
- 1Filter实现登录后自动跳转目标url_filter 跳转到别的域名
- 2高途 前端开发 校招 一面面经_高途前端面试
- 3Python蓝桥杯真题——基础练习(一)_蓝桥杯python真题
- 4TypeError [ERR_UNKNOWN_FILE_EXTENSION] [ERR_UNKNOWN_FILE_EXTENSION]: Unknown file extension “.json“_typeerror [err_unknown_file_extension]: unknown fi
- 5HashSet的实现原理_说一下 hashset 的实现原理
- 6c语言函数的值传递机制(swap函数怎么通过形参改变实参的值)_值传递进行变换
- 7牛客算法周周练1补题_算法补题
- 8【Spring Boot】快速上手SpringBoot_spring boot】快速上手springboot_高朗的博客-csdn博客
- 9扒一扒传智播客深藏在背后的内幕_传智播客 贴吧
- 10企业级应用场景中,LLM 的数据特性剖析及处理对策_llm实现数据分析
机器学习大作业——基于DEAP数据集的脑电信号识别(DNN+CNN)_数据集分为训练集和测试集 那么优化器批量尺寸学习率是根据什么数据集的识别
赞
踩
目录
一、实验目的
1.1了解DEAP数据集的格式
1.2 熟悉深度深度神经网络DNN和卷积神经网络CNN
1.3 通过统计实验对获得的模型进行测试,以比较不同的模型
二、实验原理介绍
本部分首先将介绍本次实验采用的DEAP数据集,另外由于本次实验采用了两种不同的神经网络架构:具有完全连接层的深度神经网络(DNN)和卷积神经网络(CNN),只做了一些小的修改,本部分也将详细解释该模型的基本框架及这些模型中的训练技术。
2.1 数据集描述
本次实验采用的是DEAP数据集。DEAP是2014年发布的一个用于情绪分析的数据集。它是情感计算领域最大的公开数据集之一,还包含各种不同的生理和视频信号。
DEAP数据集由两部分组成:
(1)一个由120个一分钟音乐视频组成的数据库,每一个视频由14-16名志愿者根据效价、唤醒度和主导度进行评分。
(2)40个以上音乐视频的子集,每个视频具有32个参与者中每个参与者的相应EEG和生理信号。与第一部分一样,每个视频都是根据效价、唤醒和支配维度进行评分的。
由于完成时间有限,本次实验只使用了DEAP数据集的第二部分,其中包含EEG信号。
脑电信号是使用Biosemi ActiveTwo设备收集的,该设备记录了32个具有可配置采样率的脑电通道。
DEAP是在512Hz下收集的,但数据集的创建者也提供了EEG信号的预处理版本,下采样到128Hz,并应用了频率滤波器和其他有用的预处理步骤。
特别地,对于32个参与者中的每一个,存在以下预处理的信息:
•数据:一个40 x 40 x 8064的阵列,包含40个频道中每个频道和40个音乐视频中每个频道的8064个录音。每个视频每个频道有8064个录音,因为试验时间为63秒(3秒预审基线+60秒试验),采样率为128Hz(63 x 128=8064)。
•标签:一个40 x 4的数组,包含40个音乐视频中每个视频的效价、唤醒、支配和链接的注释。
下面展示的是准备DEAP数据集相关的部分代码。
2.2深度神经网络
2.2.1 关于DNN
DNN神经网络是一个具有3个隐藏层的深度神经网络。该体系结构的近似图形方案如图2所示,而每一层的确切细节如下图所示。

上图所描绘的神经元的数量仅用于表示,每层下方都报告了神经元的真实数量。表1展示的是深度神经网络架构,表2中报告了对于DEAP数据集用于训练的超参数、优化器和损失函数。
表1:深度神经网络架构
| Layer type | Layer params | Output shape |
| Flatten | - | 3168 |
| Dropout | p=0.25 | 3168 |
| Dense | in=3168,out=5000 | 5000 |
| Dropout | p=0.50 | 5000 |
| Dense | in=5000,out=500 | 500 |
| Dropout | p=0.50 | 500 |
| Dense | in=500,out=100 | 1000 |
| Dropout | p=0.50 | 1000 |
| Dense | in=1000,out=1 | 1 |
| Number of parameters=18'847'501 | ||
表2:DEAP数据集用于训练的超参数、优化器和损失函数等指标(DNN)
| metric | DEAP |
| Batch size | 310 |
| Epochs | 250 |
| Loss function | BCE |
| Optimizer | RMSProp |
| Learning rate | 0.0001 |
| Momentum | 0 |
2.2.2 网络模型代码实现

上述设计的是一个简单的深度神经网络(DNN)模型类,继承自 PyTorch 的 Module 类。该模型由几个线性层(全连接层)和一些激活函数、Dropout 层组成。
模型的主要组件是四个线性层(self.linear1, self.linear2, self.linear3, self.linear4),分别将输入特征映射到不同的维度。其中,self.linear4 是二元分类任务的最后一层,输出一个值,用于区分高价值和低价值情绪状态。
模型还包括三个 Dropout 层(self.dropout1, self.dropout2),用于随机丢弃部分神经元,以减少过拟合风险。激活函数 ReLU(self.relu)被应用于线性层之后,以增加模型的非线性能力。最后,使用 Flatten 层(self.flatten)将输入张量展平,并通过 forward 方法来定义前向传播过程。在前向传播中,输入首先经过 Flatten 层,然后通过每个线性层、激活函数和 Dropout 层的序列。
最终,模型返回最后一个线性层的输出张量,用于进行二元分类任务的预测。
2.3 卷积神经网络
2.3.1 关于CNN
卷积神经网络 (CNN) 是一种用于处理图像和声音等网格结构数据的前馈神经网络。它利用卷积运算提取输入数据的特征,使用池化操作来压缩特征图的尺寸。CNN 可以通过改变卷积核的参数来调整特征的维度。在卷积层后通常会应用非线性激活函数,如 ReLU,并可使用批量归一化、Dropout 等技术来提高模型性能。最后一层通常是全连接层,将特征转换为向量表示以进行分类或回归等任务。下图是CNN的架构:
