
- 1 拒绝“割韭菜”— 谈谈区块链正经的商用场景!
- 2项目分享:基于微信小程序的点餐系统设计与实现_国内外微信小程序的医院食堂点餐系统研究现状
- 32024年6月12日Arxiv机器学习相关论文_deformtime:多元时间序列预测的混合信道方法
- 4OpenAI收购5人远程协作公司
- 5HarmonyOS NEXT 使用Web组件预览PDF文件实现案例_鸿蒙 pdf预览
- 621-阴影映射_samplecmplevelzero
- 7使用cv2.applyColorMap画热力图_cv2绘制热力图
- 8【华为OD机试真题 C语言】469、测试用例执行计划 | 机试真题+思路参考+代码解析(C卷)
- 9ora-65096解决方案
- 10LlamaFactory-Ollama-Langchain大模型训练-部署一条龙_ollama langchain 微调模型
大数据从入门到精通(超详细版)之Hive的案例实战,ETL数据清洗!!!_hive多维统计分析案例实战
赞
踩
前言
嗨,各位小伙伴,恭喜大家学习到这里,不知道关于大数据前面的知识遗忘程度怎么样了,又或者是对大数据后面的知识是否感兴趣,本文是《大数据从入门到精通(超详细版)》的一部分,小伙伴们如果对此感谢兴趣的话,推荐大家按照大数据学习路径开始学习哦。
以下就是完整的学习路径哦。
前面我们已经学习完了Hive的各自基本操作与基础知识,本文主要介绍Hive的实战篇章,主要关于真实环境下会遇到的各种问题,其中主要是Hive的数据清洗工作。
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
推荐大家认真学习哦!!!

需求分析
聊天平台每天都会有大量的用户在线,会出现大量的聊天数据,通过对聊天数据的统计分析,可以更好的**对用户构建精准的用户画像,**为用户提供更好的服务以及实现高ROI的平台运营推广,给公司的发展决策提供精确的数据支撑。
我们将基于一个社交平台App的用户数据,完成相关指标的统计分析并结合BI工具对指标进行可视化展现。
基于Hadoop和Hive实现聊天数据统计分析,构建聊天数据分析报表
需求:
- 统计今日总消息量
- 统计今日每小时消息量、发送和接收用户数
- 统计今日各地区发送消息数据量
- 统计今日发送消息和接收消息的用户数
- 统计今日发送消息最多的Top10用户
- 统计今日接收消息最多的Top10用户
- 统计发送人的手机型号分布情况
- 统计发送人的设备操作系统分布情况
数据准备
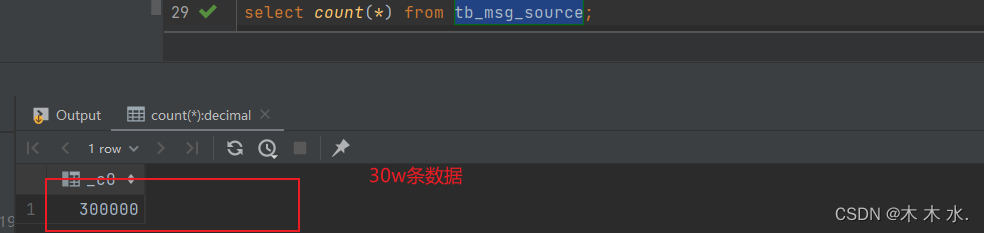
- 数据大小:30万条
- 数据列分隔符:Hive默认分隔符’\001’
- 数据字典及样例数据

上传数据:
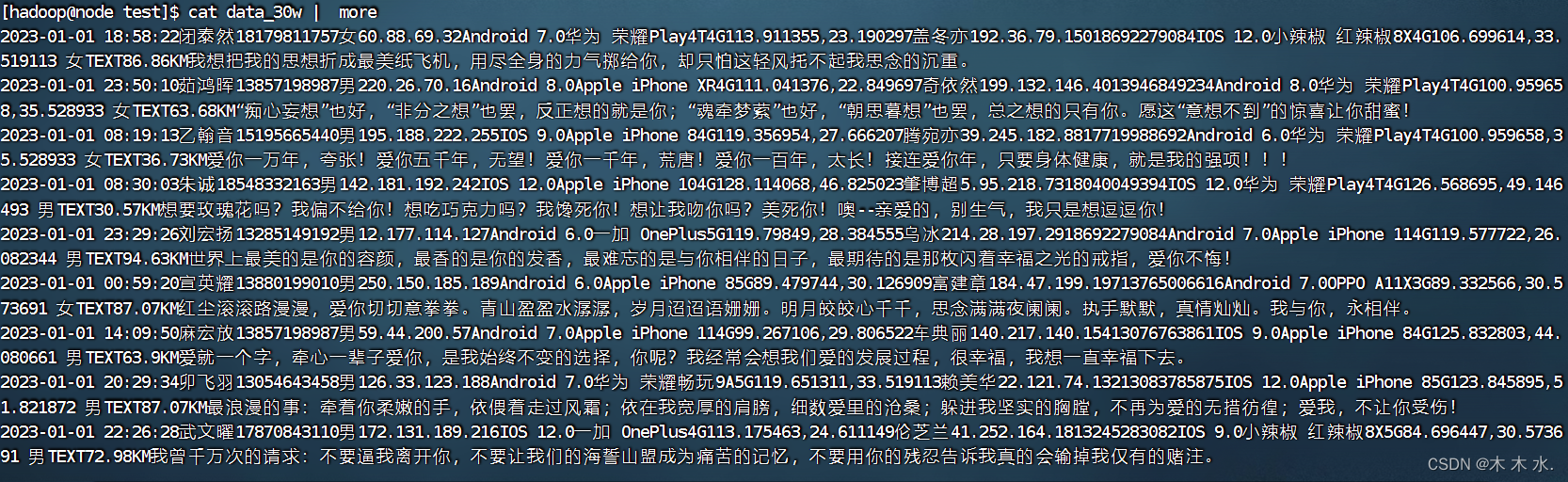
##先查看数据的大致样式
cat data_30w | more
- 1
- 2
将数据导入Hive当中:
##创建HDFS目录下的/chat/demo
hdfs dfs -mkdir -p /chatdemo/data
##将本地数据上传上去
hdfs dfs -put data_30w /chatdemo/data
- 1
- 2
- 3
- 4
建库建表
-
–如果数据库已存在就删除
drop database if exists db_msg cascade ;- 1
-
–创建数据库
create database db_msg ;- 1
-
–切换数据库
