
- 1通用大模型VS垂直大模型
- 2[大模型]Qwen2-7B-Instruct Lora 微调_qwen2 微调训练
- 3Python基础入门自学——10_def init(self, output: callable = print) -> bool:
- 4git解决合并冲突_git pull合并冲突
- 5python编写小游戏详细教程,用python做简单的小游戏_怎么编程小游戏
- 6反无人机技术详解
- 7vscode 无法导入自己写的模块文件(.py)问题_vscode中import无法导入
- 8类ChatGPT人工智能技术嵌入数字政府治理:价值、风险及其防控
- 92023年Android社招找工作需要掌握到什么程度?_2023android 简历 相关技能
- 10深度学习之Softmax回归_softmax回归 matlab csdn
【YOLO网络】总结_yolo的dbl模块
赞
踩
YOLO算法笔记
1.YOLOv3的结构
YOLO图像检测技术综述
YOLOv3取消YOLOv2的池化层可以提高运算速度
算法流程
YOLOv3的改进
YOLOv3网络结构图
根據上表可以得出,對於代碼層面的layers數量一共有252層,包括add層23層(主要用於res_block的構成,每個res_unit需要一個add層,一共有1+2+8+8+4=23層)。除此之外,BN層和LeakyReLU層數量完全一樣(72層),在網絡結構中的表現爲:每一層BN後面都會接一層LeakyReLU。卷積層一共有75層,其中有72層後面都會接BN+LeakyReLU的組合構成基本組件DBL。看結構圖,可以發現上採樣和concat都有2次,和表格分析中對應上。每個res_block都會用上一個零填充,一共有5個res_block。
作者並沒有像SSD那樣直接採用backbone中間層的處理結果作爲feature map的輸出,而是和後面網絡層的上採樣結果進行一個拼接之後的處理結果作爲feature map。爲什麼這麼做呢? 我感覺是有點玄學在裏面,一方面避免和其他算法做法重合,另一方面這也許是試驗之後並且結果證明更好的選擇,再者有可能就是因爲這麼做比較節省模型size的。
Darknet53由5个残差块组成借鉴了残差神经网络的思想。每个残差块由多个残差单元组成,残差单元由输入与两个DBL单元进行残差操作组成,DBL单元包括卷积、批归一化、leaky RELU函数。
YOLO V3对输人图片进行了5次降采样,并分别在最后3次降采样中对目标进行预测。最后3次降采样中包含了3个尺度目标检测的特征图。小特征图提供深层次的语义信息,大特征图则提供目标的位置信息,小特征图经过上采样后与大特征图融合.因此该模型既可以检测大目标.也可以检测小目标。
YOLO损失函数
2.改进:YOLOv3小目标检测
改进的 YOLOV3算法及其在小目标检测中的应用
算法思路流程:
利用原网络4倍降采样特征图进行检测的原因:它含有更多小目标的位置信息。原始网络利用8倍降采样的特征图,当目标小于8*8时,网络对目标的预测出现困难,并且检测能力有限。
- 首先.对数据集的样本进行聚类分析。得到数据集上对应的聚类中心。使用Avg IOU作为目标聚类分析的度量,对数据集进行分析,选取聚类中心个数 k=1–9,得到k与Avg iou的关系,当K=3时,即能加快损失函数收敛,又可以消除候选框的误差。
- 然后对YOLO V3输出的8倍下采样特征图进行2倍上采样,将2倍上采样特征图与Darknet53中的第2个残差块输出的4倍降采样特征图进行拼接,建立输出为4倍降采样的特征融合目标检测层,取消原有3个尺度上的输出检测。
- 最后为了获取更多的小目标特征信息,在YOLOV3网络结构Darknet53的第2个残差块中增加2个残差单元.(作用:获取更多低层的小目标位置信息)并将YOLO V3网络的目标检测输出层前的6个DBL单元变成2个DBL单元和两个ResNet单元实验结果表明。改进后的YOLOV3算法对小目标的召回率、检测的平均准确率均有明显的提高。