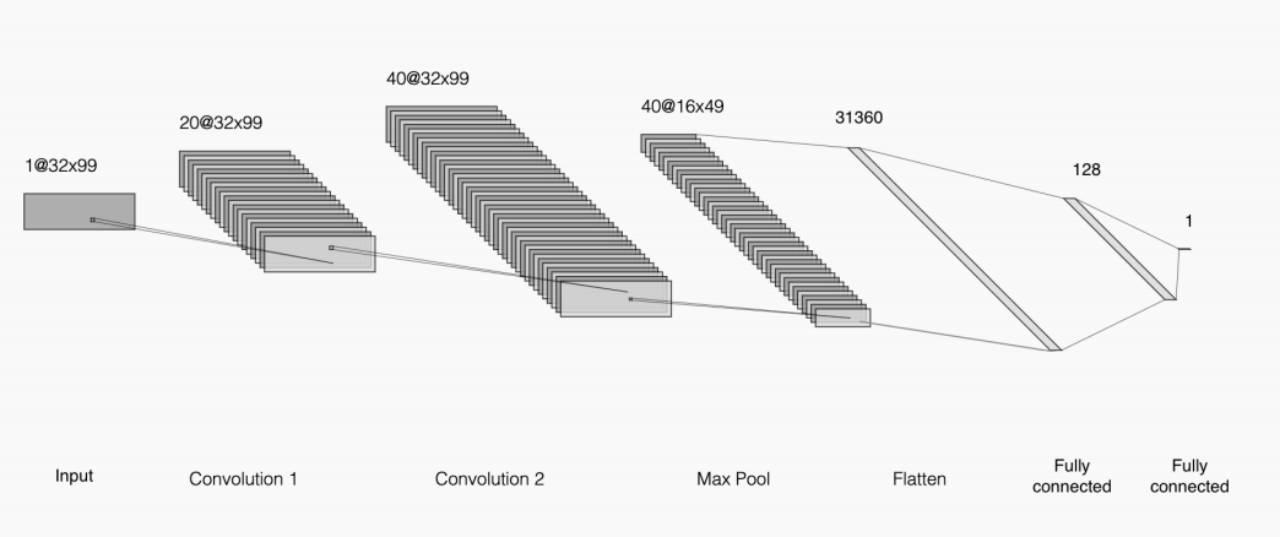
CNN模型利用卷积层,将数据视为形状为32 x 99的二维输入。
简而言之,该模型由两个卷积层组成,然后是最大池化层,最后是两个完全连接的层。卷积层将输入视为2D图像,通过卷积操作应用3x3滤波器。这种类型的层主要用于涉及图像的任务中。最大池化层用于减少数据的空间维度,在图像上滑动一个2x2的窗口,该窗口被减少到一个值:具有最高激活的神经元的值。最大池化减少了图像的空间维度,从而减少了最终完全连接层中所需的参数数量,并有助于网络避免过度拟合。
与DNN模型一样,CNN权重使用Xavier的正常技术进行初始化,偏差设置为0。表3中中报告了对于DEAP数据集用于训练的超参数、优化器和损失函数等。
表3:DEAP数据集用于训练的超参数、优化器和损失函数等指标(CNN)
| metric | DEAP |
| Batch size | 50 |
| Epochs | 250 |
| Loss function | BCE |
| Optimizer | SGD |
| Learning rate | 0.0001 |
| Momentum | 0.9 |
2.3.2 网络模型代码实现

在代码中我定义了一个名为CNN的类,继承自Module。该类实现了一个简单的卷积神经网络模型。在初始化方法中,首先定义了4个卷积层。其中,self.conv1是一个输入通道数为1,输出通道数为20的卷积层,卷积核大小为3x3,填充为1。self.conv2是一个输入通道数为20,输出通道数为40的卷积层,同样使用3x3的卷积核和1的填充。
接下来定义了一个最大池化层nn.MaxPool2d,使用2x2的窗口进行池化操作。
然后定义了两个全连接层self.linear1和self.linear2。self.linear1将输入的特征展平成一维向量,并将其映射到128维向量空间。self.linear2将128维向量映射为1维,用于二分类任务。在网络的前向传播方法forward中,首先对输入数据添加一个维度作为通道维度。然后通过self.dropout0对输入进行随机失活操作。
接下来通过卷积层self.conv1进行卷积操作,并通过ReLU激活函数进行非线性变换。随后再次应用self.dropout1进行随机失活,然后通过self.conv2进行卷积操作、ReLU激活函数和最大池化操作。之后通过self.flatten将特征图展平成一维向量,并通过self.dropout2进行随机失活。然后通过全连接层self.linear1进行线性变换和ReLU激活函数,并再次应用self.dropout3进行随机失活。
最后通过self.linear2进行线性变换,得到模型的输出。该模型总体上适用于二分类任务。
三、模型训练与测试
3.1数据预处理
在进行模型训练和测试前,对DEAP数据集进行处理。由于本次实验只使用了DEAP数据集中包含EEG信号的第二部分,数据维度已经降低。40个通道已被削减至32个,仅保留EEG信号,每个通道的8064个读数已减少至99个值。

预处理的具体过程如下:首先,通过循环遍历每位参与者(participant),并加载其数据。对每个参与者的数据进行以下操作:
①从原始数据中提取出32个EEG通道的数据,去除非EEG通道。

如图所示,已去除非EEG通道
②对通道数据进行全局标准化,即减去全局均值并除以全局标准差。
③使用reduce_dim函数对数据进行降维处理,将每个通道的数据从n_recordings维降至99维。
数据降维主要通过函数reduce_dim实现。下面是降维操作主要步骤:
·首先,根据输入数据的形状,确定分批处理的大小和总样本数。
·对每个通道的数据进行以下操作: a. 将8064个记录划分为10个批次(每个批次807个记录,第10个批次为801个记录)。 b. 针对每个批次,计算9个统计值,并将它们存储在处理后的数据中。这些统计值包括:平均值、中位数、最大值、最小值、标准差、方差、范围、偏度和峰度。 c. 对整个通道的数据也计算这9个统计值,并将它们存储在处理后的数据中的最后9个位置。
·最后,确保处理后的数据形状为(32, 99),并返回处理后的数据。
④对降维后的数据进行独立通道标准化,即分别将每个通道的数据减去该通道的均值并除以该通道的标准差。
⑤对所有通道的数据进行全局标准化,即减去总体均值并除以总体标准差。
即使用以下公式,在示例的基础上对这些汇总值进行标准化,得到0的平均值和1的标准偏差:

⑥提取情感标签(valence和arousal)。
关于情感标签:在情感分析中,valence和arousal通常用来描述情感状态的两个主要维度。Valence表示情感的好坏程度,范围通常从负面到正面,例如,沮丧、愤怒、快乐、满足等。Arousal表示情感的强度或活跃程度,范围通常从低到高,例如,冷静、放松、兴奋、惊恐等。
⑦将处理后的数据和标签保存为.dat文件。
⑧输出保存成功的信息。
经过数据预处理后,DEAP数据集的大小为1280,数据集形状为32*99。数据包含32个通道,每个通道有99个记录,而标签包含2个值(效价和唤醒)。
执行以上数据预处理处理步骤的文件在项目中以prepare deap.py的名称提供。
3.2 模型训练与测试
3.2.1训练前期准备
(1)配置文件读取
with open('deap_dnn_arousal.yml') as yaml_file:
config = yaml.load(yaml_file, Loader=yaml.FullLoader)
使用 PyYAML 库读取并解析名为 'deap_dnn_arousal.yml' 的配置文件,将配置信息存储在 config 字典中供后续使用。
配置文件常用于训练一个基于CNN模型的情感分类器来对DEAP数据集中的情感进行分类。其中包括使用dropout技术防止过拟合,设置随机种子,将数据集分为训练集和测试集,设定批量大小、学习率、动量、训练轮数和导出模型的路径等。此处给出配置文件 'deap_dnn_arousal.yml' 内容

从该配置文件中还可以看出此部分数据集中,训练集与测试集比例为(1180:100)
(2)超参数设置

从配置文件中获取训练相关的超参数,包括训练轮数、批量大小、学习率和动量。
