
- 1海思SD3403,SS928/926,hi3519dv500,hi3516dv500移植yolov7,yolov8(5)_ss928+yolov
- 2江大白 | 深入浅出,YOLOv8算法使用指南_yolov8 原文
- 3解密Spring Boot:深入理解条件装配与条件注解
- 4zookeeper集群配置以及特性
- 5iReport5.6中文PDF不显示或乱码的解决方法_ireport itextasian.jar 支持微软雅黑
- 6css引入方式有几种?link和@import有什么区别?
- 7OpenStack安装和配置存储节点_openstack存储节点
- 824上软考备考全流程梳理!软考小白报名必看(含资料)_软考高级备考时间
- 9乡村振兴的多元化产业发展:推动农村一二三产业融合发展,培育乡村新业态,打造多元化发展的美丽乡村
- 10MySQL基础之触发器,函数,存储过程_mysql触发器调用存储过程
Hadoop伪分布安装
赞
踩
1.虚拟机设置
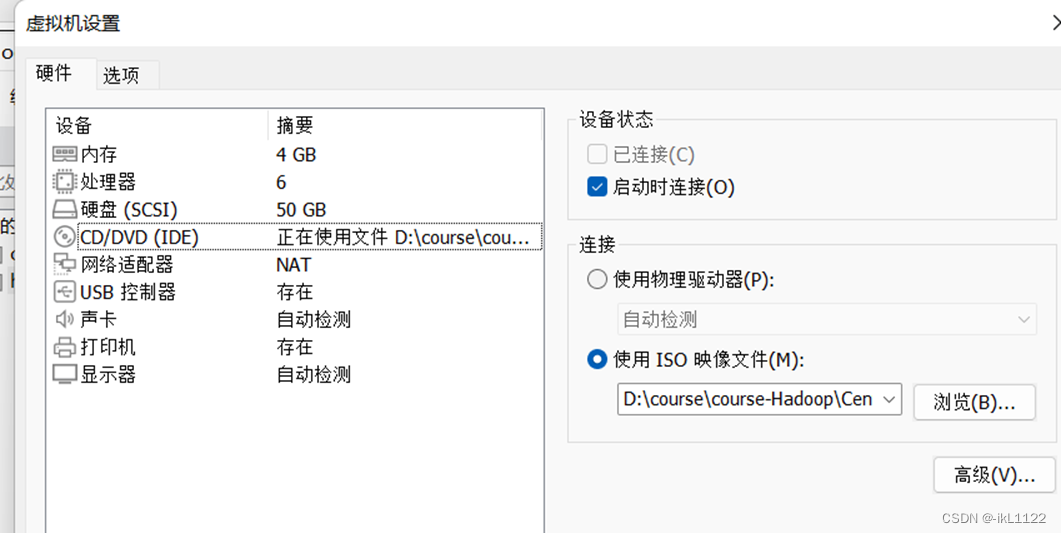
2.利用xshell7和xftp7解压jdk和hadoop并配置环境变量
 安装包统一解压到/usr/local/src目录下
安装包统一解压到/usr/local/src目录下

3.修改hdfs-site.xml等
进入hadoop所在配置文件目录,/usr/local/src/Hadoop-3.3.6/etc/Hadoop,在此目录打开终端
执行命令 vim hadoop-env.sh

vim core-stie.xm
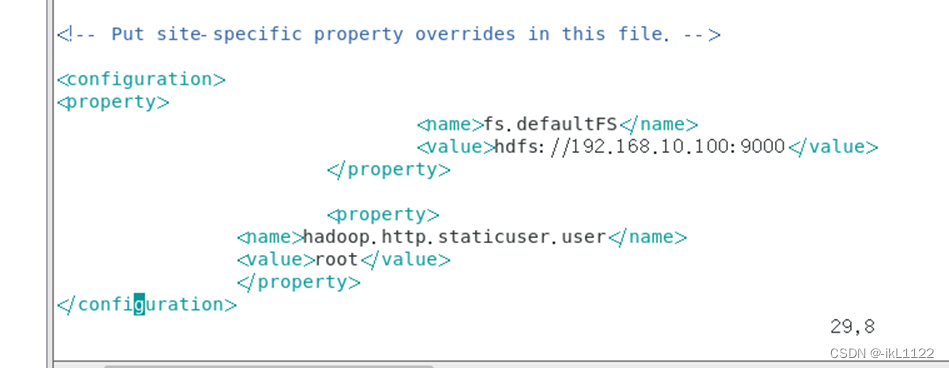
vim hdfs-stie.xml
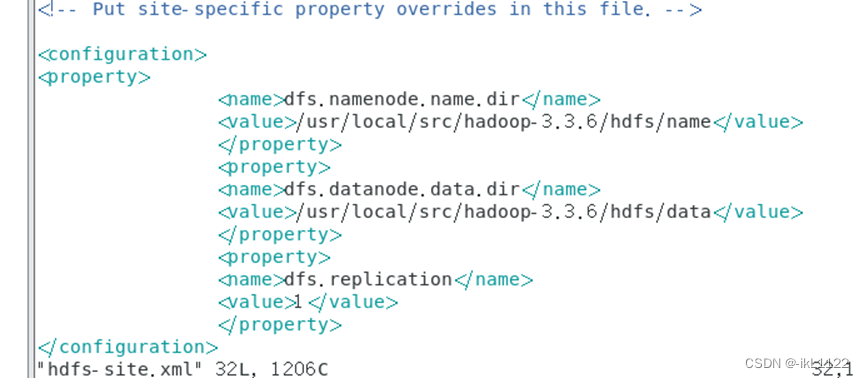
vim mapred-stie.xml
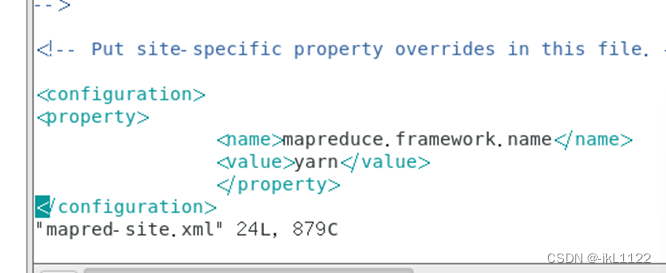
vim yarn-stie.xml
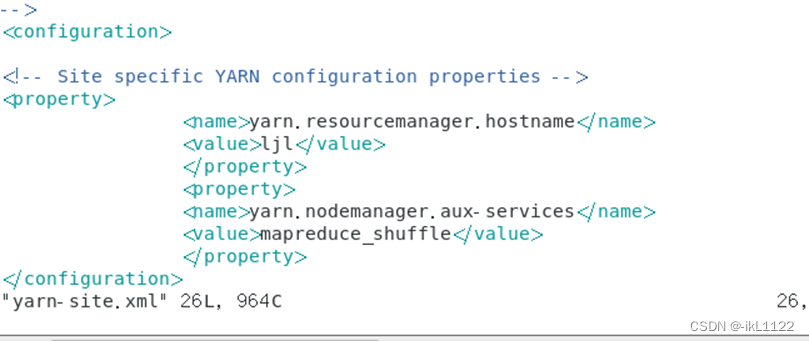 vim workers
vim workers