改进的YOLOv3网络结构
参数设置:
采用分辨率512*512的图片,改进的网络不对图像进行压缩和裁剪处理,保持输入图像的分辨率不变,对数据集中的9类目标检测
对YOLOV3和改进的YOU) V3分别进行练,训练阶段初始学习率为0.001.衰减系数为0.0005,当训练迭代次数为20000次和25000次时,分别将学习率降低为0.0001和0.00001,使损失函数进一步收敛。利用旋转图像、增加对比度等方法对数据集中的图像进行增强和扩充。
大约经过30000次迭代之后,各参数基本趋于稳定,最后的损失值下降到0.2左右,Avg IOU逐渐接近1,最终稳定在0.85左右。从此参数的收敛情况分析可知,改进的YOU) V3网络的训练结果比较理想。
结果
- 结果的定量对比: 改进的网络对9类小目标检测mAP提高了6.55%, 55.81%—>62.36
- 结果的定性对比: 改进的网络降低了漏检数和误检数,可以有效检测小目标。
3.改进YOLOv1模型
算法的思想
改进后的YOLO模型包含5个卷积层.4个最大值池化层和I个全连接层,卷积层和池化层中,s表示移动步长,P表示填零尺寸。在最后一层池化层输出与全连接层之间插入了一个Dropout层,从而提高模型的泛化能力,防止模型过拟合。经全连接层后,模型输出一个大小为637x1=(7x7x(2x5+3))的向量,表示舰船目标所在位置((x,y,二,h)、置信度分数:core及目标所属类别Class, (i= 1,2,3)。
训练参数
检测目标图像的大小,如果宽高均大于448,则将原图像平均分割为4个小图像,分别归一化处理后输入改进的YOLO模型;否则直接对原图像进行归一化处理,输入模型中。
首先在PASCAL VOC数据上进行预训练得到权重文件,并对网络初始化,再利用扩增的数据集对网络参数进行微调fine-tune完成神经网络的训练。
结果:查准率=93%和查全率90%,时间t=0.26s
4.基于YOLO的单目标(安全帽)的识别
算法流程:仅修改分类器的输出维度
- 在ImageNet上进行预训练模型,修改分类器,采用2000张训练集,1000张测试集,并进行数据扩增。
- 将安全帽检测转化为一个单分类的问题,减小网络的开销,安全帽的尺寸大小为,根据实际场景,修改分类器的最后一层输出维度为3*(5+1)=18,提高检测精度和速度。
- 通过分析训练的Loss值和Avg-IOU,采用迭代18000次的权重作为最终权重,进行测试,准确率98.7%,出现了漏检现象,漏检数大于误检数。
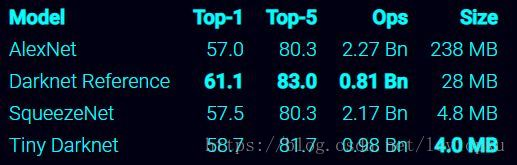
5.tiny-yolo
tiny-yolo的检测速度:
6.基于YOLOv2的目标检测算法设计与实现
两个方面:
- 提升检测精度
- 提高训练速度

yolo存在的问题:
- 在小物体和密集场景下检测效果不佳,召回率不高
- 采用固定阈值的筛选方法,去除置信度小于固定值的候选框,采用NMS去除重叠的候选框。
在不同场景下,固定闺值的缺陷也是十分明显的。因为不同图片中物体的密集程度、光影效果、图片模糊程度风格迥异,即使在同一张照片中,不同位置的日标所处的周边的环境情况也可能差异巨大。
NMS目前大量运用在目标检测算法中。但是由于其固定重叠阐值,且将大于其重叠阑值的相邻检测框置信度强制归零.这种情况下,某些可能真实出现在重叠区域的目标就会被这种硬闽值强置零的算法误删,导致算法对于该物体的检测失败,从而降低算法的平均检测率。这种情况在密集场景下的检测中尤其突出。
改进:NMS改进

基于线性衰减的NMS算法

动态阈值改进:
基础:空间金字塔池化SPP

利用多尺度卷积神经网络检测图像的密集程度,获得图像的稀疏程度矩阵(MM),利用SPP空间金字塔池化转成YOLO运算过程中所需要的动态阈值矩阵(SS)。