(3)模型类型选择
model_type = config['MODEL']['model']
从配置文件中获取模型的类型,可以是 'dnn' 或 'cnn'。
(4)训练目标选择
classification_of = config['TRAIN']['classification_of']
获取训练目标的类型,例如 'arousal' 或 'valence'。
(5)数据集加载与划分
根据DEAP数据集的路径,使用自定义的 DEAP类加载数据集。

获取随机种子和训练集、测试集的划分比例。然后使用 PyTorch 的 random_split 函数将数据集划分为训练集和测试集,并设置相应的随机种子。
(6)模型初始化

根据模型类型选择并初始化相应的模型和优化器。如果是 'dnn',则使用自定义的 DNN 类创建模型,并使用 RMSprop 优化器;如果是 'cnn',则使用自定义的 CNN 类创建模型,并使用 SGD 优化器。
(7)模型权重初始化

此部分定义了一个函数 init_weights,用于初始化模型的权重。它会遍历模型的所有线性层(Linear)并使用 Xavier 正态分布初始化权重,同时将偏置项(bias)设置为零。
3.2.2训练模型的过程
- 关于train()函数

这个函数用于训练模型。它接受一个模型、训练集数据加载器、损失函数、优化器等参数,并可选地进行准确率检查和测试集评估。
在函数内部,首先将模型设置为训练模式,并初始化最佳测试集准确率为 0.0。然后,创建空列表以记录每个 epoch 的平均损失值和准确率。
接下来,开始循环训练。对于每个 epoch,初始化当前 epoch 的损失列表。
然后,对于训练集中的每个批次,使用模型进行预测,并根据分类目标选择正确的标签列。计算损失并将其添加到当前 epoch 的损失列表中。
清零优化器的梯度,进行反向传播和参数更新。在训练过程中,还会打印当前 epoch 和批次的信息。每个 epoch 结束后,计算平均损失值,并将其添加到列表中。如果设置了准确率检查,且达到检查的间隔,则进行训练集和测试集的准确率检查。
如果测试集的准确率超过了之前的最佳准确率,则保存当前模型。
循环结束后,输出换行符以美化输出,并根据是否存在最佳准确率来输出最佳的测试集准确率。如果有最佳准确率,则返回该准确率。
2.关于准确率的计算
上部分的准确率计算依据的是函数check_accuracy
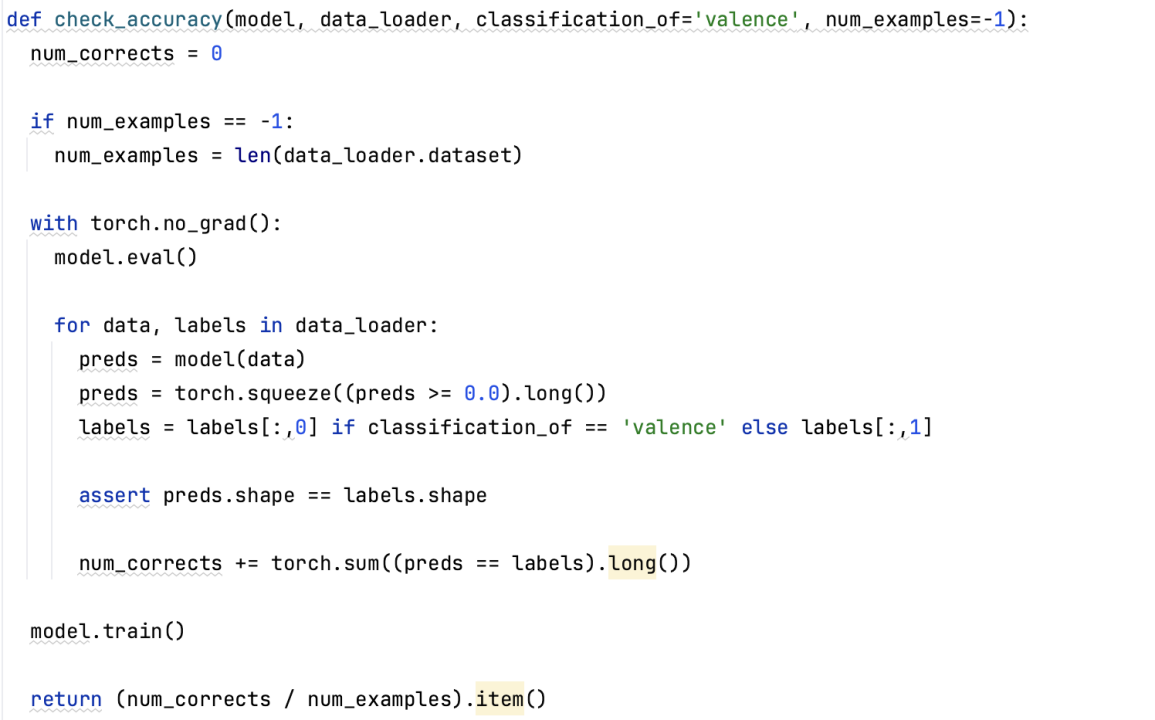
该函数用于计算模型在给定数据集上的准确率。它接受一个模型、数据加载器和一些可选参数(如分类目标、样本数量限制),并返回准确率。
在函数内部,首先初始化正确预测数目为 0,并根据需要设置样本数量限制。然后进入无梯度计算的上下文(torch.no_grad()),将模型设置为评估模式。
接下来,对于每个数据批次,使用模型进行预测,并将预测结果转换为二进制分类结果。根据分类目标选择正确的标签列,并确保预测结果和标签形状相同。
通过计算预测结果和标签相等的元素数量,累加得到正确预测的数目。最后,将模型设置回训练模式,并返回准确率。
3.关于测试集的准确度评估
在每个 epoch 的训练过程中,当满足 do_check_accuracy 为 True 并且当前 epoch 是检查准确率的间隔(根据 check_accuracy_every 参数指定)时,会执行准确率评估的代码块。
首先,会对训练集进行准确率评估,并打印出结果。接着,会对测试集进行准确率评估,并打印出结果。最后,会将测试集的准确率添加到 accuracy_per_epoch 列表中,并判断是否超过之前的最佳准确率。如果是,则保存当前模型。因此,测试集的准确率结果会在每个 epoch 的训练过程中输出,并保存在 accuracy_per_epoch 列表中供后续使用。
四、实验结果与分析
在本次实验中,每个数据集被分为两个子集:训练部分和测试部分。对于这个实验,模型已经在数据集的训练部分上进行了训练,并在相应数据集的测试集上进行了测试。
4.1二元价态分类结果
本次实验结果是采用固定训练集/测试集分割样本后的结果。
DNN和CNN模型在DEAP数据集上进行价值分类的结果,随着epoch的增加,测试的准确率变化如下图所示:
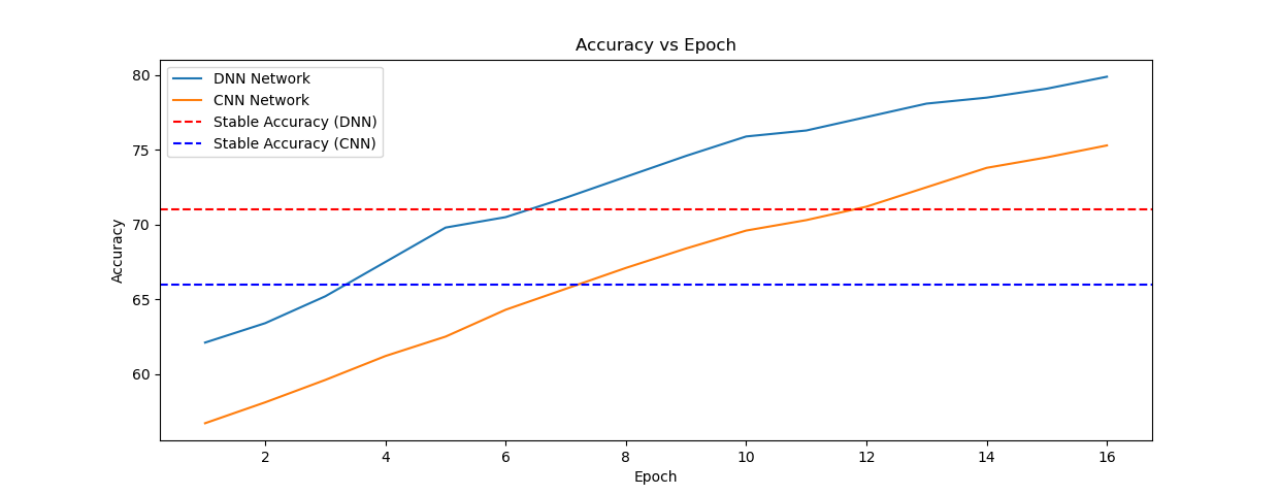
从上图可以看出,DNN模型在DEAP数据集上的分类结果似乎都优于CNN模型。
使用DNN模型分类的准确率在62%~79%之间,而使用CNN模型的分类准确率在56%~75%之间。
4.2 使用K折交叉验证对模型进行评估
此技术的主要思想是将数据集划分为相同大小的K个折叠(如果可能的话),然后,依次将每个折叠用作测试集,而数据集的其余部分用作训练集。对K个模型进行训练并评估其准确性,最后K次交叉验证的最终报告准确性是这些准确性的平均值。DEAP的32倍交叉验证结果如下图所示:

使用K-fold交叉验证发现的准确性远低于使用固定训练/测试分割发现的准确性。因此,可以说,模型存在高方差误差,即其性能与特定的训练和提供给它们的测试集高度相关。对于上图的结果,在数据集上操作的训练/测试分割很可能是“幸运”的分割,偶然产生了高精度。
在K折叠交叉验证过程中获得的特定折叠精度也证实了高方差猜想。例如,在DEAP上DNN模型的K-fold运行中,fold准确率从43%到78%不等,这表明不同的数据集分割如何从根本上改变准确率结果。
K-fold结果也证实了之前的结果,即CNN模型在两个数据集上都略优于DNN模型,而当在单个训练/测试分割上进行评估时,DNN模型能够达到更高的最大精度。
五、实验总结
本次实验我们基于DEAP数据集进行二分类脑电信号识别,采用的网络模型是深度神经网络和卷积神经网络。由于之前未接触过这方面的训练,我在最开始做本次实验时有种无从下手的感觉。因此本次实验的很多思路都是借鉴于期刊论文中的做法,例如对数据的处理思路,对模型的训练方式等。但完成本次实验后,还是得到了不少的收获。首先,我对深度神经网络和卷积神经网络有了更深的理解,理论课上只是学习了关于CNN的一些知识和运算,而通过本次实践,真正感受到了神经网络的强大和奇妙;其次,我对科研的严谨性有了更深的体会。对于每一个问题,都尝试运用不同的模型去得到结果,然后进行对比和考量,选择最优的方法。又或者将几种模型集成,得到一个更优的模型,这与理论课上学习的集成学习思想很类似。最后,本次实验也让我深知科研训练的必要性。不仅是在知识的融会贯通上,还是能力的提升上,进行相关科研训练都是十分有益的。在今后,我也将花更多的时间去锻炼自己的科研能力,努力提高自己的科研素养!
