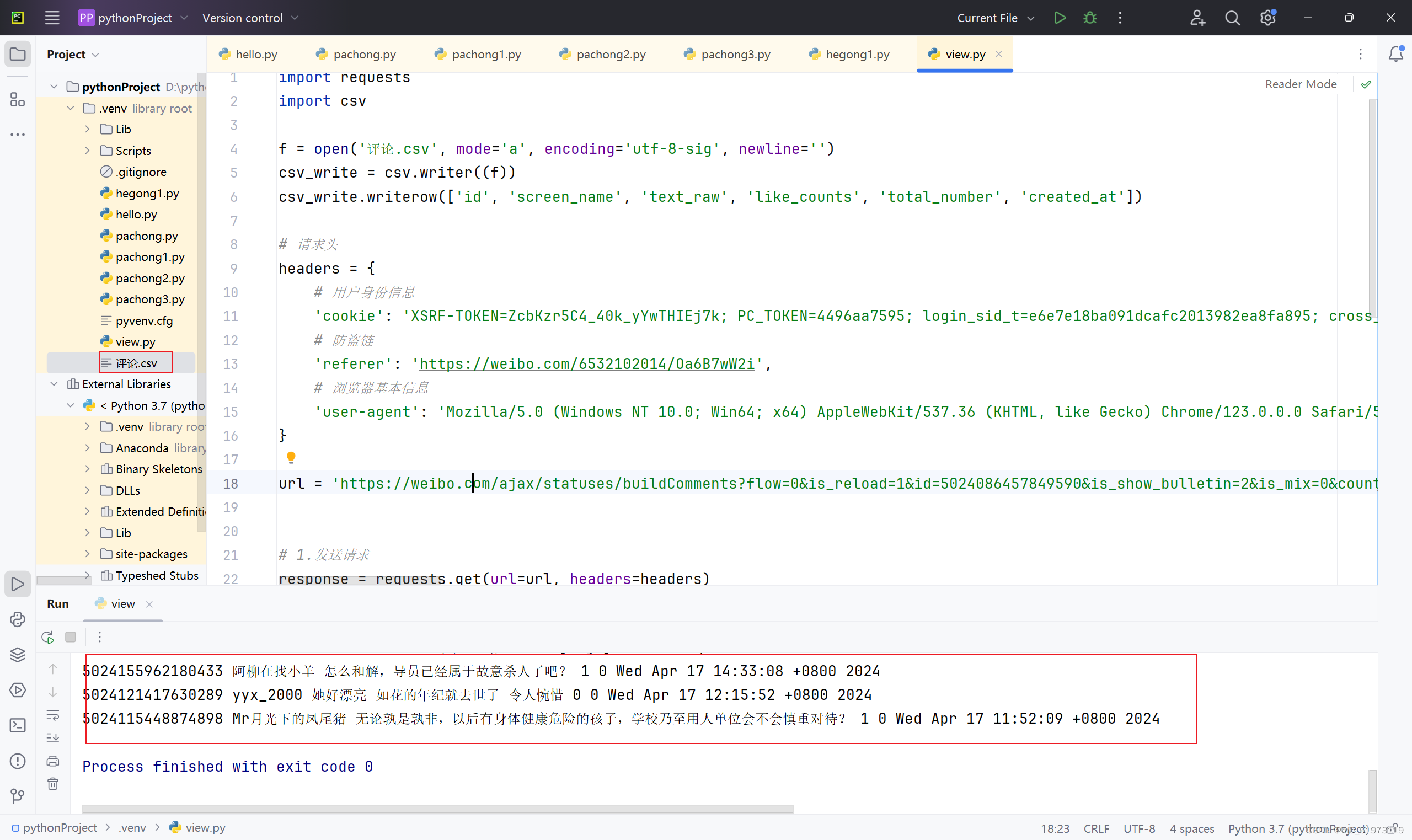
二、获取多页评论
仔细观察,多条评论应该都会包含buildComments字段
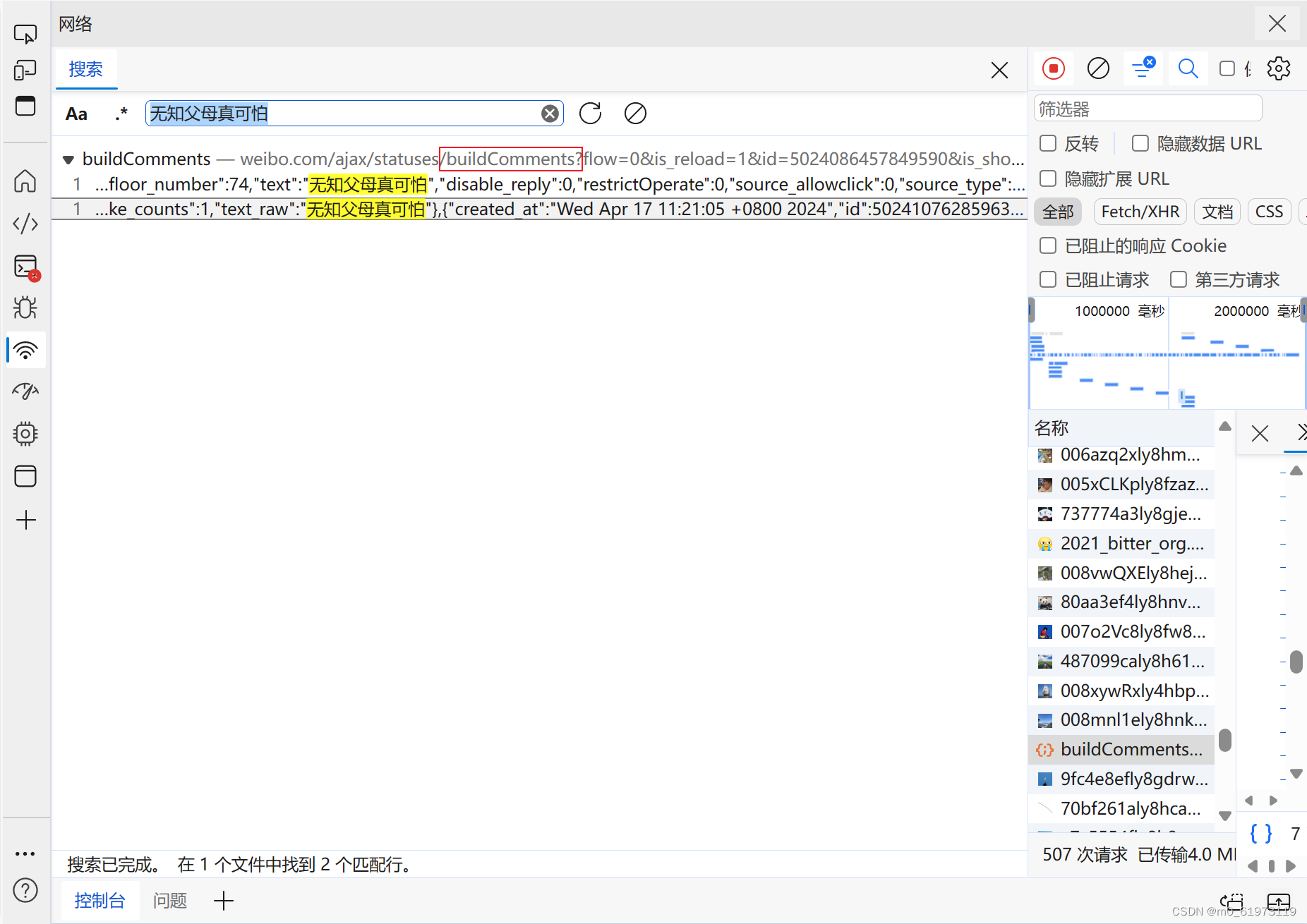
然后搜索buildComments字段,点进去看,会发现每一个路径都对应20条评论,但是我们人为输入每一条路径不显示,所以我们需要观察他们的规律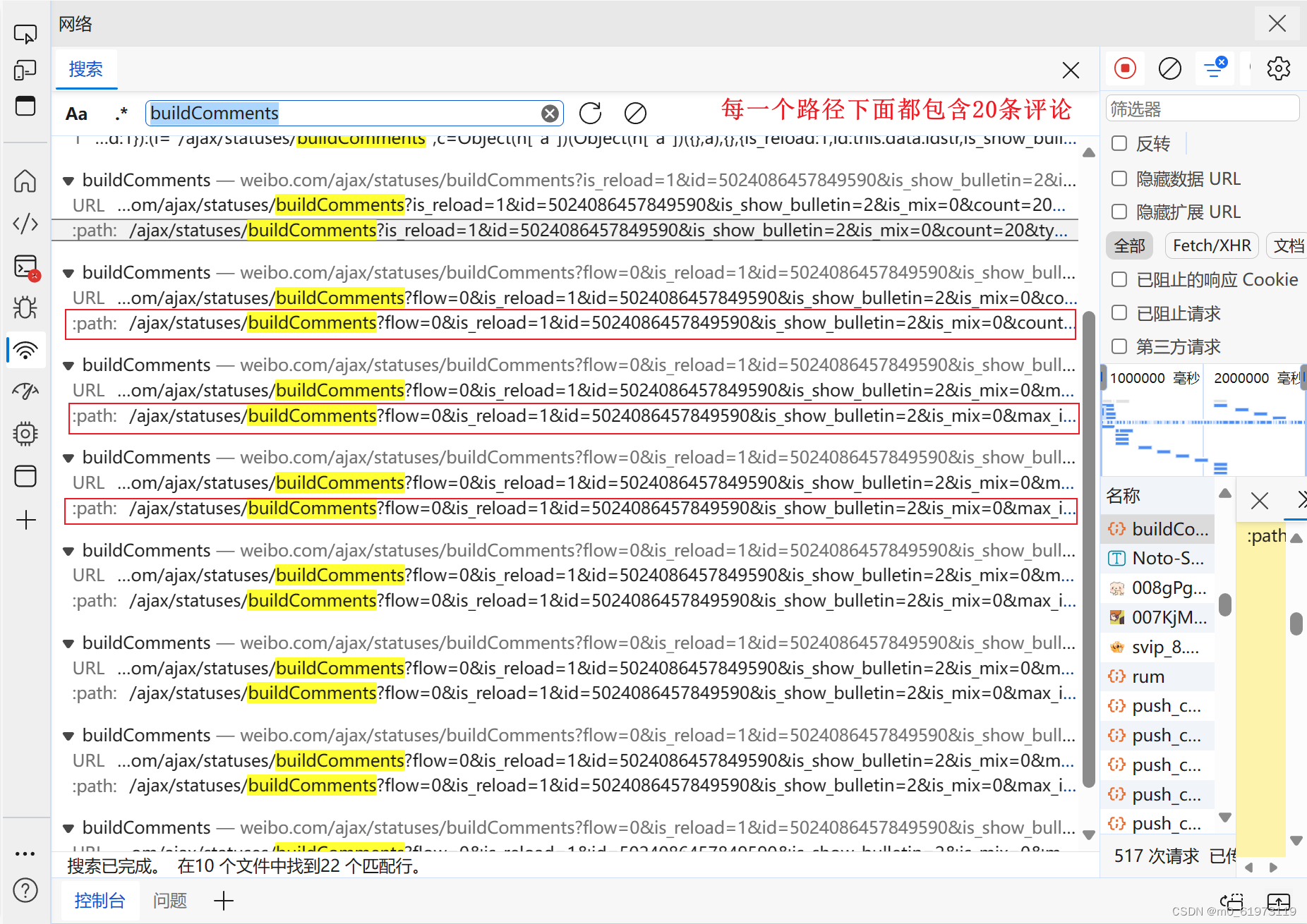
我们发现除开第一个分页格式不一样,其他分页的url完全一致,但是max_id的值不一样。我们可以多观察几组(例如第二个分页的max_id是第三个分页URL中的max_id)



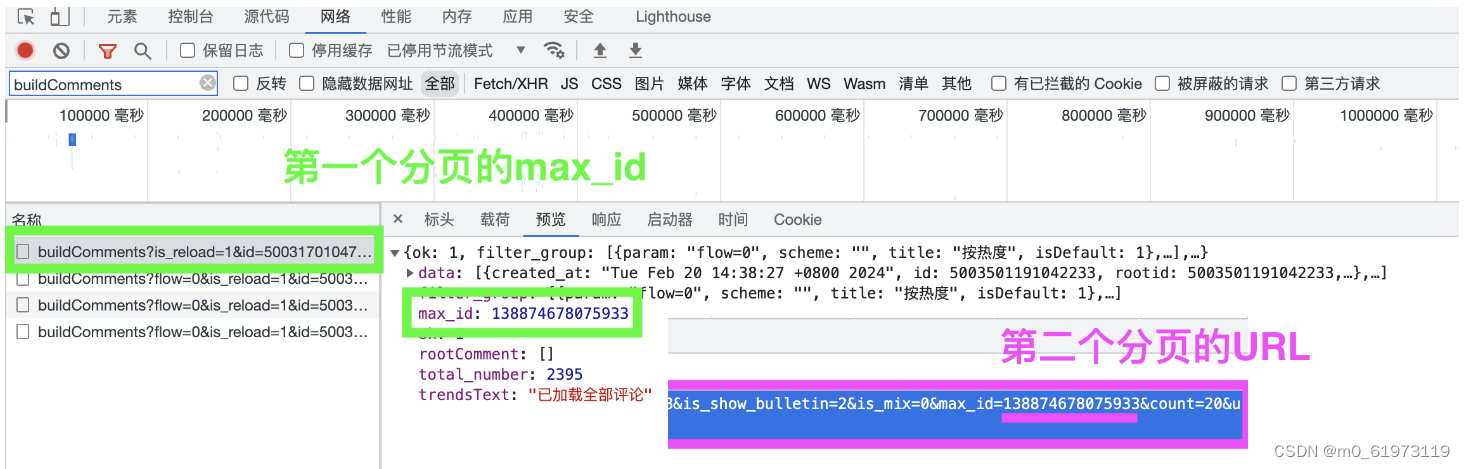
因此代码如下,
- import requests
- import csv
-
- f = open('评论.csv', mode='a', encoding='utf-8-sig', newline='')
- csv_write = csv.writer((f))
- csv_write.writerow(['id', 'screen_name', 'text_raw', 'like_counts', 'total_number', 'created_at'])
-
- # 请求头
- headers = {
