
- 1面试官各种打压你,python爬虫爬取豆瓣电影Top250(1),Python高级面试framework
- 2《意志力》_父母给的钱不够吃早餐
- 3Redis数据类型, 在springboot中集成Redis_springboot redis list类型
- 4STA | 7. SDC是如何炼成的?Exception篇 - 附MCP电路实现方法及命令优先级实例
- 5HBase常用的shell命令_hbase substring:
- 6Parallels Desktop 16 已损坏,无法打开,您应该推出磁盘映像。怎么解决?_parallels desktop已损坏,推出磁盘映像
- 7【MySQL基础】MySQL基本数据类型_mysql数据类型
- 8物体检测-系列教程16:YOLOV5 源码解析6(马赛克数据增强函数load_mosaic)_yolov5mosaic数据增强代码
- 911.图论_图的复杂度
- 10DC与DCT DCG的区别_dc dct
python数分实战——麦当劳餐品营养分析及数据可视化(含数据源)_麦当劳数据分析图表
赞
踩
今天这篇文章将给大家介绍麦当劳餐品营养分析及数据可视化案例。
**麦当劳(McDonald’s)**是源自美国南加州的跨国连锁快餐店,也是全球最大的快餐连锁店,主要贩售汉堡包及薯条、炸鸡、汽水、冰品、沙拉、水果、咖啡等快餐食品。
近年来,越来越多的人意识到快餐食品的不健康性,麦当劳也成了“垃圾食品”的代名词。
美国纪录片**《Super Size Me》**记录了一个人一个月内只吃麦当劳后的身体变化,更引起了人们对于快餐食品营养超标的担忧。
本分析旨在通过实证方法评估麦当劳数据集中260个产品的营养成分,我们先从一些标准的数据探索分析开始,之后讨论并使用Plotly绘制交互式散点图以展示不同的营养指标。
01、导入数据
数据下载:评论区回复关键字**【数据集】**获取。
# 加载需要用的库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
import warnings
warnings.filterwarnings('ignore')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
#加载数据集
menu = pd.read_csv("../input/mc_menu/mcdonald_s_menu.csv")
#预览数据集前5行
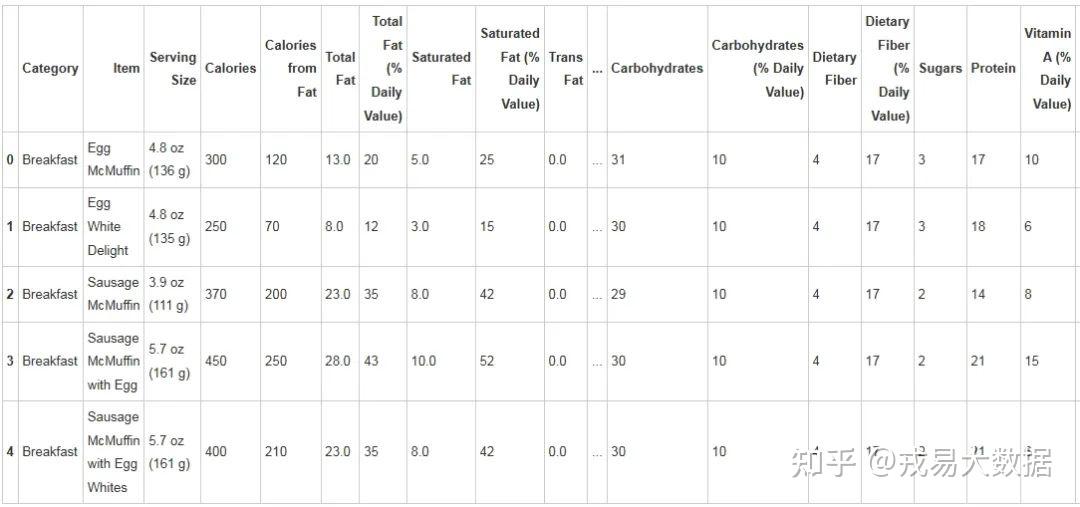
menu.head()
- 1
- 2
- 3
- 4
- 5
输出结果:
#查看数据集行列数
print("该数据集共有 {} 行 {} 列".format(menu.shape[0],menu.shape[1]))
- 1
- 2
输出结果:
该数据集共有 260 行 24 列
- 1
每一行代表一样麦当劳产品。
24列,包括了产品的类别,名称,大小,以及营养成分(如卡路里,脂肪,胆固醇,钠,碳水化合物,膳食纤维,糖,蛋白质,维他命A,维他命C,钙,铁)等内容。
02、数据质量检查
首先需要检查数据的质量,例如特征中是否存在空值或缺失值,数值的大小是否合理等等。
# 检查空值
menu.isnull().any()
- 1
- 2
输出结果:
Category False Item False Serving Size False Calories False Calories from Fat False Total Fat False Total Fat (% Daily Value) False Saturated Fat False Saturated Fat (% Daily Value) False Trans Fat False Cholesterol False Cholesterol (% Daily Value) False Sodium False Sodium (% Daily Value) False Carbohydrates False Carbohydrates (% Daily Value) False Dietary Fiber False Dietary Fiber (% Daily Value) False Sugars False Protein False Vitamin A (% Daily Value) False Vitamin C (% Daily Value) False Calcium (% Daily Value) False Iron (% Daily Value) False dtype: bool

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
# 各个column内容的描述性统计
menu.describe()
- 1
- 2
输出结果:
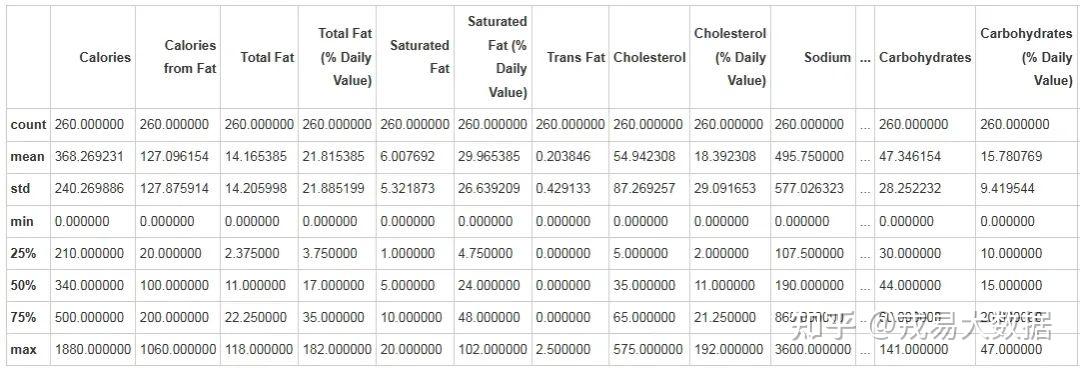
结论:
数据集中不存在空值,开始进行下一步的分析工作。
03、探索性分析
首先,我们看一下每一类食品的数量,并绘图展示:
count_by_category = menu[["Category"]].groupby(["Category"]).size().reset_index(name = 'Counts').sort_values(by = "Counts", ascending = False)