附录:实验代码
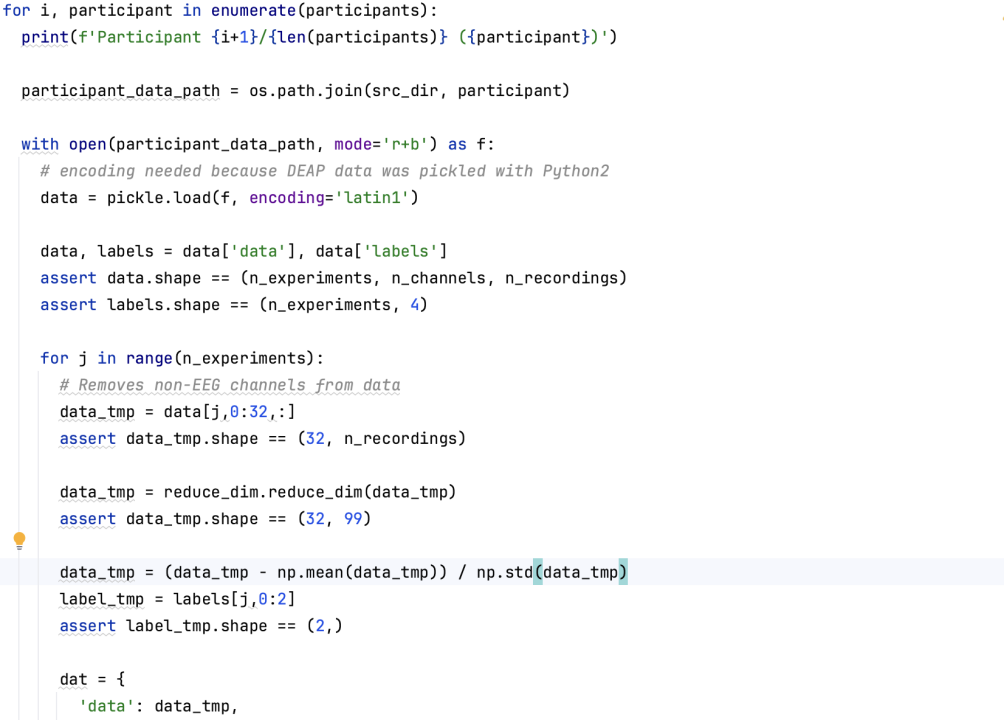
prepare_deap.py
- import os, pickle, math
- import numpy as np
- import reduce_dim
- src_dir = '/Users/peach/Desktop/DEAP/data_preprocessed_python/'
- dst_dir = '/Users/peach/Desktop/DEAP/deap_preprocessed_standardized_global/'
- n_experiments = 40 # experiment per participant
- n_channels = 40 # channel per experiment
- n_recordings = 8064 # recordings per channel
- participants = os.listdir(src_dir)
- participants.sort()
- assert len(participants) == 32 # DEAP has 32 participants
- tot_experiments = 40 * 32
- exported_experiments = 0
- for i, participant in enumerate(participants):
- print(f'Participant {i+1}/{len(participants)} ({participant})')
- participant_data_path = os.path.join(src_dir, participant)
- with open(participant_data_path, mode='r+b') as f:
- # encoding needed because DEAP data was pickled with Python2
- data = pickle.load(f, encoding='latin1')
- data, labels = data['data'], data['labels']
- assert data.shape == (n_experiments, n_channels, n_recordings)
- assert labels.shape == (n_experiments, 4)
- for j in range(n_experiments):
- # Removes non-EEG channels from data
- data_tmp = data[j,0:32,:]
- assert data_tmp.shape == (32, n_recordings)
- data_tmp = reduce_dim.reduce_dim(data_tmp)
- assert data_tmp.shape == (32, 99)
- data_tmp = (data_tmp - np.mean(data_tmp)) / np.std(data_tmp)
- label_tmp = labels[j,0:2]
- assert label_tmp.shape == (2,)
- dat = {
- 'data': data_tmp,
- 'labels': label_tmp,
- }
- dat_file_path = os.path.join(dst_dir, f'{i+1}_{j+1}.dat')
- with open(dat_file_path, mode='w+b') as dat_file:
- pickle.dump(dat, dat_file)
- print(f'{dat_file_path} exported successfully.')
- exported_experiments += 1
- print('Done.')
- print(f'Exported {exported_experiments} experiments out of {tot_experiments}.')
reduce_dim.py
- import numpy as np
- import scipy.stats as sp
- def reduce_dim(data):
- assert (data.shape == (32, 8064) or data.shape == (32, 8064*2))
- processed_data = np.zeros((32, 99))
- for channel_n in range(32):
- # Divide the 8064 recordings in 10 batches of 807 (10th batch: 801)
- if data.shape == (32, 8064):
- batch_size = 807
- n_samples = 8064
- elif data.shape == (32, 8064*2):
- batch_size = 807 * 2
- n_samples = 8064 * 2
- batch_n = 0
- for batch_n in range(10):
- if batch_n != 9:
- batch = data[channel_n,(batch_n*batch_size):(batch_n*batch_size+batch_size)]
- else:
- batch = data[channel_n,(batch_n*batch_size):n_samples]
- processed_data[channel_n,(batch_n * 9):(batch_n * 9 + 9)] = np.array([
- np.mean(batch),
- np.median(batch),
- np.max(batch),
- np.min(batch),
- np.std(batch),
- np.var(batch),
- np.max(batch) - np.min(batch),
- sp.skew(batch),
- sp.kurtosis(batch),