格式化集群hdfs namenode -format

- 若出现类似namenode is running as process 4070Stop it first and ensure /tmp/hadoop- root- namenode.pid file is empty before retry. ,要结束进程(stop- all.sh)再重新进行格式化。
4.成功启动集群截图(包括进程,web)
启动集群start-all.sh
 执行jps命令进行验证是否启动成功
执行jps命令进行验证是否启动成功

进行web访问, 打开浏览器,输入网址 192.168.10.100 主机:9870,访问成功。
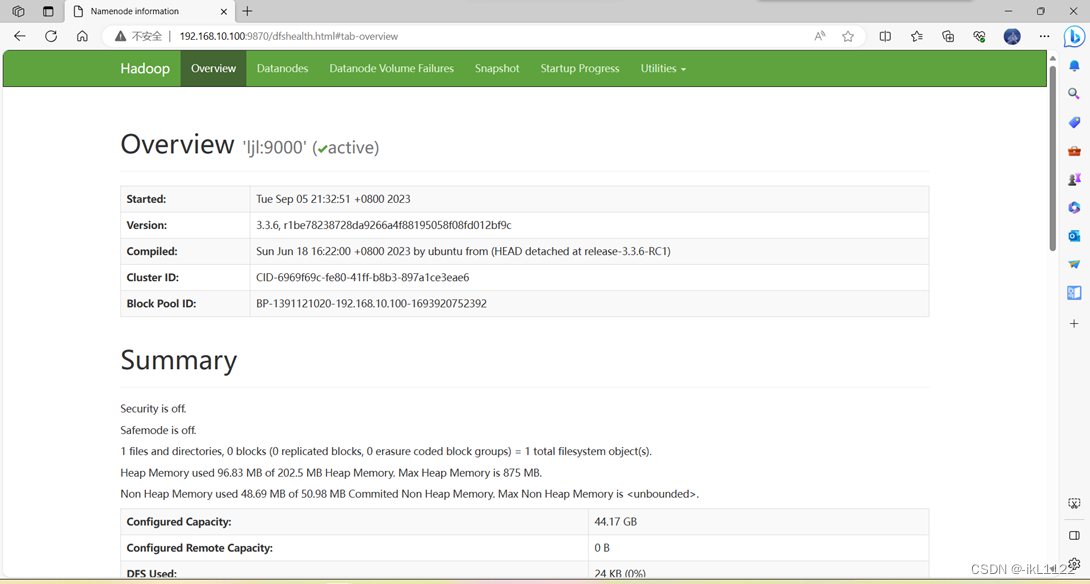
5.实验心得
| 在选择cpu的个数时,根据自己的物理机CPU个数决定,设置虚拟机处理器的数量时,处理器数量与每个处理器的内核数量乘积小于我的物理机CPU个数。电脑配置完毕后,安装系统时出现问题,原因是没有导入ISO映像文件,导入后根据引导界面安装系统。后来,在配置SSSH免密登录时开始报错,ssh: connect to host master port 22: Connection refused,后来csdn后最后解决,在配置伪分布式集群中格式化集群时,开始报错,进行jdk路径和hadoop路径修改后解决,启动集群执行jps命令进行验证时,只出现了四个进程,后将hadoop所在配置文件目录中的文件修改后成功启动所有进程,最后web访问,打开浏览器,输入192.168.10.100:9870,访问成功。其中遇到的困难有很多,也经过了很长时间,尝试很多方法才得以解决,最终成功启动集群。 |