count_by_category
- 1
- 2
输出结果:

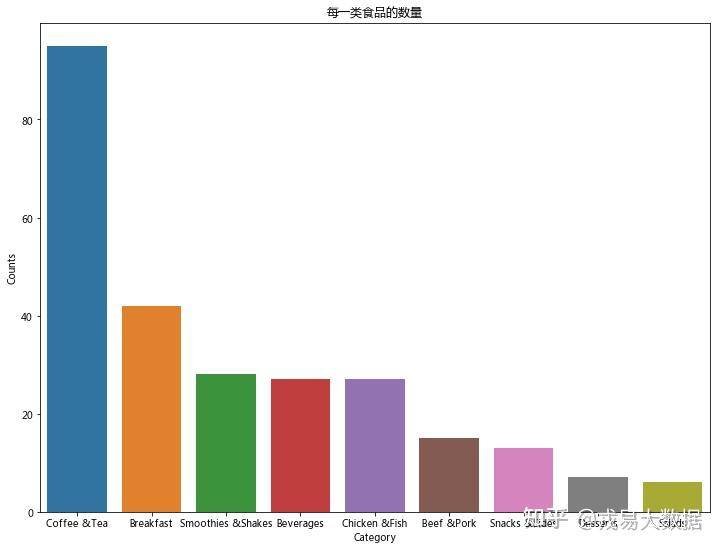
#条形图
fig, ax = plt.subplots(figsize = (12,9))
ax = sns.barplot(x="Category", y="Counts", data = count_by_category).set_title("每一类食品的数量")
- 1
- 2
- 3
输出结果:
#饼形图
plt.figure(figsize = (12,9))
plt.pie(x = count_by_category["Counts"], labels=count_by_category["Category"], autopct='%1.0f%%',)
plt.show()
- 1
- 2
- 3
- 4
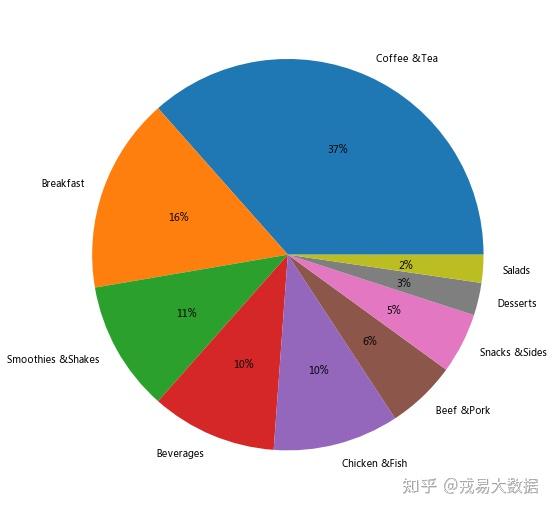
结论:
从条形图和饼形图可以看出,数量排名第一的品类是咖啡和茶,高达37%。
之后是早餐(16%),冰沙奶昔(11%),饮品(10%),鸡肉鱼肉(10%)和牛肉猪肉(6%)。
小吃,甜点和沙拉占比最少,其中沙拉类食品仅占所有食品的2%。
接下来,我们看看,不同品类的食物其卡路里含量如何呢?
#盒形图
fig, ax = plt.subplots(figsize = (12,9))
ax = sns.boxplot(x = 'Category', y = 'Calories', data = menu).set_title("卡路里")
- 1
- 2
- 3
输出结果:
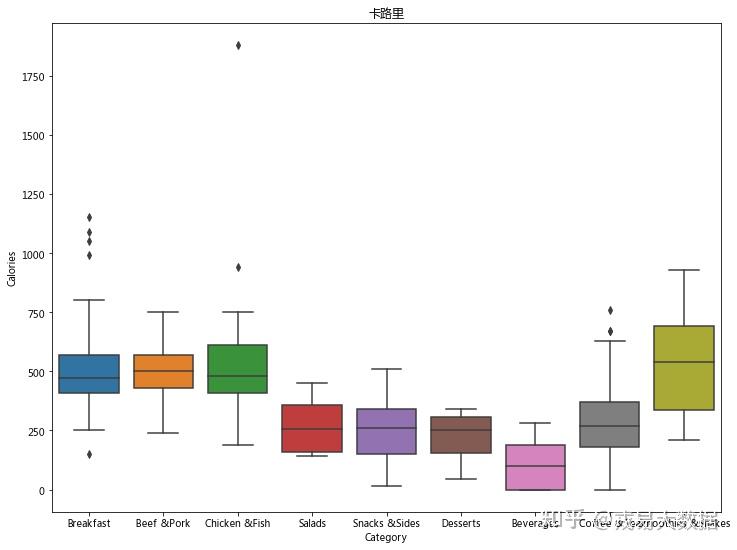
结论:
1、早餐系列、猪肉牛肉系列、鸡肉鱼肉系列的卡路里含量较高(主食),冰沙奶昔系列的卡路里含量最高。
2、沙拉、小食、甜品、咖啡和茶的卡路里含量较低,饮品的卡路里含量最低。
3、早餐系列、鸡肉鱼肉系列和咖啡茶系列有一些异常值(outlier),可能是一些大份食物。
以上分析提醒了我们:
食品的卡路里含量(及其他成分含量)会受到其份量的影响。
将食品调整至同样的份量可以让之后的分析更加客观。
通过回顾数据集中**“Serving Size”**一栏,我们发现麦当劳对份量的标注并不完全统一,有如下几种形式:
1、4.8 oz (136 g)
2、1 cookie (33 g)
3、21 fl oz cup
4、1 carton (236 ml)
5、6 fl oz (177 ml)
6、16.9 fl oz
固体食物的份量标注比较统一,都是按**【1】的形式,标出了oz和g两种重量单位,唯一的特例是【2】,只标注了g**这一重量单位。
半液态和液态食物的份量标注比较杂乱,有些和固体食物一样标注了重量,但大部分属于【3-6】,即标注fl oz和/或ml两种体积单位。
因此我们的提取原则是,重量单位优先提取g,没有g再提取oz,并转换为g。
体积单位优先提取ml,没有ml再提取fl oz,并转换为ml。
*注:1盎司(oz)=28.35克(g);1美制液体盎司(fl oz)=29.57毫升(ml)。
因为重量单位和体积单位的不一致,为了之后的分析方便,我们假设1ml的液体等于1g,并把一些半液态和液态食品的份量从体积转为重量。
#将食品调整至同样的份量(按100g计算) #正则表达式匹配几种不同的份量标注方式 import re p1 = re.compile(r'[(](.*?)[ g)]') p2 = re.compile(r'(.*?)[ ]') #定义函数,提取份量数据 def getLambda(x, p1, p2): try: val = float(re.findall(p1,x)[0]) except: val = float(re.findall(p2,x)[0]) * 29.57 # 提取的是fl oz,乘以29.57转换为ml return val #调整menu数据集 norm_menu = menu.iloc[:,:] norm_menu["Size g"] = norm_menu["Serving Size"].apply(lambda x: getLambda(x, p1, p2)) norm_menu["Calories per 100g"] = (norm_menu['Calories']/norm_menu["Size g"]) * 100 norm_menu.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
输出结果:
#盒形图
fig, ax = plt.subplots(figsize = (12,9))
sns.boxplot(x = 'Category', y = 'Calories per 100g', data = norm_menu)
- 1
- 2
- 3
输出结果:
<matplotlib.axes._subplots.AxesSubplot at 0x7f25b7ec5160>
- 1
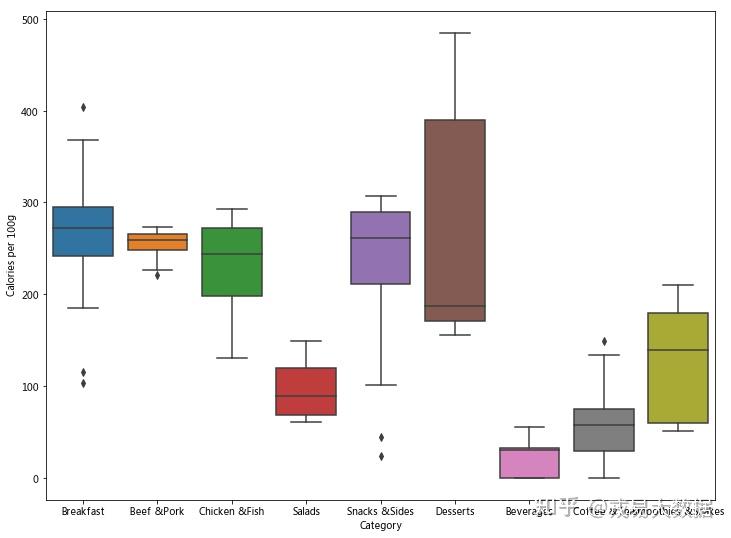
对比没有调整过的数据画出的盒形图可以得知:
