
- 1Stable Diffusion AI绘画助力建筑设计艺术创新——城市建筑设计大模型分享
- 2YOLO算法改进Backbone系列之:GCVIT
- 3解码流程图_数字解码流程图
- 4Java基于Web的电子病历管理系统的实现(开题+源码)
- 5接口自动化测试实战之pytest框架+allure讲解!_pytest接口自动化实战讲解
- 6知识积累(五):Transformer 家族的学习笔记
- 7ffmpeg解封装rtsp并录制视频-(2)使用VLC模拟一个rtsp服务器并用ffmpeg解封装该rtsp流
- 8探索AI的无限可能:ChatGPT 3.5为您带来全新体验!
- 9厉害了!Flutter制霸全平台,新版将支持Windows应用程序!_flutter win7
- 10黄聪:通过 itms:services://? 在线安装ipa ,跨过appstore
开源向量数据库介绍
赞
踩
在开源矢量数据库的世界里,有些名字因其性能、灵活性和健壮性而脱颖而出。
1. Milvus
Milvus 由 Zilliz 推出,是一款高度可定制的开源矢量数据库,在处理大规模数据方面大放异彩。由于其出色的可扩展性,当你需要处理大量数据时,它是一个极佳的选择。Milvus 使非结构化数据搜索更易于访问,无论部署环境如何,都能提供一致的用户体验。

2. Faiss
Faiss 由 Facebook 的人工智能研究团队开发,是另一个令人印象深刻的向量数据库,擅长高维向量搜索。它以高效和快速著称,是时间敏感型应用的最佳选择。Faiss 是一个用于对密集向量进行高效相似性搜索和聚类的库。它包含的算法可搜索任何大小的向量集,甚至可能无法放入 RAM 的向量集。它还包含用于评估和参数调整的支持代码。Faiss 是用 C++ 编写的,并为 Python/numpy 提供了完整的封装。一些最有用的算法是在 GPU 上实现的。
3. Annoy (Approximate Nearest Neighbors Oh Yeah)
Annoy 由 Spotify 创建,是一个轻量级但功能强大的数据库。它专为快速搜索大型数据集而设计,非常适合需要快速得到结果的应用程序。它是一个带有 Python 绑定的 C++ 库,用于搜索空间中与给定查询点相近的点。它还能创建基于文件的大型只读数据结构,并将其映射到内存中,以便多个进程共享相同的数据。
4. Nmslib (Non-Metric Space Library)
Nmslib 是一个专门的开源矢量数据库,专注于非度量空间。对于那些需要更利基解决方案的独特项目来说,它是一个不错的选择。该项目的目标是为通用和非度量空间的搜索创建一个有效而全面的工具包。尽管该库包含各种度量空间访问方法,但其主要重点是通用和近似搜索方法,尤其是非度量空间的方法。NMSLIB 可能是第一个原则性支持非度量空间搜索的库。
5. Qdrant
Qdrant(读作:象限)是一种矢量相似性搜索引擎和矢量数据库。它提供了一种生产就绪的服务,具有方便的 API,可用于存储、搜索和管理带有附加有效载荷的点矢量Qdrant 专为扩展过滤支持而定制。Qdrant 是为扩展过滤支持而定制的,因此适用于各种基于神经网络或语义的匹配、分面搜索和其他应用。

Qdrant 由 Rust 编写,因此即使在高负载情况下也能快速可靠地运行。查看基准测试。
6. Chroma
Chroma 是开源嵌入式数据库。Chroma 使知识、事实和技能可插入 LLM,从而轻松构建 LLM 应用程序。Chroma 设计得足够简单,可以快速上手,也足够灵活,可以满足多种用例。您可以使用自己的嵌入模型,用自己的嵌入来查询 Chroma,并对元数据进行过滤。