use db_msg ;- 1
-
–列举数据库
show databases ;- 1
-
–如果表已存在就删除
drop table if exists db_msg.tb_msg_source ;- 1
-
–建表(没有指定分隔符,所有使用Hive默认的分隔符 : \001)
create table db_msg.tb_msg_source( msg_time string comment "消息发送时间", sender_name string comment "发送人昵称", sender_account string comment "发送人账号", sender_sex string comment "发送人性别", sender_ip string comment "发送人ip地址", sender_os string comment "发送人操作系统", sender_phonetype string comment "发送人手机型号", sender_network string comment "发送人网络类型", sender_gps string comment "发送人的GPS定位", receiver_name string comment "接收人昵称", receiver_ip string comment "接收人IP", receiver_account string comment "接收人账号", receiver_os string comment "接收人操作系统", receiver_phonetype string comment "接收人手机型号", receiver_network string comment "接收人网络类型", receiver_gps string comment "接收人的GPS定位", receiver_sex string comment "接收人性别", msg_type string comment "消息类型", distance string comment "双方距离", message string comment "消息内容" );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
-
加载数据到表当中, 因为我们是从HDFS文件系统当中加载的数据,所以此时不需要使用
local关键字load data inpath '/chatdemo/data/data_30w' into table tb_msg_source;- 1
-
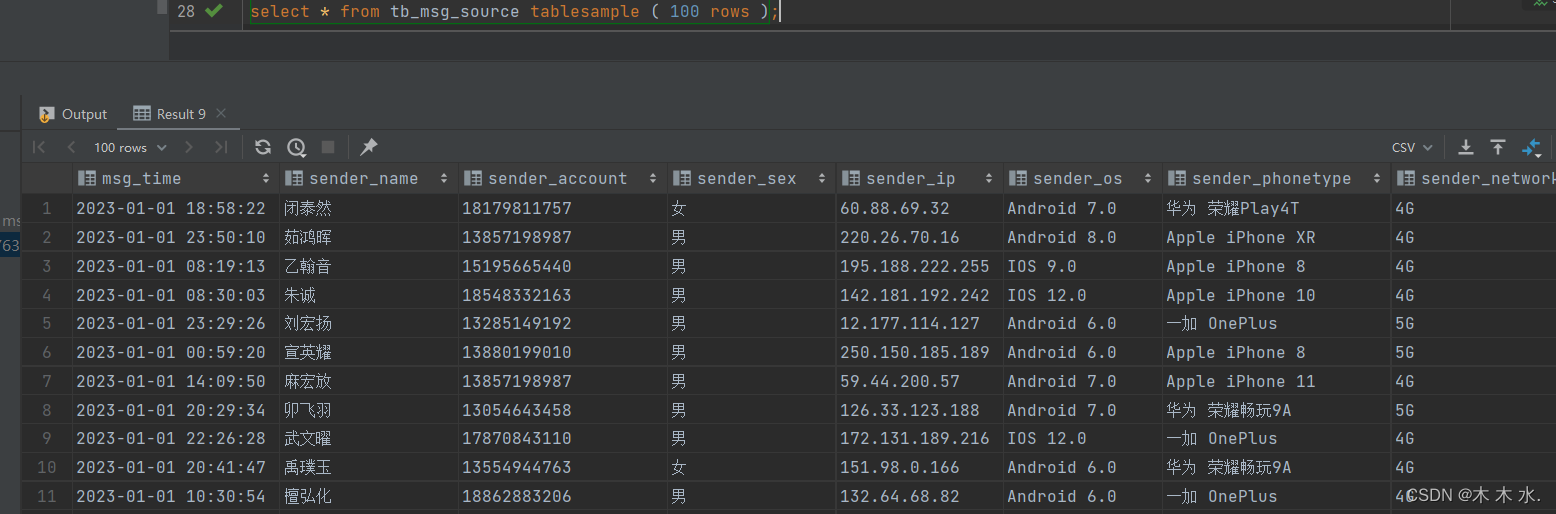
验证数据的加载
select * from tb_msg_source tablesample ( 100 rows );- 1
可以看到数据已经加载进入表当中了
-
验证数据的条数
select count(*) from tb_msg_source- 1
数据清洗
问题1:当前数据中,有一些数据的字段为空,不是合法数据
问题2:需求中,需要统计每天、每个小时的消息量,但是数据中没有天和小时字段,只有整体时间字段,不好处理
实现:
创建ETL表:
从表tb_msg_source 查询数据进行数据过滤和转换,并将结果写入到:tb_msg_etl表中的操作这种操作,本质上是一种简单的ETL行为。
ETL:E,Extract,抽取T,Transform,转换L,Load,
加载从A抽取数据(E),进行数据转换过滤(T),将结果加载到B(L),就是ETL啦