固态食品中,主食(早餐,牛肉猪肉,鸡肉鱼肉)依旧是卡路里含量最高的食品。
之前我们以为卡路里含量较低的小食、甜点等,其实只是因为份量较小,如果换算成同样的份量,卡路里含量也不低,和主食持平。
只有沙拉的卡路里含量远低于其他类食品,其平均值是主食的一半左右。
液体及半液体的饮品,卡路里含量总体低于固体食品,但冰沙奶昔的卡路里明显高于饮料和咖啡茶,甚至高于沙拉。
因此,对于一个选择麦当劳就餐的减肥人士来说,为了填饱肚子,最好点一份沙拉。如果还想点一份饮品,不建议点冰沙奶昔。
04、数据可视化
轮廓图
我们首先看看一个特征如何影响其他特征:轮廓图或者KDE图可以提供一个特征相对于另一个特征的分布。
简单来讲,这让我们对定量数据有一个快速的感知。
调用了Seaborn中的kdeplo函数。我们选取了几个主要特征,并生成了9张轮廓图,如下所示:
# KDE图 f, axes = plt.subplots(3, 3, figsize=(10, 10), sharex=True, sharey=True) s = np.linspace(0, 3, 10) cmap = sns.cubehelix_palette(start=0.0, light=1, as_cmap=True) # Generate and plot a random bivariate dataset x = menu['Cholesterol (% Daily Value)'].values y = menu['Sodium (% Daily Value)'].values sns.kdeplot(x, y, cmap=cmap, shade=True, cut=5, ax=axes[0,0]) axes[0,0].set(xlim=(-10, 50), ylim=(-30, 70), title = 'Cholesterol and Sodium') cmap = sns.cubehelix_palette(start=0.333333333333, light=1, as_cmap=True) # Generate and plot a random bivariate dataset x = menu['Carbohydrates (% Daily Value)'].values y = menu['Sodium (% Daily Value)'].values sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[0,1]) axes[0,1].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Carbs and Sodium') cmap = sns.cubehelix_palette(start=0.666666666667, light=1, as_cmap=True) # Generate and plot a random bivariate dataset x = menu['Carbohydrates (% Daily Value)'].values y = menu['Cholesterol (% Daily Value)'].values sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[0,2]) axes[0,2].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Carbs and Cholesterol') cmap = sns.cubehelix_palette(start=1.0, light=1, as_cmap=True) # Generate and plot a random bivariate dataset x = menu['Total Fat (% Daily Value)'].values y = menu['Saturated Fat (% Daily Value)'].values sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[1,0]) axes[1,0].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Total Fat and Saturated Fat') cmap = sns.cubehelix_palette(start=1.333333333333, light=1, as_cmap=True) # Generate and plot a random bivariate dataset x = menu['Total Fat (% Daily Value)'].values y = menu['Cholesterol (% Daily Value)'].values sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[1,1]) axes[1,1].