- ])
- processed_data[channel_n,90:99] = np.array([
- np.mean(data[channel_n,:]),
- np.median(data[channel_n,:]),
- np.max(data[channel_n,:]),
- np.min(data[channel_n,:]),
- np.std(data[channel_n,:]),
- np.var(data[channel_n,:]),
- np.max(data[channel_n,:]) - np.min(data[channel_n,:]),
- sp.skew(data[channel_n,:]),
- sp.kurtosis(data[channel_n,:]),
- ])
- assert processed_data.shape == (32, 99)
- return processed_data
datasets.py
- import os, pickle, torch
- from torch.utils.data import Dataset
- n_channels = 32
- n_recordings = 99
- # High val = 708, low val = 572
- # High ar = 737, low ar = 543
- class DEAP(Dataset):
- def __init__(self, dataset_path):
- self.dataset_path = dataset_path
- self.sessions = os.listdir(dataset_path)
- # remove .DS_Store if present
- if '.DS_Store' in self.sessions:
- self.sessions.remove('.DS_Store')
- def __len__(self):
- return len(self.sessions)
- def __getitem__(self, index):
- file_path = os.path.join(self.dataset_path, self.sessions[index])
- with open(file_path, mode='rb') as file:
- session = pickle.load(file)
- data, labels = session['data'], session['labels']
- data, labels = torch.from_numpy(data), torch.from_numpy(labels)
- data, labels = data.float(), labels.float()
- # 1 = high value, 0 = low value
- labels = (labels >= 5.0).long()
- assert data.shape == (n_channels, n_recordings)
- assert labels.shape == (2,)
- return data, labels
models.py
- from torch import nn
- n_channels = 32
- n_recordings = 99
- class DNN(nn.Module):
- def __init__(self, sizes=(5000, 500, 1000), dropout_probs=(0.25, 0.5)):
- super(DNN, self).__init__()
- self.linear1 = nn.Linear(n_channels * n_recordings, sizes[0])
- self.linear2 = nn.Linear(sizes[0], sizes[1])
- self.linear3 = nn.Linear(sizes[1], sizes[2])
- self.linear4 = nn.Linear(sizes[2], 1) # binary classification: high vs low
- self.dropout1 = nn.Dropout(dropout_probs[0])
- self.dropout2 = nn.Dropout(dropout_probs[1])
- self.relu = nn.ReLU()
- self.flatten = nn.Flatten(start_dim=1)
- def forward(self, x):
- x = self.flatten(x)
- x = self.dropout1(x)
- x = self.linear1(x)
- x = self.relu(x)
- x = self.dropout2(x)
- x = self.linear2(x)
- x = self.relu(x)
- x = self.dropout2(x)
- x = self.linear3(x)
- x = self.relu(x)
- x = self.dropout2(x)
- x = self.linear4(x)
- return x
- class CNN(nn.Module):
- def __init__(self, dropout_probs=(0.25, 0.15, 0.5, 0.25)):
- super(CNN, self).__init__()
- self.conv1 = nn.Conv2d(1, 20, (3, 3), padding=(1, 1))
- self.conv2 = nn.Conv2d(20, 40, (3, 3), padding=(1, 1))
- self.maxpool = nn.MaxPool2d((2, 2))
- self.linear1 = nn.Linear(40 * 16 * 49, 128)
- self.linear2 = nn.Linear(128, 1)
- self.tanh = nn.Tanh()
- self.relu = nn.ReLU()
- self.dropout0 = nn.Dropout(dropout_probs[0])
- self.dropout1 = nn.Dropout2d(dropout_probs[1])