ETL在大数据系统中是非常常见的,后续我们还会继续接触到它。目前简单了解一下即可。
create table db_msg.tb_msg_etl( msg_time string comment "消息发送时间", sender_name string comment "发送人昵称", sender_account string comment "发送人账号", sender_sex string comment "发送人性别", sender_ip string comment "发送人ip地址", sender_os string comment "发送人操作系统", sender_phonetype string comment "发送人手机型号", sender_network string comment "发送人网络类型", sender_gps string comment "发送人的GPS定位", receiver_name string comment "接收人昵称", receiver_ip string comment "接收人IP", receiver_account string comment "接收人账号", receiver_os string comment "接收人操作系统", receiver_phonetype string comment "接收人手机型号", receiver_network string comment "接收人网络类型", receiver_gps string comment "接收人的GPS定位", receiver_sex string comment "接收人性别", msg_type string comment "消息类型", distance string comment "双方距离", message string comment "消息内容", msg_day string comment "消息日", msg_hour string comment "消息小时", sender_lng double comment "经度", sender_lat double comment "纬度" );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
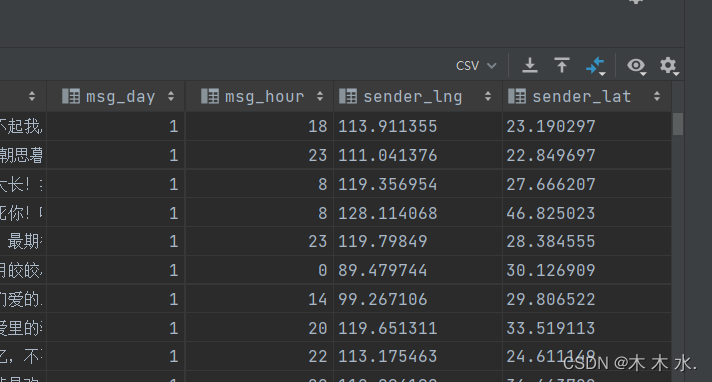
开始ETL过程 :
INSERT OVERWRITE TABLE db_msg.tb_msg_etl
SELECT
*,
day(msg_time) as msg_day,
HOUR(msg_time) as msg_hour,
split(sender_gps, ',')[0] AS sender_lng,
split(sender_gps, ',')[1] AS sender_lat
FROM tb_msg_source WHERE LENGTH(sender_gps) > 0;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
将经纬度与时间都分隔出来了.
以上就是本文实战操作.
结尾
恭喜小伙伴完成本篇文章的学习,相信文章的内容您已经掌握得十分清楚了,如果您对大数据的知识十分好奇,请接下来跟着学习路径完成大数据的学习哦,相信你会做到的~~~
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓