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Cholesterol and Total Fat') cmap = sns.cubehelix_palette(start=1.666666666667, light=1, as_cmap=True) # Generate and plot a random bivariate dataset x = menu['Vitamin A (% Daily Value)'].values y = menu['Cholesterol (% Daily Value)'].values sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[1,2]) axes[1,2].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Vitamin A and Cholesterol') cmap = sns.cubehelix_palette(start=2.0, light=1, as_cmap=True) # Generate and plot a random bivariate dataset x = menu['Calcium (% Daily Value)'].values y = menu['Sodium (% Daily Value)'].values sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[2,0]) axes[2,0].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Calcium and Sodium') cmap = sns.cubehelix_palette(start=2.333333333333, light=1, as_cmap=True) # Generate and plot a random bivariate dataset x = menu['Calcium (% Daily Value)'].values y = menu['Cholesterol (% Daily Value)'].values sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[2,1]) axes[2,1].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Cholesterol and Calcium') cmap = sns.cubehelix_palette(start=2.666666666667, light=1, as_cmap=True) # Generate and plot a random bivariate dataset x = menu['Iron (% Daily Value)'].values y = menu['Total Fat (% Daily Value)'].values sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[2,2]) axes[2,2].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Iron and Total Fat') f.tight_layout()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
输出结果:
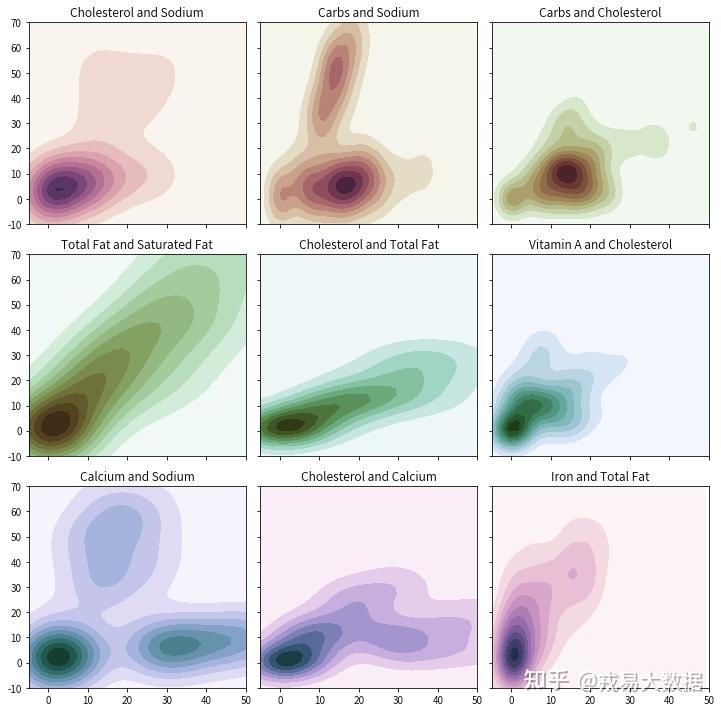
Pearson相关图
现在绘制Pearson相关图,检查不同营养指标之间的相关程度。
这次,我们调用了Plotly的交互式绘图功能,绘制特征之间相关性的热图(Heatmap),如下所示:
data = [ go.Heatmap( z = menu.ix[:, 3:].corr().values, x = menu.columns.values, y = menu.columns.values, colorscale = 'Viridis', text = True, opacity = 1.0 ) ] layout = go.Layout( title = '各个营养指标的Pearson相关图', xaxis = dict(ticks='', nticks=36), yaxis = dict(ticks=''), width = 900, height = 700, ) fig = go.Figure(data = data, layout = layout) py.iplot(fig, filename = 'labelled-heatmap')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
输出结果:
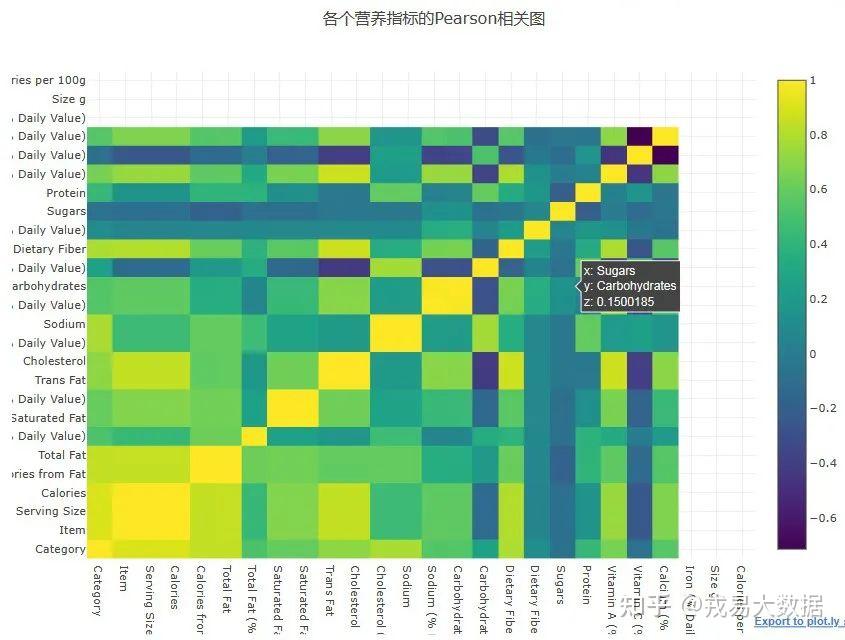
颜色越趋近于黄色,说明两者正相关性越强。
颜色越趋近于紫色,说明两者负相关性越强。
结论:
1、从相关图中可以看出明显相关的特征,例如份量和卡路里的相关性高达0.9。
2、然而,有一些相关性非常不直观。
例如,总脂肪和饱和脂肪/反式脂肪之间存在相当弱的相关性,但在我们普通人的认知中,这两者理应早存一定相关性。
3、热图也从**负相关图(深蓝/黑)**的斑点中引出了有趣的发现。
例如,它表明碳水化合物通常与反式脂肪,胆固醇,钠,膳食纤维和维生素A呈负相关。这与碳水化合物的负相关性确实很多。
数据质量是否存在任何问题?
现在很明显,碳水化合物列与其他列负相关程度很强,这是符合常识的。
然而,或许存在如下可能性:
**含碳水化合物的食物可能除了碳水化合物之外没有其他东西,**从而导致了上面提到的负相关性,这也是需要在分析中结合实际情况思考的。
分析每个产品的营养成分
对数据集中的特征进行了高度概述后,我们接下来进行更细粒度的分析。
首先,我们要解释一下**Daily Value(DV,每日推荐摄入量)**的概念。
它由FDA规定,是一份食物中关于营养成分的指南,基于一个健康成年人每天食用2000卡路里的食品。
例如,标签中标明15%的钙,那说明一份食物可以提供你一天所需要的钙的15%。
DV可以告诉你一种食品的营养成分是高还是低,如果在**5%**以下,就是偏低的;如果在20%以上,就是偏高的。
对于Trans Fat,FDA没有规定DV数值,因为专家推荐人们尽量避免含有反式脂肪的食品。
总体来看,应该选择富含维生素、矿物质和膳食纤维的食品,避免过多含有饱和脂肪酸、糖和纳的食品。
相比与营养成分本身的数值,其占每日推荐摄入量的百分比显得更加直观,因此接下来的分析使用的都是百分比。
我们使用Plotly交互式可视化工具,分析每一个产品的营养成分,并绘制交互式散点图。
●每个麦当劳产品的胆固醇(占每日推荐摄入量的百分比)散点图
trace = go.Scatter( y = menu['Cholesterol (% Daily Value)'].values, x = menu['Item'].values, mode='markers', marker=dict( size= menu['Cholesterol (% Daily Value)'].values, color = menu['Cholesterol (% Daily Value)'].values, colorscale='Portland', showscale=True ), text = menu['Item'].values ) data = [trace] layout= go.Layout( autosize= True, title= '胆固醇(占每日推荐摄入量的百分比)', hovermode= 'closest', xaxis=dict( showgrid=False, zeroline=False, showline=False ), yaxis=dict( title= 'Cholesterol (% Daily Value)', ticklen= 5, gridwidth= 2, showgrid=False, zeroline=False, showline=False ), showlegend= False ) fig = go.Figure(data=data, layout=layout) py.iplot(fig,filename='scatterChol')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
输出结果:
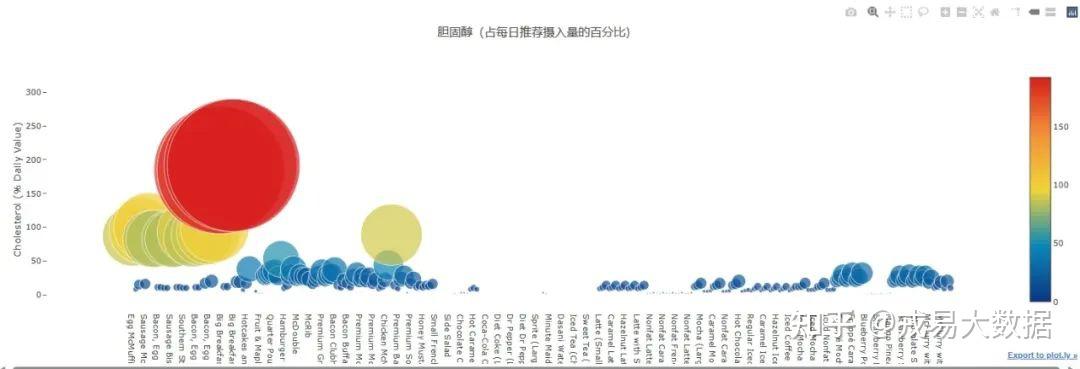
结论:
1、胆固醇散点图(以及之后一系列2D散点图)中,点的大小和颜色与营养成分的含量有关,十分直观。
2、最引人注目的是位于左上方的几个红点**(Big Breakfast系列),这表明某些食品的胆固醇含量远超每日推荐摄入量**,甚至达到了185%。
红点下面一些是更多的黄点**(如Egg/Sausage麦满分系列)**,这些食品的胆固醇含量基本上也满足了每日摄入量。
3、含有胆固醇最多的食物:Big Breakfast (Large Biscuit)。
●每个麦当劳产品的纳(占每日推荐摄入量的百分比)散点图
trace = go.Scatter( y = menu['Saturated Fat (% Daily Value)'].values, x = menu['Item'].values, mode='markers', marker=dict( size= menu['Saturated Fat (% Daily Value)'].values, color = menu['Saturated Fat (% Daily Value)'].values, colorscale='Portland', showscale=True ), text = menu['Item'].values ) data = [trace] layout= go.Layout( autosize= True, title= '饱和脂肪酸(占每日推荐摄入量的百分比)', hovermode= 'closest', xaxis=dict( showgrid=False, zeroline=False, showline=False ), yaxis=dict( title= 'Saturated Fat (% Daily Value)', ticklen= 5, gridwidth= 2, showgrid=False, zeroline=False, showline=False, ), showlegend= False ) fig = go.Figure(data=data, layout=layout) py.iplot(fig,filename='scatterChol')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