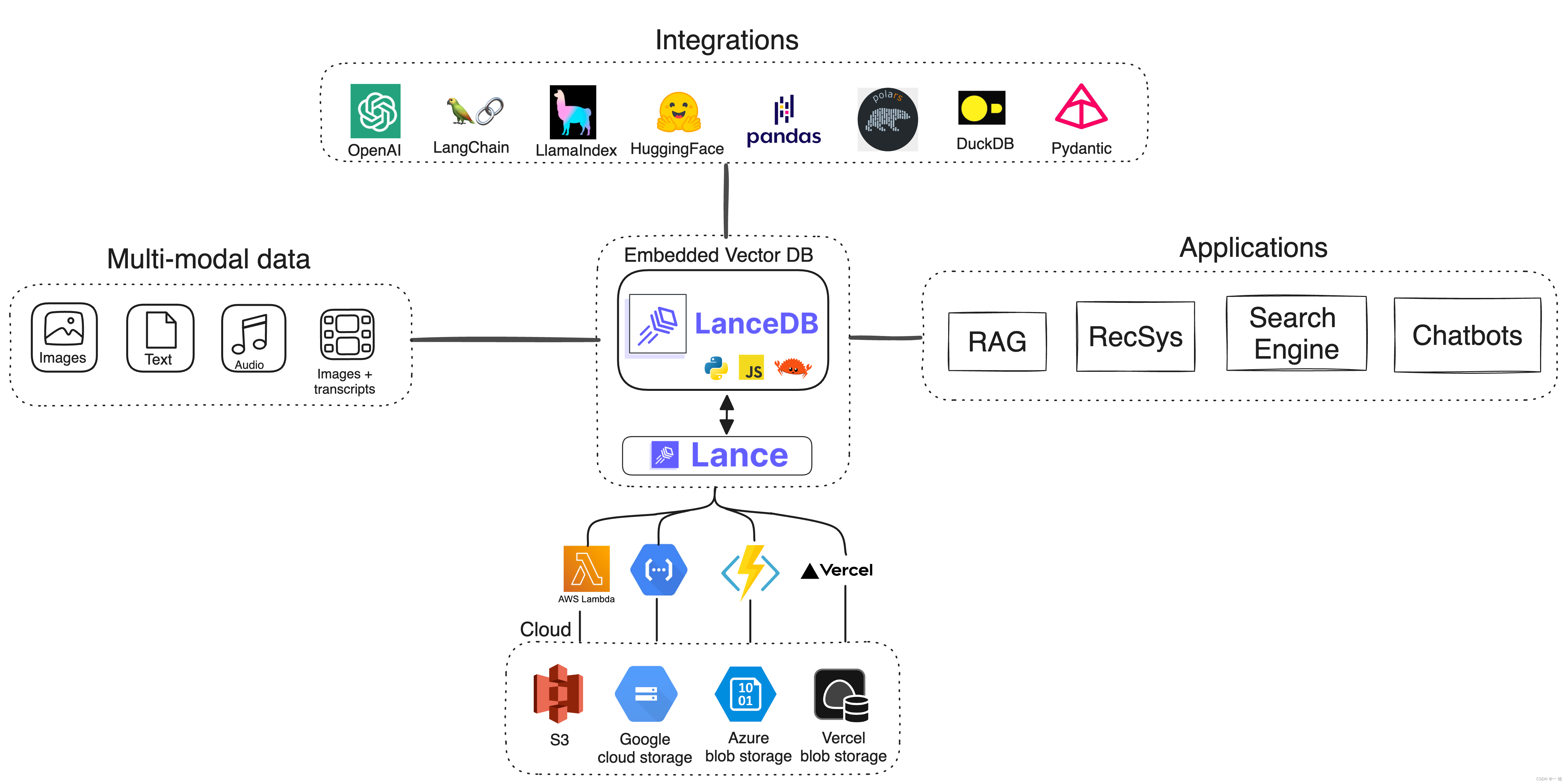
7. LanceDB
LanceDB 是一个用于向量搜索的开源数据库,采用持久存储,大大简化了嵌入的检索、过滤和管理。LanceDB 的核心是用 Rust 编写的,使用 Lance 构建,Lance 是一种开源列式格式,专为高性能 ML 工作负载而设计。LanceDB API 可与不断发展的 Python 和 Javascript 生态系统无缝协作。使用 DataFrames 操作数据,使用 Pydantic 构建模型,使用 LanceDB 存储和查询。
8. Vectra
Vectra 是一个适用于 Node.js 的本地矢量数据库,功能类似于 Pinecone 或 Qdrant,但使用本地文件构建。每个 Vectra 索引都是磁盘上的一个文件夹。文件夹中有一个 index.json 文件,其中包含该索引的所有矢量以及任何索引元数据。 创建索引时,您可以指定要索引的元数据属性,只有这些字段会存储在 index.json 文件中。项目的所有其他元数据都将存储在磁盘上的一个单独文件中,该文件的关键字为 GUID。
请记住,您的整个 Vectra 索引都会加载到内存中,因此它不太适合长期聊天机器人记忆等场景。为此,请使用真正的矢量数据库。
9. Vespa
Vespa 是一个开源平台,适用于需要对大型结构化、文本和矢量数据进行低延迟计算的应用程序。Vespa.ai 可用于在任何规模下利用大数据实时做出人工智能驱动的决策,并具有无与伦比的性能。

企业使用 vespa.ai 解决结构化、文本和矢量搜索以及实时推荐、个性化和目标定位等问题。该平台根据 Apache 2.0 许可开源,可从 vespa.ai 下载,或在 cloud.vespa.ai 作为无服务器托管服务使用。