- self.dropout2 = nn.Dropout(dropout_probs[2])
- self.dropout3 = nn.Dropout(dropout_probs[3])
- self.flatten = nn.Flatten(start_dim=1)
- self.softplus = nn.Softplus()
- def forward(self, x):
- x = x[:,None,:,:] # add dummy dim for channel
- x = self.dropout0(x)
- x = self.relu(self.conv1(x))
- x = self.dropout1(x)
- x = self.relu(self.conv2(x))
- x = self.dropout1(x)
- x = self.maxpool(x)
- x = self.flatten(x)
- x = self.dropout2(x)
- x = self.relu(self.linear1(x))
- x = self.dropout3(x)
- x = self.linear2(x)
- return x
train.py
- # Imports
- import torch, yaml, os
- from torch.utils.data import DataLoader, random_split
- from datasets import DEAP, MAHNOB
- from models import DNN, CNN
- from utils import check_train_test_split_balanced
- from train_utils import train
- # Read configs
- with open('deap_dnn_arousal.yml') as yaml_file:
- config = yaml.load(yaml_file, Loader=yaml.FullLoader)
- # Hyperparams
- num_epochs = config['TRAIN']['num_epochs']
- batch_size = config['TRAIN']['batch_size']
- lr = config['TRAIN']['lr']
- momentum = config['TRAIN']['momentum']
- # Model
- model_type = config['MODEL']['model']
- # Train
- classification_of = config['TRAIN']['classification_of']
- # Dataset
- dataset_to_use = config['DATASET']['dataset_to_use']
- # Export
- model_path = config['EXPORT']['model_path']
- model_name = f'{dataset_to_use}-{model_type}-{classification_of}'
- if dataset_to_use == 'deap':
- dataset_path = config['DATASET']['deap_dataset_path']
- dataset = DEAP(dataset_path)
- elif dataset_to_use == 'mahnob':
- dataset_path = config['DATASET']['mahnob_dataset_path']
- dataset = MAHNOB(dataset_path)
- else:
- assert False
- # check_dataset_balanced(dataset_path)
- seed = config['TRAIN']['seed']
- train_set_size, test_set_size = config['TRAIN']['train_test_split']
- train_set, test_set = random_split(
- dataset,
- [train_set_size, test_set_size],
- generator=torch.Generator().manual_seed(seed)
- )
- print(f'{len(dataset)} examples found ({train_set_size} train, {test_set_size} test)')
- train_loader = DataLoader(
- train_set,
- batch_size=batch_size,
- shuffle=True
- )
- test_loader = DataLoader(
- test_set,
- batch_size=batch_size,
- shuffle=True
- )
- check_train_test_split_balanced(train_loader, test_loader)
- # Model
- if model_type == 'dnn':
- model = DNN(
- sizes=tuple(config['MODEL']['sizes']),
- dropout_probs=tuple(config['MODEL']['dropout_probs'])
- )
- optimizer = torch.optim.RMSprop(model.parameters(), lr=lr)
- elif model_type == 'cnn':
- model = CNN(dropout_probs=tuple(config['MODEL']['dropout_probs']))
- optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)
- else:
- assert False
- def init_weights(m):
- if isinstance(m, torch.nn.Linear):
- torch.nn.init.xavier_normal_(m.weight)