- # 用户身份信息
- 'cookie': 'XSRF-TOKEN=ZcbKzr5C4_40k_yYwTHIEj7k; PC_TOKEN=4496aa7595; login_sid_t=e6e7e18ba091dcafc2013982ea8fa895; cross_origin_proto=SSL; WBStorage=267ec170|undefined; _s_tentry=cn.bing.com; UOR=cn.bing.com,weibo.com,cn.bing.com; Apache=1040794478428.4973.1713353134174; SINAGLOBAL=1040794478428.4973.1713353134174; ULV=1713353134177:1:1:1:1040794478428.4973.1713353134174:; wb_view_log=1287*8051.9891666173934937; SUB=_2A25LG8JKDeRhGeFJ71MX9S3Lzj2IHXVoWVuCrDV8PUNbmtANLVnQkW9Nf_9NjBaZTVOL8AH-RMG38C00YruaYRtp; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5kReTqg1GgdNOFZ.hiJO0G5NHD95QNS0BpSo-0S0-pWs4DqcjMi--NiK.Xi-2Ri--ciKnRi-zNS0MXeKqfe0MfeBtt; ALF=02_1715945242; WBPSESS=FH255CAr_cfIbZ29-Y520e5NsKBGpFZni0Bmim3vDfjXHIPxgSSGqvAfC_UQmc3W2RLUzLHkkX4YI-_Pn1KHeHJhkeHw5kFxeJYgMYDr9t5bvBCMRkcG_IvV3Y2XiVRlu9ZS91UwfD5AH5MY7jhkfw==',
- # 防盗链
- 'referer': 'https://weibo.com/6532102014/Oa6B7wW2i',
- # 浏览器基本信息
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'
- }
-
-
- def get_next(next='count=10'):
- url = f'https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=5024086457849590&is_show_bulletin=2&is_mix=0&{next}&count=20&uid=6532102014&fetch_level=0&locale=zh-CN'
- response = requests.get(url=url, headers=headers)
- json_data = response.json()
-
- data_list = json_data['data']
- max_id = json_data['max_id']
- for data in data_list:
- text_raw = data['text_raw']
- id = data['id']
- created_at = data['created_at']
- like_counts = data['like_counts']
- total_number = data['total_number']
- screen_name = data['user']['screen_name']
- print(id, screen_name, text_raw, like_counts, total_number, created_at)
-
- csv_write.writerow([id, screen_name, text_raw, like_counts, total_number, created_at])
-
- if max_id != 0:
- max_str = 'max_id=' + str(max_id)
- get_next(max_str)
-
- get_next()
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/665124
推荐阅读
相关标签