输出结果:
结论:
1、纳散点图的分布与上面的胆固醇散点图分布比较类似。
最大的红点来自于麦乐鸡(含40块),其含钠量是每日推荐摄入量的150%,其次是**大份早餐拼盘(含松饼)系列,在90%**左右。
2、含有纳最多的食物:麦乐鸡(含40块)。
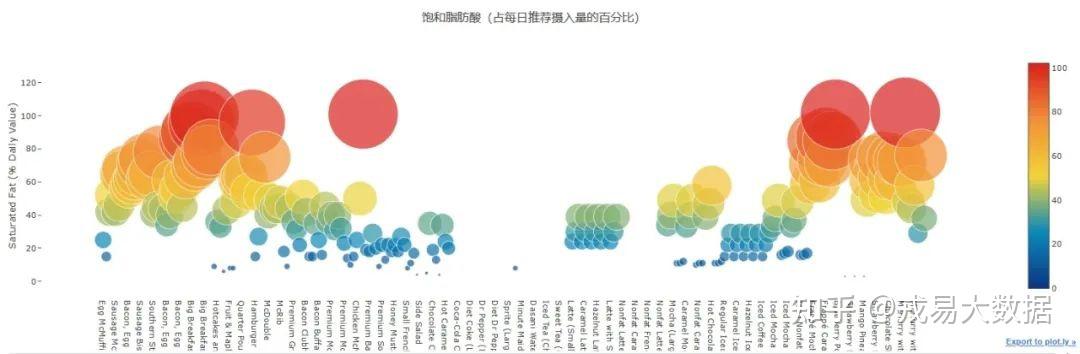
●每个麦当劳产品的饱和脂肪酸(占每日推荐摄入量的百分比)散点图
trace = go.Scatter( y = menu['Saturated Fat (% Daily Value)'].values, x = menu['Item'].values, mode='markers', marker=dict( size= menu['Saturated Fat (% Daily Value)'].values, color = menu['Saturated Fat (% Daily Value)'].values, colorscale='Portland', showscale=True ), text = menu['Item'].values ) data = [trace] layout= go.Layout( autosize= True, title= '饱和脂肪酸(占每日推荐摄入量的百分比)', hovermode= 'closest', xaxis=dict( showgrid=False, zeroline=False, showline=False ), yaxis=dict( title= 'Saturated Fat (% Daily Value)', ticklen= 5, gridwidth= 2, showgrid=False, zeroline=False, showline=False, ), showlegend= False ) fig = go.Figure(data=data, layout=layout) py.iplot(fig,filename='scatterChol')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
输出结果:
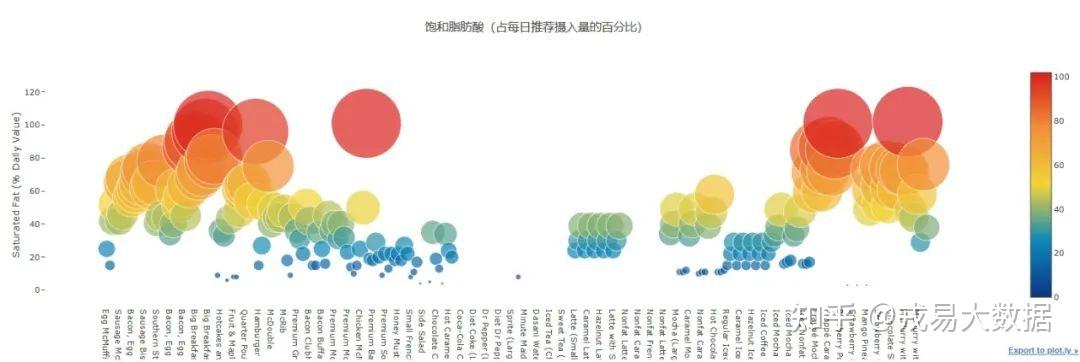
结论:
1、饱和脂肪酸散点图中含有了更多的红点,说明更多食物含有过量的饱和脂肪酸,只食用一份便可以达到每日推荐摄入量。
2、含有饱和脂肪酸最多的食物: **麦旋风(含MM豆), 麦乐鸡(含40块), 巧克力碎片咖啡冰沙, 大份早餐拼盘(含热松饼)**等
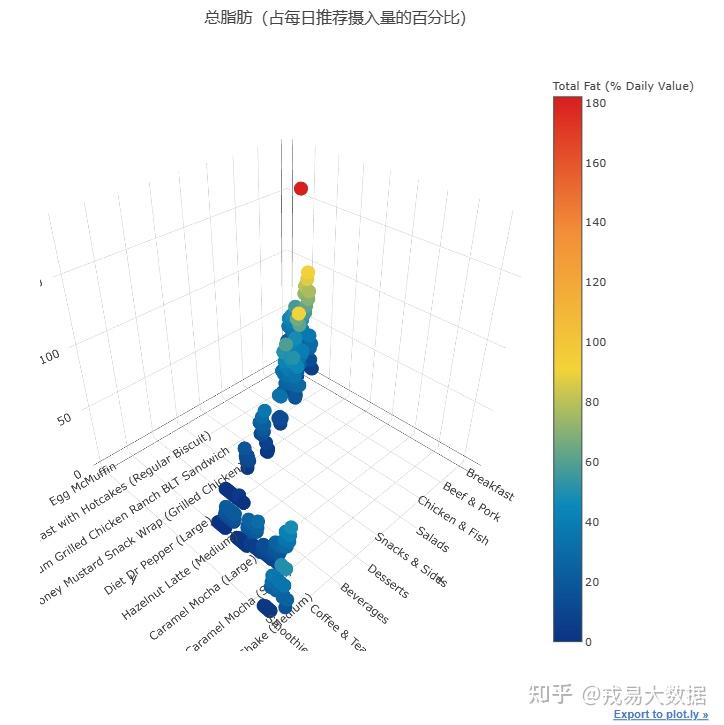
●每个麦当劳产品的总脂肪和碳水化合物水平的3D散点图
我们已经画了一些2D散点图,现在来探索一下Plotly的3D散点图功能。3D相对于2D加入了**食品类别(Category)**这个维度。
以下两幅3D散点图绘制了麦当劳不同产品的碳水化合物和总脂肪含量的分布情况:x轴是产品类别,y轴是具体产品,z轴是营养成分含量。
# 3D scatter plot for Total Fats trace1 = go.Scatter3d( x=menu['Category'].values, y=menu['Item'].values, z=menu['Total Fat (% Daily Value)'].values, text=menu['Item'].values, mode='markers', marker=dict( sizemode='diameter', color = menu['Total Fat (% Daily Value)'].values, colorscale = 'Portland', colorbar = dict(title = 'Total Fat (% Daily Value)'), line=dict(color='rgb(255, 255, 255)') ) ) data=[trace1] layout=dict(height=800, width=800, title='总脂肪(占每日推荐摄入量的百分比)') fig=dict(data=data, layout=layout) py.iplot(fig, filename='3DBubble')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
输出结果:
# 3D scatter plot for Carbohydrate trace1 = go.Scatter3d( x=menu['Category'].values, y=menu['Item'].values, z=menu['Carbohydrates (% Daily Value)'].values, text=menu['Item'].values, mode='markers', marker=dict( sizemode='diameter', color = menu['Carbohydrates (% Daily Value)'].values, colorscale = 'Portland', colorbar = dict(title = 'Carbohydrates (% Daily Value)'), line=dict(color='rgb(255, 255, 255)') ) ) data=[trace1] layout=dict(height=800, width=800, title='碳水化合物(占每日推荐摄入量的百分比)') fig=dict(data=data, layout=layout) py.iplot(fig, filename='3DBubble')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
输出结果:
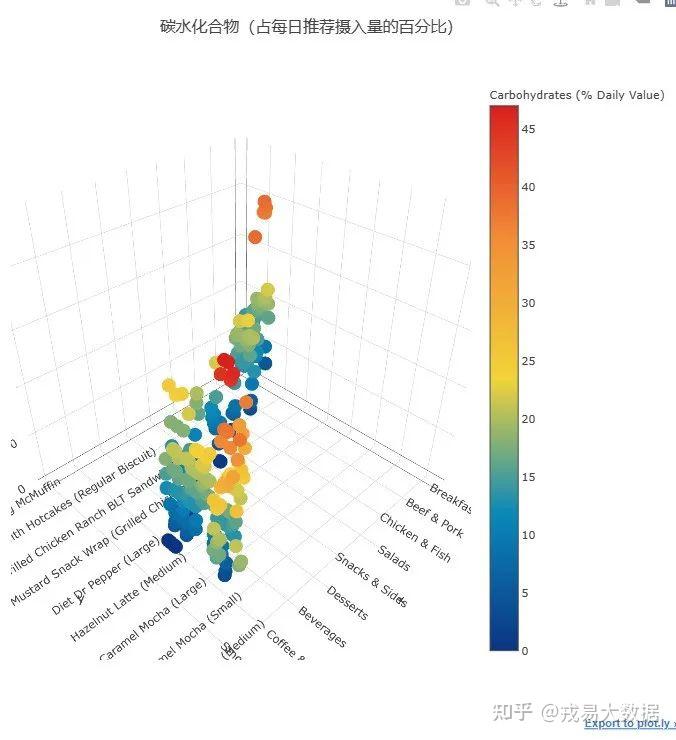
3D散点图让我们能够对比不同类别的食品的总脂肪和碳水化合物**(占每日推荐摄入量的百分比)**。
结论:
1、主食,尤其是早餐系列的食品,总脂肪占比非常高,一些食品接近100%。
2、饮料,尤其是冰沙奶昔,碳水化合物占比非常高,一些食品接近50%,可能是因为含糖量比较高。
3、想象一下,吃一份含松饼的早餐套餐,已经满足了一天脂肪摄入的需求,吃两杯份含MM豆的麦旋风,就满足了一天碳水摄入的需求!
以上的研究主要针对一些普遍被认为是**“不健康”的营养成分,如胆固醇,钠,总脂肪等等**。
下面我们来研究更多“正面”营养成分,如钙,铁,膳食纤维等。
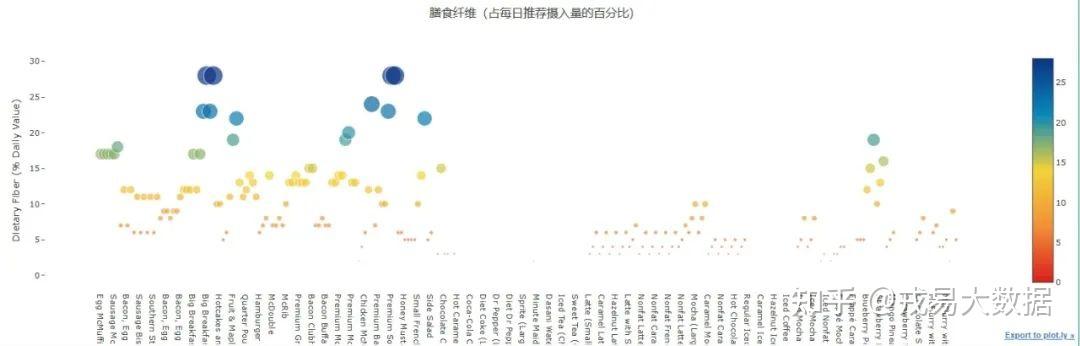
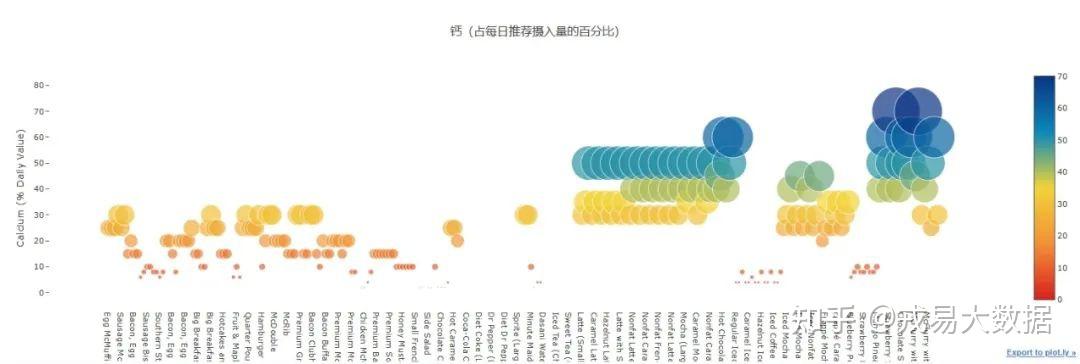
●每个麦当劳产品的膳食纤维,钙和铁(占每日推荐摄入量的百分比)散点图
#Dietary Fiber Scatter plots trace = go.Scatter( y = menu['Dietary Fiber (% Daily Value)'].values, x = menu['Item'].values, mode='markers', marker=dict( size= menu['Dietary Fiber (% Daily Value)'].values, color = menu['Dietary Fiber (% Daily Value)'].values, colorscale='Portland', reversescale = True, showscale=True ), text = menu['Item'].values ) data = [trace] layout= go.Layout( autosize= True, title= '膳食纤维(占每日推荐摄入量的百分比)', hovermode= 'closest', xaxis=dict( showgrid=False, zeroline=False, showline=False ), yaxis=dict( title= 'Dietary Fiber (% Daily Value)', ticklen= 5, gridwidth= 2, showgrid=False, zeroline=False, showline=False, ), showlegend= False ) fig = go.Figure(data=data, layout=layout) py.iplot(fig,filename='scatterChol')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
输出结果:
# Calcium Scatter plots trace = go.Scatter( y = menu['Calcium (% Daily Value)'].values, x = menu['Item'].values, mode='markers', marker=dict( size= menu['Calcium (% Daily Value)'].values, color = menu['Calcium (% Daily Value)'].values, colorscale='Portland', reversescale = True, showscale=True ), text = menu['Item'].values ) data = [trace] layout= go.Layout( autosize= True, title= '钙(占每日推荐摄入量的百分比)', hovermode= 