- m.bias.data.fill_(0.0)
- model.apply(init_weights)
- # Launch training
- best_acc_test_set = train(
- model,
- train_loader,
- torch.nn.BCEWithLogitsLoss(),
- optimizer,
- classification_of=classification_of,
- num_epochs=num_epochs,
- do_check_accuracy=True,
- check_accuracy_every=1,
- test_loader=test_loader,
- model_path=model_path,
- model_name=model_name,
- )
- os.system(f'say Best test accuracy {(best_acc_test_set*100):.2f}%')
train.py
- # Imports
- import torch, yaml, os
- from torch.utils.data import DataLoader, random_split
- from datasets import DEAP, MAHNOB
- from models import DNN, CNN
- from utils import check_train_test_split_balanced
- from train_utils import train
- # Read configs
- with open('deap_dnn_arousal.yml') as yaml_file:
- config = yaml.load(yaml_file, Loader=yaml.FullLoader)
- # Hyperparams
- num_epochs = config['TRAIN']['num_epochs']
- batch_size = config['TRAIN']['batch_size']
- lr = config['TRAIN']['lr']
- momentum = config['TRAIN']['momentum']
- # Model
- model_type = config['MODEL']['model']
- # Train
- classification_of = config['TRAIN']['classification_of']
- # Dataset
- dataset_to_use = config['DATASET']['dataset_to_use']
- # Export
- model_path = config['EXPORT']['model_path']
- model_name = f'{dataset_to_use}-{model_type}-{classification_of}'
- if dataset_to_use == 'deap':
- dataset_path = config['DATASET']['deap_dataset_path']
- dataset = DEAP(dataset_path)
- elif dataset_to_use == 'mahnob':
- dataset_path = config['DATASET']['mahnob_dataset_path']
- dataset = MAHNOB(dataset_path)
- else:
- assert False
- # check_dataset_balanced(dataset_path)
- seed = config['TRAIN']['seed']
- train_set_size, test_set_size = config['TRAIN']['train_test_split']
- train_set, test_set = random_split(
- dataset,
- [train_set_size, test_set_size],
- generator=torch.Generator().manual_seed(seed)
- )
- print(f'{len(dataset)} examples found ({train_set_size} train, {test_set_size} test)')
- train_loader = DataLoader(
- train_set,
- batch_size=batch_size,
- shuffle=True
- )
- test_loader = DataLoader(
- test_set,
- batch_size=batch_size,
- shuffle=True
- )
- check_train_test_split_balanced(train_loader, test_loader)
- # Model
- if model_type == 'dnn':
- model = DNN(
- sizes=tuple(config['MODEL']['sizes']),
- dropout_probs=tuple(config['MODEL']['dropout_probs'])
- )
- optimizer = torch.optim.RMSprop(model.parameters(), lr=lr)
- elif model_type == 'cnn':
- model = CNN(dropout_probs=tuple(config['MODEL']['dropout_probs']))
- optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)
- else:
- assert False
- def init_weights(m):
- if isinstance(m, torch.nn.Linear):
- torch.nn.init.xavier_normal_(m.weight)
- m.bias.data.fill_(0.0)
- model.apply(init_weights)
- # Launch training
- best_acc_test_set = train(
- model,