'closest', xaxis=dict( showgrid=False, zeroline=False, showline=False ), yaxis=dict( title= 'Calcium (% Daily Value)', ticklen= 5, gridwidth= 2, showgrid=False, zeroline=False, showline=False, ), showlegend= False ) fig = go.Figure(data=data, layout=layout) py.iplot(fig,filename='scatterChol')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
输出结果:
# Iron Scatter plots trace = go.Scatter( y = menu['Iron (% Daily Value)'].values, x = menu['Item'].values, mode='markers', marker=dict( size= menu['Iron (% Daily Value)'].values, #color = np.random.randn(500), #set color equal to a variable color = menu['Iron (% Daily Value)'].values, colorscale='Portland', reversescale = True, showscale=True ), text = menu['Item'].values ) data = [trace] layout= go.Layout( autosize= True, title= '铁(占每日推荐摄入量的百分比)', hovermode= 'closest', xaxis=dict( showgrid=False, zeroline=False, showline=False ), yaxis=dict( title= 'Iron (% Daily Value)', ticklen= 5, gridwidth= 2, showgrid=False, zeroline=False, showline=False, ), showlegend= False ) fig = go.Figure(data=data, layout=layout) py.iplot(fig,filename='scatterChol')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
输出结果:
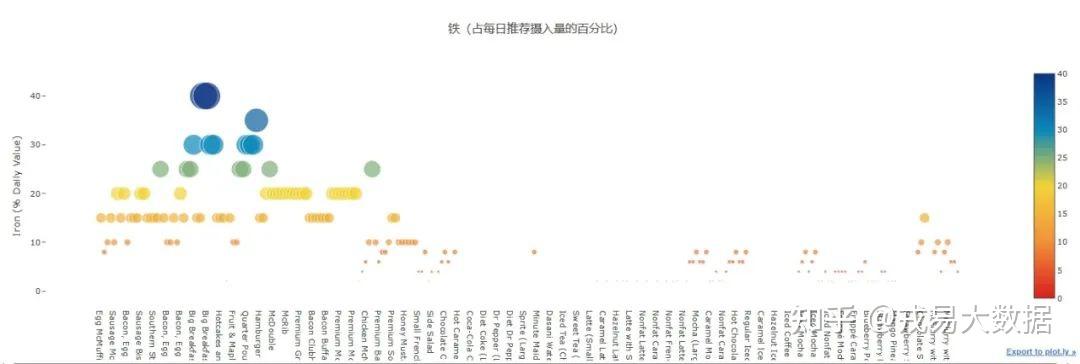
结论:
相比于不健康营养元素的**“频频超标”,健康营养元素的含量不尽如人意**。
没有任何食物的膳食纤维(占每日推荐摄入量的百分比)超过30%,铁超过40%。
●每种食品的卡路里含量:互动条形图
最后,我们绘制条形图,从高到低展示每种食品的卡路里含量。
先按照卡路里含量从高到低对食品排序,再使用Plotly绘制互动条形图。
#按照卡路里含量对食品排序 x, y = (list(x) for x in zip(*sorted(zip(menu.Calories.values, menu.Item.values), reverse = False))) # 绘制条形图 trace2 = go.Bar( x=x , y=y, marker=dict( color=x, colorscale = 'Jet', reversescale = False ), name='Household savings, percentage of household disposable income', orientation='h', ) layout = dict( title='麦当劳食品的卡路里含量', width = 1500, height = 2600, yaxis=dict( showgrid=False, showline=False, showticklabels=True, # domain=[0, 0.85], )) fig1 = go.Figure(data=[trace2]) fig1['layout'].update(layout) py.iplot(fig1, filename='plots')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
输出结果:
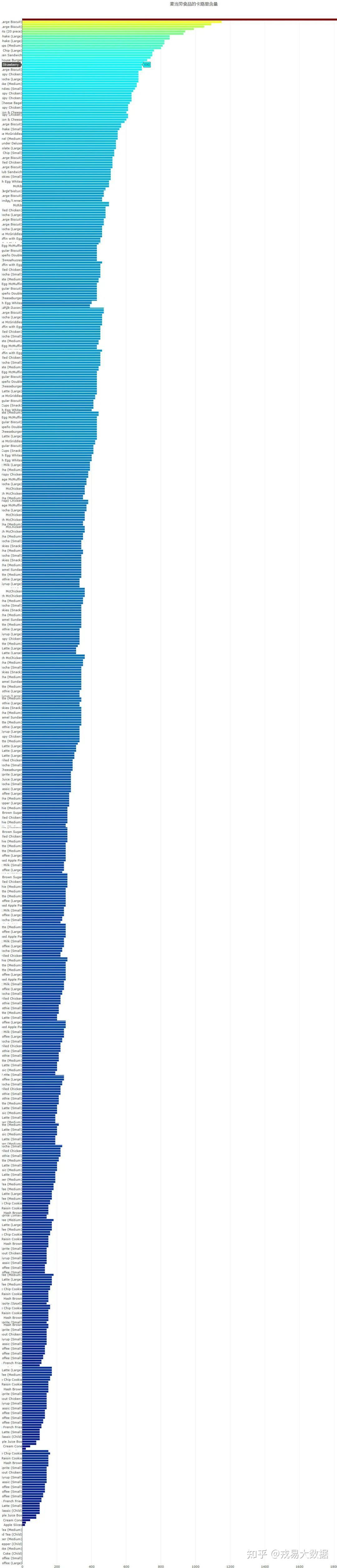
以上就是“python数分实战——麦当劳餐品营养分析及数据可视化(含数据源) ”的全部内容,希望对你有所帮助。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。