- train_loader,
- torch.nn.BCEWithLogitsLoss(),
- optimizer,
- classification_of=classification_of,
- num_epochs=num_epochs,
- do_check_accuracy=True,
- check_accuracy_every=1,
- test_loader=test_loader,
- model_path=model_path,
- model_name=model_name,
- )
- os.system(f'say Best test accuracy {(best_acc_test_set*100):.2f}%')
train_util.py
- import torch
- import numpy as np
- from utils import save_model
- def check_accuracy(model, data_loader, classification_of='valence', num_examples=-1):
- num_corrects = 0
- if num_examples == -1:
- num_examples = len(data_loader.dataset)
- with torch.no_grad():
- model.eval()
- for data, labels in data_loader:
- preds = model(data)
- preds = torch.squeeze((preds >= 0.0).long())
- labels = labels[:,0] if classification_of == 'valence' else labels[:,1]
- assert preds.shape == labels.shape
- num_corrects += torch.sum((preds == labels).long())
- model.train()
- return (num_corrects / num_examples).item()
- def train(
- model,
- train_loader,
- criterion,
- optimizer,
- classification_of='valence',
- num_epochs=100,
- do_check_accuracy=True,
- test_loader=None,
- model_path=None,
- model_name=None,
- check_accuracy_every=50
- );
- model.train()
- best_acc_test_set = 0.0
- avg_loss_per_epoch = []
- accuracy_per_epoch = []
- for epoch_n in range(1, num_epochs+1):
- epoch_losses = []
- for batch_i, (data, labels) in enumerate(train_loader, start=1):
- preds = torch.squeeze(model(data))
- labels = labels[:,0].float() if classification_of == 'valence' else labels[:,1].float()
- loss = criterion(preds, labels)
- if len(data) == train_loader.batch_size:
- epoch_losses.append(loss.item())
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- print(f'\rEPOCH {epoch_n}/{num_epochs}: batch {batch_i}: {loss:.3f}', end='')
- avg_epoch_loss = np.mean(epoch_losses)
- avg_loss_per_epoch.append(avg_epoch_loss)
- print(f' (Avg epoch loss = {avg_epoch_loss:.3f})', end='')
- if do_check_accuracy and epoch_n % check_accuracy_every == 0:
- if test_loader == None or model_path == None or model_name == None:
- assert False
- print('\nChecking accuracy on training set... ', end=' ')
- acc_train_set = check_accuracy(model, train_loader, classification_of=classification_of)
- print(f'{(acc_train_set*100):.2f}%')
- print('Testing accuracy on test set...', end=' ')
- acc_test_set = check_accuracy(model, test_loader, classification_of=classification_of)
- print(f'{(acc_test_set * 100):.2f}%')
- accuracy_per_epoch.append(acc_test_set)
- if acc_test_set > best_acc_test_set:
- save_model(model, model_path=model_path, model_name=model_name)
- best_acc_test_set = acc_test_set
- print('\n')
- if best_acc_test_set != 0.0:
- print(f'Best accuracy on test set: {(best_acc_test_set*100):.2f}%')
- return best_acc_test_set
写于2024-1-17

